Desenvolvimento e otimização de implantação de "sistema de correção de fórmula inteligente"
Resumo
Esta grande atribuição construiu e realizou a otimização de desenvolvimento e implantação do "Sistema de Correção de Fórmula Inteligente". "Sistema de correção de fórmula inteligente" é um sistema de correção inteligente que integra detecção de alvo yolo, reconhecimento de paddleocr e quatro algoritmos de julgamento aritmético. O sistema pode corrigir as páginas carregadas contendo quatro problemas aritméticos, incluindo identificar a área de cálculo e julgar a exatidão dos resultados do cálculo. A página front-end do sistema é construída pela estrutura vue3, e o back-end é construído pela estrutura flask do python, e algumas funções foram sincronizadas com o miniaplicativo WeChat. O sistema tem as funções de detecção, identificação e correção de fórmulas, além de possuir um conjunto de mecanismos de feedback e autoatualização. Depois de muito treinamento e otimização do sistema, a detecção de alvo yolo realizou a detecção precisa das coordenadas da área da fórmula, e o reconhecimento de escrita paddleocr também reconheceu com precisão o conteúdo da fórmula e julgou se o resultado está correto ou não. O efeito geral de correção do sistema é bom, mas ainda há muito espaço para melhorias.
-
Introdução ao "Sistema Inteligente de Correção de Fórmula"
-
1.1 Introdução
A correção de questões de aritmética da escola primária é uma tarefa repetitiva, e o processo é tedioso e fácil de corrigir erros. Portanto, é adequado usar métodos de aprendizado profundo para projetar um sistema de correção para correção inteligente, de modo que o "sistema de correção aritmética inteligente" vem disso. "Sistema de correção de fórmula inteligente" é principalmente para correção de lição de casa de quatro operações aritméticas simples.Este sistema tem as funções de detecção, identificação e correção de fórmula. O sistema possui uma página visual relativamente completa (conforme as Figuras 1 e 2 abaixo), que pode rodar em computadores e celulares.
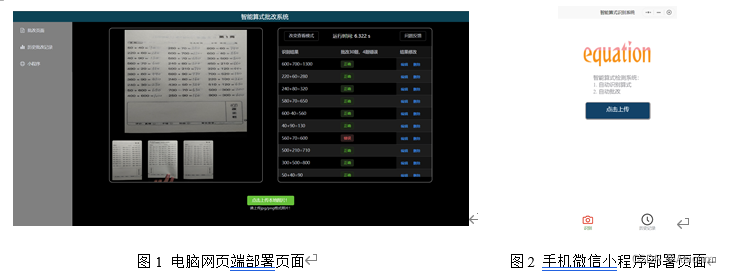
O princípio do sistema é usar yolo para detectar a fórmula primeiro e, em seguida, passar o fragmento de imagem detectado da fórmula para paddleocr para reconhecimento da fórmula. Depois de obter o conteúdo da fórmula, use o algoritmo de quatro julgamentos aritméticos para julgar o resultado do cálculo da fórmula e, finalmente, envie os dados do índice da fórmula, os dados do conteúdo e os resultados do julgamento para a página inicial criada pela estrutura vue3 para visualização (o diagrama esquemático é mostrado na Figura 3 mostrada). Além disso, o "sistema de correção inteligente" também possui feedback de correção de erro humano, funções de feedback de problemas e funções regulares de autoatualização do modelo. Para o modelo de reconhecimento, também o compactamos e otimizamos para aumentar a velocidade de raciocínio.
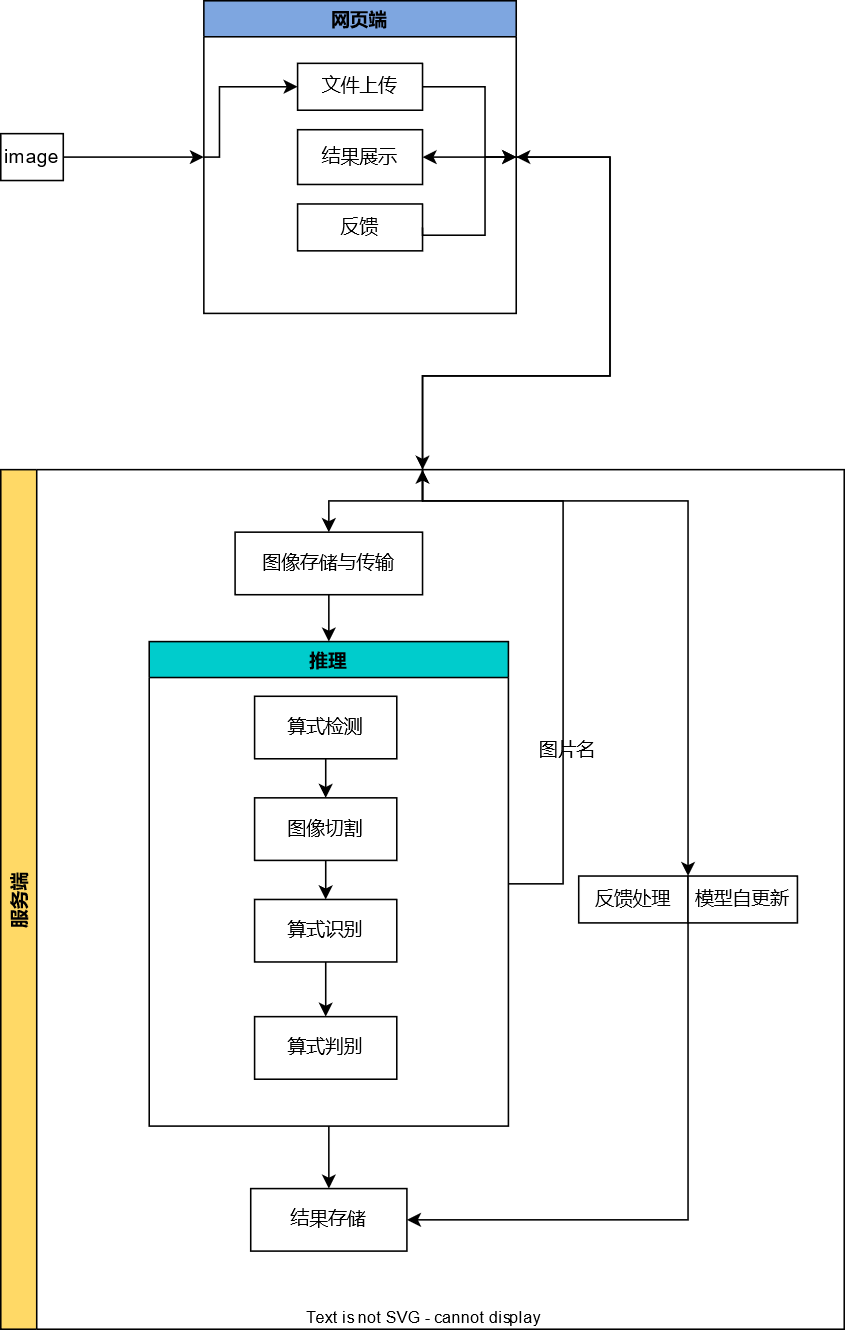
Figura 3 O diagrama de função geral do "Sistema de Correção Inteligente"
1.2 Trabalho relacionado
O desenvolvimento do "sistema de correção de fórmula inteligente" é dividido principalmente em quatro etapas, ou seja, coleta e rotulagem de dados, treinamento de modelo, implantação de modelo e otimização de modelo.
Para coleta e rotulagem de dados, primeiro concluímos um conjunto de exercícios de matemática da escola primária (os resultados do cálculo manual não são 100% corretos), depois carregamos fotos do conjunto de exercícios e usamos a plataforma CVAT para marcar a posição da fórmula e adicionar o conteúdo de a fórmula para o atributo . Depois de concluir a rotulagem dos dados, realizamos a conversão do formato dos dados em conjunto com os conjuntos de dados existentes e dividimos os conjuntos de dados de acordo com determinados métodos.
Para o treinamento do modelo, selecionamos o modelo correspondente a yolo como o modelo de detecção de fórmula e o modelo em paddleocr como o modelo de reconhecimento de fórmula. Durante o processo de treinamento, o modelo de detecção yolo tem um bom efeito, mas o modelo de reconhecimento do algoritmo paddleocr apresenta fenômeno de overfitting.
Para a implantação do modelo, utilizamos o framework vue e o element plus para construir a página front-end, que é responsável principalmente pelo upload de imagens, obtenção de resultados e desenho estatístico. Quanto ao framework back-end, escolhemos o framework flask do python, que é o principal responsável por receber imagens, detectar algoritmos, cortar imagens, identificar conteúdo e retornar conteúdo para o front-end. Ao mesmo tempo, o back-end também sincronizará com os resultados da modificação dos usuários do front-end, registrará o conteúdo do feedback e terá uma estratégia de atualização automática do modelo.
Para otimização do modelo, primeiro quantificamos o modelo de reconhecimento de remo para tornar o resultado do peso menor e mais fácil de armazenar e calcular. Além disso, também construímos um mecanismo de autoatualização do modelo, usando as imagens carregadas e previstas pelo usuário como conjunto de dados e, quando o número atinge um determinado limite, o programa inicia o modo de treinamento para atualizar o mais realista resultados de peso para reposição.
-
Anotação de dados baseada em CVAT
2.1 Rotulagem de dados
Antes de treinar o modelo, é necessário coletar um conjunto de dados adequado e marcar o conteúdo necessário do conjunto de dados, que pode estar certo ou errado. Depois de preencher, tire uma foto e salve.

Figura 4 Exemplo de página para exercícios de cálculo oral
Carregue o conjunto de imagens da página de exercício salva no site de anotação de conjunto de dados compartilhado CVAT para anotação de dados.
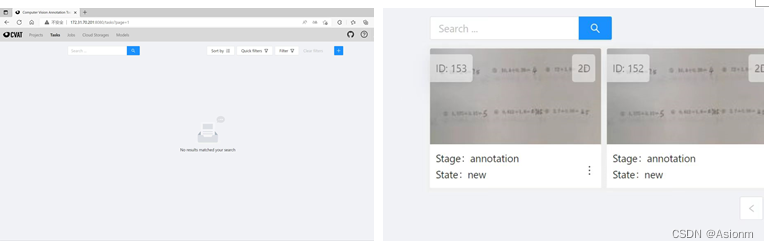
Figura 5 Carregue a imagem salva definida para CVAT
Use uma ferramenta de rotulagem baseada em CVAT para rotulagem, use principalmente um retângulo para enquadrar a fórmula, o formato é "equação", o conteúdo da etiqueta é o resultado da fórmula e do preenchimento manual e exporte o resultado da rotulagem para o formato xml como um conjunto de treinamento para subsequente treinamento do Algoritmo de detecção de alvo yolo.
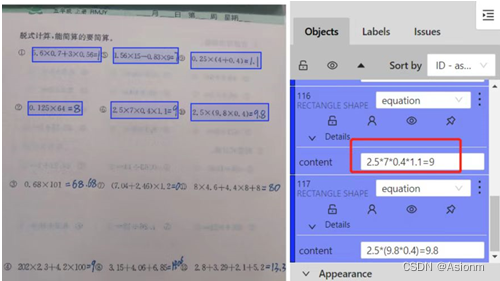
Figura 6 Exemplo de rotulagem de dados
Para o conjunto de dados de treinamento paddleocr, a imagem original geralmente é colocada na mesma pasta que a imagem de treinamento e um arquivo txt é usado para registrar o caminho e o rótulo da imagem. O conteúdo do arquivo txt é o seguinte:
" Nome do arquivo de imagem informações de anotação da imagem "
train_data/rec/train/word_001.jpg conteúdo de texto 1
train_data/rec/train/word_002.jpg conteúdo de texto 2
...
E o caminho da imagem e o rótulo do texto precisam ser separados por " ", caso contrário, um erro será relatado durante o treinamento. A estrutura do caminho do arquivo do conjunto de treinamento final deve ser a seguinte:
|-train_data
|-rec
|- rec_gt_test.txt
|- trem
|- palavra_001.jpg
|- palavra_002.jpg
|- palavra_003.jpg
| ...
2.2 Divisão do conjunto de dados
O conjunto de dados de reconhecimento de texto paddleocr desta vez usa a combinação do conjunto de imagens de quatro páginas de exercícios aritméticos existentes e o conjunto de exercícios preenchido manualmente, corta a página de exercícios em blocos contendo apenas a parte do cálculo e registra o conteúdo do cálculo da imagem e o caminho da imagem, e os conjuntos de dados são divididos aleatoriamente 7:3. Tome o conjunto de treinamento como um exemplo, conforme mostrado na figura:

Figura 7 conjunto de treinamento paddleocr conforme mostrado na figura
-
Design de modelo baseado em yolo e paddleocr
Detecção de alvo 3.1 yolo
A "correção de fórmula inteligente" é dividida principalmente em três etapas, a primeira etapa é localizar a posição da fórmula. Então, aqui usamos yolov5 para treinar o conjunto de dados para atingir o objetivo de detectar fórmulas.
3.1.1 Configuração antes do treinamento
A configuração antes do treinamento inclui principalmente três conteúdos, ou seja, conversão de formato de conjunto de dados, arquivo de configuração de conjunto de dados e configuração de estrutura de rede.
- Conversão de formato de conjunto de dados
Primeiro, o formato dos dados é processado. Como alguns conjuntos de dados estão no formato voc, os dados neste formato precisam ser convertidos para o formato yolo. Para o formato voc, seu arquivo é um arquivo do tipo xml, enquanto o yolo está no formato txt. Portanto, a conversão de formato é principalmente para extrair as informações de coordenadas no arquivo xml para o arquivo txt. Para obter o código, consulte datasets/custom/ format conversion /voc2yolo.py em yolov5.zip , o código é referenciado principalmente em
[O tutorial mais completo] Formato VOC para formato YOLO data_voc para yolo_Blue fat fat ▸'s blog-CSDN blog . O formato yolo convertido é o seguinte, no qual cada imagem corresponde a um arquivo txt e os valores das coordenadas são armazenados principalmente no arquivo txt.

Figura 8 formato de etiqueta yolo
- Arquivo de configuração do conjunto de dados
Depois de transformar o conjunto de dados, edite o arquivo de configuração do conjunto de dados. Este arquivo é encontrado em yolov5-master/data/equation.yaml no pacote compactado yolov5.zip . Seu conteúdo é principalmente para definir o caminho do conjunto de dados e a categoria de classificação. Seu conteúdo é mostrado na figura abaixo.

Figura 9 Conteúdo do arquivo de configuração do conjunto de dados
- Configuração da estrutura de rede
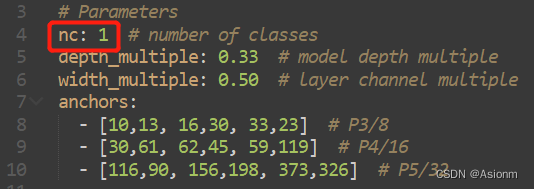
Para a rede usada para treinamento, escolhemos o modelo de rede yolov5s . Para o modelo original, suas categorias de saída são 80, então aqui precisamos alterar 80 para 1. O endereço modificado é yolov5-master/models/yolov5s.yaml em yolov5.zip . O conteúdo modificado é o seguinte e o valor de nc é alterado para 1.
|
|
| Figura 10 configuração da estrutura de rede yolo |
3.1.2 Treinamento modelo
Depois de concluir a configuração de pré-treinamento, a próxima etapa é treinar o modelo. No início do treinamento do modelo, usamos nosso próprio computador. Como não havia placa gráfica, o efeito era relativamente ruim. Posteriormente, compramos um servidor GPU em Tencent Cloud, para migrar os pesos obtidos no treinamento anterior em nosso próprio computador para o servidor GPU para treinamento.
O treinamento no servidor GPU primeiro precisa compactar a pasta yolov5 e transferi-la para o servidor e, em seguida, descompactá-la. Após a descompactação, digite o comando cd yolov5/yolov5-master para entrar na pasta e, em seguida, digite o comando pip install -r requisito.txt para instalar o pacote correspondente. A instalação do pytorch precisa se referir ao site oficial para instalar o gpu correspondente versão. Após a conclusão da instalação, digite o seguinte comando para treinar. O comando passa os parâmetros para train.py, especifica o arquivo de configuração do conjunto de dados, o arquivo de rede do modelo, o caminho do modelo pré-treinado, o tamanho do processamento da imagem e o número de épocas.
![]()
A captura de tela durante o treinamento é mostrada abaixo,
|
|
| Figura 11 captura de tela do treinamento yolo |

3.1.3 Resultados do treinamento
Quando a rodada 336 foi concluída, como não havia espaço para melhorias, o sistema lançou o treinamento e salvou os resultados, conforme mostrado na captura de tela abaixo. O arquivo de resultado exp18 pode ser encontrado em yolov5-master/runs/train/exp18 no pacote compactado yolov5.zip .
|
|
| Figura 12 Captura de tela após a conclusão do treinamento yolo |

Conecte os resultados do treinamento no servidor gpu às 10 rodadas de resultados do treinamento local para desenhar a figura a seguir,
|
|
| Figura 13 gráfico de resultados do treinamento yolo |
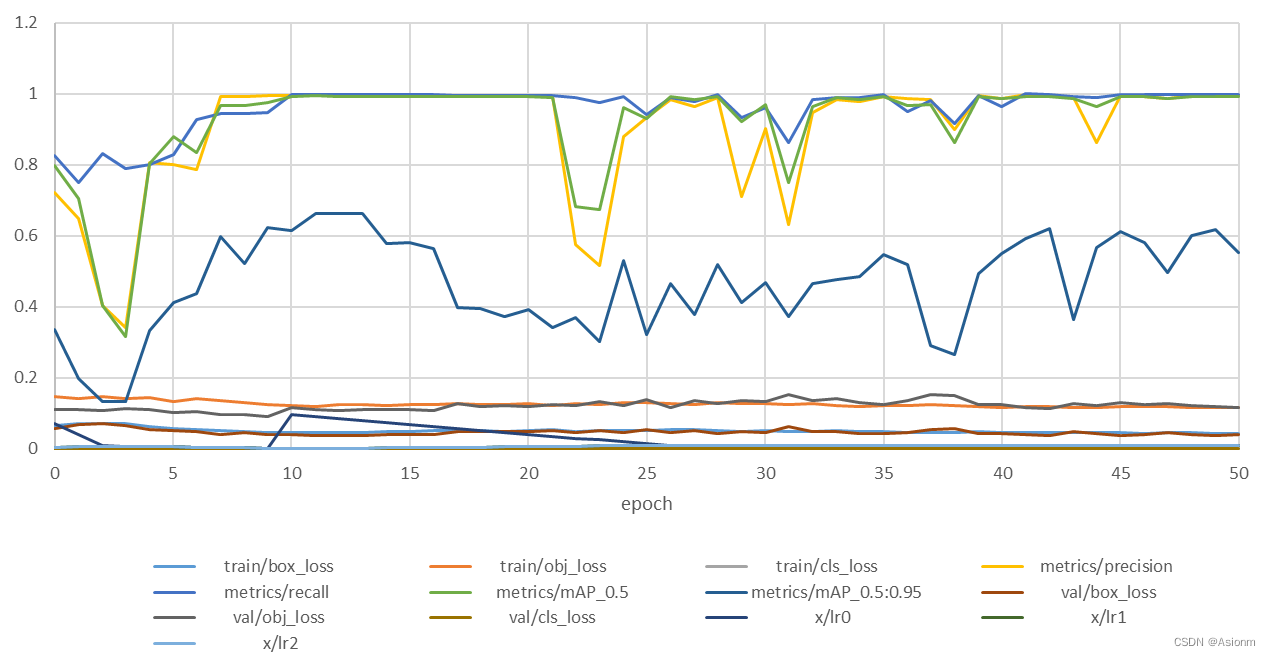
O eixo horizontal são as rodadas de treinamento, como os resultados das rodadas subseqüentes são basicamente os mesmos, as primeiras 50 rodadas são interceptadas aqui, e o eixo vertical é o valor de cada indicador. Pode-se ver que o valor map50, valor de precisão, taxa de recuperação e outros indicadores mostraram uma certa tendência de queda no início, mas isso durou pouco. O valor do último indicador subiu rapidamente para perto de 0 e depois se estabilizou em 0,9, e ficou entre 20 e 35. Há grandes flutuações entre rodadas e depois estabilidade regional. Quanto ao índice de valor de perda, ele tende basicamente a uma tendência de queda, com algumas oscilações no meio, mas basicamente estável.
A partir da análise do gráfico acima, pode-se ver que o modelo de detecção de alvo yolo pode basicamente lidar bem com os problemas de detecção do conjunto de dados atual e sua taxa de precisão é basicamente mantida acima de 0,9.
3.1.4 Insuficiência do Modelo e Direção de Melhorias
Embora o modelo yolo treinado desta vez possa detectar efetivamente as fórmulas no conjunto de dados, verificou-se em testes subsequentes que ele não pode lidar efetivamente com outras páginas de fórmula que são diferentes do estilo do conjunto de dados, conforme mostrado na Figura 9 abaixo. Existem muitas palavras no conjunto de dados original, mas a nova página de fórmula possui palavras semelhantes ao formato da fórmula, portanto, a situação mostrada na figura abaixo tende a aparecer, o que também mostra que a aplicabilidade geral desse modelo é não é bom. Além disso, ele também reconhecerá alguns ambientes especiais, como a fórmula de cálculo do verso escrita com muito vigor para que algumas partes sejam exibidas e face a face.
|
|
|
| Figura 14 Mapa de erro de reconhecimento de modelo |
|

Para esta situação, nossa próxima direção de melhoria é aumentar os conjuntos de dados de diferentes categorias e diferentes ambientes para melhorar a capacidade de generalização do modelo e, ao mesmo tempo, melhoraremos o modelo por meio do aumento de dados.
3.2 reconhecimento do algoritmo paddleocr
3.2.1 Conexão local com recursos Tencent Cloud GPU
O treinamento de reconhecimento de texto do Paddleocr requer uma grande quantidade de conjuntos de dados para convergência de treinamento, e os notebooks dos membros da equipe possuem apenas uma CPU sem uma GPU independente, portanto, a eficiência do treinamento é muito lenta e o efeito é ruim. Portanto, é considerado conecte o computador aos recursos de GPU no Tencent Cloud para treinamento. Entre no site oficial da Tencent Cloud, opte por comprar um servidor em nuvem adequado e selecione uma configuração de servidor adequada. Aqui escolhemos o modelo de GPU GN8 adequado para treinamento de aprendizado profundo, incluindo memória 56G, 6 núcleos e configuração de memória 200G.
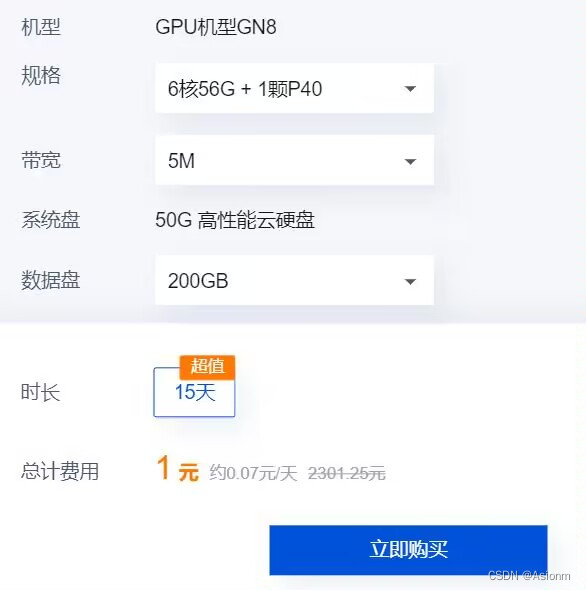
Figura 15 Servidor GPU usado
Após registrar uma conta no site oficial da Tencent Cloud para adquirir os recursos da GPU, reinstale o sistema como um sistema Ubuntu para facilitar as operações de conexão e codificação. Abra o pycharm local, conecte o terminal em execução ao terminal Ubuntu no servidor em nuvem Tencent conectando-se ao IP da rede pública e insira o nome de usuário e a senha para usar os recursos de GPU do servidor em nuvem localmente.
|
|
|
| Figura 16 Conectando-se aos recursos do terminal Tencent Cloud |
|
3.2.2 Instalar o ambiente PaddlePaddle
Este treinamento usa o sistema de reconhecimento paddleocr maduro do Baidu Feijiang como base, baixa a estrutura paddleocr do GitHub (link na referência) e carrega e sincroniza-a com o sistema Ubuntu em nuvem.

Figura 17 Paddleocr baixado
Instale o ambiente paddlepaddle e os pacotes de dependência correspondentes antes do treinamento:
|
|
|
| Figura 18 Ambiente e instalação da biblioteca dependente |
|
3.2.3 Iniciar treinamento
- Download e preparação do modelo de treinamento
Baixe o modelo oficial de treinamento de reconhecimento de texto paddleocr em gitee, aqui está o modelo de treinamento super leve em chinês e inglês

Figura 19 download do modelo de treinamento de reconhecimento de caracteres paddleocr
Selecione o arquivo yml apropriado, altere o caminho de importação do conjunto de treinamento e os dados do conjunto de verificação para o caminho do conjunto de dados dividido anteriormente e ajuste o número de rodadas de treinamento, tamanho do lote e taxa de aprendizado

Figura 20 Arquivo yml selecionado
- modificação do dicionário
Como no processo de reconhecimento de fórmula, o conteúdo a ser reconhecido é apenas números e símbolos de operação, portanto, o arquivo de dicionário original precisa ser modificado para que o conteúdo da saída de reconhecimento seja apenas números e operadores. Aqui é preciso atentar para a particularidade do sinal de divisão, que deve ser o símbolo "÷"
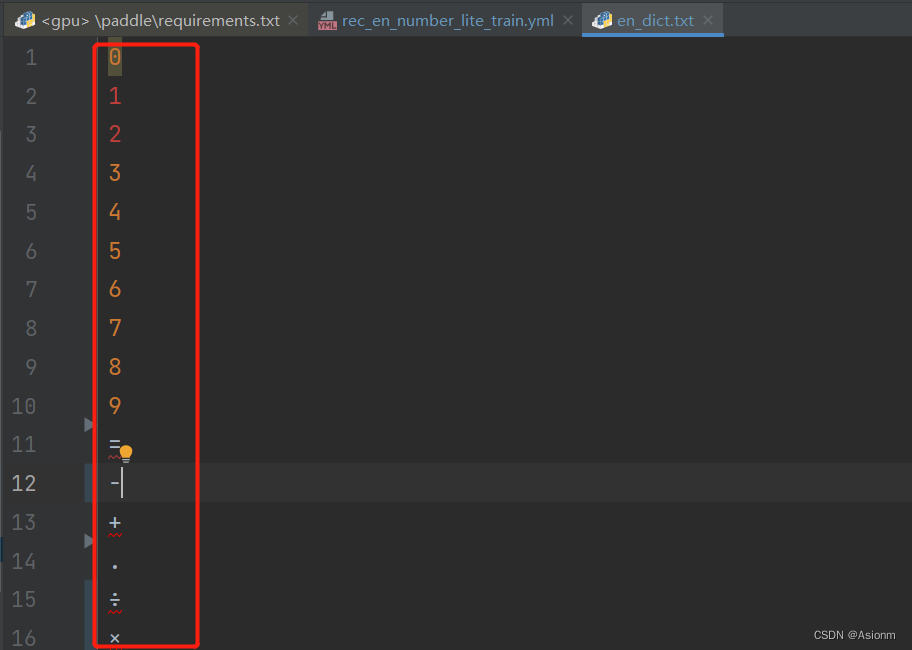
Figura 21 arquivo de dicionário
- treinamento de fundo
Para iniciar o código de treinamento, você precisa chamar o arquivo yml selecionado e o arquivo train.py no terminal, especificar o modelo de treinamento baixado e salvar o melhor arquivo de parâmetro de peso após o treinamento
# treinamento GPU
#Training icdar15 O registro de treinamento de dados em inglês será salvo automaticamente como train.log em "{ save_model_dir }"
ferramentas python/train.py -c configs/rec/multi_language/rec_en_number_lite_train.yml -o Global.pretrain_model=pretrain_models/ch_PP-OCRv3_rec_train/best_accuracy
Devido à conexão de rede instável, é fácil desconectar durante o processo de treinamento e causar falhas no treinamento. Portanto, o treinamento de fundo nohup é usado para garantir a estabilidade e a continuidade do treinamento. Primeiro, escreva o arquivo train.sh, insira o código do comando de treinamento no arquivo, conceda a permissão de execução ao arquivo sh e importe o resultado de saída para o arquivo nohup.out,

Figura 22 Código de comando em execução em segundo plano
Posteriormente, o processo de treinamento em tempo real e os resultados do treinamento podem ser observados no arquivo nohup.out gerado
Figura 23 conteúdo de saída nohup.out
3.2.3 Predição e exportação do modelo
Depois que o modelo é treinado, o modelo precisa ser testado e previsto. Selecione aleatoriamente uma imagem de quatro exercícios aritméticos para detecção, pode-se ver que o efeito de reconhecimento do modelo é bom.
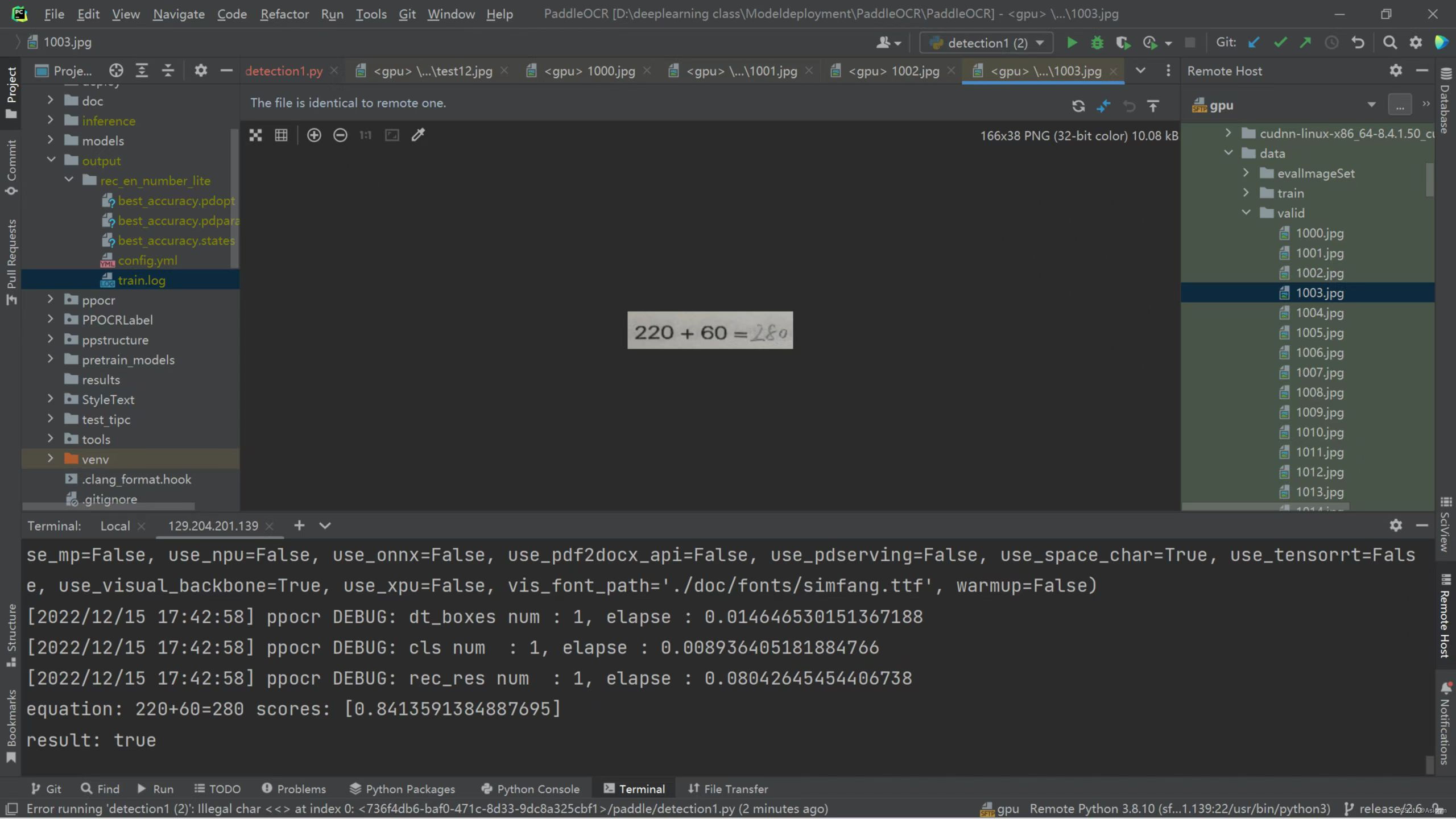
Figura 24 Resultados da detecção do modelo de treinamento
Para exportar o modelo de treinamento treinado para um modelo de inferência disponível posteriormente, o comando é o seguinte:
# Defina o arquivo de configuração yml do algoritmo de treinamento após -c
# -o parâmetros opcionais de configuração
# O parâmetro Global.pretrained_model define o endereço do modelo de treinamento a ser convertido, sem adicionar o sufixo de arquivo .pdmodel , .pdopt ou .pdparams .
# O parâmetro Global.save_inference_dir define o endereço onde o modelo convertido será salvo.
ferramentas python/export_model.py -c configs/rec/multi_language/rec_en_number_lite_train.yml -o Global.pretrained_model=output/rec_en_number_lite//best_accuracy Global.save_inference_dir=inference/equation_rec/
O modelo de inferência exportado está na pasta de inferência.
3.2.4 Algoritmo de Discriminação e Interface de Reconhecimento de Quatro Operações Aritméticas
Depois que o modelo é exportado, para conectar o front-end e a detecção de alvo do yolo, é necessário reconhecer o conteúdo do texto da fórmula de cálculo do bloco de detecção fornecido pelo yolo e analisar se o resultado do cálculo está correto . Parte do código do algoritmo é mostrado na figura e o código completo está no arquivo de detecçãoq1.py no arquivo paddleocr. O princípio geral é extrair os resultados de números, operadores e "=" do conteúdo de texto reconhecido e, em seguida, colocar e operar de acordo com a ordem de operação de acordo com o conteúdo reconhecido e comparar os resultados da operação com os resultados do reconhecimento de texto para julgar se é certo ou errado.
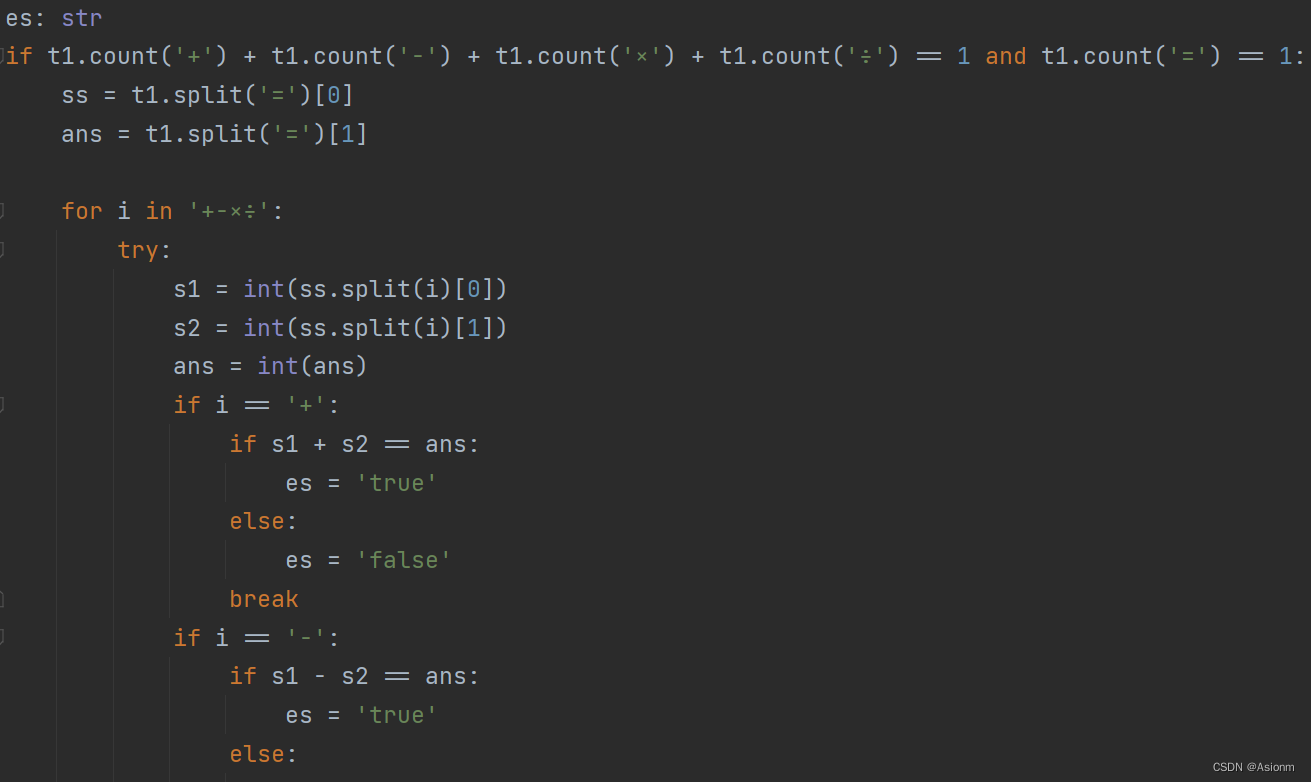
Figura 25 Algoritmo de discriminação para resultados de quatro operações aritméticas
-
Implementação de modelo baseado em flask , vue e applet WeChat
Para a implantação do modelo, implementamos a implantação na página da web do computador e do celular. A página na página da web do computador é escrita usando o framework vue, enquanto o celular usa um pequeno programa usando uniapp baseado em vue. Seja um computador ou um telefone celular, o servidor back-end depende da estrutura flask. O processo de implantação será descrito em detalhes a seguir.
4.1 back-end do balão
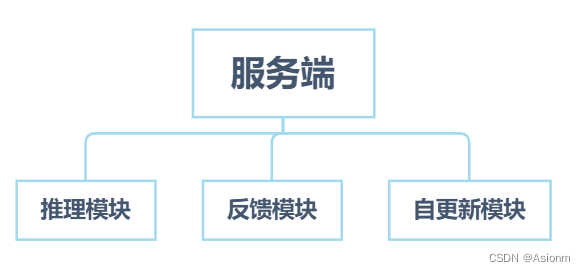
A principal função do back-end do Flask é organizar os resultados do raciocínio do modelo e as informações de desempenho no formato json e enviá-los para o front-end, além de armazenar as informações. O backend é dividido principalmente em módulo de raciocínio, módulo de feedback e módulo de atualização automática. A seguir apresentarei as funções e processos de execução de cada módulo um a um.
|
|
| Figura 26 Organograma do servidor |
- módulo de raciocínio
O módulo de raciocínio é a parte central do servidor e pode ser subdividido em três partes: detecção de algoritmo, reconhecimento de algoritmo e correção de algoritmo. Entre eles, a detecção aritmética é realizada usando yolo, que foi descrito em detalhes acima. Depois que cada fórmula for detectada, seu valor de coordenada será obtido e o programa usará esses valores para cortar a imagem e transferi-la para paddleocr um a um para reconhecimento da fórmula. A fórmula reconhecida será enviada para a área de correção de fórmulas para correção e por fim será obtido o valor de Verdadeiro ou Falso. A parte de processamento de imagem do programa é realizada através do opencv. Haverá registros de tempo durante todo o processo de execução da inferência para contar o desempenho da inferência e passar essas informações de tempo para o front-end.
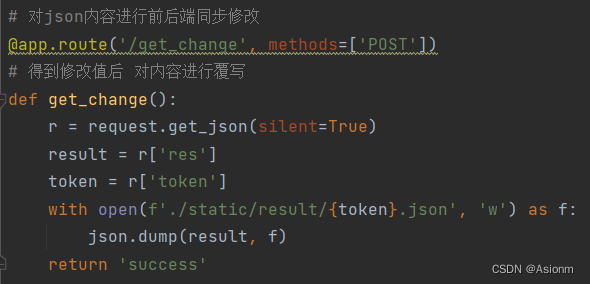
- módulo de feedback
O módulo de feedback desempenha principalmente as funções de edição de resultados e feedback de função. O módulo de feedback será vinculado ao front-end. Quando o usuário edita ou exclui uma fórmula, o front-end enviará os resultados da edição para o back-end e o back-end atualizará o arquivo json no back-end terminam em tempo real com base nesses resultados. O conteúdo do código é mostrado na Figura 11 abaixo.
|
|
| Figura 27 Código de back-end de edição de resultados |
O feedback funcional será inserido no arquivo de informações de feedback atual de acordo com o conteúdo realimentado pelo usuário do front end. Este arquivo será nomeado após a data no formato txt e seu conteúdo de amostra é mostrado na Figura 12 abaixo.
|
|
| Figura 28 Documento txt de plano de fundo do feedback do problema |

- módulo de atualização automática
O módulo de atualização automática é usado principalmente para criar conjuntos de dados automaticamente para treinamento de atualização automática. Eu construo este módulo através do método de uma classe chamada update, e seu organograma é o seguinte.
|
|
| Figura 29 Organograma de classe com atualização automática |

O módulo de inicialização é usado principalmente para adicionar uma lista de nomes de arquivos protegidos e criar uma pasta de salvamento. A função get json data é usada para obter todos os dados na pasta json na pasta. A função de julgamento completo é usada para julgar se o número de fotos na pasta atingiu o número que pode ser usado para construir um conjunto de dados e, se estiver cheio, execute o programa. A função do programa em execução é a parte principal da classe. Sua função é gravar todos os arquivos json obtidos no arquivo label.txt, cortar a imagem e excluir o arquivo original. O módulo de atualização automática só pode ser usado para construir o conjunto de dados de treinamento e não fornece uma interface para treinamento automático, pois pode exigir revisão manual da correção do conjunto de dados.
Descrição do código-fonte do back-end: o código-fonte do back-end é armazenado no pacote .zip back- end da equação , entre os quais server.py é o programa usado principalmente para executar, desde que o comando python server.py seja entrada para executar o servidor. Run.py é o arquivo usado para inferência. Detection.py é um arquivo para reconhecimento de algoritmo e update.py é um arquivo para autoatualização. A pasta estática é usada principalmente para armazenar imagens enviadas e arquivos de resultados, e a pasta de feedback armazena arquivos de informações de feedback. O resto dos arquivos são os arquivos que vêm com a incorporação de yolov5 e paddleocr.
4.2 Projeto de front-end Vue
O design de front-end aqui se refere ao design da página da Web do computador, que é usado principalmente para exibição visual. Ele pode fornecer as funções de upload de imagens, recebimento, exibição, edição de resultados de raciocínio e feedback de perguntas. Além disso, existem algumas páginas de índice não desenvolvidas, como páginas de registro de correção. O seguinte apresentará principalmente os módulos de função de exibição e feedback.
- Exibição do resultado
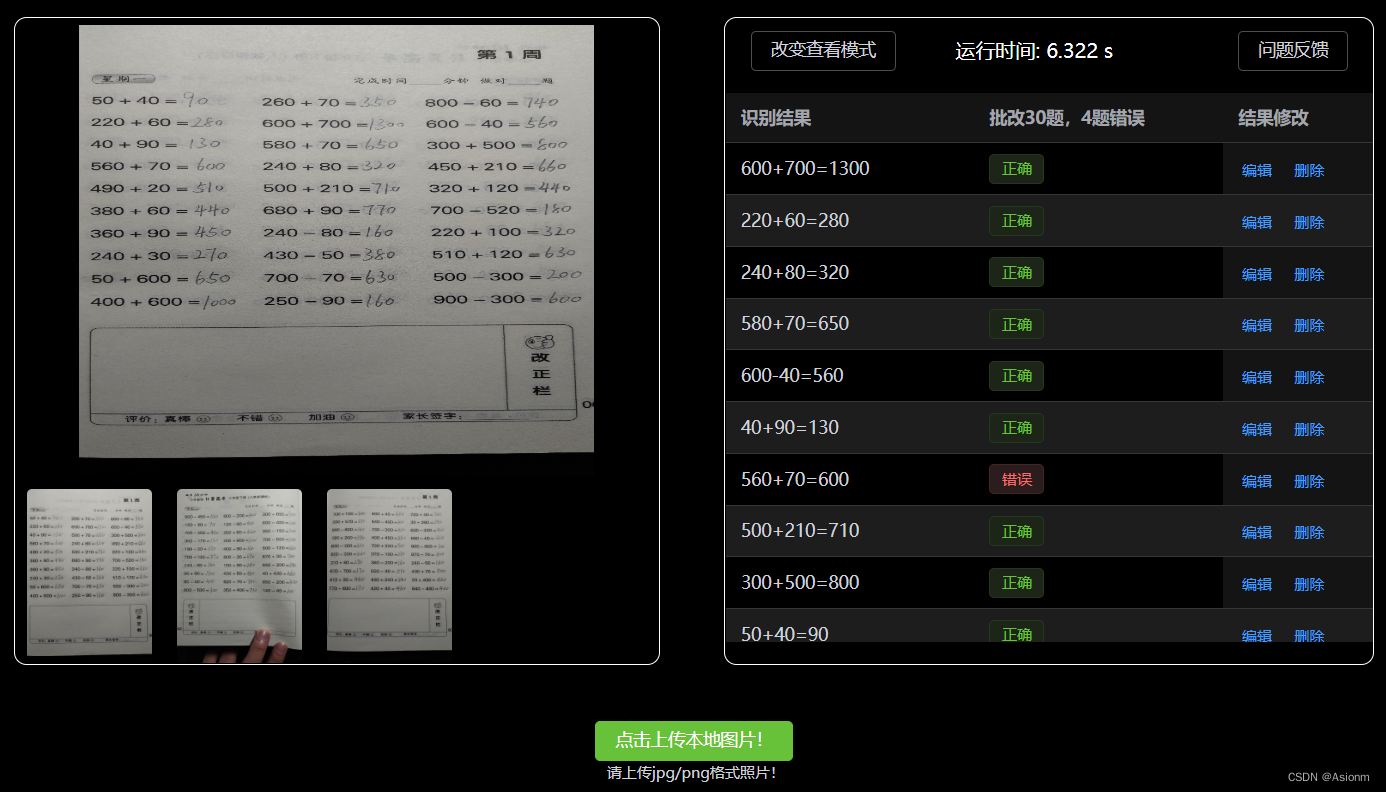
Existem dois modelos de exibição para a exibição do resultado no computador web, um é o modo de texto simples e o outro é o formato de quadro (conforme mostrado nas Figuras 13 e 14 abaixo).
|
|
|
| Figura 30 Formato de exibição de resultado de texto simples |
Figura 31 Formato de exibição do resultado em quadros |
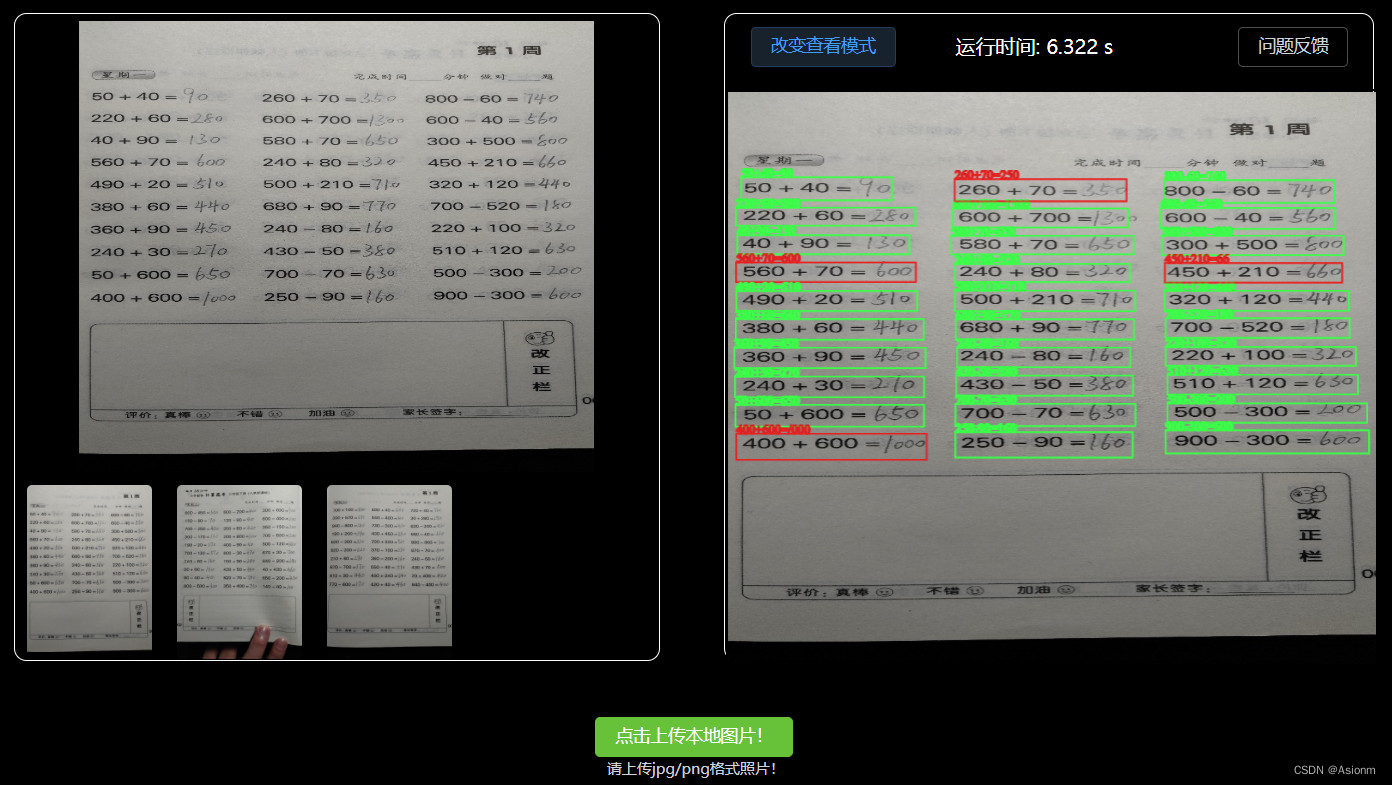
结果展示页面以及下面的功能反馈页面均集中于一个组件中进行编写,组件的名称为UpdatePart.vue中。展示区的原理是通过axios接收后端传回来包含算式坐标、内容、正确信息、运行效率的信息,然后将这些信息进行渲染统计。其中渲染的页面主要通过element plus和canvas的第三方库fabric.js进行。电脑网页端不仅仅是单张的识别,可以进行多张的切换,且一打开页面时就可以看到三张demo照片。
- 功能反馈
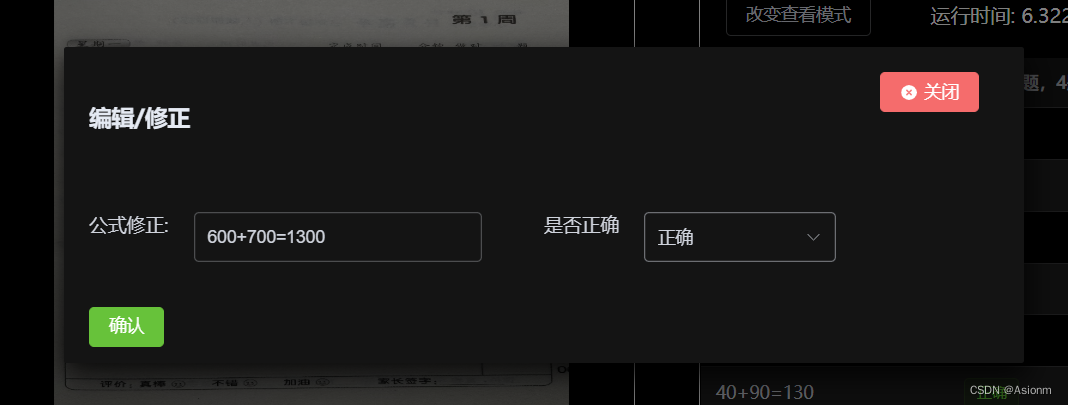
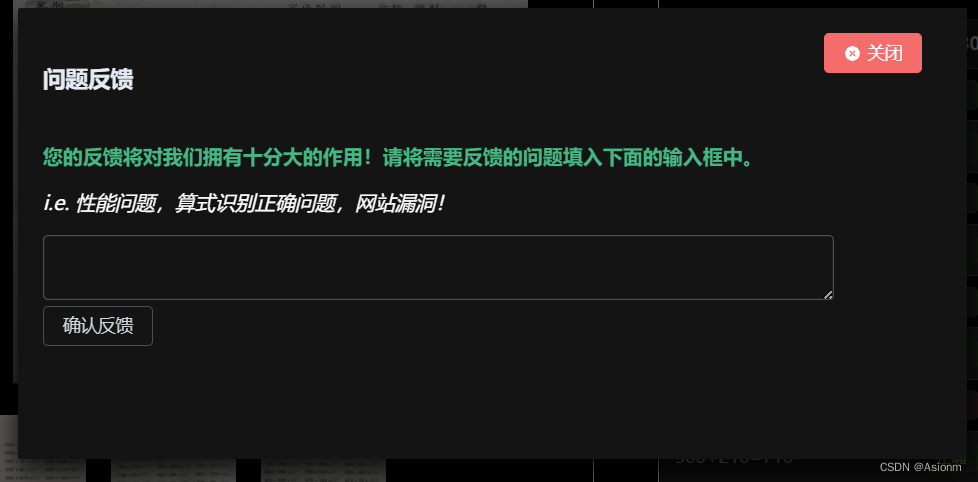
此处的功能反馈包括了算式编辑、删除、功能反馈这几方面,算式编辑删除的页面如下图图15所示,功能反馈如图16所示。
|
|
| 图32 算式编辑页面 |
|
|
| 图33 问题反馈页面 |
每当编辑按钮为确认时,编辑结果状态就会为True然后当切换图片或关闭页面时,前端就会将编辑的信息发送给后端以实现同步。而对于问题反馈,其原理仅仅只是个文本发送的功能。
源码文件说明:若要运行前端程序,需要先用npm i安装相应的以来包。电脑web端的代码在equation.zip处,其中主要的代码存储于src/views处,其包括了主要的几个页面,如索引页面、上传展示页面、未开发的历史页面、小程序页面。而主要的代码是通过组件的形式传到上传展示页面的,此文件位于src/components/Uploader.vue。除此之外src/api主要用于封装axios用于网络传输,src/router文件夹主要存储路由信息,src/main.js是整体的一些配置如引入全局包等等。
4.3 微信小程序设计
微信小程序使用的是uniapp,而其代码基本与电脑端的类似仅仅只是进行了一定的适应性修改。微信小程序的功能相对于电脑网页端的而言只保留了单张推理展示的功能,并未提供编辑结果、功能反馈等的功能。同时由于后端服务器只是为临时性服务器所以并未申请域名于ssl证书所以开真实使用上并不能连接到后端因此目前小程序只存在外观展示。而在开发中小程序的功能已经得以实现,具体的展示视频可见于小程序展示.mp4。具体代码可见于小程序.zip压缩包中,由于功能基本于电脑网页端的一致,因此不再展开描述。
-
模型压缩与自更新策略
5.1 模型优化讨论
对于我们模型中存在的问题,我们已在第三章模型设计中进行了论述。为了解决这些问题,我们将实现一系列的优化方法。为了应对模型的泛化能力不足的问题,我们将从添加各种环境下的数据以构成更庞大的数据集进行训练得到泛化能力更强的模型。而对于推理速度慢的问题,我们将从模型压缩方面考虑,将模型进行量化。将32位浮点数转换为8位置整型数以提升cpu的运行能力,同时也减少模型的体积减缓存储压力。下面将从上面提到的两方面进行详细论述实行。
5.2 模型自更新策略
更大的数据集用于训练,在此处我们通过模型的自更新策略进行。自更新原理已在第四章服务端中的自更新模块进行了论述,因此此处不再进行论述。对于此策略,我们主要通过大批量用户提供的经过一定修改的数据构成新的训练数据集,然后调用paddleocr的训练接口进行进一步的训练,在训练完后经过机器验证或人工验证无误后,将此权重代替旧的。因此模型的泛化能力将会得到提供,此策略主要依靠于用户的使用量,若用户多使用次数也多那么生成的数据集也越大越丰富,相应更新出来的模型泛化能力也会越强。下图为自动构建的数据集截图。主要代码可见于equation后端.zip中的update.py文件。
|
|
| 图34 自动生成数据集截图 |

5.3 paddleocr识别模型模型压缩
复杂的模型有利于提高模型的性能,但也导致模型中存在一定冗余,模型量化将全精度缩减到定点数减少这种冗余,达到减少模型计算复杂度,提高模型推理性能的目的。使用量化后的模型在移动端等部署时更具备速度优势。而 PaddleSlim 集成了模型剪枝、量化(包括量化训练和离线量化)、蒸馏和神经网络搜索等多种业界常用且领先的模型压缩功能。
- 安装paddleslim
使用pip 下载2.3.2版本
pip3 install paddleslim==2.3.2

图35 paddleslim安装
- 量化训练
将训练好的模型进行量化训练,量化训练包括离线量化训练和在线量化训练,在线量化训练效果更好,需加载预训练模型,在定义好量化策略后即可对模型进行量化。量化训练的代码位于slim/quantization/quant.py 中,比如训练检测模型,以PPOCRv3检测模型为例,训练指令如下:
python deploy/slim/quantization/quant.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml -o Global.pretrained_model='ch_PP-OCRv3_rec_distill_train/best_accuracy' Global.save_model_dir=./output/quant_model_distill/
- 导出模型
在得到量化训练保存的模型后,我们可以将其导出为inference_model,用于预测部署:
python deploy/slim/quantization/export_model.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_rec_cml.yml -o Global.checkpoints=output/quant_model/best_accuracy Global.save_inference_dir=./output/quant_inference_model
5.4 后期优化讨论
目前的模型仍拥有很大的优化提升空间,目前模型的推理速度仍可以进一步提升。后期我们将通过知识蒸馏的方法尝试使用更小地模型尝试更进一步加快推理速度。除此之外,目前算式识别的内容仅仅只是四则运算内容,而后期若要提高其实用性,那么就不仅仅只是四则运算,还希望能够识别如微积分运算、对数运算、复合运算等更复杂的公式判别和结果判断,所以下一步我们也将引入latex格式公式以求进一步优化模型。
结论
本文中识别模型部分主要架构为yolo目标检测和paddleocr文本识别,而在训练过程中遇到了非常多的问题,包括数据集格式、训练集和数据集导入路径问题,以及在训练后检测效果差的问题。对于paddleocr,由于训练集模板数量仍不足够,且训练的时间成本高,发生了训练过拟合、检测结果出现中英文等等问题,逐个原因排查后,训练后的模型的检测效果和不同场景、不同纸张与不同字迹的识别准确度仍有很大的进步空间,初步分析为有选用的paddleocr中的训练模型CRNN网络结构仍有待针对性的调整、数据集的选用、数据预处理的合理性以及是否考虑数据增广等等因素。整体智能批改习题的核心识别部分有待进一步的改进和完善。