Olá a todos, eu sou o Bittao. Se há coisa mais quente em 2023, é sem dúvida a onda AI liderada pelo ChatGPT. Este ano, sejam as várias mídias durante a semana, os projetos com os quais você entra em contato no trabalho ou os tópicos quentes que todos discutem em sua vida, a IA é inseparável. Na verdade, para a indústria da Internet, tem sido muito popular desde o advento do aprendizado profundo. No entanto, como a IA mais usada em termos de capacidade de monetização é o algoritmo de recomendação, o público em geral também é um pouco chato com a palavra IA. No entanto, o ChatGPT nasceu em novembro de 2022 e rapidamente rompeu o círculo em apenas dois meses, com usuários ativos mensais atingindo 100 milhões, tornando-se o principal produto do mundo. Algumas pessoas dizem que essa é a singularidade da tecnologia de IA, e que em breve a IA poderá substituir mais empregos; outros dizem que sempre falará de clichê, apenas um robô de bate-papo mais inteligente. De qualquer forma, é inegável que a inteligência artificial é o início da próxima revolução tecnológica. A IA não eliminará os humanos, a IA apenas eliminará os humanos que não podem usar a IA.
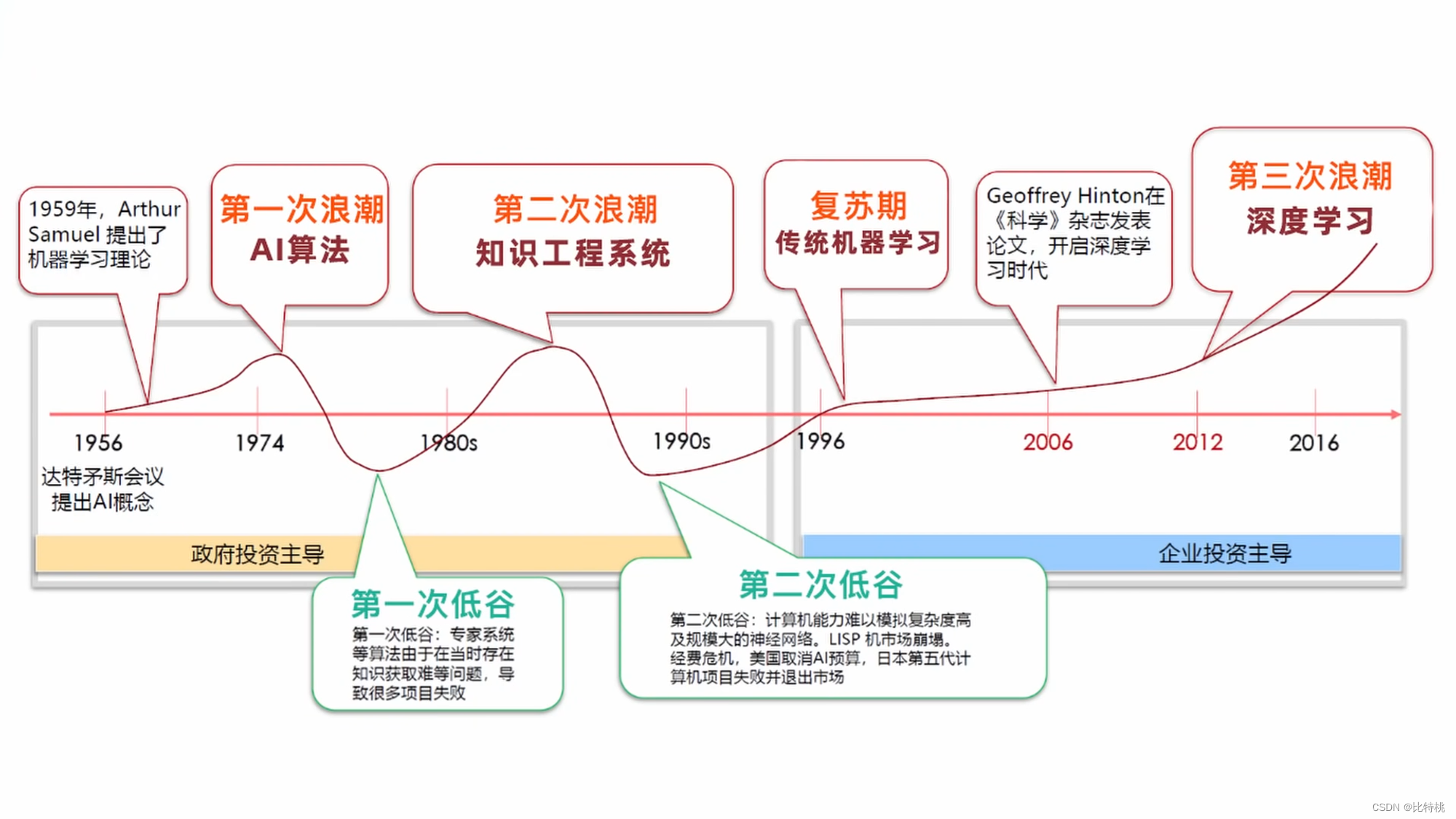
1. História da inteligência artificial
Embora a IA não esteja sob os olhos do público há muito tempo, teorias relacionadas já tomaram forma no século passado.
- Em 1940, a Cibernética descreveu o estudo interdisciplinar de explorar sistemas regulatórios, que é usado para estudar a estrutura, limitações e desenvolvimento de sistemas de controle. É o estudo científico de como pessoas, animais e máquinas controlam e se comunicam uns com os outros.
- Em 1943, os neurocientistas americanos McCulloch e Pitts propuseram redes neurais e criaram um modelo chamado modelo MP.
- Em 1950, com o desenvolvimento da ciência da computação, neurociência e matemática, Turing publicou um artigo que atravessou a era e propôs um teste muito filosófico,
The Imitation Gametambém conhecido como teste de Turing. A ideia geral é: no processo de bate-papo entre um humano e uma máquina, se a outra parte não for uma máquina, isso é chamado de teste de Turing. - Em 1956, Marvin Sky, John McCarthy e Claude Shannon (o fundador da teoria da informação) realizaram uma conferência: a Conferência de Dartmouth. A questão principal é se as pessoas podem pensar como pessoas, e a palavra IA apareceu.
- Em 1966, o robô de bate-papo do MIT, Eliza, o sistema anterior era baseado na correspondência de padrões PatternMatching, baseada em regras.
- Em 1997, o IBM Deep Blue derrotou o campeão de xadrez. Sinton, da Universidade de Toronto, introduziu o algoritmo de retropropagação BP na inteligência artificial; Yang Likun, da Universidade de Nova York, cuja famosa contribuição é a rede neural convolucional CNN; Bengio, da Universidade de Montreal (modelo de linguagem de probabilidade neural, geração de redes de confronto).
- Em 2010, um campo de aprendizado de máquina,
Artificial Neural Networksa rede neural artificial, começou a brilhar.
2. Aprendizado de máquina
A tarefa comum do aprendizado de máquina é descobrir automaticamente as leis por trás dos dados por meio de algoritmos de treinamento, melhorar continuamente o modelo e fazer previsões. Existem muitos algoritmos em aprendizado de máquina, entre os quais o algoritmo mais clássico é: 梯度下降算法. Pode nos ajudar a lidar com problemas de classificação e regressão. Através y=wx+bdo ajuste linear desta fórmula, o resultado se aproxima do valor correto.
2.1 Função de previsão
Suponha que tenhamos um conjunto de pontos amostrais causais, cada um representando um conjunto de variáveis causais. Por exemplo, o preço e a área da casa, a altura e o ritmo de uma pessoa e assim por diante. O senso comum nos diz que suas distribuições são diretamente proporcionais. Primeiro, o algoritmo de descida do gradiente determina uma pequena função de previsão de destino, que é uma linha reta que passa pela origem y = wx. Nossa tarefa é projetar um algoritmo para que esta máquina possa ajustar esses dados e nos ajudar a calcular o parâmetro w da linha reta.
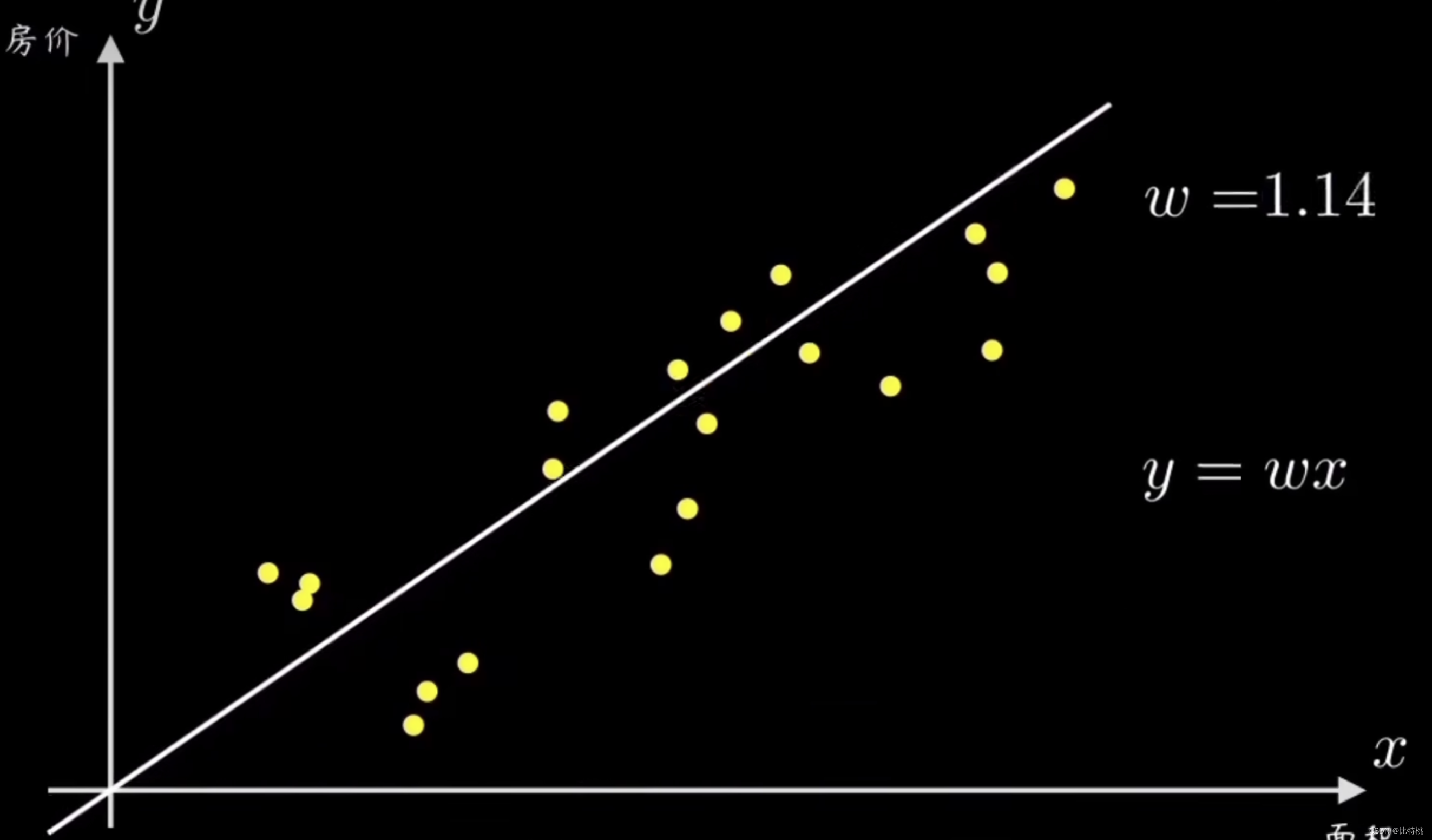
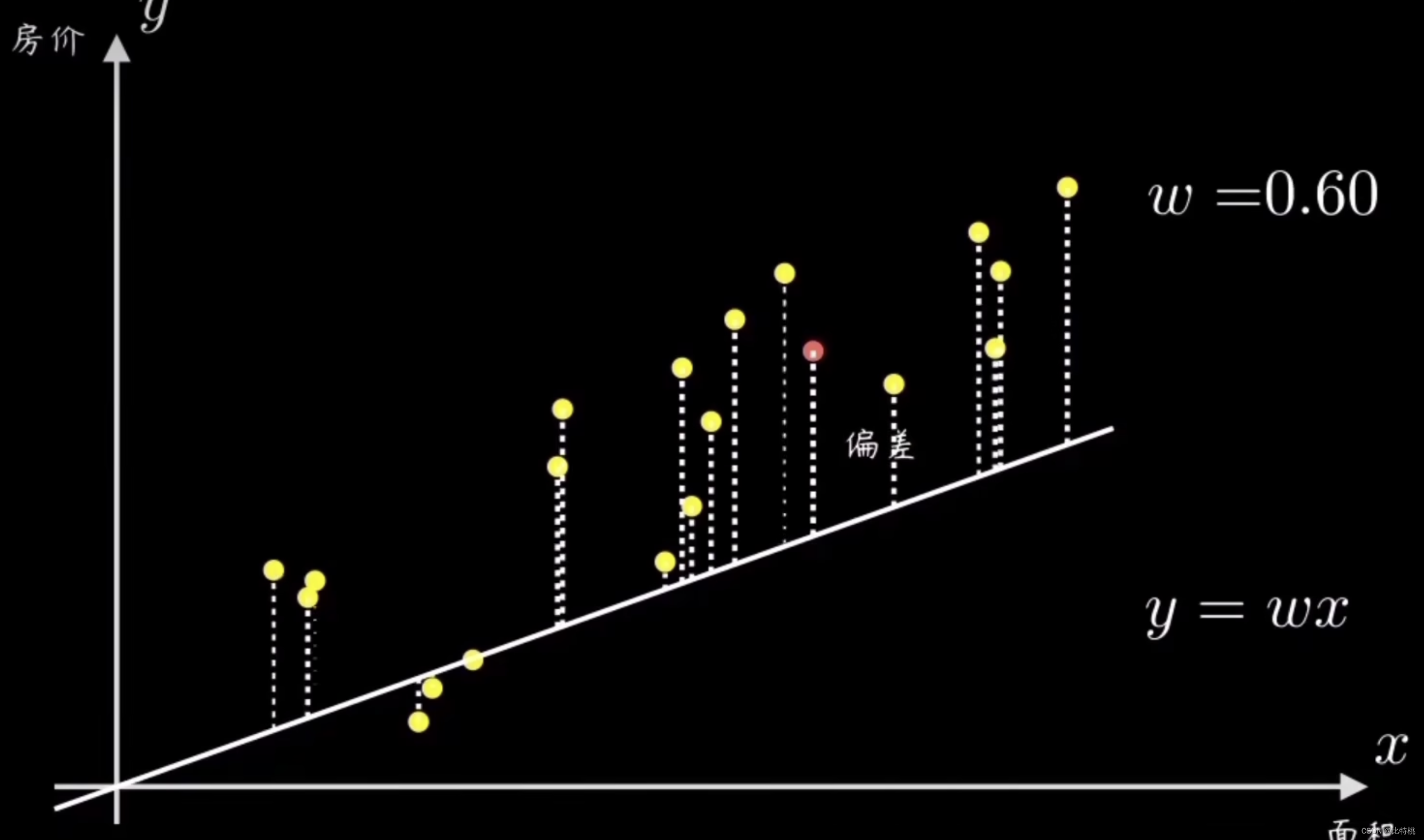
Uma maneira simples é selecionar aleatoriamente uma linha reta passando pela origem e, em seguida, calcular todos os pontos de amostra e seu desvio. Em seguida, ajuste a inclinação da linha w de acordo com o tamanho do erro.Ao
ajustar os parâmetros, quanto menor a função de perda, mais precisa é a previsão. Neste caso y = wxé a chamada função de previsão.
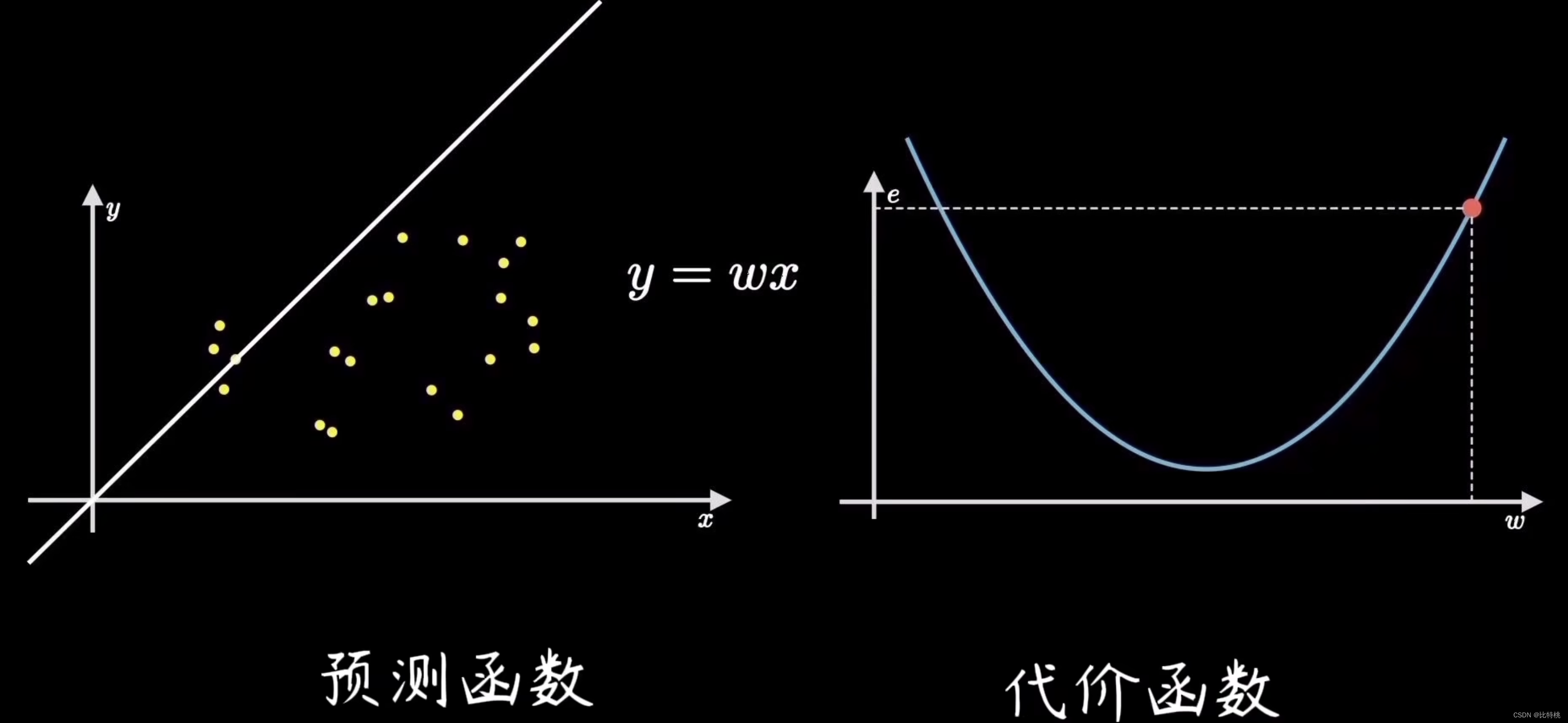
2.2 Função de custo
O processo de encontrar o erro é calcular a função de custo. Ao quantificar o grau de desvio dos dados, ou seja, o erro, o mais comum é o erro quadrático médio (a média da soma dos quadrados do erro). Por exemplo, o valor do erro é e, porque o coeficiente de encontrar o erro é a fórmula da soma dos quadrados, então a imagem da função e é mostrada no lado direito da figura abaixo. Veremos que quando a função de e estiver no ponto mais baixo, o erro na figura da esquerda será menor, ou seja, o ajuste será mais preciso.
2.3 Cálculo de gradiente
O objetivo do aprendizado de máquina é ajustar a reta mais próxima da distribuição dos dados de treinamento, ou seja, encontrar os parâmetros que minimizem o custo do erro, que corresponde ao ponto mais baixo da função de custo. Este processo de encontrar o ponto mais baixo é chamado de ** 梯度下降**.
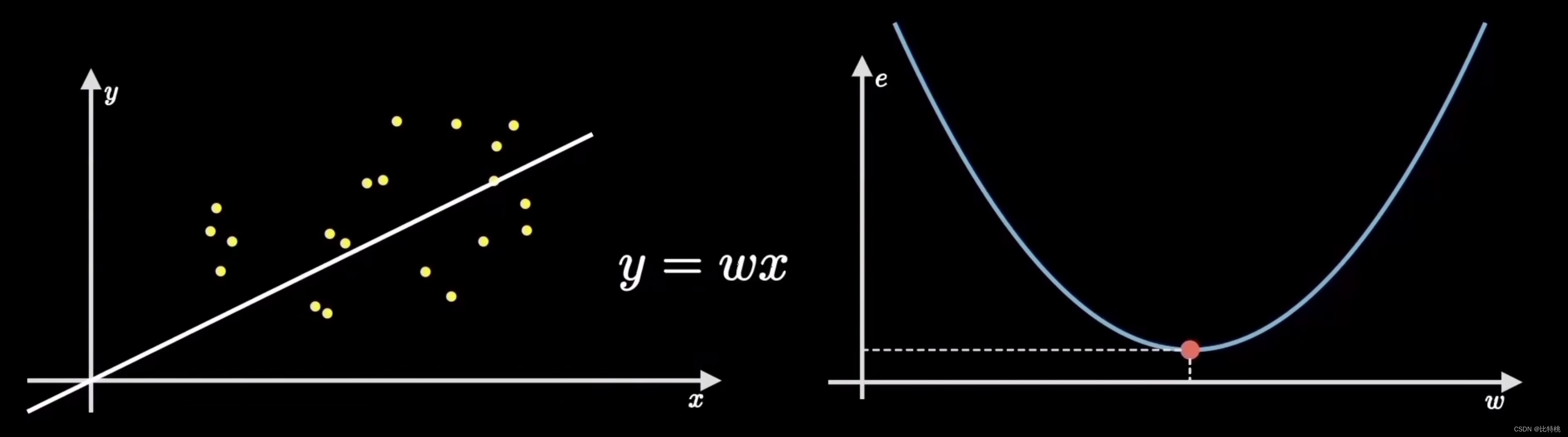
Usar o algoritmo de descida de gradiente para treinar esse parâmetro é muito semelhante ao aprendizado humano e ao processo cognitivo. A teoria do desenvolvimento cognitivo de Piaget, a chamada assimilação e adaptação, é exatamente igual ao processo de aprendizado de máquina.
3. Aprendizado Profundo
Houve muita controvérsia nos primeiros dias sobre se o algoritmo de IA deveria ser implementado usando um método de operação semelhante ao cérebro humano. E antes do surgimento do aprendizado profundo, a maioria dos cientistas da computação se dedicava à direção de pesquisa semelhante à correspondência de padrões. Agora parece que esse método é obviamente muito difícil de fazer máquinas tão inteligentes quanto os humanos. Mas não podemos olhar para as pessoas naquela época da perspectiva atual. Naquela época, os dados e o poder de computação eram escassos, então, naturalmente, havia um conjunto de teorias para refutar a ideia de usar um humanoide cérebro para alcançá-lo.
Como um computador pode funcionar com o mesmo princípio de um cérebro humano? Ainda temos que usar algoritmos tradicionais para resolver o problema. Isso também indiretamente levou à estagnação da IA naquela época. Para os Ph.D.s que estudaram nessa direção, a realidade é cruel. Por isso existe aquele ditado: O esforço humano é importante, mas também depende da direção .
Em 1943, os neurocientistas exploraram o princípio de funcionamento do cérebro humano.No cérebro humano, mais de 10 bilhões de neurônios estão conectados por meio de uma rede para julgar e transmitir informações.
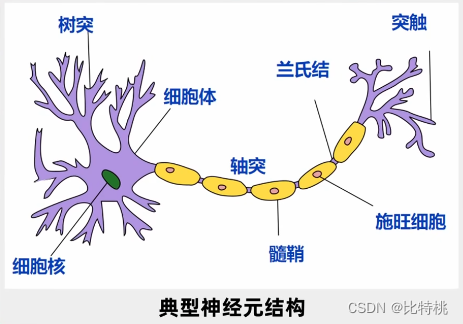
Cada neurônio tem várias entradas e uma única saída. O sinal pode ser obtido através de vários neurônios, e o sinal pode ser processado de forma abrangente, e o sinal pode ser enviado a jusante, se necessário. Esta saída tem apenas dois sinais, 0 ou 1, muito semelhantes a um computador. Então eles propuseram um modelo chamado modelo MP.
A rede neural artificial é um modelo matemático algorítmico que imita as características de comportamento das redes neurais de animais e realiza o processamento paralelo distribuído de informações. O aprendizado profundo é um algoritmo que usa redes neurais artificiais como estrutura para realizar o aprendizado de representação nos dados.
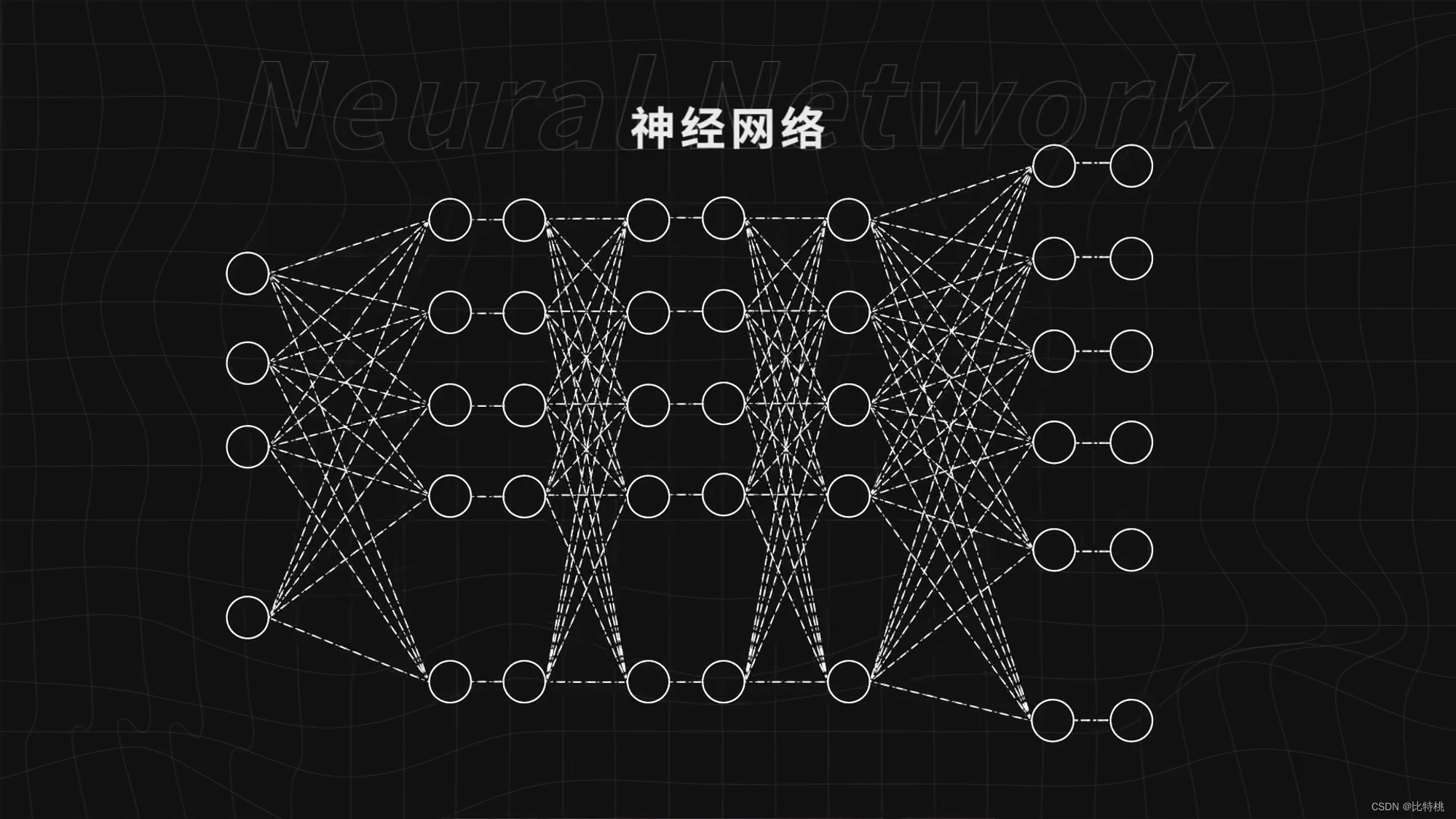
3.1 Rede neural
Conforme mostrado na figura abaixo, um círculo é um neurônio e esses círculos formam uma rede neural. Forneça dados suficientes à rede neural, diga à rede neural se ela está indo bem ou não e continue treinando a rede neural, ela pode fazer cada vez melhor e concluir tarefas complexas, como reconhecer imagens.
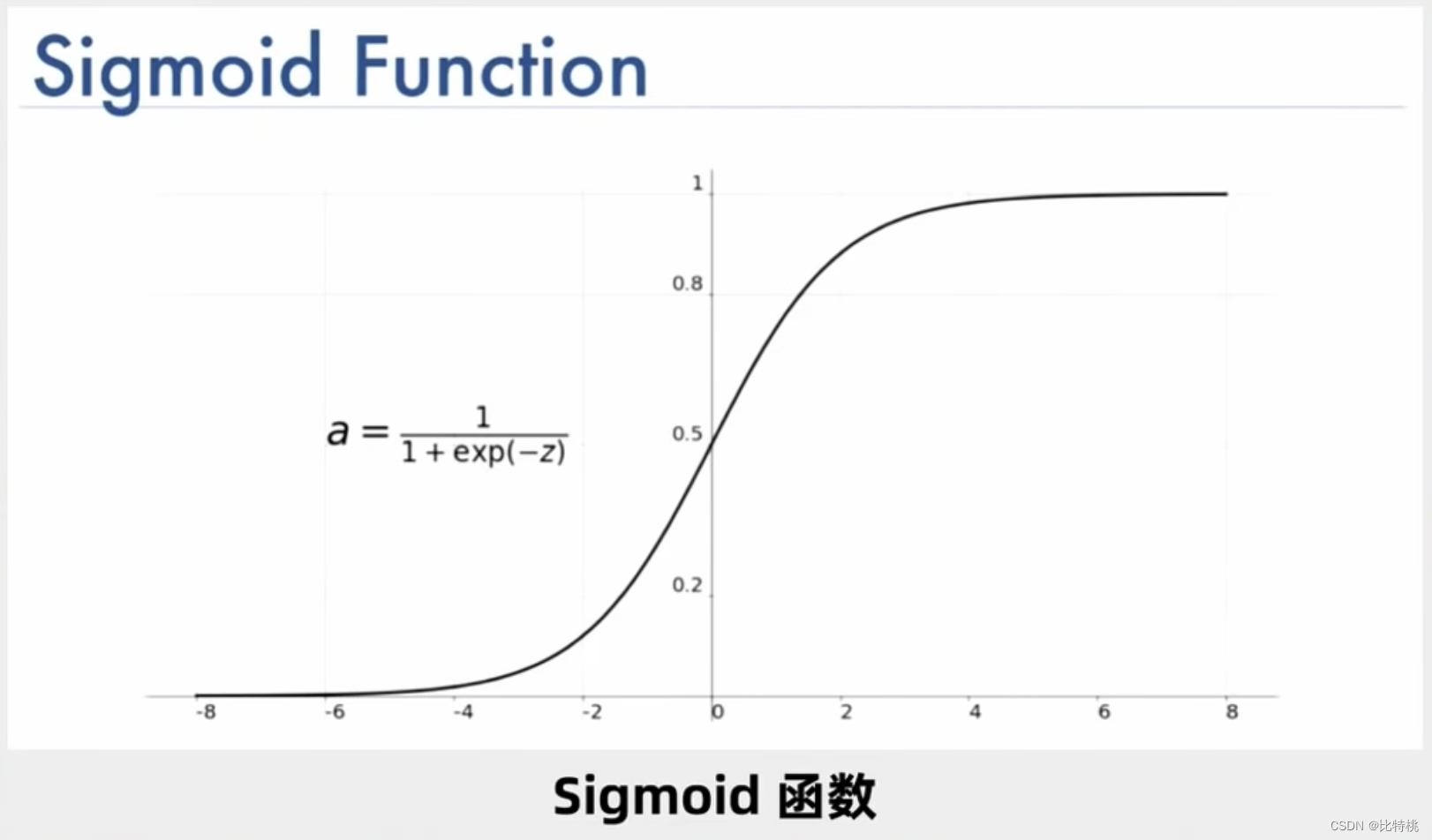
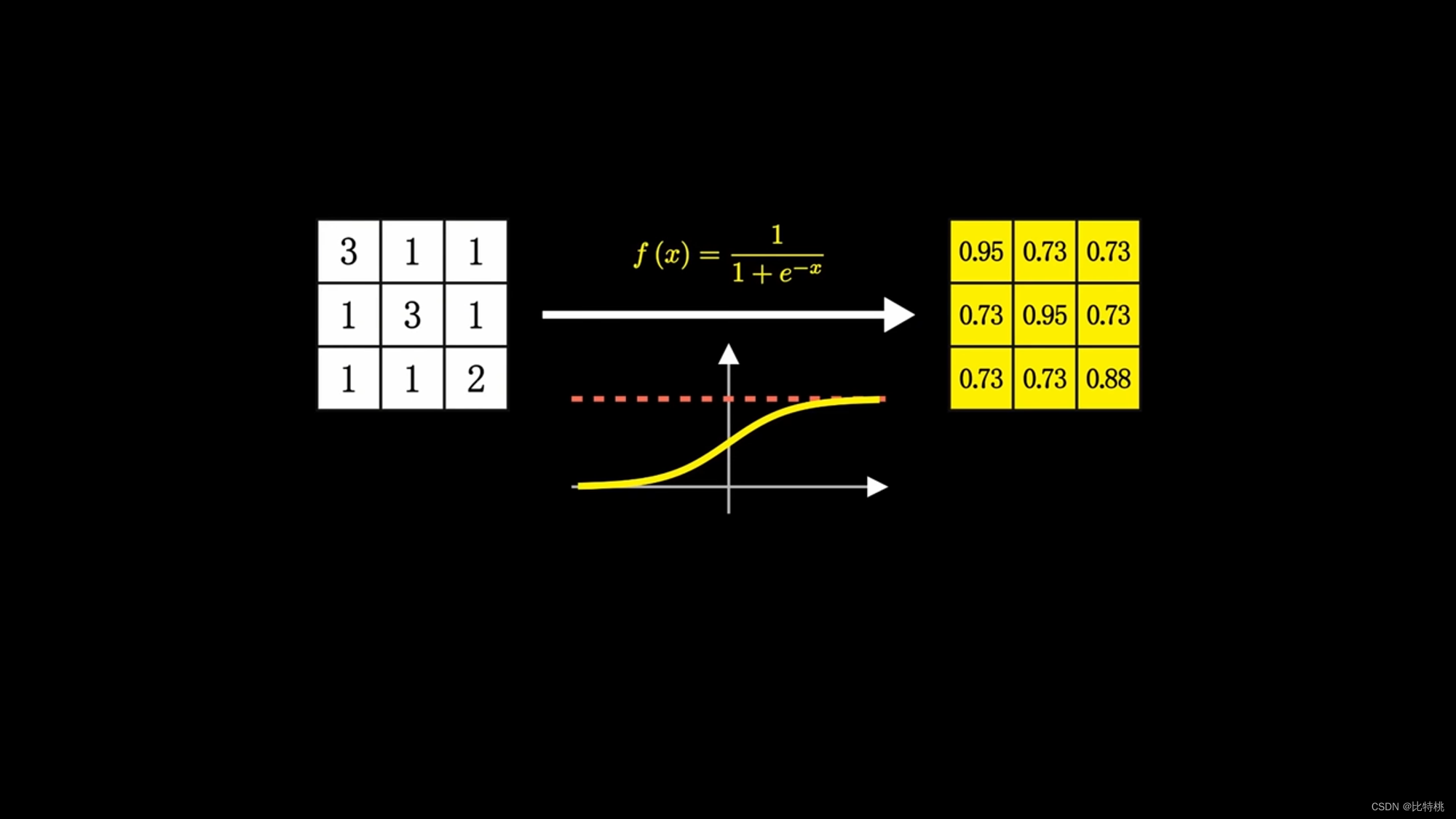
Na verdade, o cálculo dos neurônios é um monte de adições e multiplicações, mas como são suficientes, fica muito complicado. Um neurônio pode ter várias entradas e apenas uma saída, mas pode ativar vários neurônios. Por exemplo, a figura abaixo é uma das funções de ativação do Sigmóide, e sua faixa de valores pode ser encontrada em (0, 1).
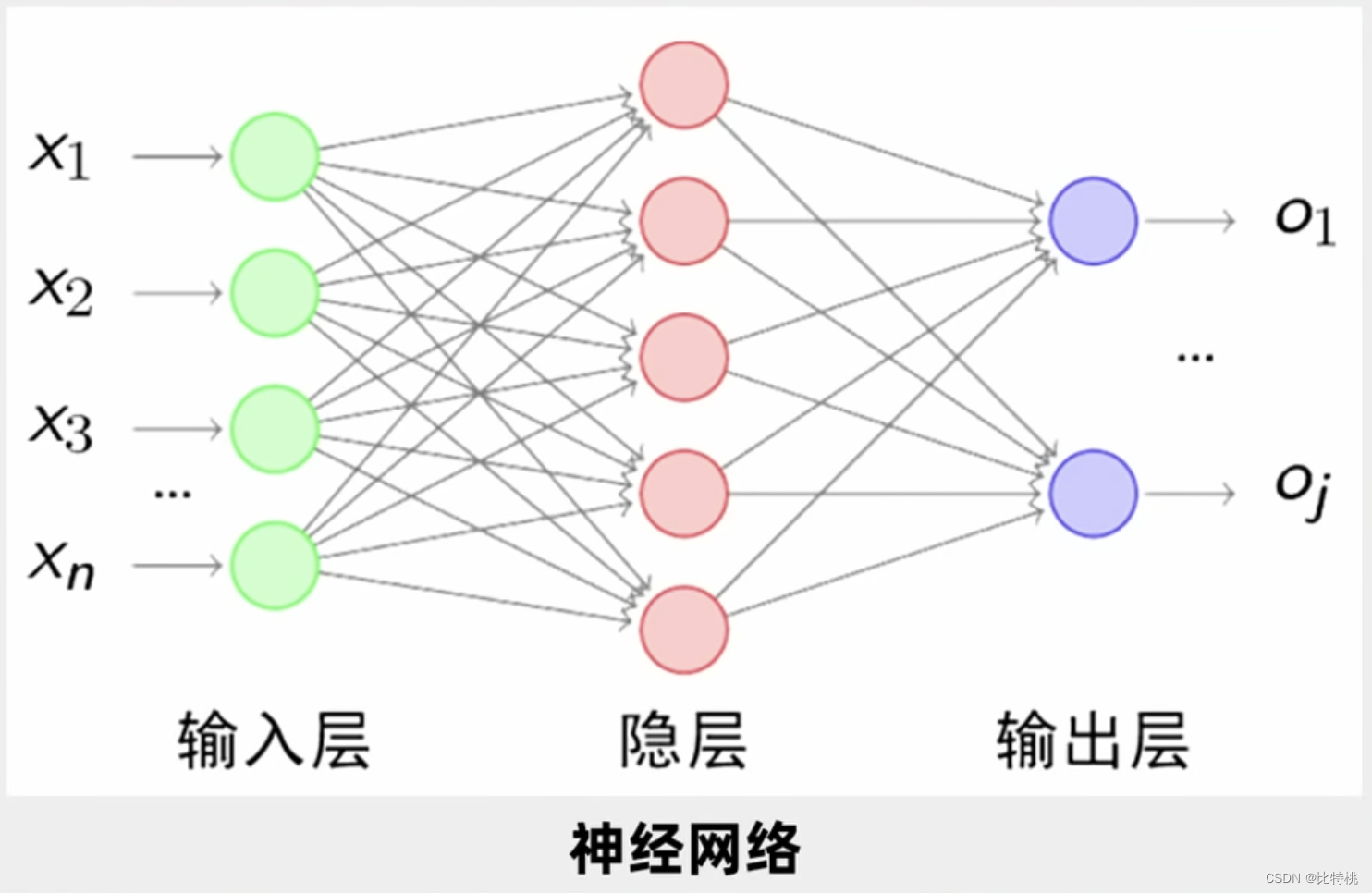
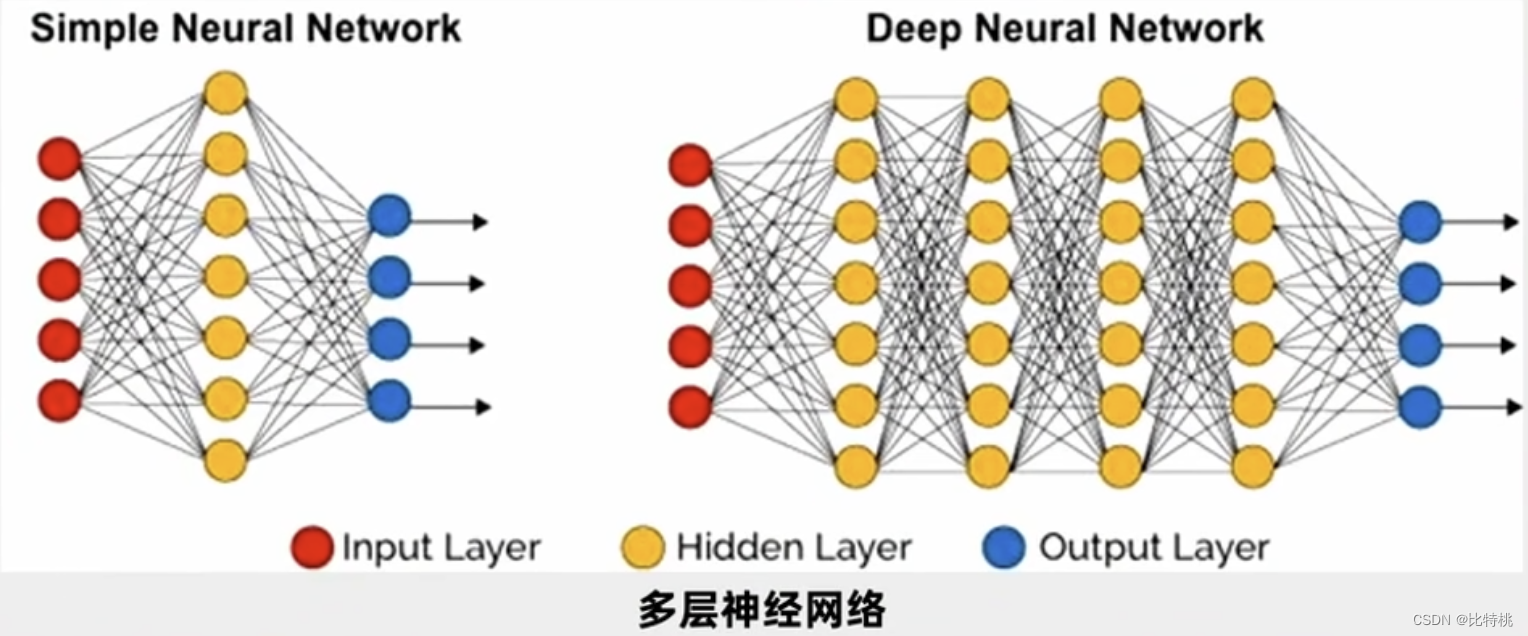
Se for apenas para julgar se é X, basta uma camada, mas, na prática, precisamos entender o reconhecimento de voz e imagem de outras pessoas. Então, as pessoas estudam várias camadas de neurônios. Uma entrada conforme mostrado na figura e, em seguida, o terminal de entrada é conectado a cada neurônio da primeira camada oculta. Depois que a primeira camada oculta gera os dados, ela escolhe a saída para a segunda camada oculta e a segunda camada oculta A saída da camada entra na terceira camada oculta. Isso é chamado de rede neural multicamada. Há um grande número de parâmetros entre cada duas camadas e ajustamos um grande número de parâmetros para o ótimo para que a função de erro final seja minimizada.
Embora as operações realizadas pelos neurônios não sejam complicadas, uma vez que a cena é complexa, a ordem de grandeza será muito grande. Por exemplo, uma imagem 5*5 tem 25 neurônios em cada camada, 625 parâmetros em cada camada e mais de 2.000 em três camadas. Se for uma imagem colorida, é mais complicado de reconhecer e muito lento de calcular. Esta é também a razão pela qual a inteligência artificial foi subestimada nos últimos tempos, nem o poder de computação nem o algoritmo conseguem acompanhar. Mais tarde, o algoritmo BP e a retropropagação apareceram, e a última camada pode ser ajustada primeiro. Depois que a última camada é ajustada, ela é ajustada para frente.A complexidade deste algoritmo é menor que a do anterior. O algoritmo BP resolve principalmente a perda de erros e o cálculo de erros no processo de transmissão de informações entre várias camadas da rede neural, liderando a terceira onda de inteligência artificial.
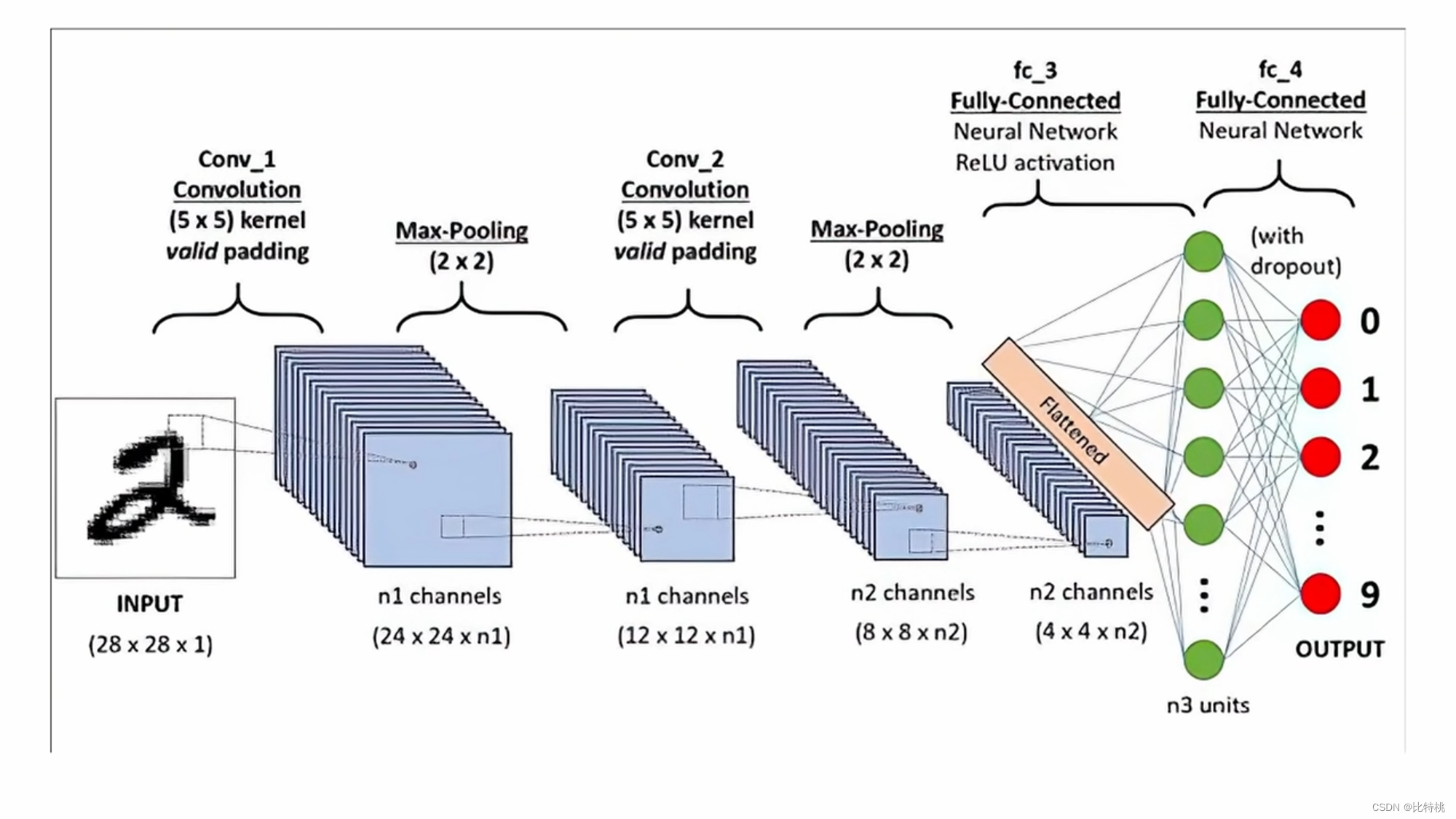
3.2 CNN
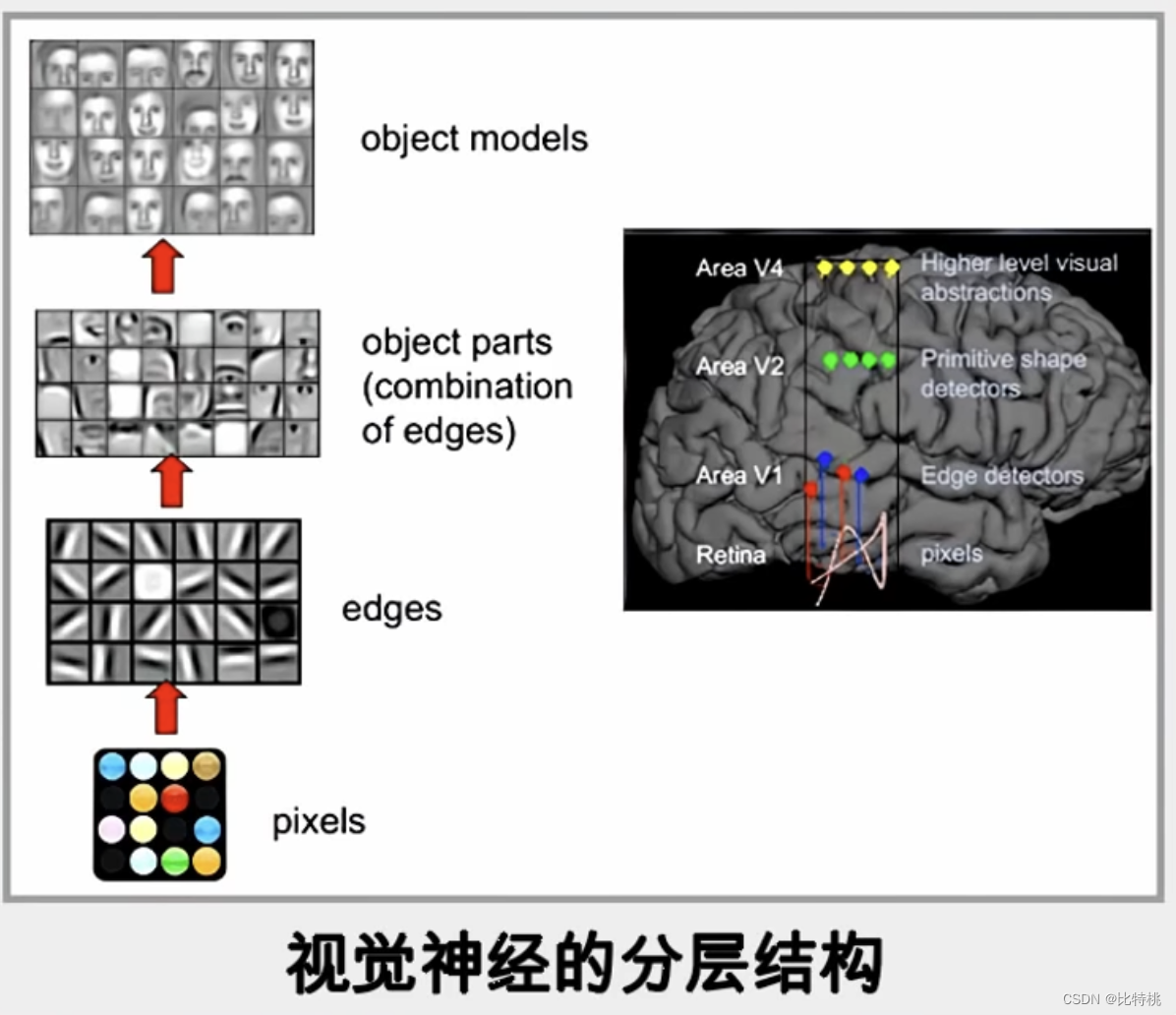
Aqui ainda tomamos um algoritmo mais clássico no algoritmo de rede neural: rede neural convolucional CNN como exemplo. O processo é semelhante ao reconhecimento cerebral dos animais: quando uma imagem é refletida no cérebro, ele vai do ponto à linha ao objeto e finalmente reconhece o que é. O mesmo é verdadeiro para computadores, que realizam o reconhecimento de imagem por meio de julgamento de detalhes de contorno de borda de pontos de pixel.
Por exemplo, se quisermos identificar se uma imagem é Xum desses caracteres, essa imagem é uma matriz bidimensional para o computador, por exemplo, preto é 1 e branco é 0. Como mostrado na figura abaixo:

Depois de ser dado ao computador, uma série de processos de treinamento pode ser usada para encontrar um grande número de parâmetros para julgar se é um X. Encontre uma função com a menor perda, ou seja, um treinamento bem-sucedido. A partir daí, posso usar esse monte de parâmetros para julgar se uma imagem é X ou não.
Especificamente, podemos usar o kernel de convolução para realizar operações de convolução extraindo os recursos da imagem. Por exemplo, o kernel de convolução é uma linha vertical inclinada (achamos que essa é uma das características da imagem X).

O núcleo de convolução (uma linha vertical inclinada) é aplicado à imagem e a operação é executada, e o resultado da operação é colocado no meio da cobertura da imagem. Então a combinação é o mapa de recursos. Quanto maior o recurso calculado, mais ele pode expressar esse recurso.
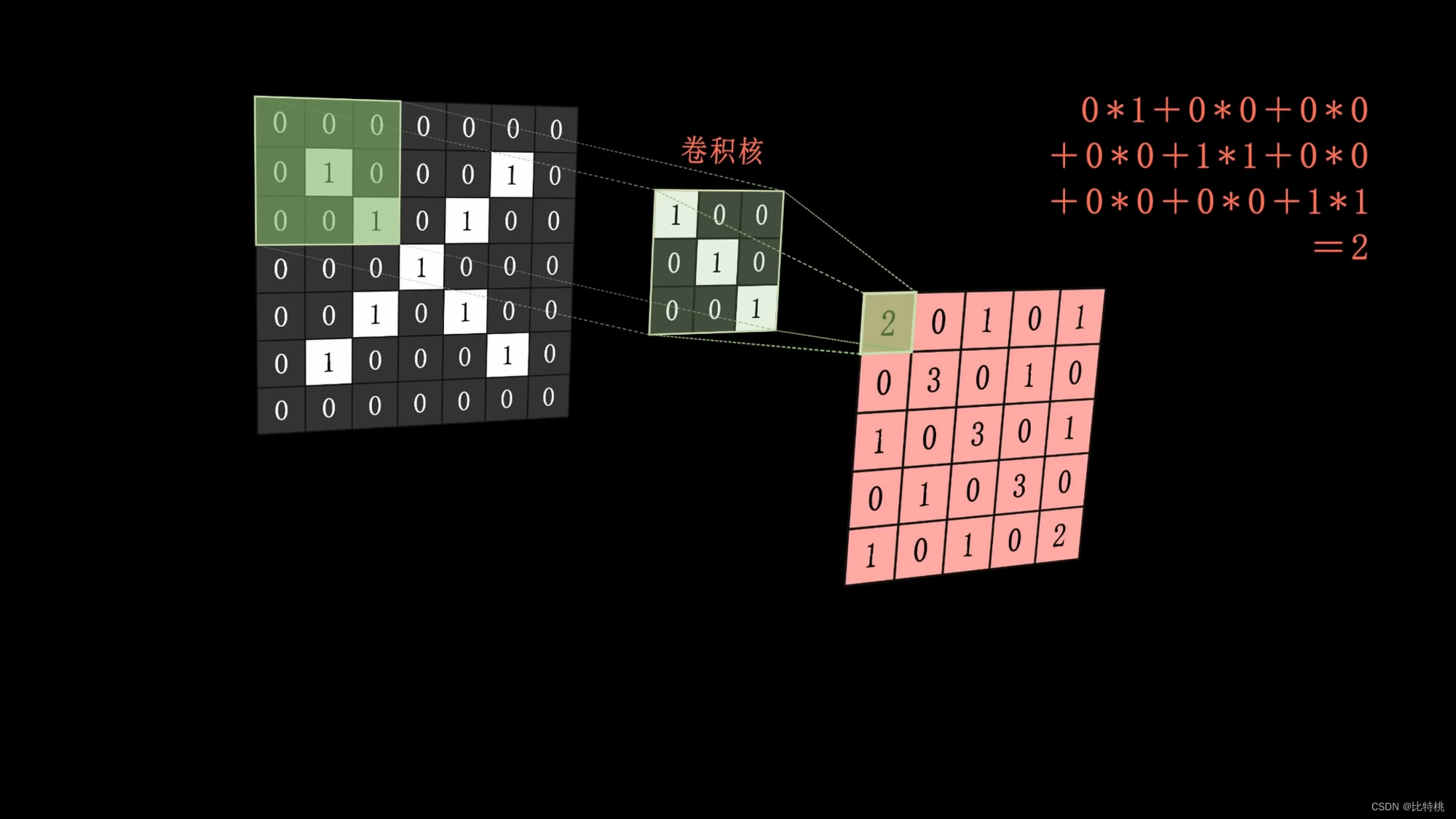
Como a quantidade de cálculo é muito grande, usamos o kernel de convolução para escanear uma área por uma área. Multiplique cada número correspondente e adicione a soma. As feições numéricas regionais são extraídas. Os dados são então agrupados, o valor máximo na área é obtido e a quantidade de dados característicos é concentrada e nivelada. Insira a rede neural completa, porque envolve operações de convolução, também é chamada de rede neural convolucional. O tamanho, o ritmo e o número de camadas convolucionais do kernel de convolução podem ser ajustados com antecedência. O valor emitido pela máquina é comparado com o valor predefinido para o resultado alvo. Se corresponder às expectativas, é um sucesso. Se não atender às expectativas, uma série de cálculos será realizada para ajustar inversamente os parâmetros (BP) de cada link, calcular novamente e repetir até atender às expectativas. Esse é o princípio do aprendizado de máquina. Convolução -> Pooling -> Ativação.
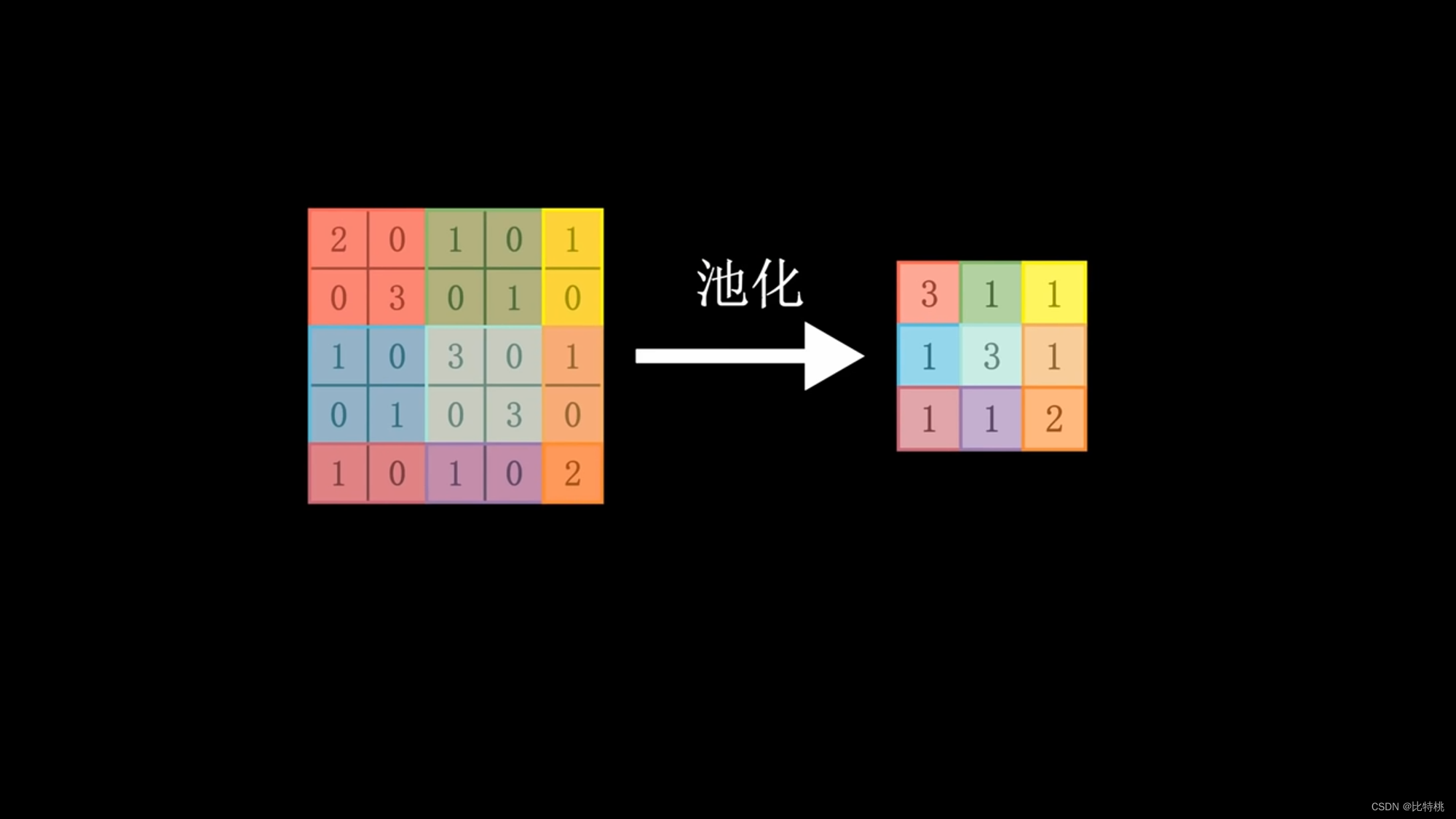
Através dos dados de características após a convolução, podemos ver que quanto mais próximo o número estiver de 1, mais ele satisfaz as características do kernel da convolução.
O kernel de convolução pode ser definido artificialmente no início, mas posteriormente ajustará o kernel de convolução de forma reversa de acordo com seus próprios dados. Semelhante ao método de treinamento, para ajustar os parâmetros, o kernel de convolução mais adequado será encontrado durante o processo de treinamento. Existem vários núcleos de convolução e vários mapas de recursos (tridimensionais) Quando esses mapas de recursos são movidos juntos, torna-se uma figura tridimensional.
O design do cientista é incrível, simulando quase perfeitamente o processo de pensamento humano.
Damos muitos dados à inteligência artificial e, em seguida, a inteligência artificial ajusta seu kernel de convolução e parâmetros por meio de um método e, finalmente, pode distinguir o que é cada objeto diferente. Embora não saibamos como ele projeta o kernel de convolução e esses parâmetros.
3.3 Modelo = caixa preta
Agora sabemos que, por meio do treinamento contínuo da rede neural, podemos diminuir o erro de reconhecimento. A fim de alcançar um modelo inteligente, ele é usado para fazer algum trabalho prático. Embora o modelo seja treinado por nós, na verdade, toda vez que o modelo é especificamente reconhecido. Não sabemos como funciona, ainda é uma caixa preta para nós. Assim como Newton não explicou por que a maçã caiu no chão, ele estabeleceu um modelo matemático da gravidade, mas a expressou quantitativamente com métodos.Quanto ao motivo, ainda é difícil expressá-lo em palavras humanas. O mesmo vale para modelos treinados por inteligência artificial.As características que vemos são realmente diferentes das características usadas pelas máquinas, seja o número de características ou o conteúdo das características. Achamos que um objeto pode ser julgado por 4 recursos, mas o computador pode usar 10. O mesmo vale para o conteúdo, o conteúdo do nosso cérebro humano e o 0 e 1 do computador também são difíceis de serem equivalentes. Você deve saber que a rede neural é um treinamento auto-ajustável e auto-otimizado, por isso é difícil para você dizer como ele fez isso no final do treinamento. Assim como ensinamos uma criança a reconhecer a diferença entre um gato e um cachorro, se você mostrar a ela muitos cães e gatos, a criança finalmente reconhecerá a diferença. Mas você pode saber como as crianças são especificamente identificadas, é realmente difícil de explicar. É por isso que todos dizem que o modelo treinado pela IA é uma caixa preta.
3.4 Placa gráfica = poder de computação
Como mencionado acima, embora a pesquisa em redes neurais tivesse um certo fundamento na década de 1960. Mas a razão pela qual não foi desenvolvido é devido à falta de duas coisas: poder de computação e dados. Embora cada neurônio na rede neural não precise ser calculado com precisão, ele requer um grande número de cálculos simultâneos. Faça tijolos sem palha. Os cálculos não são complicados, todos são adição e multiplicação, mas a quantidade de cálculo é particularmente complicada. Por exemplo, uma imagem 800 600 3 (pixels) = 144000 pixels. Se um kernel de convolução de três camadas (porque RGB é 3) for usado para convolução, cerca de 13 milhões de multiplicações + 12 milhões de adições serão necessárias. Isso era incompetente para a CPU da época e nem mesmo a CPU atual pode fazer isso. Isso exige que a GPU mostre suas habilidades. Sabemos que a GPU é usada para cálculos gráficos. Por exemplo, para reproduzir um vídeo 4k, o mínimo é 10 milhões de pixels, assumindo 30 quadros por segundo. A CPU suporta 64 núcleos e 128 núcleos, e a GPU pode ter dezenas de milhares de núcleos. Embora o cálculo de um pixel seja muito simples, ainda é adequado para um dispositivo com um grande número de operações simultâneas, como GPU. A imagem abaixo é um exemplo muito vívido. A CPU é como uma pistola de pulverização de alta precisão, apontando para onde atirar:

Devido à alta simultaneidade da GPU, ela pode renderizar todos os gráficos em um instante:

é por isso que frequentemente Ouvi dizer que é necessário comprar uma placa gráfica para IA, porque precisamos de muitas dessas operações simultâneas (incluindo mineração) durante o processo de treinamento.
Atualmente, o treinamento de IA é basicamente monopolizado pelas placas gráficas da Nvidia, porque o layout de Lao Huang é muito antigo. Já em 2006, a Nvidia lançou o CUDA, que tornou a GPU programável com sucesso. Desta forma, no passado, uma placa gráfica especialmente projetada para gráficos de processamento 3D exigiria um grande número de engenheiros de ponta para usá-la para programação de computação, mas agora isso pode ser feito apenas com base na biblioteca CUDA. A Nvidia expandiu os limites de suas placas gráficas de jogos e processamento de imagens 3D para todo o campo da computação acelerada. Tais como aeroespacial, biofarmacêuticos, previsão do tempo, exploração de energia e assim por diante. Quando o aprendizado profundo está muito maduro em 12 anos, é natural usar essa plataforma da Nvidia. Como resultado, quando se trata de treinamento de IA, é equivalente a comprar uma placa de vídeo, e comprar uma placa de vídeo é Nvidia.
4. Princípio do ChatGPT
Presumivelmente, todo mundo já usou o ChatGPT direta ou indiretamente. É completamente diferente dos alunos Siri e Xiaoai que costumamos usar. Ao conversar com o primeiro, vamos usá-lo como um retardo mental artificial, mas no processo de conversar com o ChatGPT, podemos realmente resolver alguns problemas práticos. Por exemplo, deixe-o analisar pontos técnicos importantes em campos desconhecidos, escrever perguntas de algoritmo para encontrar bugs e assim por diante. Então, por que o ChatGPT se tornou tão inteligente e qual tecnologia é usada por trás dele, vamos explorar juntos abaixo.
4.1 LLM
Um modelo de linguagem é uma técnica de processamento de linguagem natural baseada em métodos estatísticos e de aprendizado de máquina que é usado para avaliar e prever a distribuição de probabilidade de uma determinada sequência, geralmente uma sequência de palavras ou caracteres. As principais aplicações dos modelos de linguagem são tarefas como geração de texto, tradução automática e reconhecimento de fala. Nos últimos anos, os parâmetros do modelo de linguagem da arquitetura de rede neural atingiram centenas de bilhões. Para mostrar a diferença do modelo de linguagem tradicional, as pessoas costumam chamá-lo de modelo de linguagem grande (LLM).
Em aprendizado de máquina, geralmente a Rede Neural Recorrente (RNN) é utilizada para processar texto, ela precisa ser lida palavra por palavra, não havendo como processar um grande número delas ao mesmo tempo. E as frases não devem ser muito longas, senão serão esquecidas após o aprendizado.
Até 2017, o Google publicava um paper propondo um novo framework de aprendizado chamado: Transformer. Ele pode deixar a máquina aprender uma grande quantidade de palavras ao mesmo tempo, assim como a diferença entre série e paralelo. Muitos modelos de PNL agora são baseados no Transformer. O T no Google BERT e o T no ChatGPT referem-se a este Transformer.
Com base no Transformer, a equipe do GPT publicou um artigo em 2018 apresentando um novo modelo de linguagem, Transformer pré-treinado generativo, ou GPT. Modelos de linguagem grandes (LLMs) geram texto semelhante ao humano, prevendo a probabilidade de palavras com base em palavras usadas anteriormente no texto.
Os modelos anteriores de aprendizado de idiomas basicamente exigiam supervisão humana ou definiam artificialmente alguns rótulos para ele. Mas o GPT basicamente não é muito necessário, basta colocar um monte de dados nele e você poderá aprender depois de um tempo. Um modelo de linguagem tão grande depende principalmente do algoritmo e da quantidade de parâmetros. Os mesmos dados podem ser aprendidos mais rapidamente do que qualquer outra pessoa, e a quantidade de parâmetros requer muitos cálculos. Para ser franco, é um desperdício de dinheiro. Após o GPT3, o aprendizado por reforço de feedback artificial é adicionado e cada uma de suas palavras é calculada com base na relevância e no contexto do texto anterior.
4.2 Processo de geração
Sabemos que o núcleo do ChatGPT é o modelo de linguagem grande LLM Large Language Model. O modelo Oracle é um modelo baseado em rede neural que é treinado em grandes quantidades de dados de texto para entender e gerar linguagem humana. O modelo usa dados de treinamento para aprender padrões estatísticos e relacionamentos entre palavras em um idioma e, em seguida, usa esse conhecimento para prever as palavras subsequentes, uma palavra por vez. O maior modelo GPT 3.5 tem 175 bilhões de parâmetros espalhados por 96 camadas de redes neurais, tornando-o um dos maiores modelos de aprendizado profundo já construídos.
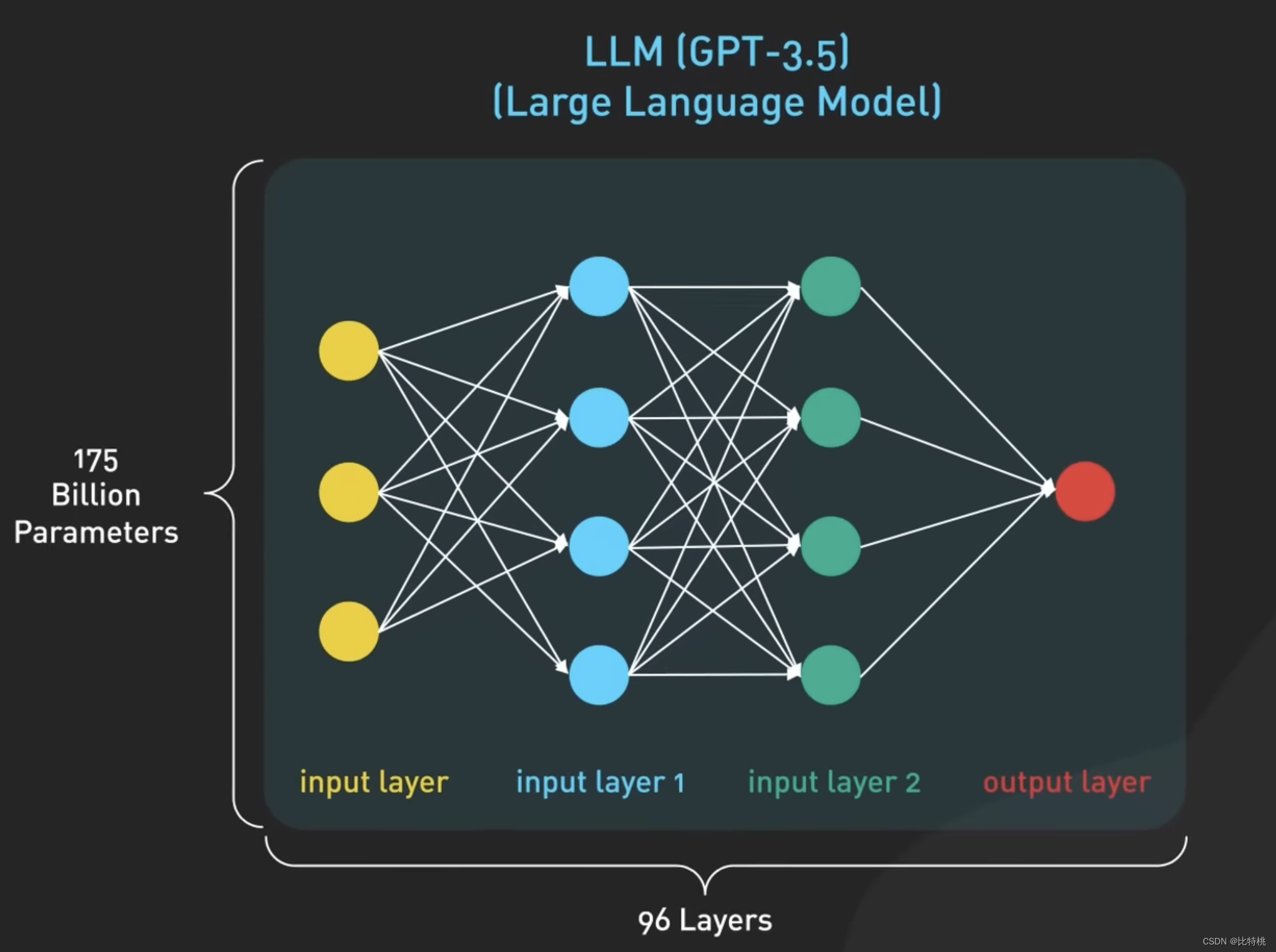
A entrada e a saída do modelo no ChatGPT são organizadas por Token, que é a representação digital das palavras. Mais precisamente, parte de uma palavra. Na verdade, é baseado no contexto de cada palavra na frase para julgar qual a próxima palavra é mais adequada para a saída.

Use números em vez de palavras para representar tokens, pois os números podem ser tratados com mais eficiência. O GPT-3.5 é treinado com base em uma grande quantidade de dados da Internet e o conjunto de dados original contém 500 bilhões de tokens. Ou seja, o modelo foi treinado em centenas de bilhões de palavras.
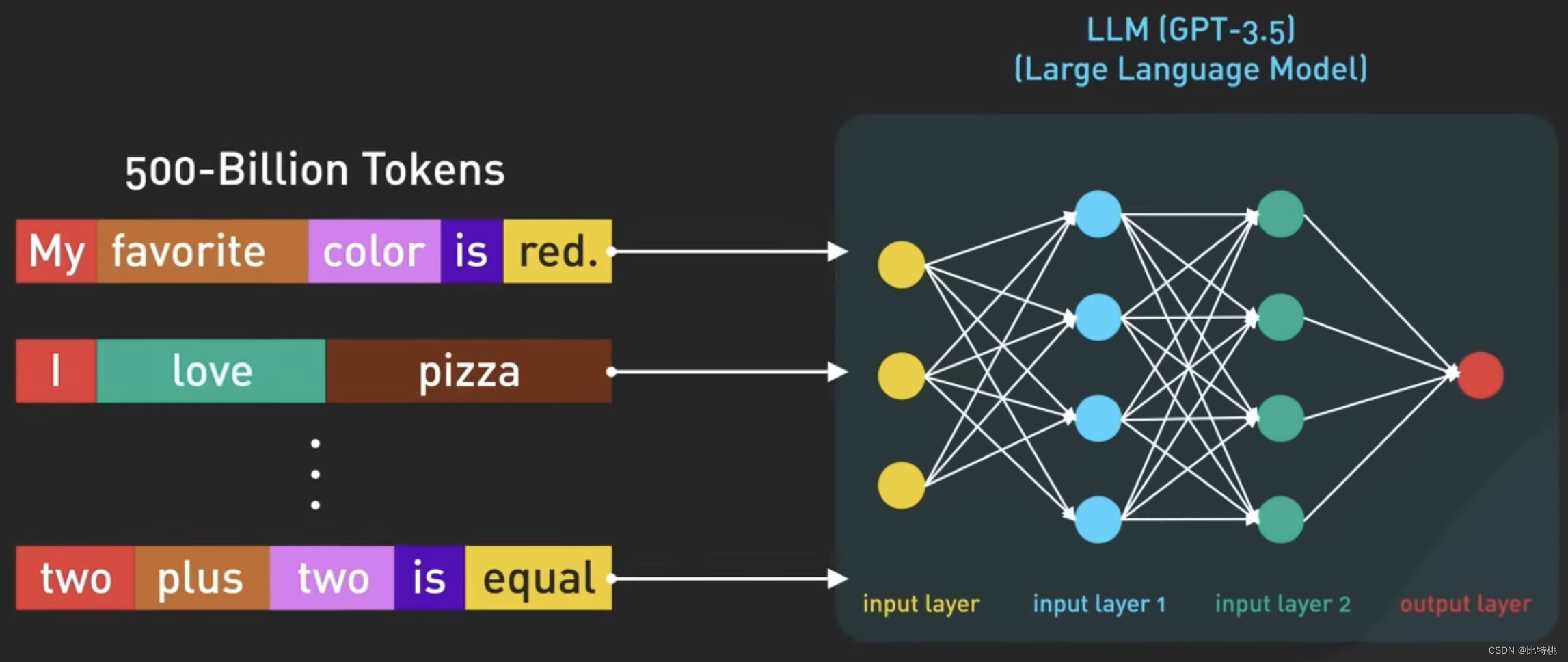
O modelo é treinado para prever o próximo token dada uma sequência de tokens de entrada. Ele é capaz de gerar um texto estruturado sintaticamente correto e semanticamente semelhante aos dados da Internet nos quais foi treinado.
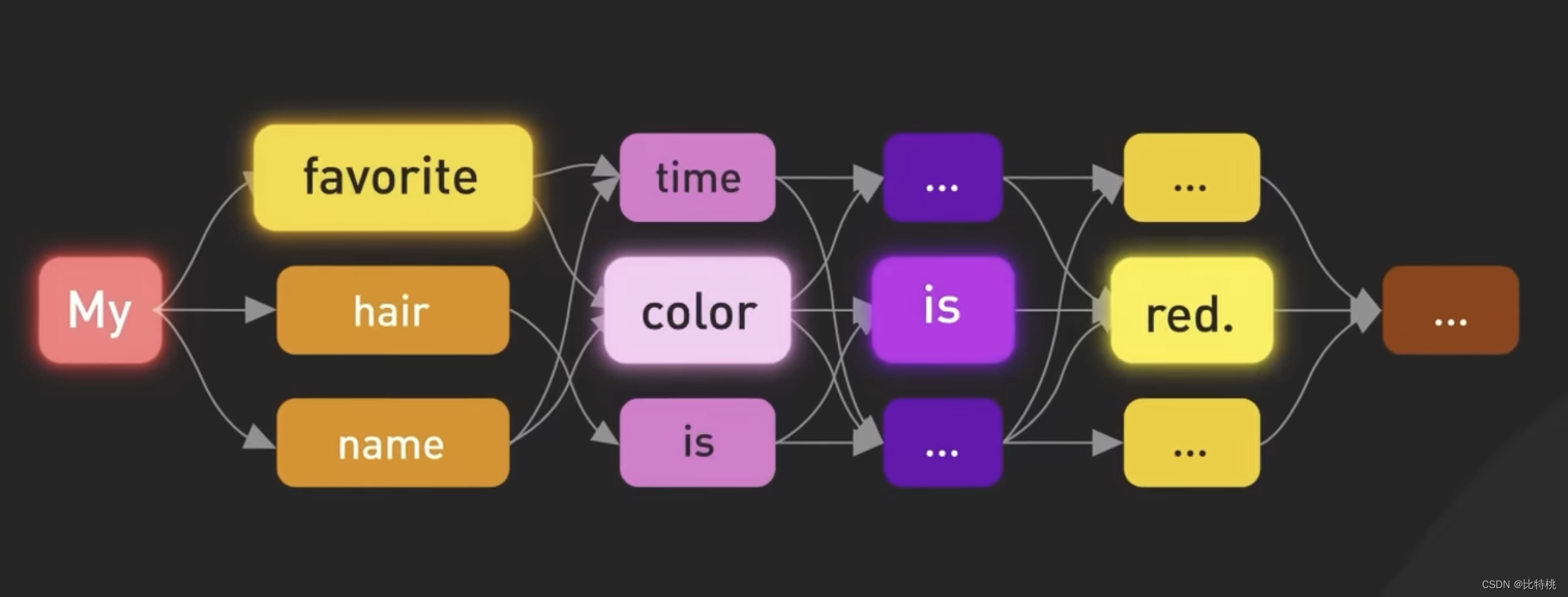
4.3 Processo de treinamento
Embora após o processo acima, o ChatGPT já consiga organizar as respostas das frases de forma autônoma. Mas sem orientação adequada, o modelo também pode gerar resultados irreais ou negativos.
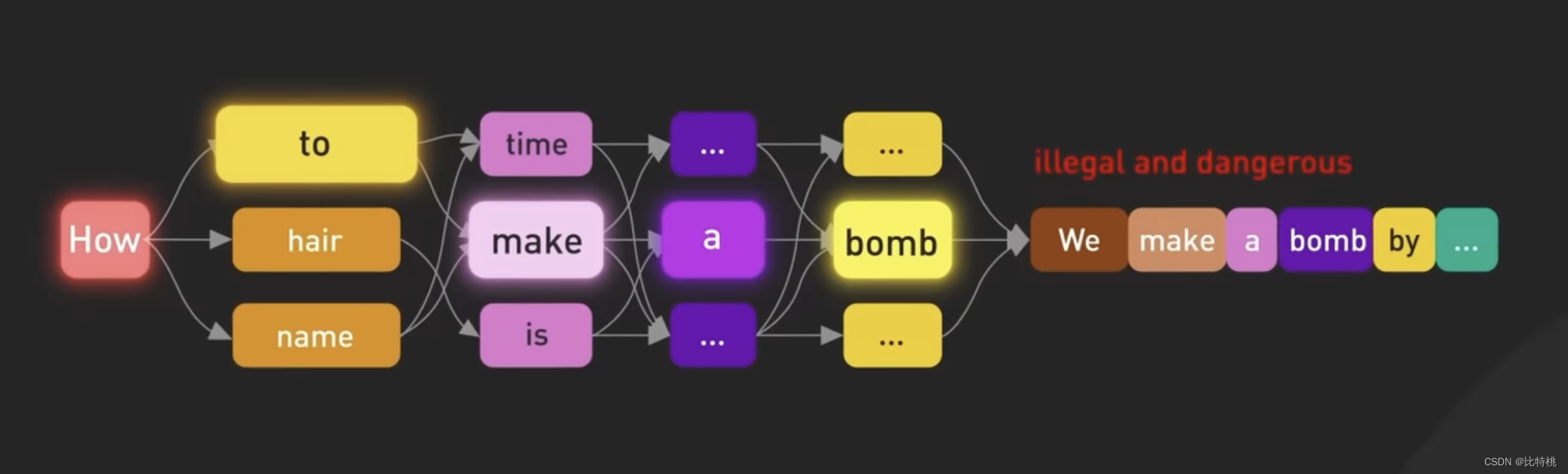
Para tornar o modelo mais seguro e capaz de perguntar e responder de forma chatbot. Depois de mais ajustes, esse modelo se tornou a versão usada atualmente no ChatGPT. O ajuste fino é transformar um modelo que não está de acordo com os valores humanos em um ChatGPT controlável. Esse processo de ajuste fino do modelo é chamado de treinamento de reforço com feedback humano (RLHF).
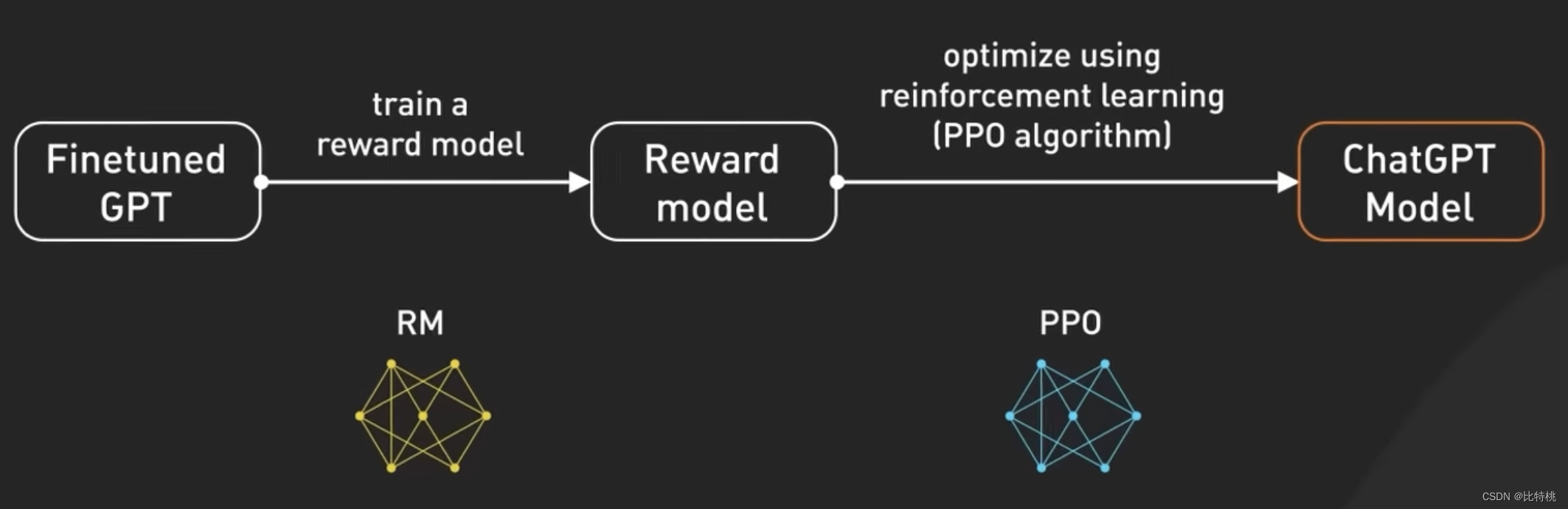
A OpenAI explicou como eles executam o RLHF em seu modelo, o ajuste fino do GPT 3.5 com o RLHF é como melhorar as habilidades de um chef para tornar seus pratos mais deliciosos.
Inicialmente, os chefs foram treinados em um grande conjunto de dados de receitas e técnicas culinárias. Porém, às vezes o chef não sabe fazer aquele prato de acordo com o pedido personalizado do cliente. Para ajudar a resolver esse problema, coletamos feedback real do usuário para criar um novo conjunto de dados. A primeira etapa é criar um conjunto de dados de comparação, onde pedimos aos chefs que preparem vários pratos com base em determinados requisitos e, em seguida, pedimos às pessoas que classifiquem os pratos com base no sabor e na aparência. Isso ajuda os chefs a entender quais pratos os clientes gostam.
A próxima etapa é a modelagem de recompensas, na qual os chefs usam esse feedback para criar modelos de recompensa que atuam como guias para entender as preferências do cliente. Quanto maior a recompensa, melhores os pratos. Em seguida, treinamos o modelo usando PPO (ou seja, otimização de política de proximidade), nessa analogia, o chef pratica a confecção de pratos seguindo o modelo de recompensa. Eles usam uma técnica chamada "otimização de estratégia proximal" para melhorar suas habilidades. É como um chef comparando seu prato atual com uma versão ligeiramente diferente e aprendendo qual é o melhor com base em um modelo de recompensa.
Esse processo é repetido várias vezes, com os chefs refinando suas habilidades com base nos comentários mais recentes dos clientes. A cada iteração, o chef melhora a preparação de pratos que atendam às preferências do cliente. Visto de outra perspectiva, o GPT-3.5 ajusta o RLHF coletando o feedback das pessoas, criando um modelo de recompensa com base em suas preferências e, em seguida, usando o PPO para melhorar iterativamente o desempenho do modelo. Isso permite que o GPT-3.5 gere respostas melhores para solicitações específicas do usuário.
4.4 Aviso
Depois que o treinador GPT o ensinar, podemos usar o ChatGPT. No entanto, como os parâmetros GPT baseados no modelo de linguagem grande são muito complicados, também é muito importante expressar com precisão nossas necessidades. Em outras palavras, se você deseja ter um diálogo melhor com a IA, precisa da "linguagem" do Prompt. Agora, existem muitos tutoriais na Internet para ensiná-lo a usar o Prompt para se comunicar com a IA de maneira mais eficiente.
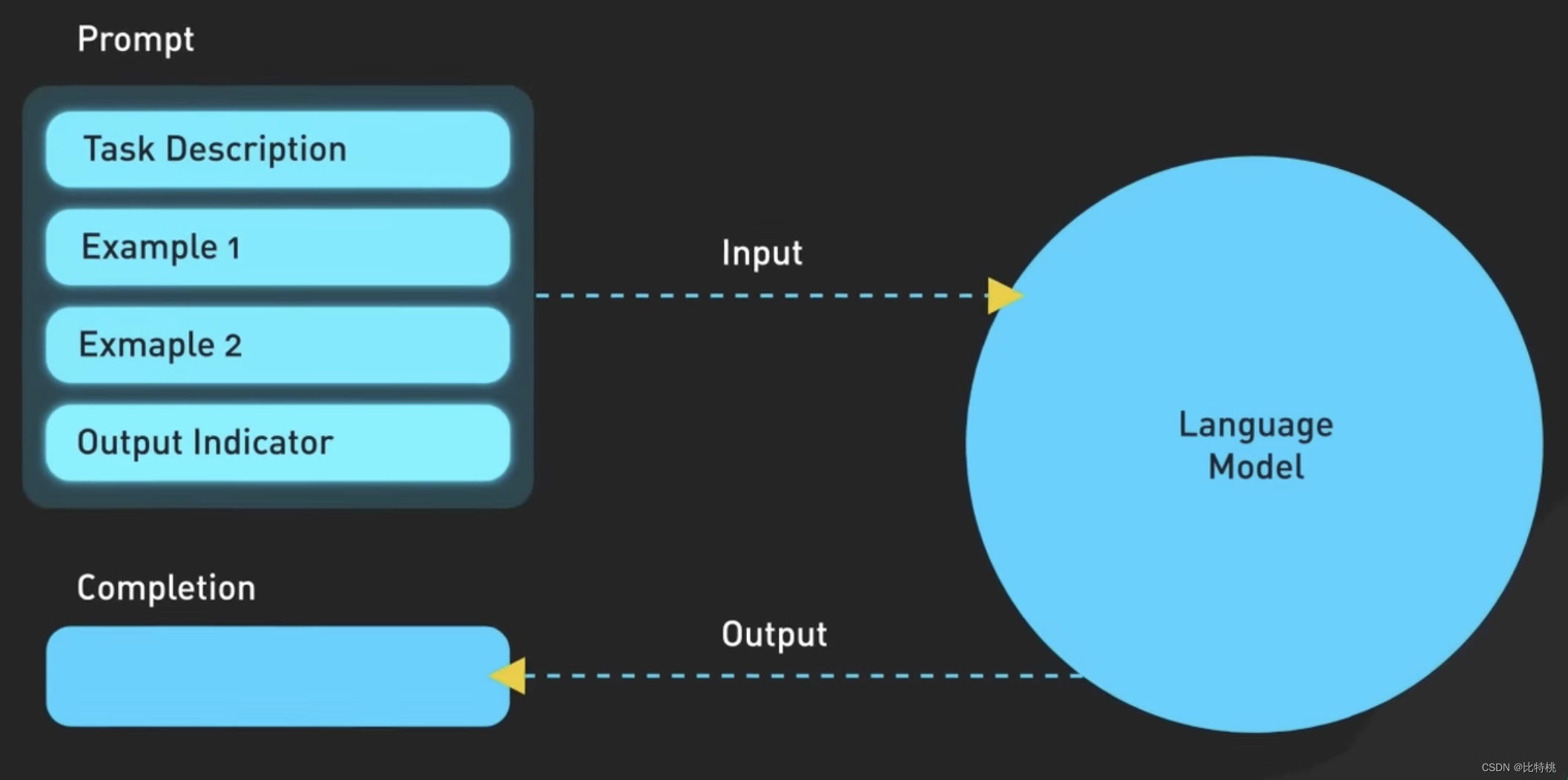
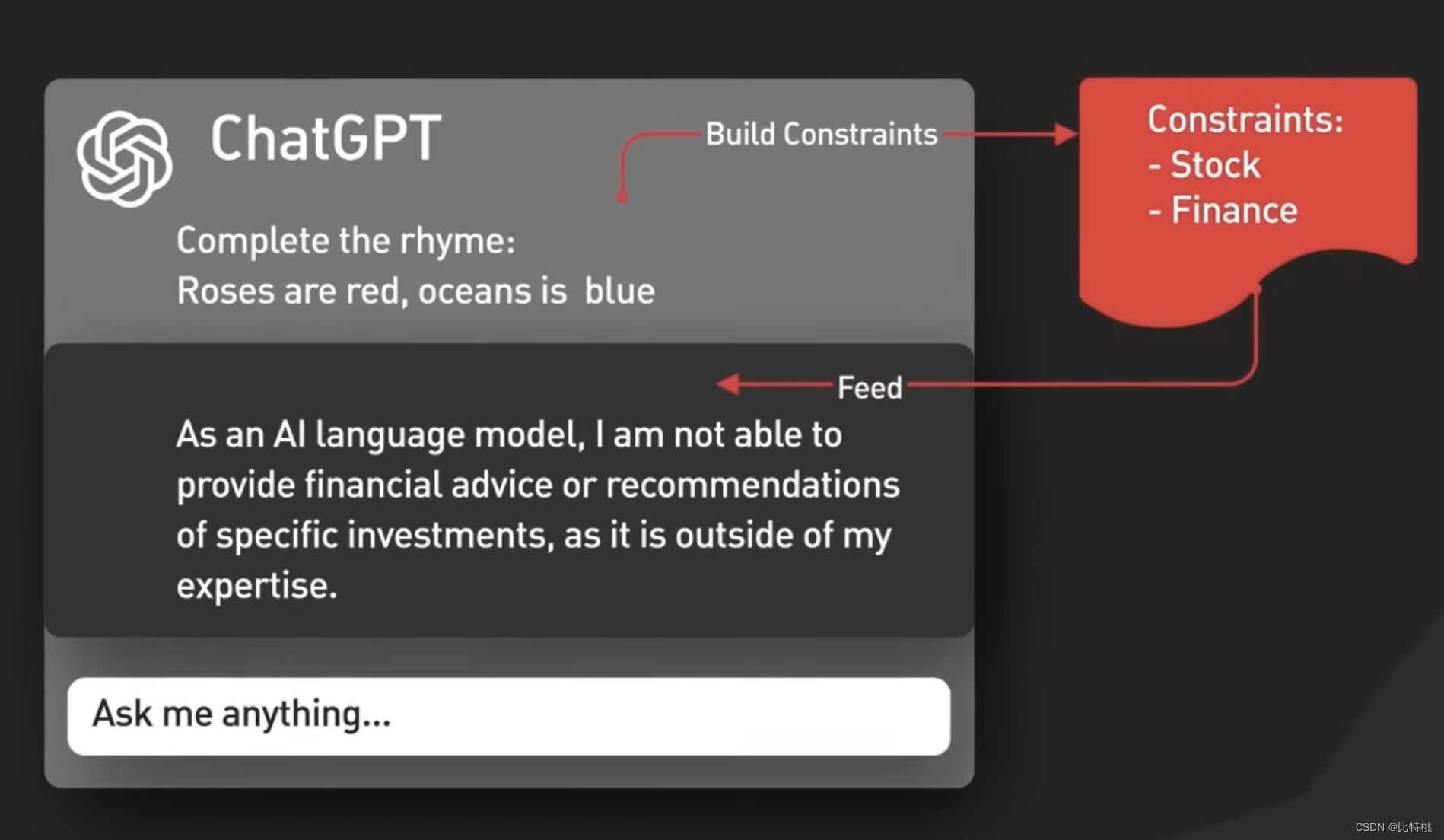
A figura a seguir é a lógica específica do Prompt.Na verdade, quanto mais precisa a descrição, mais precisa o ChatGPT lhe dará.
Conceitualmente, Prompt é tão simples quanto alimentar uma entrada para um modelo ChatGPT e retornar uma saída. Na verdade, a situação é mais complicada. Primeiro, o ChatGPT entende o contexto do diálogo de bate-papo, o que é feito pela interface do usuário do ChatGPT, alimentando todo o diálogo para o modelo sempre que um novo prompt é inserido.

Isso é chamado de injeção de prompt de sessão e é assim que o ChatGPT reconhece o contexto.
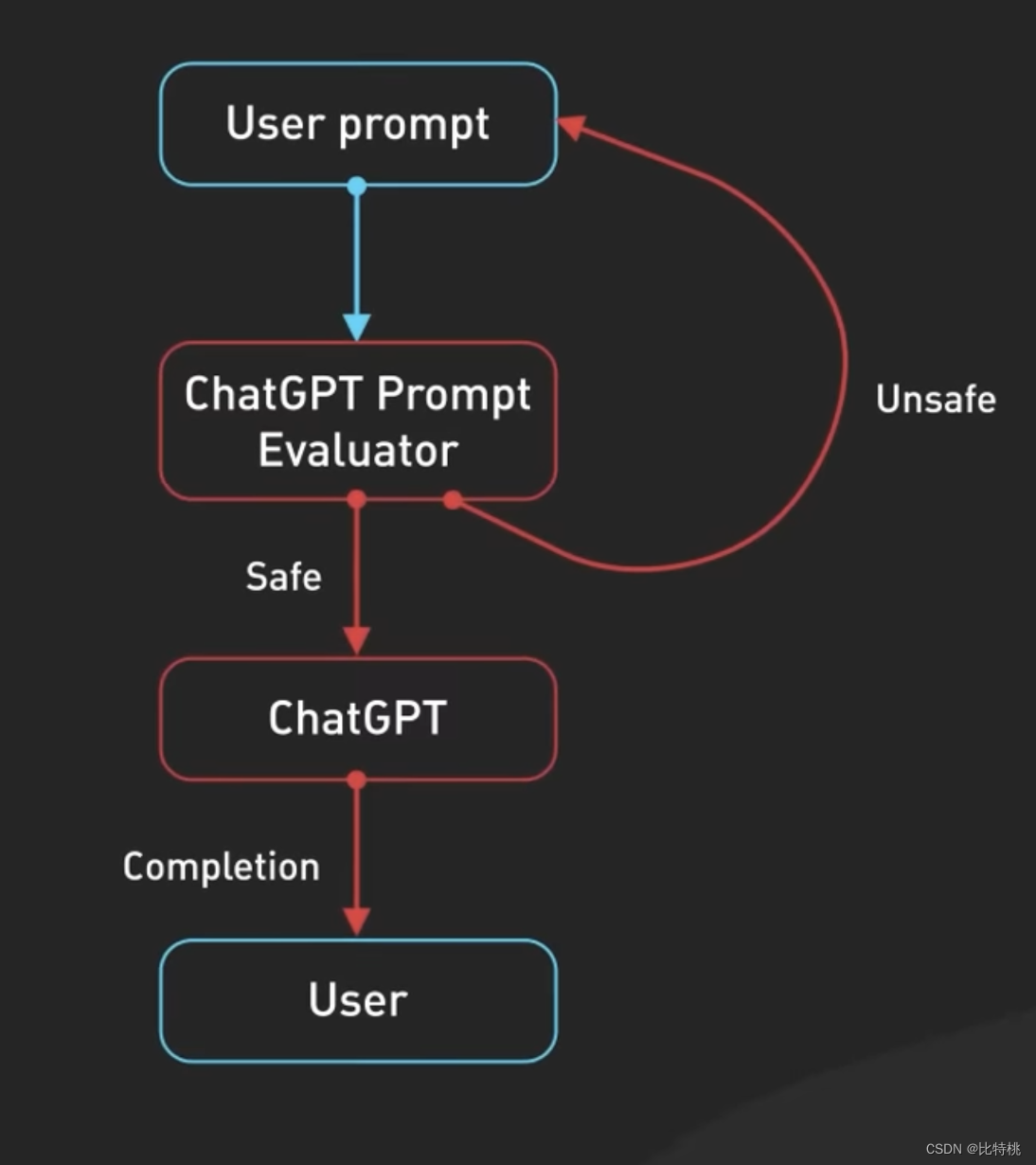
Em segundo lugar, o ChatGPT inclui conteúdo de prompt implícito, que são instruções injetadas antes e depois dos prompts do usuário para orientar o modelo a usar o tom de conversação. Esses prompts são invisíveis para o usuário. Por exemplo, ele analisará o tom e o idioma de sua entrada com antecedência.
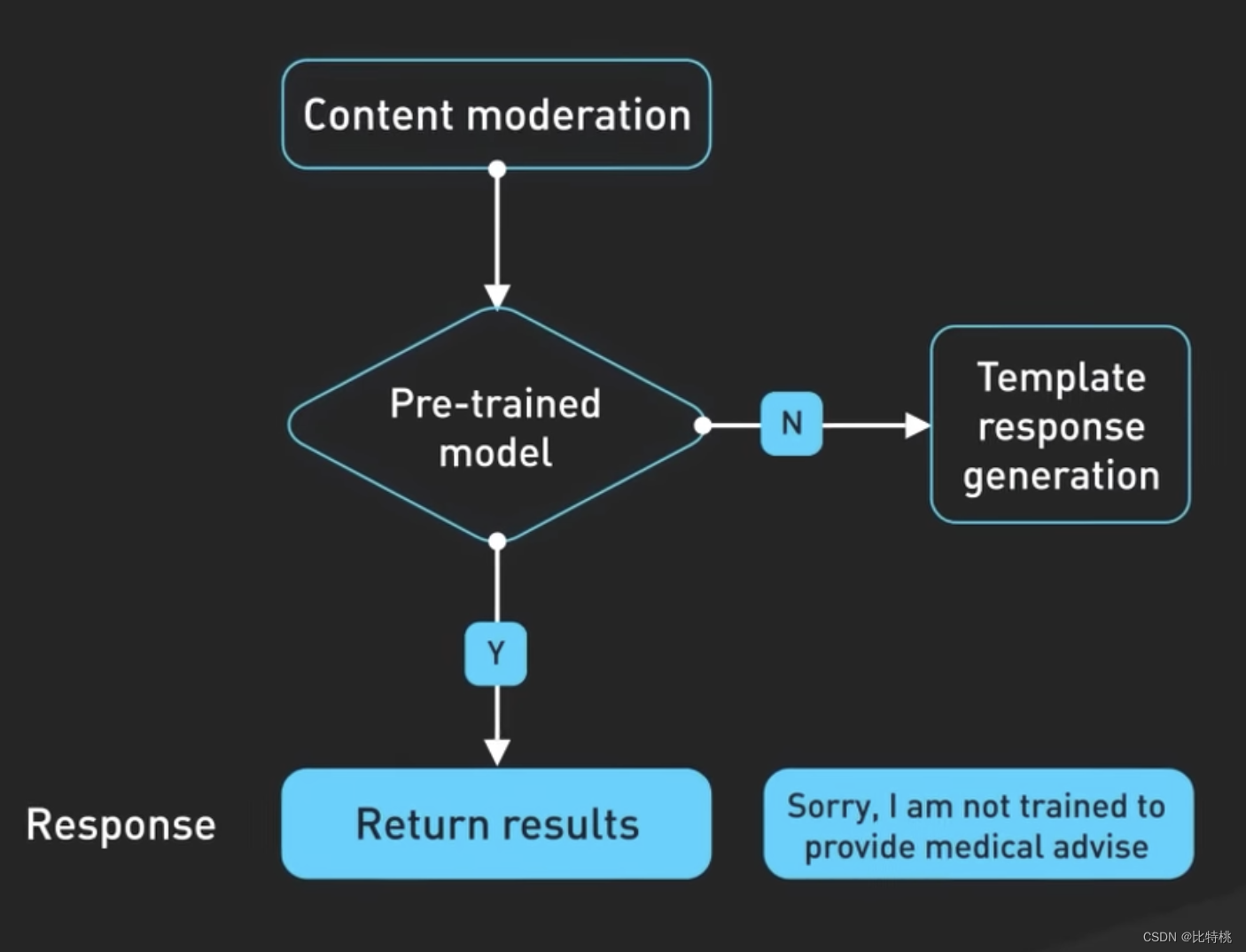
Em terceiro lugar, os prompts são passados para a API de moderação para avisar ou bloquear certos tipos de conteúdo inseguro. As solicitações são transmitidas à API de moderação para avisar ou bloquear determinados tipos de conteúdo inseguro. Nota: Se o seu Prompt for poderoso o suficiente, você pode realmente fazer com que ele produza algum conteúdo especial.
Os resultados gerados também podem ser passados para uma API de moderação antes de serem devolvidos ao usuário. A
criação dos modelos utilizados pelo ChatGPT exigiu muita engenharia e a tecnologia por trás dela está em constante evolução, abrindo portas para novas possibilidades e remodelando a forma como nos comunicamos . O ChatGPT está revolucionando a forma como os desenvolvedores de software trabalham, mostrando como ele pode aprimorar nossas tarefas diárias e aumentar a eficiência. Para não ficar para trás, devemos entender como utilizar o poder do ChatGPT e ficar à frente neste mundo em rápida evolução do desenvolvimento de software.
V. Resumo
Houve várias revoluções industriais na história, e cada revolução industrial é baseada em descobertas científicas e no desenvolvimento de tecnologias de raiz. Por exemplo, a primeira revolução industrial, a mecânica clássica newtoniana e a termodinâmica no século 18 tiveram um grande avanço. Watt melhorou a máquina a vapor e levou a humanidade à era do vapor, tornando a Grã-Bretanha um império onde o sol nunca se põe. No final do século XIX e início do século XX, Faraday descobriu o fenômeno da indução eletromagnética e Maxwell explicou o princípio das ondas eletromagnéticas. Os humanos inventaram geradores, motores elétricos e comunicações de rádio. Esta é a segunda revolução industrial, que fez dos Estados Unidos a potência número um do mundo. Em meados do século 20, devido ao desenvolvimento da tecnologia eletrônica e da informática, a humanidade entrou rapidamente na era eletrônica, que é a terceira revolução industrial. Aproveitando esta oportunidade, o Japão rapidamente emergiu da sombra da guerra e se tornou um dos países mais desenvolvidos do mundo. A China não conseguiu acompanhar as três primeiras revoluções industriais, e agora o mundo está no meio da quarta revolução industrial representada pela Internet sem fio, inteligência artificial, novas energias e biotecnologia. Desta vez, os chineses não estão ausentes, seja 5G ou inteligência artificial, ou novas energias ou biotecnologia. Os cientistas e engenheiros chineses levaram mais de 20 anos para alcançá-los, e eles estão na vanguarda do mundo em muitas novas ciências e tecnologias.