Diretório de artigos
Há alguns dias, havia um requisito no projeto de que era necessário um switch para controlar se uma parte da lógica foi executada no código, então é natural configurar ymluma propriedade no arquivo como um switch, e então podemos nacosalterar esse valor a qualquer momento para atingir nosso objetivo, yml Isso está escrito no arquivo:
switch:
turnOn: on
O código no programa também é muito simples. A lógica geral é a seguinte. Se o campo switch obtido for sim , então o código no julgamento onserá executado , caso contrário, não será executado:if
@Value("${switch.turnOn}")
private String on;
@GetMapping("testn")
public void test(){
if ("on".equals(on)){
//TODO
}
}
Mas quando o código realmente é executado, vem a parte interessante: descobrimos que o código no julgamento não será executado até que o depuremos e descobrimos que o valor obtido aqui não é onrealmente true.
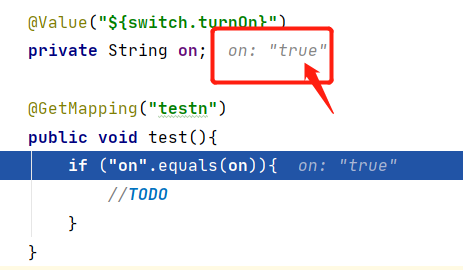
onVendo isso, parece um pouco interessante? Em primeiro lugar, o palpite cego é que ele é tratado como um valor especial no processo de análise de yml , então simplesmente testei mais alguns exemplos e estendi os atributos em yml para o seguinte :
switch:
turnOn: on
turnOff: off
turnOn2: 'on'
turnOff2: 'off'
Execute o código novamente para ver o valor mapeado:

Pode-se ver que a soma sem aspas em yml oné offconvertida em sum true, falsee a soma com aspas mantém o valor original inalterado.
Nesse ponto, não pude deixar de ficar um pouco curioso, por que esse fenômeno aconteceu? Então, suprimi minha sonolência e folheei o código-fonte, e dei uma boa olhada no processo de SpringBoot carregando o arquivo de configuração yml e, finalmente, deixe-me ver um pouco, vamos falar sobre isso pouco a pouco!
Como o carregamento do arquivo de configuração envolverá algum conhecimento relevante sobre a inicialização do SpringBoot, se você não estiver muito familiarizado com a inicialização do SpringBoot, poderá dar uma olhada no Hydra nos primeiros dias . . Na introdução a seguir, apenas algumas etapas importantes para carregar e analisar arquivos de configuração serão extraídas e analisadas, e outras partes irrelevantes serão omitidas.
carregar ouvinte
Quando iniciamos um programa SpringBoot, quando ele é executado , 11 interceptores que implementam a interface são carregados SpringApplication.run()primeiro durante o processo de inicialização .SpringApplicationApplicationListener

Estes 11 são carregados automaticamente ApplicationListener, são spring.factoriesdefinidos e SPIcarregados por extensão:

Os 10 listados aqui são spring-bootcarregados em , e o restante 1 é spring-boot-autoconfigurecarregado em . O mais importante deles é ConfigFileApplicationListenerque está relacionado ao carregamento de arquivos de configuração a serem mencionados posteriormente.
Execute o método run
Após a conclusão da instanciação SpringApplication, seu método será executado em seguida run.
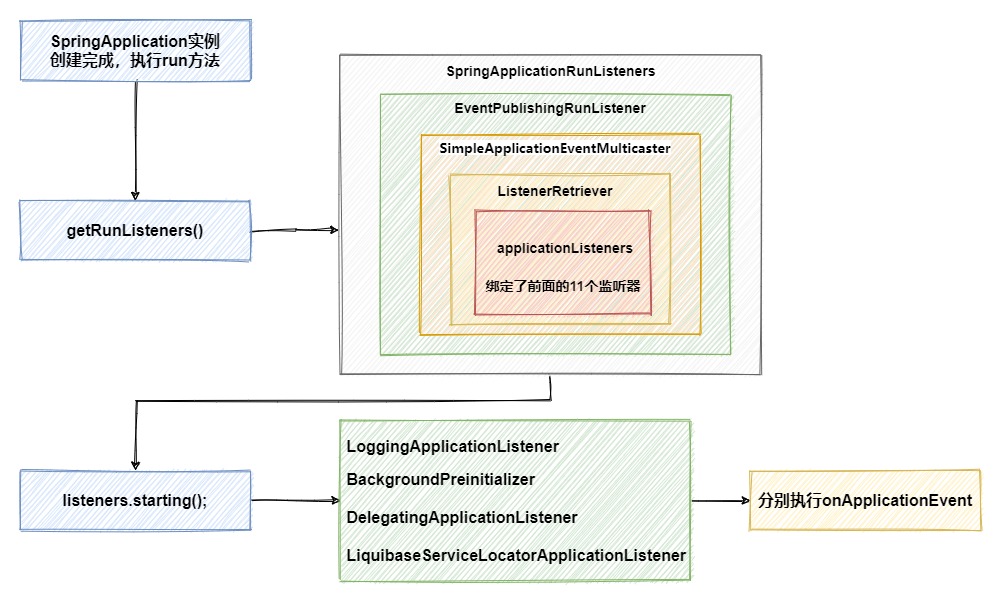
Como você pode ver, os 11 listeners que carregamos anteriormente estão vinculados ao obtido por meio getRunListenersdo método SpringApplicationRunListenershere . EventPublishingRunListenerMas startingquando o método é executado, ele é filtrado de acordo com o tipo. No final, apenas 4 métodos de escuta onApplicationEventsão realmente executados e não há nada que queremos ver ConfigFileApplicationListener. Vamos continuar a olhar para baixo.

Quando runo método for executado prepareEnvironment, um ApplicationEnvironmentPreparedEventtipo de evento será criado e transmitido. Neste momento, dentre todos os ouvintes, 7 irão escutar este evento, e então chamar seus onApplicationEventmétodos respectivamente. Dentre eles, temos o que estamos pensando . A seguir, vamos ver o que ele faz em ConfigFileApplicationListenerseu método.onApplicationEvent

No processo de chamada do método, ele carregará os 4 pós-processadores do próprio sistema e ConfigFileApplicationListenerele mesmo, totalizando 5 pós-processadores, e executará seus postProcessEnvironmentmétodos, os outros 4 não são importantes para nós e podem ser pulados, e por último o as etapas mais críticas são criar Loaderuma instância e chamar seus loadmétodos.
carregar arquivo de configuração
Aqui Loaderestá ConfigFileApplicationListeneruma classe interna, observe Loadero processo de instanciação do objeto:

No processo de instanciar Loadero objeto, dois carregadores de arquivos de propriedade são carregados novamente por meio da extensão SPI, um dos quais está YamlPropertySourceLoaderintimamente relacionado ao carregamento e análise do arquivo yml subsequente e o outro PropertiesPropertySourceLoaderé responsável pelo propertiescarregamento do arquivo. Depois que a instância é criada Loader, seus loadmétodos são chamados em seguida.
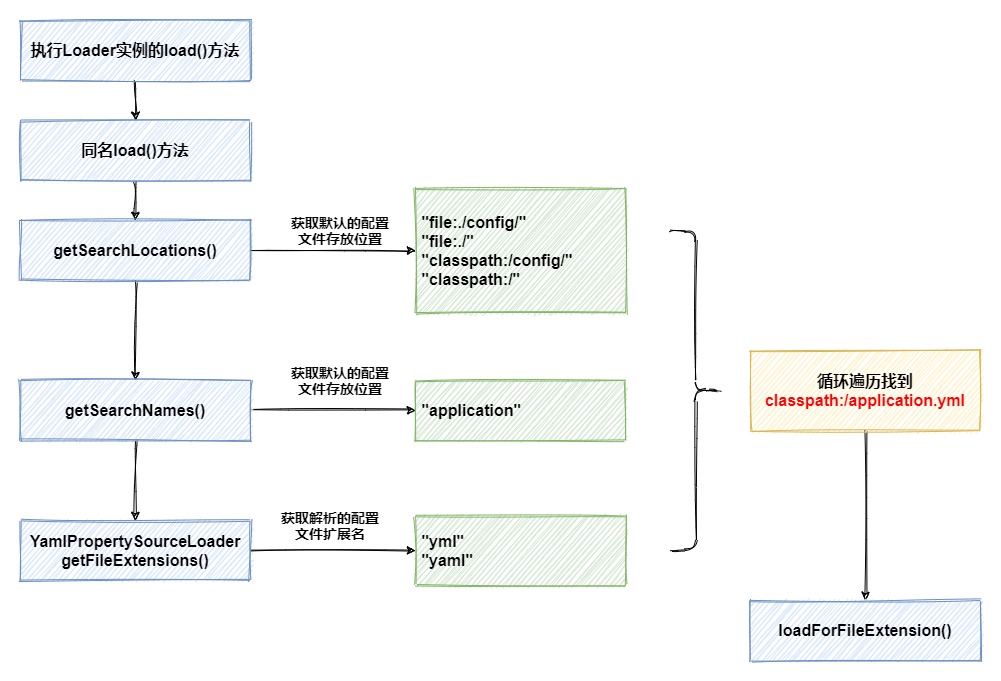
No loadmétodo, o caminho de armazenamento do arquivo de configuração padrão será percorrido por meio de loops aninhados, mais o nome do arquivo de configuração padrão e os sufixos correspondentes analisados por diferentes carregadores de arquivo de configuração e, finalmente, nosso arquivo de configuração yml será encontrado. Em seguida, comece a executar loadForFileExtensiono método.

No loadForFileExtensionmétodo, ele é classpath:/application.ymlcarregado primeiro como Resourceum arquivo e, em seguida, está pronto para iniciar oficialmente, e o método do YamlPropertySourceLoaderobjeto criado anteriormente é chamado load.
Nó do pacote
No loadmétodo, comece a preparar a análise do arquivo de configuração e o encapsulamento de dados:

loadOriginTrackedYmlLoaderO método do objeto é chamado no método load. Também podemos entendê-lo literalmente. Sua finalidade é o carregador do yml de rastreamento original. A série de chamadas de método no meio pode ser ignorada, e a última e mais importante etapa é chamar a interface OriginTrackingConstructordo objeto getDatapara analisar o yml e encapsulá-lo em um objeto.
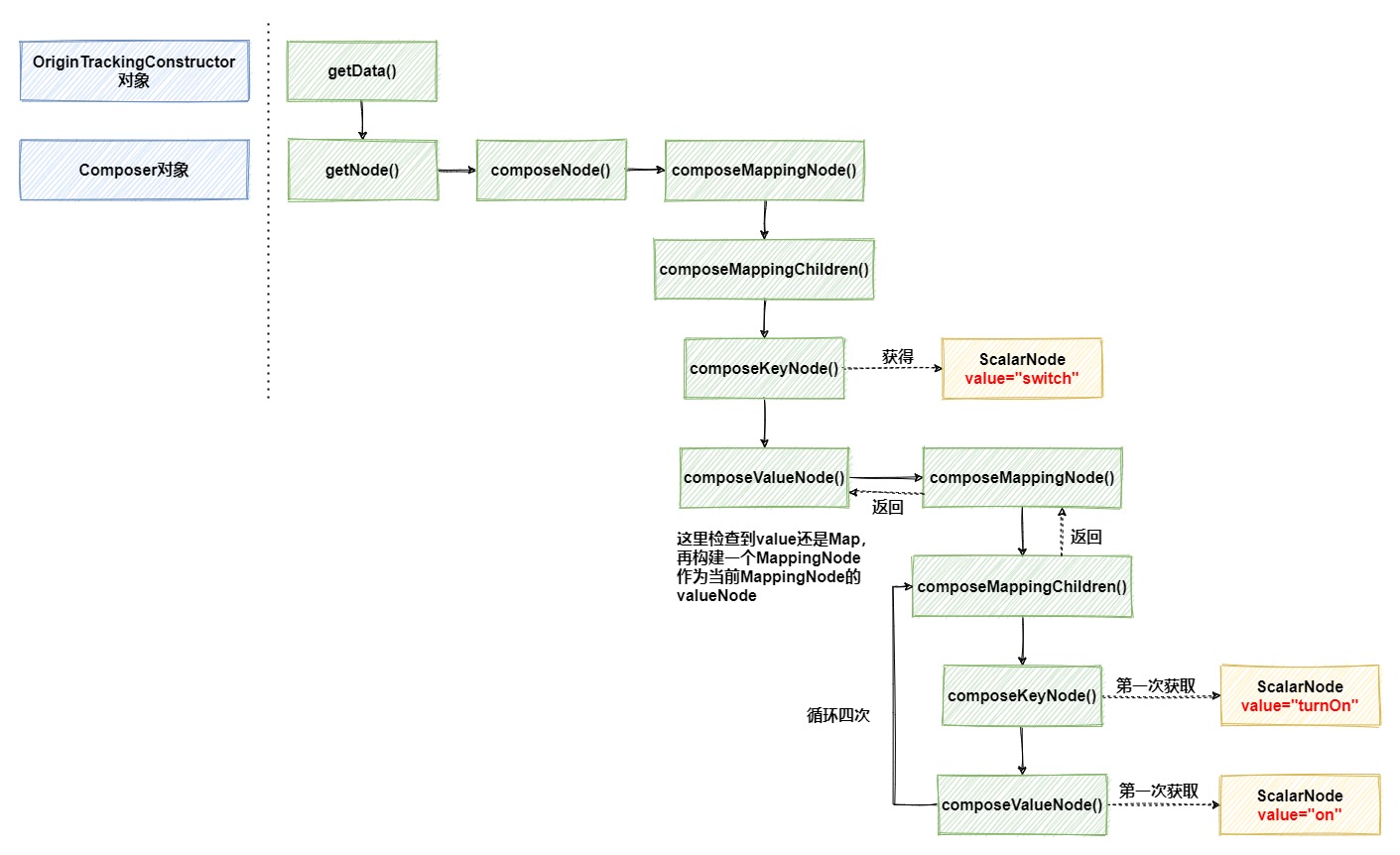
No processo de análise do yml, o construtor é realmente usado Composerpara gerar nós e, em seu getNodemétodo, os nós são criados por meio de eventos do analisador. De um modo geral, ele encapsula um conjunto de dados em yml em um MappingNodenó, e seu interior é na verdade NodeTuplecomposto por um List, NodeTuplee Mapa estrutura é semelhante, composta por um par de correspondentes keyNodee valueNode, a estrutura é a seguinte:
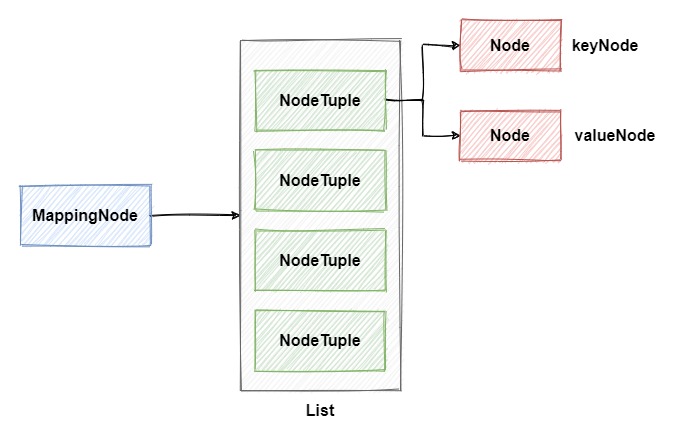
Bem, vamos voltar ao fluxograma de chamada de método acima. Ele é desenhado de acordo com o conteúdo real no arquivo yml no início do artigo. Se o conteúdo for diferente, o processo de chamada será alterado. Você só precisa entender isso princípio Vamos análise específica.
Primeiro, crie um MappingNodenó e o switchencapsule e, em seguida , keyNodecrie outro MappingNodecomo a camada externa e armazene os 4 conjuntos de atributos abaixo dele ao mesmo tempo, e é por isso que existem 4 loops acima. Não há problema em ficar um pouco confuso, basta olhar para a imagem abaixo para entender sua estrutura rapidamente.MappingNodevalueNode
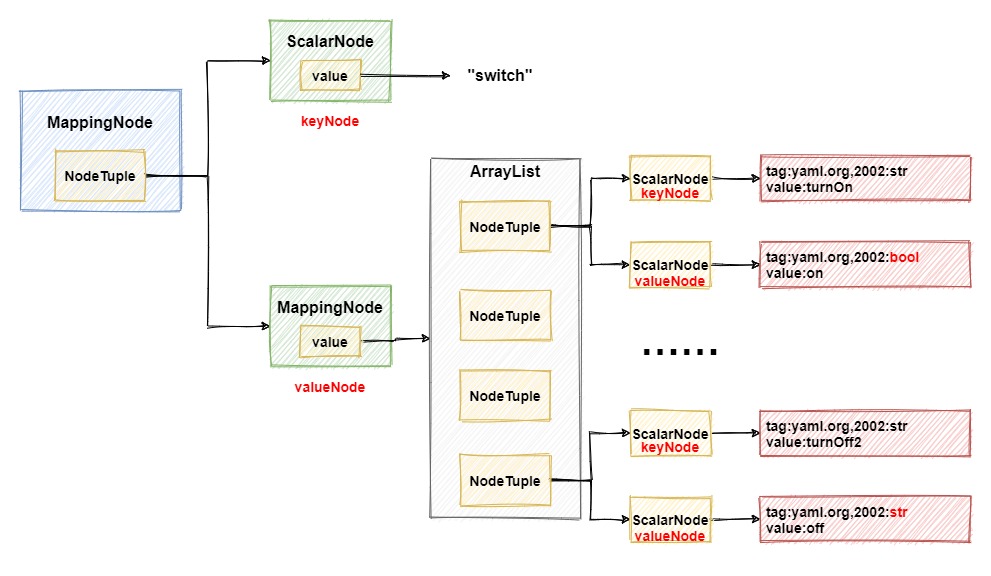
Na figura acima, um novo nó é introduzido ScalarNode, e seu uso é relativamente simples, uma string simples do tipo String pode ser encapsulada em um nó com ela. Neste ponto, os dados em yml foram analisados e encapsulados preliminarmente. Talvez os amigos mais atentos perguntem por que a imagem acima está no meio. Além de haver outro atributo, para que serve esse ScalarNodeatributo ?valuetag
Antes de apresentar sua função, vamos falar sobre como ela é determinada. A lógica desta parte é mais complicada. Você pode consultar o código-fonte do método ScannerImplde classe fetchMoreTokens. Este método decidirá como analisá-lo de acordo com cada um em yml keyouvalue com o que começa, incluindo símbolos especiais como {
, [, ', %, etc. ?Condição. Tomando como exemplo a análise de uma string sem nenhum caractere especial, o breve processo é o seguinte, omitindo algumas partes sem importância:
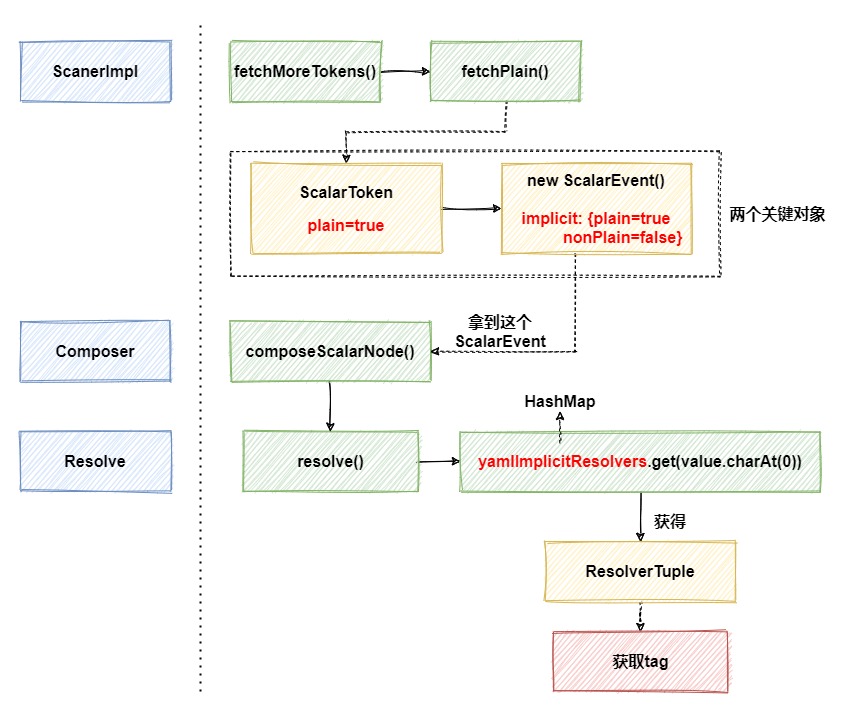
Na etapa intermediária desta imagem, dois objetos ScalarTokene objetos importantes são criados ScalarEvent, cada um com um atributo truede for plain, que pode ser entendido como se esse atributo precisa ser explicado , que é Resolverum dos principais atributos obtidos posteriormente.
A imagem acima yamlImplicitResolversé na verdade um HashMap que foi armazenado em cache com antecedência, e o relacionamento correspondente Charentre alguns tipos de caracteres foi armazenado com antecedência:ResolverTuple
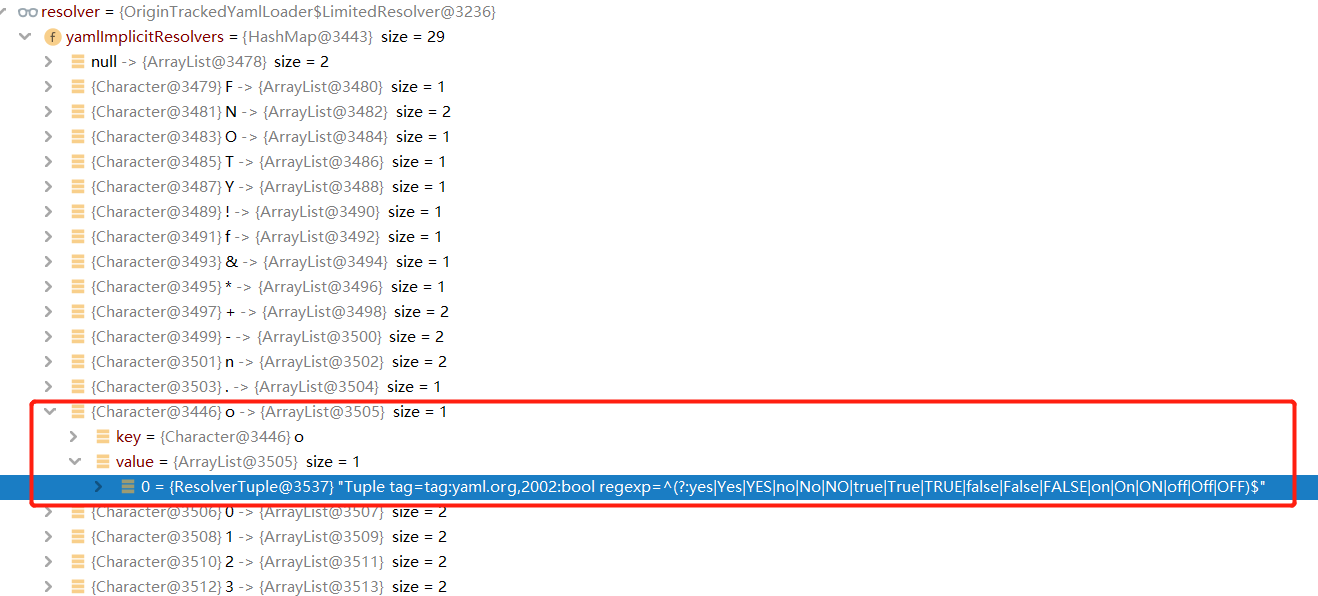
Quando o atributo for analisado on, retire a letra inicial ocorrespondente ResolverTuple, entre as quais tagestá tag:yaml.org.2002:bool. Claro que não é só tirar, depois será feito o match da expressão regular no atributo para ver se ele regexpbate com o valor do atributo, e este só será retornado quando a checagem estiver correta tag.
Neste ponto, explicamos claramente como o atributo ScalarNodedo meio tagé obtido e, em seguida, a chamada do método retorna camada por camada e retorna ao método da OriginTrackingConstructorclasse pai . Em seguida, continue executando o método para concluir a análise do documento yml.BaseConstructorgetDataconstructDocument
construtor de chamadas
Em constructDocument, existem duas etapas importantes. A primeira etapa é inferir qual tipo de construtor o nó atual deve usar. A segunda etapa é usar o construtor obtido para reatribuir valores no nó. O processo simples é o seguinte, eliminando a necessidade Nodedevalue
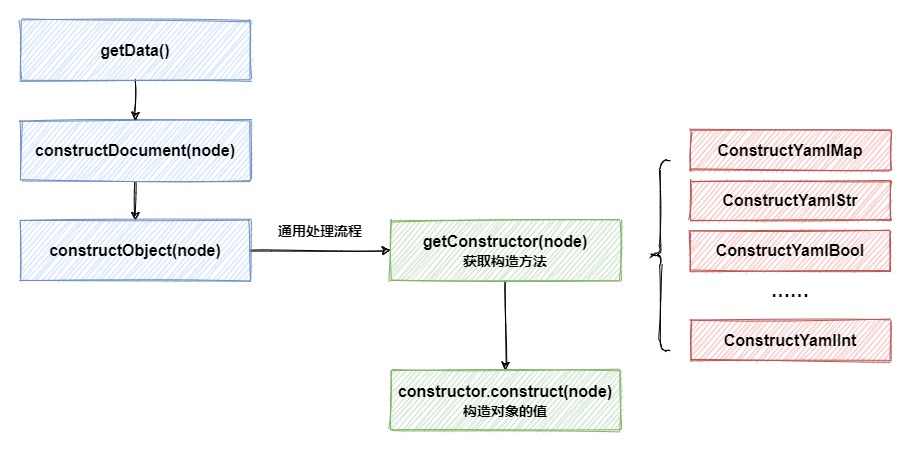
O processo de inferir o tipo de construtor também é muito simples.Na classe pai BaseConstructor, um HashMap é armazenado em cache, armazenando tago relacionamento de mapeamento entre o tipo de nó e o construtor correspondente. No getConstructormétodo, use tagos atributos armazenados no nó anterior para obter o construtor específico a ser usado:

Quando tagfor boolum tipo, ele encontrará SafeConstructa classe interna ConstructYamlBoolcomo construtor e chamará seu constructmétodo para instanciar um objeto como o valor ScalarNodedo nó value:

No constructmétodo, o val obtido é o anterior on. Quanto ao seguinte BOOL_VALUES, também é um HashMap inicializado com antecedência, que armazena alguns relacionamentos de mapeamento correspondentes com antecedência. A chave são as palavras-chave listadas abaixo e o valor é o Booleantipo trueou false:

Neste ponto, o processo de análise de atributos em yml está basicamente concluído e também entendemos porque os atributos em yml onserão convertidos para trueo princípio. Quanto ao último, Booleano tipo trueoufalse como ele é convertido em uma string é @Valuerealizado por anotações.
pensar
Então, vem a próxima pergunta, já que esse processamento especial será feito na análise do arquivo yml, propertiese se ele for substituído por um arquivo de configuração?
sw.turnOn=on
sw.turnOff=off
Execute o programa e veja o resultado:

Pode-se ver que propertiesos resultados podem ser lidos normalmente usando o arquivo de configuração. Parece que não há nenhum processamento especial no processo de análise. Quanto ao processo de análise, amigos interessados podem ler o código-fonte por conta própria.
Depois de ler o artigo e olhar para o meu cabelo ralo por ter escrito este artigo, não pude deixar de chorar. Talvez apenas me dando curtidas possa acalmar meu humor.
Peles bonitas são iguais, almas interessantes são uma em um milhão, vamos nos aquecer nesta cidade fria, eu sou Ah Q, até a próxima edição!