Zu Beginn des Jahres 2020 begannen wir mit der Migration der Big-Data-Offline-Computing-Plattform von NetEase Interactive Entertainment ins Ausland, da das Auslandsgeschäft von NetEase Interactive Entertainment wuchs und die Datenkonformität im Ausland erforderlich war. In der Anfangsphase haben wir die Lösung aus Cloud-Host-Bare-Metal und leistungsstarkem EBS-Blockspeicher übernommen. Allerdings sind die Speicherkosten dieser Lösung hoch und die Kosten sind um ein Vielfaches höher als bei selbstgebauten Computerräumen im Haushalt.
Aus diesem Grund haben wir uns entschieden, eine Plattform in der öffentlichen Cloud aufzubauen. Diese Plattform muss nicht nur besser für aktuelle Geschäftsszenarien geeignet und besser mit historischen Geschäften kompatibel sein, sondern auch wirtschaftlicher als die EMR-Hosting-Lösung in der öffentlichen Cloud. Wir haben die Kostenoptimierung hauptsächlich unter drei Aspekten durchgeführt: Speicher, Computer und datenschichtiges Lebenszyklusmanagement. Der spezifische Optimierungsplan wird im Folgenden ausführlich vorgestellt.
Letztendlich stellte dieses Projekt vollständige Hadoop-Kompatibilität für die nachgelagerten Datengeschäfts- und Analyseabteilungen bereit und vermeidete den Umsturz und die Neuerfindung der gesamten Geschäftslogik; es sparte dem Spieldatengeschäft, das ins Ausland verlagerte, eine Menge Kosten ein, die Speicherkosten betrugen zuvor 50 % Optimierung und die Gesamtrechenleistung Die Kosten betragen 40 % der Kosten vor der Optimierung, und die Kosten für kalte Daten betragen 33 % der Online-Speicherkosten nach der Optimierung. Mit zunehmendem Geschäftsvolumen werden sich die Kosteneinsparungen in Zukunft um das Zehnfache verringern, was den datenbasierten Betrieb nach einem Auslandsaufenthalt stark unterstützen wird.
01. Design von Cloud-Lösungen für Big-Data-Plattformen im Ausland
Im Jahr 2020 begaben wir uns auf eine dringende Mission zur See. In China wurde unser Geschäft in Form von selbst aufgebauten Clustern aufgebaut und betrieben. Um im Ausland schnell online gehen zu können, haben wir dringend eine Lösung eingeführt, die genau dem inländischen Cluster entspricht und eine Reihe integrierter Speicher- und Computersysteme verwendet, die aus physischen Knoten bestehen. Wir haben uns für den Bare-Metal-Server M5.metal entschieden und EBS gp3 als Speicher verwendet.

Der Nachteil dieser Lösung besteht darin, dass die Kosten sehr hoch sind, ihr Vorteil besteht jedoch darin, dass sie ein sehr schmerzhaftes Problem löst, nämlich dass wir mit allen historischen Unternehmen kompatibel sein müssen und sicherstellen müssen, dass alle historischen Unternehmen schnell und sofort im Ausland tätig werden können. Unsere vor- und nachgelagerten Geschäftsbereiche können nahtlos ins Ausland verlagert werden und unterstützen die Planung von nahezu 300.000 Aufträgen pro Tag.
Allerdings waren die Kosten schon immer ein Problem, das nicht ignoriert werden darf. Daher müssen wir die Lösung neu auswählen, um eine Lösung mit besserer Leistung und geringeren Kosten zu erhalten und die Kompatibilität sicherzustellen. Je nach Geschäftsanforderungen und Merkmalen von Big-Data-Szenarien bewerten wir, wie Lösungen aus den folgenden Richtungen ausgewählt werden können:
- Tauschen Sie Zeit/Raum gegen Leistung;
- Bereitstellungsoptimierung basierend auf Geschäftsszenarien;
- Fügen Sie Middleware hinzu, um eine Kompatibilitätsintegration zu erreichen.
- Nutzen Sie die Eigenschaften von Cloud-Ressourcen voll aus, um die Kosten zu optimieren.
Hadoop in der Cloud
Im Allgemeinen gibt es zwei Lösungen für die Cloud-Migration von Hadoop: EMR+EMRFS und Dataproc+GCS. Diese beiden Optionen sind eine normale Haltung für Ausflüge aufs Meer. Oder verwenden Sie einige Cloud-native Plattformen wie BigQuery, Snowflake, Redshift usw. als Datenabfragelösungen, wir haben diese Lösungen jedoch nicht verwendet.
Warum EMR nicht verwendet wird
Da alle unsere Unternehmen stark auf Hadoop angewiesen sind, handelt es sich bei der derzeit von uns verwendeten Hadoop-Version um eine interne Version, die an die Geschäftsanforderungen angepasst ist und Abwärtskompatibilität mit verschiedenen neuen Versionsfunktionen erreicht hat. Kann abgedeckt werden. Bei Lösungen wie dem Cloud-nativen BigQuery handelt es sich um eine Richtung mit größeren Veränderungen, die für das Unternehmen weiter entfernt ist.
Warum nicht direkt S3-Speicher nutzen?
-
Aufgrund der hohen Anforderungen an die Sicherheit von Datengeschäften verfügen wir über ein komplexes Geschäftsberechtigungsdesign, das die Obergrenze, die Amazon IAM (Identity and Access Management) ROLE erreichen kann, bei weitem überschreitet.
-
Die Leistung von S3 ist begrenzt und es sind Optimierungsmaßnahmen wie Bucketing und zufällige Verzeichnisse erforderlich, die für die geschäftliche Nutzung undurchsichtig sind. Die Anpassung von Verzeichnispräfixen zur Anpassung an S3-Partitionen oder die Verwendung von mehr Buckets erfordert geschäftliche Anpassungen an bestehenden Nutzungsmethoden, die nicht angepasst werden können Unser aktuelles Katalogdesign. Darüber hinaus sind direkte Vorgänge wie list und du in S3-Verzeichnissen als durch Objektspeicher implementiertes Dateisystem bei sehr großen Dateidaten grundsätzlich nicht verfügbar, in großen Datenszenarien handelt es sich jedoch zufällig um eine große Anzahl von Vorgängen.
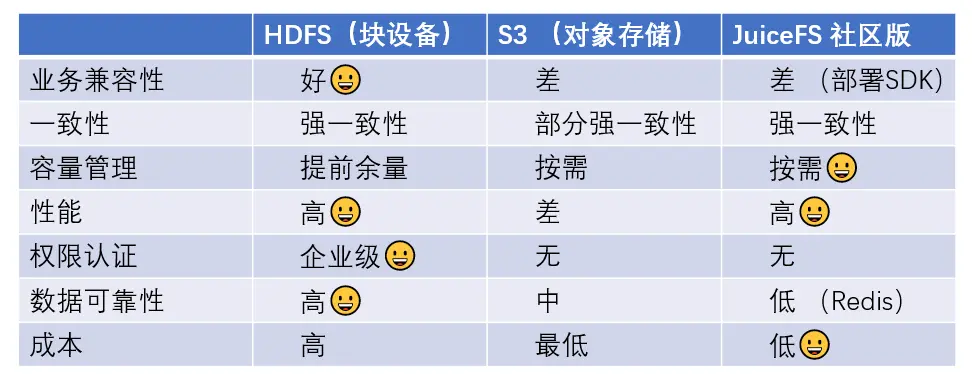
Speicherauswahl: HDFS vs. Objektspeicher vs. JuiceFS
Wir bewerten Speicherkomponenten hauptsächlich aus den folgenden Dimensionen.
Geschäftskompatibilität : Kompatibilität ist ein sehr wichtiger Aspekt in unserer Situation, in der wir ein großes Lagerbestandsgeschäft haben und ins Ausland gehen müssen. Zweitens beziehen sich Kostensenkung und Effizienzsteigerung nicht nur auf die Reduzierung der Lagerkosten, sondern umfassen auch Überlegungen zu Ressourcenkosten und Arbeitskosten. In Bezug auf die Kompatibilität ist die JuiceFS Community Edition mit dem Hadoop-Ökosystem kompatibel, muss jedoch das JuiceFS Hadoop SDK auf der Clientseite bereitstellen.
Konsistenz : Damals haben wir Untersuchungen zu S3 durchgeführt, aber vor dem ersten Quartal 2020 wurde keine starke Konsistenz erreicht, und derzeit können nicht alle Plattformen eine starke Konsistenz erreichen.
Kapazitätsmanagement : Für unsere aktuellen selbstgebauten Cluster ist die Notwendigkeit, Ressourcen zu reservieren, ein wichtiges Thema. Mit anderen Worten: Es ist uns unmöglich, 100 % der Ressourcen zu nutzen, daher ist die On-Demand-Nutzung eine sehr kostengünstige Richtung.
Leistung : Basierend auf HDFS kann es das Leistungsniveau unseres inländischen selbstgebauten HDFS erreichen. Das SLA, das wir dem Unternehmen in China anbieten, besteht darin, die RPC-Leistung von p90 innerhalb von 10 Millisekunden unter der Bedingung von 40.000 QPS in einem einzelnen Cluster zu erreichen. Aber für so etwas wie S3 ist es sehr schwierig, eine solche Leistung zu erreichen.
Autoritätsauthentifizierung : In selbst erstellten Clustern werden Kerberos und Ranger zur Authentifizierung und Autoritätsverwaltung verwendet. Aber S3 unterstützte es damals nicht. JuiceFS Community Edition wird ebenfalls nicht unterstützt.
Datenzuverlässigkeit : HDFS verwendet drei Replikate, um die Datenzuverlässigkeit sicherzustellen. Zu diesem Zeitpunkt verwendete die JuiceFS-Metadaten-Engine bei unseren Tests Redis. Wir haben festgestellt, dass im Hochverfügbarkeitsmodus der Speicher einfriert, wenn der Masterknoten wechselt, was für uns sehr schwer zu akzeptieren ist. Daher übernehmen wir die Methode, den Redis-Metadatendienst unabhängig auf jedem Computer bereitzustellen, und die Details werden weiter unten erläutert.
Kosten : Lösungen wie Blockgeräte sind teuer. Unser Ziel ist die Nutzung von S3. Wenn jeder nur S3 nutzt, sind die Kosten natürlich am niedrigsten. Wenn Sie JuiceFS verwenden, fallen für die letztgenannte Architektur gewisse zusätzliche Kosten an, weshalb wir später erklären, warum ihre Kosten nicht die niedrigsten sind.
02. Hadoop-Multi-Cloud-Migrationsplan für Übersee
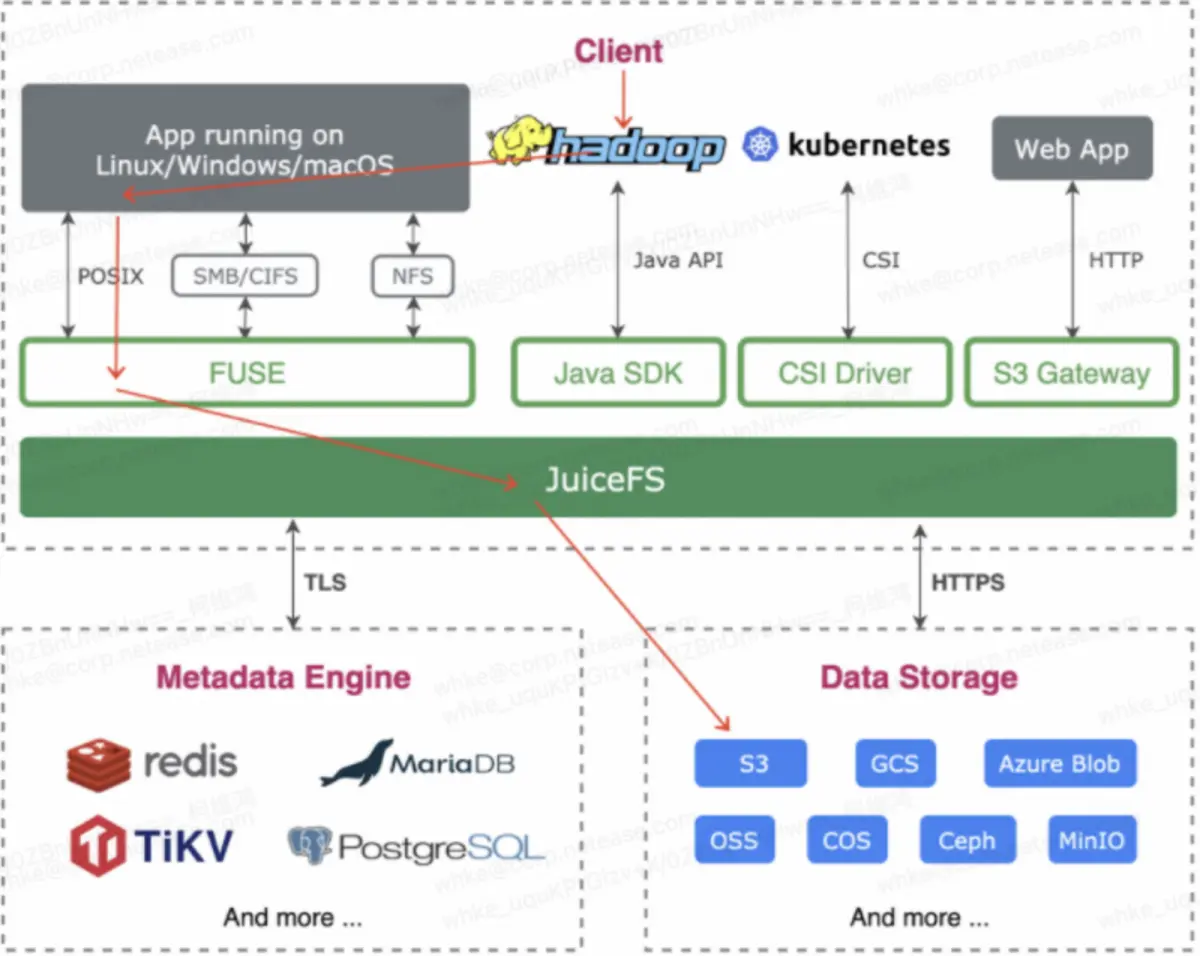
Trennung von Speicher und Computing auf der Speicherebene: Hadoop+JuiceFS+S3
Die Kombination von JuiceFS und Hadoop kann die Kosten für die Geschäftskompatibilität senken und das bestehende Geschäft im Ausland schnell realisieren. Wenn viele Benutzer die JuiceFS-Lösung verwenden, implementieren sie diese über das SDK plus die Open-Source-Version von Hadoop. Auf diese Weise entsteht jedoch ein Problem mit der Autoritätsauthentifizierung. JuiceFS Community Edition unterstützt die Autoritätsauthentifizierung von Ranger und Kerberos nicht. Daher nutzen wir weiterhin das gesamte Framework von Hadoop. Die Wartungskosten scheinen hoch zu sein, aber in China haben wir eine Reihe selbstgebauter Komponenten, die gewartet werden, sodass für uns fast keine Kosten anfallen. Wie in der folgenden Abbildung gezeigt, verwenden wir Fuse, um JuiceFS in Hadoop zu mounten, und verwenden dann S3 für die Speicherung.
Vergleichen wir kurz die Leistung unseres selbst erstellten Einzelclusters auf Basis von EBS.
- Bei 40.000 QPS kann p90 10 ms erreichen;
- Ein einzelner Knoten kann 30.000 IOPS aushalten.
Als wir zum ersten Mal in die Cloud gingen, verwendeten wir den HDD-Modus, genauer gesagt den Speichertyp st1. Doch bald stellten wir fest, dass bei einer geringen Anzahl von Knoten die tatsächlichen IOPS bei weitem nicht unseren Anforderungen entsprechen. Aus diesem Grund haben wir uns entschieden, alle ST1-Speichertypen auf GP3 zu aktualisieren.
Jeder GP3 bietet standardmäßig etwa 3000 IOPS. Um die Leistung zu verbessern, haben wir 10 GP3-Speichervolumes bereitgestellt und so eine Gesamtleistung von 30.000 IOPS erreicht. Durch diese Verbesserung kann unser System die IOPS-Anforderungen besser erfüllen und ist nicht mehr durch Leistungsengpässe eingeschränkt, wenn die Anzahl der Knoten gering ist. Die hohe Leistung und Flexibilität von gp3 machten es zur idealen Wahl für unser IOPS-Problem.
Die aktuelle Standardbandbreite pro Knoten beträgt 10 GB. Aber auch die Bandbreite verschiedener Modelle ist unterschiedlich. Wir haben einen Benchmark mit 30.000 IOPS für einen einzelnen Knoten mit 10 GB Bandbreite durchgeführt. Unser Ziel ist es, unseren S3-Speicher integrieren zu können, das heißt, die Speicherkosten zu berücksichtigen und gleichzeitig eine hohe Leistung aufrechtzuerhalten, und die Daten werden schließlich auf S3 fallen.
Das Wichtigste ist die Kompatibilität mit dem Hadoop-Zugriff, das heißt, alle Unternehmen müssen keine Änderungen vornehmen und können direkt in die Cloud gehen, um Kompatibilitätsprobleme zu lösen. Für einige historische Unternehmen kann dies einen gewissen geschäftlichen Wert haben, wir müssen jedoch die Kosten für die Geschäftstransformation und die Plattformkompatibilität bewerten. In unserem Geschäftsszenario sind die Arbeitskosten für die Rekonstruktion aller historischen Unternehmen derzeit höher als die Kosten für die Plattformkompatibilität Unmöglich, in kurzer Zeit fertig zu werden.
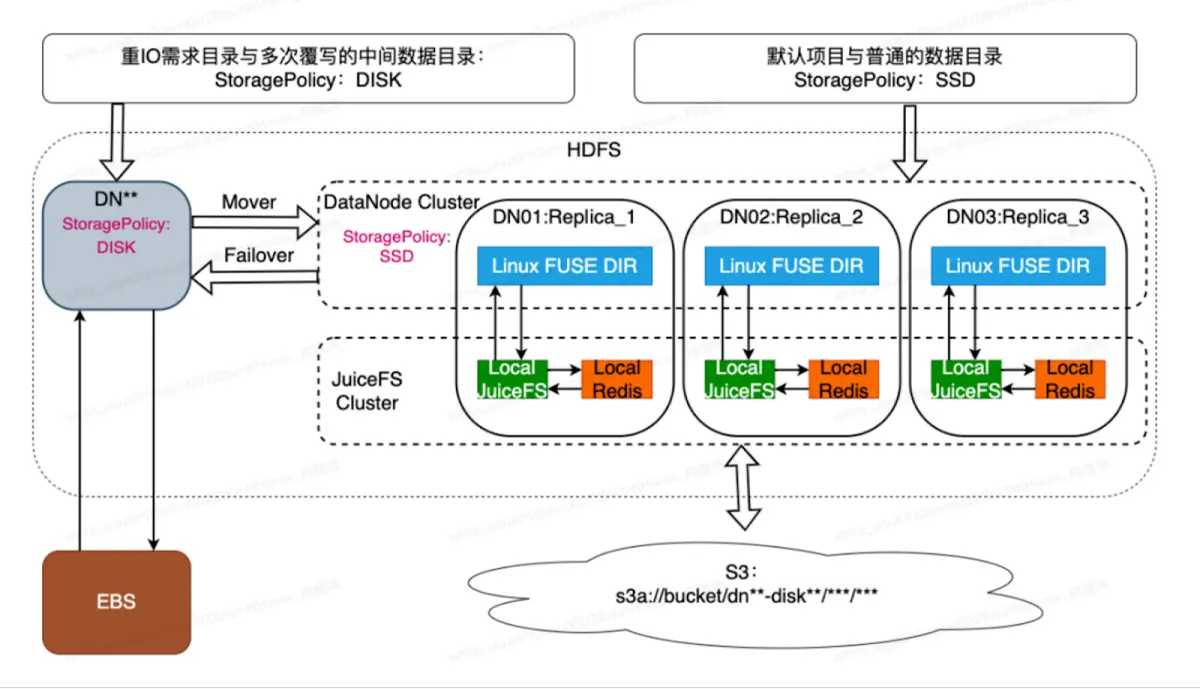
Die Art und Weise, wie wir JuiceFS bereitstellen, unterscheidet sich möglicherweise von der offiziellen Website. Wir haben JuiceFS und Redis lokal auf jeder Maschine bereitgestellt (wie im Bild unten gezeigt). Dies geschieht, um die Leistung von JuiceFS zu maximieren und den Verlust lokaler Metadaten zu minimieren. Wir haben versucht, Redis-Cluster und TiDB-Cluster zu verwenden, haben jedoch festgestellt, dass die Metadatenleistung um mehrere Größenordnungen schlechter ist. Daher haben wir uns von Anfang an für die lokale Bereitstellungsmethode entschieden.

Ein weiterer Vorteil besteht darin, dass unser System an DNO (Data Node Object) gebunden ist. Wir können die Anzahl der Dateien für jeden DNO, also die Anzahl der Dateien für einen einzelnen Knoten, steuern, sodass sie auf einem angemessenen Niveau stabilisiert werden kann. Beispielsweise hat unser DNO eine Obergrenze von etwa 3 bis 8 Millionen Metadatendateien, sodass ein einzelner Metadatenknoten etwa 20 GB groß ist. Auf diese Weise müssen wir seiner Erweiterung nicht zu viel Aufmerksamkeit schenken und eine groß angelegte verteilte Redis-Anforderung in eine Redis-Anforderung mit kontrollierbaren Metadaten auf einem einzelnen Knoten umwandeln. Aber auch die Stabilität stellt ein Problem dar. Wenn ein einzelner Knoten ein Stabilitätsproblem hat, besteht das Risiko eines Verlusts.
Um das Ausfallzeitproblem eines einzelnen Knotens zu lösen, haben wir eine Verbindung mit DNO hergestellt und den HDFS-Mehrfachkopiermechanismus verwendet. In unserem Cluster gibt es zwei Kopiermodi: einen dreifachen Kopiermodus und einen EC-Kopie (Erasure Coding). In verschiedenen Modi wird eine hohe Datenzuverlässigkeit durch den Replikationsmechanismus erreicht: Beim Multi-Copy-Bereitstellungsschema können wir einen Knoten auch dann direkt entfernen, wenn er vollständig ausfällt, ohne den Gesamtbetrieb und die Datenzuverlässigkeit zu beeinträchtigen.
In der Praxis ist die lokale Bereitstellung eines einzelnen Knotens unter Verwendung von JuiceFS und Redis mit einem einzelnen Knoten der Weg, um die beste Leistung zu erzielen. Weil wir die Leistung von HDFS- und EBS-Lösungen vergleichen müssen.
Wir haben leistungsstarkes HDFS durch HDFS-basierte verteilte horizontale Erweiterung und JuiceFS-Cache- und Lese-/Schreibstrategieoptimierung erreicht. Der Optimierungsteil ist wie folgt:
- Verwenden Sie JuiceFS, um das GP3-Verzeichnis zu ersetzen, und verwenden Sie einen kleinen GP3-Speicher als JuiceFS-Cache-Verzeichnis, um die mit GP3 übereinstimmende IOPS-Ebene zu erreichen.
- Durch Optimierung des JuiceFS-Cache-Mechanismus, benutzerdefiniertes asynchrones Löschen, asynchrones Zusammenführungs-Upload, S3-Verzeichnis-TPS-Voreinstellung und andere Optimierungen, um die Situation eines Absturzes auf S3 zu reduzieren, ersetzt der kostengünstige Speicher S3 gp3;
- Verteilte Implementierung der horizontalen Knotenerweiterung basierend auf einem HDFS-Cluster;
- Nutzen Sie die Eigenschaften des heterogenen Hadoop-Speichers und zerlegen Sie E/A entsprechend den Geschäftsmerkmalen, um Leistung und Kosten zu optimieren. Wir haben den HDFS-Speicher in zwei Teile aufgeteilt: „DISK“ und „SSD“. Der Speichertyp „SSD“ entspricht einem Hybridspeicher, der den EBS-Cache und die S3-Integration von JuiceFS nutzt. Der Speichertyp „DISK“ ist so konfiguriert, dass er in das EBS-gespeicherte Verzeichnis des DN schreibt. In den Verzeichnissen, die häufig überschrieben werden, wie z. B. dem Stage-Verzeichnis, werden wir diese Verzeichnisse so einstellen, dass sie DISK zur Speicherung verwenden. EBS-Speicher eignet sich besser für häufiges Löschen und Schreiben. Im Vergleich zu S3 sind die zusätzlichen OP-Kosten geringer und der Gesamtspeicherbedarf dieser Verzeichnisse ist kontrollierbar, sodass wir in diesem Szenario einen kleinen Teil des EBS-Speichers reservieren.
Rechenschicht: gemischtes Bereitstellungsschema aus Spot-Knoten und On-Demand-Knoten
Wenn wir den inländischen selbst erstellten YARN-Cluster in die Cloud migrieren, kann er sich zunächst nicht an die Ressourceneigenschaften in der Cloud anpassen, um eine Kostenoptimierung zu erreichen. Daher kombinieren wir die YARN-basierte intelligente dynamische Skalierungslösung mit der Etikettenplanung und übernehmen eine gemischte Bereitstellungslösung aus Spot-Knoten und On-Demand-Knoten, um die Nutzung von Rechenressourcen zu optimieren.
- Passen Sie die Scheduler-Strategie an die Kapazitätsplanung an (CapacityScheduler).
- Teilen Sie On-Demand-Knotenpartitionen und Spot-Knotenpartitionen auf.
- Passen Sie die Partition zustandsbehafteter Knoten an bedarfsgesteuerte Knoten an, sodass Aufgaben mit unterschiedlichen Zuständen in unterschiedlichen Bereichen ausgeführt werden.
- Verwenden Sie On-Demand-Knoten, um das Endergebnis abzudecken.
- Recycling-Benachrichtigung und GracefulStop: Wenn der präventive Knoten vor dem Recycling eine Benachrichtigung über das Recycling erhält, rufen Sie 6 auf. GracefulStop stoppt das Geschäft und vermeidet einen direkten Ausfall des Benutzerjobs.
Spark+RSS verringert die Wahrscheinlichkeit, dass sich die Daten beim Recycling eines Knotens ursprünglich auf dem dynamischen Knoten befinden und der Job neu berechnet werden muss.
-
Basierend auf unseren Geschäftsanforderungen haben wir einige dynamische, intelligente Skalierungslösungen entwickelt. Im Vergleich zur nativen Lösung legen wir mehr Wert auf die Richtung der dynamischen Skalierung basierend auf der Geschäftslage, da es für Cloud-Anbieter unmöglich ist, die Hotspots des Geschäfts zu kennen.
-
Die intelligente Skalierung wird auf Basis der periodischen Prognose des internen Betriebs- und Wartungstools Smarttool realisiert. Wir nehmen historische Daten der ersten drei Wochen, führen eine einfache Anpassung durch und erhalten dann über den Smarttool-Voreinstellungsalgorithmus die Restsequenzresid der Anpassung und den vorhergesagten Wert ymean. Verwenden Sie dieses Tool, um vorherzusagen, wie die Ressourcennutzung zu einem bestimmten Zeitpunkt am Tag aussehen sollte, und implementieren Sie dann eine dynamische Skalierung.
-
Geplante Skalierung basierend auf Zeitregeln, z. B. Vorskalierung für eine bestimmte Zeit: Voreingestellte Kapazität zu bestimmten Zeiten, z. B. zur monatlichen Berichtserstellungszeit am 1. jedes Monats, bei großen Werbeaktionen usw.
-
Dynamische Skalierung basierend auf der Nutzungsrate: Wenn die genutzte Kapazität innerhalb eines bestimmten Zeitraums über der Obergrenze des Schwellenwerts oder unter der Untergrenze des Schwellenwerts liegt, wird eine automatische Erweiterung und Verkleinerung ausgelöst, um unerwarteten Nutzungsanforderungen gerecht zu werden. Versuchen Sie sicherzustellen, dass unser Unternehmen eine stabile, aber relativ kostengünstige Rechenressourcenlösung in der Cloud erhalten kann.
Lebenszyklusmanagement: Daten-Tiering zur Optimierung der Speicherkosten
Wir haben JuiceFS und S3 tatsächlich für die Datenzuverlässigkeit basierend auf dem Replikatmechanismus integriert. Unabhängig davon, ob es sich um eine EC mit drei Kopien oder 1,5 Kopien handelt, fallen zusätzliche Kosten für den Speicheraufwand an. Wir gehen jedoch davon aus, dass die Daten eine gewisse Beliebtheit aufweisen. Sobald die Daten einen bestimmten Lebenszyklus durchlaufen haben, ist der Bedarf an E/A möglicherweise nicht mehr so hoch. Aus diesem Grund haben wir eine Einzelkopieebene von Alluxio+S3 eingeführt, um diese Daten zu verarbeiten. Es ist jedoch zu beachten, dass die Leistung dieser Ebene tatsächlich viel schlechter ist als bei der Verwendung von JuiceFS, wenn die Verzeichnisstruktur nicht geändert wird. Dennoch können wir eine solche Leistung in Cold-Data-Szenarien noch akzeptieren.
Aus diesem Grund haben wir unabhängig einen Daten-Governance- und Organisationsschichtungsdienst entwickelt und die Verwaltung und Kostenoptimierung von Daten in verschiedenen Lebenszyklen durch asynchrone Datenverarbeitung realisiert. Wir nennen diesen Dienst Data Lifecycle Management Tool BTS.

Das Design von BTS basiert auf unserer Dateidatenbank, Metadaten und Prüfprotokolldaten und realisiert das Datenlebenszyklusmanagement durch die Verwaltung von Tabellen und deren Wärme. Benutzer können den übergeordneten DAYU-Regelmanager verwenden, um Regeln anzupassen und die Popularität von Daten zum Generieren von Regeln zu nutzen. Diese Regeln legen fest, welche Daten als kalt und welche als heiß gelten.
Gemäß diesen Regeln führen wir verschiedene Lebenszyklusverwaltungsvorgänge wie Komprimierung, Zusammenführung, Transformation, Archivierung oder Löschung der Daten durch und verteilen sie zur Ausführung an den Planer. Das Data-Lifecycle-Management-Tool BTS bietet folgende Funktionen:
- Datenreorganisation, Zusammenführung kleiner Dateien zu großen Dateien, Optimierung der EC-Speichereffizienz und des Namensknotendrucks;
- Konvertierung von Tabellenspeicher- und Komprimierungsmethoden: Konvertieren Sie Tabellen asynchron vom Textspeicherformat in das ORC- oder Parquet-Speicherformat und konvertieren Sie die Komprimierungsmethode von None oder Snappy in ZSTD, was die Speicher- und Leistungseffizienz verbessern kann. BTS unterstützt die asynchrone Tabellenkonvertierung nach Partition;
- Heterogene Datenmigration, die Daten asynchron zwischen Speichern verschiedener Architekturen migriert und so organisatorische Möglichkeiten für die Datenebene bietet.
Wir unterteilen die Speicherschichtarchitektur einfach in drei Schichten:
- Die beste Leistung bietet HDFS auf JuiceFS (hot), 3 Kopien;
- gefolgt von einer (warmen) 1,5-Kopie von HDFS auf JuiceFS EC;
- Wieder eine Kopie von Alluxio auf S3 (niederfrequente Kaltdaten);
- Bevor alle Daten gelöscht werden, werden sie in Alluxio auf S3 archiviert und zu einer Einzelkopie.

Derzeit sind die Auswirkungen der Datenlebenszyklus-Governance wie folgt:
- 60 % kalt, 30 % warm, 10 % heiß;
- Die durchschnittliche Anzahl der Replikate (70 % * 1 + 20 % * 1,5 + 10 % * 3) = 1,3. Bei der Archivierung, die keine hohe Leistung erfordert, können wir etwa 70 % der Daten erreichen. Etwa 20 % der Daten bei Verwendung von EC-Replikaten und etwa 10 % bei Verwendung von drei Replikaten. Wir haben die Anzahl der Replikate insgesamt kontrolliert und durchschnittlich etwa 1,3 Replikate beibehalten.
03. Der Online-Effekt der neuen Übersee-Architektur: Leistung und Kosten
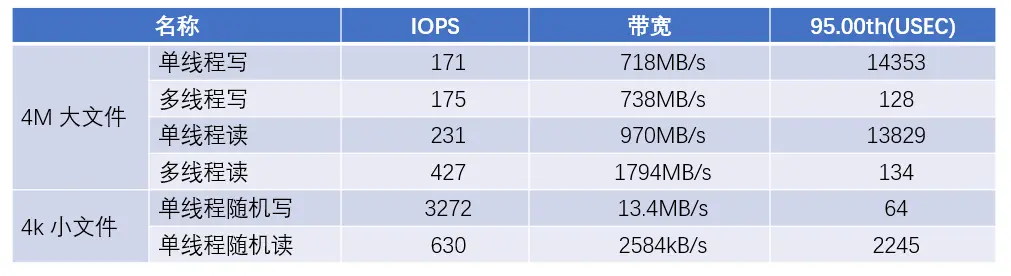
In Tests konnte JuiceFS eine recht hohe Bandbreite zum Lesen und Schreiben großer Dateien erreichen. Insbesondere im Multithread-Modell liegt die Bandbreite zum Lesen großer Dateien nahe an der Bandbreitenbegrenzung der Netzwerkkarte des Clients.
Im Szenario mit kleinen Dateien ist die IOPS-Leistung beim zufälligen Schreiben besser (dank der GP3-Festplatte als Cache), während die IOPS-Leistung beim zufälligen Lesen relativ niedrig ist, etwa fünfmal schlechter.
Der Vergleich zwischen der EBS-Lösung und der JuiceFS + S3-Lösung in der tatsächlichen Geschäftsmessung. Der Testfall ist das Geschäfts-SQL in unserer Produktionsumgebung. Es ist ersichtlich, dass sich JuiceFS + S3 im Grunde nicht wesentlich von EBS unterscheidet, einige SQL-Anweisungen jedoch noch besser. JuiceFS + S3 kann also die gesamte Menge an EBS ersetzen.
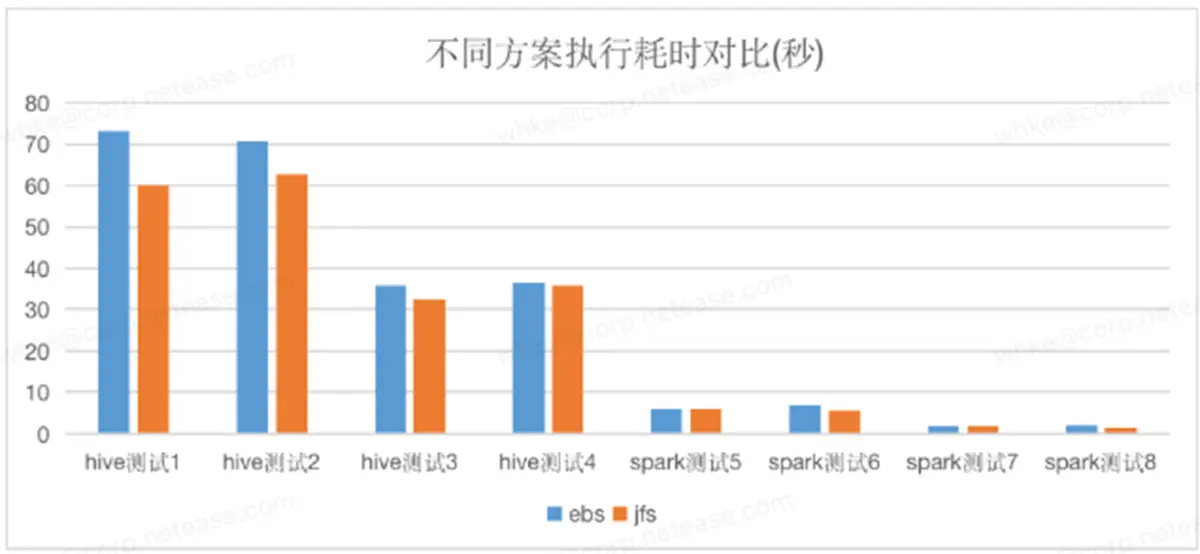
Verwenden Sie die JuiceFS-basierte S3+EBS-Hybrid-Layer-Storage-Computing-Trennungslösung, um die ursprüngliche EBS-Lösung zu ersetzen. Durch Datenverwaltung und Datenschichtung wird der ursprüngliche Hadoop-Dreikopiemechanismus auf durchschnittlich 1,3 Kopien reduziert, wodurch 55 % mehrerer Kopien eingespart werden Kosten: Die Gesamtspeicherkosten sanken um 72,5 %.

Durch intelligente dynamische Skalierung werden 85 % der Cluster-Nutzungsrate und 95 % der Spot-Instanzen zum Ersetzen von On-Demand-Knoten verwendet, und die gesamten Rechenkosten betragen mehr als 80 % im Vergleich zu denen vor der Optimierung.
04. Zusammenfassung und Ausblick: Auf dem Weg zu Cloud Native
Im Vergleich zur ursprünglichen JuiceFS-Lösung verwendet Hadoop+JuiceFS zusätzliche Kopien, um die Speicherleistung zu optimieren und Kompatibilität und hohe Verfügbarkeit zu unterstützen. DN schreibt nur eine Kopie und verlässt sich dabei auf die iterative Optimierung von JuiceFS hinsichtlich der Zuverlässigkeit.
Obwohl eine Multi-Cloud-kompatible Lösung, die besser als EMR ist, in verschiedenen Clouds implementiert wurde, sind für hybride Multi-Cloud- und Cloud-native-Lösungen weitere Iterationen erforderlich.
Im Hinblick auf die Aussicht auf Cloud-native Big-Data-Szenarien in der Zukunft ist die Lösung, die wir derzeit verwenden, nicht die ultimative Version, sondern eine Übergangslösung, die auf die Lösung von Kompatibilitäts- und Kostenproblemen abzielt. Für die Zukunft planen wir folgende Maßnahmen:
- Fördern Sie die Migration von Unternehmen zu einer stärker cloudnativen Lösung, verwirklichen Sie die Entkopplung der Hadoop-Umgebung und integrieren Sie Data Lake und Cloud Computing eng.
- Wir treiben ein höheres Maß an Hybrid-Multi-Cloud-Computing- und Hybrid-Speicherlösungen voran und ermöglichen echte Integration und nicht nur Kompatibilität. Dies wird den oberen Geschäftsbereichen mehr Wert und Flexibilität bringen.
Ich hoffe, dieser Inhalt kann Ihnen weiterhelfen. Wenn Sie weitere Fragen haben, treten Sie bitte der JuiceFS-Community bei , um mit allen zu kommunizieren.
Ministerium für Industrie und Informationstechnologie: Bereitstellung von Netzwerkzugriffsdiensten für nicht registrierte Apps. Go 1.21 offiziell veröffentlicht. Ruan Yifeng hat ein „ TypeScript-Tutorial“ veröffentlicht . Bram Moolenaar, der Vater von Vim, ist krankheitsbedingt verstorben. Der selbst entwickelte Kernel Linus hat den Code persönlich überprüft , in der Hoffnung, die durch das Bcachefs-Dateisystem ausgelösten „internen Machtkämpfe“ zu beruhigen. ByteDance hat einen öffentlichen DNS-Dienst gestartet . Ausgezeichnet, habe mich diesen Monat für die Hauptlinie des Linux-Kernels entschieden