Por Sherry Ger

O que é o ChatGPT?
Em primeiro lugar, o ChatGPT é incrível! Ele pode ajudá-lo a trabalhar com mais eficiência - desde resumir um documento de 10.000 palavras até fornecer uma lista de diferenças entre produtos concorrentes, entre muitas outras tarefas.

ChatGPT é o mais famoso modelo de linguagem grande ( LLM ) baseado na arquitetura Transformer . Mas você pode ter ouvido falar de outros LLMs, incluindo BERT (Representação de Codificador Bidirecional do Transformer), Bard (Modelo de Linguagem para Aplicativos Conversacionais) ou LLaMA (LLM Metaartificial Intelligence). Os LLMs têm várias camadas de redes neurais que trabalham juntas para analisar o texto e prever a saída. Eles foram treinados com tradutores da esquerda para a direita ou bidirecionais que maximizam a probabilidade de seguir e preceder palavras no contexto para descobrir o que pode vir a seguir em uma frase. Os LLMs também possuem um mecanismo de atenção que lhes permite focalizar seletivamente certas partes do texto para identificar as partes mais relevantes. Por exemplo, Rex é fofo e ele é um gato. Nesta frase, "ele" refere-se a "gato" e "rex".
mais é mais
Modelos de linguagem grandes geralmente são comparados por número de parâmetros - quanto maior, melhor. O número de parâmetros é uma medida do tamanho e complexidade do modelo. Quanto mais parâmetros um modelo tiver, mais dados ele poderá processar, aprender e gerar. No entanto, ter mais parâmetros também significa exigir mais recursos de computação e memória. Durante o treinamento, os parâmetros são aprendidos ou atualizados usando um algoritmo de otimização que tenta minimizar o erro ou perda entre a saída prevista e a saída real. Ao ajustar parâmetros, um modelo pode melhorar seu desempenho e precisão em uma determinada tarefa ou domínio.
O treinamento LLM é caro
Os LLMs modernos têm bilhões de parâmetros treinados em trilhões de tokens a um custo de milhões de dólares. O treinamento de um LLM envolve a identificação do conjunto de dados, certificando-se de que o conjunto de dados seja grande o suficiente para executar funções como um ser humano, determinando as configurações da camada de rede, usando o aprendizado supervisionado para aprender informações no conjunto de dados e, finalmente, o ajuste fino. Desnecessário dizer que o retreinamento de LLMs em dados específicos de domínio também é muito caro.
Como funciona o modelo GPT?
Um modelo de transformador pré-treinado generativo (GPT) é uma rede neural que usa a arquitetura do transformador para aprender com grandes quantidades de dados de texto. O modelo tem dois componentes principais: um codificador e um decodificador. Um codificador pega o texto de entrada e o transforma em uma sequência de vetores chamados embeddings, que representam o significado e o contexto de cada palavra/subpalavra no número. No entanto, o decodificador gera o texto de saída prevendo a próxima palavra na sequência com base na incorporação e nas palavras anteriores.
Os modelos GPT usam uma técnica chamada "atenção" para focar nas partes mais relevantes do texto de entrada e saída e capturar dependências e relacionamentos de longo alcance entre as palavras. O modelo é treinado usando um grande corpus de texto como entrada e saída e minimizando a diferença entre palavras previstas e reais. Ele pode então ser ajustado ou adaptado a tarefas ou domínios específicos usando conjuntos de dados menores e mais especializados.
marca (símbolo)
Tokens são as unidades básicas de texto ou código que o LLM usa para processar e gerar idiomas. Os tokens podem ser caracteres, palavras, subpalavras ou outros fragmentos de texto ou código, dependendo do método ou esquema de tokenização escolhido. Eles recebem valores numéricos ou identificadores e são organizados em sequências ou vetores, que são então inseridos ou gerados no modelo. A tokenização é o processo de segmentar o texto de entrada e saída em unidades menores que podem ser processadas por um modelo LLM.
Por exemplo, a frase "Uma rápida raposa marrom pula sobre um cachorro preguiçoso" pode ser tokenizada com os seguintes tokens: "a", "rápido", "marrom", "raposa", "pula", "over", "a ", ", " preguiçoso” e “cachorro”.
Incorporações
Incorporações são vetores ou matrizes de números que representam o significado e o contexto dos tokens processados e gerados pelo modelo. Eles são derivados dos parâmetros do modelo e são usados para codificar e decodificar o texto de entrada e saída. As incorporações ajudam o modelo a entender as relações semânticas e sintáticas entre os tokens e a gerar um texto mais relevante e coerente. Eles são uma parte importante da arquitetura Transformer usada por modelos baseados em GPT. Eles também podem variar em tamanho e dimensões, dependendo do modelo e da tarefa.
Os LLMs pré-treinados contêm pelo menos dezenas de milhares de incorporações de palavras, tokens e termos. Por exemplo, ChatGPT-3 tem um vocabulário de 14.735.746 palavras e uma dimensão de 1.536. O seguinte é de um pequeno modelo chamado distilbert-based-uncased. Embora este seja um modelo pequeno, ainda tem 100 megabytes de tamanho.
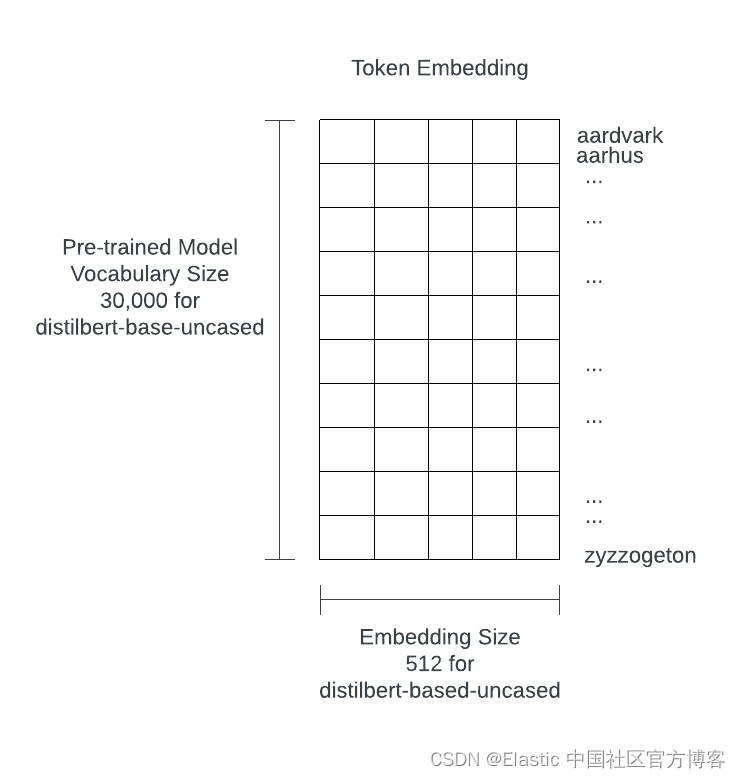
Transformador - Transformador
Um modelo Transformer é uma rede neural que aprende contexto, ou significado, rastreando relacionamentos em dados sequenciais, como as palavras nesta frase. Em sua forma mais simples, um transformador recebe uma entrada e prevê uma saída. Dentro do transformador, há uma pilha de codificadores e uma pilha de decodificadores.
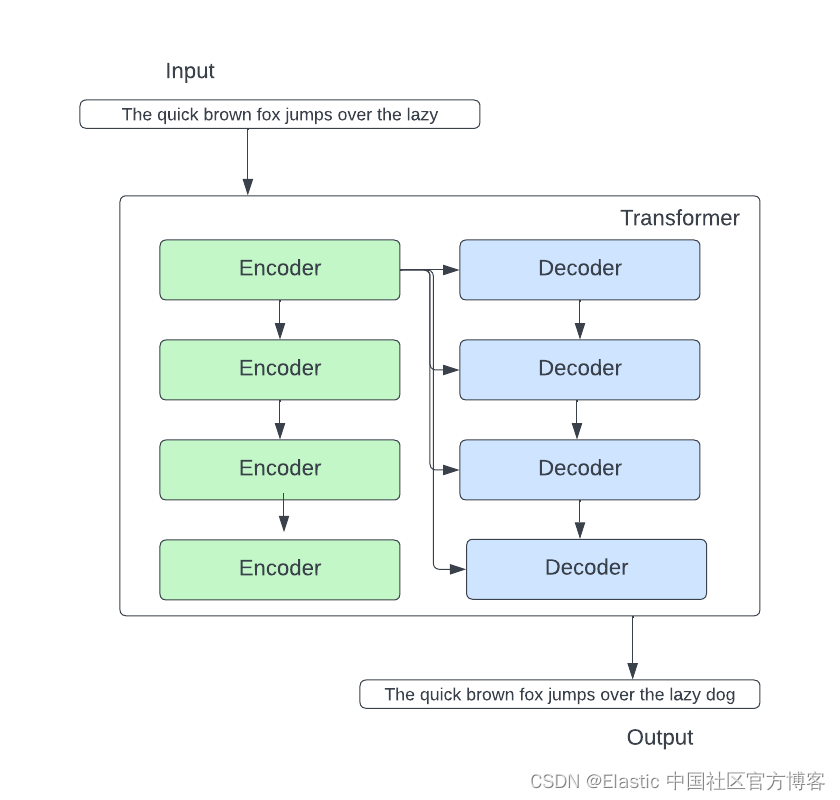
Vamos nos aprofundar no bloco codificador e no bloco decodificador. No bloco codificador, existem dois componentes importantes: rede neural de auto-atenção e rede neural de alimentação direta.

A camada de auto-atenção é crucial porque se baseia na " compreensão " da palavra atual por palavras anteriores relacionadas à palavra atual . Por exemplo, "isso" refere-se à galinha em "a galinha atravessou a rua porque quer saber do que se tratam as piadas".
Outra camada importante no codificador é a rede neural feed-forward (FFNN). FFNN prevê palavras que ocorrem após o token atual.
Passando para o lado do decodificador, a camada de atenção do codificador-decodificador vem à tona. A camada do codificador-decodificador concentra-se nas partes relevantes da frase de entrada, levando em consideração a saída das camadas abaixo dela e a pilha do codificador.
Juntando tudo:
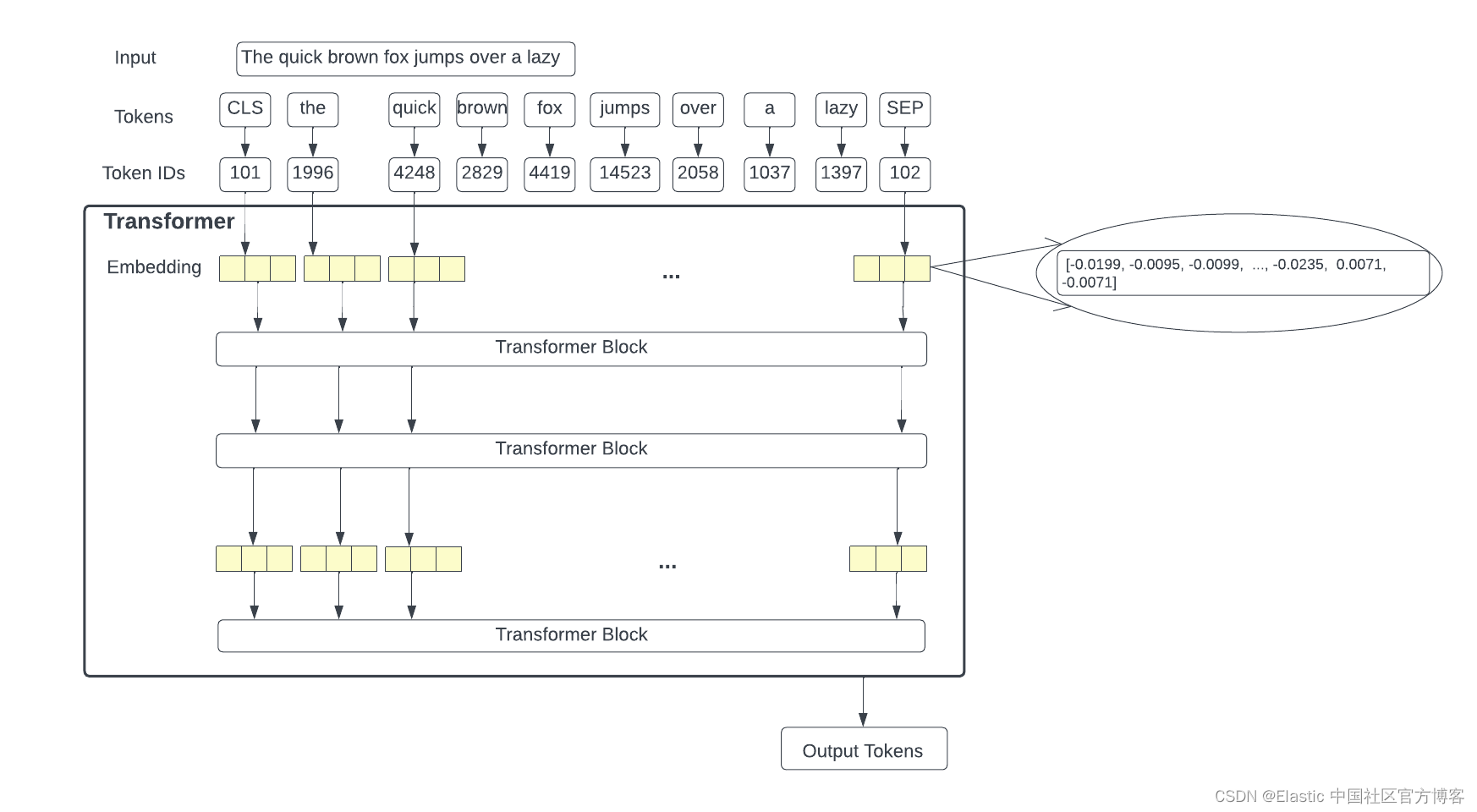
Pegaremos a entrada, tokenizaremos a entrada e obteremos o ID do token do token, que então transformaremos em uma incorporação para cada token. A partir daí, passamos as incorporações para o bloco do transformador. No final do processo, o transformador preverá uma sequência de tokens de saída. A figura abaixo detalha o modelo do transformador.

A pilha do decodificador gera um vetor de números de ponto flutuante. A camada linear projeta os vetores de ponto flutuante produzidos pela pilha do decodificador em vetores maiores chamados vetores de logits. Se o modelo tiver um vocabulário de 10.000 palavras, uma camada linear mapeia a saída do decodificador para 10.000 vetores unitários. Uma camada Softmax converte essas pontuações de vetores logit em probabilidades (ambas positivas) e somam 100%. A célula com maior probabilidade é selecionada e a palavra associada a ela é gerada como saída desta etapa.
Desafios para ChatGPT e LLMs
- Os dados nos quais eles são treinados não têm conhecimento de domínio e podem estar desatualizados. Por exemplo, alucinação é dar respostas erradas como se estivessem corretas, o que é comum em LLMs.
- O próprio modelo não possui uma capacidade natural de aplicar ou extrair filtros da entrada. Os exemplos incluem hora, data e filtros geográficos.
- Não há controle de acesso sobre o conteúdo do documento que os usuários podem visualizar.
- Existem sérias preocupações com privacidade e controle de dados confidenciais.
- Treinar com seus próprios dados e mantê-los atualizados é lento e muito caro.
- ChatGPT ou outros LLMs podem demorar para responder. Normalmente, o Elasticsearch® responde a consultas em milissegundos. Para LLMs, pode levar alguns segundos para obter uma resposta. Mas isso é de se esperar, já que os LLMs estão realizando tarefas complexas. Além disso, o ChatGPT cobra pelo número de tokens processados. Se você tiver uma carga de trabalho de alta velocidade, como uma pesquisa de itens da Black Friday para um site de comércio eletrônico, ela pode ficar muito cara muito rapidamente. Sem mencionar que pode não ser capaz de atender ao SLA (Acordo de Nível de Serviço) <10 ms).
- Explicar como o ChatGPT ou outros LLMs chegam aos resultados da consulta é difícil, se não impossível. Além das alucinações, o ChatGPT e outros LLMs podem gerar respostas irrelevantes e é difícil determinar como o modelo pode gerar a resposta errada.
Onde o Elasticsearch é adequado?
Além da pesquisa de vetores nativos por meio de kNN e aNN (kNN é a distância exata do vizinho mais próximo para todos os documentos e aNN é um valor aproximado), o Elasticsearch também suporta métodos de recuperação de informações bag of words (bag of words) e BM25 . Para aNN, o Elasticsearch usa o algoritmo HNSW (Hierarchical Navigable Small World) para calcular as distâncias aproximadas dos vizinhos mais próximos. A Elastic alivia muitos dos problemas do LLM enquanto permite que nossos usuários aproveitem todas as vantagens que o ChatGPT e outros LLMs podem oferecer.
O Elasticsearch pode ser usado como um banco de dados vetorial e realizar pesquisas híbridas em texto e dados vetoriais. Quando o Elasticsearch é usado com LLMs, ele pode fornecer vantagens distintas em três modos:
- Forneça contexto aos seus dados e integre-se ao ChatGPT ou outros LLMs
- Permite que você traga seus próprios modelos (quaisquer modelos de terceiros)
- Use o modelo integrado Elastic Learned Sparse Encoder
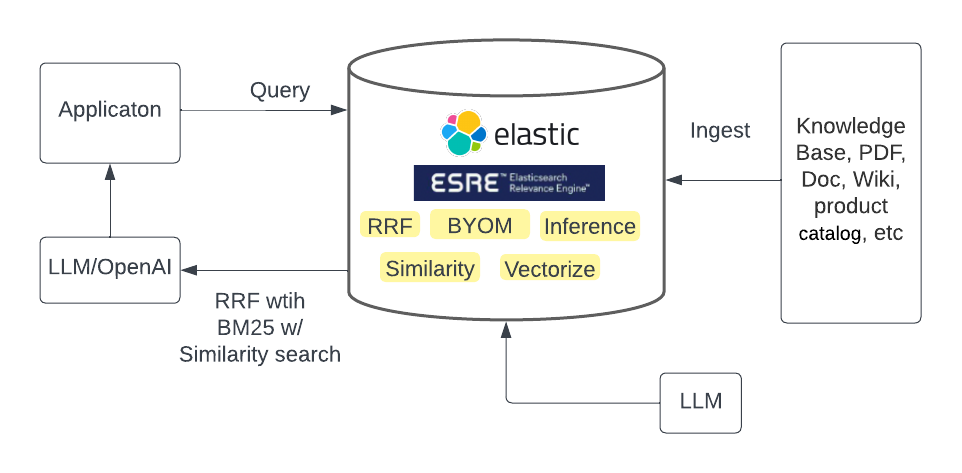
Abordagem 1: Forneça contexto aos seus dados e integre com ChatGPT ou outros LLMs
Veja como dissociar LLMs de dados enquanto integra com IA generativa.
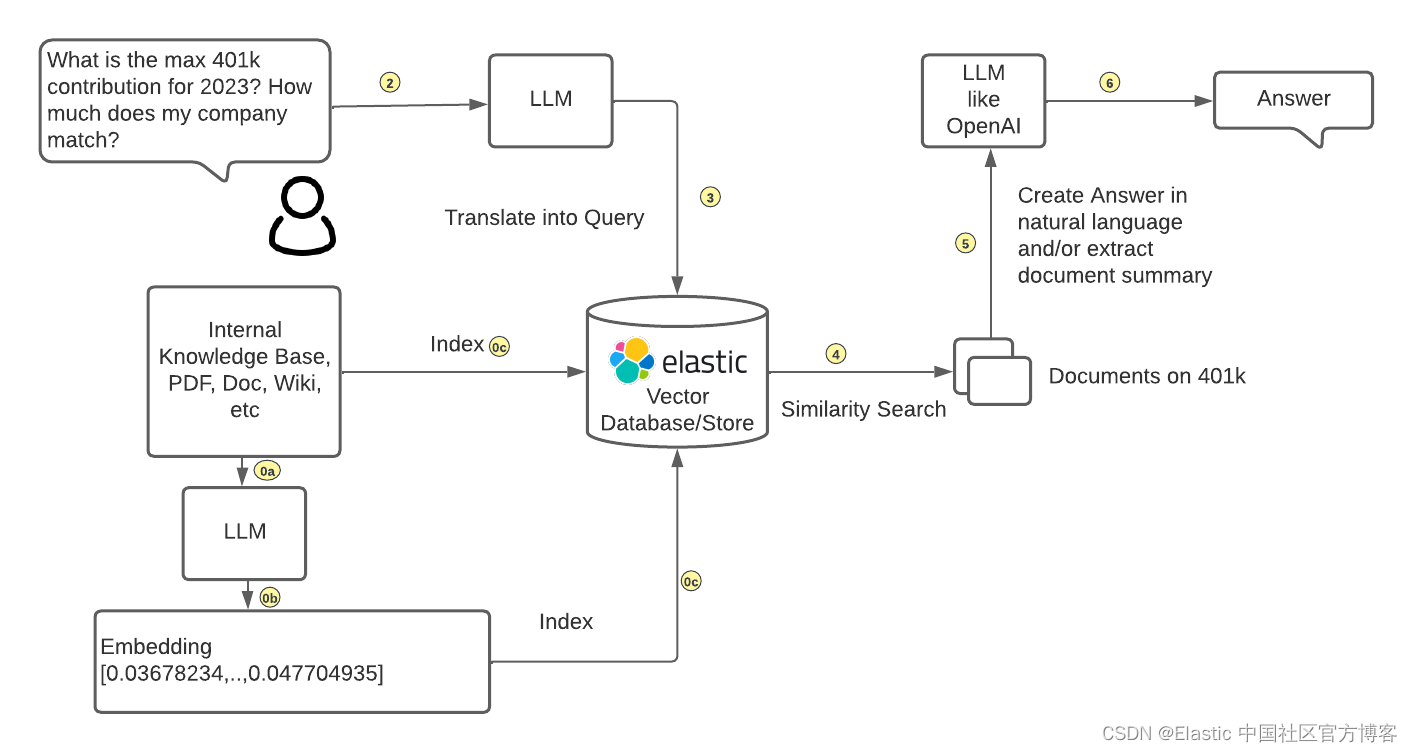
Os clientes podem trazer suas próprias incorporações geradas pelo LLM e inserir seus dados no Elasticsearch junto com as incorporações. Os clientes podem alimentar os resultados da pesquisa de similaridade de seus próprios dados armazenados no Elasticsearch (o contexto das perguntas do usuário) para o ChatGPT ou outros LLMs para criar respostas baseadas em linguagem natural para os usuários.
Além disso, o recém-lançado Reciprocal Rank Fusion (RRF) permite que os usuários realizem pesquisas híbridas, onde os resultados da pesquisa podem ser combinados e classificados. Por exemplo, o método BM25 pode filtrar documentos relevantes, bem como pesquisa vetorial para fornecer os melhores documentos. Com o RRF, os clientes podem obter os melhores resultados de pesquisa localmente por meio do Elasticsearch, em vez de por meio de seus próprios aplicativos, o que reduz bastante a complexidade do aplicativo e os custos de manutenção.
Método 2: traga seu próprio modelo
O recém-lançado Elasticsearch Relevance Engine ™ ( ESRE ™ ) oferece a capacidade de ter seu próprio LLM. Por meio do aprendizado de máquina, esse recurso já está disponível há algum tempo. A equipe de aprendizado de máquina do Elasticsearch vem construindo a infraestrutura para integrar modelos baseados no Transformer. A partir da versão 8.8 , você pode ingerir e consultar por meio da API de pesquisa como de costume no Elasticsearch. O melhor de tudo é que você pode combinar métodos de pesquisa híbridos com RRF, o que fornece correlações ainda melhores. Como os modelos são gerenciados e integrados ao Elasticsearch, a complexidade operacional pode ser reduzida enquanto se obtém os resultados de pesquisa mais relevantes.
Essa abordagem exige que os usuários saibam qual modelo é melhor para seu caso de uso e relacionamento comercial com a Elastic.
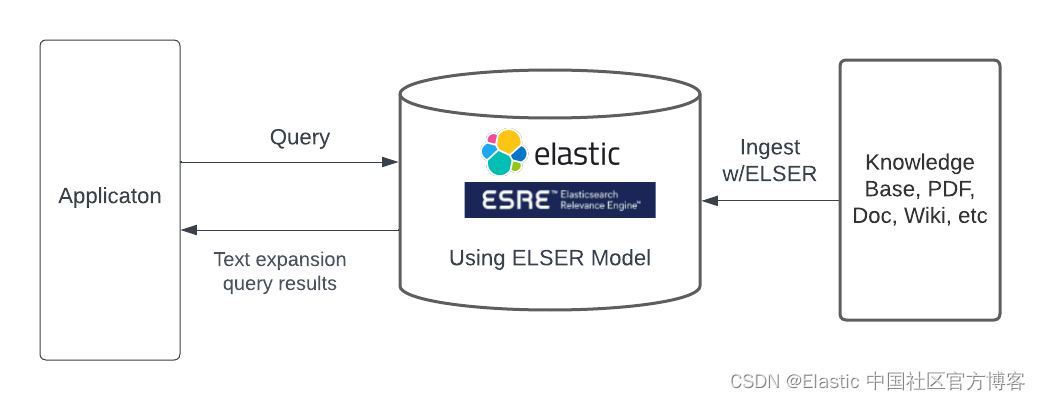
Método 3: Use o modelo de codificador esparso integrado
O Elastic Learned Sparse Encoder é o modelo de linguagem pronto para uso da Elastic, que supera o SPLADE (SParse Lexical And Expansion Model), que em si é um modelo de última geração. O Elastic Learned Sparse Encoder resolve o problema de incompatibilidade de vocabulário, em que os documentos podem ser relevantes para uma consulta, mas não contêm nenhum termo que apareça na consulta. Um exemplo de incompatibilidade pode ser que, se perguntarmos " como as empresas americanas ajudaram nos esforços da Covid-19 ", o fabricante do ventilador pode não aparecer nos resultados da consulta.
Assim como outros endpoints de pesquisa, o Elastic Learned Sparse Encoder pode ser acessado por meio de uma consulta text_expansion. O Elastic Learned Sparse Encoder permite que nossos usuários iniciem pesquisas de IA generativas de última geração com um clique e produzam resultados instantaneamente. O Elastic Learned Sparse Encoder também é um recurso comercial da Elastic.
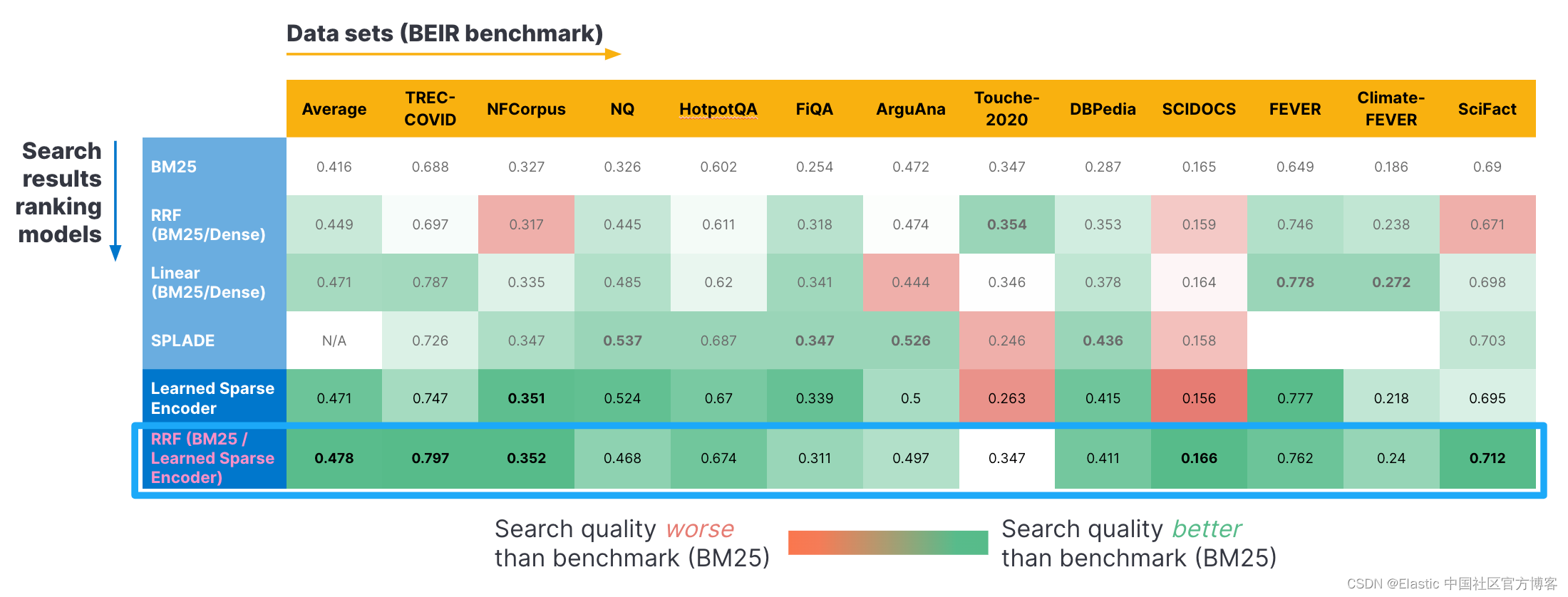
Aqui estão alguns resultados de benchmark usando o benchmark BEIR. Usamos vários conjuntos de dados normalizados (eixo horizontal) e aplicamos diferentes métodos de recuperação (eixo vertical). Como você pode ver, a combinação de BM25 e nosso codificador esparso aprendido usando RRF retorna a melhor pontuação de correlação. Quando consideradas individualmente, essas pontuações para RRF superam o modelo SPLADE e nosso modelo Learned Sparse Encoder (ELSER). Postamos mais detalhes em nosso blog aqui .
Termos e definições
rede neural (NN)
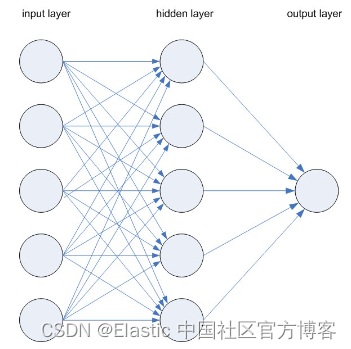
Cada nó é um neurônio. Pense em cada nó individual como seu próprio modelo de regressão linear, consistindo em dados de entrada (dados), pesos (pesos), viés (viés) (ou limite - limite) e saída. Uma representação matemática pode ser assim:
∑wixi + bias = w1x1 + w2x2 + w3x3 + bias
output = f(x) = 1 if ∑w1x1 + b>= 0; 0 if ∑w1x1 + b < 0Uma vez que a camada de entrada é determinada, os pesos (w) são atribuídos. Esses pesos ajudam a determinar a importância de qualquer variável, com variáveis maiores contribuindo mais para a saída do que outras entradas. Todas as entradas são então multiplicadas por seus respectivos pesos e somadas. Em seguida, a saída passa por uma função de ativação, que determina a saída. Se essa saída exceder um determinado limite, ela ativa o nó e passa os dados para a próxima camada da rede. Isso faz com que a saída de um nó se torne a entrada do próximo nó. Esse processo de passar dados de uma camada para a próxima é uma rede de alimentação direta. Este é apenas um tipo de rede neural.
Parâmetros LLM
Os pesos são valores que definem a força das conexões entre os neurônios em diferentes camadas do modelo. O viés é um valor adicional adicionado à soma ponderada das entradas antes de passar pela função de ativação.
SPLASH
SPLADE é um modelo de interação tardia. A ideia por trás do modelo SPLADE é que usar um modelo de linguagem pré-treinado como o BERT pode identificar conexões entre palavras e usar esse conhecimento para aprimorar incorporações de vetores esparsos. Você o usa quando tem um documento que cobre um tópico amplo (como um artigo da Wikipedia sobre filmes da Segunda Guerra Mundial) - inclui o enredo, os atores, a história e o estúdio que lançou o filme.
Usando apenas técnicas de recuperação incorporadas, a relevância dos documentos para as consultas torna-se um problema, uma vez que os documentos podem ser projetados em um grande número de dimensões e aproximados de qualquer consulta. O SPLADE resolve esse problema combinando todas as distribuições de probabilidade em nível de token em uma única distribuição que nos informa a relevância de cada token no vocabulário para a sentença de entrada, semelhante ao método BM25. O Elastic Learned Sparse Encoder é a versão elástica do modelo SPLADE.
RRF
RRF é uma consulta de pesquisa híbrida que normaliza e combina vários conjuntos de resultados de pesquisa com diferentes métricas de relevância em um único conjunto de resultados. De acordo com nossos próprios testes, a combinação de RRF (BM25 + Elastic Learned Sparse Encoder) produz a melhor relevância de pesquisa.
Resumir
Ao combinar o poder inovador de tecnologias como o ChatGPT com o contexto comercial de dados proprietários, podemos realmente mudar a maneira como clientes, funcionários e organizações pesquisam.
A geração aumentada de recuperação (RAG) preenche a lacuna entre grandes modelos de linguagem para IA generativa e fontes de dados privadas. As limitações bem conhecidas de modelos de linguagem grandes podem ser abordadas com recuperação baseada em contexto, permitindo que você crie pesquisas profundamente envolventes.
原文:Desmistificando o ChatGPT: Diferentes métodos para construir a pesquisa de IA | Blog Elástico