1. O que são conjuntos classificados
Os conjuntos classificados, semelhantes aos conjuntos, são um tipo de coleção e não haverá dados duplicados (membro) na coleção . A diferença é que o elemento Sorted Sets consiste em duas partes, membro e pontuação. Um membro será associado a uma pontuação de tipo duplo (pontuação), e os conjuntos classificados classificarão os membros de pequeno a grande de acordo com essa pontuação por padrão. Se as pontuações associadas aos membros forem iguais, elas serão classificadas de acordo com o ordem do dicionário das strings.
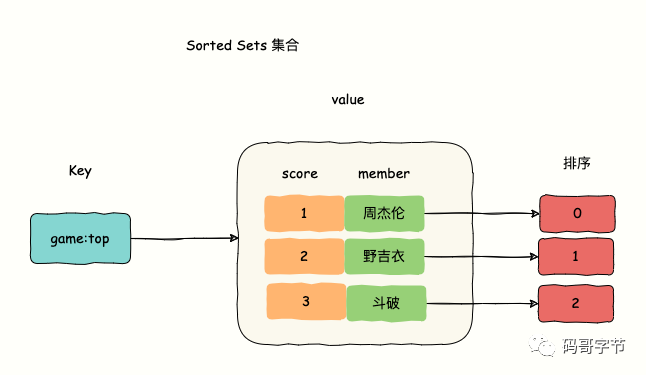
Cenários de uso comuns:
- Tabelas de classificação, como manter uma lista ordenada dos 10 melhores classificados por pontuação em um grande jogo online.
- Limitador de taxa, construa um limitador de taxa de janela deslizante a partir de uma coleção classificada.
- Na fila de atraso, a pontuação armazena o tempo de expiração, classificado do menor ao maior, sendo o primeiro o dado que expira primeiro.
2. Pratique o método mental
Existem duas maneiras subjacentes aos Conjuntos Classificados para armazenar dados.
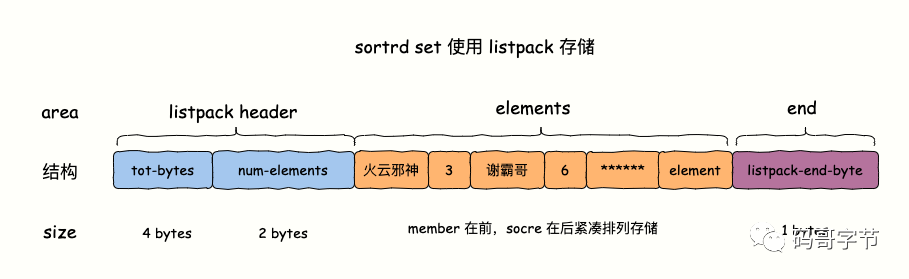
- Era ziplist antes da versão 7.0 e foi substituído por listpack posteriormente. A condição para usar o armazenamento de listpack é que o número de elementos da coleção seja menor ou igual ao valor de configuração (padrão 128)
zset-max-listpack-entriese o tamanho do byte ocupado pelos membros seja menor do quezset-max-listpack-valueo valor de configuração (padrão 64) Use armazenamento de listpack, membro e pontuação são armazenados compactamente como um elemento de listpack. - Se as condições acima não forem atendidas, a combinação de skiplist + dict (tabela hash) é usada para armazenamento. Os dados serão inseridos na skiplist e os dados serão inseridos no dict (tabela hash) ao mesmo tempo. Isso é uma ideia de trocar espaço por tempo. A chave da tabela hash armazena o membro do elemento e o valor armazena a pontuação associada ao membro.
MySQL: "Ou seja, o listpack é adequado para cenários em que o número de elementos é pequeno e o conteúdo dos elementos não é grande."
Sim, o objetivo de usar o armazenamento do listpack é economizar memória. Conjuntos classificados podem oferecer suporte a consultas de intervalo eficientes precisamente por causa da tabela de salto da lista de saltos. Por exemplo, a complexidade ZRANGE de tempo do comando é , n é o número de membros e m é o número de resultados retornados. Observe que você deve evitar comandos que retornam um grande número de resultados.O(log(n)) + m
A razão para usar dict é atingir complexidade de tempo O(1) para consultar um único elemento. Tais como ZSCORE key member instruções. Para resumir, quando Sorted Sets é inserido ou atualizado, ele irá inserir ou atualizar os dados correspondentes na skiplist e na tabela hash ao mesmo tempo. Assegure-se de que os dados na skiplist e na tabela de hash sejam consistentes.
MySQL: "Este método é muito engenhoso. A skiplist é usada para executar consultas de intervalo ou consultas únicas com base na pontuação, e a tabela dict hash é usada para realizar a consulta de complexidade de tempo O(1) correspondente à pontuação de acordo com os dados consulta, que satisfaz a consulta de intervalo eficiente e a consulta de elemento único. Informe-se."
O código-fonte dos conjuntos classificados está principalmente nos dois arquivos a seguir.
- A estrutura é definida em
server.h. - A função é realizada agora
t_zset.c.
Primeiro veja como a estrutura de dados skiplist (pular tabela) + dict (tabela hash) armazena dados.
skiplist + ditado
MySQL: "Diga-me o que é uma tabela de salto"
A essência é uma lista encadeada ordenada que pode realizar pesquisa binária . A tabela de salto adiciona um índice de vários níveis à lista encadeada ordenada original e realiza uma pesquisa rápida no índice. Ele não apenas melhora o desempenho da pesquisa, mas também o desempenho das operações de inserção e exclusão. É comparável à árvore rubro-negra e à árvore AVL em desempenho, mas o princípio e a implementação da tabela de salto são mais simples do que a árvore rubro-negra. Olhando para trás na lista encadeada, seu ponto problemático é que a consulta é muito lenta e a complexidade do tempo O(n) é insuportável para o Redis, que é o único rápido e inquebrável.

Se um ponteiro de "salto" para o próximo nó for adicionado a cada dois nós adjacentes da lista encadeada ordenada, a complexidade de tempo da pesquisa poderá ser reduzida à metade do original, conforme mostrado na figura abaixo.

Dessa forma, o nível 0 e o nível 1 formam respectivamente duas listas encadeadas, e o número de nós da lista encadeada no nível 1 é de apenas 2 (6, 26).
Ignorar pesquisa de nó de tabela
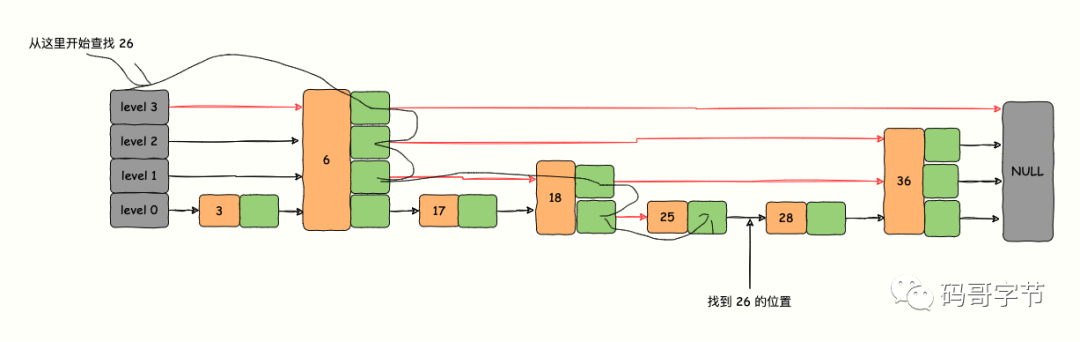
Os dados de pesquisa são sempre comparados a partir do nível mais alto. Se o valor salvo pelo nó for menor que os dados a serem verificados, a tabela de saltos continuará acessando o próximo nó da camada; se encontrar um nó com valor maior que os dados a serem verificados, ele pulará para A lista encadeada da próxima camada do nó atual continua a pesquisa. Por exemplo, se você deseja pesquisar 17 agora, o caminho de pesquisa deve estar na direção indicada pelo vermelho na figura abaixo.
![]()
- Comece no nível 1, compare 17 com 6, o valor é maior que o nó, continue comparando com o próximo nó.
- Comparado com 26, 17 < 26, retorne ao nó original, salte para a lista encadeada de nível 0 do nó atual, compare com o próximo nó e encontre o alvo 17.
skiplist foi inspirado na ideia dessa lista encadeada de várias camadas. De acordo com o método acima de geração de listas encadeadas, o número de nós em cada camada da lista encadeada é metade do da camada inferior.Este processo de pesquisa é semelhante a uma pesquisa binária e a complexidade de tempo é O(log n).
No entanto, esse método tem um grande problema ao inserir dados. Cada vez que um novo nó é adicionado, ele interrompe a relação 2:1 entre o número de nós na lista encadeada de duas camadas adjacentes. Se essa relação for mantida, é necessário Para ajustes de lista encadeada, a complexidade do evento é O(n). Para evitar esse problema, ele não requer uma relação proporcional estrita entre o número de nós da lista encadeada superior e inferior, mas seleciona aleatoriamente um número de camada para cada nó, de modo que a inserção de nós precise apenas modificar os ponteiros dianteiro e traseiro . A figura abaixo é uma skiplist com uma lista vinculada de 4 camadas. Suponha que queremos pesquisar 26. A figura abaixo mostra o caminho que a pesquisa percorreu.
Depois de ter uma imagem intuitiva da clássica skip list, vamos dar uma olhada nos detalhes de implementação da skiplist no Redis. A estrutura de dados dos Sorted Sets é definida da seguinte forma.
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;
zset Existem duas variáveis na estrutura, ou seja, a tabela de hash dict e a tabela de salto zskiplist. dict foi mencionado no artigo anterior, vamos nos concentrar nele zskiplist .
typedef struct zskiplist {
// 头、尾指针便于双向遍历
struct zskiplistNode *header, *tail;
// 当前跳表包含元素个数
unsigned long length;
// 表内节点的最大层级数
int level;
} zskiplist;
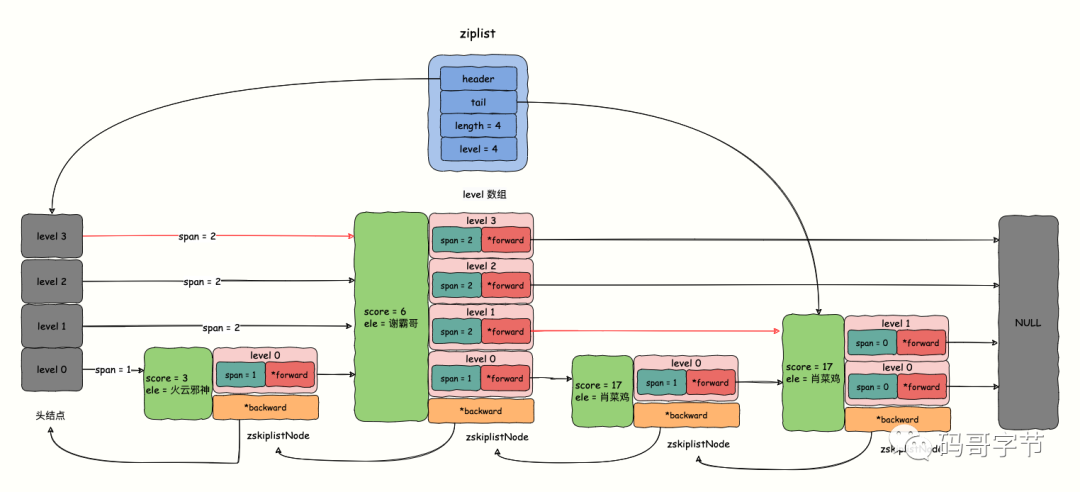
zskiplistNode *header, *tail, dois ponteiros de cabeça e cauda, usados para realizar a travessia bidirecional.length, o número total de nós contidos na lista encadeada. Observe que os recém-criadoszskiplistgeram um ponteiro de cabeça nulo, que não é incluído na contagem de comprimento.level, representaskiplisto número máximo de camadas de todos os nós.
Em seguida, continue a observar a zskiplistNode estrutura de definição de cada nó na skiplist.
typedef struct zskiplistNode {
sds ele;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned long span;
} level[];
} zskiplistNode;
-
Sorted Set não apenas salva os elementos, mas também salva o peso dos elementos. Portanto, correspondente ao elemento do tipo sds, o conteúdo real é armazenado e a pontuação do tipo double é usada para salvar o peso.
-
*backward, o ponteiro de volta, apontando para o nó anterior deste nó, o que é conveniente para pesquisar na ordem inversa do nó final. Observe que cada nó tem apenas um ponteiro para trás e apenas a lista vinculada de nível 0 é uma lista duplamente vinculada. -
level[], que é umazskiplistLevelmatriz flexível do tipo de estrutura. A lista de salto é uma lista vinculada ordenada de várias camadas e os nós de cada camada também são vinculados por ponteiros, de modo que cada elemento na matriz representa uma camada da lista de salto.-
*forward, o ponteiro de avanço da camada. -
span*forward, span, usado para registrar o número de nós que abrangem a camada level0 entre o ponteiro desta camada e o próximo nó apontado pelo ponteiro. span é usado para calcular o rank do elemento (rank), por exemplo, para achar o rank de ele = Xiaocaiji, score = 17, basta somar os spans dos nós por onde passa o caminho de busca, conforme mostra a figura abaixo, o acúmulo de extensão do caminho vermelho (rank = (2 + 2) - 1 = 3menos 1 porque a classificação começa em 0). Se você deseja calcular a classificação de grande para pequeno, você só precisa subtrair o valor acumulado de span no caminho de pesquisa do comprimento da skiplist, ou seja,4 - (2 + 2) = 0.
-
O diagrama abaixo mostra uma possível estrutura de um skiplsit no Redis.
pacote de lista
MySQL: "De acordo com
zset
a definição da estrutura, duas estruturas de dados, dict e zskiplist, são usadas respectivamente, e a sombra do listpack é invisível."
Esta pergunta é boa. Os detalhes do uso do armazenamento do listpack são refletidos nas funções no arquivo de código-fonte. Parte do código é a seguinte e, internamente, julgará se deve usar o listpack para armazenamento t_zset.c . zaddGenericCommand·
void zaddGenericCommand(client *c, int flags) {
// 省略部分代码
// key 不存在则创建 sorted set
zobj = lookupKeyWrite(c->db,key);
if (checkType(c,zobj,OBJ_ZSET)) goto cleanup;
if (zobj == NULL) {
if (xx) goto reply_to_client;
// 当 zset_max_listpack_entries == 0 或者
// 元素字节大小大于 zset_max_listpack_value 配置
// 则使用 skiplist + dict 存储,否则使用 listpack。
if (server.zset_max_listpack_entries == 0 ||
server.zset_max_listpack_value < sdslen(c->argv[scoreidx+1]->ptr))
{
zobj = createZsetObject();
} else {
zobj = createZsetListpackObject();
}
dbAdd(c->db,key,zobj);
}
// 省略部分代码
}
Sabemos que o listpack é uma memória contígua que consiste em vários itens de dados. Cada elemento do conjunto ordenado é composto de duas partes: membro e pontuação. Ao usar o armazenamento de listpack para inserir um par de dados (membro, pontuação), cada par de dados de membro/pontuação é armazenado em um arranjo compacto. A maior vantagem do listpack é que ele economiza memória.Na busca de elementos, só pode ser buscado em ordem, e a complexidade de tempo é O(n). É por isso que, no caso de uma pequena quantidade de dados, pode economizar memória sem afetar o desempenho. Cada etapa de pesquisa avança dois itens de dados, ou seja, em um par de dados de membro/pontuação.