prefácio
Com o estudo contínuo e aprofundado da linguagem C, temos que começar a aprender um pouco da estrutura de dados para aumentar nossa força interna. Embora muitas tabelas de sequência de linguagem de alto nível, listas encadeadas, etc. não possam ser implementadas por nós mesmos, precisamos para fazermos nós mesmos na linguagem C. Percebi, isso não significa que a linguagem C e outras linguagens são mais diferentes da linguagem C. Vamos simular e implementar essa estrutura de dados através da linguagem C, que pode nos dar uma compreensão mais profunda alguns dos conteúdos que costumamos usar em outros idiomas. Claro, o que temos que aprender não é apenas sua implementação, mas, mais importante, suas ideias.
1. Tabela de sequência
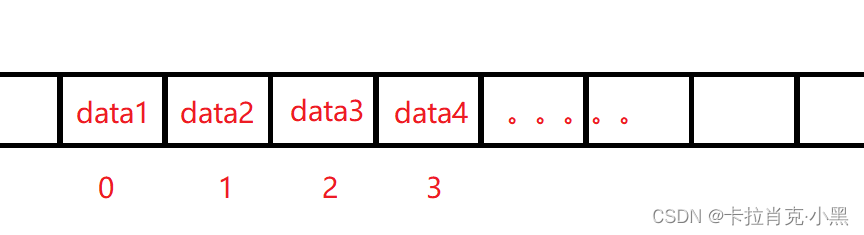
A tabela sequencial é uma tabela linear armazenada em forma de array na memória do computador. O armazenamento sequencial da tabela linear refere-se ao armazenamento de cada elemento da tabela linear em sequência com um grupo de unidades de armazenamento com endereços contínuos, de modo tabela linear é adjacente na estrutura lógica.Os elementos de dados são armazenados em unidades de armazenamento físico adjacentes . A tabela de sequência serve para armazenar os nós da tabela em sequência em um grupo de unidades de armazenamento com endereços contínuos na memória do computador.
O armazenamento na memória é o seguinte:
Em segundo lugar, a função da tabela de sequência
As funções das tabelas de sequência comuns incluem adicionar, excluir, pesquisar e modificar. Existem algumas outras funções: classificação, mesclagem, retorno do número de elementos, etc.
Aumento : O aumento pode ser dividido em aumento da cabeça, aumento da cauda e aumento da posição especificada, e o aumento da posição especificada pode ser dividido em aumento à esquerda ou à direita do elemento especificado.
Exclusão : A exclusão pode ser dividida em exclusão de cabeça, exclusão de cauda e exclusão de posição especificada.
Find : Como o nome sugere, encontre o elemento ou local especificado.
Modificar : Modifique o elemento especificado ou o elemento na posição para outros elementos.
Ordenar : Classifica os dados na estrutura.
Mesclar : Mesclar várias estruturas em uma.
Retornar o número de elementos : exibe o número específico de elementos na tabela de sequência.
Em terceiro lugar, a realização da tabela de sequência
A implementação da tabela de sequência pode ser dividida em estática e dinâmica .
O tamanho da tabela de sequência estática foi corrigido, mas o tamanho da tabela de sequência dinâmica pode ser alterado. O uso da tabela de sequência estática é muito limitado e haverá uma situação embaraçosa de espaço desperdiçado e espaço insuficiente. A tabela de sequência dinâmica resolve o problema da tabela de sequência estática. Mas ainda temos que aprender sobre a tabela de sequência estática e observar as semelhanças e diferenças entre dinâmico e estático. Nossas implementações de funções são todas realizadas por referência, e a necessidade de passar valores é para evitar cópias em grande escala, o que acarretará perda de tempo e espaço.
1. Implementação estática da tabela de sequência
Criação da tabela de sequência
#define MAX 10 //存放元素的最大个数
typedef int datatype;//把类型重新命名,方便后面的参数类型的修改,增加代码的鲁棒性
typedef struct SList//定义顺序表的结构体
{
int position;//表中元素的个数和位置
datatype arr[MAX];//用来存放元素
}SL;//把结构体类型重新命名为SL
O que implementamos é uma tabela de sequência simples, o tipo de armazenamento é dados do tipo int e é colocado em uma matriz do tipo int.
Inicialização, impressão e destruição da tabela de sequência
void Initialization(SL *sl)//初始话顺序表
{
assert(sl);//进行断言,防止传入的指针或者地址不合法而造成的错误
sl->position = 0;//开始没有元素,所以位置为0
}
SL* InitializationList()
{
SL* sl = (SL*)malloc(sizeof(SL));
sl->position = 0;
return sl;
}
void print(const SL *sl)//打印顺序表
{
assert(sl);//进行断言
for (int i = 0; i < sl->position; i++)
{
printf("%d ", sl->arr[i]);
}
printf("\n");
}
void Destroy1(SL* sl)//销毁顺序表
{
assert(sl);
sl->position = 0;//把元素个数置为0
}
void Destroy2(SL* sl)//销毁顺序表
{
assert(sl);
free(sl);//把空间进行释放
sl->position = 0;
sl = NULL;//把指针置空
}
Existem dois tipos de inicialização da tabela de sequência, uma é criada na função principal e inicializada através da primeira função, e a outra é criada na função e retornada para a função principal através do tipo de retorno. A função de destruição também é projetada para as duas funções de inicialização acima. A primeira não é aberta dinamicamente, então free não pode ser usada. A segunda é o espaço aberto dinamicamente na função, então ela precisa ser liberada por free. evitar vazamentos de memória.
Não temos uma implementação estática aqui? Por que você ainda usa o desenvolvimento dinâmico?
O estático aqui significa que o tamanho de armazenamento dos dados é constante. A memória exigida por uma estrutura que desenvolvemos dinamicamente é fixa. O tamanho da matriz na estrutura é fixo. O número de seus elementos de armazenamento é o mesmo que o de nosso É irrelevante se o corpo é aberto dinamicamente ou não. relacionado ao tamanho do array.
Estamos chamando por referência, quando não precisamos modificar o elemento, podemos adicionar const para modificá-lo para evitar que o modifiquemos.
Adição e exclusão de tabelas de sequência
Vejamos primeiro a implementação do código:
void Popback(SL* sl, datatype n)//头插
{
assert(sl);//进行断言
if (sl->position < MAX )//判断数组中是否还有空间
{
int sum = sl->position;//创建一个变量等于数组中插入元素后的位置
for (; sum > 0; sum--)
{
sl->arr[sum] = sl->arr[sum - 1];//把插入元素后的前一个元素向后移动
}
sl->arr[sum] = n;//把数组中的一个元素设置为传入的值
sl->position++;//元素位置向后移动
}
else
{
printf("空间不足\n");
return;
}
}
void Popfornt(SL* sl)//头删
{
assert(sl);//进行断言
int sum = 1;
for (; sum < sl->position; sum++)
{
sl->arr[sum - 1] = sl->arr[sum];//把数组中元素进行前移进行覆盖
}
sl->position--; //元素位置向前移动
}
void Pushback(SL* sl, datatype n)//尾插
{
assert(sl);
if (sl->position < MAX)//判断数组中是否还有空间
{
sl->arr[sl->position] = n;//直接在数组后插入元素
sl->position++;//元素位置向后移动
}
else
{
printf("空间不足\n");
return;
}
}
void Pushfornt(SL* sl)//尾删
{
assert(sl);
sl->position--;//直接进行个数减一,表明这个位置可以进行覆盖
}
Inserção e exclusão de cabeçalho : insira o elemento na primeira posição da matriz, de modo que todos os elementos atrás da primeira posição precisem ser movidos para trás e a exclusão de cabeçalho precise sobrescrever todos os elementos atrás da primeira posição.
Inserção final e exclusão final : insira diretamente o elemento na última posição ou reduza diretamente o número de elementos em um para obter o efeito de inserção final e exclusão final.
void test1()//进行头删,尾删,头插,尾插。
{
SL sl;
Initialization(&sl);//初始话顺序表
Popback(&sl, 1);//进行头插
Popback(&sl, 2);
Popback(&sl, 3);
Popback(&sl, 4);
Popback(&sl, 5);
printf("头插后:");
print(&sl);
Pushback(&sl, 6);//进行尾插
Pushback(&sl, 7);
Pushback(&sl, 8);
Pushback(&sl, 9);
Pushback(&sl, 10);
Pushback(&sl, 11);//超过数组中的大小,空间不足
printf("尾插后:");
print(&sl);//打印顺序表的元素
Pushfornt(&sl);//进行尾删
printf("尾删后:");
print(&sl);
Popfornt(&sl);//进行头删
printf("头删后:");
print(&sl);
Destroy1(&sl);
}
int main()
{
test1();
return 0;
}

Inserção, consulta e modificação da tabela de sequência
A inserção e modificação da tabela de sequência dependem da função de consulta, portanto, precisamos primeiro implementar a consulta da tabela de sequência e também podemos modificar diretamente os elementos subscritos que queremos modificar, mas geralmente não sabemos o que os elementos de subscrito que queremos modificar são , então a função de pesquisa é necessária, como o catálogo de endereços a ser implementado, podemos encontrar o subscrito da pessoa através do nome e, em seguida, modificar nosso valor.
Aqui está o nosso código de implementação:
int Seeklift(const SL *sl, datatype n)//左查找
{
assert(sl);
int sum = 0;
for (sum = 0; sum < sl->position; sum++)
{
if (sl->arr[sum] == n)//判断改下标的元素是否和我们所需的元素相同。
{
return sum+1;//数组下标从0开始,所以返回位置进行加1
}
}
return -1;
}
int Seekright(const SL *sl, datatype n)//右查找
{
assert(sl);
int sum = sl->position-1;
for (; sum >0; sum--)
{
if (sl->arr[sum] == n)
{
return sum+1;
}
}
return -1;
}
void Modify(SL *sl, int n, datatype num)//修改
{
assert(sl);
sl->arr[n - 1] = num;//把坐标还原为数组的下标
}
void Insertpos(SL* sl, int n, datatype num)//按数组位置插入,在元素左插入
{
assert(sl);
//判断数组中是否还有空间
if (sl->position < MAX)
{
int sum = sl->position;//创建一个变量等于数组中插入元素后的位置
for (; sum > n-1; sum--)//把坐标还原为数组的下标
{
sl->arr[sum] = sl->arr[sum - 1];//把插入元素后的前一个元素向后移动
}
sl->arr[n-1] = num;//把数组中的一个元素设置为传入的值
sl->position++;//元素位置向后移动
}
else
{
printf("空间不足\n");
return;
}
}
void Insertright(SL* sl, int n, datatype num)//在元素右插入
{
assert(sl);
//判断数组中是否还有空间
if (sl->position < MAX)
{
int sum = sl->position;//创建一个变量等于数组中插入元素后的位置
for (; sum > n; sum--)//把坐标还原为数组的下标
{
sl->arr[sum] = sl->arr[sum - 1];//把插入元素后的前一个元素向后移动
}
sl->arr[n] = num;//把数组中的一个元素设置为传入的值
sl->position++;//元素位置向后移动
}
else
{
printf("空间不足\n");
return;
}
}
Pesquisa : Dividimos a pesquisa em pesquisa da esquerda e pesquisa da direita, respectivamente, a primeira à esquerda encontra o número que precisamos e a da direita encontra o número que precisamos. Definimos o valor de retorno como sendo do tipo int, se não for encontrado, retornamos -1. As modificações só podem ser feitas quando os elementos de que precisamos são encontrados.
Inserção : Dividimos em inserção à esquerda e inserção à direita. A inserção à esquerda tem a mesma lógica da inserção normal, portanto, o padrão também é a inserção à esquerda. A inserção à direita é apenas diferente da inserção à esquerda e a lógica de implementação do código é exatamente a mesma.
Modificação : A modificação é realizada através do subscrito do elemento que encontramos. Se não for encontrado, não pode ser modificado.
Aqui está nossa função de teste:
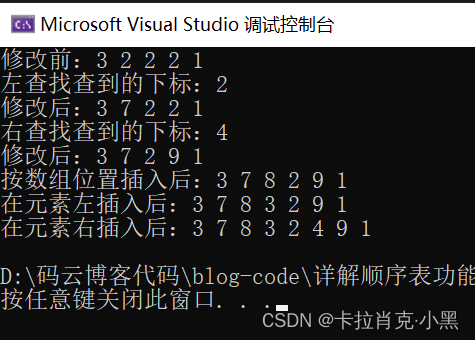
void test2()//进行插入,查询,修改
{
SL sl;
Initialization(&sl);//初始话顺序表
Popback(&sl, 1);//进行头插
Popback(&sl, 2);
Popback(&sl, 2);
Popback(&sl, 2);
Popback(&sl, 3);
printf("修改前:");
print(&sl);
if (-1 != Seeklift(&sl, 2))//左查找
{
printf("左查找查到的下标:%d\n", Seeklift(&sl, 2));
Modify(&sl, Seeklift(&sl, 2), 7);//修改
printf("修改后:");
print(&sl);
}
if (-1 != Seekright(&sl, 2))//右查找
{
printf("右查找查到的下标:%d\n", Seekright(&sl, 2));
Modify(&sl, Seekright(&sl, 2), 9);
printf("修改后:");
print(&sl);
}
Insertpos(&sl, 3, 8);//按数组位置插入
printf("按数组位置插入后:");
print(&sl);
Insertpos(&sl, Seeklift(&sl, 2), 3);//在元素左插入
printf("在元素左插入后:");
print(&sl);
Insertright(&sl, Seeklift(&sl, 2), 4);//在元素右插入
printf("在元素右插入后:");
print(&sl);
Destroy1(&sl);
}
int main()
{
test2();
return 0;
}
A lógica do nosso teste é primeiro inserir 5 elementos, realizar pesquisas esquerda e direita e modificá-los e, finalmente, inserir esquerda e direita.
A classificação ascendente e descendente da tabela de sequência e o retorno do número de elementos
Todos nós usamos classificação de bolhas para classificação aqui, e vamos transformá-lo em um método de classificação com um algoritmo melhor quando esperarmos pelo capítulo de classificação. A única diferença entre classificação ascendente e classificação descendente aqui é a diferença na maneira como julgamos o tamanho. O número de elementos que retornamos é para retornar diretamente a posição total do subscrito de nossos elementos de estrutura, que também é o número total de nossos elementos .
void Sortmax(SL* sl)//升排序
{
assert(sl);
//冒泡排序
int i, j, temp;
for (i = 1; i < sl->position; i++)
{
for (j = 0; j < sl->position - i; j++)
{
if (sl->arr[j] > sl->arr[j + 1])
{
temp = sl->arr[j];
sl->arr[j] = sl->arr[j + 1];
sl->arr[j + 1] = temp;
}
}
}
}
void Sortmin(SL* sl)//降排序
{
assert(sl);
//冒泡排序
int i, j, temp;
for (i = 1; i < sl->position; i++)
{
for (j = 0; j < sl->position - i; j++)
{
if (sl->arr[j] < sl->arr[j + 1])
{
temp = sl->arr[j];
sl->arr[j] = sl->arr[j + 1];
sl->arr[j + 1] = temp;
}
}
}
}
int Size(const SL *sl)//返回顺序表中元素个数
{
assert(sl);
return sl->position;
}
Aqui está o nosso código de teste:
void test3()//进行升降排序
{
SL* sl;
sl = InitializationList();//初始话顺序表
Popback(sl, 1);
Popback(sl, 5);
Popback(sl, 3);
Popback(sl, 4);
Popback(sl, 2);
printf("排序前:");
print(sl);
Sortmax(sl);//升序排列
printf("升序后:");
print(sl);
Sortmin(sl);//降序排列
printf("降序后:");
print(sl);
printf("元素总个数:%d", Size(sl));
Destroy2(sl);
}
int main()
{
test3();
return 0;
}

Aqui usamos o segundo método de inicialização, então não há necessidade de adicionar símbolos de endereço para passagem de parâmetro. A função de destruição também é usada em segundo lugar para evitar vazamentos de memória.
Consolidação de listas de sequências
Para mesclar tabelas de sequência, mesclamos em ordem crescente e também mesclamos duas tabelas de sequência crescente.
Aqui está o nosso pensamento:
SL* Merge(const SL* sl1,const SL* sl2)//合并两个有序的顺序表
{
assert(sl1 && sl2);
SL* sl = (SL*)malloc(sizeof(SL));
sl->position = 0;
int i = 0;//用来访问数组中的元素
int j = 0;
while (i < sl1->position && j < sl2->position)//当任意一个数组中的元素到达尾部时结束循环
{
if (sl1->arr[i] <= sl2->arr[j])//判断数组中的元素大小,谁小谁进行尾插
{
Pushback(sl, sl1->arr[i]);
i++;
}
else
{
Pushback(sl, sl2->arr[j]);
j++;
}
}
if (i >= sl1->position)//判断哪一个数组到达了尾部,把没到达尾部的数组元素进行尾插
{
while(j < sl2->position)
{
Pushback(sl, sl2->arr[j]);
j++;
}
}
else
{
while (i < sl1->position)
{
Pushback(sl, sl1->arr[i]);
i++;
}
}
return sl;
}
A ideia da fusão é criar primeiro uma estrutura, depois comparar os arrays nas duas estruturas, e inserir o menor na estrutura que criamos. Então, quando os elementos de uma tabela de sequência são usados, todos os elementos de outra tabela de sequência são inseridos na estrutura que criamos.
Aqui está o nosso código de teste:
void test4()//合并两个有序的顺序表
{
SL *sl;
SL sl1 = {
3,{
1,6,7}};
SL sl2 = {
3,{
2,3,5}};
printf("s1:");
print(&sl1);
printf("s2:");
print(&sl2);
sl = Merge(&sl1, &sl2);//合并两个有序的顺序表
printf("合并后:");
print(sl);
Destroy2(sl);
Destroy1(&sl1);
Destroy1(&sl2);
}
int main()
{
test4();
return 0;
}

1. Realização dinâmica da tabela de sequência
Criação da tabela de sequência
A essência da implementação dinâmica da tabela de sequência é realizada por meio de ponteiros.
typedef int datatype;
typedef struct SList//定义顺序表的结构体
{
datatype* num;//数据类型的指针
int sz;//数据元素的个数
int max;//数据元素的最大个数
}TSL;
Aqui, alteramos a matriz anterior para o tipo de ponteiro correspondente, mas adicionamos um número máximo adicional de elementos. O número máximo de elementos é usado para avaliar se nosso armazenamento atual está cheio. Se o armazenamento estiver cheio, precisamos expandir a capacidade. .
Inicialização, impressão e destruição da tabela de sequência
void InitIalization(TSL* sl)//初始话顺序表
{
sl->max = 4;//数据初始元素最大为4个
sl->sz = 0;//数据的起始元素为0个
sl->num = (datatype*)malloc(sizeof(datatype) * sl->max);
}
Aqui definimos a capacidade inicial para 4. Quando o número de nossos elementos for igual à nossa capacidade, iremos expandir a capacidade. Aqui escrevemos apenas o código de inicialização, e os códigos de impressão e destruição são exatamente os mesmos da implementação estática.
Adição e exclusão de tabelas de sequência
void Expansion(TSL* sl)//进行扩容
{
datatype* sl1 = (datatype*)realloc(sl->num, sizeof(datatype) * (sl->max * 2));
{
if (sl1 == NULL)//判断是否开辟空间成功
{
perror("sl1 err\n");//开辟失败进行报错
return;
}
else
{
sl->num = sl1;
sl->max *= 2;//更改容量的大小
}
}
}
void PopBack(TSL* sl, datatype n)//头插
{
assert(sl);
if (sl->sz == sl->max)//判断空间是否已满,满则扩容
{
Expansion(&sl);//传递的是sl的地址,不是sl存放的地址
}
int i = 0;
for (i = sl->sz; i > 0; i--)
{
sl->num[i] = sl->num[i - 1];//把插入元素后的前一个元素向后移动
}
sl->num[0] = n;//把数组中的一个元素设置为传入的值
sl->sz++;//元素位置向后移动
}
Aqui podemos ver que a lógica do código adicionado é exatamente a mesma que a estática, exceto que há uma operação de expansão adicional.
Nota: Devemos prestar atenção que o aumento de capacidade pode falhar, portanto não podemos usar diretamente nosso endereço, mas criar uma estrutura primeiro e depois atribuir nossa criação à nossa estrutura original após a criação ser bem-sucedida.
Aqui nós apenas demonstramos o código de head plugging. A lógica do tail plugging é a mesma que a estática, mas o código de julgamento é substituído pelo julgamento de expandir ou não.
Aqui está o código de demonstração:
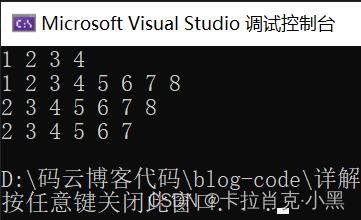
void test5()
{
TSL sl;
InitIalization(&sl);//初始话顺序表
PopBack(&sl, 4);
PopBack(&sl, 3);
PopBack(&sl, 2);
PopBack(&sl, 1);
Print(&sl);
PushBack(&sl, 5);
PushBack(&sl, 6);
PushBack(&sl, 7);
PushBack(&sl, 8);
Print(&sl);
PopFornt(&sl);
Print(&sl);
PushFornt(&sl);
Print(&sl);
DEstroy(&sl);
}
int main()
{
test5();
}
Resumo da Tabela de Sequência Dinâmica
A tabela de sequência dinâmica apenas adiciona uma função de expansão ao local onde é julgado se está cheia. Os outros códigos são exatamente iguais aos estáticos e as ideias também são as mesmas. Substituímos os arrays estáticos pelos ponteiros correspondentes, e pode expandir a capacidade através do desenvolvimento dinâmico. Nossa expansão é para aumentar a capacidade do ponteiro na estrutura, não para aumentar a capacidade da própria estrutura.
1. Código dinâmico da tabela de sequência
código de teste dinâmico
//main1.c 动态测试代码
#include"main1.h"
void test5()
{
TSL sl;
InitIalization(&sl);//初始话顺序表
PopBack(&sl, 4);
PopBack(&sl, 3);
PopBack(&sl, 2);
PopBack(&sl, 1);
Print(&sl);
PushBack(&sl, 5);
PushBack(&sl, 6);
PushBack(&sl, 7);
PushBack(&sl, 8);
Print(&sl);
PopFornt(&sl);
Print(&sl);
PushFornt(&sl);
Print(&sl);
DEstroy(&sl);
}
void test6()
{
TSL sl;
InitIalization(&sl);//初始话顺序表
PopBack(&sl, 3);
PopBack(&sl, 2);
PopBack(&sl, 2);
PopBack(&sl, 2);
PopBack(&sl, 1);
Print(&sl);
if (-1 != SeekLift(&sl, 2))//左查找
{
printf("%d\n", SeekLift(&sl, 2));
MODify(&sl, SeekLift(&sl, 2), 20);//修改
Print(&sl);
}
if (-1 != SeekRight(&sl, 2))//右查找
{
printf("%d\n", SeekRight(&sl, 2));
MODify(&sl, SeekRight(&sl, 2), 200);
Print(&sl);
}
InsertPos(&sl, 3, 8);//按数组位置插入
Print(&sl);
InsertPos(&sl, SeekLift(&sl, 2), 33);//在元素左插入
Print(&sl);
InsertRight(&sl, SeekLift(&sl, 2), 44);//在元素右插入
Print(&sl);
printf("%d\n", SIze(&sl));
DEstroy(&sl);
}
void test7()
{
TSL sl;
InitIalization(&sl);//初始话顺序表
PopBack(&sl, 1);
PopBack(&sl, 5);
PopBack(&sl, 3);
PopBack(&sl, 4);
PopBack(&sl, 2);
Print(&sl);
SortMax(&sl);//升序排列
Print(&sl);
SortMin(&sl);//降序排列
Print(&sl);
DEstroy(&sl);
}
void test8()
{
TSL* sl;
TSL sl1;
InitIalization(&sl1);//初始话顺序表
TSL sl2;
InitIalization(&sl2);//初始话顺序表
PushBack(&sl1, 1);
PushBack(&sl1, 6);
PushBack(&sl1, 7);
PushBack(&sl2, 2);
PushBack(&sl2, 3);
PushBack(&sl2, 5);
Print(&sl1);
Print(&sl2);
sl = MErge(&sl1, &sl2);//合并两个有序的顺序表
Print(sl);
DEstroy(sl);
DEstroy(&sl1);
DEstroy(&sl2);
}
int main()
{
test5();
test6();
test7();
test8();
return 0;
}
Implementar dinamicamente o arquivo de cabeçalho
//main1.h 动态头文件
#pragma once
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
#define MAX 10
typedef int datatype;
typedef struct SList//定义顺序表的结构体
{
datatype* num;//数据类型的指针
int sz;//数据元素的个数
int max;//数据元素的最大个数
}TSL;
void InitIalization(TSL* sl);//初始话顺序表
void PopBack(TSL* sl, datatype n);//头插
void PopFornt(TSL* sl);//头删
void PushBack(TSL* sl, datatype n);//尾插
void PushFornt(TSL* sl);//尾删
int SeekLift(const TSL* sl, datatype n);//左查找
int SeekRight(const TSL* sl, datatype n);//右查找
void MODify(TSL* sl, int n, datatype num);//修改
void InsertPos(TSL* sl, int n, datatype num);//按数组位置插入,在元素左插入
void InsertRight(TSL* sl, int n, datatype num);//在元素右插入
void SortMax(TSL* sl);//升排序
void SortMin(TSL* sl);//降排序
int SIze(const TSL* sl);//返回顺序表中元素个数
TSL* MErge(TSL* sl1, TSL* sl2);//合并两个有序的顺序表
void Print(const TSL* sl);//打印顺序表
void DEstroy(TSL* sl);//销毁顺序表
Implementação de funções concretas dinâmicas
//test1.c 动态具体函数的实现
#include"main1.h"
void InitIalization(TSL* sl)//初始话顺序表
{
sl->max = 4;//数据初始元素最大为4个
sl->sz = 0;//数据的起始元素为0个
sl->num = (datatype*)malloc(sizeof(datatype) * sl->max);
}
void Expansion(TSL* sl)//进行扩容
{
datatype* sl1 = (datatype*)realloc(sl->num, sizeof(datatype) * (sl->max * 2));
{
if (sl1 == NULL)//判断是否开辟空间成功
{
perror("sl1 err\n");//开辟失败进行报错
return;
}
else
{
sl->num = sl1;
sl->max *= 2;//更改容量的大小
}
}
}
void PopBack(TSL* sl, datatype n)//头插
{
assert(sl);
if (sl->sz == sl->max)//判断空间是否已满,满则扩容
{
Expansion(sl);
}
int i = 0;
for (i = sl->sz; i > 0; i--)
{
sl->num[i] = sl->num[i - 1];//把插入元素后的前一个元素向后移动
}
sl->num[0] = n;//把数组中的一个元素设置为传入的值
sl->sz++;//元素位置向后移动
}
void PopFornt(TSL* sl)//头删
{
assert(sl);
int i = 0;
for (i = 0; i < sl->sz; i++)
{
sl->num[i] = sl->num[i + 1];
}
sl->sz--;
}
void PushBack(TSL* sl, datatype n)//尾插
{
assert(sl);
if (sl->sz == sl->max)
{
Expansion(sl);
}
sl->num[sl->sz] = n;
sl->sz++;
}
void PushFornt(TSL* sl)//尾删
{
assert(sl);
sl->sz--;
}
int SeekLift(const TSL* sl, datatype n)//左查找
{
assert(sl);
int i = 0;
for (i = 0; i < sl->sz; i++)
{
if (sl->num[i] == n)
{
return i + 1;//数组下标从0开始,所以返回位置进行加1
}
}
return -1;
}
int SeekRight(const TSL* sl, datatype n)//右查找
{
assert(sl);
int i = sl->sz - 1;
for (; i > 0; i--)
{
if (sl->num[i] == n)
{
return i + 1;
}
}
return -1;
}
void MODify(TSL* sl, int n, datatype num)//修改
{
assert(sl);
sl->num[n - 1] = num;
}
void InsertPos(TSL* sl, int n, datatype num)//按数组位置插入,在元素左插入
{
assert(sl);
//判断数组中是否还有空间
if (sl->sz == sl->max)
{
Expansion(sl);
}
int sum = sl->sz;//创建一个变量等于数组中插入元素后的位置
for (; sum > n - 1; sum--)//把坐标还原为数组的下标
{
sl->num[sum] = sl->num[sum - 1];//把插入元素后的前一个元素向后移动
}
sl->num[n - 1] = num;//把数组中的一个元素设置为传入的值
sl->sz++;//元素位置向后移动
}
void InsertRight(TSL* sl, int n, datatype num)//在元素右插入
{
assert(sl);
//判断数组中是否还有空间
if (sl->sz == sl->max)
{
Expansion(sl);
}
int sum = sl->sz;//创建一个变量等于数组中插入元素后的位置
for (; sum > n ; sum--)//把坐标还原为数组的下标
{
sl->num[sum] = sl->num[sum - 1];//把插入元素后的前一个元素向后移动
}
sl->num[n] = num;//把数组中的一个元素设置为传入的值
sl->sz++;//元素位置向后移动
}
void SortMax(TSL* sl)//升排序
{
assert(sl);
//冒泡排序
int i, j, temp;
for (i = 1; i < sl->sz; i++)
{
for (j = 0; j < sl->sz - i; j++)
{
if (sl->num[j] > sl->num[j + 1])
{
temp = sl->num[j];
sl->num[j] = sl->num[j + 1];
sl->num[j + 1] = temp;
}
}
}
}
void SortMin(TSL* sl)//降排序
{
assert(sl);
//冒泡排序
int i, j, temp;
for (i = 1; i < sl->sz; i++)
{
for (j = 0; j < sl->sz - i; j++)
{
if (sl->num[j] < sl->num[j + 1])
{
temp = sl->num[j];
sl->num[j] = sl->num[j + 1];
sl->num[j + 1] = temp;
}
}
}
}
int SIze(const TSL* sl)//返回顺序表中元素个数
{
assert(sl);
return sl->sz;
}
TSL* MErge(TSL* sl1, TSL* sl2)//合并两个有序的顺序表
{
assert(sl1 && sl2);
TSL* sl = (TSL*)malloc(sizeof(TSL));
if (sl == NULL)//判断是否为空
{
perror("malloc: ");//报错且退出
return;
}
InitIalization(sl);
int i = 0;//用来访问数组中的元素
int j = 0;
while (i < sl1->sz && j < sl2->sz)//当任意一个数组中的元素到达尾部时结束循环
{
if (sl1->num[i] <= sl2->num[j])//判断数组中的元素大小,谁小谁进行尾插
{
if (sl->sz == sl->max)
{
Expansion(sl);
}
PushBack(sl, sl1->num[i]);
i++;
}
else
{
if (sl->sz == sl->max)
{
Expansion(sl);
}
PushBack(sl, sl2->num[j]);
j++;
}
}
if (i >= sl1->sz)//判断哪一个数组到达了尾部,把没到达尾部的数组元素进行尾插
{
while (j < sl2->sz)
{
if (sl->sz == sl->max)
{
Expansion(sl);
}
PushBack(sl, sl2->num[j]);
j++;
}
}
else
{
while (i < sl1->sz)
{
if (sl->sz == sl->max)
{
Expansion(sl);
}
PushBack(sl, sl1->num[i]);
i++;
}
}
return sl;
}
void Print(const TSL* sl)//打印顺序表
{
int i = 0;
for (i = 0; i < sl->sz; i++)
{
printf("%d ", sl->num[i]);
}
printf("\n");
}
void DEstroy(TSL* sl)//销毁顺序表
{
assert(sl);
free(sl->num);
sl->num = NULL;
sl->max = 0;
sl->sz = 0;
}
Resumir
Você pode comparar a diferença entre estático e dinâmico. O dinâmico é apenas uma pequena melhoria com base no estático, adicionando uma função de expansão, e os outros são exatamente os mesmos. Em seguida, usaremos um pequeno projeto para aprofundar nossa impressão da sequência table. é a nossa primeira estrutura de dados, e vamos usá-la para comparar com a lista encadeada atrás. Aprender as vantagens e desvantagens de cada estrutura é o que nos permite escolher a solução ótima em diferentes problemas.