1. Arquitetura de GPU móvel
Arquitetura de renderização de modo imediato (IMR)
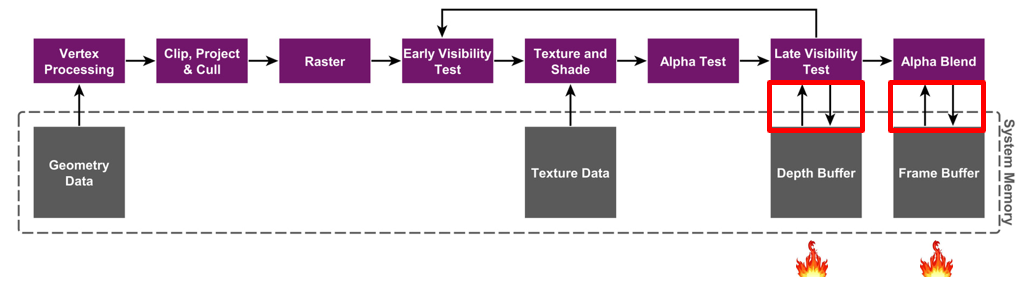
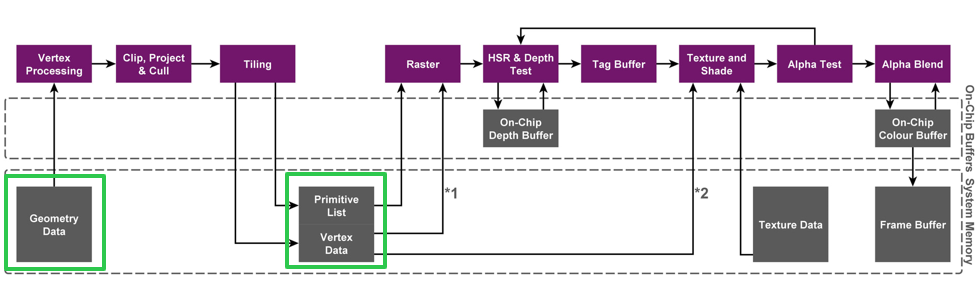
A maioria das GPUs do lado do PC anteriores usava a arquitetura IMR. O fluxo geral da arquitetura IMR é mostrado na figura.Vale a pena notar que para cada pixel, após várias leituras e gravações de cor/profundidade, ele é finalmente desenhado no framebuffer. Cada uma dessas leituras e gravações interage diretamente com a memória. Portanto, a leitura e gravação frequentes da memória consumirão muita largura de banda e esse processo gerará muito calor. Para PCs, para maior qualidade de imagem e taxa de quadros, melhores ventiladores e dissipação de calor podem ser usados para resolver o problema de aquecimento externo, mas para telefones celulares com espaço muito limitado, é definitivamente impossível instalar dissipação de calor.
Arquitetura de renderização baseada em blocos (TBR)
Portanto, para resolver o problema de aquecimento causado pela largura de banda, as GPUs de telefones celulares geralmente usam uma arquitetura baseada em blocos. As GPUs Adreno/Mali/PowerVR têm suas próprias otimizações exclusivas nessa base. Por exemplo, HSR na arquitetura TBDR do PowerVR pode eliminar completamente overdraw ao renderizar objetos opacos, então não vamos discutir isso aqui.
No entanto, suas ideias principais são as mesmas e todas abrem uma memória on-chip para a GPU. O recurso dessa memória on-chip é que, em comparação com a interação com a memória, a sobrecarga de leitura e gravação pelo A GPU é muito pequena.
A renderização baseada em blocos divide um framebuffer completo em vários blocos. Antes que o conteúdo de cada bloco seja completamente desenhado, a GPU apenas lê e grava na memória do chip. Depois que um bloco é completamente renderizado, o conteúdo na memória do chip é renderizado Gravação única na memória, a figura a seguir descreve o processo geral de desenho.
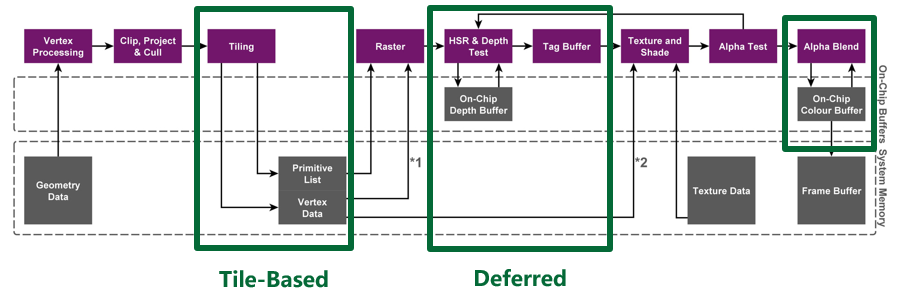
Dessa forma, o desenho original de cada pixel requer leitura e gravação direta da memória, mas agora é alterado para memória on-chip com sobrecarga de leitura e gravação extremamente baixa, economizando largura de banda e reduzindo o consumo de energia.
2. Por que usar o Vulkan?
Esse também é um problema que deve ser considerado no desenvolvimento de renderização móvel, exigindo que a equipe técnica do mecanismo tenha uma compreensão muito clara dos requisitos do projeto, API Vulkan e recursos de hardware de telefone móvel relacionados. A API Vulkan tem as seguintes vantagens especiais:
1) Seus drivers são mais finos. O Vulkan está mais próximo da camada inferior e o driver não fará muitos palpites e julgamentos como o GLES, portanto, pode reduzir significativamente a carga da CPU se for bem usado;
2) Vulkan fornece instruções explícitas de sincronização e controle de largura de banda. O uso correto e eficaz dessas instruções pode melhorar a eficiência operacional da GPU e reduzir o consumo de energia da GPU.
3) O Vulkan grava e envia a arquitetura commandbuffer, que suporta melhor a renderização multithread. Por exemplo, a extremidade do PC Unity usa multithreading de buffer de comando secundário para renderizar objetos na mesma cena ao mesmo tempo. UE também usa as características do Vulkan para separar o thread RHI do thread de renderização, calcular a média da carga multi-core e melhorar a eficiência multinúcleo.
4) Como o padrão Vulkan é relativamente novo e foi valorizado, ele inclui diretamente muitos métodos de uso dos recursos de hardware mais recentes ao personalizar o padrão Vulkan.
Portanto, no caso de agendamento razoável, Vulkan pode aproveitar os benefícios da CPU trazidos pela espessura do driver e multi-threading. Do lado da GPU, com um entendimento completo da arquitetura de hardware e das características de cada driver, o controle manual de sincronização e largura de banda pode efetivamente melhorar o desempenho do jogo. No entanto, alguns projetos geralmente gastam muito tempo e energia otimizando o algoritmo de renderização, melhorando o processo de renderização ou adicionando um pipeline de renderização personalizado, mas apenas porque eles não entendem um determinado recurso de hardware ou usam uma determinada API incorretamente. a degradação do desempenho é muito séria ou o algoritmo otimizado é aprimorado negativamente, mesmo incluindo os primeiros pipelines de renderização móvel padrão Unity e Unreal, que são mais ou menos insuficientes nessa área.
3. Largura de banda e consumo de energia em jogos
Vamos começar com um exemplo muito simples.
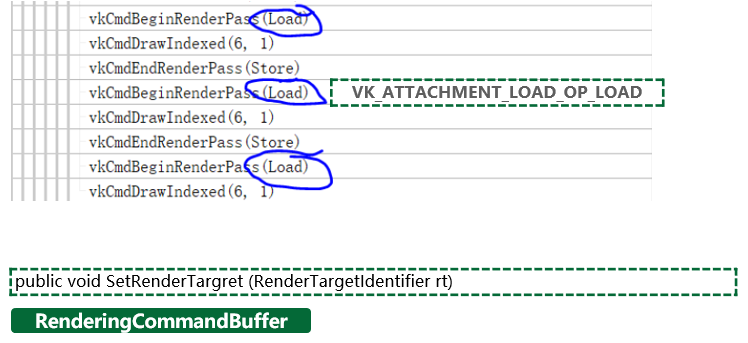
A imagem acima é um processo de renderização de pós-processamento personalizado implementado com o commandbuffer de renderização do Unity. Ao alternar o rendertarget, se apenas usarmos a interface padrão para definir RT e passá-lo para a camada inferior, podemos ver que a ação de carregamento do Vulkan renderpass é carregada, ou seja, o resultado da renderização anterior é mantido.
E quando usamos a interface a seguir para definir explicitamente a loadaction do rendertarget para alterar a load action do Vulkan para dontcare, podemos ver que a taxa de quadros aumentou em mais de 1 quadro quando a GPU está vinculada.

Isso ocorre porque, quando carregamos este rendertarget, na arquitetura Tile-base, o rendertarget é carregado da memória para a memória on-chip, gerando sobrecarga adicional. E se definirmos explicitamente o dontcare, o tempo de carregamento e a largura de banda serão reduzidos.No caso do limite de GPU, a melhoria de desempenho é refletida diretamente na taxa de quadros.
Aplicação de renderização baseada em blocos na renderização atrasada
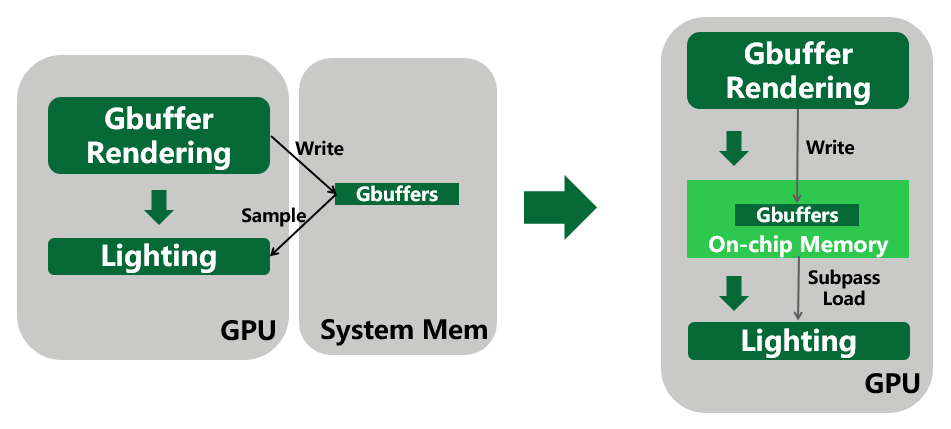
No método tradicional de renderização diferida, depois que o Gbuffer é renderizado, ele é gravado na memória e, em seguida, os gbuffers são amostrados no estágio de iluminação. E como no estágio de iluminação, cada pixel precisa das informações do gbuffer em sua própria posição de pixel, podemos usar o subpass para armazenar o gbuffer na memória do chip e lê-lo diretamente da memória do chip na iluminação subsequente estágio. Ele economiza o consumo de largura de banda de armazenar a memória primeiro e depois amostrar duas vezes.
A seguir está uma demonstração de renderização atrasada, a esquerda é o método de amostra e a direita é o método subpass:

Em ambos os casos, o algoritmo de iluminação, resolução, número de luzes, fps, incluindo a frequência da GPU, são todos fixos. A única diferença é se ele interage com a memória.O lado esquerdo é o Gbuffer salvo na memória de amostragem, o lado direito não interage com a memória e escreve e lê diretamente a memória do chip.
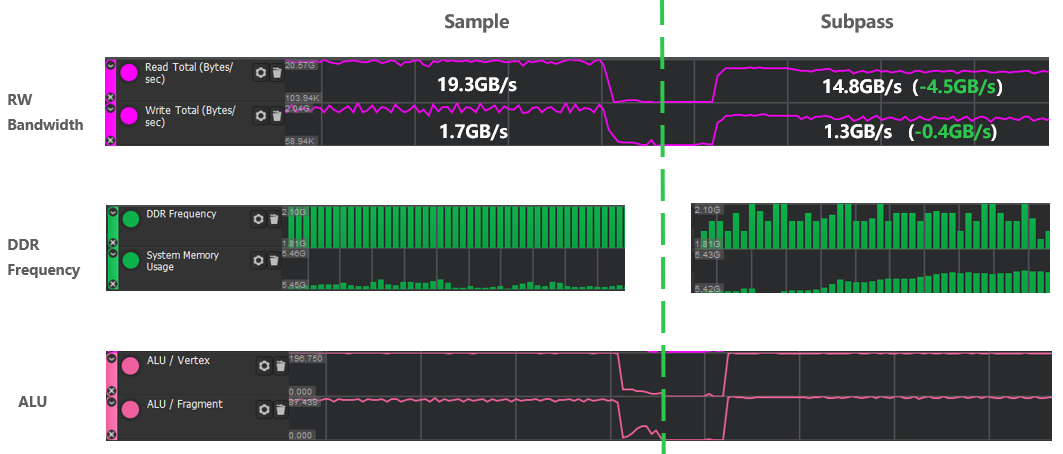
Pode ser visto nos resultados do teste que a quantidade de cálculo do sombreador é a mesma, mas a frequência da memória e a largura de banda são muito melhoradas pela solução de subpassagem. Aqui, a largura de banda de leitura e gravação é reduzida em 4,9 Gb/s no total, e a frequência da memória também é reduzida.
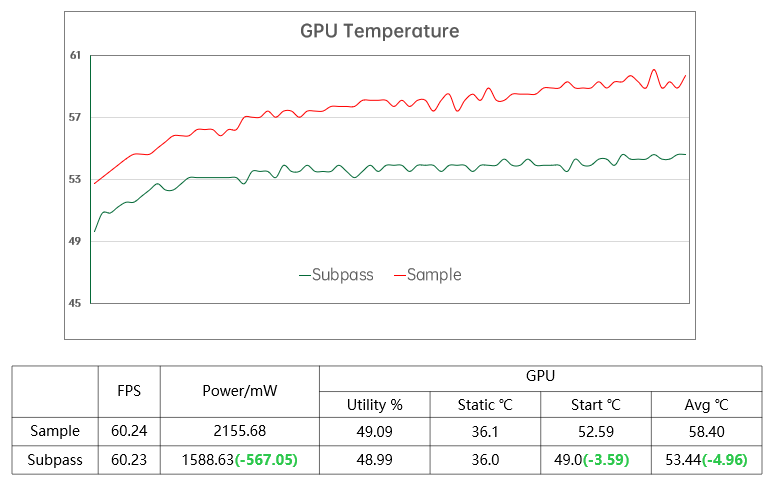
No caso de não haver diferença na taxa de quadros, uso e frequência da GPU, puramente por causa da redução na largura de banda, uma diferença de potência de 567mW foi gerada e a temperatura média da GPU também foi reduzida em 5 graus.
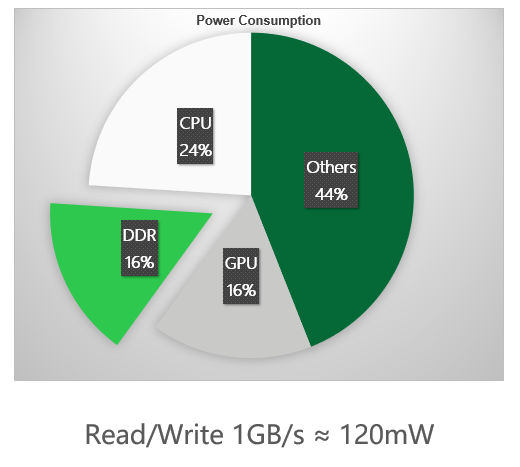
Aqui está uma referência geral. O consumo de energia gerado pela largura de banda da memória é quase igual ao consumo de energia da GPU. Cada vez que 1 GB de largura de banda da memória é consumido, ele gera cerca de 120 mW de consumo de energia, o que também é consistente com o anterior Resultados do teste de 5 GB e 567 mW.
Não apenas a renderização atrasada, desde que você queira ler a cor histórica e a profundidade da posição atual do pixel no processo de renderização, você pode usar o subpass. Por exemplo, decalque, renderização semitransparente de alguns efeitos de partículas, anti-aliasing MSAA, etc., pode obter benefícios consideráveis em termos de largura de banda usando subpass razoavelmente.
Obviamente, a arquitetura baseada em blocos ainda apresenta algumas desvantagens:
Por exemplo, na fase de ladrilhos, todos os cálculos de VS precisam ser concluídos e todas as variações precisam ser armazenadas na memória. Portanto, em comparação com o IMR, além da sobrecarga comum de buscar dados de geometria, a fase de ladrilhos também tem atraso adicional e consumo de largura de banda.
Portanto, a organização dos dados dos vértices também é muito importante. Por exemplo, nos dados de vértice personalizados mostrados na figura abaixo, aColor será passado para o fragment shader para renderização personalizada.
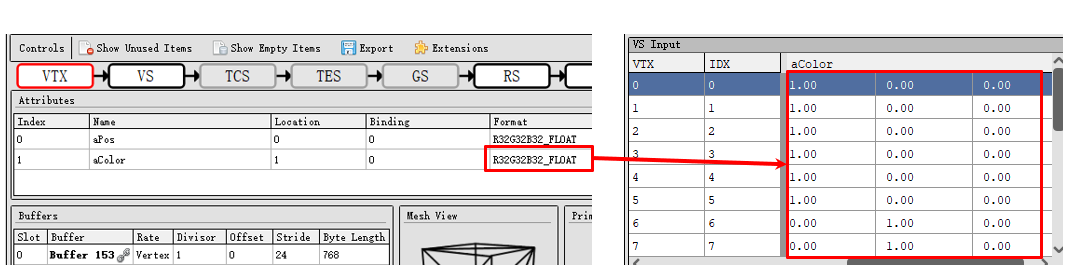
Observe que cada dado é um número inteiro com apenas 1 dígito significativo, mas é armazenado em um formato de 32 bits. No caso de modelos complexos e muitos vértices, isso também é uma sobrecarga considerável. Na verdade, o formato de 16 bits ou mesmo de 8 bits é suficiente. Portanto, no caso de saber o objetivo de cada dado de vértice em nosso projeto, devemos usar o menor formato possível.
Sombreamento de vértice orientado por índice (IDVS)
A figura abaixo mostra a otimização feita no ARM para reduzir a largura de banda dos dados de geometria de busca. A rigor, não pode ser considerada uma otimização especialmente projetada para a arquitetura TBR, mas seus benefícios são realmente grandes.
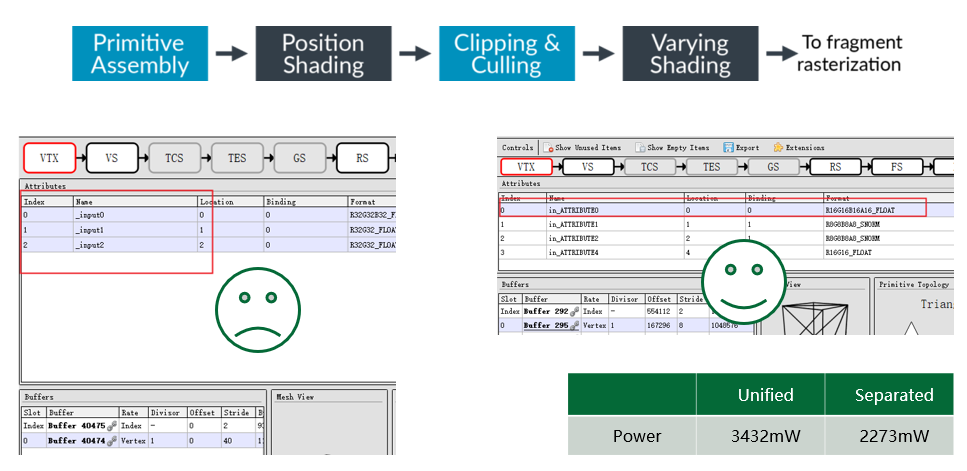
A ideia do IDVS é que no VS, apenas os cálculos relacionados à posição sejam feitos primeiro e, após a conclusão da eliminação, outros dados de atributos serão buscados e os cálculos relacionados à variação serão feitos. No entanto, essa otimização exige que os desenvolvedores armazenem a posição e outros atributos em buffers separados, para que a GPU possa buscá-los separadamente.
A maioria dos jogos móveis no mercado estão no lado esquerdo, todos os dados de vértice são armazenados no mesmo vkbuffer; o lado direito é a maneira recomendada, um vkbuffer armazena apenas os dados de posição e a variação restante é armazenada em outro vkbuffer , em alguns casos em que vs é mais pesado, a diferença de consumo de energia entre os dois excede 30%. Portanto, se os dados do vértice forem complexos, vale a pena dividi-los.
4. Sincronização no Vulkan
Um elemento muito importante na sincronização do Vulkan são as barreiras do pipeline. Desde que um projeto modifique o pipeline nativo do mecanismo, ele definitivamente envolverá a modificação das barreiras do pipeline. Na prática, quase todos os projetos têm alguns usos inapropriados. Além disso, se o ciclo de desenvolvimento do projeto for relativamente longo e uma versão anterior dos mecanismos Unity e Unreal for usada, o código nativo poderá ser usado de forma mais ou menos inadequada.
Os três pontos a seguir são o papel da barreira do duto mencionado acima na especificação Vulkan.
Primeiro, ele pode controlar a ordem de execução. Quando a GPU realmente executa as instruções, ela não necessariamente as executa na ordem em que as enviamos. Portanto, adicionar uma barreira de pipeline entre as instruções pode garantir que as instruções antes da barreira estão antes das instruções após a barreira. A instrução é executada.
Apenas a ordem em que as instruções começam é garantida. No caso de paralelismo, a ordem em que as instruções terminam não pode ser controlada. Problemas surgirão quando a modificação da memória estiver envolvida.
Em segundo lugar, a barreira do pipeline também garante as dependências de memória entre as instruções, que serão explicadas em detalhes posteriormente.
O terceiro ponto é que a conversão do layout da imagem é igualmente importante.Os leitores interessados podem consultar as informações relevantes.
Perigos
Como a situação real é muito mais complicada, aqui simplificamos o modelo de leitura/gravação em três partes: GPU core-cache-memory:
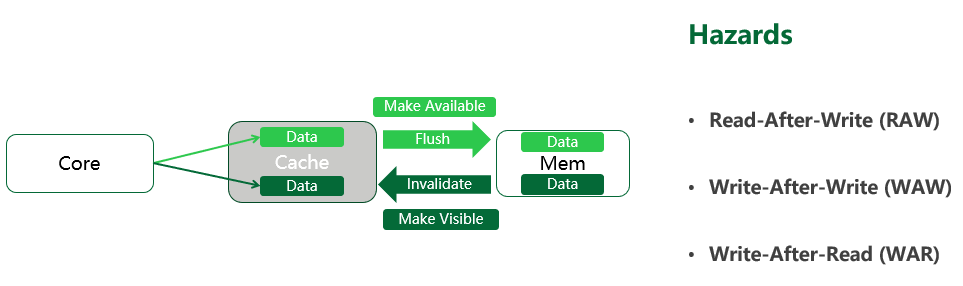
Ao gravar dados, o núcleo da GPU precisa liberar o cache após modificá-lo e copiar os dados contidos nele para a memória. Esse processo é chamado de disponibilizar memória.
Quando o núcleo da GPU lê os dados, ele deve primeiro invalidar o cache e carregar os dados da memória no cache. Esse processo é chamado de tornar a memória visível.
Depois de entender esse modelo simplificado, vamos examinar os três perigos da leitura e gravação da memória: leitura após gravação, gravação após gravação e gravação após leitura.
Se não houver sincronização, como leitura após gravação, é provável que, quando o comando read for executado, o comando write anterior não tenha tido tempo de modificar a memória, resultando em erros de renderização. Esse tipo de situação precisa ser evitado por meio de comandos de sincronização.
O processo específico de processamento de barreira Pipline WAR, RAW, WAW
Dentre os três problemas, a melhor solução é escrever após a leitura, para isso, desde que a ordem de execução das instruções seja restrita pela barreira do pipeline, pode-se garantir a exatidão da leitura dos dados. Como a instrução de leitura é executada primeiro, os dados já foram carregados no cache. Mesmo no pior caso, a operação de escrita subsequente é concluída imediatamente e apenas modifica o conteúdo da memória, não podendo afetar o que estamos lendo. Dados que foram carregados no cache.
Em seguida, vamos ver as outras duas sincronizações um pouco mais complicadas.
A máscara de estágio do pipeline e a máscara de acesso determinam em qual segmento de memória a barreira do pipeline entra em vigor. Então, se o mesmo segmento de memória for gravado primeiro e depois lido, a operação de leitura deverá ser executada depois que todos os dados forem gravados na memória.
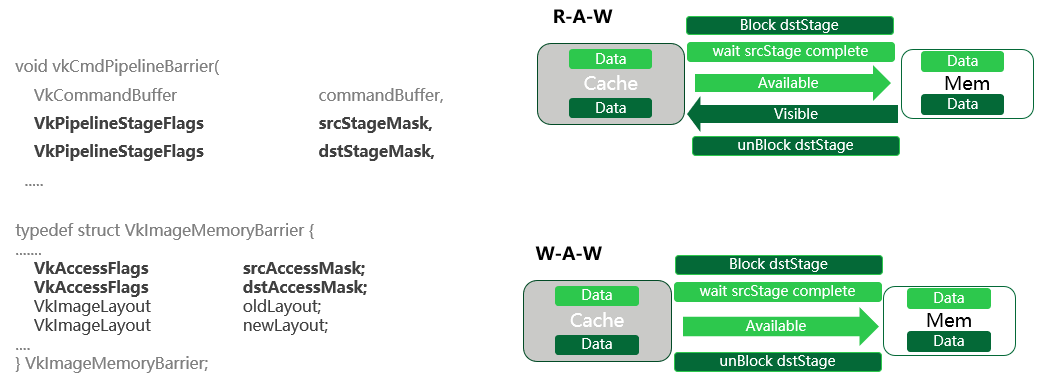
Portanto, sob a proteção da barreira do duto, todo o processo de sincronização é mostrado no canto superior direito:
Primeiramente, o comando de leitura será bloqueado, aguardando a execução do comando de escrita; srcAccessMask significa disponibilizar essa memória para garantir que os dados sejam gravados na memória. dstAccessMask significa tornar essa memória visível, ou seja, garantir que os dados recém-gravados na memória sejam carregados com sucesso no cache.
Finalmente, execute o comando de leitura. Desta forma, toda a sincronização de memória é concluída.
O princípio de escrever após escrever é semelhante: primeiro, bloqueie a segunda operação de gravação, aguarde a conclusão da primeira operação de gravação e os dados foram liberados na memória e, em seguida, execute a próxima operação de gravação.

O exemplo acima é um típico exemplo síncrono de leitura após gravação. Esta é uma demonstração de renderização atrasada que usa amostragem para ler Gbuffer. Simulação é o processo mais comum em jogos. É renderizar um RT primeiro e depois um fragmento. shader mostra o resultado deste RT. Além da renderização atrasada, shadowmap, sss, alguns campos de vento em tempo real, pré-processamento de pegadas, etc. são comuns.
O lado direito está completamente correto. Primeiro bloqueie o fs no estágio de iluminação e, em seguida, disponibilize a memória gravada pelo anexo de cor do estágio de saída de cores no estágio Gbuffer anterior e, em seguida, torne visível a mesma memória para ser lida pelo shader Desbloqueie fs, para que o fs no estágio de iluminação possa ler o Gbuffer corretamente.
A única diferença à esquerda é que o estágio de fragmento que deveria estar esperando é alterado para vértice, o que faz com que a GPU bloqueie o pipeline antecipadamente durante o estágio de sombreamento de vértice.
Este problema está muito oculto. Primeiro de tudo, a camada de validação do Vulkan não reportará um erro, porque é apenas ineficiente, não um erro. Se você testar aproximadamente alu, largura de banda de leitura e gravação e tempo de renderização, poderá ver que quase não há diferença nos resultados do teste desses dados no gráfico. Portanto, esta questão é facilmente ignorada.
Uso de ferramentas de análise de teste
Cada fabricante de Soc fornece suas próprias ferramentas de análise e teste de GPU, como Mali agilize para chips Mali, PVRTune para chips PowerVR e criador de perfil Snapdragon para Qualcomm. Neste exemplo, o celular que usamos é uma GPU do Mali, então use a ferramenta de teste do Mali para análise:
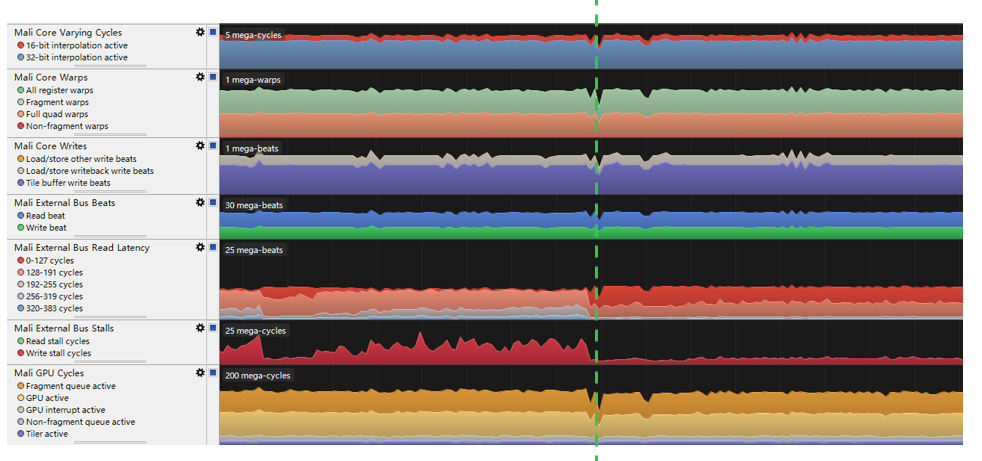
Como mostrado na figura acima, não há diferença na quantidade de cálculo e na largura de banda de leitura e gravação, a única coisa que muda é a latência de leitura do barramento externo e a parada do barramento externo.
Especificamente, há uma lacuna de 6 vezes no ciclo de bloqueio da leitura de dados do barramento de memória, porque nossa instrução de sincronização faz com que o estágio de espera atinja o estágio de sombreamento de vértice mais cedo. Mas como a frequência da GPU é alta o suficiente e a cena não é complexa o suficiente para atingir o limite da GPU, esses atrasos não são altos o suficiente para afetar a taxa de quadros.
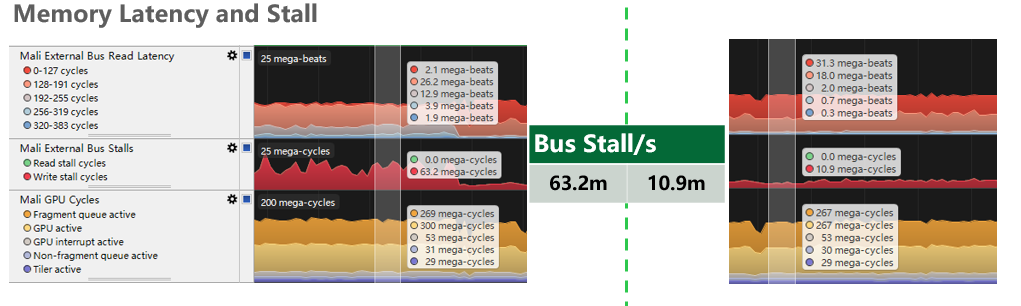
Agora, vamos limitar artificialmente a frequência da GPU e simular a situação de limite da GPU. Neste momento, o atraso de leitura e gravação do barramento de memória não pode ser coberto e o problema é exposto.

Pode-se ver que o impacto do Bus Stall na taxa de quadros ainda é óbvio. A diferença de tempo de quadro é de 3 milissegundos, ou seja, se 8 quadros não forem testados em profundidade, é fácil ignorar esse problema. A pressão de renderização aumenta gradualmente, e quando o problema é exposto, pode não ser possível encontrar a causa original.
Resumindo, o problema de sincronização é muito importante. Precisamos entender completamente o modelo de memória cache-núcleo, saber claramente que tipo de perigos o pipeline encontra e usar a barreira do pipeline corretamente para utilizar totalmente os benefícios de desempenho trazidos pelo controle manual sincronização.
Outras instruções de sincronização
Claro, existem muitas outras instruções de sincronização no Vulkan, como a dependência de subpass, que é quase o mesmo que a barreira, mas apenas a memória relacionada ao anexo no renderpass pode ser sincronizada. O semáforo é usado para sincronização entre as filas e o fence é usado para sincronizar GPU e CPU. O evento raramente é usado em jogos para dispositivos móveis. Atualmente, exceto por um ou dois jogos que modificaram seus mecanismos, apenas a versão mais recente do irreal está disponível em dispositivos móveis renderizador de sombreamento A parte de consulta de oclusão o usa.
5. Resumo
Este artigo primeiro apresenta a arquitetura de renderização móvel e suas características, depois explica as vantagens da API Vulkan, analisa as vantagens e desvantagens da renderização baseada em Tile com base em resultados de teste reais e, finalmente, concentra-se no controle de sincronização explícita do Vulkan, combinado com cenários específicos e com base nos dados medidos, o esquema de otimização é dado e a causa raiz é analisada.
Espero que os leitores possam obter uma compreensão mais profunda da API Vulkan e da arquitetura de renderização móvel por meio deste artigo, combinar cenários de desenvolvimento específicos e usar racionalmente as ferramentas de análise de teste para melhorar o consumo de energia, a largura de banda e os problemas de sincronização na renderização móvel.
Referências
A vantagem do PowerVR (imgtec.com)
https://docs.imgtec.com/Architecture_Guides/PowerVR_Architecture/topics/powervr_architecture_the_powervr_advantage.html
Exemplos de sincronização · KhronosGroup/Vulkan-Docs Wiki · GitHub
https://github.com/KhronosGroup/Vulkan-Docs/wiki/Synchronization-Examples
Prática recomendada de software ARM/Vulkan para desenvolvedores móveis
https://github.com/ARM-software/vulkan_best_practice_for_mobile_developers
SaschaWillems/Vulkan: Exemplos e demonstrações para a nova API Vulkan
https://github.com/SaschaWillems/Vulkan
Recomendações de uso do Vulkan | Desenvolvedores Samsung
https://developer.samsung.com/galaxy-gamedev/resources/articles/usage.html
baldurk/renderdoc
https://github.com/baldurk/renderdoc
Snapdragon Profiler - Qualcomm Developer Network
https://developer.qualcomm.com/software/snapdragon-profiler
Passado
Esperar
empurrar
recomendar
Análise da arquitetura de processador mais recente da Arm em 2023 - X4, A720 e A520
Visualização ao vivo | Página do kernel do Linux para alterações no fólio
Sobre a importância de um bom nome: a mudança da página do kernel do Linux para o fólio

Pressione e segure para seguir Kernel Craftsman WeChat
Tecnologia Linux Kernel Black | Artigos técnicos | Tutoriais em destaque