Notas sobre Sistemas de Computação Distribuída
Introdução ao curso
plano de fundo do curso
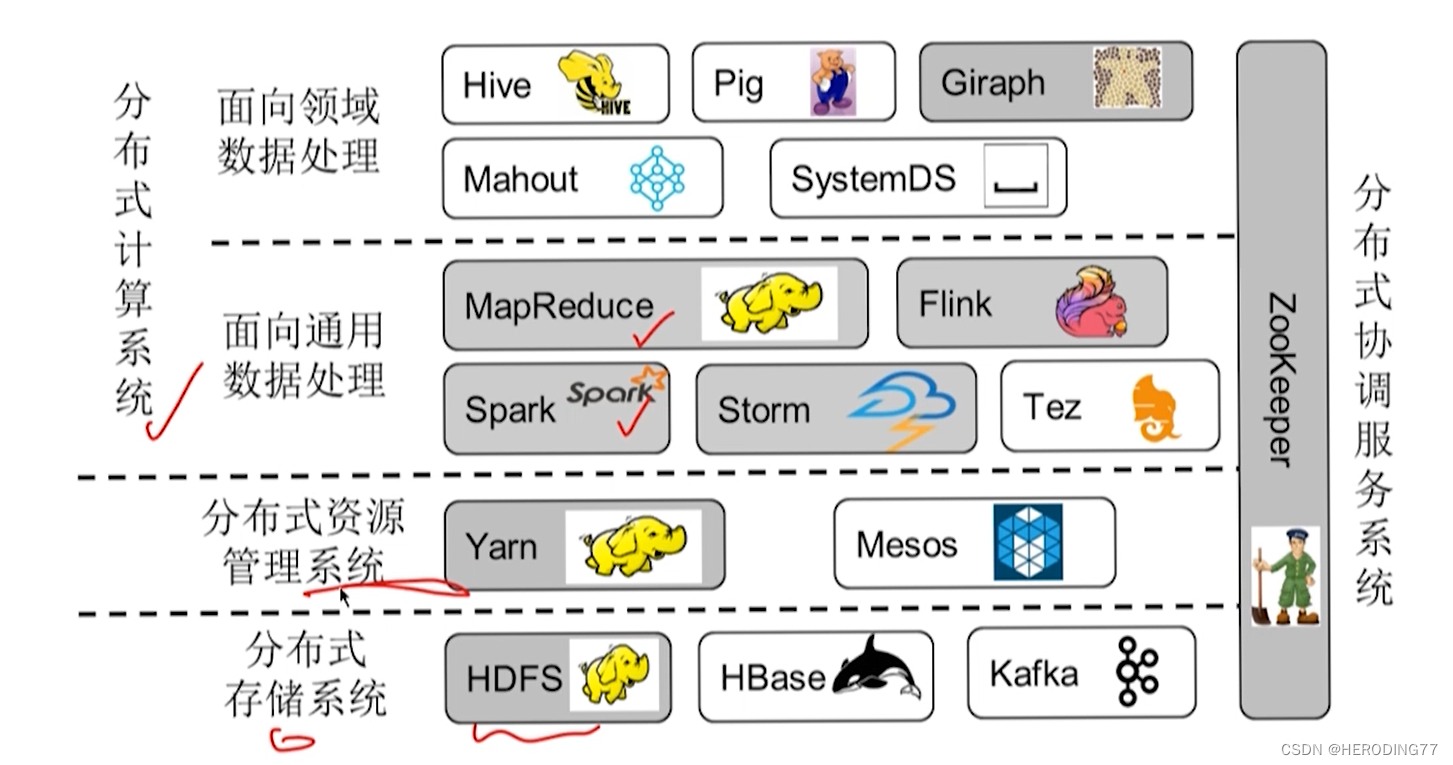
Sistema de Processamento de Big Data ——> Sistema de Computação Distribuída
- Hadoop, Spark, Flink
- O significado de big data é muito amplo
Este curso/livro
- Ênfase na coleção de design de sistema, princípios e programação
objetivo do curso
- desenvolver pensamento sistêmico
- Camada de aplicação: pesquisa, recomendação
- Camada de design de algoritmo: PageRank, SVM, CNN
- Camada do sistema de software: Spark, Flink, TensorFlow, OceanBase
- Camada da plataforma de hardware: GPU, NVM, Cambriano
Livro didático do curso: "Sistema de Computação Distribuída"
avaliação do curso
- Pontuação normal: 50%
- Avaliação final: 50%
informação do curso
- Plataforma do curso: https://www.shuishan.net.cn/education/
- Assistente de ensino: XXX
Capítulo Um Introdução
contorno
-
Sistemas distribuídos
- O que é um sistema distribuído
- Tipos de Sistemas Distribuídos
-
Sistemas distribuídos sob a perspectiva do gerenciamento de dados.
- Revisão do Desenvolvimento do Sistema de Gestão de Dados
- Desafios enfrentados pelo gerenciamento de dados no contexto de big data
- Sistema distribuído para gerenciamento de dados
-
sistema de computação distribuído
- O que é um Sistema de Computação Distribuída
- Ecossistema do sistema
-
Organização do Curso
1.1 Sistema distribuído
1.1.1 O que é um sistema distribuído
"Sistema distribuído: conceito e design" acredita que: um sistema distribuído é uma coleção de vários computadores independentes e esses computadores são como um sistema autônomo para os usuários.
1.1.2 Tipos de Sistemas Distribuídos
-
Sistema distribuído baseado em computador
- sistema de computação distribuído
- Cluster computing (mesma instituição)
- Computação em grade (diferentes instituições)
- computação em nuvem
- sistema de informação distribuído
- processamento de transações
- Integração de informações corporativas
- sistema de computação distribuído
-
Sistemas distribuídos construídos em dispositivos minúsculos
- família inteligente
- eSaúde
- rede de sensores
1.2 Sistemas distribuídos sob a ótica da gestão de dados
1.2.1 Revisão do desenvolvimento do sistema de gerenciamento de dados
Primeira geração: sistemas de banco de dados hierárquicos e interligados
- O armazenamento e o acesso aos dados são separados do aplicativo (sistema de arquivos)
Segunda Geração: Sistemas de Banco de Dados Relacionais
- OLTP (transação)
A terceira geração: sistema de data warehouse
- OLAP (análise)
Quarta Geração: Sistema de Gerenciamento de Big Data
- Distribuído, escalável e altamente disponível
1.2.2 Desafios enfrentados pela gestão de dados sob o pano de fundo do big data
![[Transferência de imagem...(img-83aOGaSf-1687590392089)]](https://img-blog.csdnimg.cn/86962224bffd43d0b81074d68b9d526d.png)
Oportunidades e Desafios
Grande quantidade de dados: os sistemas de gerenciamento de big data são necessários para armazenar e gerenciar TB ou até mesmo dados em nível de PB.
Vários tipos de dados: os sistemas de gerenciamento de big data são necessários para processar vários tipos de dados na mesma plataforma.
Velocidade de geração rápida: O sistema de gerenciamento de big data é necessário para poder processar dados em tempo real (ms) durante o processo de geração de dados.
Alto valor potencial: o sistema de gerenciamento de big data é necessário para suportar o uso de aprendizado de máquina, mineração de dados, análise de dados, etc.
Baixa qualidade de dados: sistemas de gerenciamento de big data são necessários para dar suporte a governança de dados mais complexos, análise de dados e técnicas de aprendizado de máquina.
PS: O resumo é, grande, poderoso, rápido
1.2.3 Sistema distribuído para gerenciamento de dados
Do "de uma vez por todas" à customização de categorias.
A razão pela qual é impossível fazer isso de uma vez por todas: nem as redes sociais nem os gráficos de conhecimento são dados estruturados.

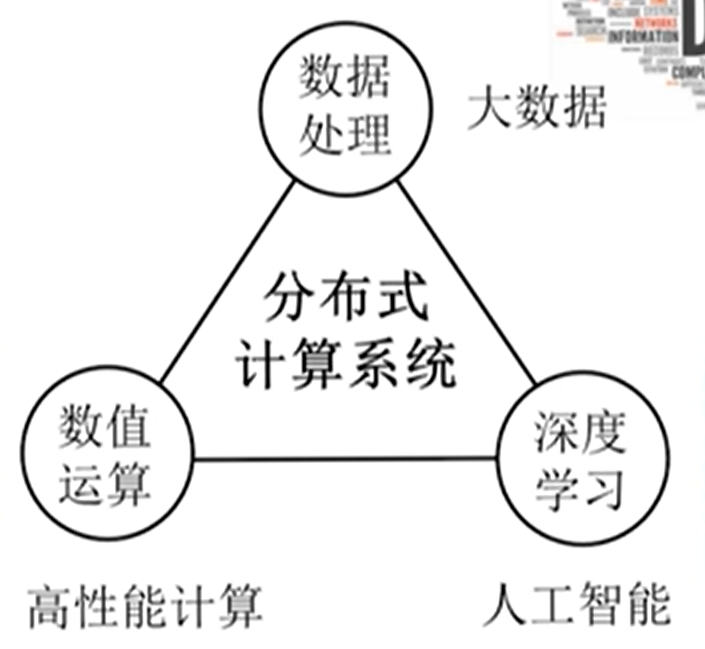
1.3 Sistema de Computação Distribuída
1.3.1 O que é um sistema de computação distribuído
É um sistema de software que atua em vários computadores independentes, permitindo que esses computadores cooperem para executar cálculos para concluir uma aplicação.
O que se resume a um sistema distribuído projetado para resolver certas classes de problemas de aplicativos.
Classificação
- Aplicativos de computação intensiva: o poder de processamento da CPU torna-se o principal fator limitante.
- Aplicativos com uso intensivo de dados: a largura de banda de E/S torna-se o primeiro fator limitante (crítico).
1.3.2 Ecossistema do sistema
![[)(https://cdn.staticaly.com/gh/heroding77/pic_bed@main/distributed_computing_system/boxcnCzWL8eqyrdKdV7BPp3KEVe.png)]](https://img-blog.csdnimg.cn/40b5eaa276f84f9f9a473a910d1ea0a3.png)

1.4 Estrutura de Organização do Curso
- pensamento de design
- arquitetura
- princípio de trabalho
- mecanismo de tolerância a falhas
- exemplo de programação

Capítulo 2: Sistema de arquivos Hadoop
2.1 Pensamento do projeto
Biblioteca de pesquisa de texto de origem por Doug Cutting
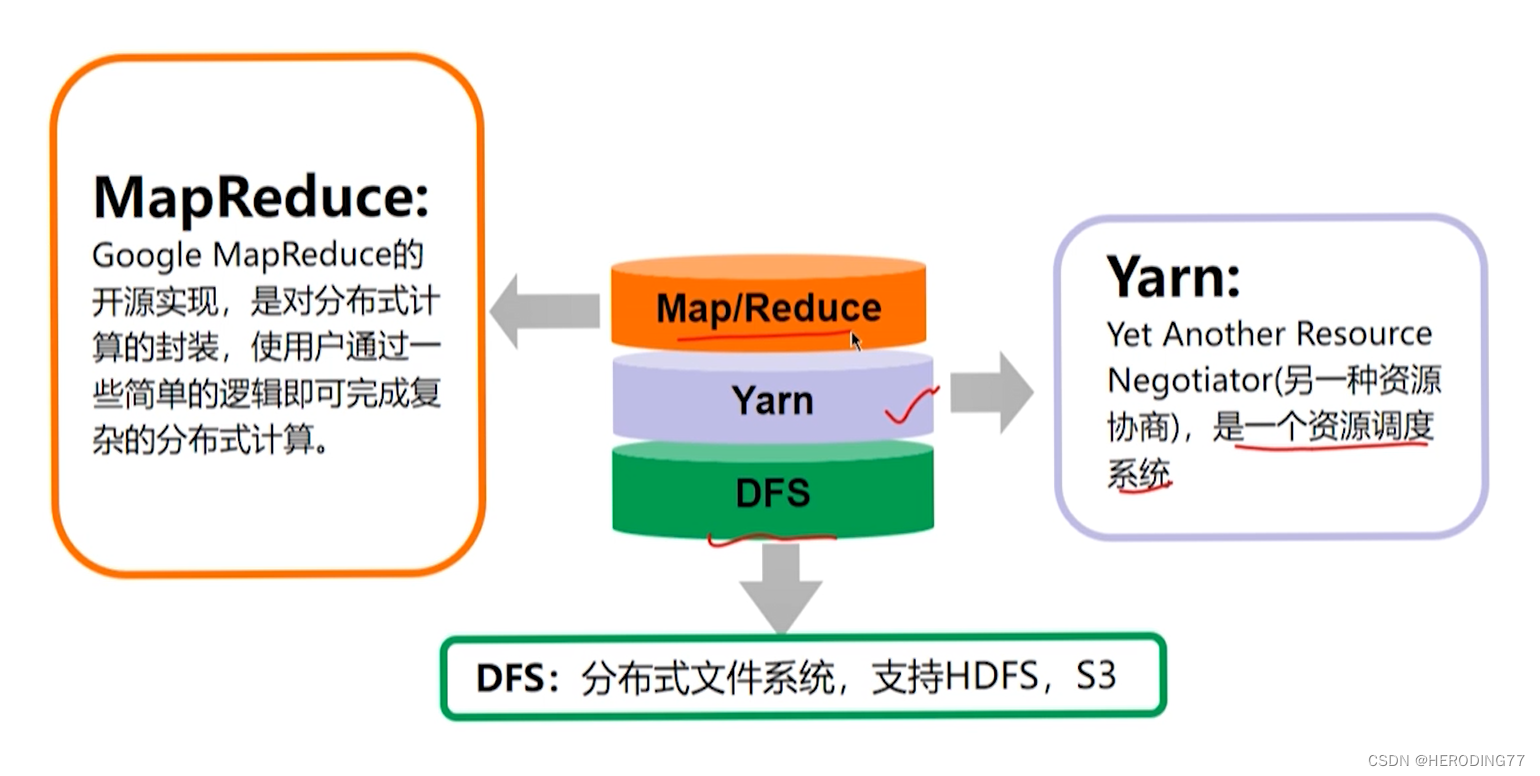
Nascido em 2006, MapReduce+HDFS
- HDFS: Sistema de Arquivos Distribuídos
- MapReduce: Estrutura de Computação Distribuída
Topologia de rede de cluster
- quadro
- nó

Alguns problemas encontrados antes do HDFS:
- Não é possível armazenar arquivos grandes (centenas de GB/TB).
- A taxa de tolerância a falhas do sistema de cluster é baixa.
- Leitura e gravação simultânea de arquivos grandes.
HDFS:
- Armazenamento em bloco de arquivos (padrão 64 MB)
- Indexação entre máquinas (os blocos são distribuídos para várias máquinas e o índice é salvo com entradas de diretório de arquivo)
- bloquear armazenamento redundante
- Leitura e gravação simplificadas de arquivos (a gravação de arquivos não é mais modificada, apenas leituras múltiplas são permitidas e apenas a gravação sequencial é suportada)
2.2 Arquitetura
2.2.1 Diagrama de Arquitetura

papéis HDFS
-
NameNode
- Responsável pelo gerenciamento do HDFS, incluindo o gerenciamento da estrutura do diretório de arquivos, manutenção do status do DataNode, etc.
- O arquivo não é realmente armazenado.
-
SecondaryNameNode
- Atua como um backup NameNode.
- Quando o NameNode falhar, use o SecondaryNameNode para recuperar.
-
DataNode
- Responsável pelo armazenamento dos blocos de dados.
- Serve os dados reais do arquivo para o cliente.
Ferramentas para Gerenciamento de NameNode
- FsImage: Um instantâneo do diretório de arquivo na memória e seus metadados no disco.
- EditLog: Operações em modificações de diretório e arquivo entre dois instantâneos.


2.2.2 Fluxo de execução do aplicativo
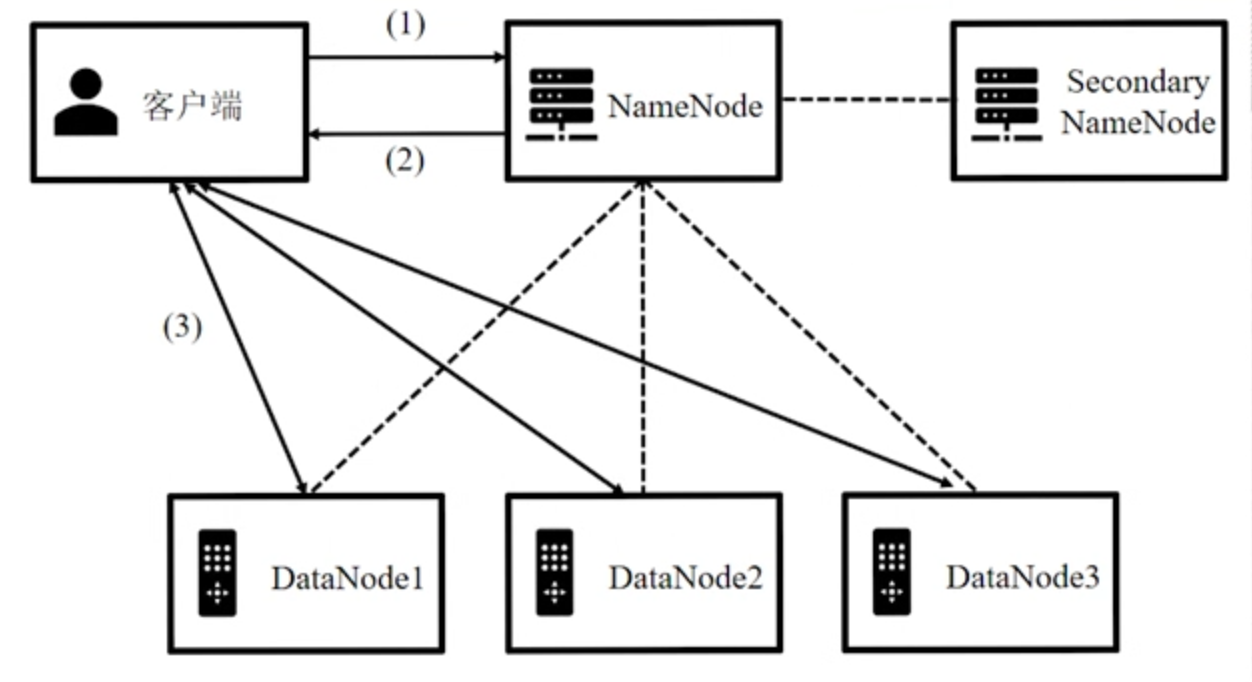
Processo de implementação:
-
O cliente inicia uma solicitação de operação de arquivo para o NameNode.
-
Feedback do NameNode
- Operações de leitura e gravação, informando ao cliente onde o bloco de arquivo está armazenado.
- Criar, excluir, renomear, NameNode modifica a estrutura do diretório de arquivos.
- Uma operação de exclusão espera um determinado período de tempo antes de realmente excluir.
-
Operação de leitura e gravação O cliente obtém as informações de localização e realiza interações de leitura e gravação com o DataNode.
2.3 Princípio de funcionamento
2.3.1 Partição e Backup de Arquivos

Estratégia de armazenamento de bloco de arquivo
-
primeira cópia
- Se o cliente e um DataNode estiverem localizados no mesmo nó físico, o HDFS colocará a primeira cópia no DataNode (local mais rápido)
- Se não estiver no mesmo nó físico que qualquer DataNode, o HDFS selecionará aleatoriamente um nó cujo disco não esteja cheio e cuja CPU não esteja ocupada.
-
segunda cópia
- Um nó colocado em um rack diferente.
- É benéfico reduzir o tráfego de rede dos clientes nos racks como um todo.
-
terceira cópia
- Colocado em um nó diferente do mesmo rack da primeira réplica.
- Leituras de blocos de arquivo em resposta a falhas de switch.
2.3.2 Escrita de arquivo
O NameNode informa aos clientes onde cada bloco de dados do arquivo está armazenado.
Os clientes transferem blocos de dados diretamente para nós de dados designados.
2.3.3 Leitura de arquivos

2.3.4 Leitura e escrita de arquivos e consistência
Escreva uma vez, leia muitas vezes
- Depois que o arquivo é criado, gravado e fechado, o conteúdo do arquivo não deve ser alterado.
- Já gravado no arquivo HDFS, só é permitido anexar dados no final do arquivo.
- Uma operação de gravação de arquivo negará outras solicitações de leitura e gravação no arquivo.
- As operações de leitura permitem leituras simultâneas.
2.4 Mecanismo de tolerância a falhas
tipo de falha
- erro de disco
- Falha no DataNode
- falha no interruptor
- Falha no nó de nome
- falha do centro de dados
2.4.1 Falha no NameNode
Restaurar com base nos dados FsImage e Editlog em SecondaryNameNode.
2.4.2 Falha no DataNode
- Tempo de inatividade, a marca do nó no nó é ilegível.
- Verifique o fator de backup regularmente.
2.5 Exemplo de programação
2.5.1 Escrevendo arquivos
- Obtenha o objeto do sistema de arquivos do HDFS
- Obtenha o fluxo de saída hdfsOutputStream
- Grave no arquivo HDFS usando o fluxo de saída
2.5.2 Lendo arquivos
- Obtenha o objeto do sistema de arquivos do HDFS
- Obter o fluxo de entrada InputStream
- Copie o fluxo de entrada do arquivo HDFS para o fluxo de saída do arquivo local
Pergunta
-
Por que o HDFS é necessário e como seria sem o HDFS?
- Armazene arquivos grandes no nível de centenas de GB/TB.
- Garanta a tolerância a falhas do sistema de arquivos.
- Execute leitura e gravação simultâneas de arquivos grandes.
-
Quais partes o HDFS inclui e quais são suas funções?
Consulte 2.2.1 Diagrama de arquitetura para obter detalhes.
Capítulo 3 Sistema de processamento em lote MapReduce
3.1 Pensamento de design
3.1.1 MPI e MapReduce
MPI é uma interface de programação de aplicativo de passagem de mensagem, incluindo protocolo e especificação semântica.
limitação:
- Do ponto de vista do usuário, os programadores precisam considerar o paralelismo entre os processos , e a comunicação entre os processos precisa ser explicitamente expressa.
- Do ponto de vista da implementação do sistema, o programa MPI é executado na forma de um processo.Se o processo travar, ele não pode fornecer tolerância a falhas (a menos que o usuário adicione a recuperação de falhas).
3.1.2 Modelo de Dados
Abstraia dados em pares chave-valor e converta pares chave-valor durante o processamento.
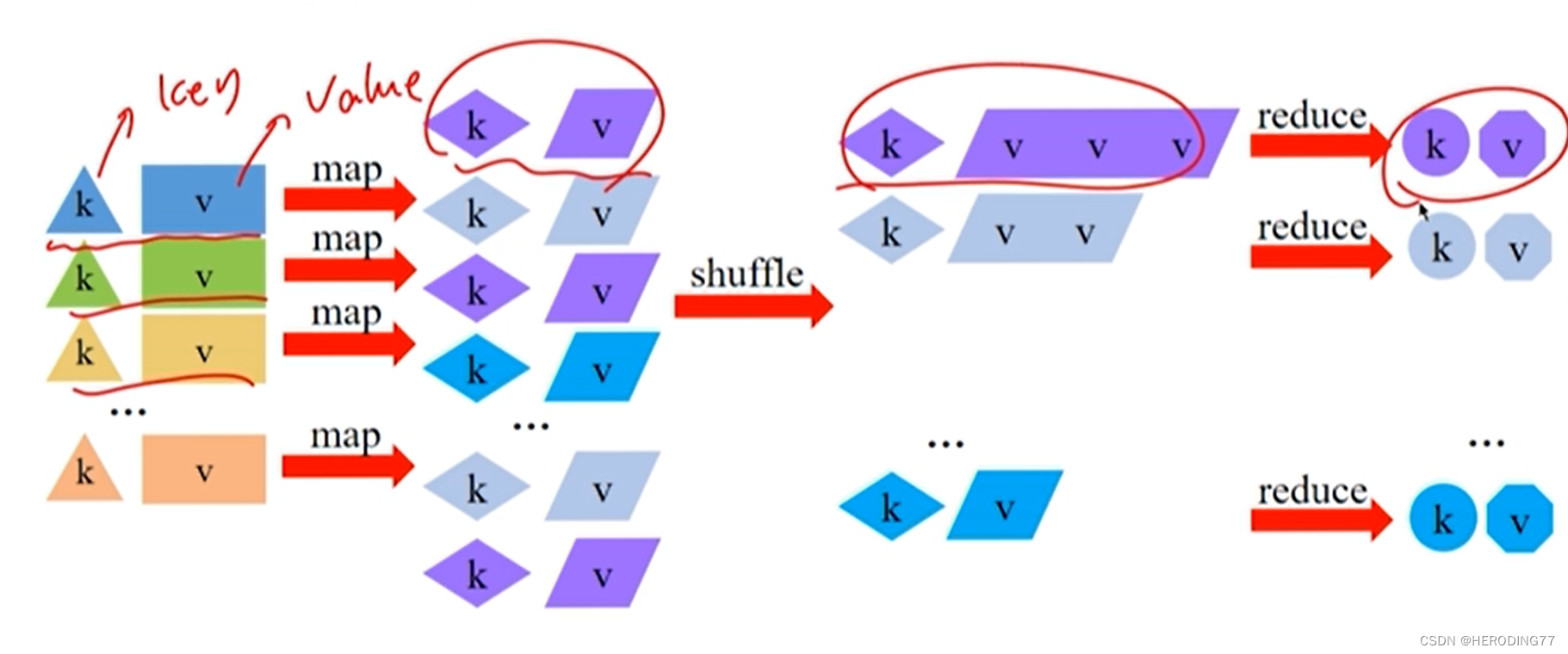
3.1.3 Modelo de cálculo
Mapear+Reduzir
- Mapa: converte pares de valores-chave de entrada em novos pares de valores-chave.
- Reduzir: Calcule o valor da chave da mesma chave.
Fisicamente, a ideia de dividir e conquistar é completada pela computação paralela de múltiplas tarefas.
3.2 Arquitetura
3.2.1 Diagrama de Arquitetura
Diagrama de arquitetura abstrata

Diagrama de arquitetura do Hadoop MapReduce

Se é uma tarefa de mapa ou uma tarefa de redução, não pode ser visto de fora.
JobTracker
- Gerenciamento de recursos: monitore e gerencie recursos de computação no sistema.
- Gerenciamento de tarefas: divida tarefas em tarefas, agende tarefas, rastreie recursos em execução de tarefas e outras informações.
Rastreador de Tarefas
- Gerenciar recursos de nós locais
- Execute o comando JobTracker.
- Reporte ao JobTracker.
MapReduce é um método multi-processo , enquanto Spark e Flink são multi-threaded .
Relação entre MapReduce e HDFS:
- Computação e armazenamento separados.
- A computação se move em direção aos dados, não os dados em direção à computação.

3.2.2 Fluxo de execução do aplicativo

processo:
- O cliente carrega as informações de configuração do trabalho MapReduce, pacote jar e outras informações escritas pelo usuário para o sistema de arquivos compartilhado (geralmente HDFS);
- O cliente envia o trabalho para o JobTracker e informa a localização das informações do trabalho;
- O JobTracker lê as informações do trabalho, gera uma série de tarefas Map e Reduce e as agenda para o TaskTracker com slots livres (recursos);
- TaskTracker inicia o processo Child para executar a tarefa Map de acordo com a instrução JobTracker, e a tarefa Map lê os dados de entrada do sistema de arquivos compartilhado.
- O JobTracker obtém as informações de progresso da tarefa Map do TaskTracker.
- Após a conclusão da tarefa Mapear, o JobTracker distribui a tarefa Reduzir para o TaskTracker;
- O TaskTracker inicia o Child para executar a tarefa Reduzir de acordo com as instruções obtidas, e a **tarefa Reduzir extrairá a saída do Mapa do **disco local (não HDFS)** do nó onde a tarefa Mapa está localizada;
- O JobTracker obtém as informações de andamento da tarefa Reduzir do TaskTracker.
- A tarefa Reduzir termina e grava o resultado no sistema de arquivos compartilhado, o que significa que todo o trabalho é executado.
3.3 Princípio de funcionamento
Entrada (HDFS) --> Mapa --> shuffle --> redução --> saída (HDFS)
3.3.1 Entrada de dados
Haverá arquivos armazenados em blocos e pode haver registros entre blocos . Unidade de leitura do mapa Divisão.
Dividir vs Bloquear
- O primeiro é um conceito lógico e o último é um conceito físico.
- split contém algumas metainformações, como posição inicial dos dados, comprimento dos dados, etc.
- A divisão não contém informações entre blocos, mas o bloco pode.
3.3.2 Etapa do mapa
[k1,v1]——>Lista([k2,v2])

Um processo típico de classificação por mesclagem bidirecional.
O número de tarefas de mapa geralmente é determinado pelo número de divisões.
3.3.3 Fase de embaralhamento

Quando embaralhar?
- Quando a taxa de conclusão da tarefa Mapear no sistema atinge o limite definido, a tarefa Reduzir é iniciada.
- Os dados extraídos por Reduce devem ser a tarefa Map concluída.
3.3.4 Reduzir estágio

Semelhante ao processo do Map, também há um processo de mesclagem e classificação.
Número de tarefas Reduzir
Execute de acordo com a tarefa Reduzir escrita pelo usuário.
3.3.5 Saída de dados
A entrada é um arquivo e a saída é um conjunto de arquivos.

Ao contrário do nó de dados de entrada, MapReduce precisa definir o formato do arquivo de saída, OutputFormat.
3.4 Mecanismo de tolerância a falhas
- Falha do nó primário: tempo de inatividade
- Falha do nó escravo: tempo de inatividade
- Falha na tarefa: memória JVM insuficiente
3.4.1 Falha no JobTracker
O MapReduce1.0 não manipula o mecanismo de falha do JobTracker, que se torna um único ponto de gargalo, e todos os trabalhos devem ser executados novamente.
3.4.2 Falha do TaskTracker
O mecanismo de pulsação é mantido.
Incapaz de se conectar, o JobTracker agenda outros TaskTrackers para reexecutar tarefas com falha.
O processo é transparente para o usuário.
3.4.3 Falha na tarefa
- Falha no mapa
- Reduzir falha
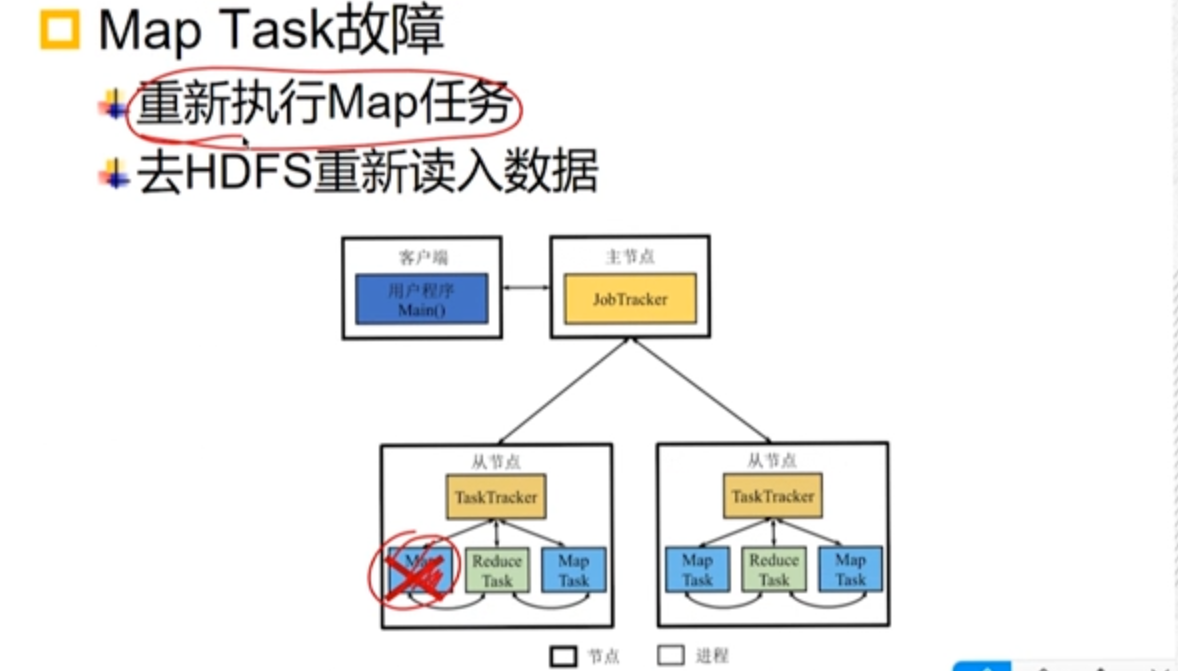
Reduza as tarefas de releitura dos dados do disco local.
Quando uma tarefa falha após o número máximo de tentativas, todo o trabalho é marcado como com falha.
3.5 Exemplo de programação
Otimização
- método de combinação
- Reduzir o número de Shuffles
- Reduzir a quantidade de dados processados pelo processo Reduzir

Pergunta
- A diferença entre combinar e mesclar?
A soma de dois pares chave-valor <“a”,1>, <“a”,1>se mesclados, resulta em <“a”,2>, e se mesclados, resulta<“a”,<1,1>>
- Qual é o papel do cache distribuído no MapReduce?
Ele desempenha o papel de broadcast e distribui o conjunto de dados a serem processados em um cache distribuído para melhorar a velocidade de leitura.
Capítulo 4 Sistema de processamento em lote Spark
Originalmente um sistema de processamento em lote baseado em computação de memória , agora também suporta o uso simultâneo de memória interna e externa.
O Spark foi 3 vezes mais rápido que o Hadoop em 2014 com um décimo dos recursos.

4.1 Pensamento do projeto
4.1.1 Limitações do MapReduce
limitação
- A capacidade expressiva da estrutura é limitada e os operadores básicos são muito poucos (apenas Mapear e Reduzir).
- Os dados no estágio Shuffle de uma única tarefa são transmitidos de maneira bloqueada, com alta sobrecarga de E/S e alta latência.
- Várias conexões de trabalho envolvem sobrecarga de E/S e a latência do aplicativo é alta.
4.1.2 Tipos de dados
RDD (conjunto de dados distribuído resiliente)
- é um conjunto de dados e o objeto de operação Spark é um conjunto de dados abstrato em vez de um arquivo.
- Distribuído, cada RDD pode ser dividido em várias partições, e diferentes partições de um RDD podem ser armazenadas em diferentes nós do cluster.
- Os RDDs são elásticos e têm tolerância a falhas recuperáveis.
4.1.3 Modelo de cálculo
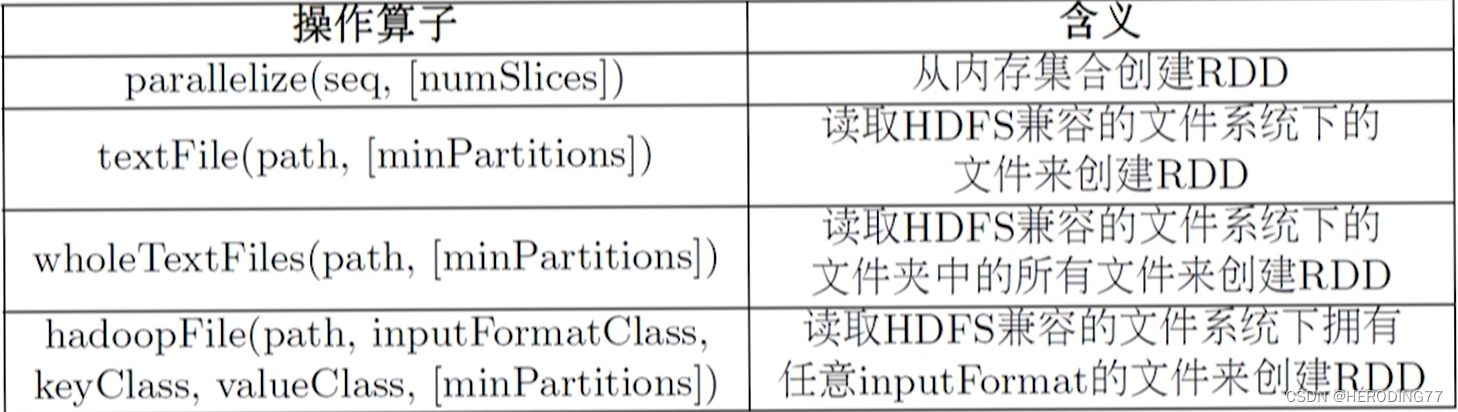
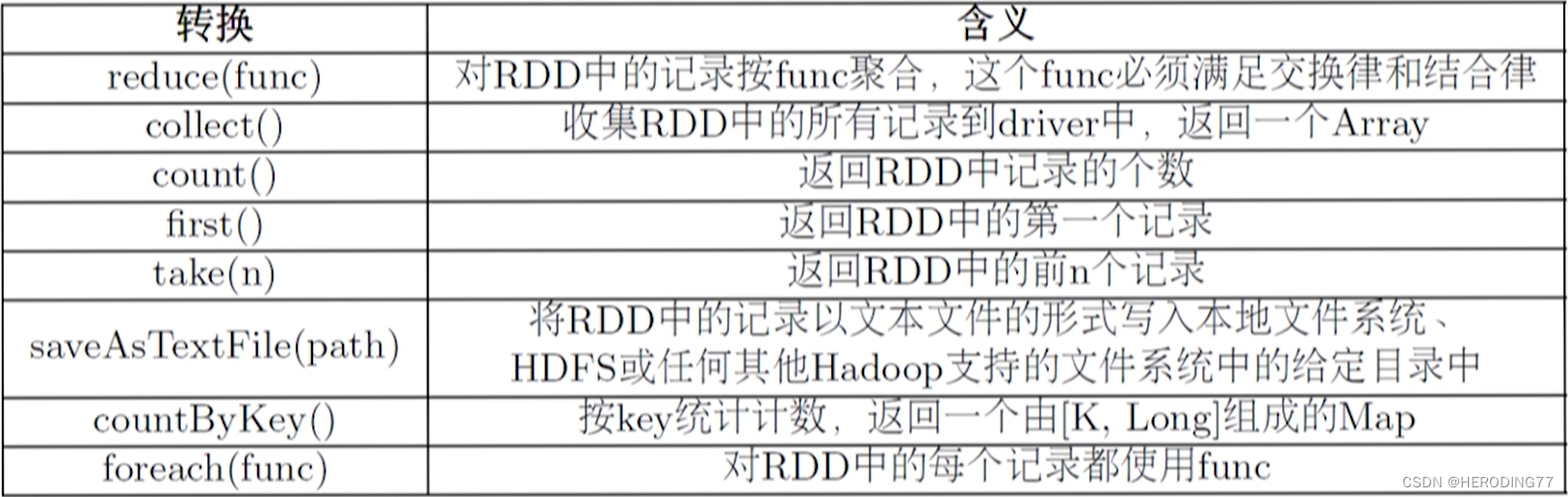
Operador de operação: operador de criação, operador de conversão, operador de ação
criar operador
operador de conversão

operador de ação
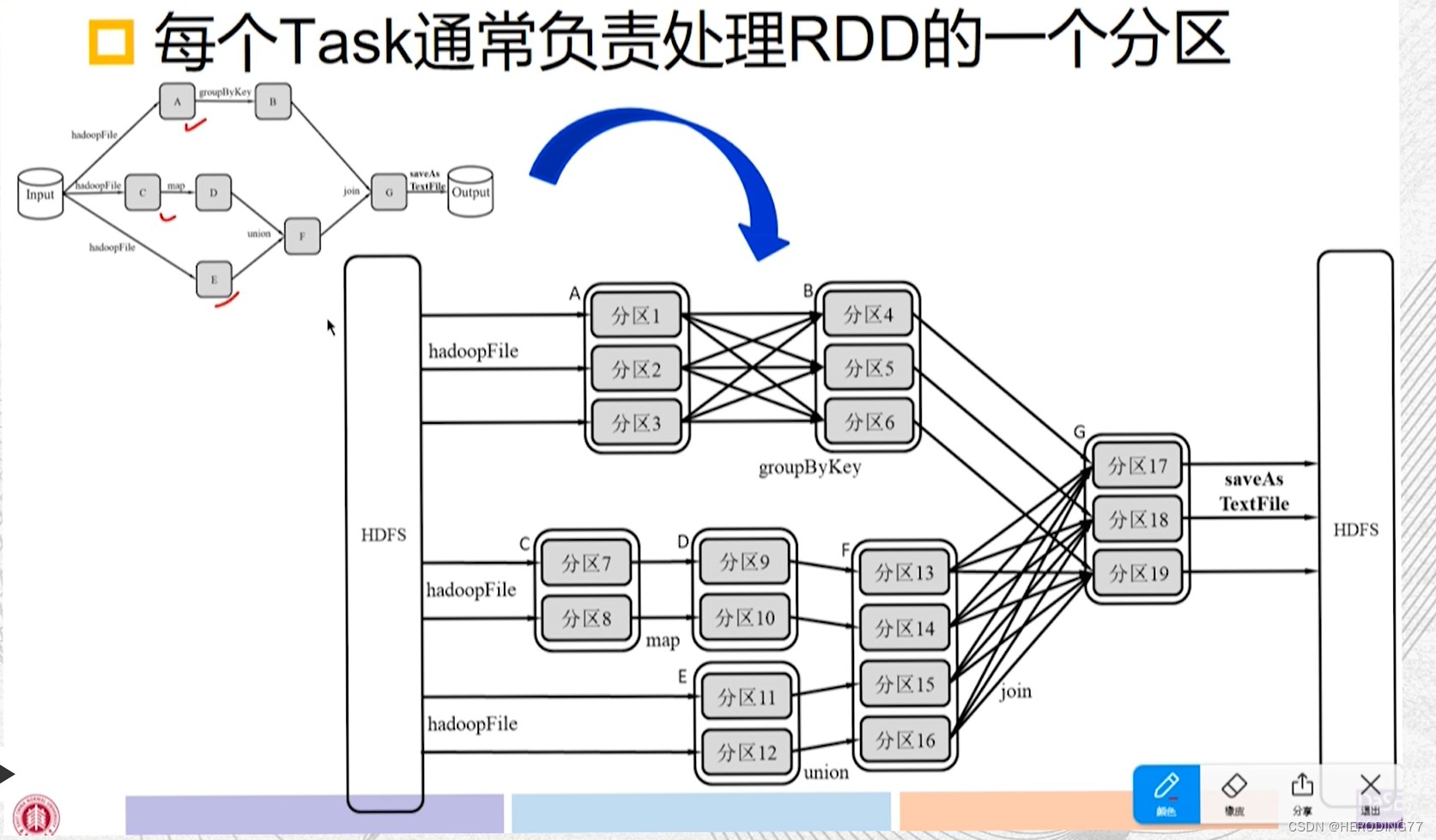
Descrever o processo de cálculo do ponto de vista das operações do operador

Descrever o processo de cálculo da perspectiva da transformação RDD

Linhagem RDD (topologia de gráfico acíclico direcionado por DAG)
- RDDs são criados pela leitura de dados externos.
- O RDD passa por uma série de operações de conversão e cada operação gera um novo RDD para a próxima operação de conversão.
- O último RDD é transformado pela operação de ação e enviado para fora.
Propriedades RDD
- RDD é uma coleção somente leitura de partições de registro e não pode ser modificada após a criação.
- RDDs são imutáveis. Após a operação RDD, um novo RDD é obtido em vez de ser modificado na base original.
- Seguindo as características da programação funcional.
4.2 Arquitetura
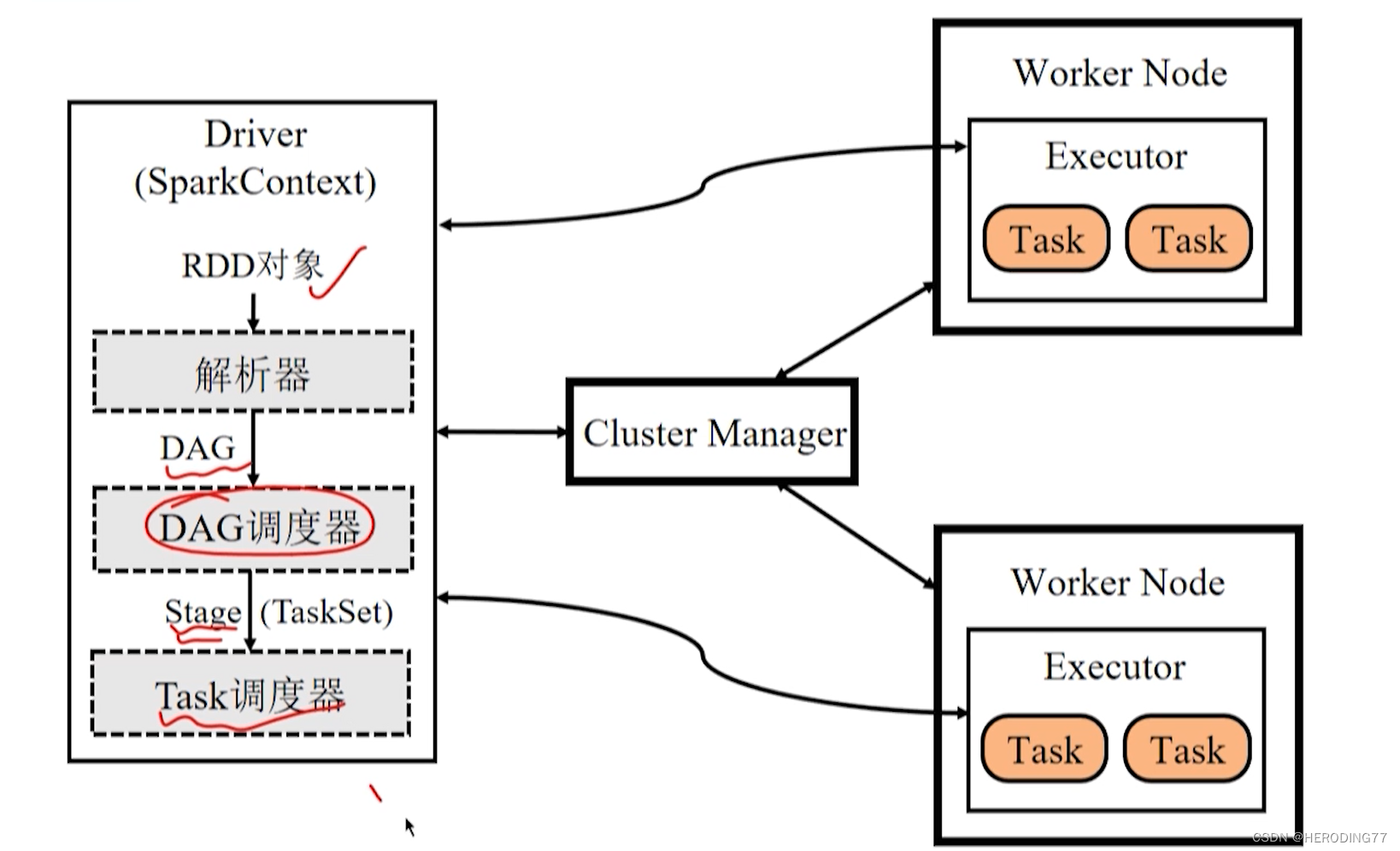
4.2.1 Diagrama de Arquitetura
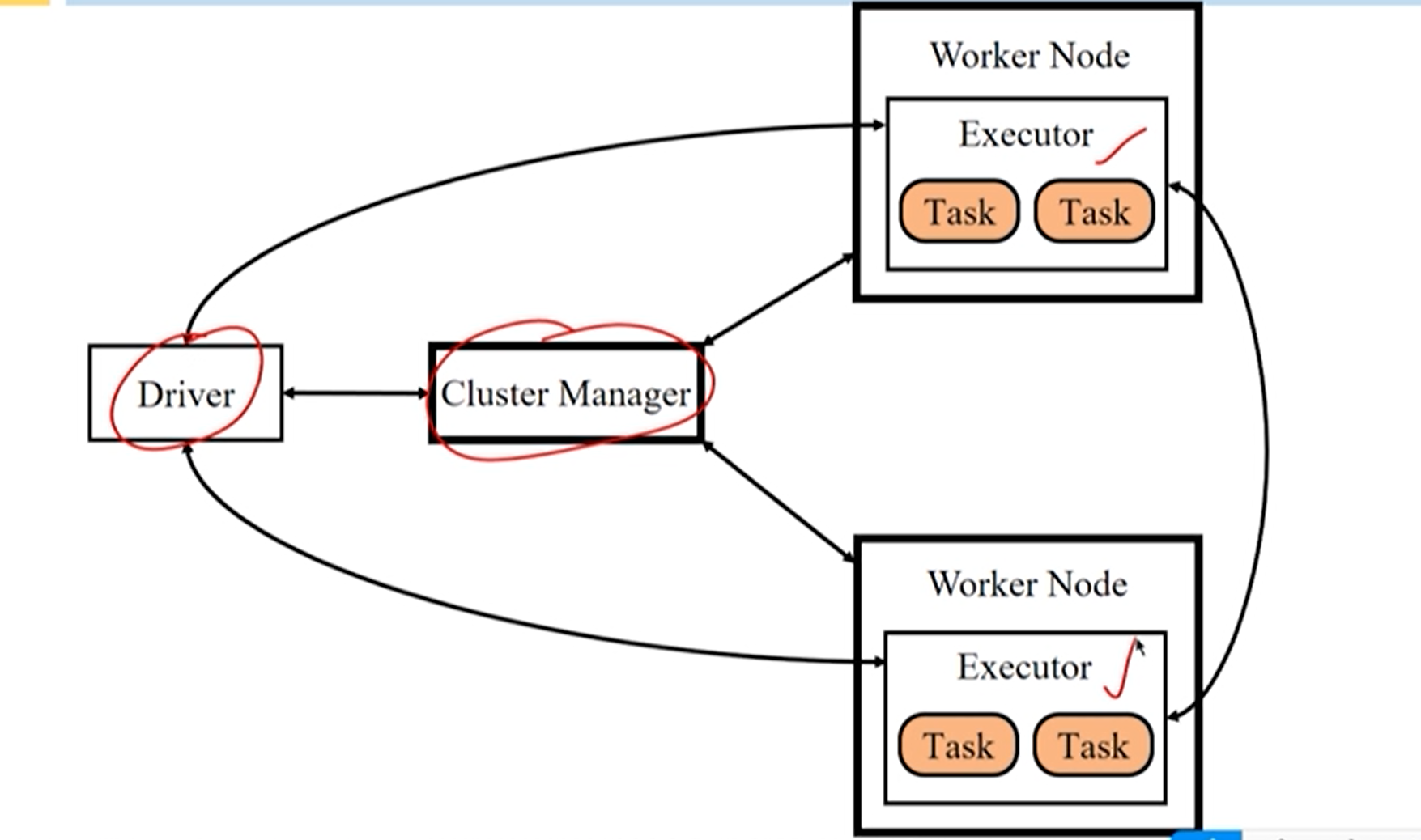
**Cluster Manager (Cluster Manager): **Responsável por gerenciar os recursos de todo o sistema e monitorar os nós de trabalho.
- No modo Standalone (sem usar outros sistemas de gerenciamento de recursos, como yarn), o gerenciador de cluster inclui Master e Worker.
- No modo Yarn, o gerenciador de cluster inclui Resource Manager e Node Manager.
Executor : responsável pela execução da tarefa
- Um executor é um processo em execução em um nó de trabalho , que inicia várias tarefas de thread ou TaskSets de grupo de threads para executar tarefas.
- Na implantação autônoma, o nome do processo Executor é CoarseGrainedExecutorBackend.
**Driver (Driver):** é responsável por iniciar o método principal do aplicativo e gerenciar o funcionamento do trabalho.
A arquitetura Spark realiza a separação de gerenciamento de recursos e gerenciamento de tarefas .
- O Cluster Manager é responsável pelo gerenciamento de recursos do cluster.
- O motorista é responsável pelo gerenciamento do trabalho.
Diagrama de arquitetura independente
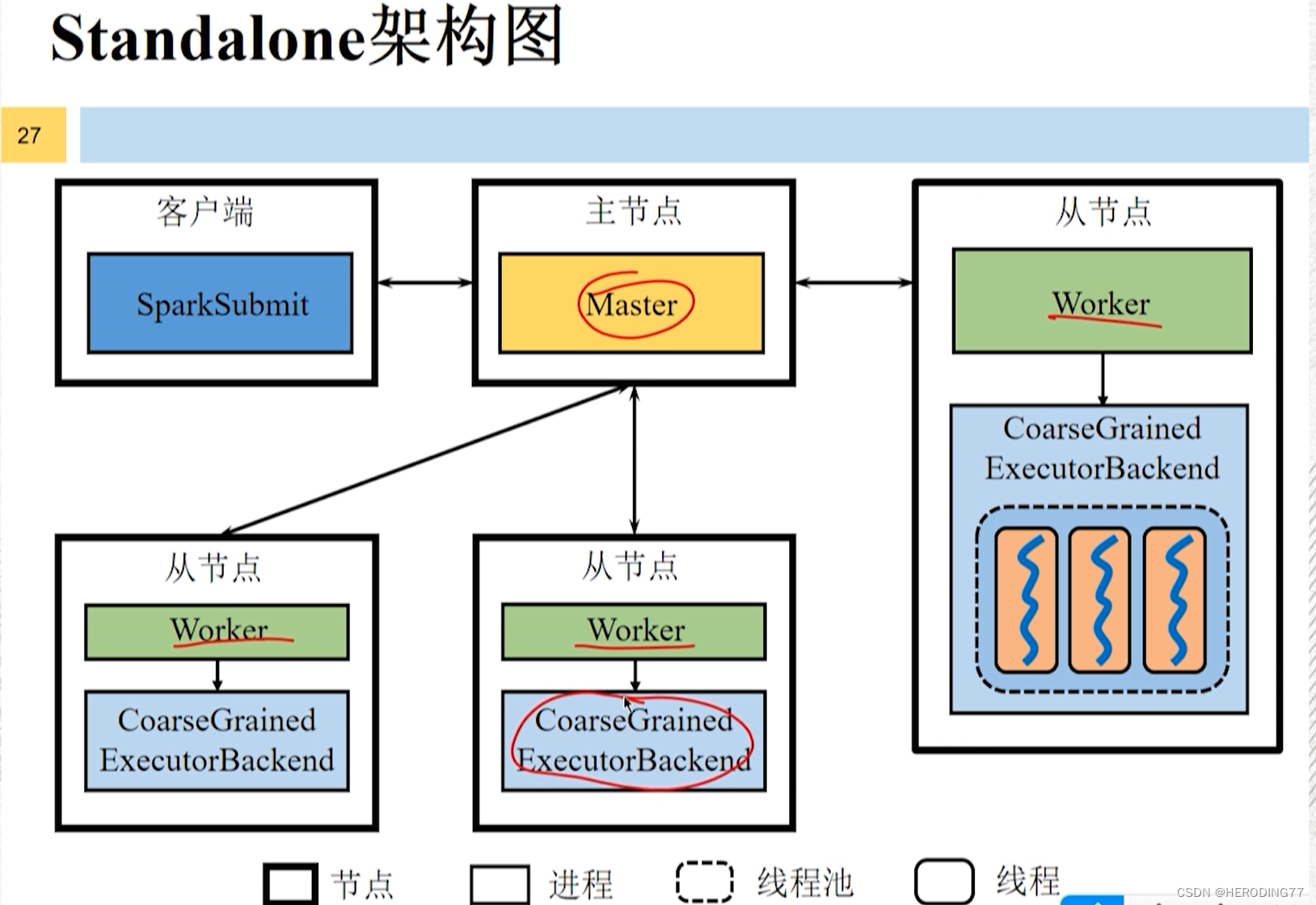

Como o Driver se manifesta?
Logicamente, os Drivers são independentes dos nós mestres, nós escravos e clientes, mas existirão dependendo de como o aplicativo é implantado.
- Implantação do cliente: existe no mesmo processo (SparkSubmit) que o cliente.
- Implantação de cluster: o sistema iniciará um processo chamado DriverWrapper como o driver por um trabalhador.
Os clientes podem escolher a implantação de cliente ou cluster ao enviar aplicativos.

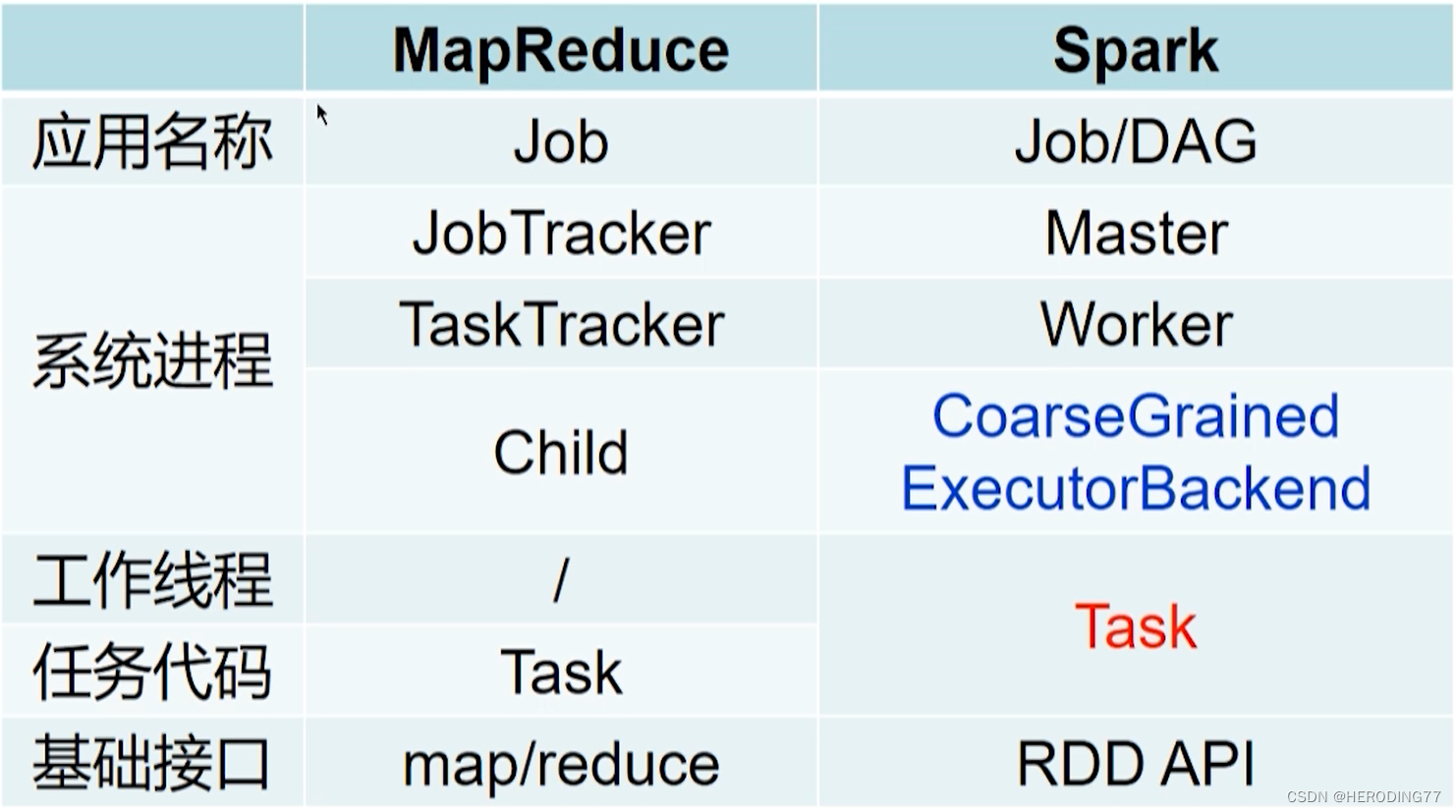
Spark VS Hadoop
4.2.2 Fluxograma de execução do aplicativo
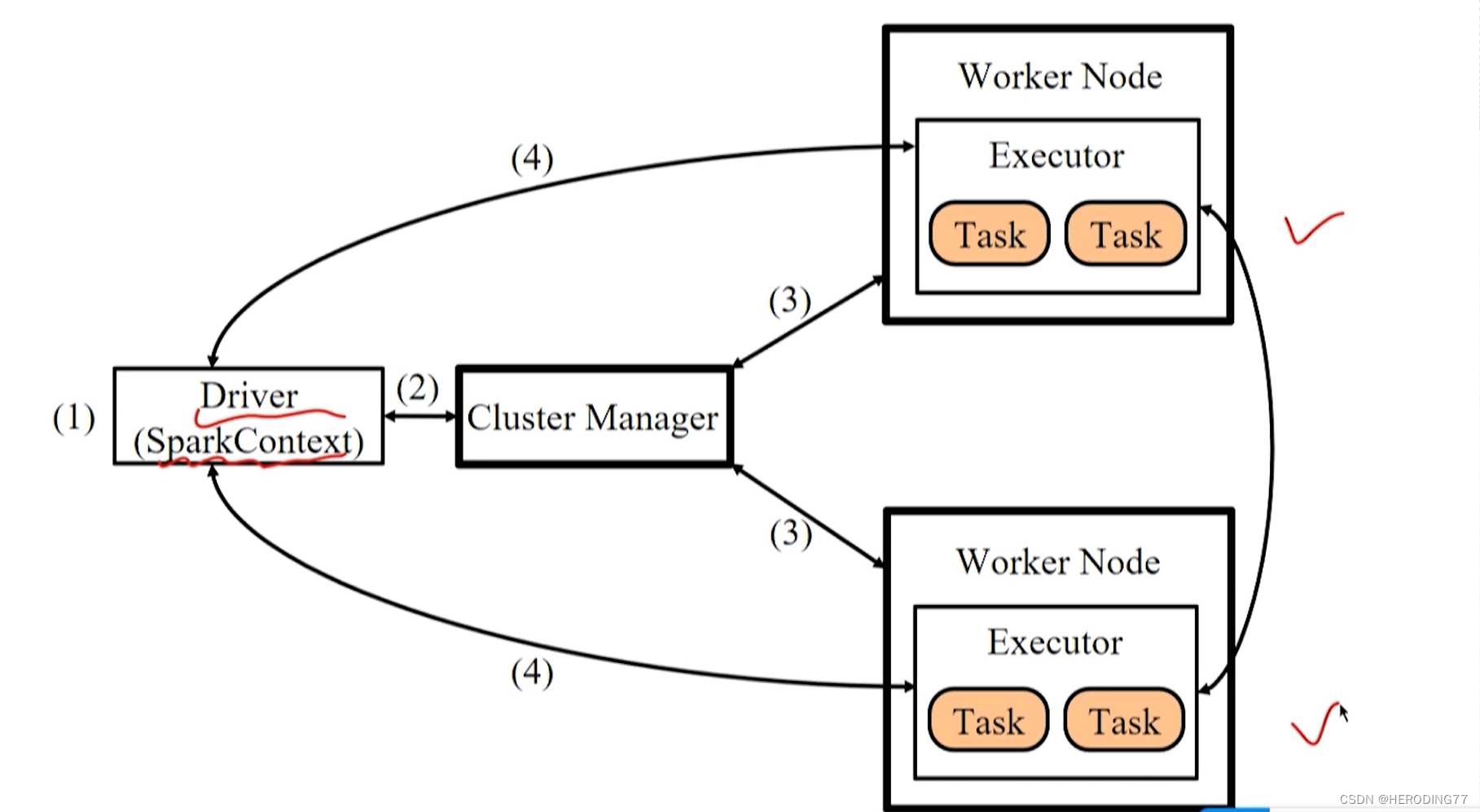
- Inicie o Driver, o modo Client inicia diretamente no cliente e registra com o Master; o modo de implantação Cluster submete a aplicação ao Master, e o Master especifica o Worker para iniciar o processo do Driver (DriverWapper).
- Construa o ambiente operacional básico, crie o SparkContext pelo Driver, solicite recursos do Cluster Manager e atribua e monitore tarefas pelo Driver.
- O Cluster Manager notifica os nós do trabalhador para iniciar o processo Executor e o multithreading interno funciona.
- Executor registra com Driver.
- SparkContext constrói DAG para dividir tarefas e entregá-las a threads no Executor para executar tarefas.
4.3 Princípio de funcionamento
4.3.1 Divisão de Etapas
dependências RDD
- Dependência estreita: as partições do RDD pai e as partições do RDD filho estão em um relacionamento um-para-um ou muitos-para-um.
- Ampla dependência: um relacionamento um-para-muitos entre uma partição do RDD pai e uma partição do RDD filho.
Método de divisão de palco
- Análise reversa no DAG, desconecte ao encontrar dependências amplas.
- Quando dependências estreitas são encontradas, o RDD atual é adicionado ao Palco.
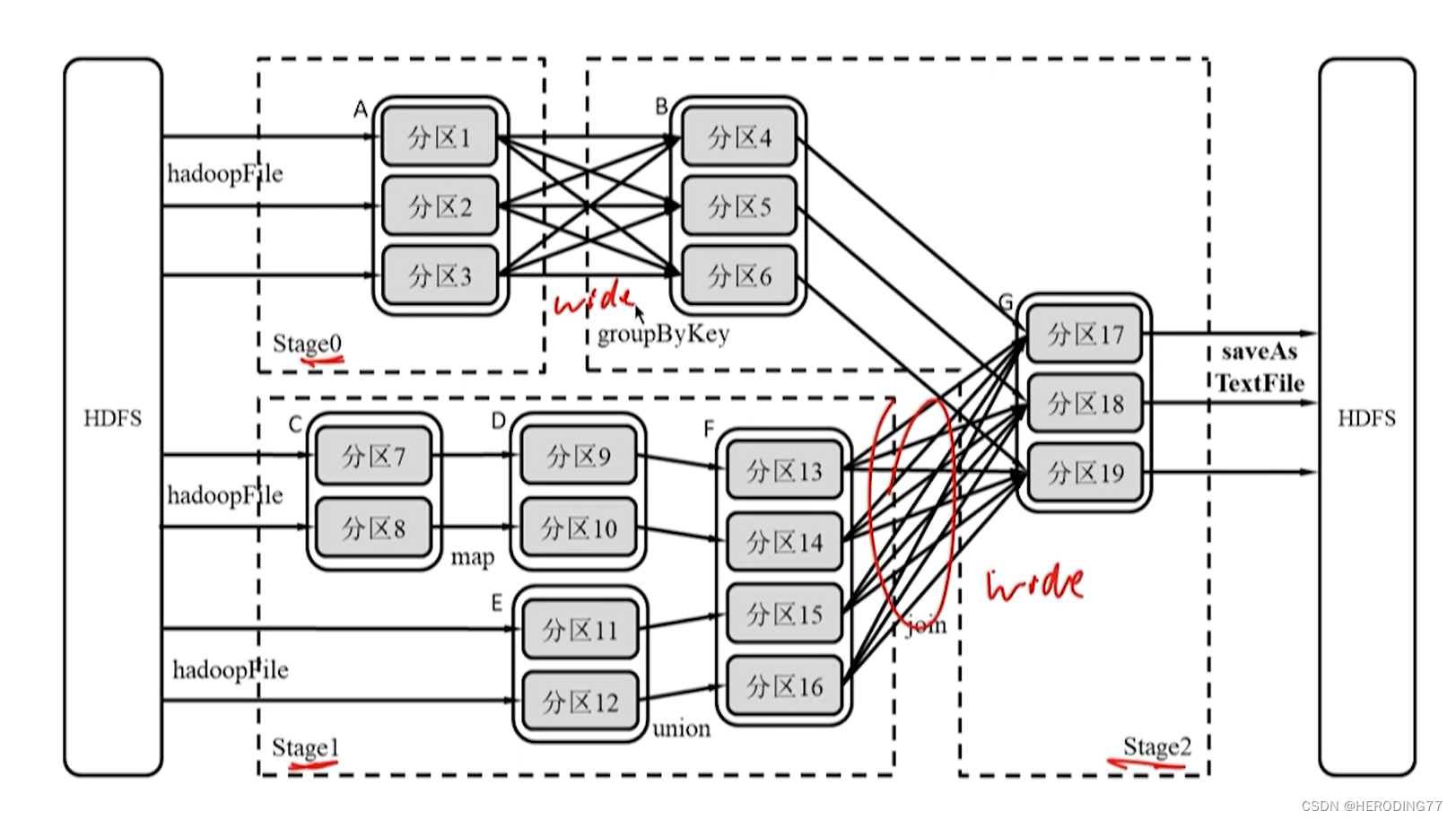
Divisão de palco com base no operador DAG

tipo de palco
-
ShuffleMapStage
- Entrada: Pode ser obtido de dados externos ou pode ser a saída de outro ShuffleMapStage.
- Saída: Considere Shuffle como a saída, como o início de outro Estágio.
- Características: Não é a etapa final, a saída deve passar pelo processo Shuffle e ser ingressada como uma etapa subseqüente, não existindo necessariamente em cada DAG.
-
Estágio de Resultados
- Entrada: Pode ser obtido de dados externos ou pode ser a saída de outro ShuffleMapStage.
- Saída: deve produzir um resultado ou armazená-lo.
- Características: É a etapa final, que deve ser incluída em um DAG.
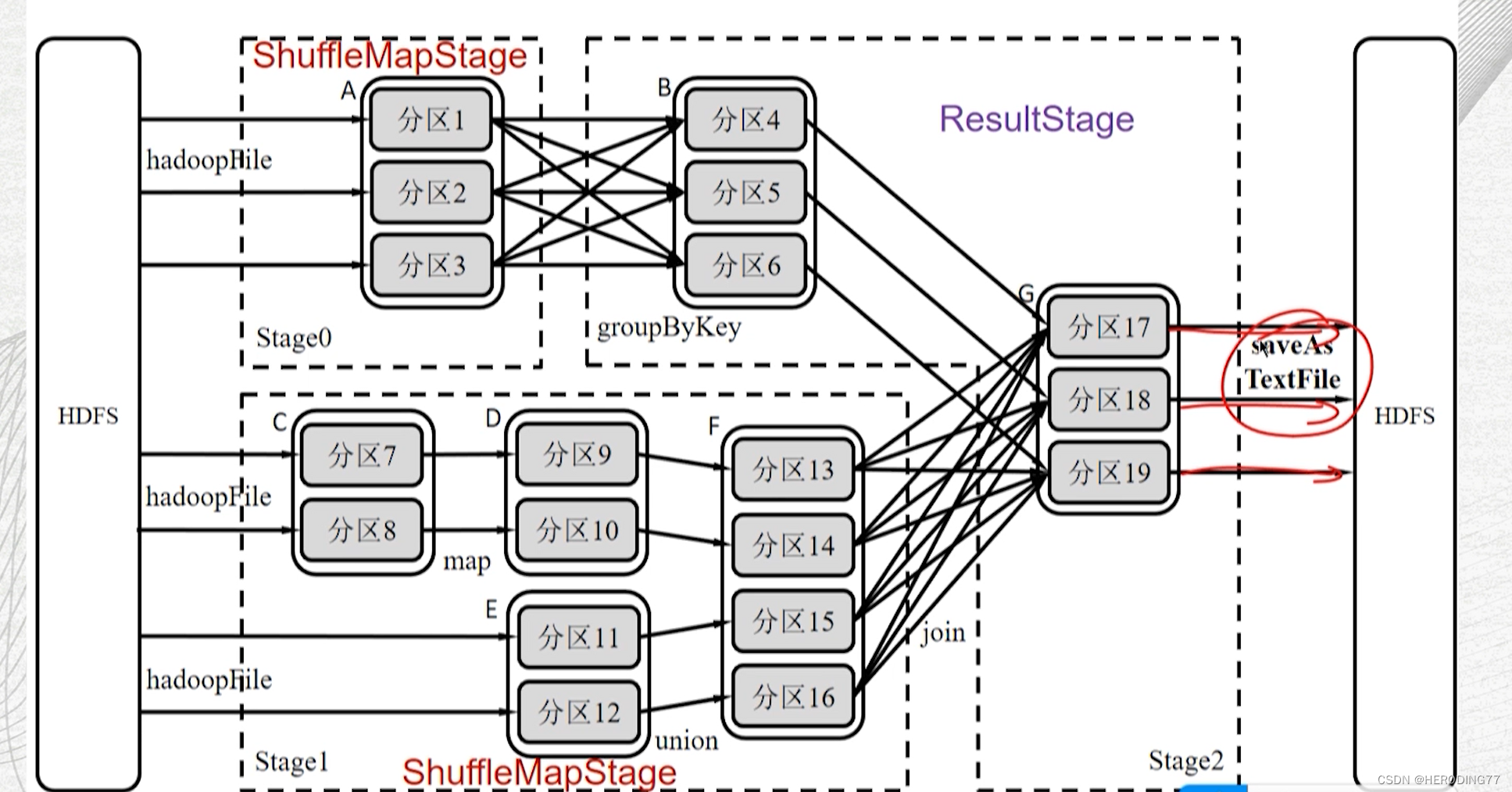
4.3.2 Transmissão de dados internos do palco
Todas as dependências são dependências estreitas , que podem implementar pipeline (pipeline) para transmissão de dados.
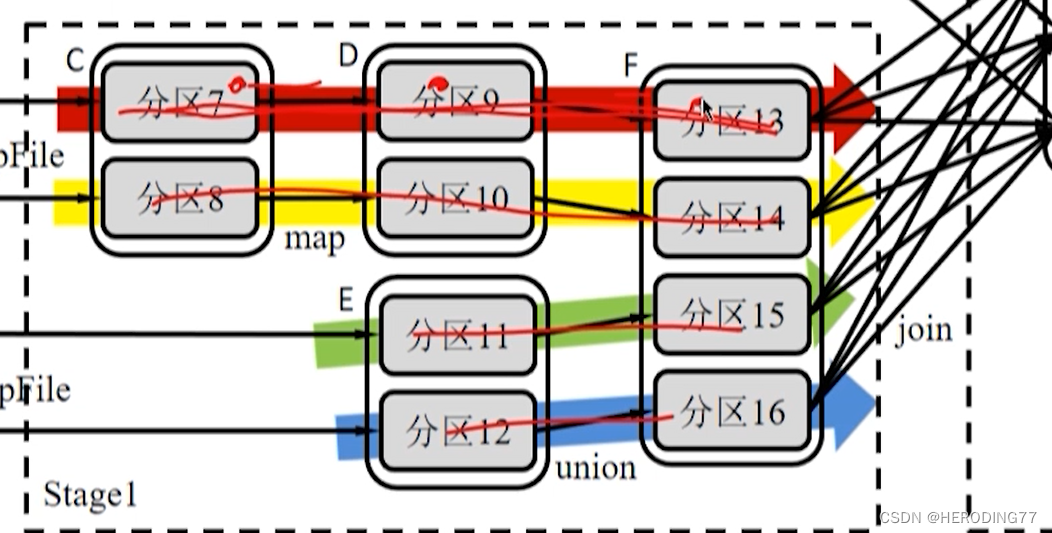
Pipeline é um método sem bloqueio, enquanto Shuffle é um método de bloqueio.
ShuffleMapTask vs ResultTask
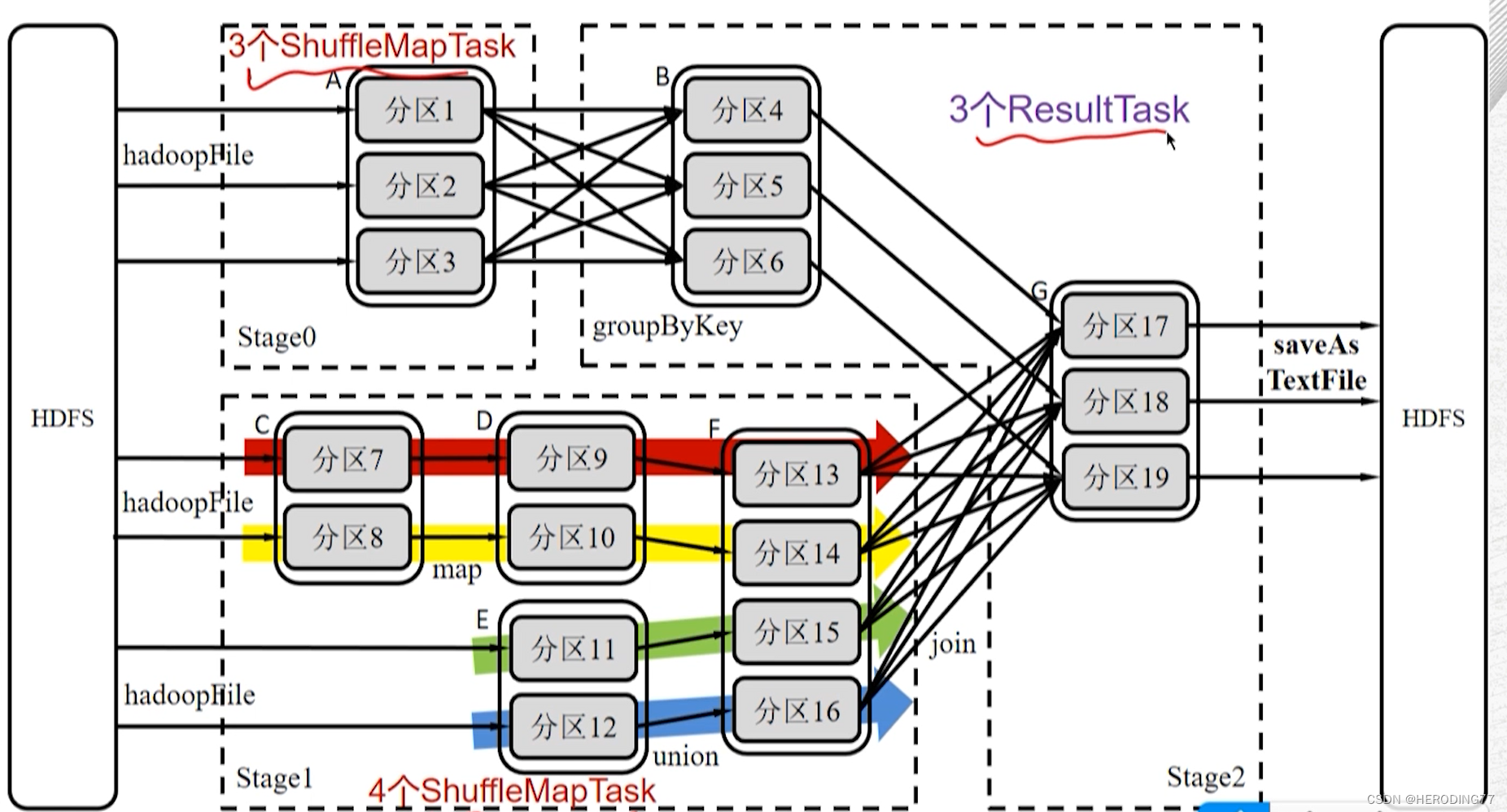
Um total de 10 tarefas são necessárias.
4.3.3 Transmissão de dados entre estágios
Todas as dependências são amplas e só podem ser executadas pelo Shuffle.
O Shuffle ocorre entre dois ShuffleMapStage ou entre ShuffleMapStage e ResultStage. Da perspectiva de Task, o processo é representado como transmissão de dados entre dois conjuntos de ShuffleMapTasks ou entre um conjunto de ShuffleMapTasks e um conjunto de ResultTasks.
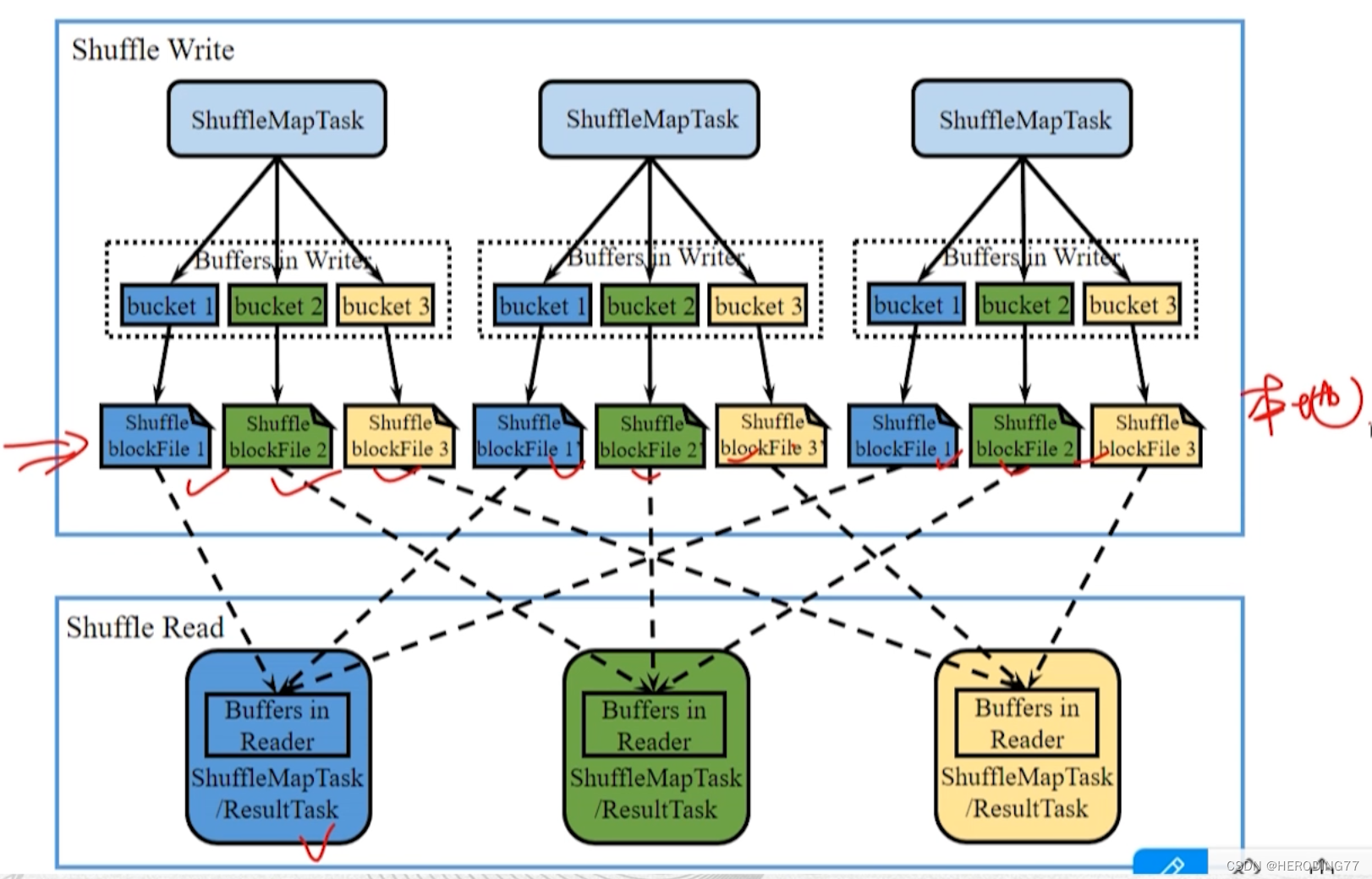
- Na fase Shuffle Write, ShuffleMapTask precisa dividir os registros RDD de saída em baldes correspondentes de acordo com a função de partição e materializá-los no disco local para gerar um ShuffleblockFile, que pode ser obtido na fase Shuffle Read.
- Na fase Shuffle Read, ShuffleMapTask ou ResultTask lê o ShuffleblockFile correspondente de acordo com a função de partição, armazena-o no buffer e executa cálculos subsequentes.
4.3.4 Aplicações e operações
Aplicativo: aplicativo Spark escrito pelo usuário
Job: Um Job contém vários RDDs e as operações de conversão aplicadas aos RDDs correspondentes e, finalmente, são todas ações.

Estágio: Um Job é dividido em vários grupos de Tarefas (Estágios), também conhecidos como TaskSets.
- A unidade básica de agendamento de um Trabalho.
- Representa um conjunto de tarefas associadas entre si e sem dependências do Shuffle.
Tarefa: Uma unidade de trabalho em execução em um Executor.


4.4 Mecanismo de tolerância a falhas
4.4.1 Persistência do RDD
tipo de falha
- Falha do mestre: o ZooKeeper configura vários mestres
- Falha do trabalhador
- Falha do executor
- Falha do driver: reinicialização
Mecanismo de armazenamento RDD
-
Quando o RDD atingir o limite do espaço de armazenamento correspondente, o Spark usará o algoritmo de substituição para liberar parte do espaço de memória do RDD.
-
Sem declaração, o RDD será descartado diretamente.
-
RDD fornece interface de persistência (cache)
- Persist(StorageLevel): Aceita o tipo de armazenamento e pode configurar vários níveis. Após persistência, será mantido no nó de trabalho e reutilizado por ações subsequentes.
- Cache(): Equivalente a Cache(MEMORY_ONLY)



4.4.2 Recuperação de falhas
Mecanismo de linhagem

A parte vermelha é perdida e a parte roxa precisa ser recalculada.
- Recalcule as partições perdidas.
- O processo de recálculo pode ser paralelizado em diferentes nós.
Comparação com Recuperação de Banco de Dados
- RDD Lineage: registra operações de granulação grossa
- Replicação ou registro de dados: registre operações refinadas
4.4.3 Pontos de Verificação
Inadequações do mecanismo acima mencionado:
- A linhagem pode ser muito longa.
- Os RDDs são persistidos nos discos das máquinas do cluster, o que não é totalmente confiável.
O checkpointing grava RDDs em um sistema de arquivos distribuído externo confiável, como o HDFS. No nível de implementação, escrever pontos de verificação é um trabalho independente, que é executado após a conclusão do trabalho do usuário.
4.5 Exemplo de programação
4.5.1 Estatísticas de frequência de palavras

Otimização

O MapReduce exige que os usuários personalizem o método Combine, enquanto o Spark possui um mecanismo de combinação integrado, que simplifica a programação do usuário.
4.5.2 Junção natural e otimização de tabelas relacionais
A conexão de tabela no Spark encontra o problema de tabelas grandes e pequenas:
Como a sobrecarga do Shuffle é muito alta, a mesa pequena é transmitida para evitar o Shuffle da mesa grande.
4.5.3 Classificação de links de páginas da Web
Pertence ao processo de implementação iterativa de Job, mas o todo é um Application.
A transmissão de dados entre as iterações do MapReduce precisa ser concluída lendo e gravando o HDFS, enquanto os dados RDD entre as iterações do Spark podem residir diretamente na memória.
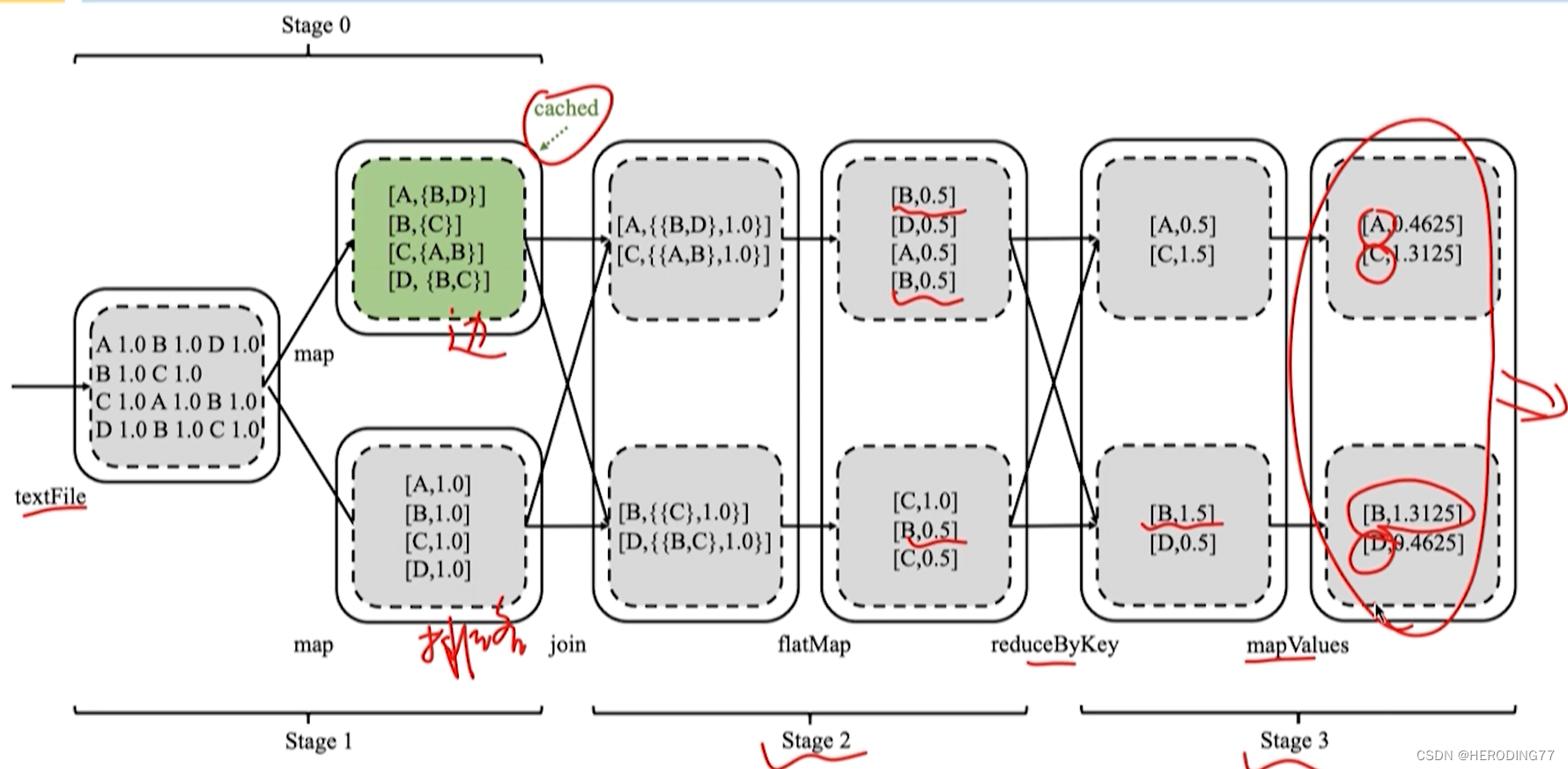

4.5.4 Agrupamento de K-Means
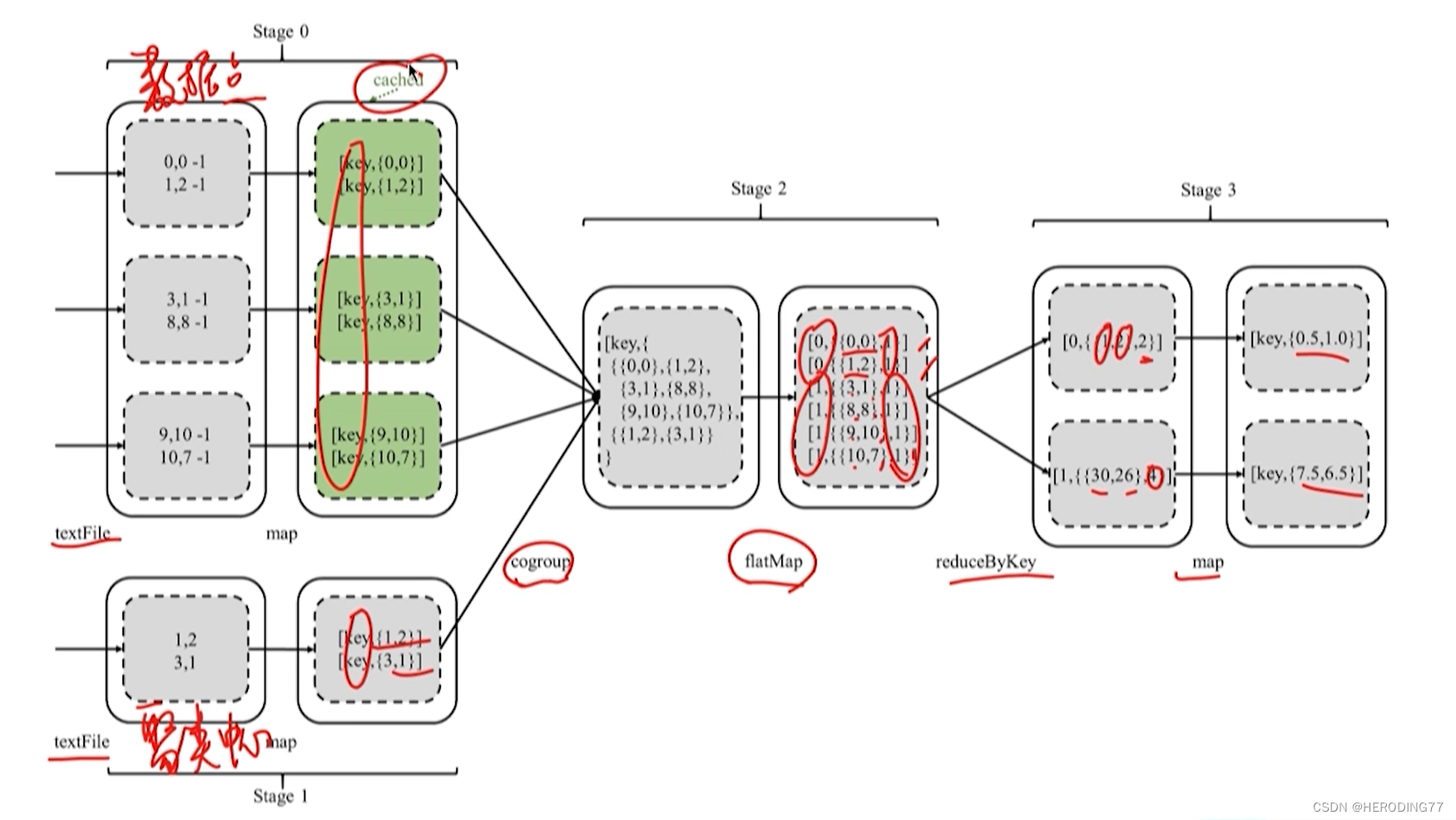
Recursos: Cada ponto de dados é calculado com todos os centros de cluster.
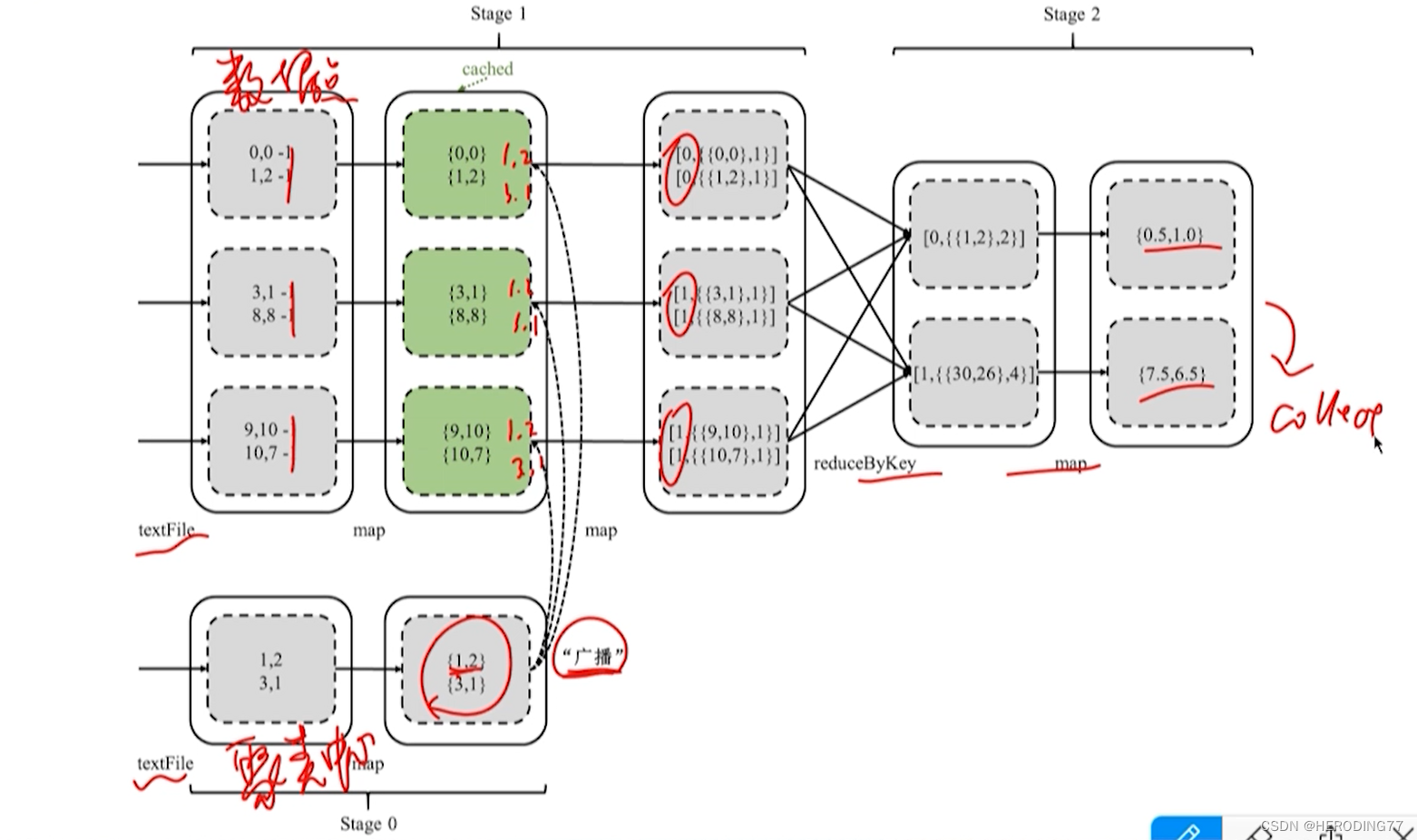
Otimizado na forma de transmissão, reduzindo o número de shuffle.
4.5.5 Pontos de Verificação
Tome o PageRank como exemplo, verificando a classificação das páginas da web a cada cinco iterações.
Cache RDDs de PageRanks antes de escrever pontos de verificação.
- Escrever um ponto de verificação é um trabalho independente, e o RDD do ponto de verificação a ser gravado é primeiro armazenado em cache para evitar cálculo duplo.

Pergunta
- Por que os RDDs do Spark são projetados para serem imutáveis?
Um exemplo de troca de espaço por tempo.
- Por que há uma distinção entre os modos cliente e cluster?
Atender às necessidades de depuração e produção.
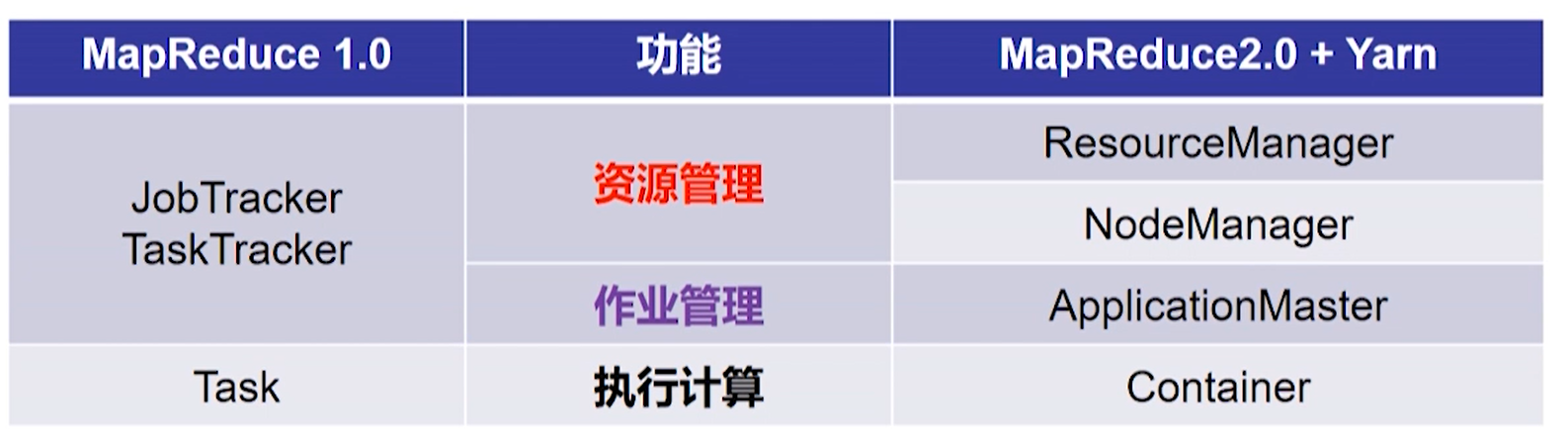
Capítulo 5 Fio do Sistema de Gerenciamento de Recursos
5.1 Pensamento do projeto
5.1.1 Gestão de Trabalhos e Recursos
Defeitos de MapReduce1.0
-
O gerenciamento de recursos está fortemente associado aos trabalhos
- O gerenciamento de recursos não é apenas necessário para sistemas MapReduce, mas é comum.
-
Controle e gerenciamento de operações altamente centralizados
- O JobTracker tem uma grande sobrecarga de memória.
- O número de jobs executados ao mesmo tempo aumenta e a frequência de comunicação entre os JobTrackers aumenta, resultando em instabilidade do processo.
5.1.2 Plataforma e Estrutura
sistema
- Plataforma: um sistema com a função de fornecer recursos
- Framework: o sistema que roda na plataforma
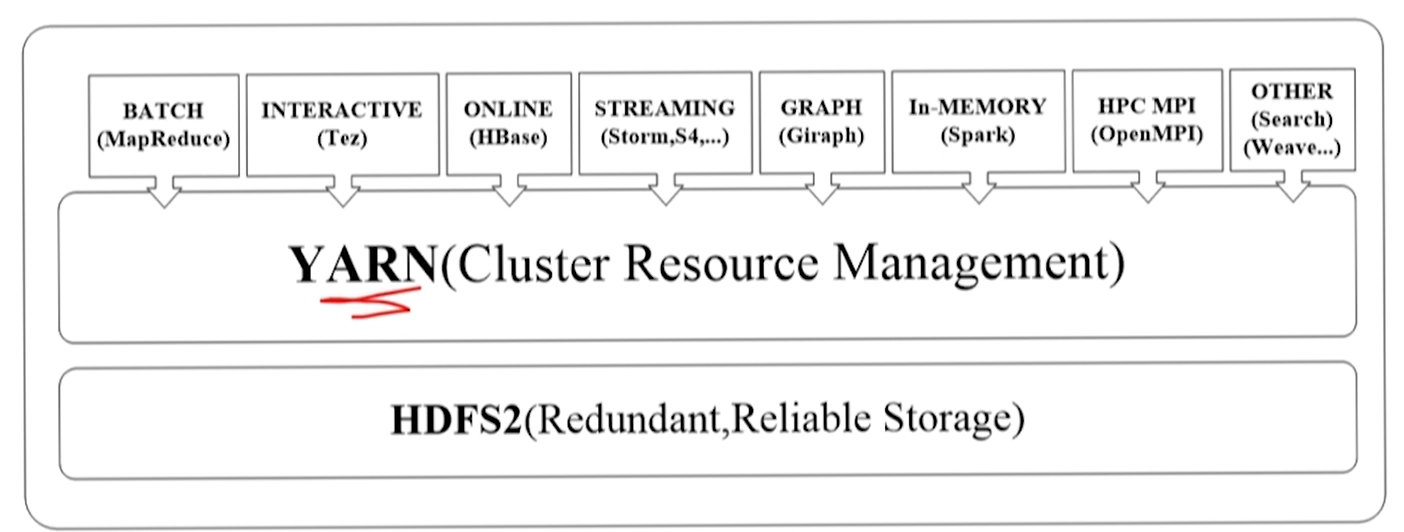
Aplicação de fios
A granularidade do gerenciamento do Yarn é a aplicação
- mas não necessariamente a aplicação no quadro
- A estrutura em execução na plataforma Yarn pode mapear aplicativos ou trabalhos para aplicativos Yarn
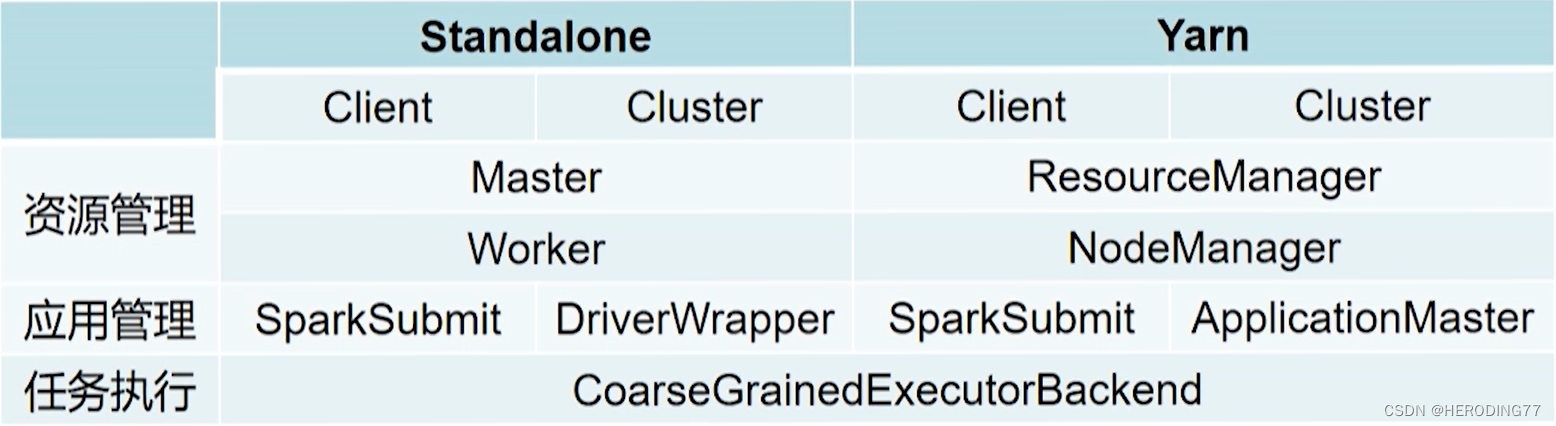
| Fio | Fagulha | MapReduce |
|---|---|---|
| aplicativo | aplicativo | Trabalho |
5.2 Arquitetura
5.2.1 Diagrama de Arquitetura
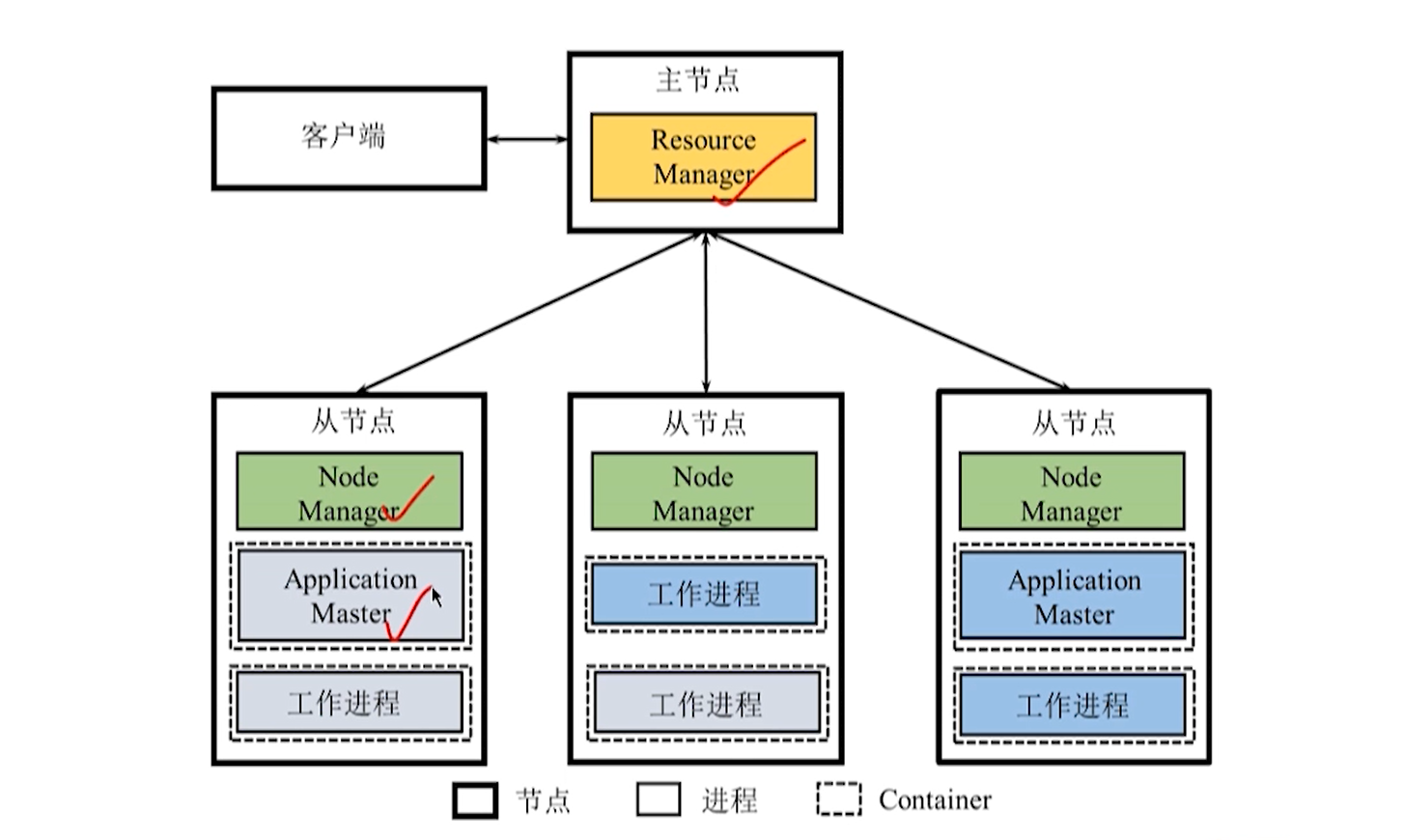
Gerente de Recursos
**Gerente de Recursos:** Responsável pelo gerenciamento de recursos e alocação de todo o sistema
-
Agendador de Recursos (Resource Scheduler): aloca o Container e executa o agendamento de recursos.
-
Application Manager (Gerenciador de aplicativos): gerencia todos os aplicativos em execução no sistema.
- Submissão da aplicação
- Negociar recursos com o coordenador para iniciar o ApplicationMaster
- Monitore o status de execução do ApplicationMaster
**NodeManager: **Responsável por cada recurso de nó e gerenciamento de tarefas
- Relate regularmente o uso de recursos do nó e o status de execução do contêiner ao RM.
- Aceita e processa várias solicitações de AM, como início/parada de contêiner.
**ApplicationMaster:** quando um usuário envia um aplicativo de estrutura baseado na plataforma Yarn, o Yarn inicia um AM para gerenciar o aplicativo.

Contêiner: A representação abstrata de recursos, incluindo CPU, memória e outros recursos, é uma unidade dinâmica de divisão de recursos.
Quando AM se aplica a recursos de RM, RM retorna os recursos representados por Container para AM.
Vantagens do Fio
- O gerenciamento de recursos é separado do gerenciamento de tarefas
- O Yarn é um sistema independente de gerenciamento de recursos. O MapReduce2.0 é responsável apenas pelo gerenciamento do trabalho como um sistema de computação.
5.2.2 Fluxo de execução do aplicativo
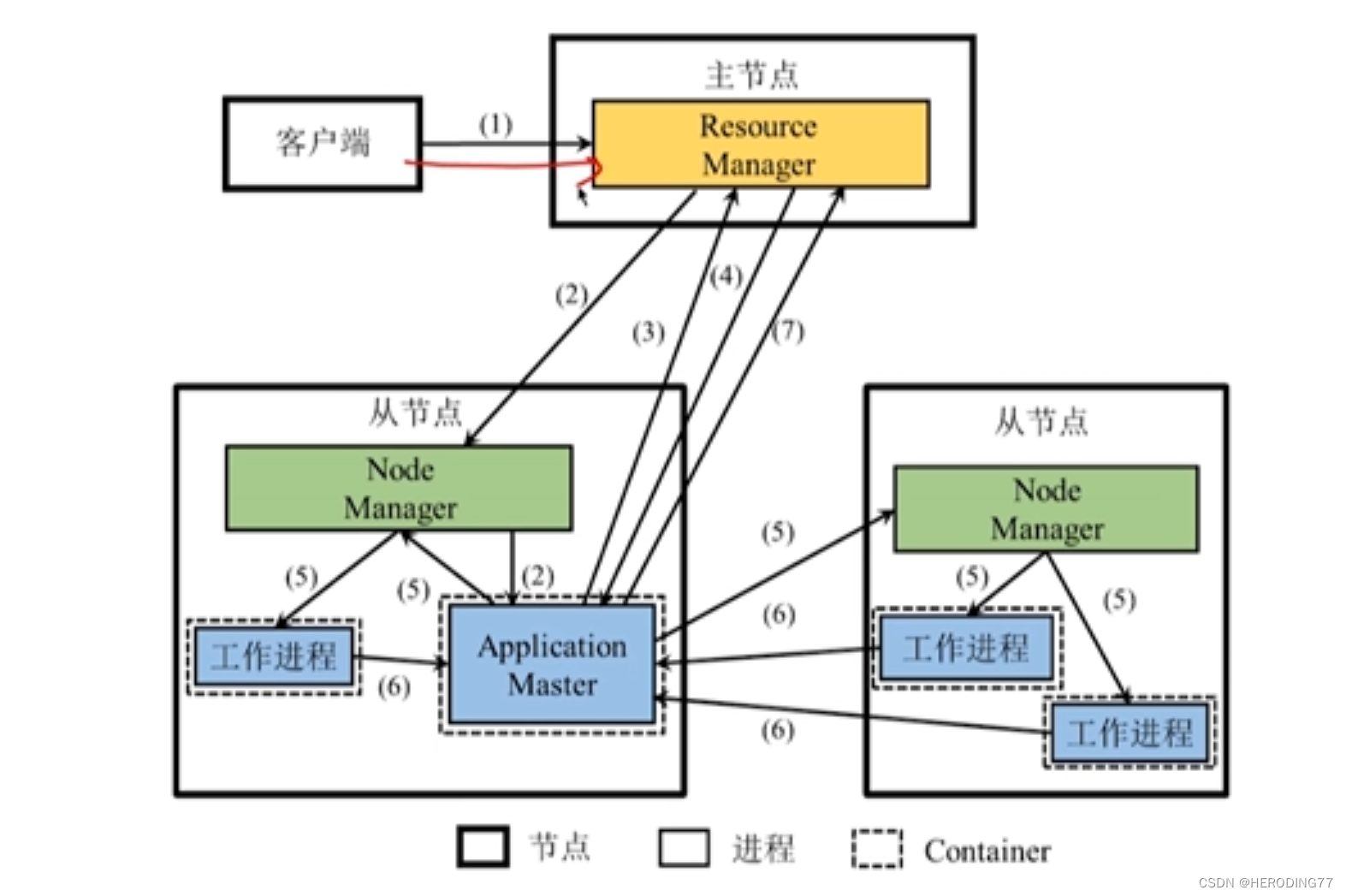
- Os usuários escrevem aplicativos e enviam aplicativos ao Yarn.
- O RM é responsável por receber e processar a requisição do cliente, tentando alocar o primeiro Container para o programa, e iniciar o AM no Container se a alocação for bem sucedida.
- O AM se registra com o RM e os clientes podem visualizar o uso de recursos do aplicativo por meio do RM. AM analisa o aplicativo em trabalhos e ainda o decompõe em várias tarefas e solicita recursos ao RM para iniciar essas tarefas.
- O RM aloca os recursos expressos na forma de Container para o AM aplicante . Os recursos solicitados pelo AM são alocados entre várias tarefas.
- Depois que o AM determina o esquema de alocação, ele se comunica com o NM correspondente e inicia o processo de trabalho correspondente no Container correspondente para executar a tarefa.
- Cada tarefa relata o status e o progresso para o AM, para que o AM possa entender o status de execução de cada tarefa em tempo real.
- Após o término da tarefa, AM libera recursos e faz logoff para RM para se fechar.
5.3 Princípio de funcionamento
5.3.1 Plataforma única e vários frameworks

5.3.2 Alocação de recursos da plataforma
O agendador no RM mantém uma ou mais filas de aplicativos . Cada fila possui determinados recursos e a mesma fila compartilha recursos.
O objeto de alocação de recursos do Yarn é o aplicativo .Cada aplicativo enviado pelo usuário será alocado para uma das filas, e a fila determina o limite máximo de recursos que o aplicativo pode usar.
estratégia de alocação de recursos
- FIFO
Primeiro a chegar primeiro a ser servido, longa espera.
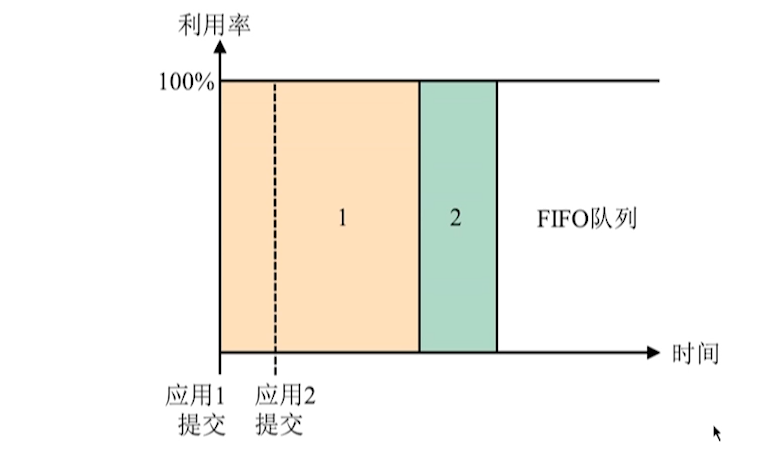
- Agendador de capacidade
Uma fila hierárquica é mantida para evitar a situação em que um aplicativo de execução longa monopoliza recursos, mas haverá problemas de recursos ociosos causando desperdício.

- Agendador de Feiras
Compartilhamento de recursos entre filas.

5.4 Mecanismo de tolerância a falhas
-
Falha do Gerenciador de Recursos
- Restaurar informações de estado do armazenamento persistente
- A implantação de vários RMs é coordenada pelo ZooKeeper para garantir a alta disponibilidade dos RMs.
-
Falha no gerenciador de nós
- AM reaplica a RM para obter recursos para executar essas tarefas
- RM atribuirá contêineres de outros nós para executar essas tarefas
- O NM se recupera da falha e se registra novamente com o RM para redefinir o estado local.
-
Falha no mestre do aplicativo: reinicialização
-
Falha na tarefa no contêiner: reinicie
5.5 Exemplo de programação
5.5.1 A plataforma Yarn executa o framework MapReduce


5.5.2 Execute o framework Spark na plataforma Yarn
Modo Yarn-Cluster
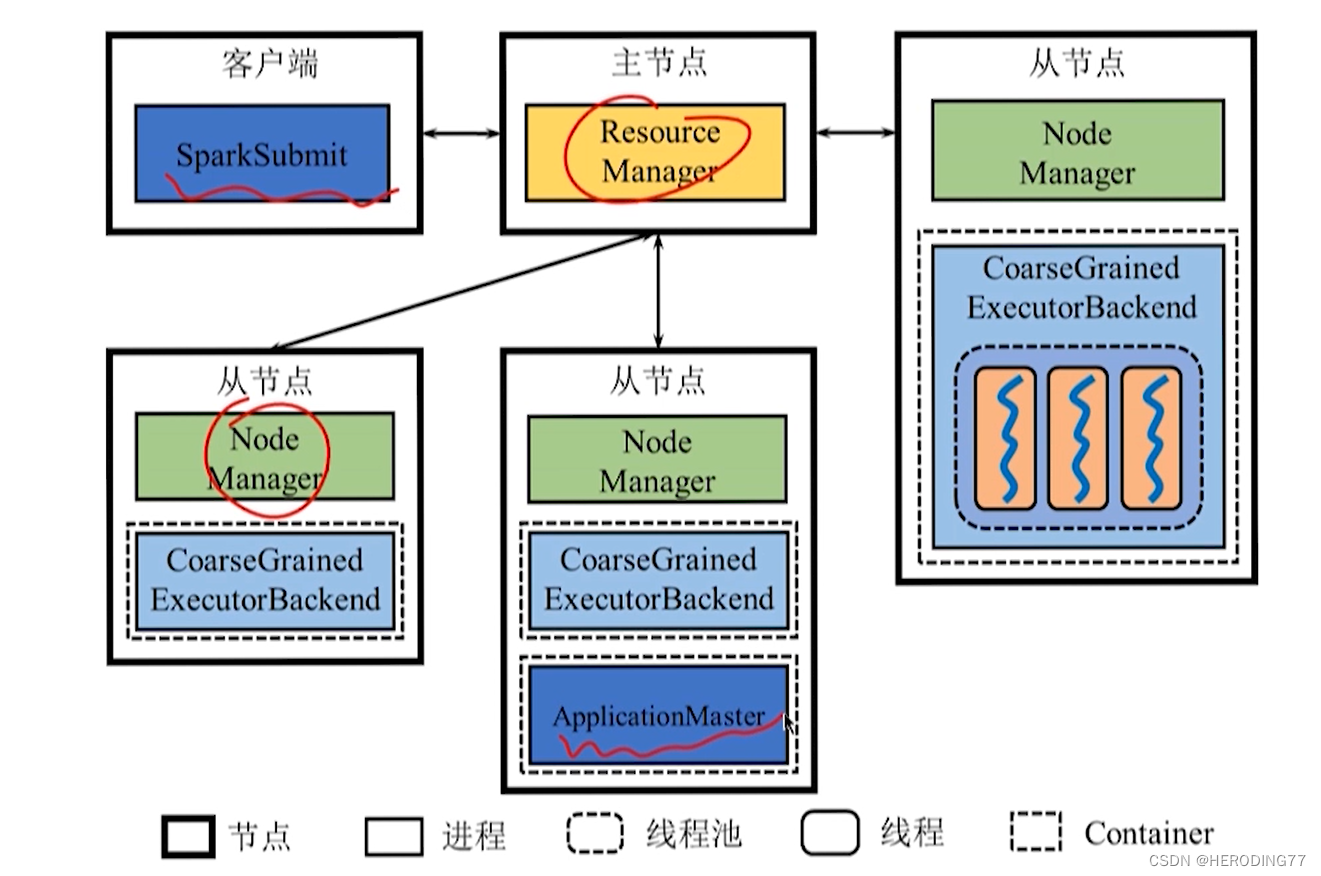
modo Yarn-client

Yarn-client vs Yarn-cluster
Fio-cliente
- Driver: No processo iniciado pelo cliente
- Aplicativo: nomeado ExecutorLauncher para solicitar recursos do RM, usar recursos do contêiner para vincular outros NMs e, em seguida, iniciar o executor
Yarn-Cluster
- Driver existe em um AM em NM.
Capítulo 6 Sistema de Serviço de Coordenação ZooKeeper
6.1 Pensamento do projeto
**Objetivo do projeto: **Encapsular serviços complexos de consistência distribuída em um conjunto eficiente e confiável de primitivos e fornecer aos usuários uma série de interfaces fáceis de usar.
**Como funciona:** Armazene metadados ou informações de configuração para coordenar os serviços.
6.1.1 Modelo de Dados
O ZooKeeper mantém uma estrutura hierárquica semelhante a um sistema de arquivos e o modelo de dados é uma árvore. Cada nó de dados é chamado de Znode e cada Znode contém informações.
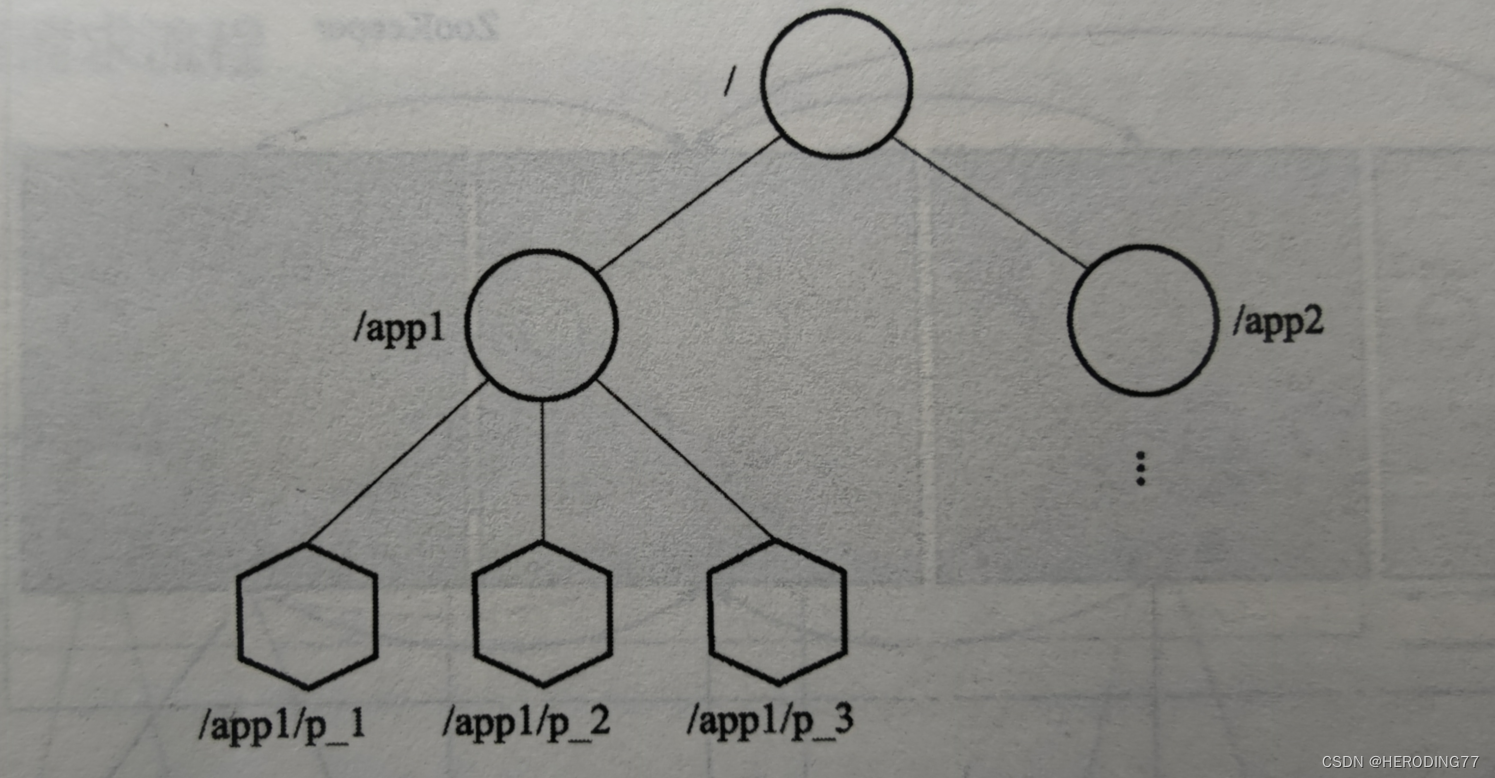
Znode
- Znode persistente: a menos que seja removido ativamente, sempre existirá no sistema ZooKeeper.
- Temporary Znode: O ciclo de vida está vinculado à sessão do cliente.
O ZooKeeper permite que os usuários adicionem ordem ao Znode, conforme mostrado em /app1/p1_1 na figura.
6.1.2 Primitivas de operação
- Criar
- Excluir
- Existe
- Obter dados: lê dados de um Znode.
- Definir dados: gravar dados de um Znode.
- ter filhos
- Sync: Aguardando sincronização de dados.
6.2 Arquitetura

Um nó do ZooKeeper consiste em um conjunto de servidores para armazenar dados do ZooKeeper, e cada servidor mantém um backup dos dados estruturados em árvore. Tipo de servidor:
**Líder: **Determinado pelo processo de seleção do líder (algoritmo de seleção principal), e fornece serviços de leitura e gravação diretamente para o cliente.
**Follower:** só pode fornecer serviços de leitura, e as operações de gravação enviadas pelo cliente ao seguidor devem ser encaminhadas ao líder.
**Observador: **O papel é semelhante ao de um seguidor, a diferença é que ele não participa do processo de eleição de um líder, sendo esse papel opcional.
O cliente é conectado a um servidor por meio de uma sessão e a conexão é mantida por heartbeat . Os clientes podem receber notificações de eventos Watch do servidor. O evento Watch significa que o cliente pode definir um Watcher em um determinado Znode. Pode retornar notificações de alterações no servidor.
6.3 Princípio de funcionamento
ZooKeeper é um sistema de armazenamento de dados leve que mantém várias cópias de dados.
O ZooKeeper precisa garantir a consistência das cópias entre cada nó, por isso é necessário determinar o líder.
6.3.1 Eleição do Líder
O protocolo de consenso distribuído é usado para resolver o problema de como um sistema distribuído chega a um consenso sobre uma proposta, e o paxos é um dos algoritmos clássicos para implementar esse protocolo. A ideia central é que alguns nodos emitam propostas e, em seguida, outros nodos votem e, finalmente, todos os nodos cheguem a um consenso.
6.3.2 Processo de solicitação de leitura e gravação
6.3.2.1 Solicitação de leitura

- O cliente estabelece uma conexão com um servidor e inicia uma solicitação de gravação de dados.
- Se o servidor for um seguidor ou observador, a solicitação de gravação é encaminhada ao líder, caso contrário, o líder a trata diretamente.
- Em teoria, o líder precisa encaminhar a solicitação de gravação para todos os nós do servidor até que todos os nós do servidor executem a operação de gravação com sucesso. A solicitação de gravação foi concluída. Na verdade, mais da metade das operações de gravação podem ser consideradas concluídas. Este processo é um processo de sincronização de dados, que requer o uso de um protocolo de consenso distribuído, no qual os dados que precisam ser sincronizados podem ser considerados como uma proposta.
- O servidor retorna as informações de gravação bem-sucedida para o cliente.
6.3.2.2 Solicitação de gravação
Quando o cliente retorna uma solicitação de gravação, seguidores, observadores e líderes podem responder à solicitação. Os dois primeiros podem não ser os últimos, então você pode chamar sync() para aguardar a sincronização de dados.
- O cliente se conecta a um servidor e inicia uma solicitação de sincronização ().
- Sincronização de dados com o líder se o servidor for um observador ou seguidor.
- O servidor retorna as últimas notícias sincronizadas para o cliente.
- O cliente lê os dados do servidor.
6.4 Mecanismo de tolerância a falhas
Falha do líder: reeleição.
Falha do seguidor ou do observador: não afeta o todo e sincroniza os dados do líder ou de outros nós durante a recuperação.
6.5 Exemplo típico
6.5.1 Serviço de nomes
Para representar vários recursos, é necessário criar um namespace, para que seja conveniente localizar os recursos necessários no namespace.
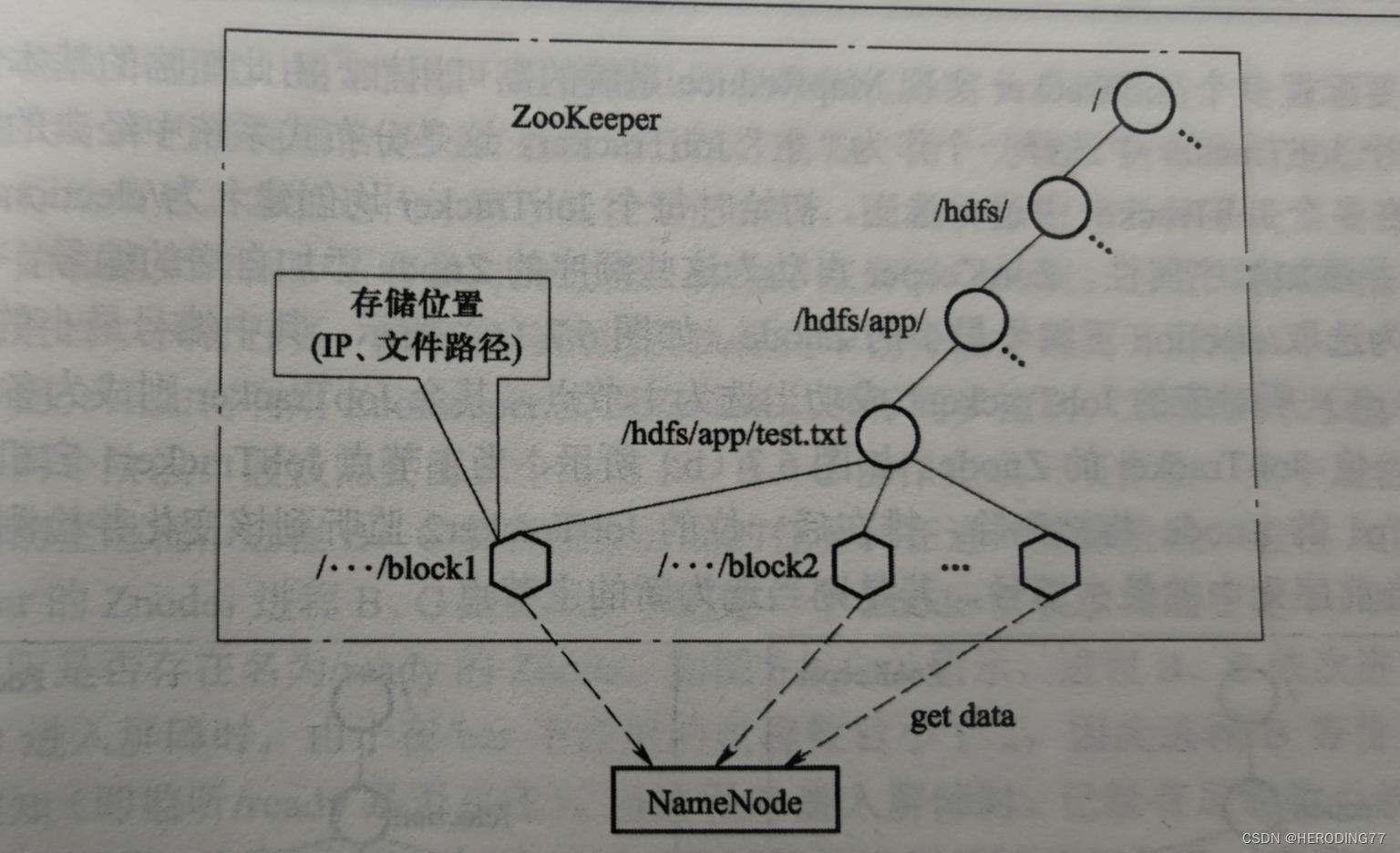
Conforme mostrado na figura, o usuário carrega um arquivo chamado "hdfs://app/test.txt".
6.5.2 Gerenciamento de Cluster
Para evitar falhas no nó escravo, o monitoramento do status do nó escravo e a escolha do nó mestre múltiplo são essenciais.
Monitoramento de status do nó escravo:
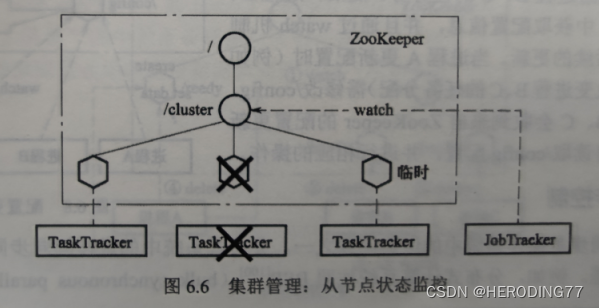
Ele é implementado criando um Znode temporário. Tomando MapReduce como exemplo, o TaskTracker começa a criar um Znode temporário em /cluster. Uma vez que o TaskTracker falha, a conexão com o TaskTracker é desconectada e o Znode é deletado.
Problema de eleição mestre
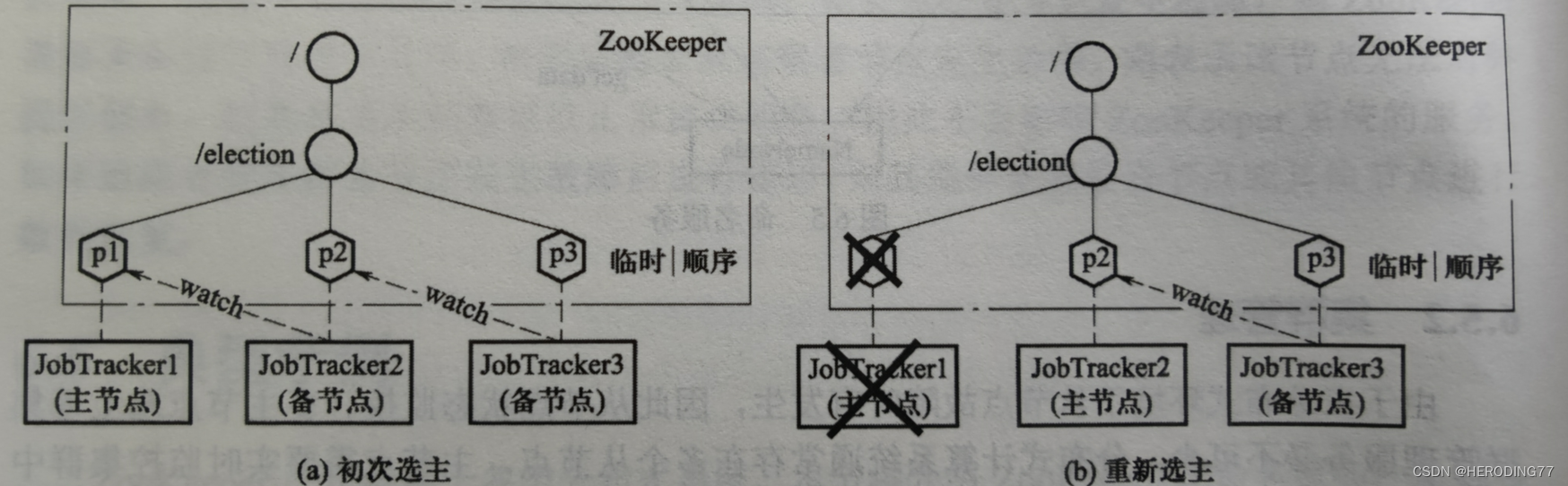
Para evitar que um único JobTracker tenha um único ponto de falha, vários JobTrackers precisam ser configurados para obter alta disponibilidade do sistema MapReduce. O nó mestre toma aquele com o subscrito Znode menor como o nó mestre e será transferido para o próximo em caso de inatividade.
6.5.3 Atualização de configuração
Os sistemas distribuídos geralmente precisam modificar dinamicamente a configuração durante a operação. Após o processo A criar a configuração, se os processos B e C precisarem usá-la, ele precisará monitorar continuamente a notificação de atualização de A. Uma vez atualizado, leia a configuração /config e execute as operações correspondentes.
6.5.4 Controle síncrono
Mecanismo de barreira dupla (para um conjunto de trabalhos iterativos)
- Uma pré-condição para um processo executar um cálculo iterativo é geralmente que todos os processos estejam prontos.
- O cálculo iterativo dessa rodada só pode ser considerado concluído após a execução das tarefas responsáveis por todos os processos participantes.
Capítulo 7 Tempestade do sistema de computação de fluxo
**MapReduce, Spark: **Dados estáticos
**Storm:** dados dinâmicos em tempo real (dados de streaming)
7.1 Pensamento de design
O sistema de computação de fluxo de tempestade processa dados na forma de fluxos.
7.1.1 Processamento contínuo
No processamento em lote, a tarefa é executada por um curto período de tempo e os dados são processados e encerrados.
A computação de fluxo precisa ser executada por um longo período de tempo e é teoricamente ilimitada. As tarefas de computação residem em nós de computação por um longo tempo e atualizam seu próprio status.
**Status:** Um tipo especial de dado que mantém parte dos resultados do cálculo (o status é mantido somente após o Storm).
7.1.2 Modelo de Dados
Storm trata os dados de streaming como uma sequência contínua e ilimitada de tuplas .
**Tupla:** Uma tupla corresponde a um registro e um registro contém vários campos.
7.1.3 Modelo de cálculo
Storm usa abstração de topologia para descrever o processo de computação, e a topologia é uma rede composta de spouts e bolts .
Uma topologia é logicamente um gráfico acíclico direcionado (DAG).
As arestas descrevem a direção na qual os dados fluem.
**Spout: **Fonte de dados de fluxo, responsável por ler continuamente os dados da fonte de dados e, em seguida, encapsula-los em tuplas e enviá-los para Bolt.
**Parafuso: **Descrição Visando o processo de conversão dos dados do stream, encapsula internamente a lógica de processamento da mensagem e é responsável por converter os dados do stream recebido em novos dados do stream (filtragem, agregação, consulta, etc.).
Os bolts na topologia são implementados fisicamente por várias tarefas.
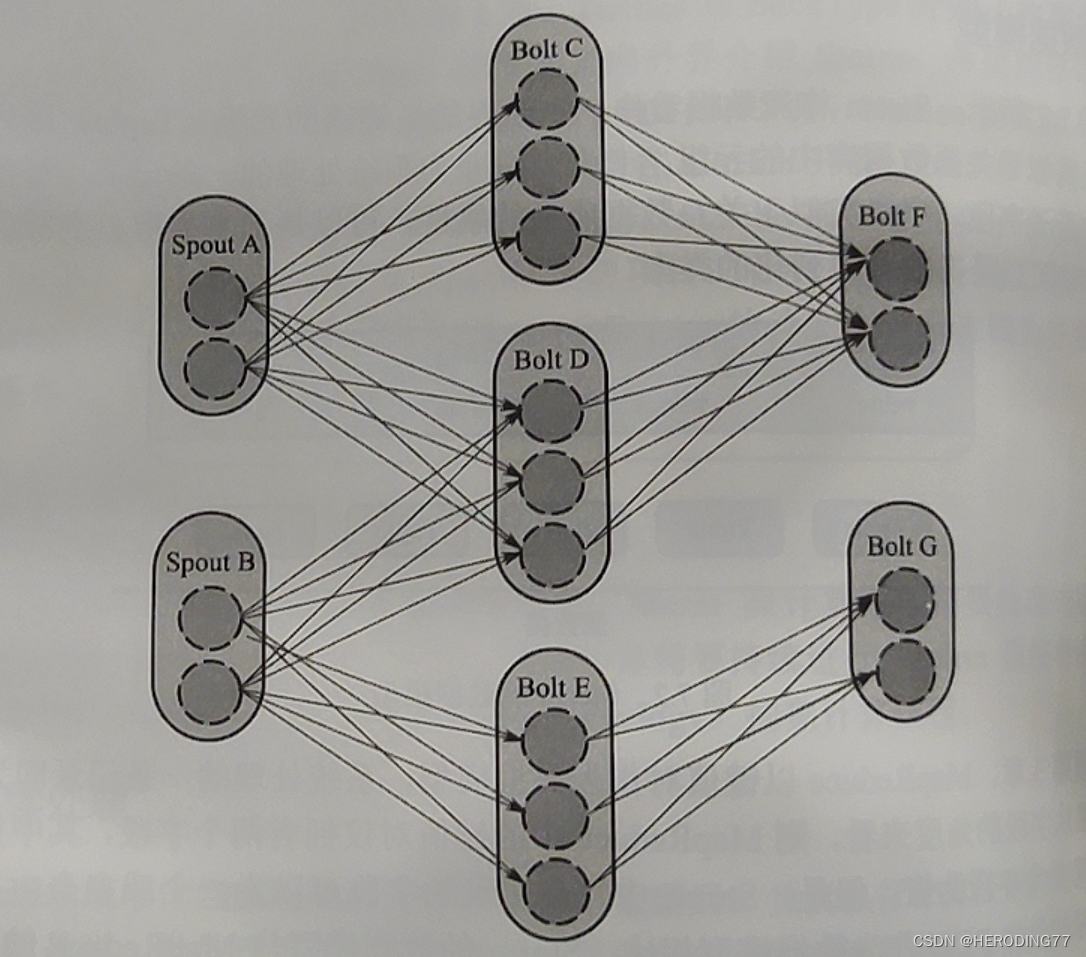
7.2 Arquitetura
7.2.1 Diagrama de Arquitetura
Storm adota uma arquitetura mestre-escravo e seus principais componentes de trabalho incluem: Nimbus, Supervisor, Worker e ZooKeeper. O Nimbus está localizado no nó mestre e o Supervisor e o Trabalhador estão localizados nos nós escravos. A coordenação do nó mestre-escravo depende do ZooKeeper.
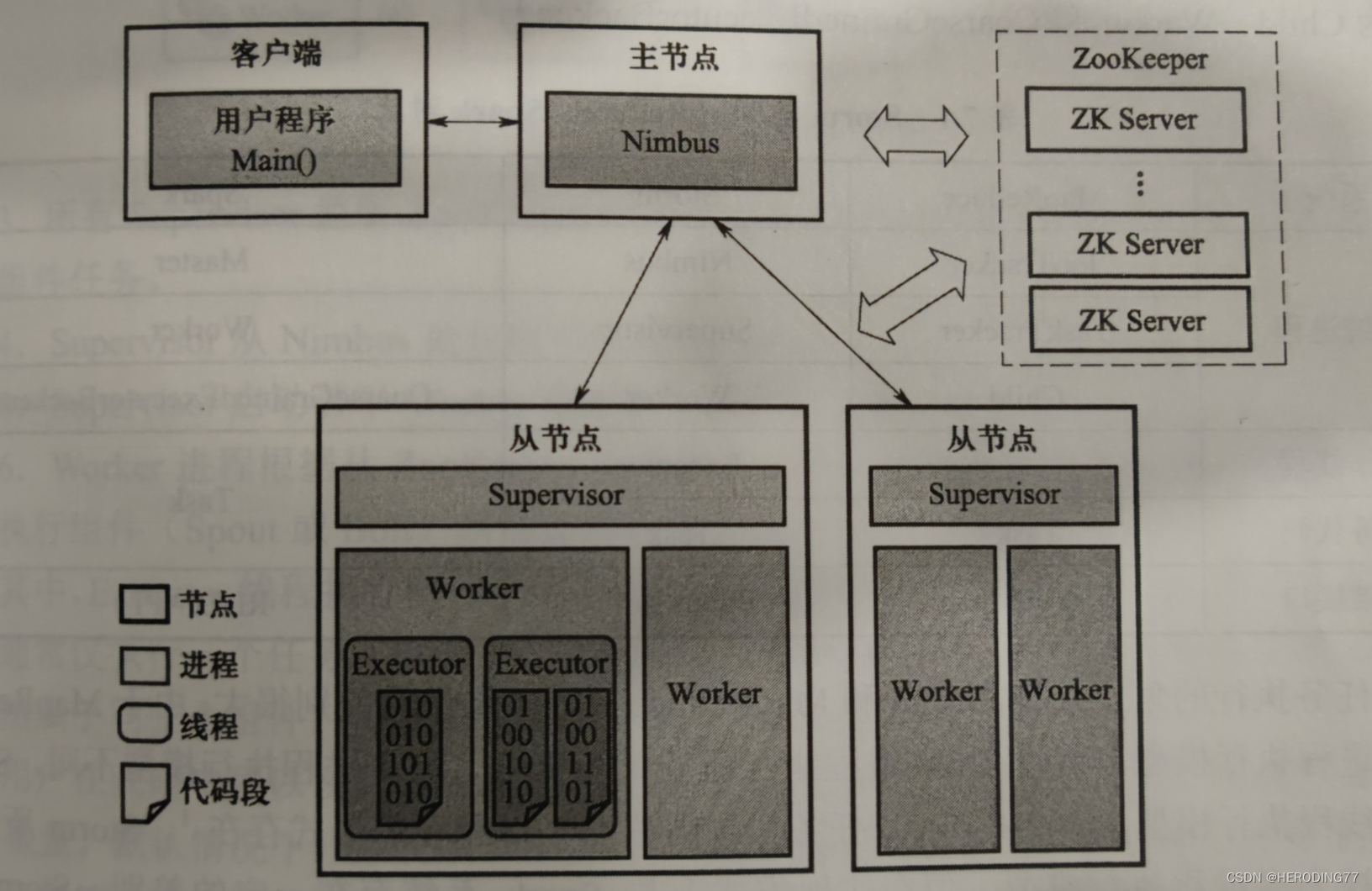
- **Nimbus: **O processo em segundo plano em execução no nó mestre, semelhante ao JobTracker, armazena o código do programa de topologia do usuário, distribui o código, atribui tarefas e detecta falhas.
- **Supervisor: **O processo em segundo plano executado a partir do nó, semelhante ao TaskTracker no MapReduce. É responsável por monitorar o trabalho da máquina do nó onde está localizado, e decidir ou parar o processo do Worker de acordo com as tarefas atribuídas pelo Nimbus. Um nó escravo executa vários processos de trabalho ao mesmo tempo.
- **Zookeeper: ** é responsável pela coordenação entre Nimbus e Supervisor. O endereço do Supervisor e os metadados do trabalho são armazenados no ZooKeeper. A recuperação de dados lê os dados do ZooKeeper.
- **Worker:** o processo responsável por executar tarefas, executado por vários threads internos.
Entre eles, Nimbus e Supervisor são iniciados como serviços do sistema Storm, e o processo Worker é iniciado com a execução do aplicativo. As threads executoras executam uma ou mais tarefas do mesmo componente (Spout ou Bolt), e as tarefas são códigos que existem na forma de objetos.
Comparação entre Storm, MapReduce e Spark
| sistema | MapReduce | Tempestade | Fagulha |
|---|---|---|---|
| processo do sistema | JobTracker | Nuvem | Mestre |
| Rastreador de Tarefas | Supervisor | Trabalhador | |
| Criança | Trabalhador | CoarseGrainedExecutorBack-end | |
| thread de trabalho | - | Executor | Tarefa |
| código de tarefa | Tarefa | Tarefa | |
| interface básica | Mapear\Reduzir | Bico/Parafuso | API RDD |
7.2.2 Fluxo de execução do aplicativo
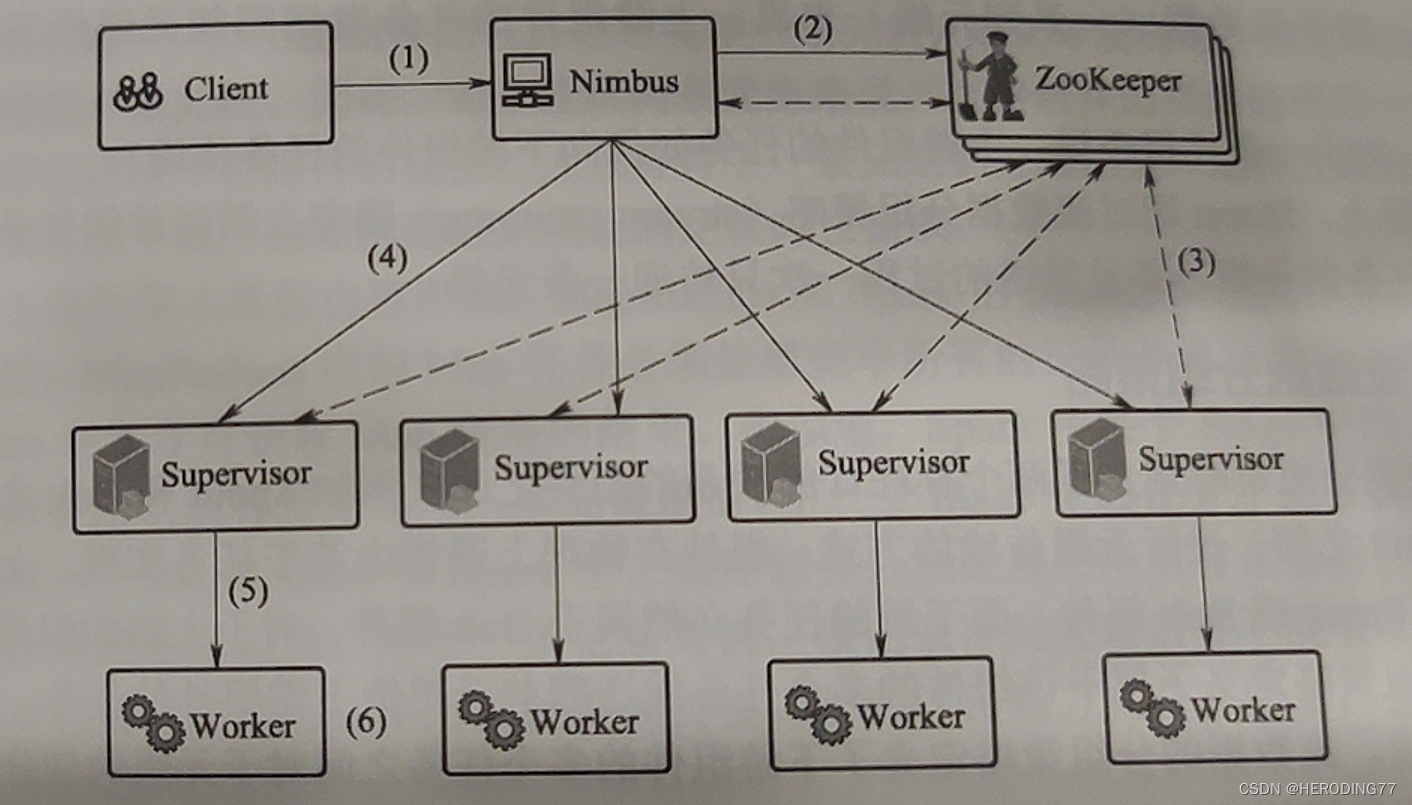
- O usuário escreve o programa, que é serializado e empacotado e submetido ao nó mestre Nimbus.
- O Nimbus cria um arquivo de correspondência de componente para nó físico e grava atomicamente o arquivo em um nó no ZooKeeper.
- Todos os Supervisores escutam o Znode no ZooKeeper para serem notificados, a fim de obter as tarefas do componente que o nodo precisa executar.
- O supervisor extrai o código executável do Nimbus.
- O Supervisor inicia vários processos do Worker para executar tarefas específicas.
- O Worker inicia várias threads do Executor de acordo com as informações do arquivo obtidas no ZooKeeper, e esta thread é responsável por executar as tarefas descritas pelos componentes (Spout, bolt).
Um thread Executor geralmente executa apenas uma tarefa e várias tarefas são executadas em série (e pertencem ao mesmo componente).
7.3 Princípio de funcionamento
Para completar a transmissão da tupla, os dois problemas a seguir precisam ser resolvidos:
- Para dados de streaming, quais tuplas são enviadas por tarefas de componente upstream para tarefas de componente downstream.
- Para uma tupla, como a tarefa do componente upstream é passada para a tarefa do componente downstream.
Na verdade, Storm usa a estratégia de agrupamento de dados de fluxo para determinar as tuplas que a tarefa do componente upstream envia para a tarefa do componente downstream, e o processo de envio passa apenas uma tupla por vez.
7.3.1 Estratégia de agrupamento de dados de fluxo
A estratégia de agrupamento de dados de fluxo define a forma de transmissão da tupla entre dois componentes assinantes. Estratégias comuns de agrupamento:
- agrupamento aleatório
- agrupamento de campo
- Agrupamento de campo parcial (balanceamento de carga entre tarefas de componentes downstream quando os dados são distorcidos)
- pacote de transmissão
- agrupamento global
- não agrupado
- agrupamento direto
- local ou aleatório
7.3.2 Método de entrega de tupla
tupla por vez (um registro por vez)
Por outro lado, Reduce em MapReduce precisa esperar que o estágio Map seja processado antes de obter os resultados Map do disco, e o Stage in Spark deve gravar os resultados no disco para que as tarefas no próximo Stage possam ler os resultados.
7.4 Mecanismo de tolerância a falhas
Tipo de falha:
- Falha do nó primário: Incapaz de receber novos trabalhos, selecione um novo Nimbus primário do Nimbus em espera.
- Falha do nó escravo: falha do processo do trabalhador (reiniciar, reiniciar falha para permitir que outros supervisores abram novos trabalhadores), falha do processo do supervisor (reiniciar, reiniciar falha ao iniciar o Nimbus para iniciar um novo supervisor, reagendamento do trabalhador em funcionamento) e ambas as falhas ao mesmo tempo (Comando Nimbus Outros Supervisores iniciam os processos do Trabalhador).
- Falha do ZooKeeper
7.4.1 Definição de tolerância a falhas
Uma garantia confiável tolerante a falhas deve garantir a consistência das mensagens antes e depois de uma falha. Nível semântico de tolerância a falhas:
- no máximo uma vez: as mensagens podem ser perdidas
- pelo menos uma vez: não perdido, mas pode ser repetido
- Exatamente uma vez: sem perda, sem repetição
Storm usa o mecanismo ACK para alcançar a semântica de tolerância a falhas pelo menos uma vez.
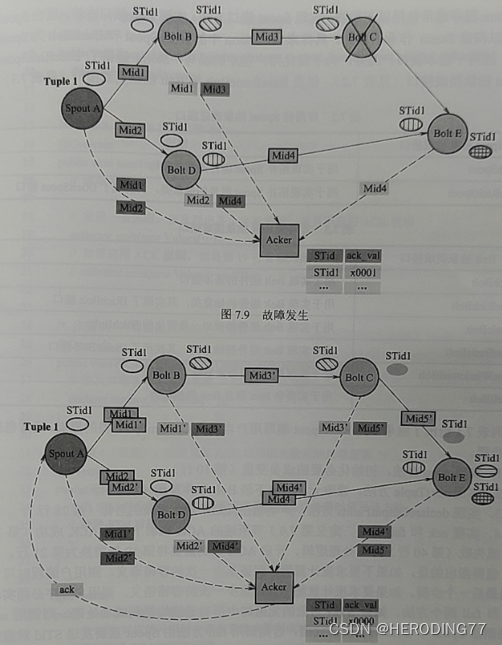
7.4.2 Árvore de tuplas
Cada tupla no spout corresponde a um número de tupla. No Storm, quando um grafo spout emite uma tupla, o usuário pode especificar um identificador para ela, chamado STid. As tuplas do mesmo STid constituem um número de tupla.

7.4.3 Mecanismo ACK
**Acker:** Uma classe especial de tarefas responsável por rastrear as tuplas emitidas pelo spout e o número de tuplas. O padrão é 1.
**Mid: **Transmissão da mensagem representada fisicamente pela transmissão da tupla na árvore de tuplas, incluindo o identificador de 64 bits. Se a transmissão for normal, o Mid da mensagem recebida pelas tarefas do componente upstream e downstream é o mesmo.
O lado ACKer mantém a tabela de mapeamento de <STid, ack_val>, e inicializa o ack_val do STid correspondente em 0 quando recebe uma mensagem do Spout. Independentemente de o Acker receber a mensagem reportada pelo componente upstream ou downstream , ele corresponderá ao Mid nele com o ack_val na tabela de mapeamento. O ack_val do STid correspondente é XORed.
Quando o número de Ackers é maior que 1, um hash consistente é usado para mapear um STid para um Acker, para que vários Ackers não interfiram entre si.
7.4.4 Repetição de mensagem
Se o processo do Worker falhar e algumas mensagens forem perdidas, o Acker não pode receber a mensagem de confirmação do STid enviada pelo topology end Bolt dentro do tempo definido, ou o ack_val correspondente ao STid não é 0. Storm escolhe reenviar a tupla identificada por STid.
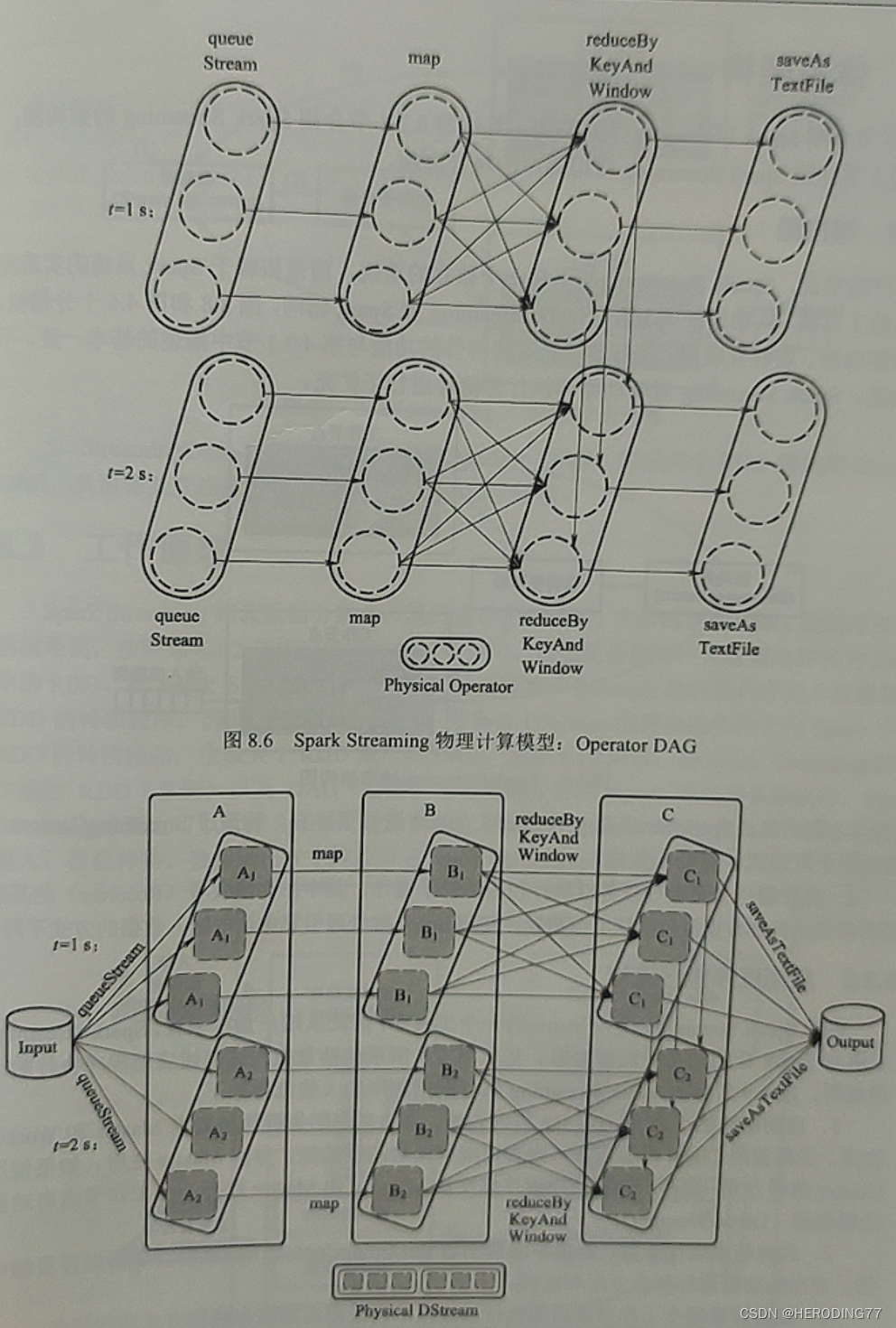
Capítulo 8 Stream Computing System Spark Streaming
Na verdade, é uma extensão da API principal do Spark, que pode discretizar dados de streaming contínuo e entregá-los ao sistema de processamento em lote do Spark. Realizou o uso do sistema de processamento em lote para suportar a computação de fluxo.
8.1 Pensamento de design
8.1.1 Microlotes
O método de microlote considera os dados dentro de um determinado intervalo de tempo como um lote de dados estáticos e os envia ao sistema de processamento em lote para processamento.
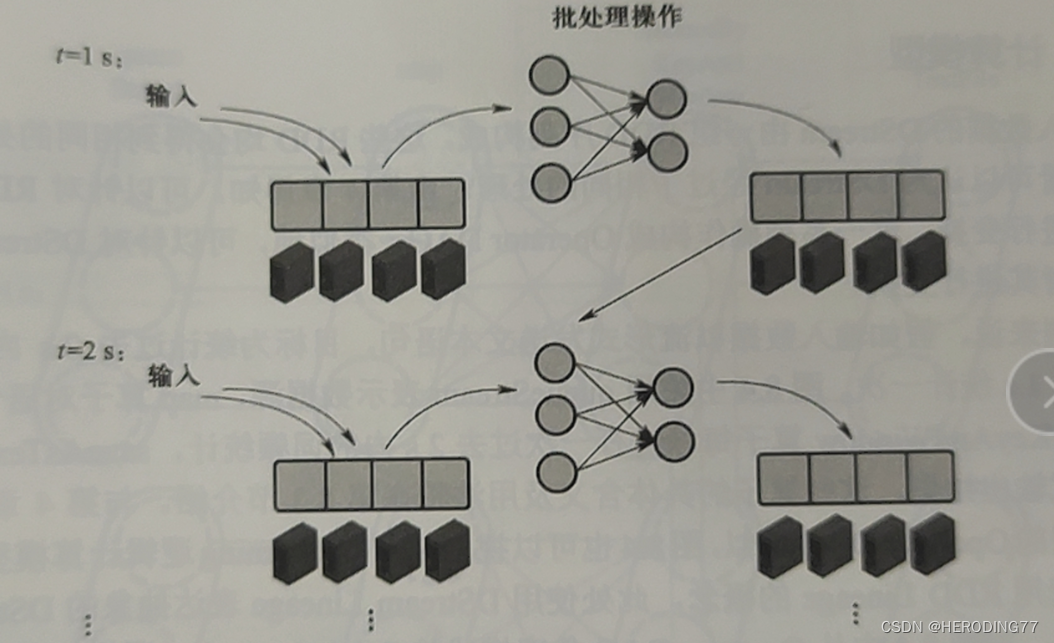
8.1.2 Modelo de Dados
O Spark Streaming usa processamento em microlotes para dividir dados de streaming contínuos para gerar uma série de pequenos pedaços de dados.
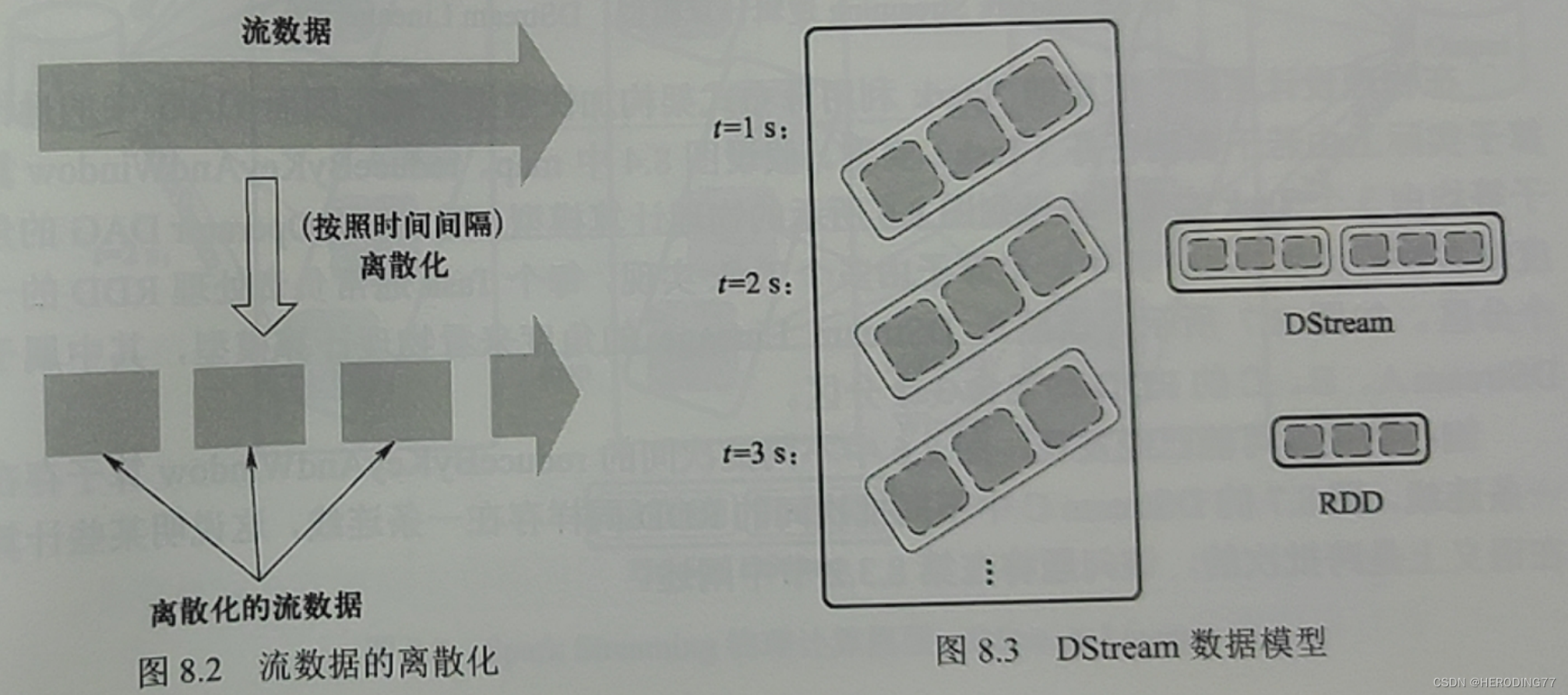
8.1.3 Modelo de cálculo
O DStream dos dados de entrada consiste em um conjunto de sequências RNN.Esses RDDs serão processados da mesma forma, e uma série de operações podem ser executadas nos RDDs para formar um DAG Operador.
No nível físico, o Spark subjacente usa uma arquitetura distribuída para acelerar o processamento de dados, de modo que os operadores no DAG são realmente implementados por várias tarefas de instância.
8.2 Arquitetura
8.2.1 Diagrama de Arquitetura
A arquitetura física é a mesma do Spark, a diferença é que o Spark Streaming expande os componentes do driver e do atuador.
- Driver: o Spark Streaming estende o SparkContext para construir o StreamingContext, que contém metadados para gerenciar a computação de fluxo.
- Executor: Responsável por executar tarefas para realizar operações de operador correspondentes, e certas tarefas como receptores são responsáveis por obter continuamente dados de streaming de fontes de dados externas.
8.2.2 Fluxo de execução do aplicativo
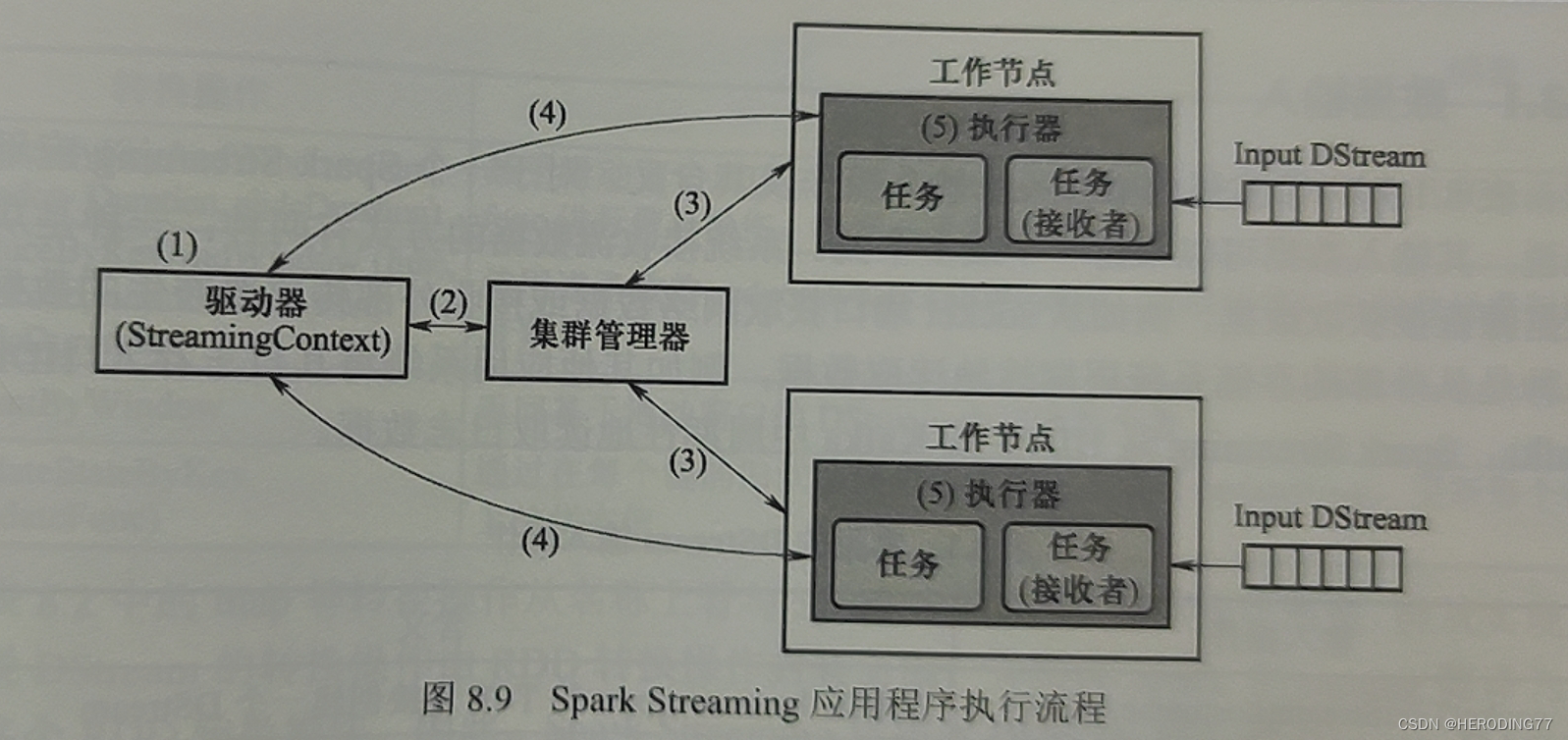
- unidade de inicialização
- Crie um ambiente operacional básico, solicite recursos do gerenciador de cluster e atribua e monitore tarefas pelo driver.
- O gerenciador do cluster instrui os nós do trabalhador a iniciar o processo executor, que é executado internamente com vários encadeamentos.
- O processo executor se registra com o driver.
- StreamingContext gera o Operator DAG sobre a conversão de RDD de acordo com o Operator DAG do DStream, de modo a entregá-lo ao thread no processo do executor para executar a tarefa.
8.3 Princípio de funcionamento
O Spark Streaming precisa converter a operação de conversão do DStream na operação de conversão do RDD no Spark e gerar um DAG sobre a operação do RDD.

8.3.1 Entrada de dados
Para um aplicativo Spark Streaming, seus dados de entrada podem vir de um ou mais fluxos. O sistema recebe dados de streaming das seguintes maneiras:
- Uma delas é obter dados diretamente de uma fonte de dados externa.
- A outra é ler periodicamente os dados de um sistema de armazenamento externo.
O primeiro precisa garantir que os dados sejam copiados nos dois nós de trabalho antes de enviar uma mensagem de confirmação ao cliente, enquanto o último não precisa de backup porque possui um sistema de armazenamento como o HDFS.
8.3.2 Conversão de dados
Operações de conversão do DStream:
- Operações como transformação RDD
- Operações usando transformações RDD
- operação de janela
- operação de estado
A operação de transformação do DStream é encapsulada pela operação de transformação RDD e é traduzida em uma ou mais operações de transformação RDD pelo Spark Streaming. Portanto, o Spark Streaming transforma o DAG do Operador que descreve a conversão do DStream no DAG do Operador que descreve a conversão do RDD e o entrega ao mecanismo subjacente de processamento em lote do Spark para gerar uma série de trabalhos para os pequenos lotes de dados que chegam continuamente.
O Spark Streaming oferece suporte a operações de janela baseadas em tempo.
- Janela deslizante: tamanho da janela maior que o intervalo
- Janela fixa: tamanho da janela igual ao intervalo
- Janela de salto: o tamanho da janela é menor que o intervalo
O método não incremental de janela deslizante causará muitos cálculos repetidos.
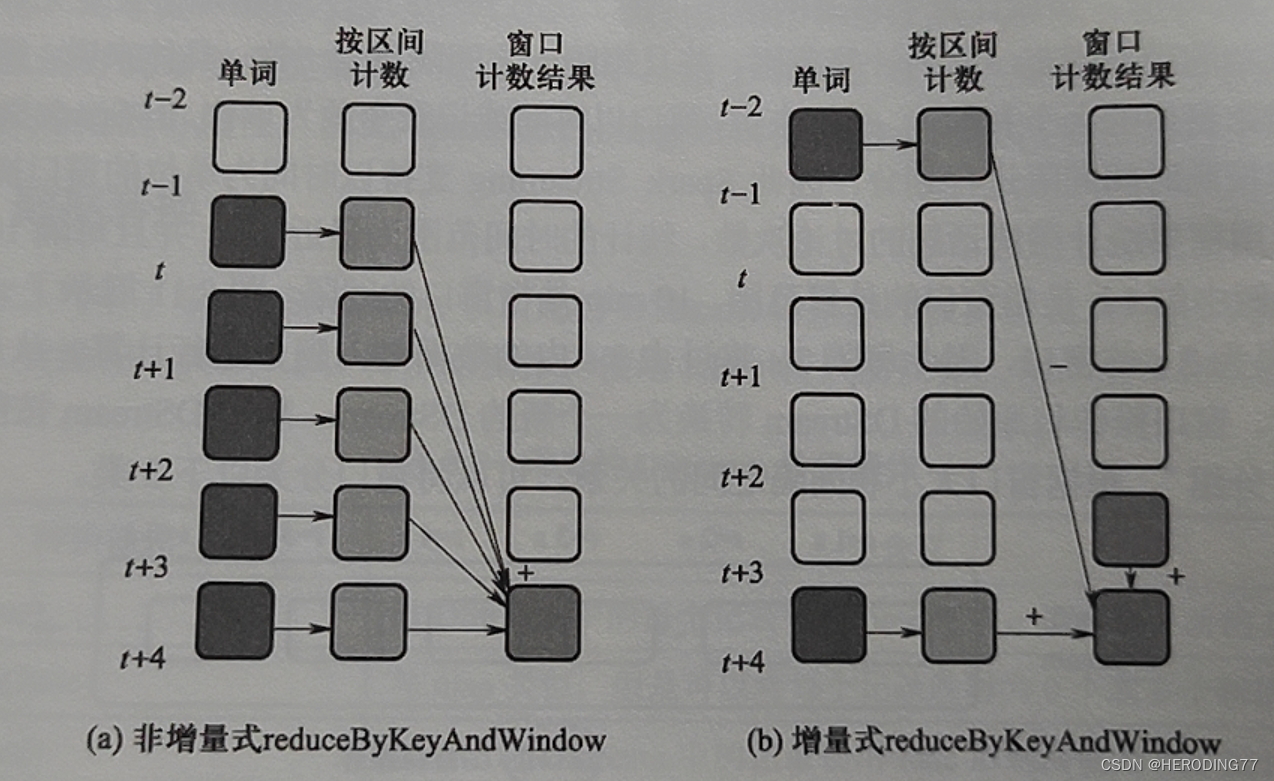
**Estado:** os dados salvos em uma operação são considerados estado se forem reutilizados em cálculos feitos após a chegada de novos dados.
O estado no Spark Streaming é o RDD gerado durante a operação do sistema.
8.3.3 Saída de dados
No Spark Streaming, um DAG composto por operações DStream tem uma operação de saída. Por outro lado, o Spark gera DAG ao encontrar operações de ação, enquanto o Spark Streaming não possui o conceito de operações de ação, mas gera DAG com base nas operações de saída.
O mecanismo Spark subjacente executa um DAG que consiste em operações RDD.
8.4 Mecanismo de tolerância a falhas
Tipo de falha:
- Falha do gerenciador de cluster: responsável pelo agendamento de recursos do sistema
- falha na unidade
- falha do atuador
8.4.1 Tolerância a falhas com base na linhagem RDD
Se um Executor falhar e não contiver uma tarefa Receiver, somente a tarefa responsável pelo processamento de dados será afetada. Portanto, o mecanismo Lineage pode ser usado para tolerância a falhas.
8.4.2 Tolerância a falhas baseada em log
Para o problema de falha do executor com o Receiver, uma estratégia de tolerância a falhas baseada em log é adotada.
Para dados obtidos de fontes de dados externas, o Spark Streaming os divide em dois nós de trabalho. Se o executor falhar, ele pode ser recuperado do nó de backup. Se o nó de backup falhar ao mesmo tempo, ele só poderá declarar falha.
**Problema: **Após reiniciar, o executor recupera os dados novamente, o que envolve o problema de quais dados obter e leitura repetida.
**Solução:** Armazene os dados em um sistema de arquivos externo (HDFS) na forma de um log. Quando o executor falha e reinicia, o Receptor carrega o log do sistema de arquivos externo e relê os dados de entrada para garantir que os dados existentes no log não sejam lidos repetidamente.
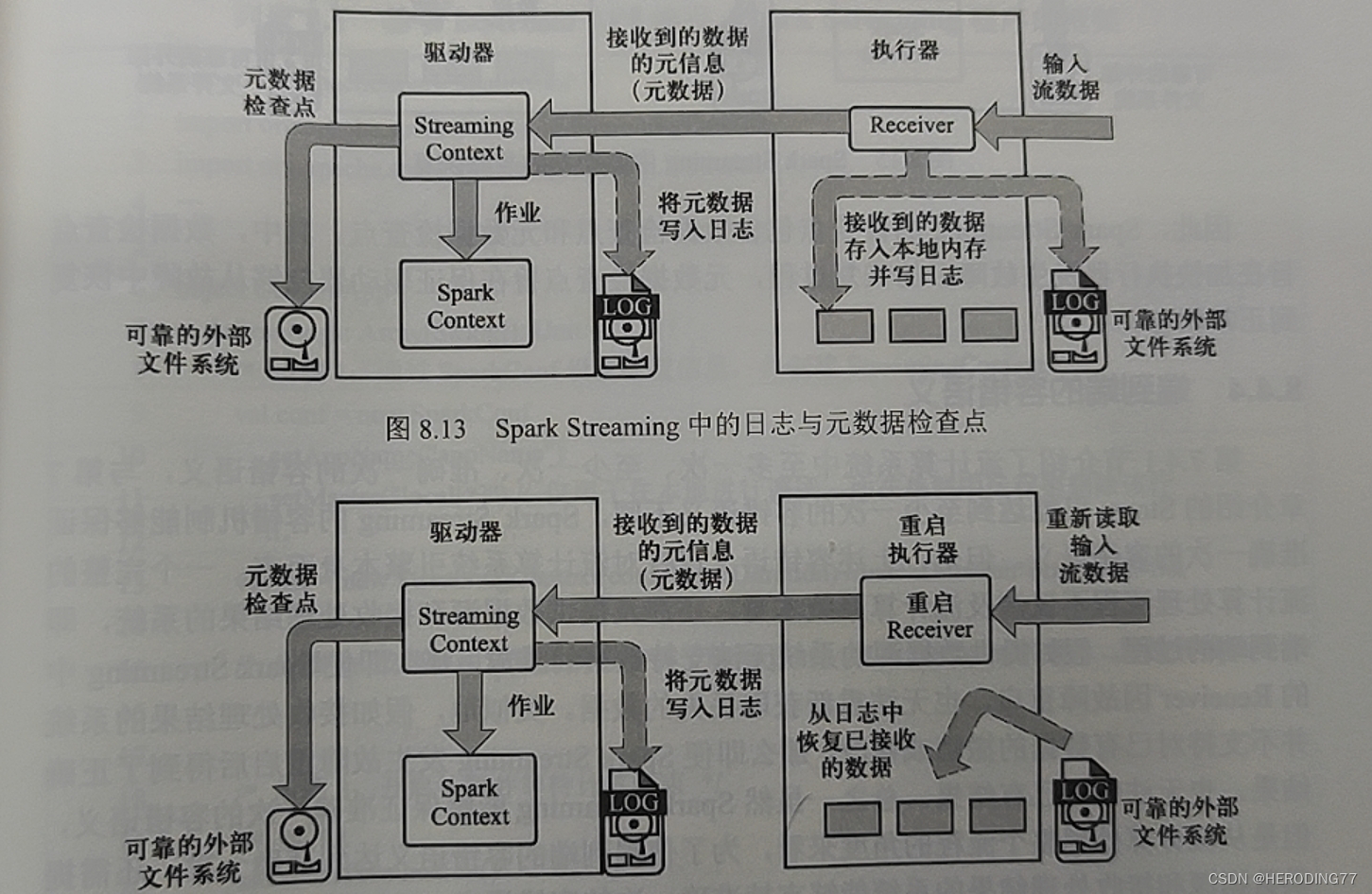
8.4.3 Tolerância a falhas baseada em ponto de verificação
Evite que o processo RDD Lineage cause sobrecarga elevada no processo de recuperação e combine pontos de verificação para evitar o recálculo.
Para oferecer suporte à recuperação de falha de unidade, os pontos de verificação de metadados precisam ser projetados .
- Informações de configuração: crie informações de configuração para aplicativos Spark Streaming.
- Informações de operação do DStream: informações de operação do DStream que definem a lógica de operação do aplicativo.
- Informações de lote não processadas: informações de dados de lote que estão sendo enfileiradas e não foram processadas.
Enquanto o sistema está em execução, os pontos de verificação de metadados são gravados em um sistema de arquivos externo confiável. Quando ocorre uma falha de unidade, os checkpoints e diários de metadados são carregados de um sistema de arquivos externo.
ponto de verificação:
- Pontos de verificação de dados: aceleram o processo de recuperação de falhas do atuador.
- Pontos de verificação de metadados: Recuperação de unidade garantida de falhas.
8.4.4 Semântica de tolerância a falhas de ponta a ponta
O Spark Streaming pode garantir a semântica de tolerância a falhas exatamente uma vez. No entanto, do ponto de vista de todo o processo de processamento de computação em fluxo, para alcançar a semântica tolerante a falhas exatamente uma vez para ponta a ponta, também é necessário que o sistema que fornece a fonte de dados e recebe os resultados do processamento suporte a semântica tolerante a falhas exatamente uma vez.
Capítulo 9 Fundamentos do Batch Stream Fusion
9.1 Histórico da fusão de fluxo em lote
O processamento em lote é adequado para processar grandes lotes de dados e não requer alto desempenho em tempo real, enquanto o processamento em fluxo é adequado para cenários em que o processamento rápido dos dados gerados requer alto desempenho em tempo real. Módulos diferentes na mesma cena podem ter requisitos diferentes para desempenho em tempo real, que é o valor do processamento de fluxo em lote.
9.1.1 Requisitos de inscrição
Por exemplo, Weibo, dados históricos são adequados para processamento em lote e novos dados são adequados para processamento de fluxo.
9.1.2 Arquitetura Lambda e suas limitações
Qualquer consulta sobre os dados pode ser expressa usando a seguinte equação:
consulta = função ( todos os dados ) consulta = função (todos \ dados)pergunta _ _=função ( todos os dados ) _ _ _ _ _ _ _ _ _ _
Cenários com dados particularmente grandes são difíceis de responder rapidamente.
visão pré-materializada
Pré-computação para consultas para obter visualização em lote
- Quando uma consulta precisa ser executada, os resultados são lidos na visualização em lote.
- Oferece suporte a leituras aleatórias por meio de indexação para tempos de resposta mais rápidos.
exibição de lote = função 1 (todos os dados) lote \ exibição = função_1 (todos \ dados)b t c h v i e w =função _ _ _ _ _ _ _1( todas as datas ) _ _ _
consulta = função 2 (exibição em lote) consulta = função_2(lote \ exibição)pergunta _ _=função _ _ _ _ _ _ _2( ba t c h v i e w )
Mas os dados tendem a aumentar rápida e dinamicamente, portanto, há um atraso nos resultados da visualização em lote.
Solução: estrutura de três camadas
- Camada de processamento em lote: processamento em lote offline de dados para gerar exibições de processamento em lote.
- Camada de aceleração: processamento em tempo real de novos dados, exibições de lote compensadas de forma incremental.
- Camada de serviço: responde às solicitações de consulta do usuário.
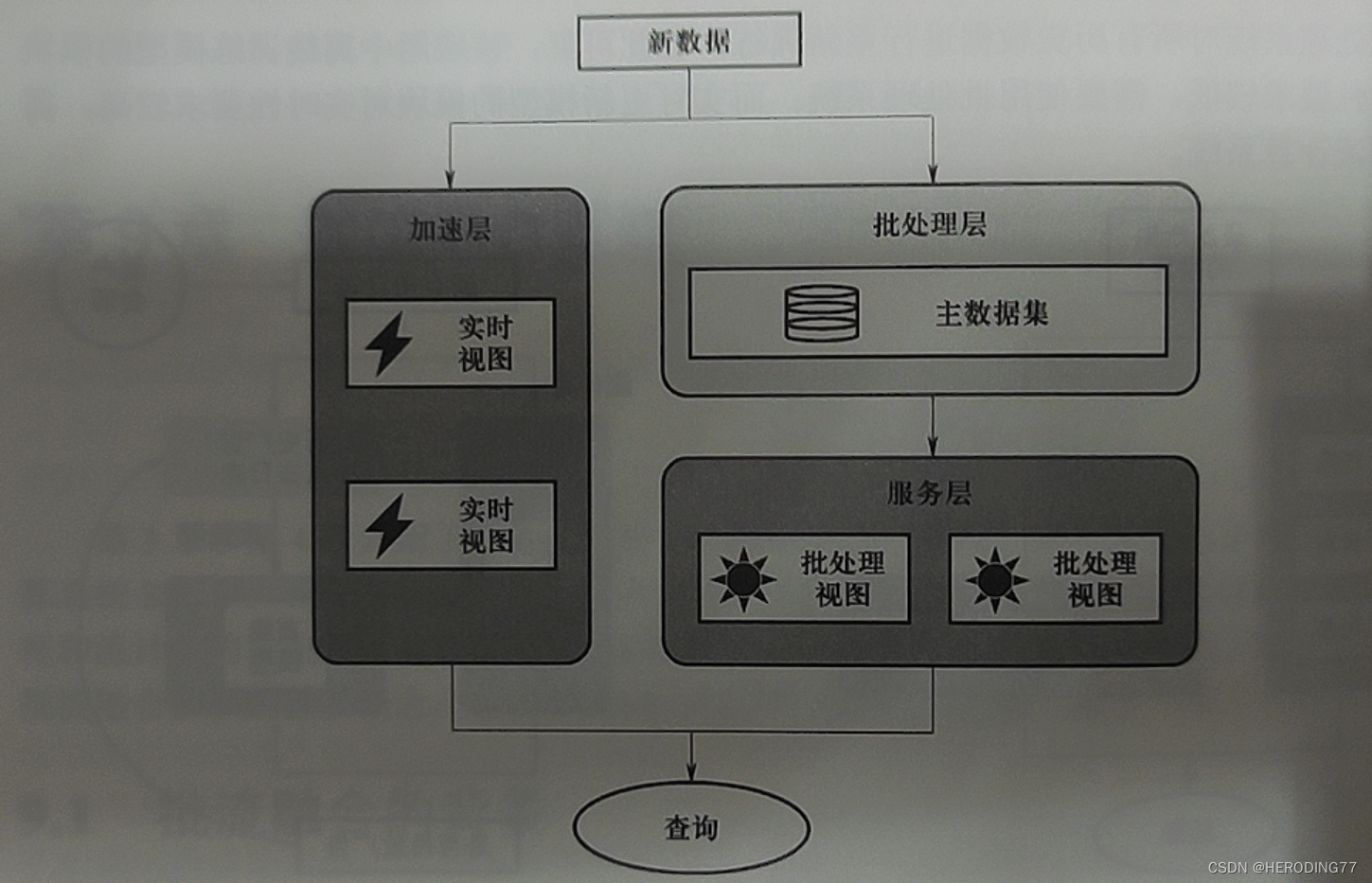
Na verdade, obter todos os dados e consultá-los geralmente é difícil de conseguir. A arquitetura Lambda trata todos os dados como uma combinação de **conjunto de dados mestre e novos dados**.
Em geral, a arquitetura Lambda pode ser expressa pelas três equações a seguir:
exibição de lote = função 1 (todos os dados) lote \ exibição = função_1 (todos \ dados)b t c h v i e w =função _ _ _ _ _ _ _1( todas as datas ) _ _ _
visualização em tempo real = função 2 (visualização em tempo real, novos dados) visualização em tempo real\=function_2(visualização\ em tempo real,\, novos dados)eu sou _−visualização do tempo _ _ _ _ =função _ _ _ _ _ _ _2( é um l−visualização do tempo , _ _ _ _ novo dado ) _ _ _ _ _
query = function 3 (batch view, real-time view) query = function_3(batch \ view, real-time\ view)pergunta _ _=função _ _ _ _ _ _ _3( ba t c h v i e w , eu sou _−visualização do tempo ) _ _ _ _
MapReduce é usado como camada de processamento em lote, Strom é usado como camada de aceleração e o banco de dados distribuído Cassandra é usado como camada de serviço.
vantagem:
Ele equilibra a contradição entre a alta sobrecarga de recomputação e a necessidade de baixa latência.
deficiência:
- O desenvolvimento é complicado e todos os algoritmos precisam ser implementados duas vezes. O sistema batch e o sistema em tempo real são programados separadamente, e o resultado também deve ser uma combinação dos resultados dos dois sistemas.
- A operação e a manutenção são complicadas e dois conjuntos de motores são mantidos ao mesmo tempo.
9.2 A unidade de processamento em lote e computação em fluxo
Pergunta: O mecanismo de processamento em lote pode processar apenas dados em lote e o mecanismo de computação em fluxo pode processar apenas dados em fluxo?
Não necessariamente, apenas um problema de desempenho.
9.2.1 Conjuntos de dados limitados vs. ilimitados
Conjunto de dados limitado: correspondente aos dados em lote
Conjuntos de dados ilimitados: dados de streaming correspondentes
9.2.2 Operação da Janela
Baseado em elementos:
- janela baseada em tempo
- Janela baseada em registro
De acordo com a relação entre o tamanho da janela e o intervalo, a janela é dividida em:
- janela deslizante
- janela fixa
- pular janela
As janelas de sessão baseadas em tempo geralmente são definidas de acordo com o período de tempo limite e todos os registros dentro do período de tempo limite pertencem à mesma sessão (relacionado ao comportamento de navegação do usuário).
9.2.3 Domínio do tempo
Trate um registro de dados como um evento
- Hora do evento: a hora em que o evento foi gerado
- Tempo de processamento: O tempo em que o evento foi processado pelo sistema.
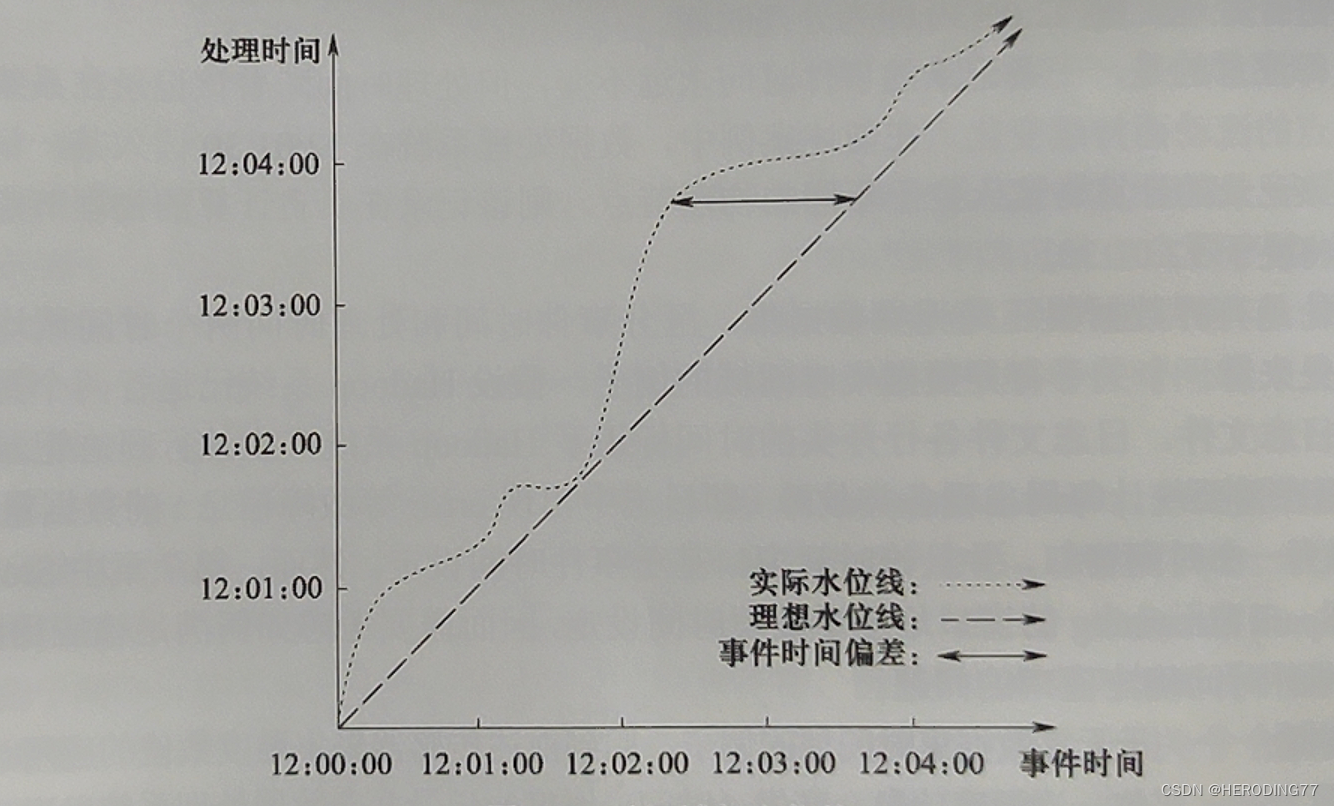
Haverá uma diferença entre o tempo do evento e o tempo de processamento. Introduza o conceito de marca d'água , que é um timestamp de evento, e a hora do evento indicada por ele indica que os registros de tempo anteriores ao evento foram completamente observados pelo sistema.
9.3 Modelo de programação unificada de fluxo de dados
O modelo de programação Dataflow trata todos os dados de entrada como conjuntos de dados ilimitados, com dados limitados como um caso especial de dados ilimitados. Características dos dados de entrada processados pelo modelo de programação:
- ilimitado
- Atraso
- fora de serviço
O modelo de programação de fluxo de dados também é chamado de modelo WWWH (What-Where-When-How), o significado básico é o seguinte:
- Descrição da operação: qual operação precisa ser feita.
- Definição de janela: onde dividir a janela.
- Gatilho: Uma janela definida com base no horário do evento quando o sistema deve ser acionado no domínio do tempo de processamento devido a atrasos nos dados de entrada.
- Correção de resultado: dados de entrada fora de ordem, ainda pode haver dados atrasados chegando depois que o gatilho é acionado, como corrigir o resultado do cálculo da janela acionada.
9.3.1 Descrição da operação
Use PCollection<KV<tipo de chave, tipo de valor>> para representar o conjunto de dados, que é uma coleção de pares chave-valor, e as operações principais incluem ParDo e GroupByKey.
- ParDo: semelhante ao mapa
- GroupByKey: semelhante ao Shuffle
9.3.2 Definição de janela

Para dados ilimitados, por meio da definição da janela, você só pode executar operações nos dados da janela sem obter todos os dados.
9.3.3 Gatilhos
Descreve quando exibir os resultados da janela. Quando o nível da água cruza o tempo de evento especificado da janela, a saída do resultado é acionada.
9.3.4 Correção de resultados
- Descartar o conteúdo da janela: quando o gatilho é acionado, o conteúdo da janela é descartado.
- Conteúdo cumulativo da janela: depois que o gatilho é acionado, o conteúdo da janela é persistente e os resultados recém-obtidos corrigirão os resultados de saída (não retirados).
- Acumule e retire o conteúdo da janela: Depois que o gatilho é acionado, não apenas o conteúdo da janela é mantido, mas também os resultados de saída precisam ser registrados. A janela é acionada novamente para recuperar os resultados gerados e exibir os resultados recém-obtidos.
9.4 Modelo de programação Relacional Dataflow
Da perspectiva do modelo de dados relacional, se os pares chave-valor forem considerados como tuplas, uma série de pares chave-valor pode constituir uma tabela relacional. O modelo de programação relacional do Dataflow considera os dados de entrada como uma tabela relacional, em vez de uma série de registros de pares chave-valor, e a saída também é uma tabela relacional.
No início, havia uma linguagem de consulta contínua CQL para streaming de dados , que era usada para executar operações SQL em dados de streaming.
Com base na ideia de CQL, o modelo de programação relacional do Dataflow converte o conjunto de dados ilimitado de entrada em uma tabela relacional. Como a tabela relacional está mudando dinamicamente, as operações SQL são executadas na tabela relacional no momento da definição do gatilho para obter um nova tabela relacional e, em seguida, converta a nova tabela relacional em um conjunto de dados ilimitado de acordo.
9.5 Mecanismo de Execução Integrado
A programação unificada em lote pode ser compreendida em dois níveis:
- O modelo de programação de processamento em lote e computação de streaming é unificado entre vários mecanismos de execução diferentes.
- A programação unificada de processamento em lote e computação de fluxo é realizada em um mecanismo de execução.
**Mecanismo de Execução Integrado:** Ele pode suportar processamento em lote e computação de fluxo ao mesmo tempo, bem como programação unificada.
9.5.1 Processamento em lote como núcleo
O streaming estruturado realiza a programação unificada do processamento em lote. A camada subjacente usa o mecanismo de processamento em lote Spark e adota o modo de execução do processamento em microlote. O sistema inicia continuamente aplicativos de curto prazo para processar dados de microlote, e o atraso entre a conclusão do processamento está no segundo nível.

vantagem:
- Prioridade do lote, status do núcleo.
- Conjuntos de dados limitados dominam.
deficiência:
- É diferente da compreensão do Dataflow de dados limitados e ilimitados.
- Não é propício implementar janela de contagem de registros e janela de sessão, etc., e a latência é alta.
9.5.2 Stream Computing como o Núcleo
O representante é Flink. O sistema inicia um aplicativo de execução longa uma vez. A latência é substancialmente menor do que a do microlote. Geralmente em milissegundos.

Vantagem:
- A computação de fluxo é a prioridade e a posição principal.
- O mecanismo de computação de fluxo processa conjuntos de dados ilimitados e limitados de maneira unificada para atingir o objetivo de integrar o mecanismo de execução.
- É consistente com o reconhecimento do modelo de programação Dataflow de conjuntos de dados limitados e ilimitados.
- latência em milissegundos.
Capítulo 10 Sistema de Computação de Stream Flink
10.1 Pensamento do projeto
10.1.1 Modelo de Dados
** Ano 2008 **
A German Science Foundation financia o projeto de pesquisa Stratosphere.
O sistema de processamento em lote expande os operadores MapReduce e introduz pipelines para transmissão de dados.

Combine os pontos fortes do banco de dados com o MapReduce.
2015
O Google publicou um artigo sobre o modelo Dataflow
O Flink é gradualmente posicionado como um mecanismo de execução integrado de fluxo em lote e suporta operações de fusão de fluxo em lote definidas no modelo Dataflow.
2019
Alibaba adquire a Ververica
modelo de dados
O Flink trata os dados de entrada como uma sequência ininterrupta, ilimitada e contínua de registros.
Flink abstrai esta série de registros em DataStream.
Como RDDs, DataStreams são imutáveis.

Comparação de modelos de dados

10.1.2 Modelo de Cálculo
operador DataStream
-
O operador transforma o DataStream
- DataStream obtém um novo DataStream após a operação de transformação
- Semelhante ao RDD no Spark que é transformado para gerar um novo RDD
-
Uma série de operações de transformação formam um grafo acíclico direcionado DAG
- fonte de dados
- converter
- conjunto de dados
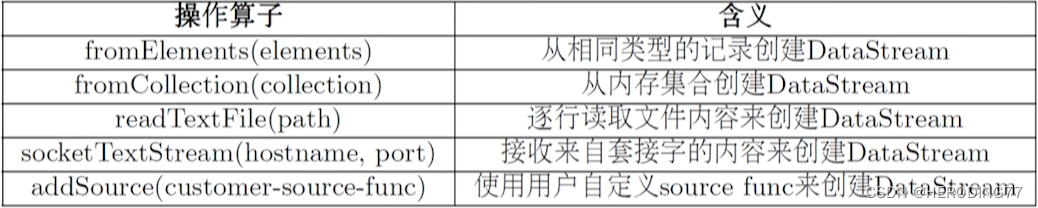
Fonte de dados
Descreva a fonte dos dados.
Transformação
Descrever a lógica de transformação do DataStream no sistema.

DataSink
Descreva a direção dos dados, marcando o final do DAG.

Uma série de operadores constituem o DAG, descrevendo a composição do cálculo:

De um modo geral, o sistema Flink corresponde a um DAG , enquanto um aplicativo no Spark contém um ou mais DAGs .
Como o DataStream é transformado dinamicamente, não há como corrigir os nós (os nós mudam constantemente), o que não faz sentido para tolerância a falhas subsequentes.
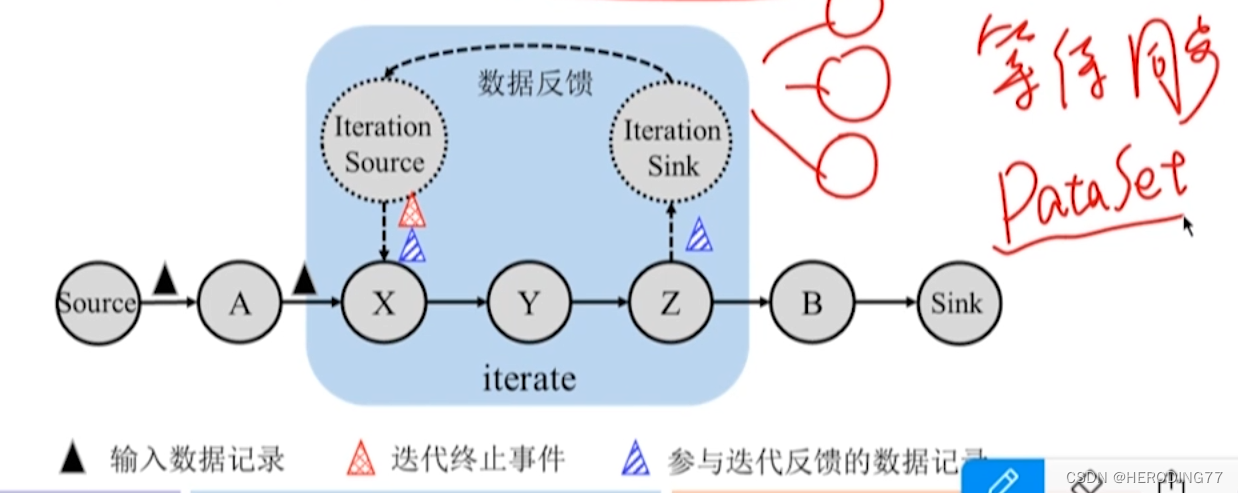
10.1.3 Modelo Iterativo
- Deve haver loops no processo iterativo
- Se a iteração como um todo for considerada como um operador, não haverá loop.
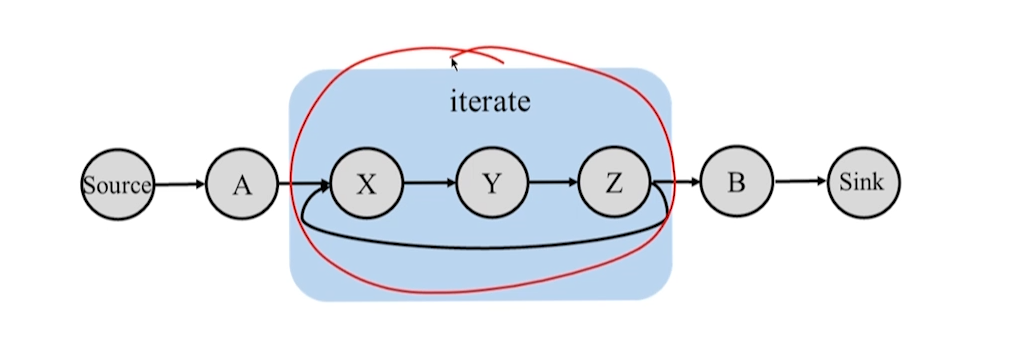
comparação iterativa

10.2 Arquitetura
10.2.1 Diagrama de Arquitetura

Cliente
- Traduza e otimize o programa DataStream escrito pelo usuário em um gráfico de execução lógica e envie o gráfico de execução lógica otimizado para o JobManager.
- No modo Standalone, o processo Client é chamado de CLIFrontend.
JobManager
-
Um grafo de execução física é gerado de acordo com o grafo de execução lógica , que é responsável por coordenar a execução do trabalho do sistema, incluindo agendamento de tarefas, pontos de verificação de coordenação e recuperação de falhas.
-
No modo Autônomo:
- JobManager é responsável pelo gerenciamento de recursos do sistema Flink
- O nome do processo JobManager é StandaloneSessionClusterEntrypoint
Gerenciador de tarefas
-
Execute as tarefas atribuídas pelo JobManager e seja responsável pela leitura de dados, cache de dados e transmissão de dados com outros TaskManagers.
-
No modo autônomo
- TaskManager é responsável pelo gerenciamento de recursos do nó e abstrai a memória e outros recursos em vários TaskSlots para executar tarefas.
- O processo TaskManager é denominado TaskManagerRunner.
Comparação Entre Sistemas

Arquitetura do modo Yarn

Modo Autônomo vs Fio

10.2.2 Fluxo de execução do aplicativo

método de envio
No modo autônomo, quando os usuários usam o cliente para enviar aplicativos Flink, eles podem escolher anexado ou separado.
- Método de envio em anexo: o cliente mantém uma conexão com o JobManager e pode obter informações sobre a execução do aplicativo
- Método de envio desanexado: o cliente é desconectado do JobManager e não consegue obter informações sobre a execução do aplicativo
Fluxo de execução do aplicativo no modo Yarn



Enviar método em Yarn:
CliFrontend também são os métodos de envio Attached e Detached, mas o objeto conectado ou desconectado é YarnJobClusterEntrypoint, que é equivalente a appMaster.
10.3 Princípio de funcionamento
10.3.1 Geração e otimização do grafo de execução lógica
O programa DataStream escrito pelo usuário é analisado pelo cliente do Flink para gerar um grafo de execução lógica DAG.
**Otimização de encadeamento: **Mesclar operadores dependentes estreitos em operadores grandes.
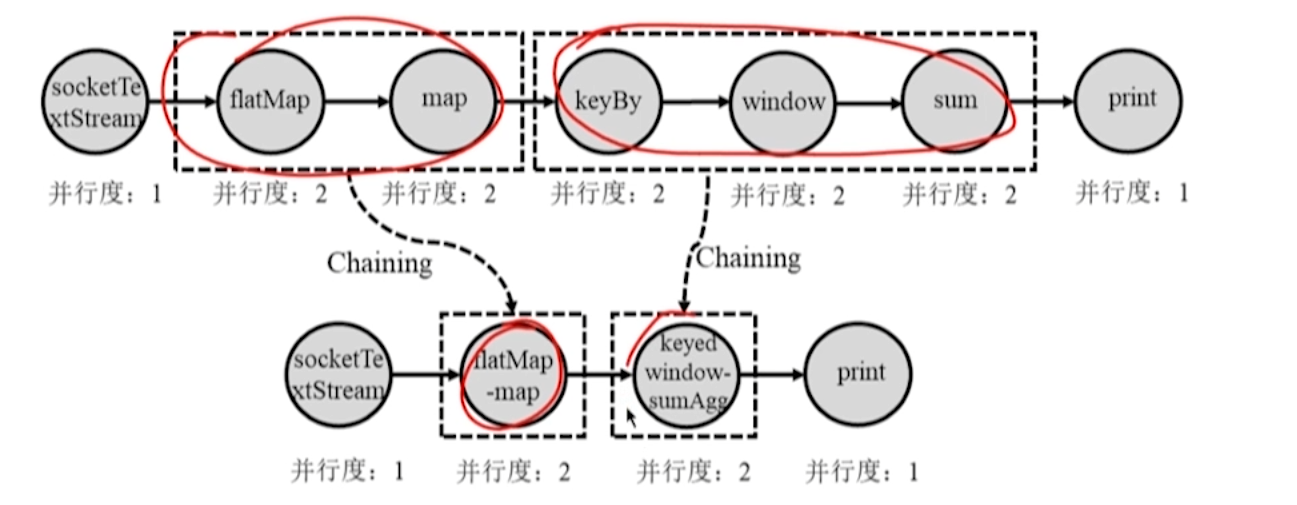
10.3.2 Geração do Gráfico de Execução Física e Atribuição de Tarefas
- Após o JobManager receber o gráfico de execução lógica enviado pelo Cient, ele converte o gráfico de execução lógica em um gráfico de execução física de acordo com o paralelismo dos operadores.
- Um nó no grafo de execução física corresponde a uma tarefa, que será atribuída ao TaskManager para execução.
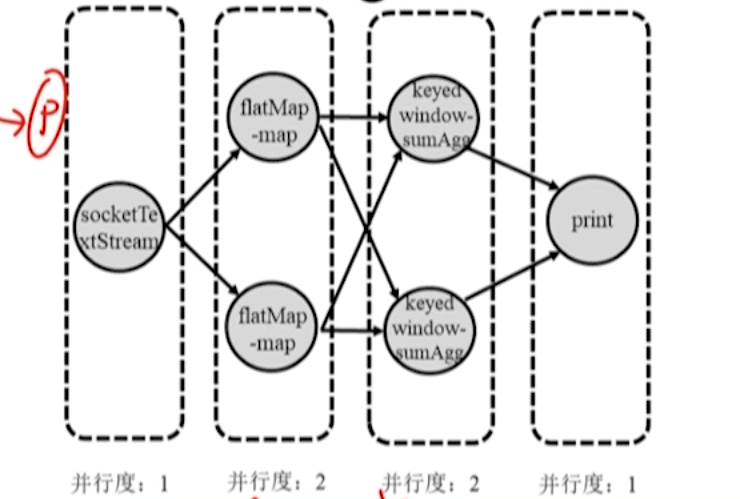
Atribuição de tarefas
JobManager atribui cada tarefa do operador ao TaskManager.
De acordo com a capacidade do slot de tarefa, tente colocar as instâncias do operador com relacionamento de transmissão de dados no mesmo slot de tarefa para manter a localidade de transmissão de dados.
Comparativamente ao Spark, no Spark, tanto o gráfico de execução lógica DAG quanto a etapa do plano de execução física são gerados no Driver, enquanto no Flink, o gráfico de execução lógica é concluído no Client e o gráfico de execução física é concluído pelo JobManager.
10.3.3 Transferência de dados entre tarefas não iterativas
Mecanismo de tubulação

Os dados não são armazenados no disco, mas apenas no buffer, portanto, se o downstream falhar, a cópia não poderá ser obtida do upstream.
Pipeline em Flink vs Spark
- Métodos de transmissão de dados entre diferentes tarefas no Flink
- No Spark, a mesma Tarefa dentro do Palco implementa a transmissão de dados entre vários operadores diferentes.
- O Spark Pipeline é semelhante ao Flink Chaining
Método de transmissão de dados entre tarefas
- Bloqueio da transmissão de dados: Todos os dados de uma Tarefa são processados e até gravados em disco antes de serem enviados para a Tarefa downstream.
- Transmissão de dados sem bloqueio: Uma Tarefa processa uma parte dos dados, que geralmente são armazenados no cache e depois enviados para a Tarefa downstream.

10.3.4 Transferência de dados entre tarefas de iteração
operador de iteração
- Um conjunto aninhado em um DAG que descreve um processo computacional.
- Há um loop dentro do iterador.
Realização de feedback de dados
- front end da iteração e final da iteração
- Duas tarefas estão no mesmo Gerenciador de Tarefas e a saída final pode ser usada novamente como entrada frontal.
iteração de streaming
- Parte do resultado de cada rodada de iteração é passada de volta como saída e a outra parte do resultado é usada como entrada da próxima rodada de cálculo de iteração, e o processo de iteração continuará.
- A próxima rodada de cálculos no front-end iterativo não depende de todos os registros que terminam na rodada anterior.
- Depois de receber o feedback do terminal, o front-end pode executar uma nova rodada de cálculo iterativo imediatamente e usar o método de pipeline para transmissão de dados.
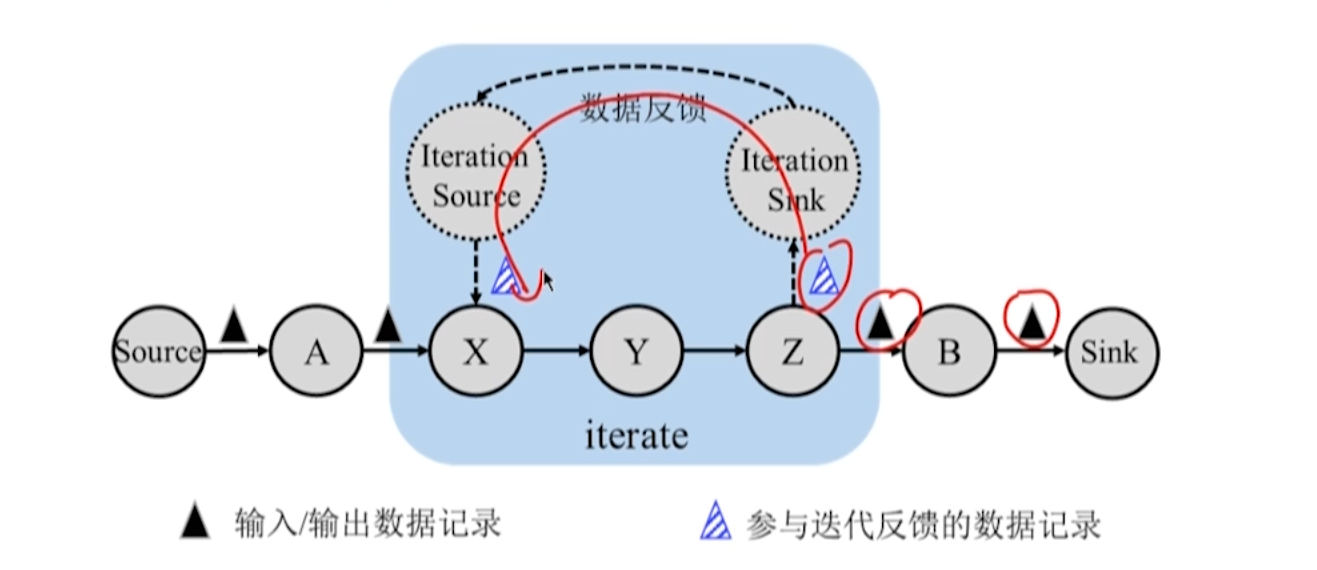
iteração em lote
- No cálculo iterativo em lote, todos os resultados de cada rodada de cálculo iterativo são geralmente a entrada da próxima rodada de cálculo iterativo, até que a condição de convergência seja satisfeita.
- O front end da iteração emite um registro especial para indicar o final da iteração.
- O front-end da iteração deve receber todos os registros no final antes de poder calcular uma nova rodada de iteração.
- O front-end tem um processo de bloqueio aguardando feedback do back-end e o mecanismo de pipeline não pode ser usado para transmissão de dados.
10.4 Mecanismo de tolerância a falhas
Falha do JobManager
- Falha na tarefa iterativa
- falha de tarefa não iterativa
10.4.1 Gestão do Estado
O que é estado?
O conteúdo que o operador de janela precisa manter.
PS: Observe que é necessário distinguir entre o estado do operador e o estado do processo/nó.
Por que o gerenciamento de estado é necessário?
-
Status de gerenciamento do programa do usuário
- HashMap, mas a tarefa onde o operador está localizado falha e o HashMap na memória é perdido.
- Para suportar a tolerância a falhas, é necessário escrever um programa para gravar o HashMap no disco para facilitar a recuperação de falhas. No entanto, diferentes estruturas de dados precisam ser salvas de acordo, o que é muito problemático.
-
Portanto, o gerenciamento de estado deve ser deixado para o sistema e não para o usuário.
**Status:** Uma estrutura de dados especial definida pelo sistema, usada para registrar os resultados dos cálculos dos operadores que precisam ser salvos.

Operador com estado vs Operador sem estado
- Stateful operator: Um operador com capacidade de memória, que pode reter os resultados do registro processado (como janelas).
- Operador sem estado: não possui capacidade de memória e considera apenas os registros atualmente processados (como mapa).
Gerenciamento de estado e tolerância a falhas
- Tolerância a falhas no nível do operador: salve o estado durante o tempo de execução, restaure e redefina o estado quando ocorrer uma falha e continue processando registros não salvos.
- Tolerância a falhas no nível DAG: Se o estado de todos os operadores for salvo como um ponto de verificação ao mesmo tempo, assim que ocorrer uma falha, todos os operadores redefinirão o estado de acordo com o ponto de verificação e processarão os registros não salvos.
10.4.2 Tolerância a Falhas para Processos Computacionais Não Iterativos
Em determinado momento, os registros processados pelo sistema de stream computing podem ser divididos em três tipos:
- Registros que foram processados
- registros sendo processados
- registros não processados
Embora não exista um relógio síncrono absoluto, o objetivo de salvar o estado do operador no ponto de verificação ao mesmo tempo é distinguir o primeiro tipo de registro dos dois últimos tipos de registro.
instantâneo de barreira assíncrona
**Algoritmo de Chandy-Lamport: ** Usado em sistemas distribuídos para salvar o estado do sistema.
Algoritmo instantâneo de barreira assíncrona
- O instantâneo salvo é o ponto de verificação
- Ao injetar barreiras nos dados de entrada e salvar instantâneos de forma assíncrona, o mesmo objetivo de salvar todos os estados do operador nos pontos de verificação ao mesmo tempo é alcançado.
barreira
O JobManager insere barreiras nos registros de entrada, e essas barreiras fluem com os registros downstream para tarefas computacionais.

assíncrono
Depois que uma tarefa alinhou a barreira identificada como n, ela pode continuar recebendo dados pertencentes ao ponto de verificação n+1.
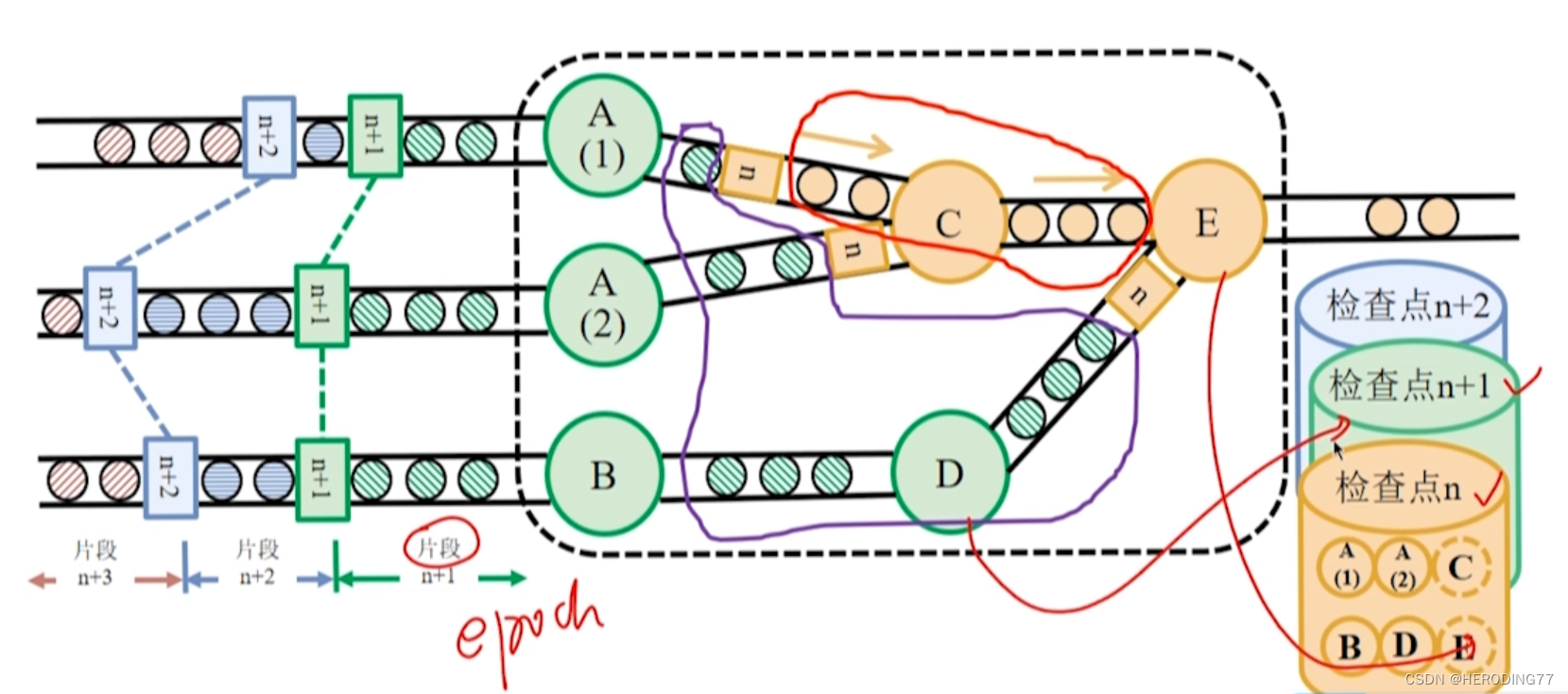
Armazenamento de estado Flink

Recuperação
-
quando ocorre uma falha
- O Flink escolhe o ponto de verificação completo mais recente n e redefine o estado de cada operador no sistema para o estado salvo no ponto de verificação.
- Releia os registros da fonte de dados que estão após a barreira n
-
A tolerância a falhas do Flink pode satisfazer exatamente uma vez a semântica de tolerância a falhas
10.4.3 Tolerância a Falhas no Processo de Cálculo Iterativo
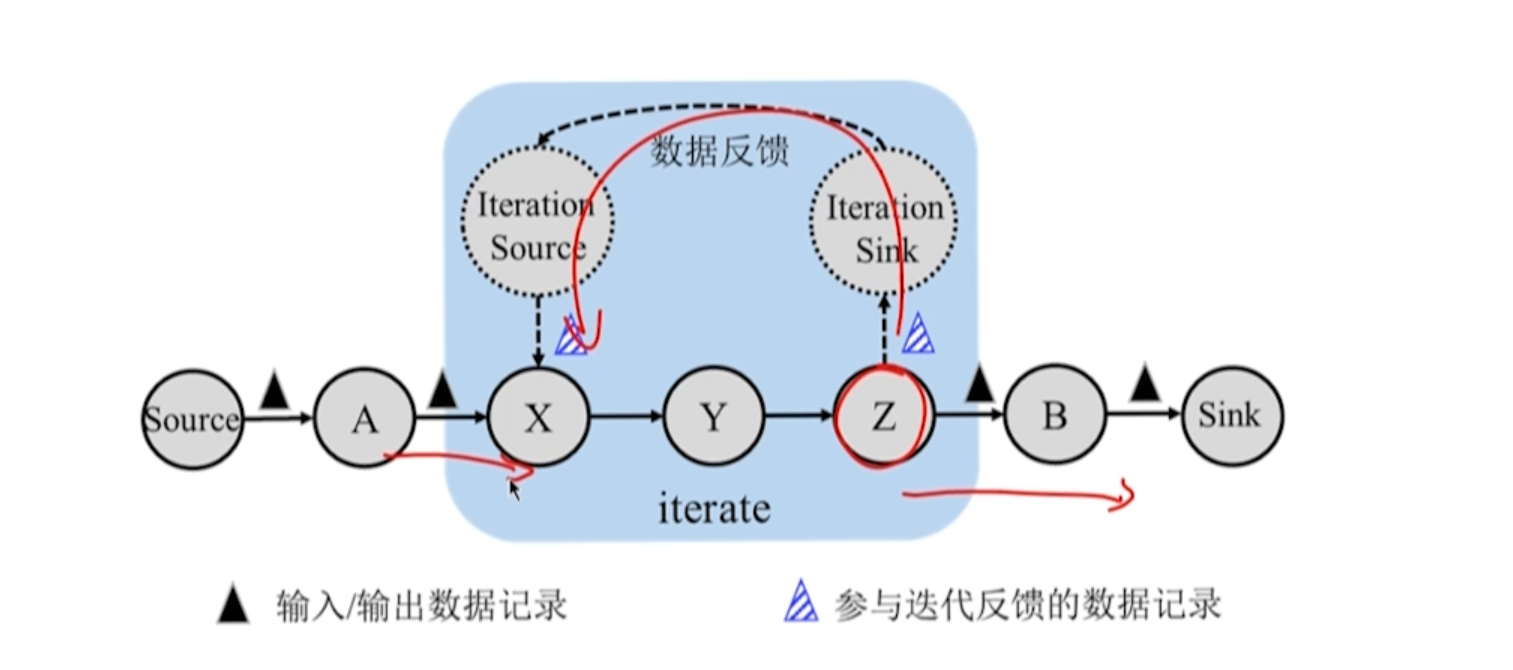
Nas iterações, as barreiras sozinhas não conseguem distinguir entre os casos pertencentes ao ponto de verificação n e ao ponto de verificação n+1.
De acordo com o algoritmo Chandy-Lamport, todos os registros no loop de feedback precisam ser mantidos em forma de log.
Ocorre uma falha, o sistema:
- Redefine os estados individuais do operador com base no ponto de verificação completo mais recente n.
- Releia os registros pertencentes à barreira n e os registros no log.
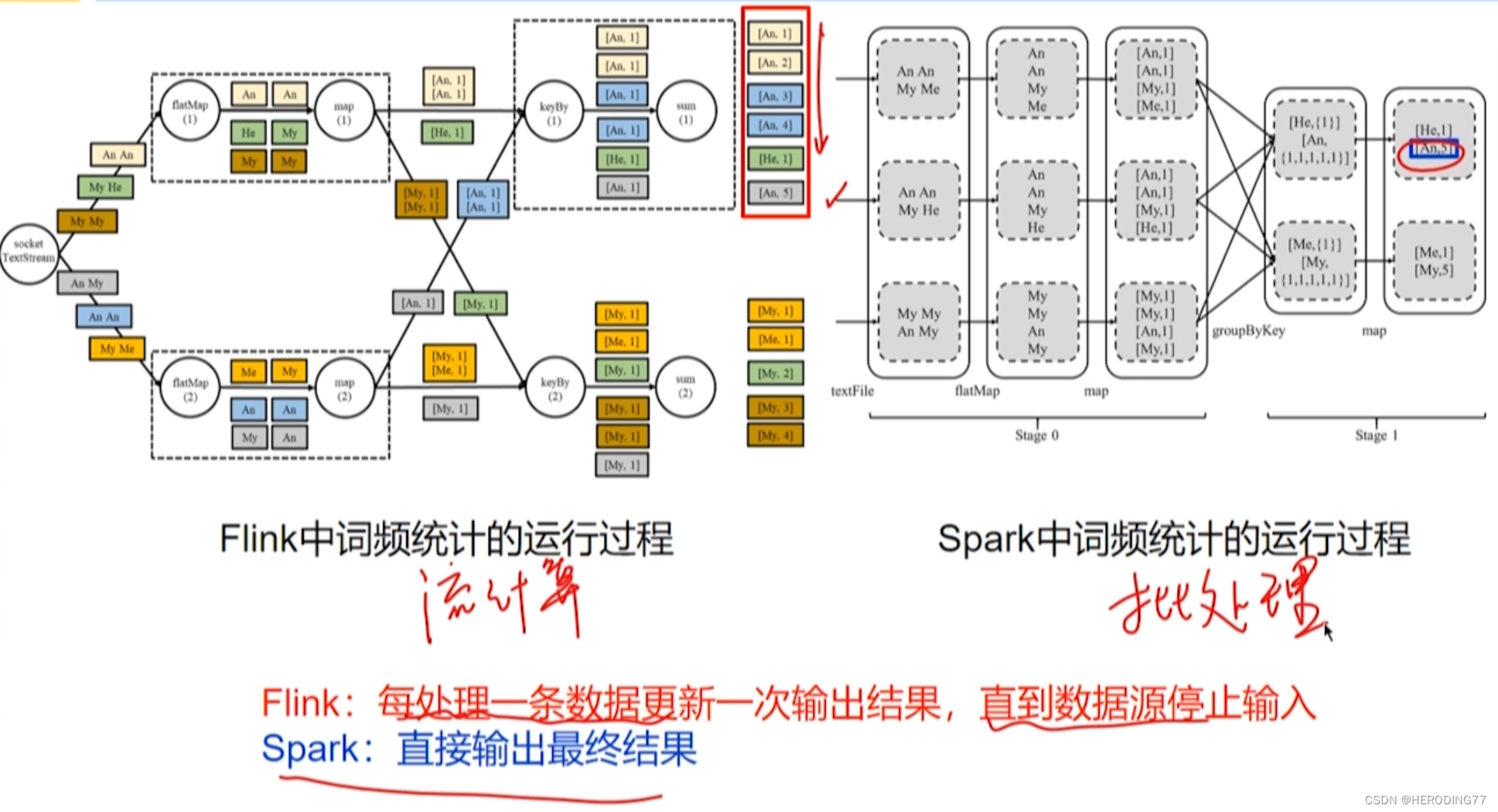
10.5 Exemplo de programação
Flink vs Faísca
Capítulo 11 Sistema de Processamento Gráfico Giraph
Giraph é uma solução para processamento de grafos em grande escala.
11.1 Pensamento de design
Bibliotecas de algoritmos de gráficos existentes ou sistemas MapReduce não possuem todas as seguintes características:
- Comum para algoritmos de processamento de gráficos
- Suporta processamento gráfico em grande escala
- própria tolerância a falhas
- Otimizado para processamento de gráficos
11.1.1 Modelo de Dados
Um gráfico consiste em vértices e arestas, e o Giraph representa os dados do gráfico de maneira semelhante a uma lista de adjacências. <vertexID,neighborID>Representa uma aresta cujo peso é peso.
11.1.2 Modelo de Cálculo
O Giraph usa um modelo de computação centrado no vértice. Os cálculos são executados apenas nos vértices.
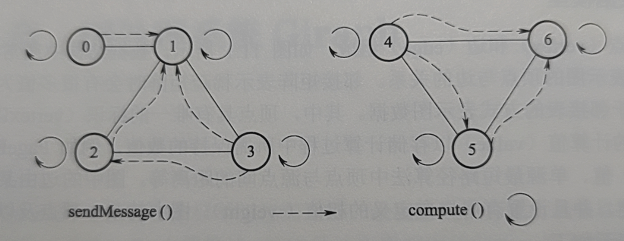
11.1.3 Modelo Iterativo
Giraph adota um modelo iterativo paralelo globalmente síncrono.

- Fase de cálculo local: Cada processador executa apenas cálculos locais nos dados armazenados na memória local.
- Fase de comunicação global: opera em quaisquer dados não locais.
- Fase de sincronização de cerca: Aguardando o fim de todos os comportamentos de comunicação.
O processo de cálculo do Giraph consiste em uma série de iterações de superpassos, e o processo de execução de cada superpasso é o seguinte:
- Na fase de computação local, cada processador chama um método de computação definido pelo usuário para cada vértice. Este método pode ler a mensagem enviada para um determinado vértice V no superpasso S-1 e descrever a operação que o vértice V precisa realizar no superpasso S. Durante este processo, o valor calculado do vértice e o peso de sua aresta de saída são modificados.
- Na fase de comunicação global, o método sendMessage chamado para cada vértice contém o conteúdo que ele precisa enviar para os outros vértices. O conteúdo dessas mensagens é transmitido entre cada processador por meio de comunicação, de modo que as mensagens sejam enviadas para outros vértices, e outros vértices as utilizem para o cálculo do próximo superpasso S+1.
- Durante a fase de sincronização da cerca, cada vértice espera que todos os outros vértices concluam a computação e enviem mensagens.

A figura acima é a tarefa de atualização do número, ou seja, o rótulo de cada componente conectado é atualizado para o número mínimo no grafo conectado. (a) e (b) são um processo de cálculo local (número de inicialização) e comunicação global em um superpasso. As quatro superetapas a seguir são o processo completo de atualização de numeração.
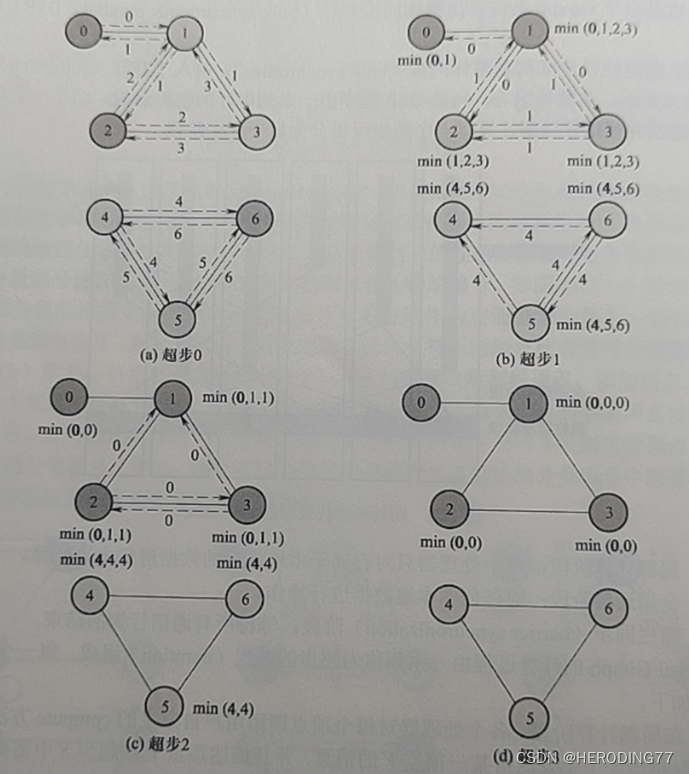
Como o processo de cálculo de algoritmos como componentes conectados e caminho mais curto de fonte única satisfaz a característica de ordem parcial descendente de obter o valor mínimo, ele pode julgar automaticamente se a iteração para (sem nova atualização de mensagem), mas para PageRank e K-means algoritmo de agrupamento não Para atender a essa característica, geralmente é necessário definir o número máximo de superpassos para controlar o processo iterativo.
11.2 Arquitetura
11.2.1 Diagrama de Arquitetura
A arquitetura Pregel (a fonte de Giraph) consiste em Mestre e Trabalhador. Entre eles, o sistema divide o grafo para formar várias partições. Cada Worker é responsável por uma ou mais partições e é responsável pelas tarefas de cálculo das partições. O Master atua como administrador e é responsável por coordenar a execução das tarefas de cada Trabalhador.
Trabalhador
As informações de partição governadas por um Worker são armazenadas na memória e as informações de vértice de partição incluem valores de vértice e aresta, mensagens e sinalizadores.
- Valores de vértice e aresta: contém o valor de cálculo atual do vértice, uma lista de arestas de saída a partir do vértice e cada aresta de saída contém o ID do vértice de destino e o valor da aresta.
- Mensagens: Contém todas as mensagens recebidas enviadas para este vértice.
- Bit sinalizador: marca se o vértice está ativo. Se um vértice recebe uma mensagem em S, ele está ativo em S+1.
Mestre
Coordene os trabalhadores para executar tarefas, cada trabalhador se registra com o mestre e o mestre atribui um ID exclusivo ao trabalhador. O mestre mantém o ID, o endereço e as informações de partição do trabalhador.
Girafa
A implementação do Giraph é emprestada da estrutura MapReduce. Implemente toda a lógica de processamento de gráficos no método run para iniciar a tarefa Map. Da perspectiva do MapReduce, a execução do trabalho Giraph apenas inicia a tarefa Map.
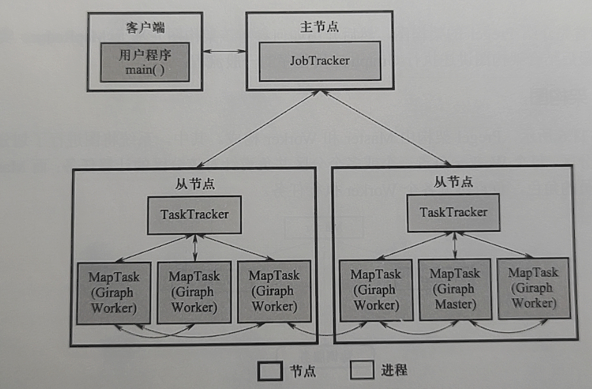
Use o serviço de coordenação do ZooKeeper para selecionar um mestre e determinar uma tarefa de mapa como mestre.
11.2.2 Fluxo de Execução do Aplicativo
- O cliente carrega as informações de configuração do trabalho, pacote jar, etc. contidos no aplicativo Giraph escrito pelo usuário para o sistema de arquivos compartilhados (HDFS);
- O cliente envia o trabalho para o JobTracker e informa o JobTracker sobre a localização das informações do trabalho;
- O JobTracker lê as informações do trabalho, gera uma série de tarefas de mapa e as agenda para o TaskTracker com slots livres;
- TaskTracker inicia o processo Child para executar a tarefa Map de acordo com as instruções do JobTracker, e a tarefa Map lê os dados de entrada de um sistema de arquivos compartilhado, como HDFS ou outros sistemas de armazenamento que armazenam dados gráficos;
- Múltiplos Mapas são selecionados através do ZooKeeper. Uma das tarefas do Mapa é o Mestre do Giraph, e as demais são Trabalhadores. O Mestre e o Trabalhador coordenam a execução dos trabalhos do Giraph através do ZooKeeper;
- O JobTracker obtém as informações de progresso do mestre e do trabalhador de Giraph do TaskTracker;
- Após a conclusão da tarefa, o resultado é gravado no sistema de arquivos compartilhados, indicando que a tarefa foi concluída.
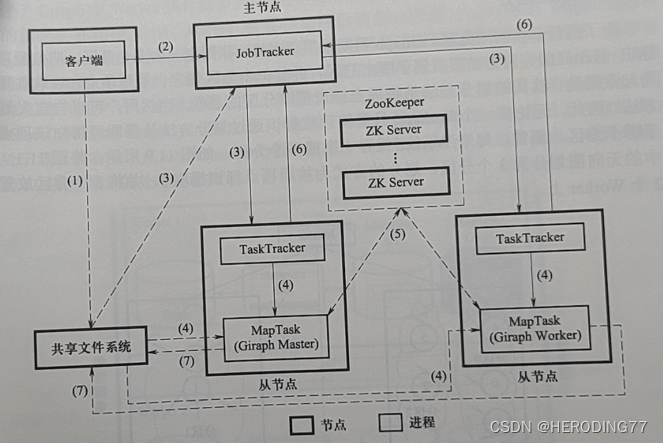
Para MapReduce, embora enviar trabalhos e iniciar tarefas de Mapa sejam iguais aos trabalhos de MapReduce comuns, no processo de cálculo iterativo, MapReduce precisa enviar continuamente trabalhos de MapReduce e ler e gravar repetidamente de HDFS (baixa eficiência), enquanto Giraph apresenta apenas um trabalho de começando a terminar, a iteração começa a inserir dados e a iteração termina para gravar o resultado de saída.
11.3 Princípio de funcionamento
O processo de trabalho do Giraph pode ser dividido em três etapas: entrada de dados, cálculo iterativo e saída de dados.
11.3.1 Particionamento de Dados
O Giraph precisa dividir um grafo em múltiplas partições de acordo com os vértices, ou seja, determinar a qual partição o vértice pertence de acordo com o identificador de vértice, e cada partição contém uma série de vértices e arestas a partir desses vértices.
O particionamento dos dados de entrada é muitas vezes inconsistente com o particionamento exigido pelo Giraph. O particionamento de dados é, na verdade, o ajuste dos dados de entrada ao particionamento desejado do Giraph. Este processo é realizado em conjunto pelo Mestre e pelo Trabalhador.
11.3.2 Cálculo do Superstep
Quando a superetapa começa, o Worker chama o método de cálculo para cada vértice e atualiza o valor calculado do vértice de acordo com a mensagem da superetapa anterior obtida.
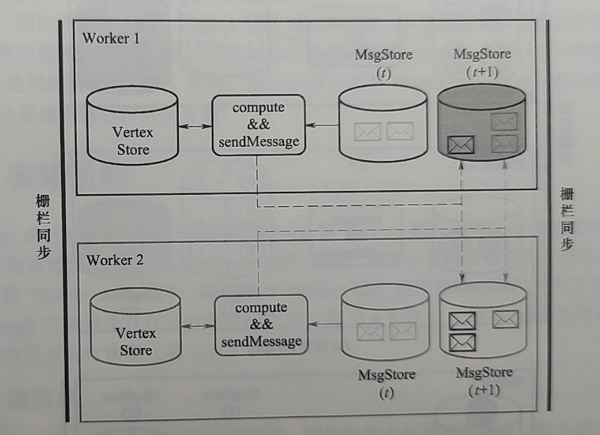
VertexStore armazena identidades de vértice, valores calculados e informações de borda. MsgStore(t) armazena as mensagens obtidas por cada vértice na fase de comunicação global do superpasso t-1, e esta parte é utilizada para o cálculo dos vértices do superpasso t. MsgStore(t+1) armazena as mensagens obtidas por cada vértice na fase de comunicação global do superpasso t, e esta parte é utilizada para o cálculo dos vértices do superpasso t+1.
Semelhante à mensagem, o sinalizador também armazena duas cópias, StatStore(t) e StatStore(t+1), que armazenam os vértices ativos em superstep t e superstep t+1, respectivamente.
Em geral, o processamento de um determinado vértice no superpasso t é o seguinte:
- De acordo com um vértice ativo em StatStore(t), leia a mensagem pertencente ao vértice de MsgStore(t) e chame o método Compute para atualizar VertexStore;
- Envie o valor calculado atualizado para os vértices vizinhos na forma de mensagem;
- Se nenhum outro vértice enviar uma mensagem, defina StatStore(t+1) para o estado inativo do vértice, caso contrário, a mensagem será armazenada em MsgStore(t+1) para a próxima superetapa e StatStore(t+1) O vértice será tornado ativo.
Para reduzir a sobrecarga de transmissão e buffer, o Worker combina várias mensagens enviadas para o mesmo vértice em uma mensagem ao enviar mensagens.
Se o usuário usar Aggregator. Cada vértice pode fornecer dados para um Aggregator, e o Worker relata o conteúdo para o Master, e o Master resume e executa uma operação de agregação para gerar o valor do próximo cálculo da superetapa.
11.3.3 Controle síncrono
O controle síncrono garante que todos os trabalhadores concluam a superetapa t e, em seguida, entrem na superetapa t+1 e concluam a sincronização por meio do Zookeeper.
Terminada a superetapa, se o número de nodos ativos recebidos pelo Mestre for 0, significa que o processo de iteração acabou.Neste momento, o Mestre notifica o Worker para armazenar persistentemente os resultados dos cálculos.
11.4 Mecanismo de tolerância a falhas
Falha do mestre, toda a execução do trabalho falha, falha do trabalhador, reverte para o ponto de verificação mais recente para recuperação.
11.4.1 Pontos de Verificação
O Giraph permite que os usuários definam o intervalo para escrever checkpoints, ou seja, quantos supersteps escrever checkpoints. Quando a superetapa que precisa definir um ponto de verificação é iniciada, o Mestre notifica todos os Trabalhadores para gravar as informações da partição sob sua jurisdição no HDFS e salva o valor do Agregador ao mesmo tempo.
11.4.2 Recuperação de Falha
Se um ponto de verificação for definido, volte para a superetapa em que o ponto de verificação mais recente foi localizado, caso contrário, reinicie a computação.
Nesse processo, mesmo que apenas um Worker falhe, todos os Workers devem ser recarregados, resultando em cálculo duplo.
O artigo de Pregel propõe uma estratégia de recuperação parcial , que limita a operação de recuperação à partição perdida, melhorando assim a eficiência da recuperação. Ou seja, a mensagem enviada é gravada na forma de um log ao mesmo tempo, o Worker recém-iniciado apenas recupera a partição perdida do checkpoint, e o outro Worker repete o log para fazer o novo Worker recalcular para a superetapa onde o falha ocorreu.