1. Entenda os microsserviços
1.1. Evolução da Arquitetura de Serviço
1.1.1. Arquitetura Monolítica
Arquitetura Monolítica : Todas as funções do negócio são desenvolvidas em um projeto e empacotadas em um único pacote para implantação.

As vantagens e desvantagens da arquitetura monolítica são as seguintes:
vantagem:
- estrutura simples
- Baixo custo de implantação
deficiência:
- Alto grau de acoplamento (difícil de manter e atualizar)
1.1.2, arquitetura distribuída
Arquitetura distribuída : O sistema é dividido de acordo com as funções de negócios, e cada módulo de função de negócios é desenvolvido como um projeto independente, chamado de serviço.
Vantagens e desvantagens da arquitetura distribuída:
vantagem:
- Reduza o acoplamento de serviço
- Propicia a atualização e expansão do serviço
deficiência:
- O relacionamento da chamada de serviço é intrincado
Embora a arquitetura distribuída reduza o acoplamento de serviços, ainda há muitos problemas a serem considerados ao dividir os serviços:
- Como definir a granularidade da divisão do serviço?
- Como manter o endereço do cluster de serviço?
- Como implementar chamadas remotas entre serviços?
- Como perceber o estado de saúde do serviço?
As pessoas precisam desenvolver um conjunto de padrões eficazes para restringir a arquitetura distribuída.
1.1.3. Microsserviços
Características arquiteturais dos microsserviços:
- Responsabilidade Única: A granularidade da divisão de microsserviços é menor, e cada serviço corresponde a uma capacidade de negócio única, de forma a atingir uma responsabilidade única
- Autonomia: equipe independente, tecnologia independente, dados independentes, implantação e entrega independentes
- Orientado a serviços: os serviços fornecem uma interface padrão unificada, independente de linguagem e tecnologia
- Forte isolamento: as chamadas de serviço são isoladas, tolerantes a falhas e degradadas para evitar problemas em cascata
As características acima dos microsserviços estão, na verdade, estabelecendo um padrão para arquitetura distribuída, reduzindo ainda mais o acoplamento entre serviços e fornecendo independência e flexibilidade de serviços. Obtenha alta coesão e baixo acoplamento.
Portanto, os microsserviços podem ser considerados como uma solução de arquitetura distribuída com arquitetura bem projetada .
Mas como o plano deve ser implementado? Qual pilha de tecnologia escolher? Empresas de Internet em todo o mundo estão tentando ativamente suas próprias soluções de implementação de microsserviços.
Dentre elas, a que mais chama a atenção na área de Java é a solução oferecida por Spring Cloud.
1.1.4. Resumo
Características da arquitetura monolítica?
- Simples e conveniente, altamente acoplado, baixa escalabilidade, adequado para pequenos projetos. Exemplo: Sistema de Gestão Estudantil
Características da arquitetura distribuída?
- Acoplamento frouxo e boa escalabilidade, mas a estrutura é complexa e difícil. Adequado para projetos de Internet de grande escala, como JD.com e Taobao
Microsserviços: uma boa solução de arquitetura distribuída
- Vantagens: menor granularidade dividida, serviços mais independentes e menor acoplamento
- Desvantagens: a estrutura é muito complexa, e a dificuldade de operação e manutenção, monitoramento e implantação é aumentada
- SpringCloud é uma solução completa para arquitetura de microsserviços, integrando vários excelentes componentes funcionais de microsserviços
1.2. Comparação de tecnologias de microsserviço
1.2.1. Estrutura de microsserviço
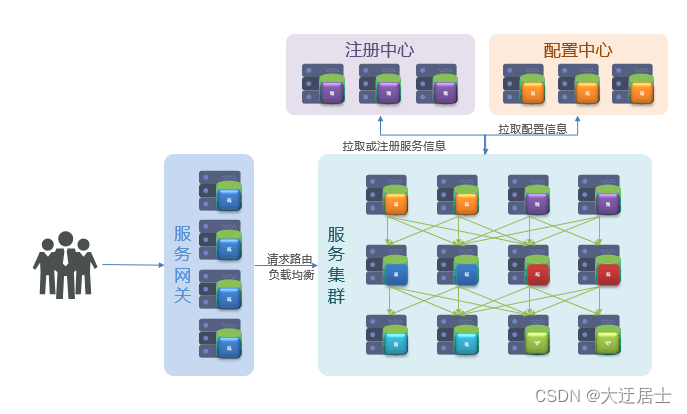
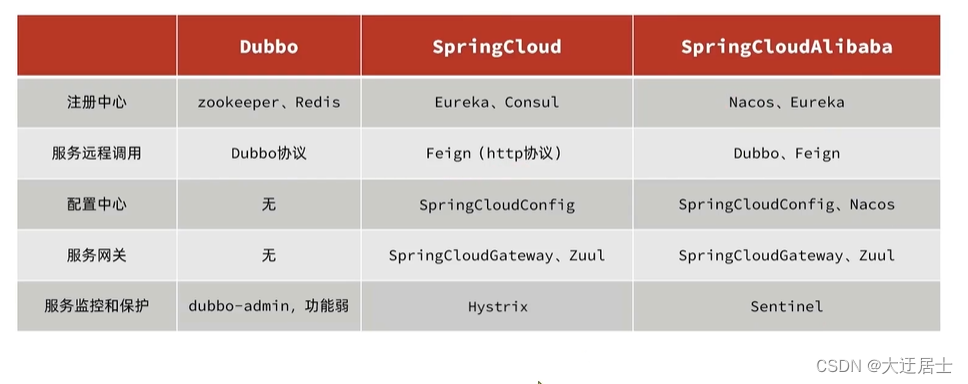
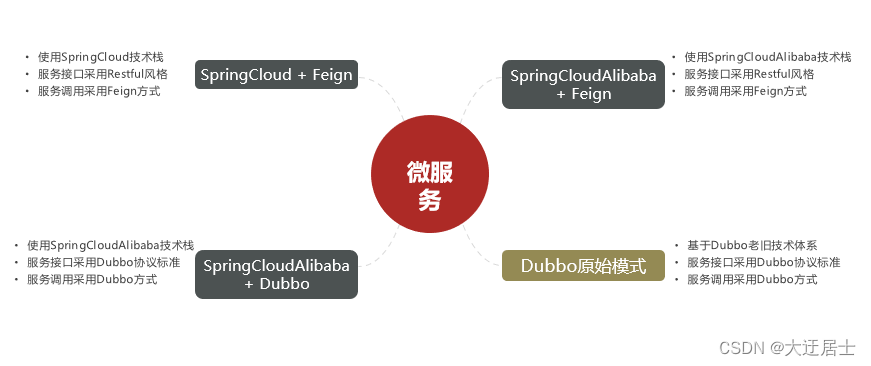
A solução de microsserviço requer uma estrutura técnica para implementá-la. Empresas de Internet em todo o mundo estão tentando ativamente sua própria tecnologia de implementação de microsserviço. Os mais conhecidos na China são SpringCloud e Dubbo do Alibaba.
1.2.2. Comparação de microsserviços
1.3、SpringCloud
O SpringCloud é atualmente a estrutura de microsserviço mais usada na China. Endereço do site oficial: https://spring.io/projects/spring-cloud.
O SpringCloud integra vários componentes funcionais de microsserviços e realiza a montagem automática desses componentes com base no SpringBoot, proporcionando assim uma boa experiência pronta para uso:
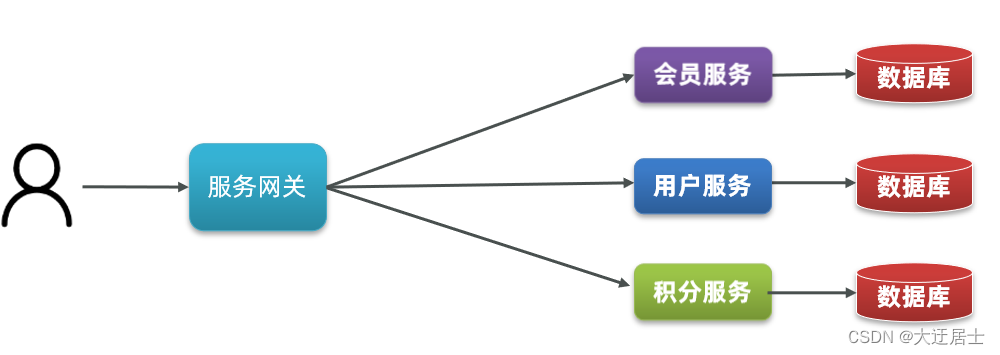
2. Divisão de microsserviços e chamadas remotas
2.1. Princípios de divisão de serviço
- Diferentes microsserviços, não desenvolvem o mesmo negócio repetidamente
- Os dados do microsserviço são independentes, não acesse o banco de dados de outros microsserviços
- Os microsserviços podem expor seus negócios como interfaces para outros microsserviços chamarem
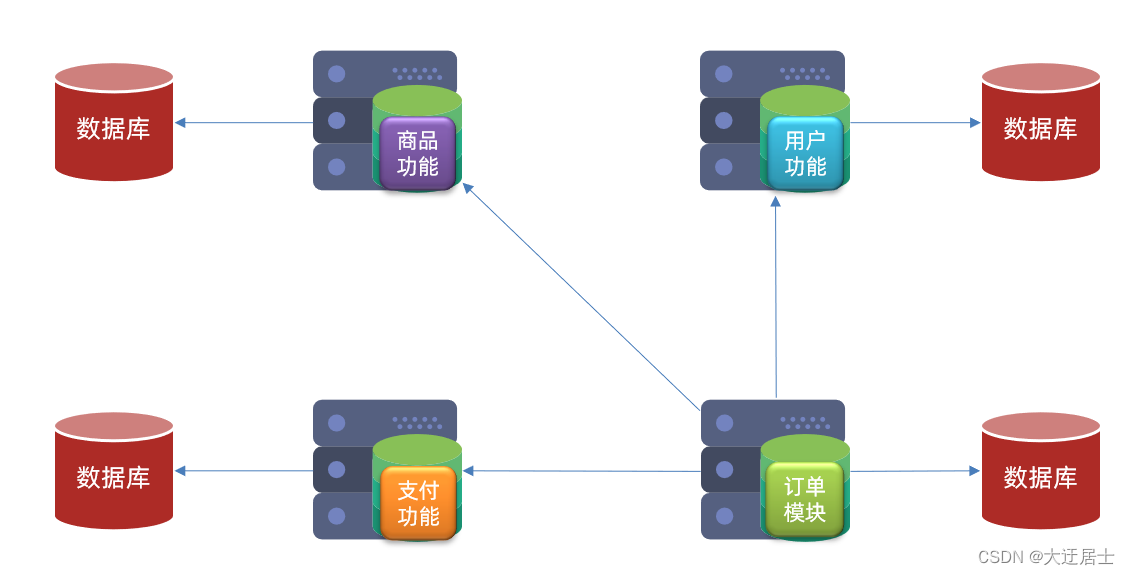
2.2. Exemplo de divisão de serviço
cloud-demo: projeto pai, gerenciar dependências
- order-service: microsserviço de pedidos, responsável por negócios relacionados a pedidos
- user-service: microsserviço do usuário, responsável pelos negócios relacionados ao usuário
Exigir:
- Tanto o microsserviço de pedido quanto o microsserviço de usuário devem ter seus próprios bancos de dados, independentes um do outro
- Tanto o serviço de pedido quanto o serviço de usuário expõem as interfaces Restful para o mundo externo
- Se o serviço de pedidos precisar consultar informações do usuário, ele poderá chamar apenas a interface Restful do serviço do usuário e não poderá consultar o banco de dados do usuário
2.2.1. Instrução SQL de importação
2.2.2. Importar projeto de demonstração
3. Centro de Registro Eureka
3.1, princípio Eureka
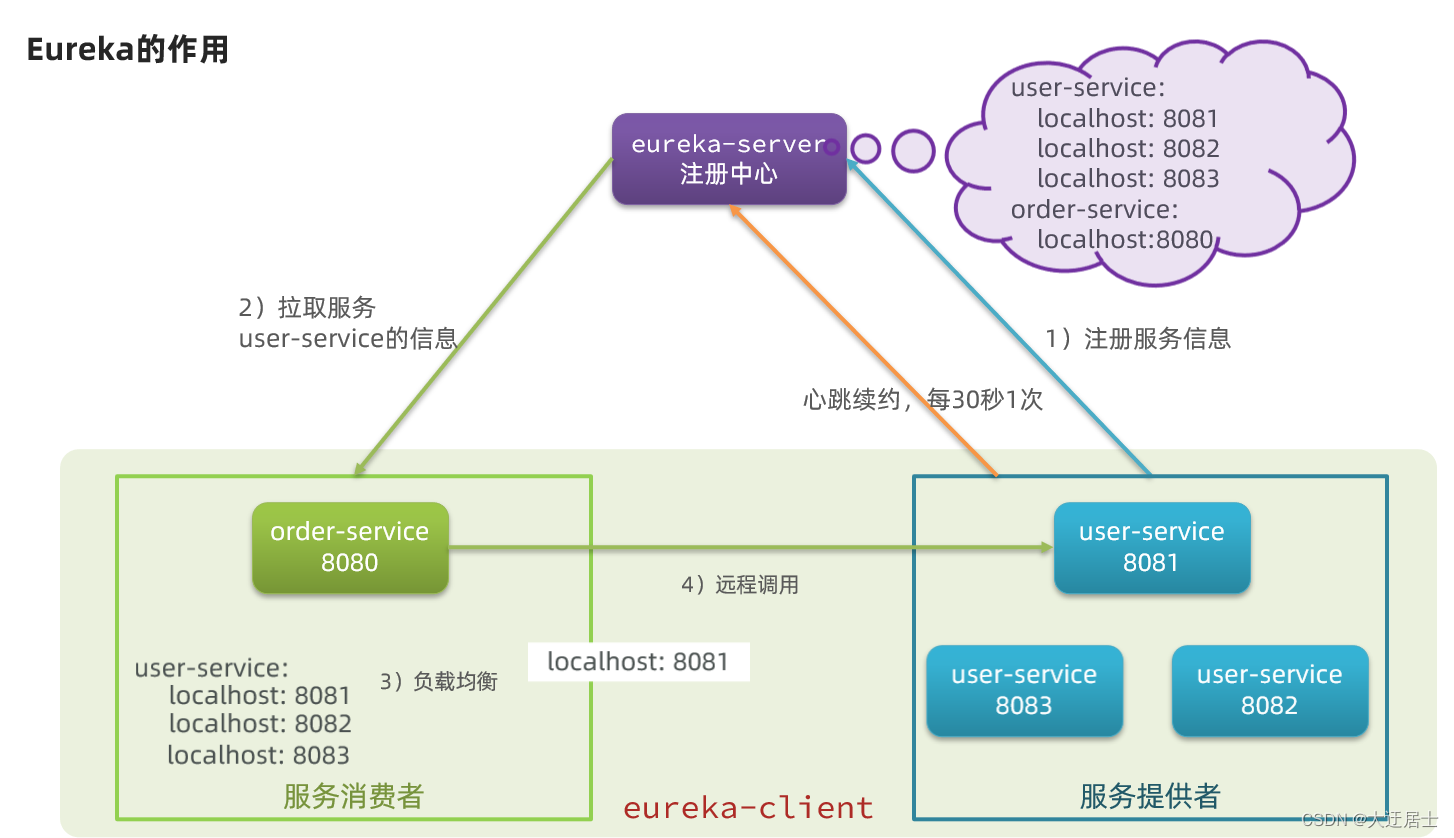
Como os consumidores devem obter informações específicas sobre os prestadores de serviços?
- O provedor de serviços registra suas próprias informações no eureka quando inicia
- eureka salva esta informação
- Os consumidores extraem informações do provedor do eureka de acordo com o nome do serviço
Se houver vários provedores de serviços, como os consumidores devem escolher?
- O consumidor do serviço usa o algoritmo de balanceamento de carga para selecionar um serviço da lista de serviços
Como os consumidores percebem o estado de saúde dos prestadores de serviços?
- O provedor de serviços enviará uma solicitação de pulsação ao EurekaServer a cada 30 segundos para relatar o status de integridade
- eureka atualizará as informações da lista de serviço de registro e a pulsação anormal será removida
- Os consumidores podem obter as informações mais recentes
Na arquitetura Eureka, existem dois tipos de funções de microsserviço:
-
EurekaServer: servidor, centro de registro
- Registrar informações de serviço
- Monitoramento de batimentos cardíacos
-
EurekaClient: cliente
-
Provedor: provedor de serviço, como usuário-atendimento no caso
- Registre suas próprias informações no EurekaServer
- Envie uma pulsação para o EurekaServer a cada 30 segundos
-
consumidor: consumidor de serviço, como pedido-serviço no caso
-
Puxe a lista de serviços do EurekaServer de acordo com o nome do serviço
-
Faça o balanceamento de carga com base na lista de serviços e inicie uma chamada remota após selecionar um microsserviço
-
-
3.2. Construir EurekaServer
3.2.1. Criar serviço eureka-server
3.2.2. Introduzir dependência eureka
Apresente a dependência inicial fornecida pelo SpringCloud para eureka:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
3.2.3, escreva a classe de inicialização
Para escrever uma classe de inicialização para o serviço eureka-server, certifique-se de adicionar uma anotação @EnableEurekaServer para ativar a função de centro de registro do eureka:
package cn.test.eureka;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.eureka.server.EnableEurekaServer;
@SpringBootApplication
@EnableEurekaServer
public class EurekaApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaApplication.class, args);
}
}
3.2.4. Gravando arquivos de configuração
Escreva um arquivo application.yml com o seguinte conteúdo:
server:
port: 10086
spring:
application:
name: eureka-server
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:10086/eureka
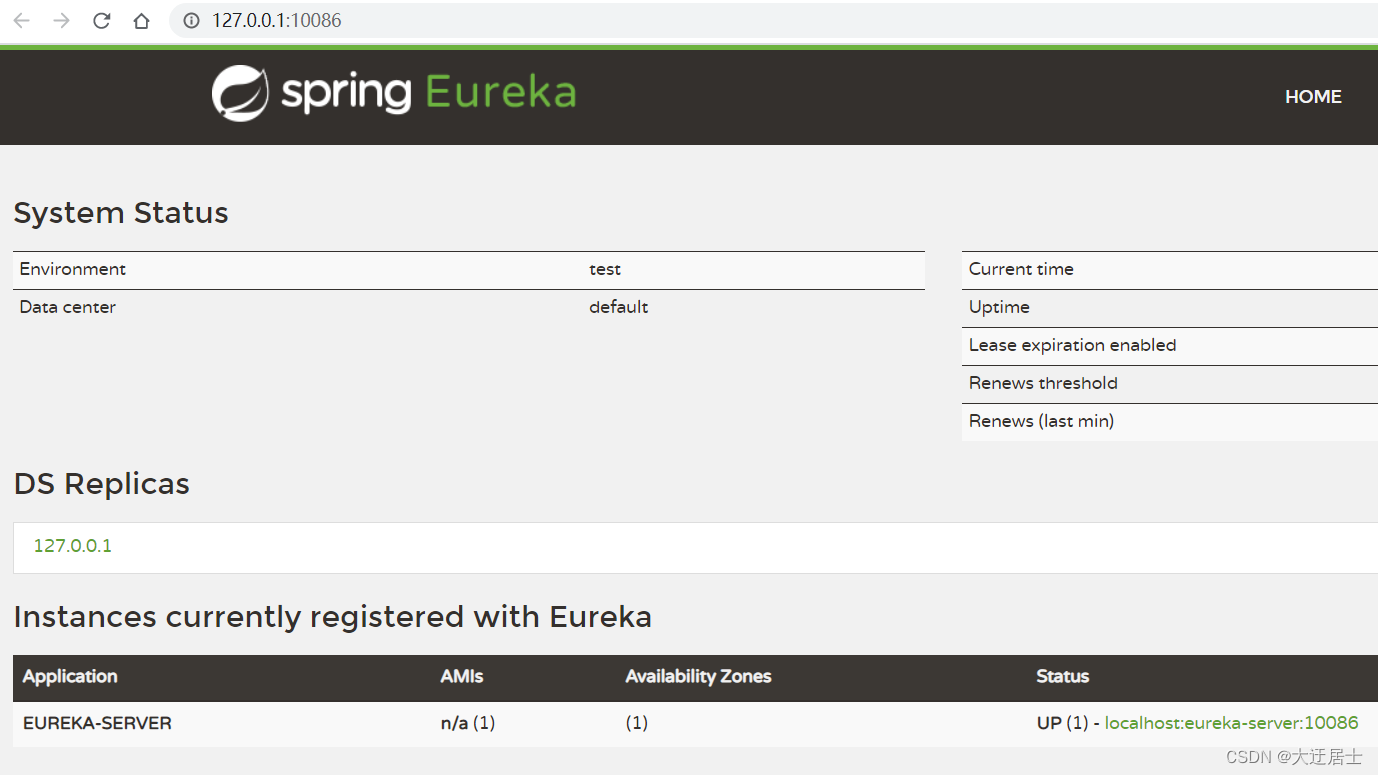
3.2.5. Iniciar serviço
Inicie o microsserviço e, em seguida, visite-o no navegador: http://127.0.0.1:10086
Veja o seguinte resultado deve ser bem sucedido:
3.3. Registro de serviço
3.3.1. Apresentando dependências
No arquivo pom do user-service, introduza as seguintes dependências do eureka-client:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
3.3.2. Arquivo de configuração
Em user-service, modifique o arquivo application.yml e adicione o nome do serviço e o endereço eureka:
spring:
application:
name: userservice
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:10086/eureka
3.3.3. Iniciar várias instâncias de serviço do usuário
Para demonstrar um cenário em que um serviço possui várias instâncias, adicionamos uma configuração de inicialização SpringBoot e iniciamos um serviço de usuário.
3.4. Descoberta de serviço
3.4.1. Apresentando dependências
Conforme mencionado anteriormente, a descoberta de serviço e o registro de serviço são todos encapsulados nas dependências do eureka-client, portanto, esta etapa é consistente com o registro de serviço.
No arquivo pom do order-service, introduza as seguintes dependências do eureka-client:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
3.4.2. Arquivo de configuração
A descoberta de serviço também precisa saber o endereço eureka, portanto, a segunda etapa é consistente com o registro do serviço, que é configurar as informações eureka:
Em order-service, modifique o arquivo application.yml e adicione o nome do serviço e o endereço eureka:
spring:
application:
name: orderservice
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:10086/eureka
3.4.3. Serviço pull e balanceamento de carga
Por fim, vamos extrair a lista de instâncias do serviço de atendimento ao usuário do eureka-server e implementar o balanceamento de carga.
Mas não precisamos fazer essas ações, só precisamos adicionar algumas anotações.
No OrderApplication do order-service, adicione uma anotação @LoadBalanced ao RestTemplate Bean:
O Spring nos ajudará automaticamente a obter a lista de instâncias do lado do servidor eureka de acordo com o nome do serviço userservice e, em seguida, concluir o balanceamento de carga.
3.5. Resumo
Construir Servidor Eureka
-
Introduzir dependência eureka-server
-
Adicionar anotação @EnableEurekaServer
-
Configure o endereço eureka em application.yml
registro de serviço
-
Introduzir dependência eureka-client
-
Configure o endereço eureka em application.yml
descoberta de serviço
- Introduzir dependência eureka-client
- Configure o endereço eureka em application.yml
- Adicione a anotação @LoadBalanced ao RestTemplate
- Chamada remota com o nome do serviço do provedor de serviços
4. O princípio do balanceamento de carga da fita
4.1. Princípio do balanceamento de carga
A camada inferior do Spring Cloud na verdade usa um componente chamado Ribbon para implementar o balanceamento de carga.
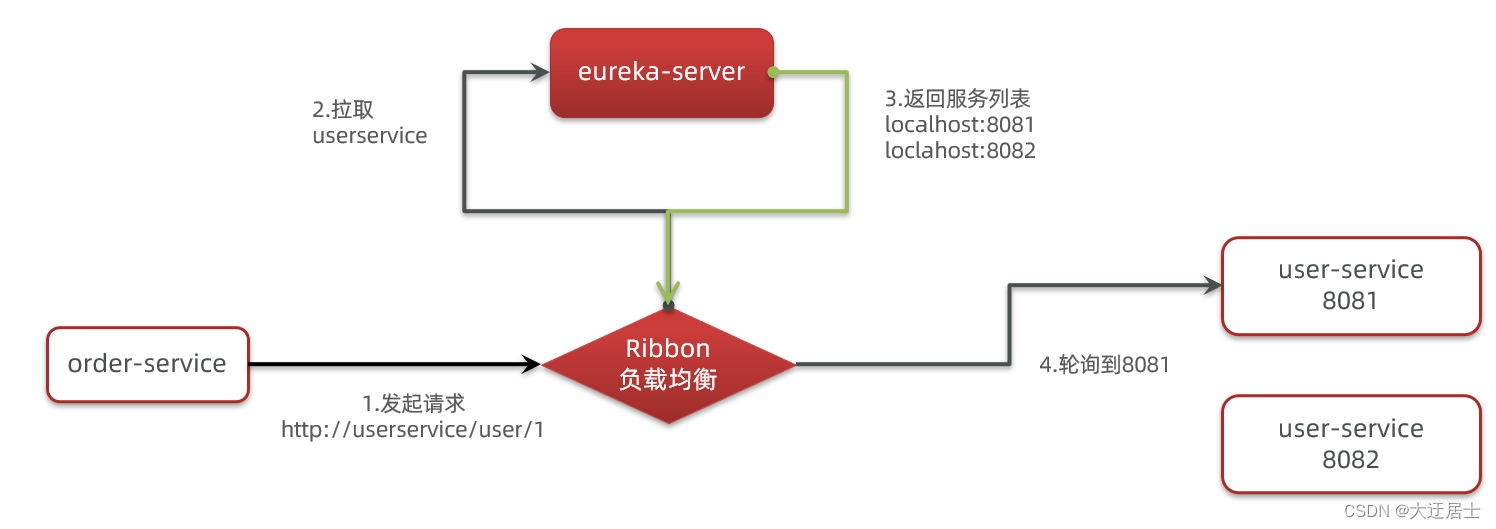
4.2. Rastreamento do código-fonte
Por que podemos acessá-lo apenas digitando o nome do serviço? Você também precisa obter o ip e a porta antes.
Obviamente, alguém nos ajudou a obter o ip e a porta da instância do serviço com base no nome do serviço. Ou seja LoadBalancerInterceptor, essa classe interceptará a solicitação RestTemplate, obterá a lista de serviços do Eureka de acordo com o ID do serviço e usará o algoritmo de balanceamento de carga para obter as informações reais do endereço do serviço e substituir o ID do serviço.
Fazemos rastreamento de código-fonte:
4.2.1、LoadBalancerInterceptor
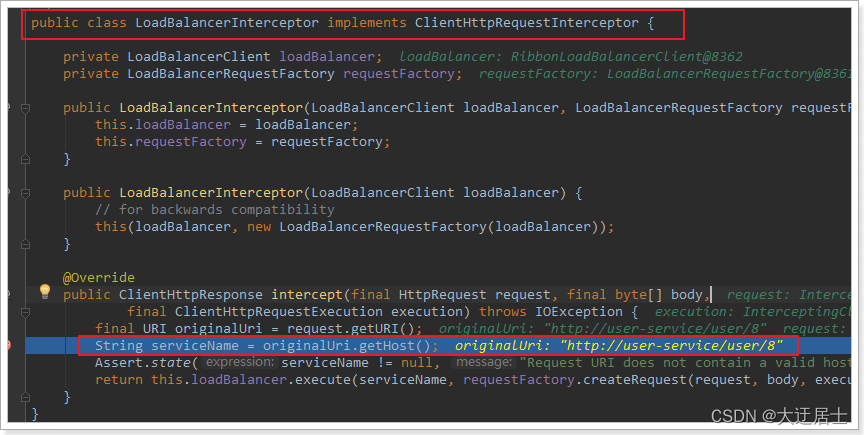
Você pode ver que o método intercept aqui intercepta a solicitação HttpRequest do usuário e faz várias coisas:
request.getURI(): Obtenha o uri de solicitação, neste caso é http://user-service/user/8originalUri.getHost(): obtenha o nome do host do caminho uri, que na verdade é o ID do serviço.user-servicethis.loadBalancer.execute(): ID do serviço de processo e solicitações do usuário.
Aqui this.loadBalancerestá LoadBalancerCliento tipo, continuamos a seguir.
4.2.2、LoadBalancerClient
Continue a seguir o método de execução:
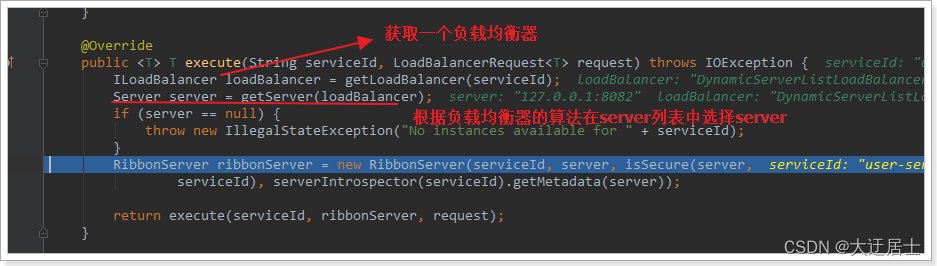
O código é assim:
- getLoadBalancer(serviceId): obtenha o ILoadBalancer de acordo com o id do serviço e o ILoadBalancer levará o id do serviço para eureka para obter a lista de serviços e salvá-la.
- getServer(loadBalancer): Use o algoritmo de balanceamento de carga integrado para selecionar um na lista de serviços. Neste exemplo, você pode ver que o serviço na porta 8082 foi obtido
Após a liberação, acesse e trace novamente, e constatei que o obtido é 8081:
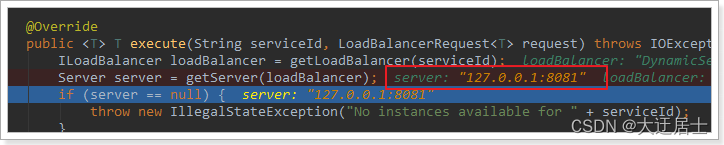
Com certeza, o balanceamento de carga é alcançado.
4.2.3, estratégia de balanceamento de carga IRule
No código agora, você pode ver que o serviço de acesso usa um getServermétodo para fazer balanceamento de carga:
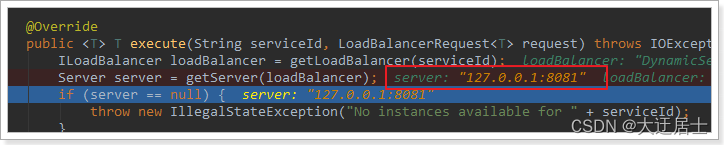
Continuamos a acompanhar:
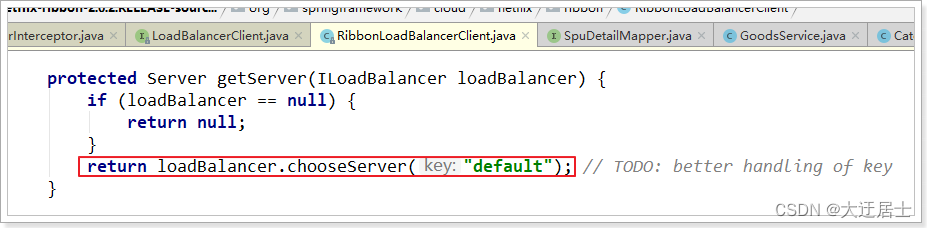
Continue a rastrear o código-fonte do método chooseServer e encontre esse trecho de código:
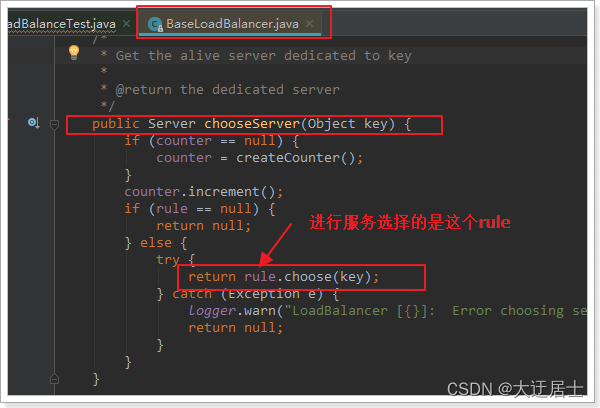
Vamos ver quem é essa regra:
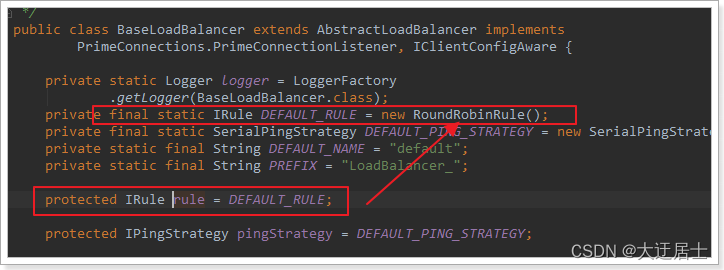
O valor padrão da regra aqui é um RoundRobinRule, veja a introdução da classe:
Não é isso que significa votação?
Neste ponto, todo o processo de balanceamento de carga está claro para nós.
4.2.4. Resumo
A camada inferior do SpringCloudRibbon usa um interceptador para interceptar a solicitação enviada pelo RestTemplate e modificar o endereço. Resumindo com uma foto:
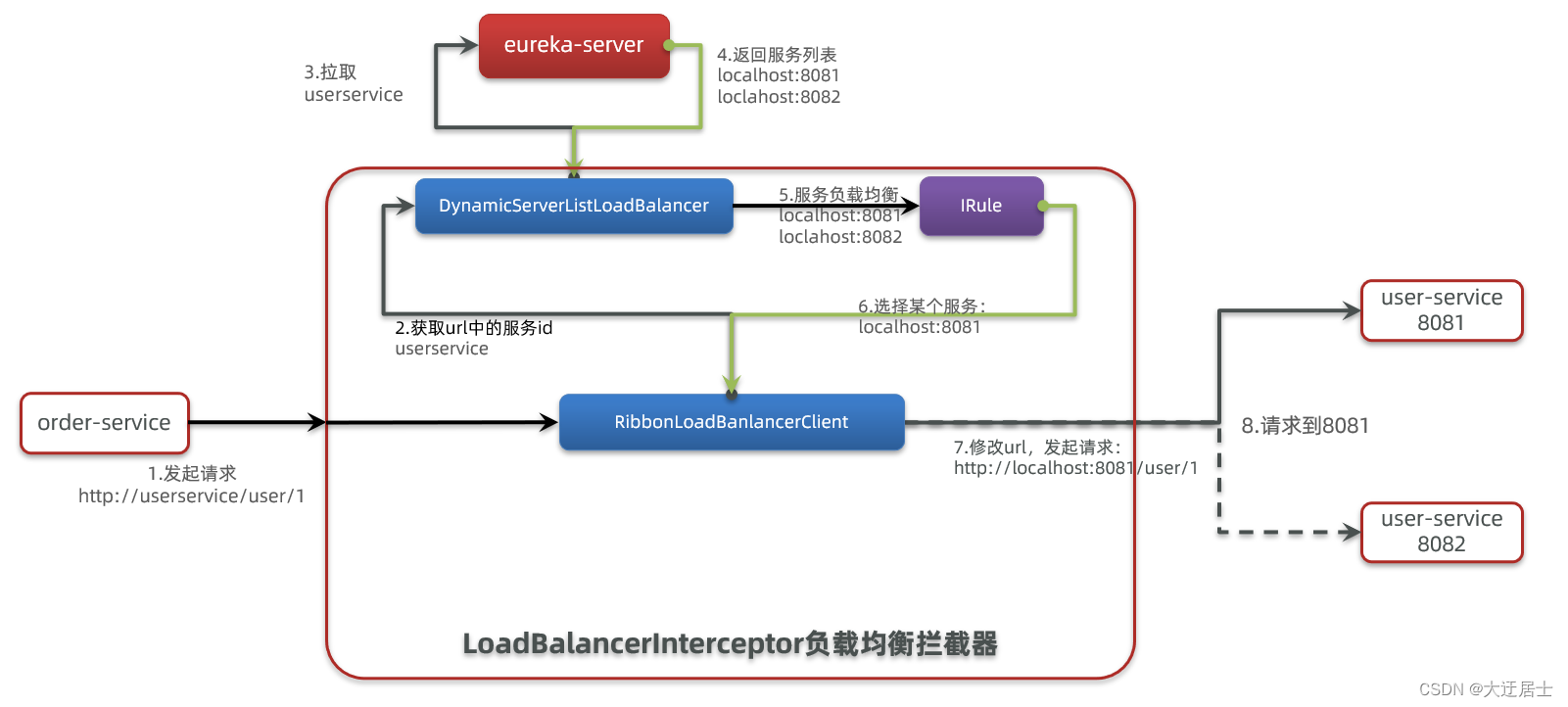
O processo básico é o seguinte:
- Intercepte nossa solicitação RestTemplate http://userservice/user/1
- RibbonLoadBalancerClient obterá o nome do serviço do URL da solicitação, que é user-service
- DynamicServerListLoadBalancer extrai a lista de serviços de eureka de acordo com o serviço do usuário
- eureka retorna a lista, localhost:8081, localhost:8082
- IRule usa regras de balanceamento de carga integradas, selecione uma na lista, como localhost:8081
- RibbonLoadBalancerClient modifica o endereço da solicitação, substitui userservice por localhost:8081, obtém http://localhost:8081/user/1 e inicia uma solicitação real
4.3. Estratégia de balanceamento de carga
4.3.1, estratégia de balanceamento de carga
As regras de balanceamento de carga são definidas na interface IRule, e IRule tem muitas classes de implementação diferentes:
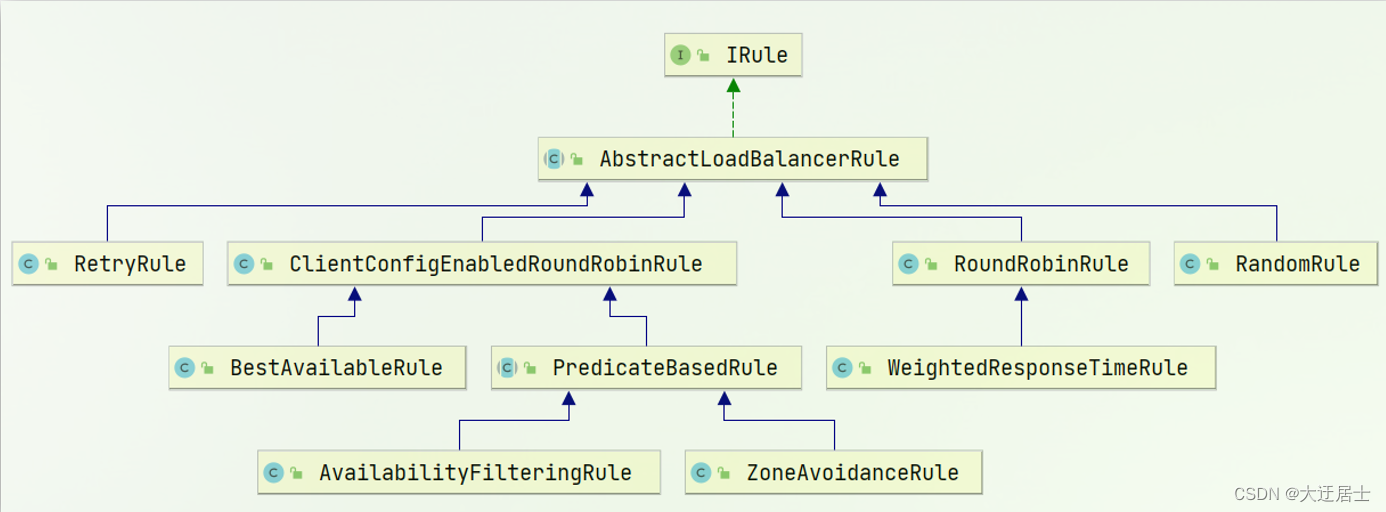
Os significados das diferentes regras são os seguintes:
| Classe de regra de balanceamento de carga integrada | Descrição da regra |
|---|---|
| Regra RoundRobin | Basta consultar a lista de serviços para selecionar um servidor. É a regra de balanceamento de carga padrão da Faixa de Opções. |
| Regra de filtragem de disponibilidade | Ignore os dois servidores a seguir: (1) Por padrão, se este servidor falhar ao conectar 3 vezes, este servidor será definido para o estado "curto-circuito". O estado de curto-circuito durará 30 segundos e, se a conexão falhar novamente, a duração do curto-circuito aumentará geometricamente. (2) Servidores com simultaneidade muito alta. Se o número de conexões simultâneas de um servidor for muito alto, o cliente configurado com a regra AvailabilityFilteringRule também irá ignorá-lo. O limite superior do número de conexões simultâneas pode ser configurado pela propriedade ..ActiveConnectionsLimit do cliente. |
| WeightedResponseTimeRule | Atribua um valor de peso a cada servidor. Quanto maior o tempo de resposta do servidor, menor o peso desse servidor. Essa regra selecionará aleatoriamente um servidor e esse valor de peso afetará a seleção do servidor. |
| ZoneAvoidanceRule | A seleção do servidor é baseada nos servidores disponíveis na região. Use Zona para classificar servidores. Esta Zona pode ser entendida como uma sala de informática, um rack, etc. Em seguida, pesquise vários serviços na zona. |
| MelhorRegraDisponível | Ignore os servidores que estão em curto-circuito e escolha servidores com menor simultaneidade. |
| RandomRule | Selecione aleatoriamente um servidor disponível. |
| RetryRule | Lógica de seleção para o mecanismo de repetição |
A implementação padrão é ZoneAvoidanceRule, que é um esquema de pesquisa
4.3.2, estratégia de balanceamento de carga personalizada
As regras de balanceamento de carga podem ser modificadas definindo a implementação IRule. Existem duas maneiras:
- Método de código: na classe OrderApplication em order-service, defina uma nova IRule:
@Bean
public IRule randomRule(){
return new RandomRule();
}
- Método do arquivo de configuração: No arquivo application.yml do order-service, adicionar novas configurações também pode modificar as regras:
userservice: # 给某个微服务配置负载均衡规则,这里是userservice服务
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule # 负载均衡规则
Observe que as regras de balanceamento de carga padrão geralmente são usadas sem modificações.
4.4. Carregamento lento
A Ribbon utiliza o lazy loading por padrão, ou seja, o LoadBalanceClient é criado somente quando for acessado pela primeira vez, e o tempo de requisição será muito longo.
O carregamento de fome será criado quando o projeto começar a reduzir o tempo gasto para a primeira visita. Habilite o carregamento de fome através da seguinte configuração:
ribbon:
eager-load:
enabled: true
clients: userservice
4.5. Resumo
Regras de balanceamento de carga da fita
-
A interface da regra é IRule
-
A implementação padrão é ZoneAvoidanceRule, selecione a lista de serviços de acordo com a zona e, em seguida, pesquise
Método de balanceamento de carga personalizado
-
Método de código: configuração flexível, mas precisa ser reempacotado e liberado quando modificado
-
Método de configuração: intuitivo, conveniente, sem necessidade de reempacotar e publicar, mas a configuração global não é possível
carregamento de fome
-
Ativar carregamento de fome
-
Especifique o nome do microsserviço para carregamento de fome
5. Centro de Registro de Naco
5.1. Entendendo e instalando o Nacos
5.1.1, instalação do Windows
5.1.1.1. Baixe o pacote de instalação
Na página do GitHub do Nacos, há um link de download para baixar o servidor Nacos compilado ou o código-fonte:
Página inicial do GitHub: https://github.com/alibaba/nacos
Página de download da versão do GitHub: https://github.com/alibaba/nacos/releases
Como mostrado na imagem:
5.1.1.2, Descompressão
Descompacte este pacote em qualquer diretório não chinês, conforme mostrado na figura:
Descrição do diretório:
- bin: script de inicialização
- conf: arquivo de configuração
5.1.1.3, configuração de porta
A porta padrão do Nacos é 8848. Se outros processos em seu computador ocuparem a porta 8848, tente fechar o processo primeiro.
Caso não consiga fechar o processo que ocupa a porta 8848 , você também pode entrar no diretório conf do nacos e modificar a porta no arquivo de configuração:
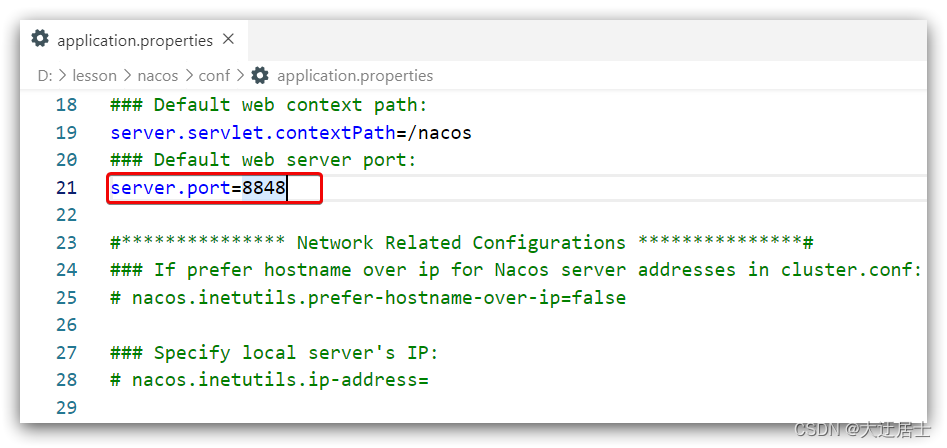
5.1.1.4, iniciar
A inicialização é muito simples, entre no diretório bin, a estrutura é a seguinte:
Em seguida, execute o comando:
-
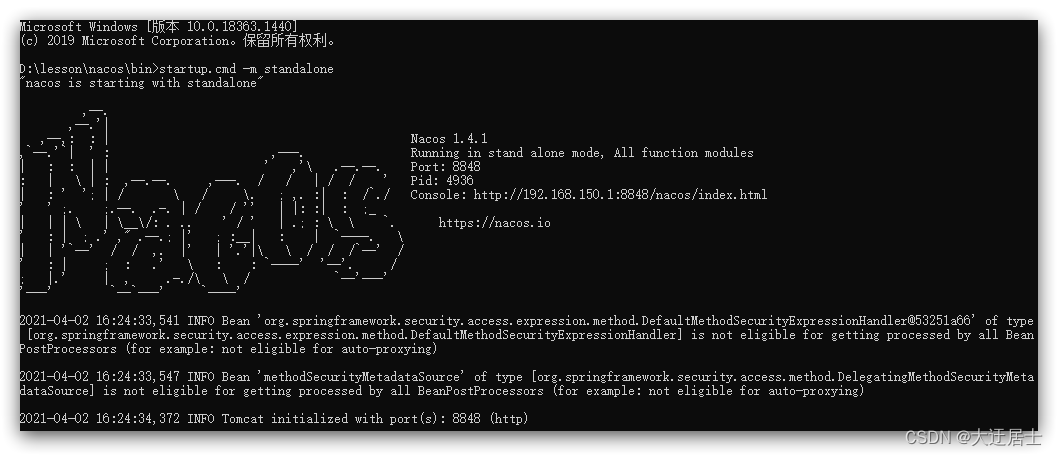
comando do windows:
startup.cmd -m standalone
O efeito após a execução é o seguinte:
5.1.1.5. Acesso
Digite o endereço no navegador: http://127.0.0.1:8848/nacos:
A conta e a senha padrão são ambas nacos, depois de inserir:
5.1.2, instalação do Linux
5.1.2.1, instale o JDK
O Nacos depende do JDK para ser executado e o JDK precisa ser instalado no índice Linux.
Carregue o pacote de instalação do jdk:
Carregar para um diretório, por exemplo:/usr/local/
Depois descompacte:
tar -xvf jdk-8u144-linux-x64.tar.gz
então renomeie para java
Configurar variáveis de ambiente:
export JAVA_HOME=/usr/local/java
export PATH=$PATH:$JAVA_HOME/bin
Definir variáveis de ambiente:
source /etc/profile
5.1.2.2. Carregar pacote de instalação
Como mostrado na imagem:
Carregue em um diretório do servidor Linux, por exemplo, /usr/local/srcno diretório:
5.1.2.3, Descompressão
Comando para descompactar o pacote de instalação:
tar -xvf nacos-server-1.4.1.tar.gz
Em seguida, remova o pacote de instalação:
rm -rf nacos-server-1.4.1.tar.gz
O estilo final no diretório:
Dentro do diretório:
5.1.2.4, configuração de porta
Semelhante a janelas
5.1.2.5, iniciar
No diretório nacos/bin, insira o comando para iniciar o Nacos:
sh startup.sh -m standalone
5.2. Início rápido do Nacos
O Nacos é um componente do SpringCloudAlibaba, e o SpringCloudAlibaba também segue as especificações de registro e descoberta de serviço definidas no SpringCloud. Portanto, não há muita diferença entre usar Nacos e usar Eureka para microsserviços.
As principais diferenças são:
- depende de diferentes
- o endereço do serviço é diferente
5.2.1. Apresentando dependências
<dependencyManagement>Introduza a dependência de SpringCloudAlibaba no arquivo pom do projeto pai cloud-demo :
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>2.2.6.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
Em seguida, introduza as dependências do nacos-discovery nos arquivos pom em user-service e order-service:
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
Nota : Não se esqueça de comentar as dependências do eureka.
5.2.2. Configurar endereço nacos
Adicione o endereço nacos em application.yml de user-service e order-service:
spring:
cloud:
nacos:
server-addr: localhost:8848
Nota : Não se esqueça de comentar o endereço de eureka
5.2.3, reinicie
Depois de reiniciar o microsserviço, faça login na página de gerenciamento do nacos e você poderá ver as informações do microsserviço:
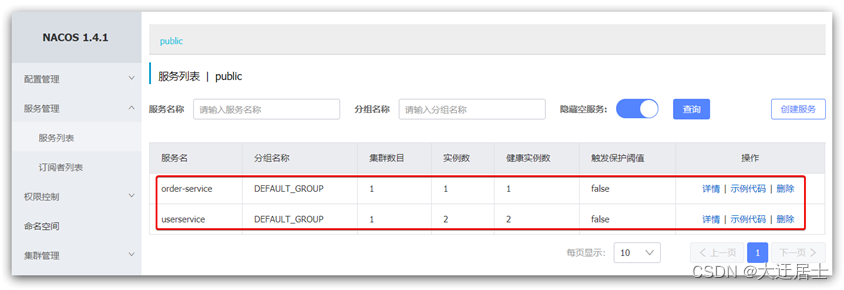
Resumir:
Construção de serviços Nacos
- Baixe o pacote de instalação
- descomprimir
- Execute o comando no diretório bin: startup.cmd -m standalone
Registro ou descoberta do serviço Nacos
- Apresentar a dependência nacos.discovery
- Configurar o endereço nacos spring.cloud.nacos.server-addr
5.3, modelo de armazenamento hierárquico do serviço Nacos
Um serviço pode ter múltiplas instâncias , como nosso user-service, pode ter:
- 127.0.0.1:8081
- 127.0.0.1:8082
- 127.0.0.1:8083
Se essas instâncias estiverem distribuídas em diferentes salas de informática pelo país, por exemplo:
- 127.0.0.1:8081, na sala de informática de Xangai
- 127.0.0.1:8082, na sala de informática de Xangai
- 127.0.0.1:8083, na sala de informática de Hangzhou
O Nacos divide as instâncias na mesma sala de computadores em um cluster .
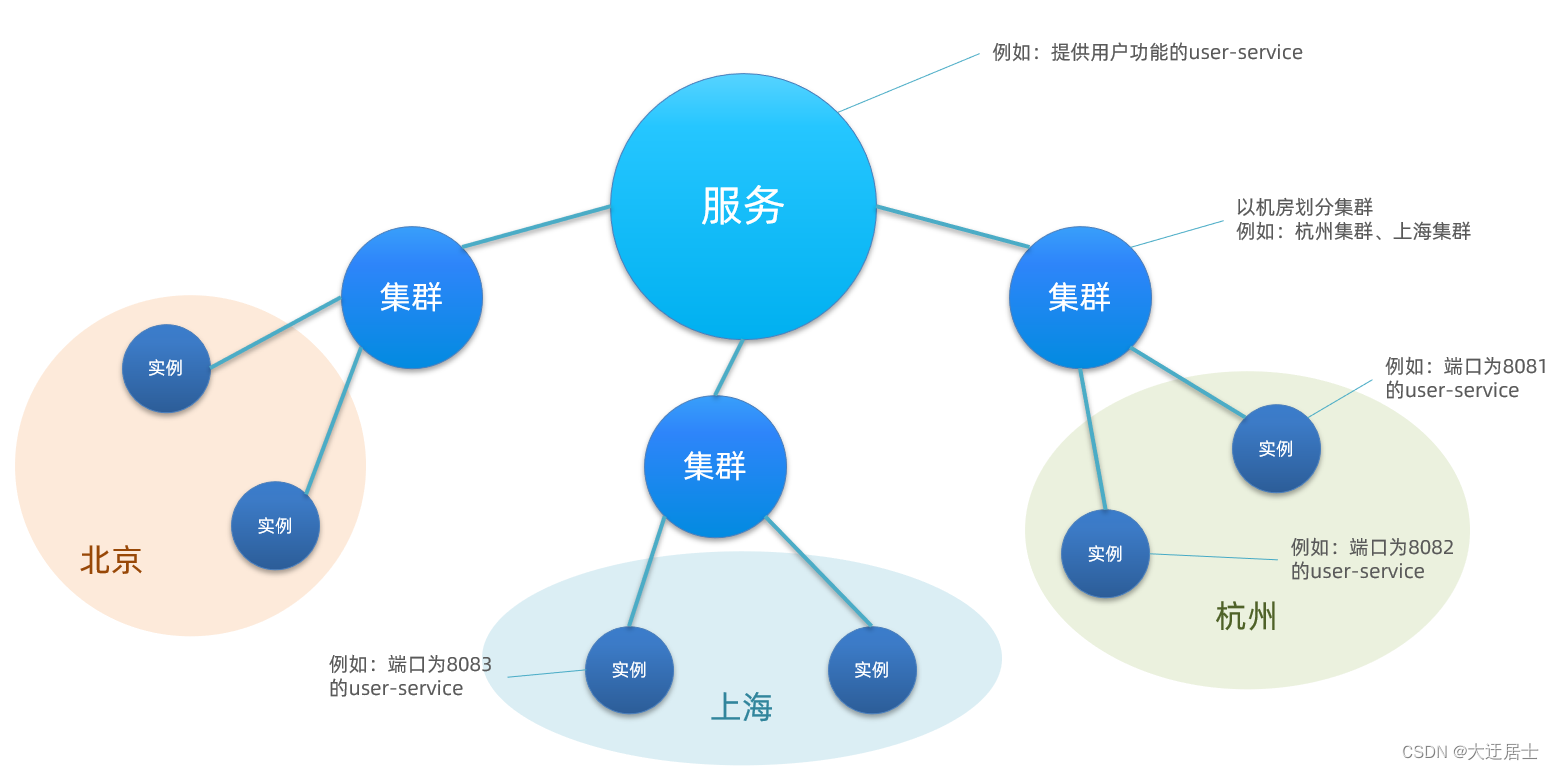
Em outras palavras, user-service é um serviço. Um serviço pode conter vários clusters, como Hangzhou e Shanghai. Cada cluster pode ter várias instâncias, formando um modelo hierárquico, conforme mostrado na figura:
Quando os microsserviços acessam uns aos outros, eles devem acessar a mesma instância de cluster tanto quanto possível, porque o acesso local é mais rápido. Acesse outros clusters somente quando o cluster estiver indisponível. Por exemplo:
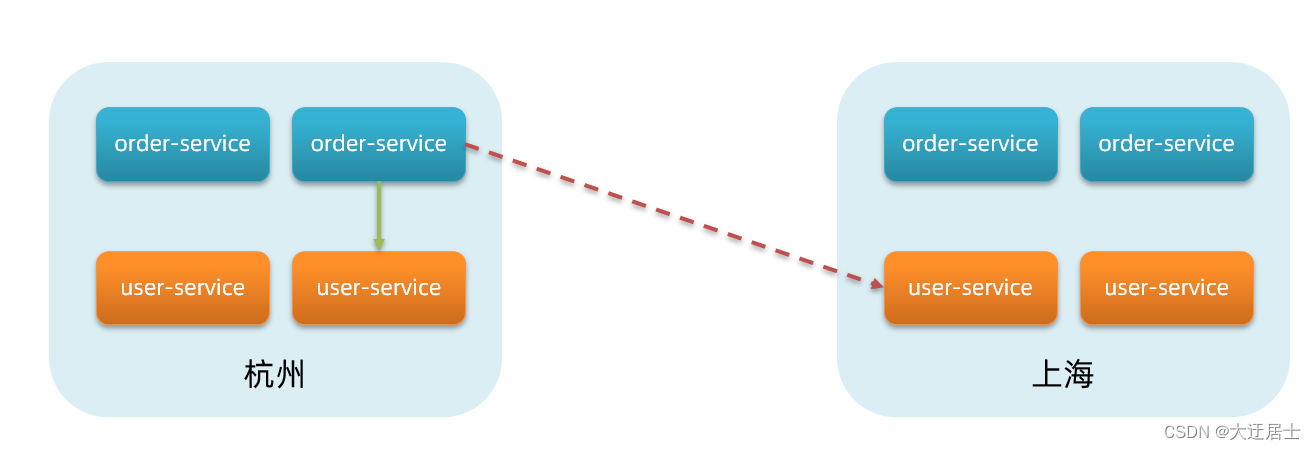
O serviço de pedidos na sala de computadores em Hangzhou deve dar prioridade ao acesso ao serviço de usuários na mesma sala de computadores.
Resumir:
Modelo de armazenamento hierárquico do serviço Nacos
- O primeiro nível é um serviço, como userservice
- O segundo nível é o cluster, como Hangzhou ou Xangai
- O terceiro nível é uma instância, como um servidor em uma sala de computadores em Hangzhou que implementa o serviço de usuário
Como definir propriedades de cluster para uma instância
- Modifique o arquivo application.yml e inclua a propriedade spring.cloud.nacos.discovery.cluster-name
5.3.1. Configurar cluster para serviço de usuário
Modifique o arquivo application.yml do user-service e adicione a configuração do cluster:
spring:
cloud:
nacos:
server-addr: localhost:8848
discovery:
cluster-name: HZ # 集群名称
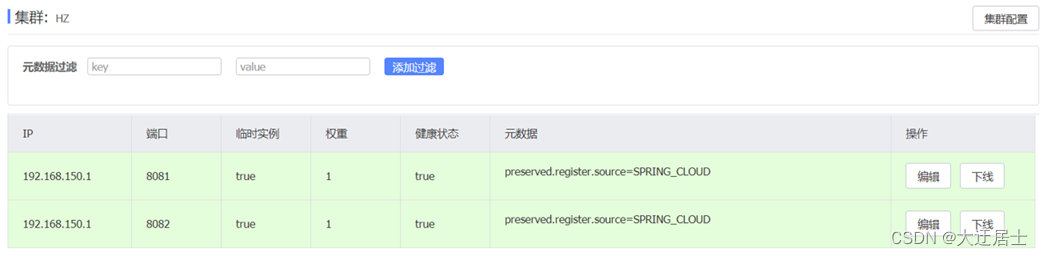
Depois de reiniciar as duas instâncias de serviço de usuário, podemos ver os seguintes resultados no console nacos:
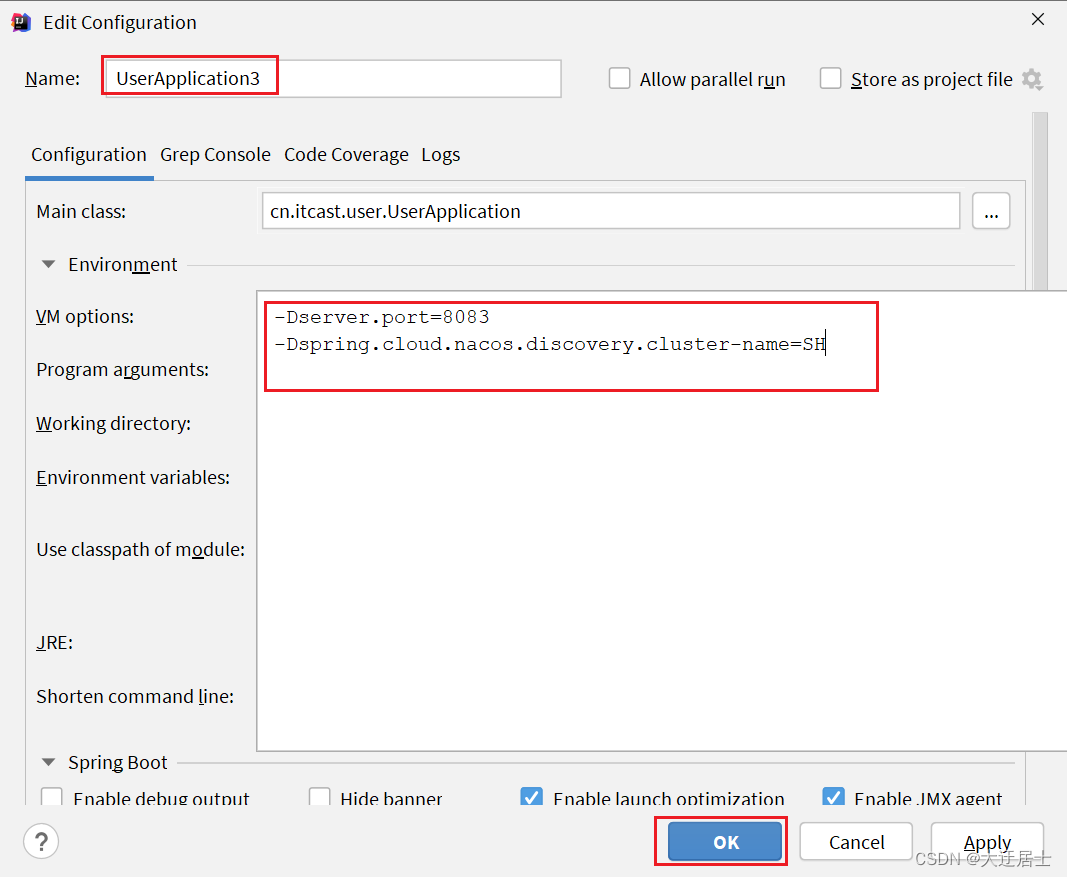
copiamos uma configuração de inicialização de serviço de usuário novamente e adicionamos propriedades:
-Dserver.port=8083 -Dspring.cloud.nacos.discovery.cluster-name=SH
A configuração é mostrada na figura:
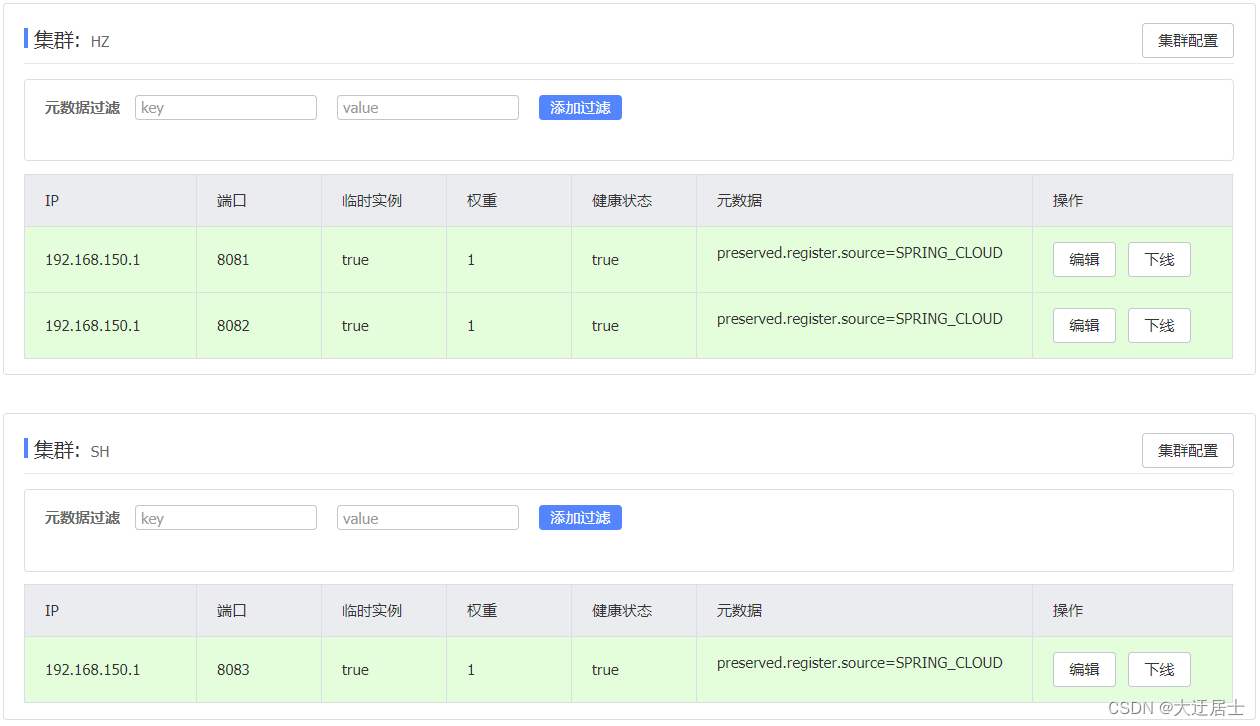
Verifique o console nacos novamente após iniciar o UserApplication3:
5.3.2. Balanceamento de carga com a mesma prioridade de cluster
Por padrão, ZoneAvoidanceRulenão é possível obter balanceamento de carga com base na prioridade do mesmo cluster.
Portanto, o Nacos fornece uma NacosRuleimplementação que pode selecionar preferencialmente instâncias do mesmo cluster.
1) Configurar informações de cluster para serviço de pedido
Modifique o arquivo application.yml de order-service e adicione a configuração do cluster:
spring:
cloud:
nacos:
server-addr: localhost:8848
discovery:
cluster-name: HZ # 集群名称
2) Modifique as regras de balanceamento de carga
Modifique o arquivo application.yml de order-service e modifique as regras de balanceamento de carga:
userservice:
ribbon:
NFLoadBalancerRuleClassName: com.alibaba.cloud.nacos.ribbon.NacosRule # 负载均衡规则
Estratégia de balanceamento de carga NacosRule
- Priorize a lista de instâncias de serviço no mesmo cluster
- O cluster local não consegue encontrar o provedor, então ele vai para outros clusters para procurá-lo e um aviso será relatado
- Depois de determinar a lista de instâncias disponíveis, o balanceamento de carga aleatório é usado para selecionar as instâncias
5.4. Configuração de peso
Na implantação real, esse cenário aparecerá:
O desempenho dos equipamentos do servidor é diferente. Algumas instâncias têm melhor desempenho, enquanto outras têm desempenho inferior. Esperamos que as máquinas com melhor desempenho possam suportar mais solicitações do usuário.
Mas por padrão, o NacosRule é selecionado aleatoriamente no mesmo cluster, sem considerar o desempenho da máquina.
Portanto, o Nacos fornece configuração de peso para controlar a frequência de acesso, quanto maior o peso, maior a frequência de acesso.
No console nacos, localize a lista de instâncias de serviço do usuário, clique em Editar e você pode modificar o peso:
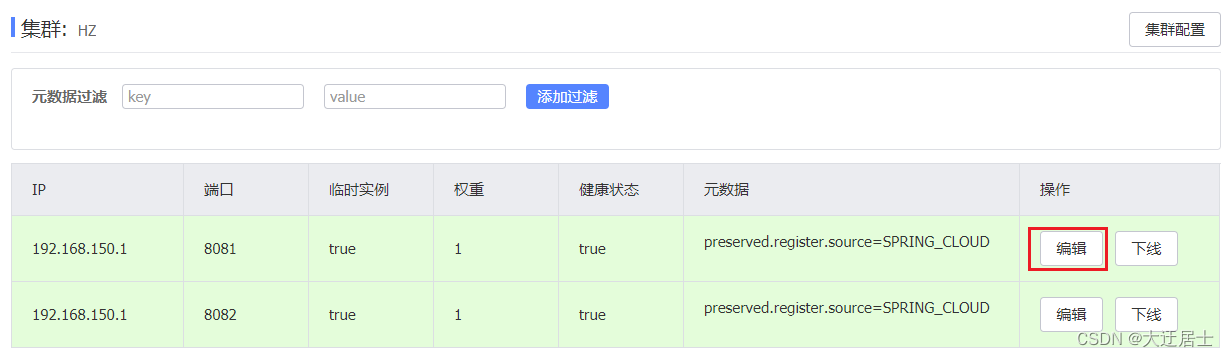
Na janela pop-up de edição, modifique o peso:

Nota : Se o peso for modificado para 0, a instância nunca será visitada
5.5. Isolamento do ambiente Nacos
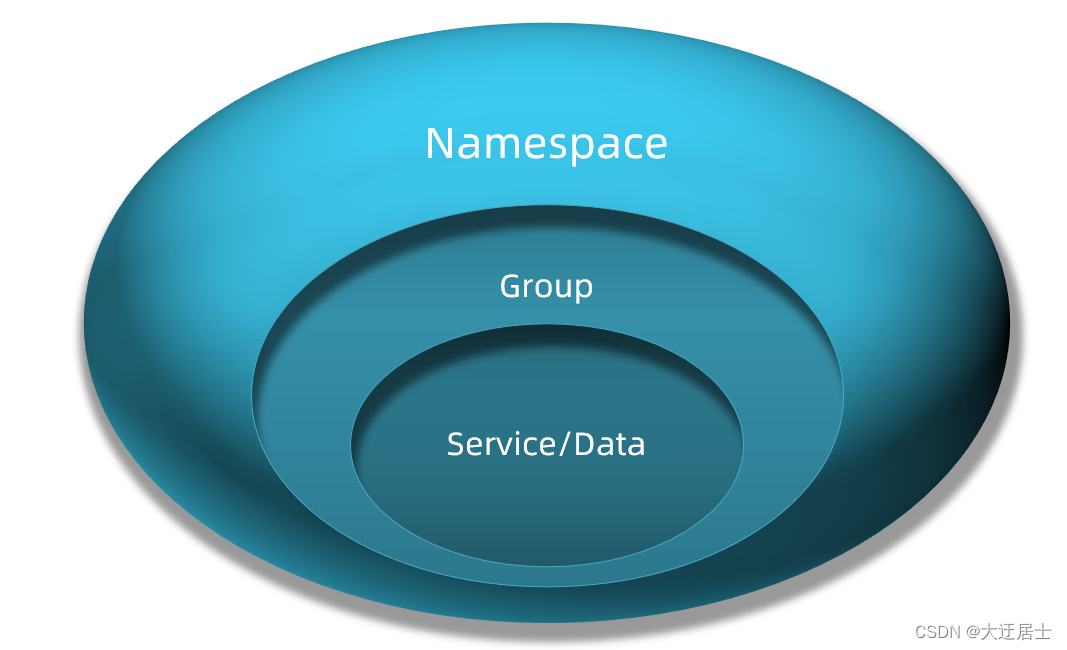
A Nacos fornece namespace para implementar o isolamento do ambiente.
- Pode haver vários namespaces em nacos
- Pode haver grupo, serviço, etc. sob o namespace
- Namespaces diferentes são isolados uns dos outros, por exemplo, serviços em namespaces diferentes são invisíveis entre si
5.5.1. Criar um namespace
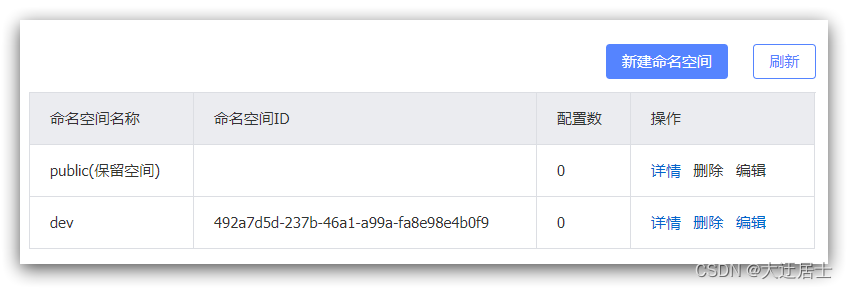
Por padrão, todos os serviços, dados e grupos estão no mesmo namespace denominado public:
Podemos clicar no botão Adicionar na página para adicionar um namespace:
Em seguida, preencha o formulário:
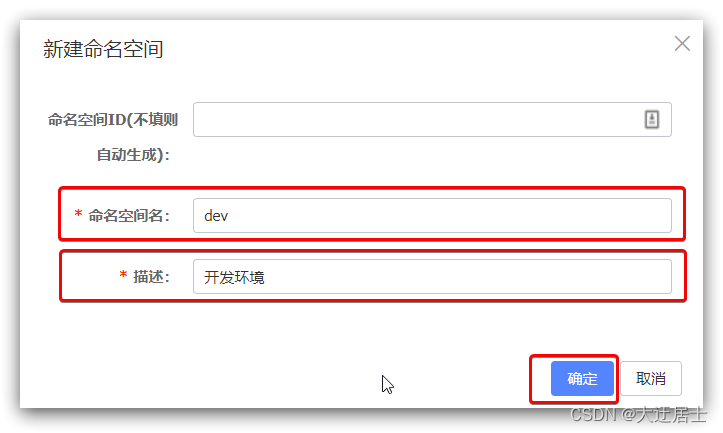
Você pode ver um novo namespace na página:
5.5.2. Configurar namespace para microsserviços
A configuração de namespaces para microsserviços só pode ser feita modificando a configuração.
Por exemplo, modifique o arquivo application.yml de order-service:
spring:
cloud:
nacos:
server-addr: localhost:8848
discovery:
cluster-name: HZ
namespace: 492a7d5d-237b-46a1-a99a-fa8e98e4b0f9 # 命名空间,填ID
Depois de reiniciar o serviço de pedidos, acesse o console e você verá os seguintes resultados:
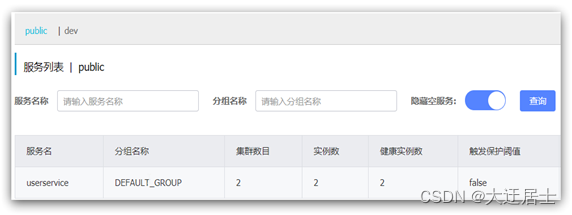
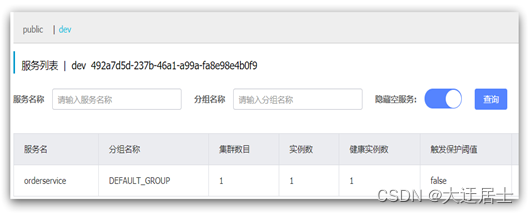
Neste momento, ao acessar o order-service, como o namespace é diferente, o userservice não será encontrado e o console informará um erro:

Resumir:
Isolamento do ambiente Nacos
- Cada namespace tem um id único
- Quando o serviço definir o namespace, escreva o id em vez do nome
- Serviços em diferentes namespaces são invisíveis uns para os outros
5.6 A diferença entre Nacos e Eureka
As instâncias do serviço Nacos são divididas em dois tipos:
-
Instância temporária: Caso a instância fique fora do ar por mais de um determinado período de tempo, ela será removida da lista de serviços, o tipo padrão.
-
Instância não temporária: Se a instância cair, ela não será removida da lista de serviços e também pode ser chamada de instância permanente.
Configure uma instância de serviço como uma instância permanente:
spring:
cloud:
nacos:
discovery:
ephemeral: false # 设置为非临时实例
A estrutura geral de Nacos e Eureka é semelhante, registro de serviço, pull de serviço, espera de pulsação, mas existem algumas diferenças:
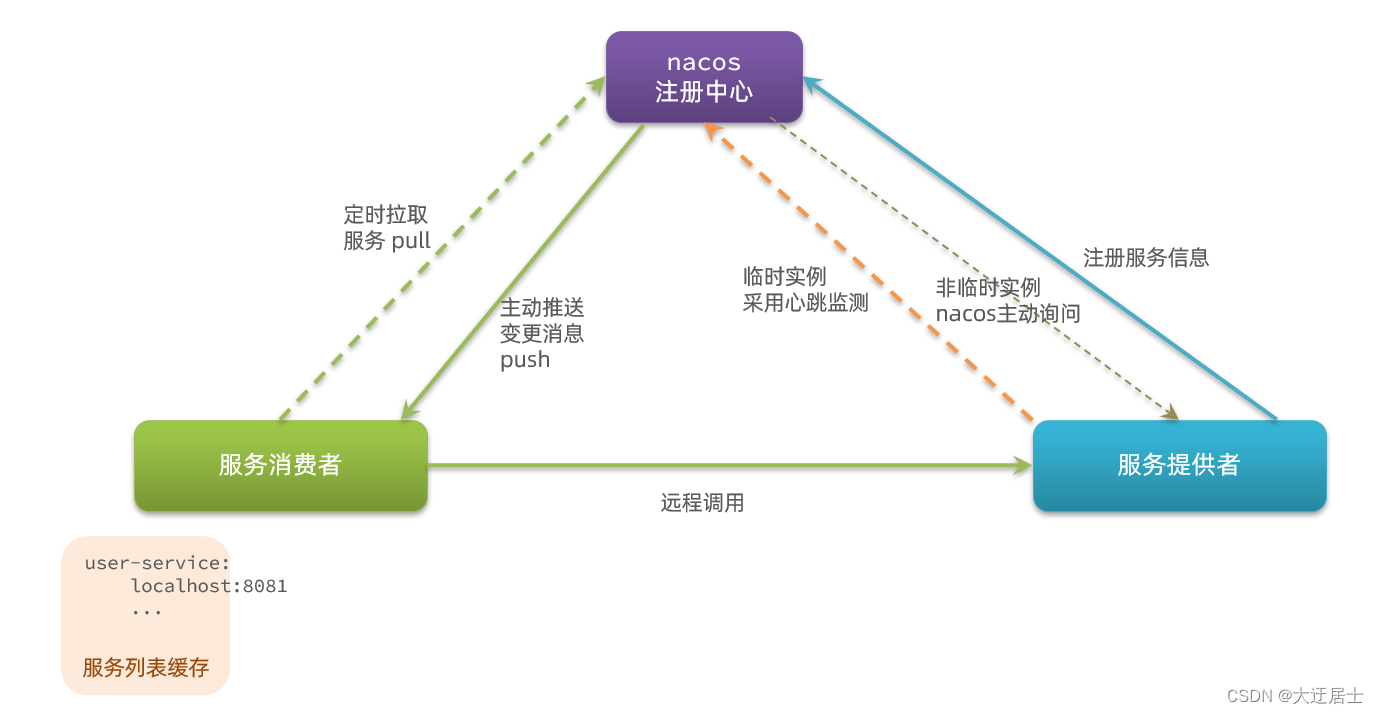
-
O que Nacos e eureka têm em comum
- Ambos oferecem suporte ao registro de serviço e ao pull de serviço
- Ambos oferecem suporte ao método de pulsação do provedor de serviços para detecção de integridade
-
A diferença entre Nacos e Eureka
- Nacos suporta o servidor para detectar ativamente o status do provedor: a instância temporária adota o modo de pulsação e a instância não temporária adota o modo de detecção ativa
- Instâncias temporárias com pulsação anormal serão removidas, enquanto instâncias não temporárias não serão removidas
- O Nacos suporta o modo push de mensagens das alterações da lista de serviços e as atualizações da lista de serviços são mais oportunas
- O cluster Nacos adota o modo AP por padrão. Quando há instâncias não temporárias no cluster, o modo CP é adotado; Eureka adota o modo AP
6. Gerenciamento de configuração do Nacos
6.1. Gerenciamento de configuração unificado
Quando mais e mais instâncias de microsserviços são implantadas, chegando a dezenas ou centenas, modificar a configuração dos microsserviços um a um deixará as pessoas malucas e propensas a erros. Precisamos de uma solução unificada de gerenciamento de configuração que possa gerenciar centralmente a configuração de todas as instâncias.
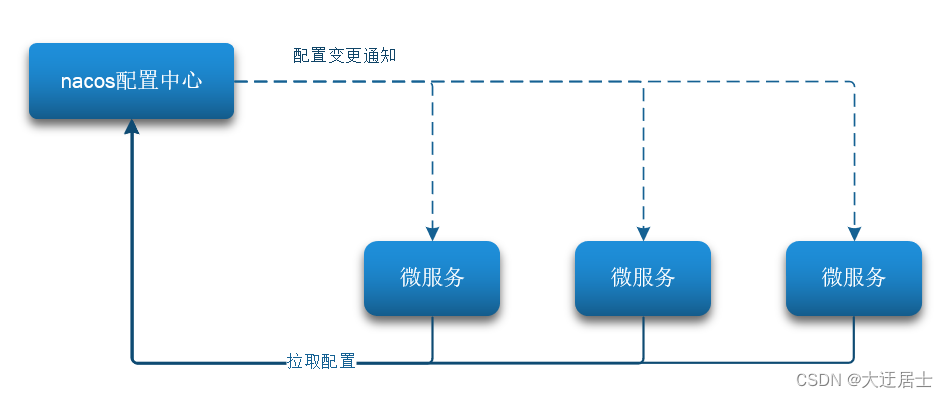
Por um lado, o Nacos pode gerenciar centralmente a configuração e, por outro lado, quando a configuração é alterada, pode notificar o microsserviço a tempo de realizar uma atualização dinâmica da configuração.
6.1.1. Adicionar arquivos de configuração em nacos
Como gerenciar a configuração em nacos?
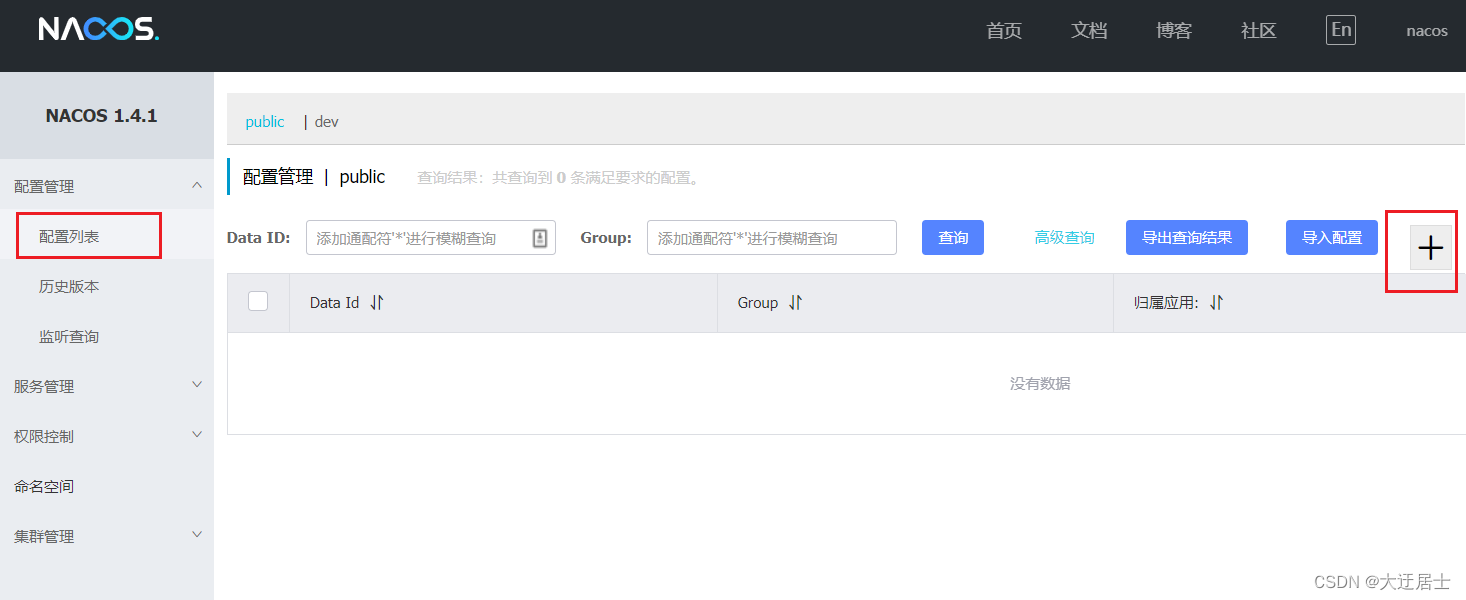
Em seguida, preencha as informações de configuração no formulário pop-up:
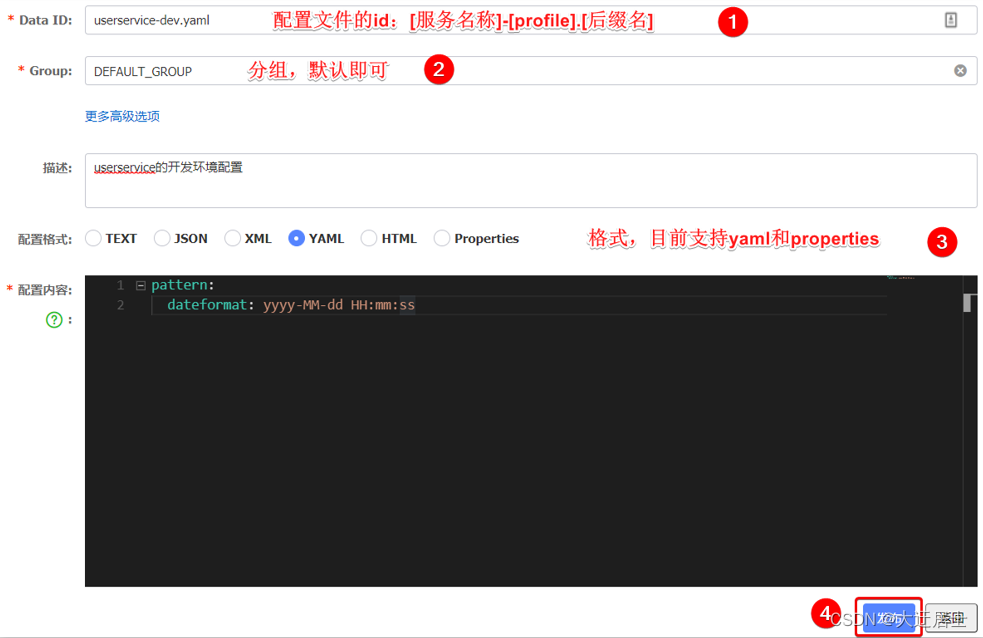
Nota: A configuração principal do projeto precisa ser gerenciada por nacos somente quando a configuração de atualização automática é necessária. É melhor salvar algumas configurações que não serão alteradas localmente no microsserviço.
6.1.2. Configuração de pull de microsserviços
O microsserviço precisa extrair a configuração gerenciada em nacos e mesclá-la com a configuração local do application.yml para concluir a inicialização do projeto.
Mas se application.yml ainda não foi lido, como você sabe o endereço de nacos?
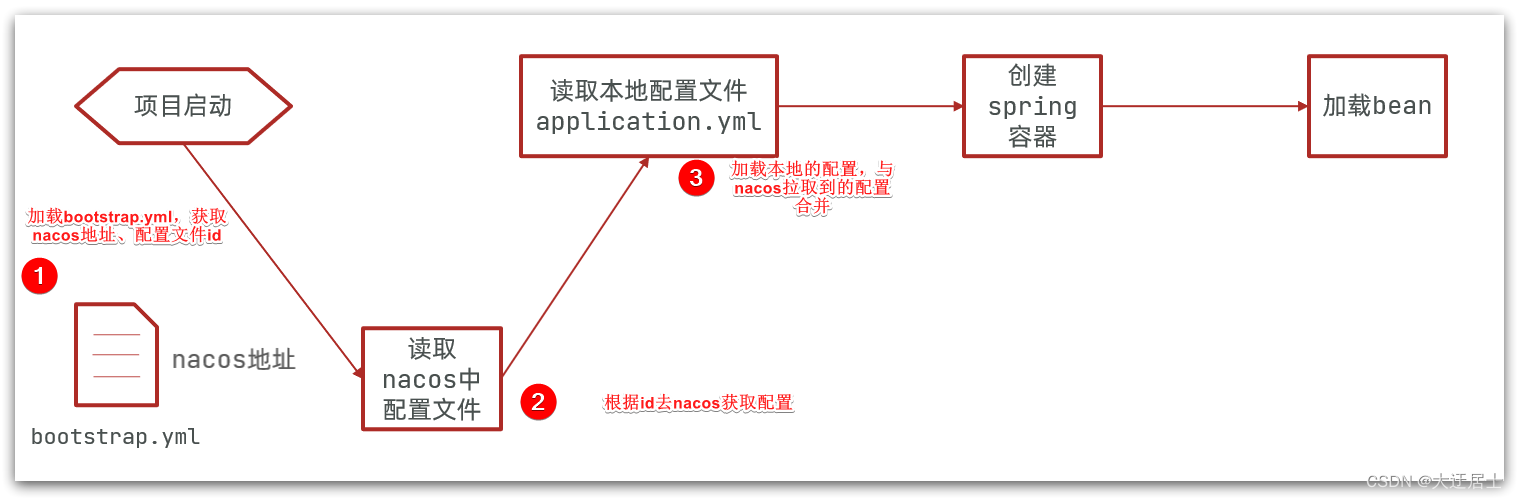
Portanto, o spring apresenta um novo arquivo de configuração: o arquivo bootstrap.yaml, que será lido antes do application.yml. O processo é o seguinte:
1) Introduza a dependência nacos-config
Primeiro, no serviço de atendimento ao usuário, introduza a dependência do cliente de nacos-config:
<!--nacos配置管理依赖-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
2) Adicionar bootstrap.yaml
Em seguida, adicione um arquivo bootstrap.yaml em user-service com o seguinte conteúdo:
spring:
application:
name: userservice # 服务名称
profiles:
active: dev #开发环境,这里是dev
cloud:
nacos:
server-addr: localhost:8848 # Nacos地址
config:
file-extension: yaml # 文件后缀名
Aqui, o endereço nacos será obtido de acordo com spring.cloud.nacos.server-addr e, em seguida, de acordo com
${spring.application.name}-${spring.profiles.active}.${spring.cloud.nacos.config.file-extension}Como um id de arquivo, para ler o arquivo configuration.
Neste exemplo, é para ler userservice-dev.yaml:

3) Leia a configuração do nacos
Adicione a lógica de negócios ao UserController no serviço do usuário, leia a configuração pattern.dateformat:
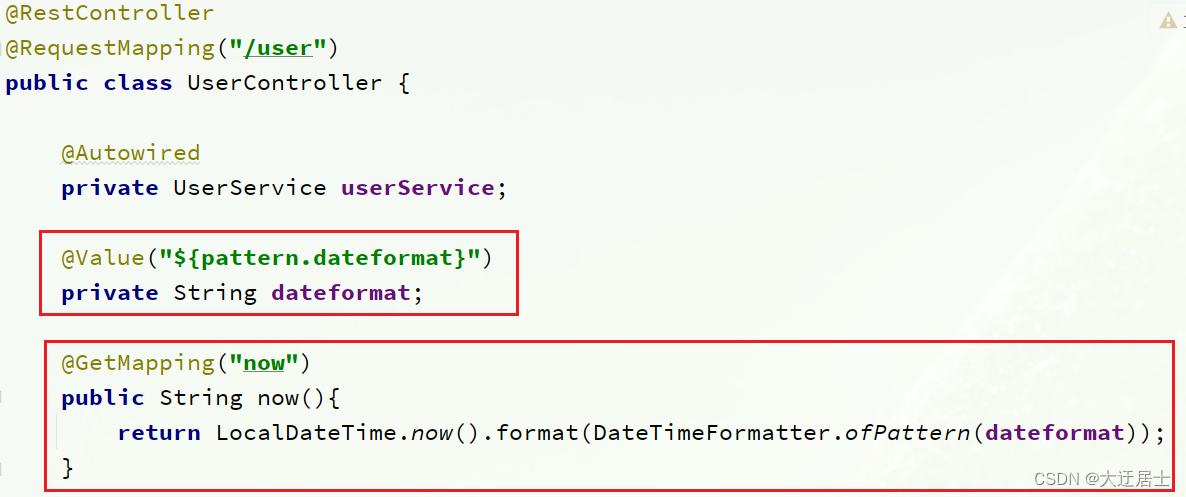
Código completo:
@Slf4j
@RestController
@RequestMapping("/user")
public class UserController {
@Autowired
private UserService userService;
@Value("${pattern.dateformat}")
private String dateformat;
@GetMapping("now")
public String now(){
return LocalDateTime.now().format(DateTimeFormatter.ofPattern(dateformat));
}
// ...略
}
Ao visitar a página, você pode ver o efeito:

Resumir:
Etapas para entregar a configuração ao gerenciamento da Nacos
- Adicionar arquivos de configuração no Nacos
- Introduzir dependências de configuração do nacos em microsserviços
- Adicione bootstrap.yml ao microsserviço e configure o endereço nacos, o ambiente atual, o nome do serviço e a extensão do arquivo. Estes determinam qual arquivo ler do nacos quando o programa iniciar
6.2. Atualização a quente da configuração
Nosso objetivo final é modificar a configuração no nacos, para que o microsserviço possa fazer a configuração entrar em vigor sem reiniciar, ou seja, hot update da configuração .
Para obter a atualização dinâmica da configuração, dois métodos podem ser usados:
6.2.1. Método 1
Adicione a anotação @RefreshScope à classe onde está localizada a variável injetada por @Value:

6.2.2. Método 2
Use a anotação @ConfigurationProperties em vez da anotação @Value.
No serviço de atendimento ao usuário, adicione uma classe para ler a propriedade patternern.dateformat:
@Component
@Data
@ConfigurationProperties(prefix = "pattern")
public class PatternProperties {
private String dateformat;
}
Use esta classe em vez de @Value no UserController:
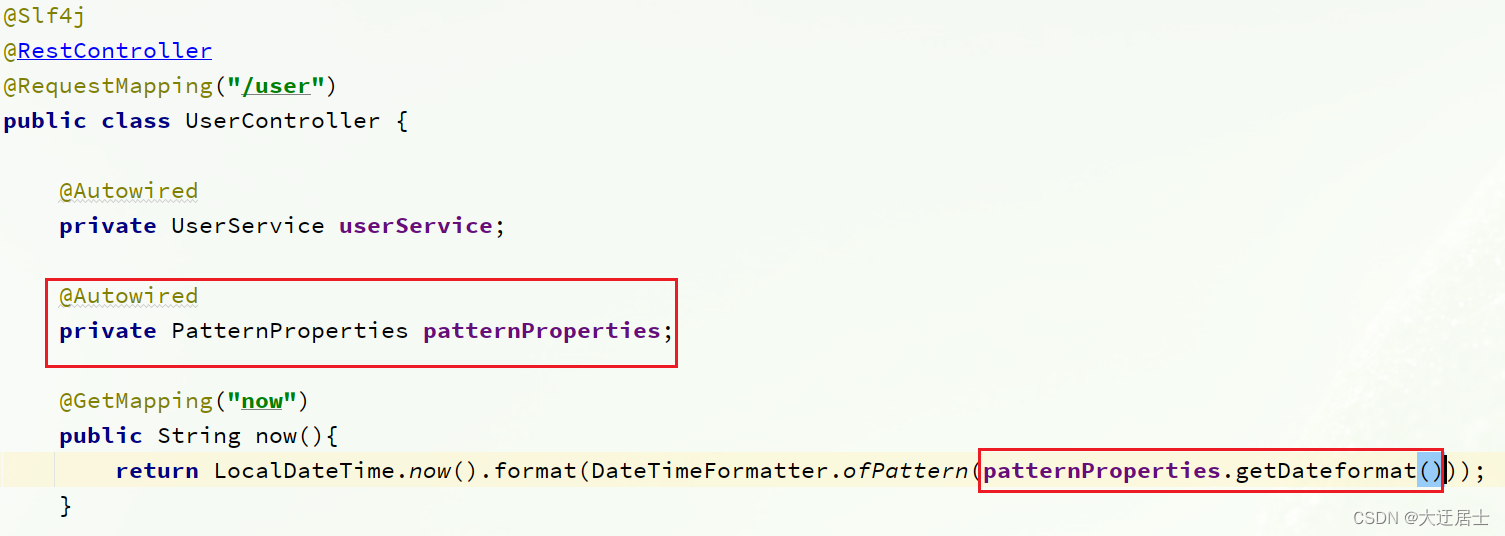
Código completo:
@Slf4j
@RestController
@RequestMapping("/user")
public class UserController {
@Autowired
private UserService userService;
@Autowired
private PatternProperties patternProperties;
@GetMapping("now")
public String now(){
return LocalDateTime.now().format(DateTimeFormatter.ofPattern(patternProperties.getDateformat()));
}
// 略
}
Resumir:
Depois que a configuração do Nacos é alterada, os microsserviços podem ser atualizados das seguintes maneiras:
- Injetado por meio da anotação @Value, combinado com @RefreshScope para atualizar
- Injetado por meio de @ConfigurationProperties, atualizado automaticamente
Precauções:
-
Nem todas as configurações são adequadas para serem colocadas no centro de configuração, o que é problemático de manter
-
Recomenda-se colocar alguns parâmetros-chave e parâmetros que precisam ser ajustados em tempo de execução no centro de configuração do nacos, que geralmente são configurações personalizadas
6.3, compartilhamento de configuração
Na verdade, quando o microsserviço for iniciado, ele irá para o nacos para ler vários arquivos de configuração, por exemplo:
-
[spring.application.name]-[spring.profiles.active].yaml, por exemplo: userservice-dev.yaml -
[spring.application.name].yaml, por exemplo: userservice.yaml
Não[spring.application.name].yaml contém ambientes, portanto pode ser compartilhado por vários ambientes.
Vamos testar o compartilhamento de configuração através do caso
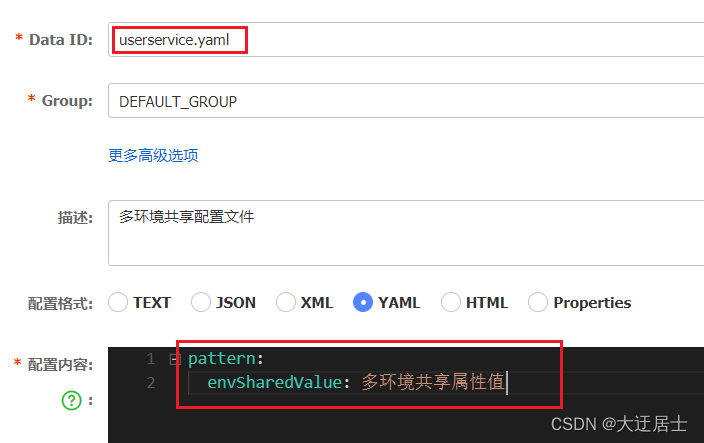
6.3.1. Adicionar uma configuração de compartilhamento de ambiente
Adicionamos um arquivo userservice.yaml em nacos:
6.3.2. Leia a configuração compartilhada no serviço do usuário
No serviço de atendimento ao usuário, modifique a classe PatternProperties para ler as propriedades recém-adicionadas:
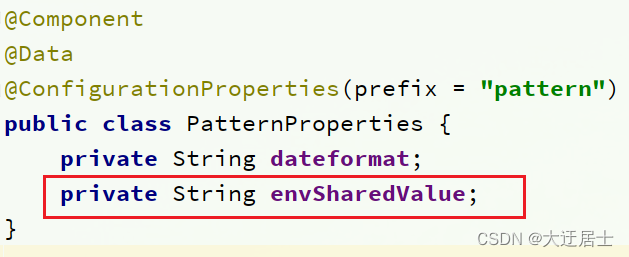
No serviço de serviço do usuário, modifique UserController e adicione um método:
6.3.3. Execute dois UserApplications com perfis diferentes
Modifique o item de inicialização UserApplication2 e altere seu valor de perfil:
Desta forma, o perfil utilizado por UserApplication (8081) é dev, e o perfil utilizado por UserApplication2 (8082) é test.
Iniciar UserApplication e UserApplication2
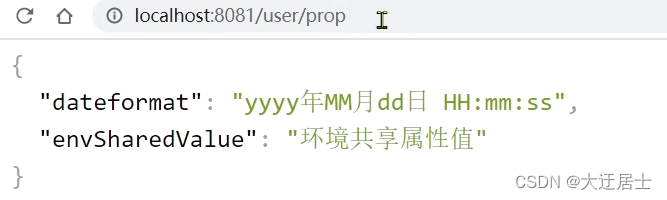
Visite http://localhost:8081/user/prop, o resultado:
Visite http://localhost:8082/user/prop, o resultado:

Pode-se ver que os ambientes de desenvolvimento e teste leram o valor do atributo envSharedValue.
6.3.4. Configure a prioridade de compartilhamento
Quando nacos e service local possuem o mesmo atributo ao mesmo tempo, a prioridade é dividida em alta e baixa:

resumo:
Arquivos de configuração lidos por microsserviços por padrão:
- [nome do serviço]-[spring.profile.active].yaml, a configuração padrão
- [nome do serviço].yaml, compartilhamento de vários ambientes
Arquivos de configuração compartilhados por diferentes microsserviços:
- Especificado por configurações compartilhadas
- Especificado por extension-configs
prioridade:
- Configuração do ambiente > service name.yaml > extension-config > extension-configs > shared-configs > configuração local
6.2. Construir um cluster Nacos
6.2.1. Diagrama de estrutura de cluster
O diagrama de cluster oficial do Nacos:
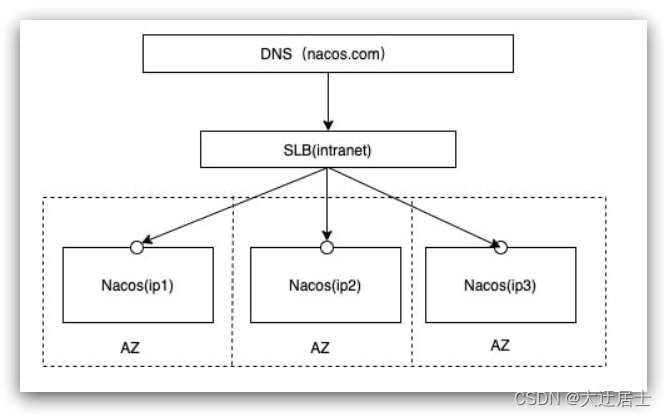
Ele contém 3 nós nacos e, em seguida, um proxy de balanceador de carga 3 Nacos. Aqui, o balanceador de carga pode usar nginx.
Nossa estrutura de cluster planejada:
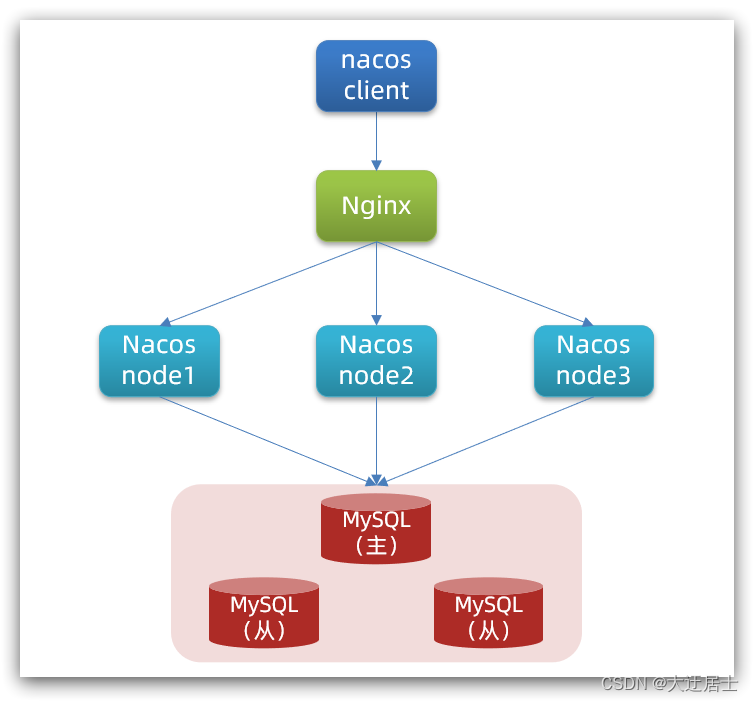
Endereços de três nós nacos:
| nó | ip | porta |
|---|---|---|
| nacos1 | 192.168.150.1 | 8845 |
| nacos2 | 192.168.150.1 | 8846 |
| nacos3 | 192.168.150.1 | 8847 |
6.2.2. Construindo um cluster
As etapas básicas para criar um cluster:
- Construa o banco de dados e inicialize a estrutura da tabela do banco de dados
- Baixe o pacote de instalação do nacos
- configurar nacos
- Iniciar cluster nacos
- proxy reverso nginx
6.2.2.1. Inicializar o banco de dados
Os dados padrão do Nacos são armazenados no banco de dados incorporado Derby, que não é um banco de dados disponível para produção.
A melhor prática oficialmente recomendada é usar um cluster de banco de dados de alta disponibilidade com mestre-escravo Aqui, tomamos um banco de dados de ponto único como exemplo para explicar.
Primeiro crie um novo banco de dados, nomeie-o nacos e importe o seguinte SQL:
CREATE TABLE `config_info` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'id',
`data_id` varchar(255) NOT NULL COMMENT 'data_id',
`group_id` varchar(255) DEFAULT NULL,
`content` longtext NOT NULL COMMENT 'content',
`md5` varchar(32) DEFAULT NULL COMMENT 'md5',
`gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间',
`src_user` text COMMENT 'source user',
`src_ip` varchar(50) DEFAULT NULL COMMENT 'source ip',
`app_name` varchar(128) DEFAULT NULL,
`tenant_id` varchar(128) DEFAULT '' COMMENT '租户字段',
`c_desc` varchar(256) DEFAULT NULL,
`c_use` varchar(64) DEFAULT NULL,
`effect` varchar(64) DEFAULT NULL,
`type` varchar(64) DEFAULT NULL,
`c_schema` text,
PRIMARY KEY (`id`),
UNIQUE KEY `uk_configinfo_datagrouptenant` (`data_id`,`group_id`,`tenant_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='config_info';
/******************************************/
/* 数据库全名 = nacos_config */
/* 表名称 = config_info_aggr */
/******************************************/
CREATE TABLE `config_info_aggr` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'id',
`data_id` varchar(255) NOT NULL COMMENT 'data_id',
`group_id` varchar(255) NOT NULL COMMENT 'group_id',
`datum_id` varchar(255) NOT NULL COMMENT 'datum_id',
`content` longtext NOT NULL COMMENT '内容',
`gmt_modified` datetime NOT NULL COMMENT '修改时间',
`app_name` varchar(128) DEFAULT NULL,
`tenant_id` varchar(128) DEFAULT '' COMMENT '租户字段',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_configinfoaggr_datagrouptenantdatum` (`data_id`,`group_id`,`tenant_id`,`datum_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='增加租户字段';
/******************************************/
/* 数据库全名 = nacos_config */
/* 表名称 = config_info_beta */
/******************************************/
CREATE TABLE `config_info_beta` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'id',
`data_id` varchar(255) NOT NULL COMMENT 'data_id',
`group_id` varchar(128) NOT NULL COMMENT 'group_id',
`app_name` varchar(128) DEFAULT NULL COMMENT 'app_name',
`content` longtext NOT NULL COMMENT 'content',
`beta_ips` varchar(1024) DEFAULT NULL COMMENT 'betaIps',
`md5` varchar(32) DEFAULT NULL COMMENT 'md5',
`gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间',
`src_user` text COMMENT 'source user',
`src_ip` varchar(50) DEFAULT NULL COMMENT 'source ip',
`tenant_id` varchar(128) DEFAULT '' COMMENT '租户字段',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_configinfobeta_datagrouptenant` (`data_id`,`group_id`,`tenant_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='config_info_beta';
/******************************************/
/* 数据库全名 = nacos_config */
/* 表名称 = config_info_tag */
/******************************************/
CREATE TABLE `config_info_tag` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'id',
`data_id` varchar(255) NOT NULL COMMENT 'data_id',
`group_id` varchar(128) NOT NULL COMMENT 'group_id',
`tenant_id` varchar(128) DEFAULT '' COMMENT 'tenant_id',
`tag_id` varchar(128) NOT NULL COMMENT 'tag_id',
`app_name` varchar(128) DEFAULT NULL COMMENT 'app_name',
`content` longtext NOT NULL COMMENT 'content',
`md5` varchar(32) DEFAULT NULL COMMENT 'md5',
`gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间',
`src_user` text COMMENT 'source user',
`src_ip` varchar(50) DEFAULT NULL COMMENT 'source ip',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_configinfotag_datagrouptenanttag` (`data_id`,`group_id`,`tenant_id`,`tag_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='config_info_tag';
/******************************************/
/* 数据库全名 = nacos_config */
/* 表名称 = config_tags_relation */
/******************************************/
CREATE TABLE `config_tags_relation` (
`id` bigint(20) NOT NULL COMMENT 'id',
`tag_name` varchar(128) NOT NULL COMMENT 'tag_name',
`tag_type` varchar(64) DEFAULT NULL COMMENT 'tag_type',
`data_id` varchar(255) NOT NULL COMMENT 'data_id',
`group_id` varchar(128) NOT NULL COMMENT 'group_id',
`tenant_id` varchar(128) DEFAULT '' COMMENT 'tenant_id',
`nid` bigint(20) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`nid`),
UNIQUE KEY `uk_configtagrelation_configidtag` (`id`,`tag_name`,`tag_type`),
KEY `idx_tenant_id` (`tenant_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='config_tag_relation';
/******************************************/
/* 数据库全名 = nacos_config */
/* 表名称 = group_capacity */
/******************************************/
CREATE TABLE `group_capacity` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`group_id` varchar(128) NOT NULL DEFAULT '' COMMENT 'Group ID,空字符表示整个集群',
`quota` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '配额,0表示使用默认值',
`usage` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '使用量',
`max_size` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '单个配置大小上限,单位为字节,0表示使用默认值',
`max_aggr_count` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '聚合子配置最大个数,,0表示使用默认值',
`max_aggr_size` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '单个聚合数据的子配置大小上限,单位为字节,0表示使用默认值',
`max_history_count` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '最大变更历史数量',
`gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_group_id` (`group_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='集群、各Group容量信息表';
/******************************************/
/* 数据库全名 = nacos_config */
/* 表名称 = his_config_info */
/******************************************/
CREATE TABLE `his_config_info` (
`id` bigint(64) unsigned NOT NULL,
`nid` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`data_id` varchar(255) NOT NULL,
`group_id` varchar(128) NOT NULL,
`app_name` varchar(128) DEFAULT NULL COMMENT 'app_name',
`content` longtext NOT NULL,
`md5` varchar(32) DEFAULT NULL,
`gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
`gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
`src_user` text,
`src_ip` varchar(50) DEFAULT NULL,
`op_type` char(10) DEFAULT NULL,
`tenant_id` varchar(128) DEFAULT '' COMMENT '租户字段',
PRIMARY KEY (`nid`),
KEY `idx_gmt_create` (`gmt_create`),
KEY `idx_gmt_modified` (`gmt_modified`),
KEY `idx_did` (`data_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='多租户改造';
/******************************************/
/* 数据库全名 = nacos_config */
/* 表名称 = tenant_capacity */
/******************************************/
CREATE TABLE `tenant_capacity` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`tenant_id` varchar(128) NOT NULL DEFAULT '' COMMENT 'Tenant ID',
`quota` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '配额,0表示使用默认值',
`usage` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '使用量',
`max_size` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '单个配置大小上限,单位为字节,0表示使用默认值',
`max_aggr_count` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '聚合子配置最大个数',
`max_aggr_size` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '单个聚合数据的子配置大小上限,单位为字节,0表示使用默认值',
`max_history_count` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '最大变更历史数量',
`gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_tenant_id` (`tenant_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='租户容量信息表';
CREATE TABLE `tenant_info` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'id',
`kp` varchar(128) NOT NULL COMMENT 'kp',
`tenant_id` varchar(128) default '' COMMENT 'tenant_id',
`tenant_name` varchar(128) default '' COMMENT 'tenant_name',
`tenant_desc` varchar(256) DEFAULT NULL COMMENT 'tenant_desc',
`create_source` varchar(32) DEFAULT NULL COMMENT 'create_source',
`gmt_create` bigint(20) NOT NULL COMMENT '创建时间',
`gmt_modified` bigint(20) NOT NULL COMMENT '修改时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_tenant_info_kptenantid` (`kp`,`tenant_id`),
KEY `idx_tenant_id` (`tenant_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='tenant_info';
CREATE TABLE `users` (
`username` varchar(50) NOT NULL PRIMARY KEY,
`password` varchar(500) NOT NULL,
`enabled` boolean NOT NULL
);
CREATE TABLE `roles` (
`username` varchar(50) NOT NULL,
`role` varchar(50) NOT NULL,
UNIQUE INDEX `idx_user_role` (`username` ASC, `role` ASC) USING BTREE
);
CREATE TABLE `permissions` (
`role` varchar(50) NOT NULL,
`resource` varchar(255) NOT NULL,
`action` varchar(8) NOT NULL,
UNIQUE INDEX `uk_role_permission` (`role`,`resource`,`action`) USING BTREE
);
INSERT INTO users (username, password, enabled) VALUES ('nacos', '$2a$10$EuWPZHzz32dJN7jexM34MOeYirDdFAZm2kuWj7VEOJhhZkDrxfvUu', TRUE);
INSERT INTO roles (username, role) VALUES ('nacos', 'ROLE_ADMIN');
6.2.2.2. Baixar nacos
nacos tem um endereço de download no GitHub: https://github.com/alibaba/nacos/tags, você pode escolher qualquer versão para baixar.
6.2.2.3, configurar Nacos
Descompacte este pacote em qualquer diretório não chinês, conforme mostrado na figura:
Descrição do diretório:
- bin: script de inicialização
- conf: arquivo de configuração
Entre no diretório conf de nacos, modifique o arquivo de configuração cluster.conf.example e renomeie-o para cluster.conf:
Em seguida, adicione o conteúdo:
127.0.0.1:8845
127.0.0.1.8846
127.0.0.1.8847
Em seguida, modifique o arquivo application.properties e adicione a configuração do banco de dados
spring.datasource.platform=mysql
db.num=1
db.url.0=jdbc:mysql://127.0.0.1:3306/nacos?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true&useUnicode=true&useSSL=false&serverTimezone=UTC
db.user.0=root
db.password.0=123
6.2.2.4, iniciar
Copie a pasta nacos três vezes e nomeie-as: nacos1, nacos2, nacos3
Em seguida, modifique o application.properties nas três pastas, respectivamente,
nacos1:
server.port=8845
nacos2:
server.port=8846
nacos3:
server.port=8847
Em seguida, inicie três nós nacos, respectivamente:
startup.cmd
6.2.2.5, proxy reverso nginx
Encontre o pacote de instalação nginx e extraia-o em qualquer diretório não chinês:
Modifique o arquivo conf/nginx.conf, a configuração é a seguinte:
upstream nacos-cluster {
server 127.0.0.1:8845;
server 127.0.0.1:8846;
server 127.0.0.1:8847;
}
server {
listen 80;
server_name localhost;
location /nacos {
proxy_pass http://nacos-cluster;
}
}
Então acesse no navegador: http://localhost/nacos.
A configuração do arquivo application.yml no código é a seguinte:
spring:
cloud:
nacos:
server-addr: localhost:80 # Nacos地址
6.2.2.6. Otimização
-
Na implantação real, é necessário definir um nome de domínio para o servidor nginx que atue como um proxy reverso, para que não haja necessidade de alterar a configuração do cliente nacos se um servidor for migrado posteriormente.
-
Cada nó do Nacos deve ser implantado em vários servidores diferentes para recuperação e isolamento de desastres
Resumir:
Etapas de construção do cluster:
- Crie um cluster MySQL e inicialize a tabela do banco de dados
- Baixe e descompacte nacos
- Modificar a configuração do cluster (informações do nó), configuração do banco de dados
- Inicie vários nós nacos separadamente
- proxy reverso nginx
Sete, fingir chamada remota
Vamos primeiro ver o código que usamos para iniciar chamadas remotas usando RestTemplate:

Existem os seguintes problemas:
• Baixa legibilidade do código e experiência de programação inconsistente
• URLs com parâmetros complexos são difíceis de manter
Feign é um cliente http declarativo, endereço oficial: https://github.com/OpenFeign/feign
Seu papel é nos ajudar a implementar com elegância o envio de solicitações http e resolver os problemas mencionados acima.
7.1, Feign substitui RestTemplate
Os passos para usar o Fegin são os seguintes:
7.1.1. Apresentando dependências
Introduzimos a dependência feign no arquivo pom do serviço order-service:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
7.1.2. Adicionar anotações
Adicione anotações à classe de inicialização de order-service para habilitar a função de Feign:
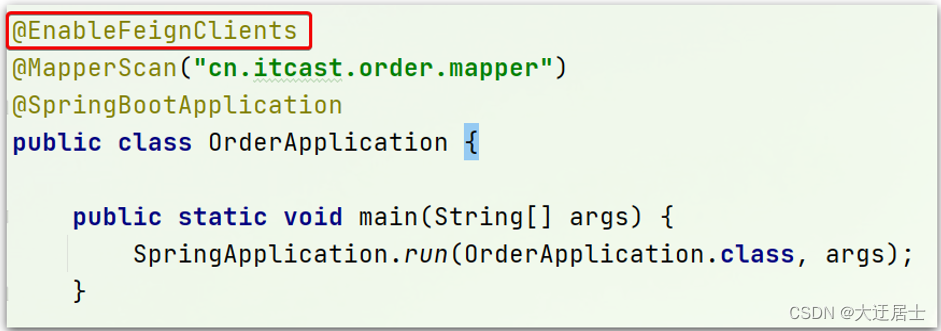
7.1.3, escreva Cliente falso
Crie uma nova interface no order-service com o seguinte conteúdo:
@FeignClient("userservice")
public interface UserClient {
@GetMapping("/user/{id}")
User findById(@PathVariable("id") Long id);
}
Este cliente é baseado principalmente em anotações SpringMVC para declarar informações de chamadas remotas, como:
- Nome do serviço: userservice
- Método de solicitação: GET
- Caminho da solicitação: /user/{id}
- Parâmetro de solicitação: ID longo
- Tipo de valor de retorno: Usuário
Dessa forma, Feign pode nos ajudar a enviar solicitações http sem usar RestTemplate para enviá-las nós mesmos.
7.1.4. Teste
Modifique o método queryOrderById na classe OrderService no serviço de pedido e use o cliente Feign em vez de RestTemplate:
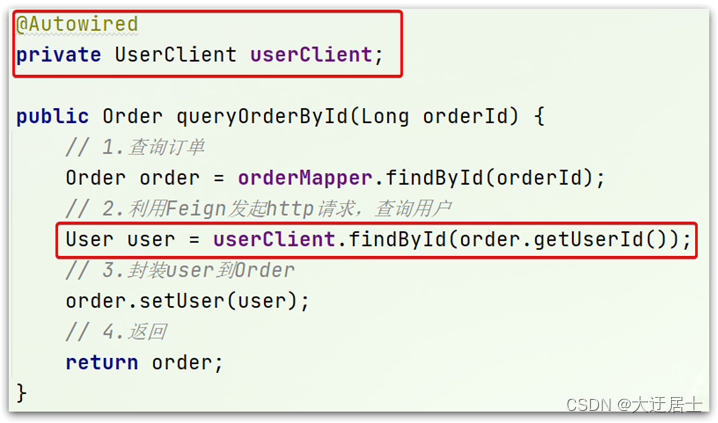
Não parece mais elegante.
7.1.5. Resumo
Passos para usar Feign:
① Introduzir dependência
② Adicione a anotação @EnableFeignClients
③ Escreva a interface FeignClient
④ Use o método definido em FeignClient em vez de RestTemplate
7.2, configuração personalizada
Feign pode suportar muitas configurações personalizadas, conforme mostrado na tabela a seguir:
| tipo | efeito | ilustrar |
|---|---|---|
| fingir.Logger.Level | Modificar nível de registro | Contém quatro níveis diferentes: NONE, BASIC, HEADERS, FULL |
| fingir.codec.Decoder | Analisador para o resultado da resposta | Analisar os resultados de chamadas remotas http, como analisar strings json em objetos java |
| fingir.codec.Encoder | solicitar codificação de parâmetro | Codificar parâmetros de solicitação para envio via solicitações http |
| fingir. Contrato | Formatos de anotação suportados | O padrão é a anotação do SpringMVC |
| fingir. Nova tentativa | Mecanismo de repetição de falha | O mecanismo de repetição para falha de solicitação, o padrão é não, mas a repetição da faixa de opções será usada |
Em circunstâncias normais, o valor padrão é suficiente para nós usarmos. Se você quiser customizá-lo, você só precisa criar um @Bean personalizado para substituir o Bean padrão.
O exemplo a seguir usa logs como exemplo para demonstrar como personalizar a configuração.
7.2.1. Método de arquivo de configuração
Modificar o nível de log do feign com base no arquivo de configuração pode direcionar um único serviço:
feign:
client:
config:
userservice: # 针对某个微服务的配置
loggerLevel: FULL # 日志级别
Também é possível segmentar todos os serviços:
feign:
client:
config:
default: # 这里用default就是全局配置,如果是写服务名称,则是针对某个微服务的配置
loggerLevel: FULL # 日志级别
O nível de log é dividido em quatro tipos:
- NONE: Não registra nenhuma informação de log, que é o valor padrão.
- BÁSICO: Registre apenas o método de solicitação, URL, código de status de resposta e tempo de execução
- CABEÇALHOS: Com base no BASIC, as informações do cabeçalho da solicitação e resposta são gravadas adicionalmente
- COMPLETO: registre detalhes de todas as solicitações e respostas, incluindo informações de cabeçalho, corpo da solicitação e metadados.
7.2.2, método de código Java
Você também pode modificar o nível de log com base no código Java, primeiro declarar uma classe e, em seguida, declarar um objeto Logger.Level:
public class DefaultFeignConfiguration {
@Bean
public Logger.Level feignLogLevel(){
return Logger.Level.BASIC; // 日志级别为BASIC
}
}
Se você quiser ter efeito globalmente , coloque-o na anotação @EnableFeignClients da classe de inicialização:
@EnableFeignClients(defaultConfiguration = DefaultFeignConfiguration .class)
Se for localmente efetivo , coloque-o na anotação @FeignClient correspondente:
@FeignClient(value = "userservice", configuration = DefaultFeignConfiguration .class)
Resumir:
Configuração do log do Feign:
-
A primeira maneira é configurar o arquivo, feign.client.config.xxx.loggerLevel
- Se xxx for o padrão, significa global
- Se xxx for um nome de serviço, como userservice, ele representa um serviço
-
A segunda maneira é configurar o Logger.Level Bean no código java
- Se declarado na anotação @EnableFeignClients, representa o global
- Se declarado na anotação @FeignClient, representa um serviço
7.3, Otimização de uso de simulação
A camada inferior do Feign inicia solicitações http e depende de outras estruturas. Sua implementação de cliente subjacente inclui:
-
URLConnection: implementação padrão, não suporta pool de conexões
-
Apache HttpClient: pool de conexões de suporte
-
OKHttp: pool de conexões de suporte
Portanto, otimizar o desempenho do Feign inclui principalmente:
- Use um pool de conexões em vez da URLConnection padrão
- nível de log, de preferência básico ou nenhum
Aqui usamos o HttpClient do Apache para demonstrar.
7.3.1. Apresentando dependências
Introduza a dependência HttpClient do Apache no arquivo pom de order-service:
<!--httpClient的依赖 -->
<dependency>
<groupId>io.github.openfeign</groupId>
<artifactId>feign-httpclient</artifactId>
</dependency>
7.3.2, configure o pool de conexão
Adicione a configuração em application.yml de order-service:
feign:
client:
config:
default: # default全局的配置
loggerLevel: BASIC # 日志级别,BASIC就是基本的请求和响应信息
httpclient:
enabled: true # 开启feign对HttpClient的支持
max-connections: 200 # 最大的连接数
max-connections-per-route: 50 # 每个路径的最大连接数
Resumir
-
Tente usar basic como o nível de log
-
Use HttpClient ou OKHttp em vez de URLConnection
-
Introduzir a dependência feign-httpClient
-
O arquivo de configuração habilita a função httpClient e define os parâmetros do pool de conexão
-
7.4. Melhores Práticas
A chamada prática recente refere-se à experiência somada durante o processo de uso, a melhor forma de utilizá-lo.
A observação do autoestudo mostra que o cliente de Feign é muito semelhante ao código do controlador do provedor de serviços:
fingir cliente:
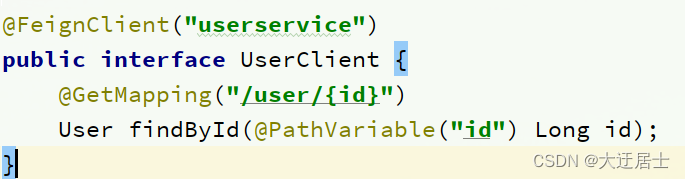
Controlador de usuário:
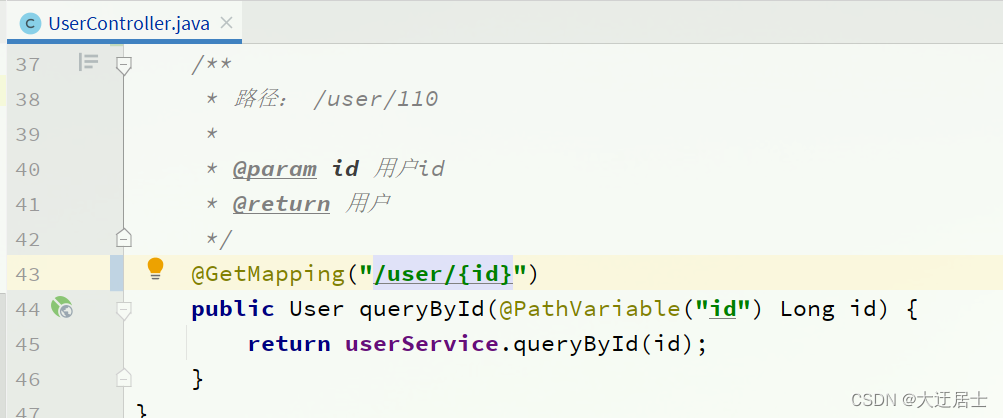
Existe uma maneira de simplificar essa codificação repetitiva?
7.4.1. Método de herança
O mesmo código pode ser compartilhado por herança:
1) Defina uma interface de API, use o método de definição e faça uma declaração com base nas anotações do SpringMVC.
2) Tanto o cliente Feign quanto o Controller integram a interface
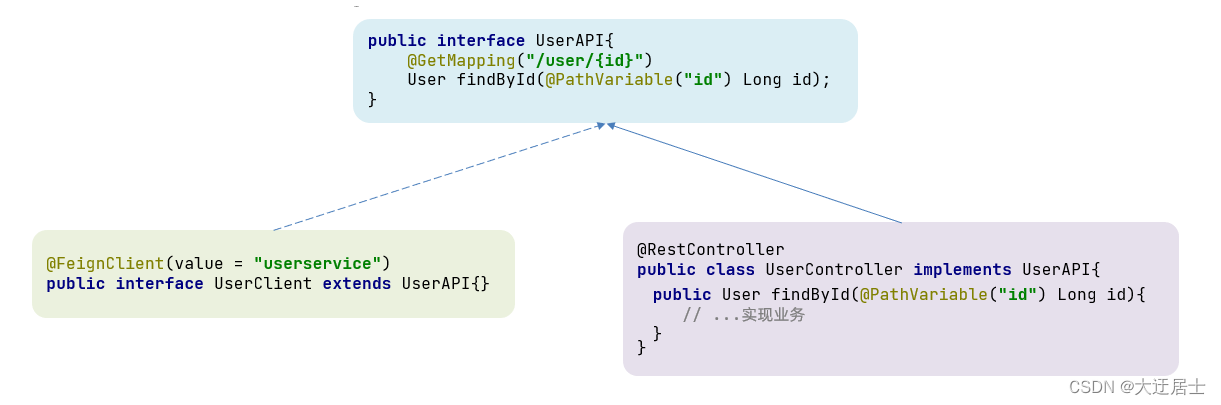
vantagem:
- Simples
- Compartilhamento de código
deficiência:
-
Provedor de serviço e consumidor de serviço estão fortemente ligados
-
O mapeamento de anotação na lista de parâmetros não será herdado, portanto, o método, a lista de parâmetros e a anotação devem ser declarados novamente no Controller
7.4.2. Método de extração
Extraia o Feign's Client como um módulo independente e coloque o POJO relacionado à interface e a configuração padrão do Feign neste módulo e forneça-o a todos os consumidores.
Por exemplo, as configurações padrão de UserClient, User e Feign são todas extraídas em um pacote feign-api e todos os microsserviços podem ser usados diretamente referenciando esse pacote de dependência.
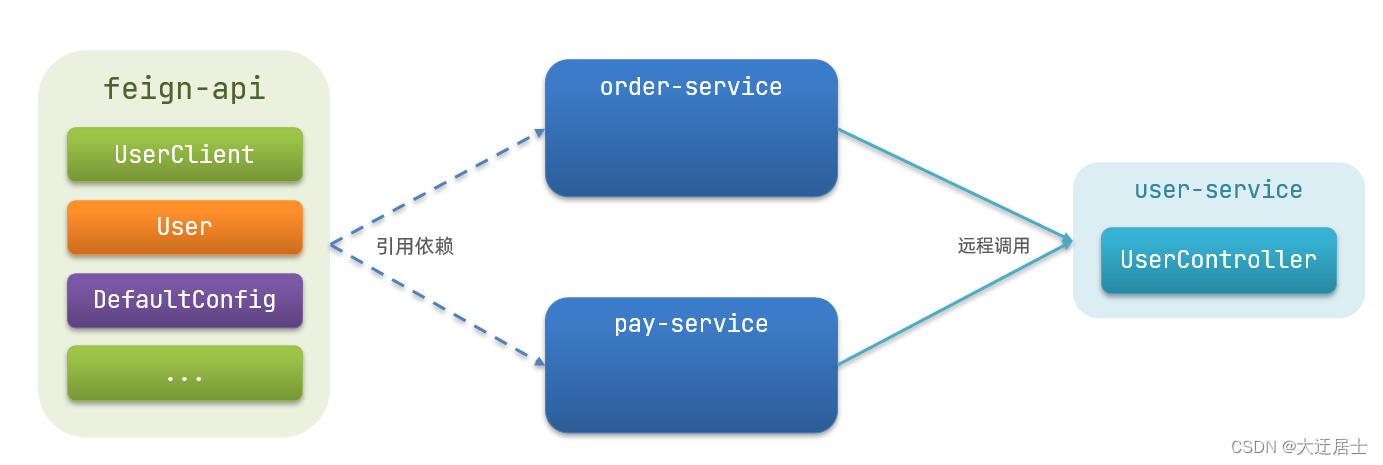
Resumir:
Práticas recomendadas para fingir:
- Deixe o controller e o FeignClient herdarem a mesma interface
- Defina a configuração padrão de FeignClient, POJO e Feign em um projeto para uso de todos os consumidores
7.4.3. Implementando as melhores práticas baseadas em extração
7.4.3.1. Extração
Primeiro crie um módulo chamado feign-api:
Em feign-api, introduza a dependência inicial de feign
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
Em seguida, UserClient, User e DefaultFeignConfiguration escritos em order-service são todos copiados para o projeto feign-api
7.4.3.2. Usando feign-api no serviço de pedidos
Primeiro, exclua classes ou interfaces como UserClient, User e DefaultFeignConfiguration em order-service.
Introduza a dependência de feign-api no arquivo pom de order-service:
<dependency>
<groupId>cn.test.demo</groupId>
<artifactId>feign-api</artifactId>
<version>1.0</version>
</dependency>
Modifique todas as partes de importação do pacote relacionadas aos três componentes acima no serviço de pedidos e altere-as para importar o pacote em feign-api
7.4.3.3, reinicie o teste
Após reiniciar, verificou-se que o serviço relatou um erro:
Isso ocorre porque o UserClient agora está no pacote cn.test.feign.clients,
A anotação @EnableFeignClients de order-service está no pacote cn.test.order, não no mesmo pacote, e UserClient não pode ser varrido.
7.4.3.4, Resolver o problema do pacote de digitalização
método um:
Especifique os pacotes que o Feign deve verificar:
@EnableFeignClients(basePackages = "cn.test.feign.clients")
Método 2:
Especifique a interface do cliente que precisa ser carregada:
@EnableFeignClients(clients = {
UserClient.class})
Existem duas maneiras de importar FeignClient de diferentes pacotes:
- Adicione basePackages na anotação @EnableFeignClients para especificar o pacote onde FeignClient está localizado
- Adicione clientes à anotação @EnableFeignClients para especificar o bytecode do FeignClient específico
Resumir:
As etapas para implementar o Método de Melhores Práticas 2 são as seguintes:
- Primeiro, crie um módulo chamado feign-api e, em seguida, introduza a dependência inicial do feign
- Copie UserClient, User e DefaultFeignConfiguration escritos em order-service para o projeto feign-api
- Introduza a dependência de feign-api em order-service
- Modifique todas as partes de importação relacionadas aos três componentes acima no serviço de pedido e altere-as para importar o pacote em feign-api
- teste de reinício
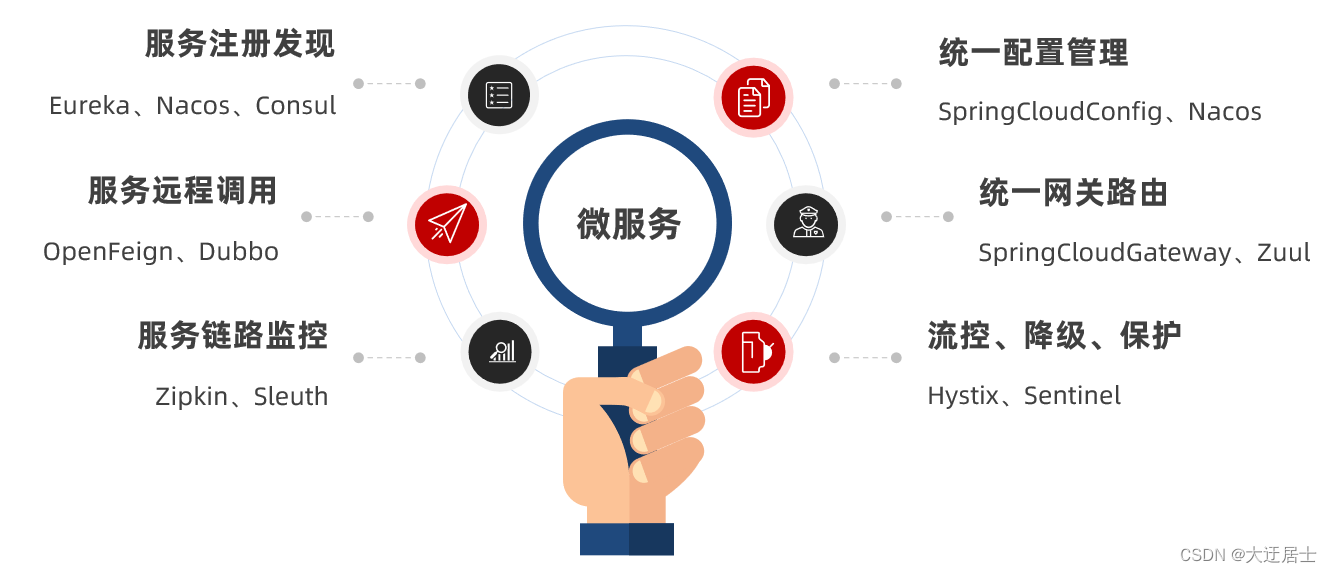
8. Gateway de Serviço de Gateway
O Spring Cloud Gateway é um novo projeto do Spring Cloud, que é um gateway desenvolvido com base no Spring 5.0, Spring Boot 2.0 e Project Reactor e outras tecnologias de programação reativa e fluxo de eventos. Visa fornecer um método de gerenciamento de rota de API unificado simples e eficaz.
8.1. Por que precisamos de um gateway
Gateway é o porteiro de nossos serviços, a entrada unificada de todos os microsserviços.
As principais características funcionais do gateway :
- roteamento de solicitação
- controle de acesso
- limitando
Diagrama de arquitetura:
![[Falha na transferência da imagem do link externo, o site de origem pode ter um mecanismo anti-leeching, é recomendável salvar a imagem e carregá-la diretamente (img-jD806LhV-1681478872549)(assets/image-20210714210131152.png)]](https://img-blog.csdnimg.cn/1fcb55f833d34a77b1095ba64519b2af.png)
Controle de acesso : como ponto de entrada dos microsserviços, o gateway precisa verificar se o usuário é elegível para a solicitação e, caso contrário, interceptá-lo.
Roteamento e balanceamento de carga : Todas as requisições devem primeiro passar pelo gateway, mas o gateway não processa o negócio, mas encaminha a requisição para um microsserviço de acordo com certas regras. Este processo é chamado de roteamento. Obviamente, quando há vários serviços de destino para roteamento, o balanceamento de carga também é necessário.
Limitação de corrente : Quando o tráfego de requisição é muito alto, o gateway irá liberar a requisição de acordo com a velocidade que o microsserviço downstream pode aceitar, de forma a evitar pressão excessiva de serviço.
Existem dois tipos de implementações de gateway no Spring Cloud:
- Porta de entrada
- zul
Zuul é uma implementação baseada em Servlet e pertence à programação de bloqueio. O Spring Cloud Gateway é baseado no WebFlux fornecido no Spring 5, que é uma implementação de programação responsiva e tem melhor desempenho.
Resumir:
O papel do gateway:
- Realizar autenticação de identidade e verificação de permissão em solicitações de usuários
- Encaminhe solicitações de usuários para microsserviços e implemente balanceamento de carga
- Limitar solicitações de usuários
8.2, início rápido do gateway
A seguir, demonstraremos a função básica de roteamento do gateway. Os passos básicos são os seguintes:
- Crie um gateway de projeto SpringBoot e introduza dependências de gateway
- Escrever classe de inicialização
- Escrever configuração básica e regras de roteamento
- Inicie o serviço de gateway para teste
8.2.1. Criar um serviço de gateway e introduzir dependências
Crie um serviço e introduza dependências:
<!--网关-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
<!--nacos服务发现依赖-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
8.2.2. Escrever classe de inicialização
@SpringBootApplication
public class GatewayApplication {
public static void main(String[] args) {
SpringApplication.run(GatewayApplication.class, args);
}
}
8.2.3. Escrever configuração básica e regras de roteamento
Crie um arquivo application.yml com o seguinte conteúdo:
server:
port: 10010 # 网关端口
spring:
application:
name: gateway # 服务名称
cloud:
nacos:
server-addr: localhost:8848 # nacos地址
gateway:
routes: # 网关路由配置
- id: user-service # 路由id,自定义,只要唯一即可
# uri: http://127.0.0.1:8081 # 路由的目标地址 http就是固定地址
uri: lb://userservice # 路由的目标地址 lb就是负载均衡,后面跟服务名称
predicates: # 路由断言,也就是判断请求是否符合路由规则的条件
- Path=/user/** # 这个是按照路径匹配,只要以/user/开头就符合要求
Faremos Pathproxy de todas as solicitações que correspondam às regras para urio endereço especificado pelo parâmetro.
Neste exemplo, fazemos proxy /user/**da solicitação inicial para, lb://userservicelb é o balanceamento de carga, extraímos a lista de serviços de acordo com o nome do serviço e realizamos o balanceamento de carga.
8.2.4, reinicie o teste
Reinicie o gateway, ao acessar http://localhost:10010/user/1, cumpre /user/**as regras, a requisição é encaminhada para uri: http://userservice/user/1, e o resultado é obtido:
8.2.5. Fluxograma de roteamento de gateway
Todo o processo de acesso é o seguinte:
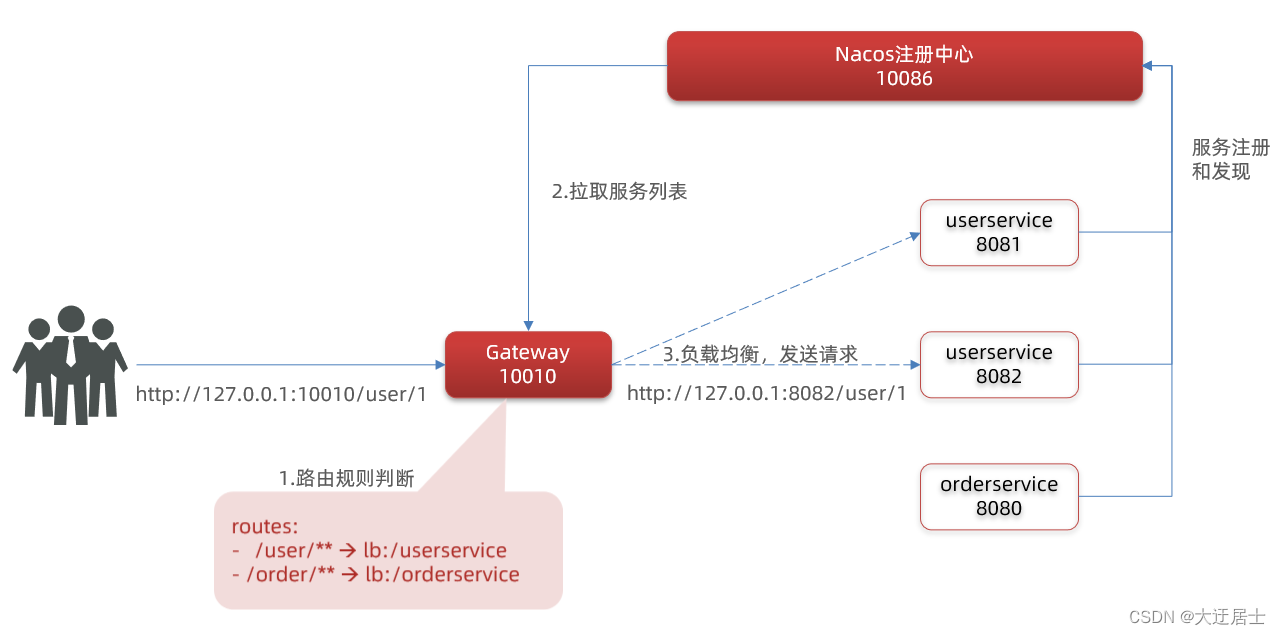
Resumir:
Etapas de construção do portal:
-
Crie um projeto, introduza a descoberta de serviços nacos e as dependências de gateway
-
Configurar application.yml, incluindo informações básicas de serviço, endereço nacos, roteamento
A configuração de roteamento inclui:
-
ID da rota: o identificador exclusivo da rota
-
Destino do roteamento (uri): o endereço de destino do roteamento, http significa endereço fixo, lb significa balanceamento de carga com base no nome do serviço
-
Asserções de roteamento (predicados): regras para julgar roteamento,
-
Filtros de rota (filtros): processar a solicitação ou resposta
8.3. Fábrica de asserções
O conteúdo que pode ser configurado na rota do gateway inclui:
- ID da rota: o identificador exclusivo da rota
- uri: destino de roteamento, suporta lb e http
- predicados: Asserção de roteamento, para julgar se a solicitação atende aos requisitos, se atender à solicitação, será encaminhada para o destino de roteamento
- filtros: filtros de roteamento, processamento de solicitações ou respostas
As regras de asserção que escrevemos no arquivo de configuração são apenas strings, que serão lidas e processadas pela Predicate Factory e transformadas em condições para julgamentos de roteamento
Por exemplo, Path=/user/** é correspondido de acordo com o caminho. Esta regra é determinada por
org.springframework.cloud.gateway.handler.predicate.PathRoutePredicateFactoryaula para
Para processamento, há mais de uma dúzia de fábricas de asserções como esta no Spring Cloud Gateway:
| nome | ilustrar | exemplo |
|---|---|---|
| Depois | é um pedido depois de um certo ponto no tempo | - Após=2037-01-20T17:42:47.789-07:00[América/Denver] |
| Antes | é um pedido antes de algum ponto no tempo | - Antes=2031-04-13T15:14:47.433+08:00[Ásia/Shanghai] |
| Entre | é uma solicitação antes de certos dois pontos no tempo | - Entre=2037-01-20T17:42:47.789-07:00[América/Denver], 2037-01-21T17:42:47.789-07:00[América/Denver] |
| Biscoito | As solicitações devem conter determinados cookies | - Biscoito=chocolate, cap. |
| Cabeçalho | As solicitações devem conter determinados cabeçalhos | - Cabeçalho=X-Request-Id, \d+ |
| Hospedar | A solicitação deve ser para acessar um determinado host (nome de domínio) | - Host= .somehost.org, .anotherhost.org |
| Método | O método de solicitação deve ser especificado | - Método=GET,POST |
| Caminho | O caminho da solicitação deve estar em conformidade com as regras especificadas | - Caminho=/vermelho/{segmento},/azul/** |
| Consulta | Os parâmetros da solicitação devem conter os parâmetros especificados | - Consulta=nome, Jack ou - Consulta=nome |
| RemoteAddr | O ip do solicitante deve estar no intervalo especificado | - RemoteAddr=192.168.1.1/24 |
| Peso | processamento de peso |
Precisamos apenas dominar a engenharia de roteamento do Path.
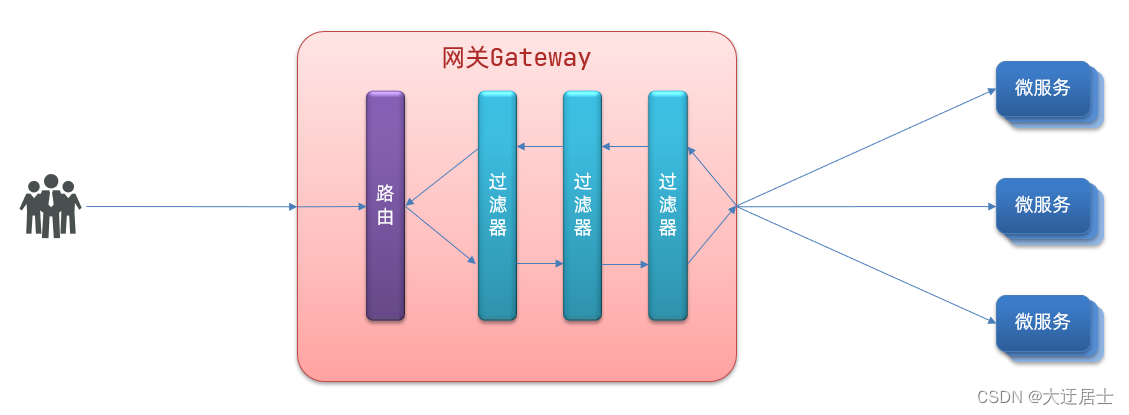
8.4. Fábrica de filtros
GatewayFilter é um filtro fornecido no gateway, que pode processar as solicitações que entram no gateway e as respostas retornadas pelos microsserviços:
8.4.1. Tipos de filtros de roteamento
O Spring fornece 31 fábricas de filtros de rota diferentes. Por exemplo:
| nome | ilustrar |
|---|---|
| AddRequestHeader | Adicionar um cabeçalho de solicitação à solicitação atual |
| RemoveRequestHeader | Remover um cabeçalho de solicitação da solicitação |
| AddResponseHeader | Adicione um cabeçalho de resposta ao resultado da resposta |
| RemoveResponseHeader | Há um cabeçalho de resposta removido do resultado da resposta |
| RequestRateLimiter | limitar a quantidade de pedidos |
8.4.2. Solicitar filtro de cabeçalho
Vamos usar AddRequestHeader como exemplo para explicar.
Requisito : Adicione um cabeçalho de solicitação a todas as solicitações que entrarem no userservice: Truth=test é incrível!
Basta modificar o arquivo application.yml do serviço de gateway e adicionar filtragem de rota:
spring:
cloud:
gateway:
routes:
- id: user-service
uri: lb://userservice
predicates:
- Path=/user/**
filters: # 过滤器
- AddRequestHeader=Truth, test is freaking awesome! # 添加请求头
O filtro atual está escrito na rota userservice, portanto, é válido apenas para solicitações de acesso a userservice.
8.4.3, filtro padrão
Se você quiser ter efeito para todas as rotas, você pode escrever a fábrica de filtros como padrão. O formato é o seguinte:
spring:
cloud:
gateway:
routes:
- id: user-service
uri: lb://userservice
predicates:
- Path=/user/**
default-filters: # 默认过滤项
- AddRequestHeader=Truth, test is freaking awesome!
8.4.4 Resumo
Qual é a função do filtro?
① Processe a solicitação ou resposta de roteamento, como adicionar um cabeçalho de solicitação
② O filtro configurado na rota só tem efeito para a solicitação da rota atual
Qual é o papel dos defaultFilters?
① Um filtro eficaz para todas as rotas
8.5. Filtro global
上次学习的过滤器,网关提供了31种,但每一种过滤器的作用都是固定的。如果我们希望拦截请求,做自己的业务逻辑则没办法实现。
8.5.1、全局过滤器作用
全局过滤器的作用也是处理一切进入网关的请求和微服务响应,与GatewayFilter的作用一样。区别在于GatewayFilter通过配置定义,处理逻辑是固定的;而GlobalFilter的逻辑需要自己写代码实现。
定义方式是实现GlobalFilter接口。
public interface GlobalFilter {
/**
* 处理当前请求,有必要的话通过{@link GatewayFilterChain}将请求交给下一个过滤器处理
*
* @param exchange 请求上下文,里面可以获取Request、Response等信息
* @param chain 用来把请求委托给下一个过滤器
* @return {@code Mono<Void>} 返回标示当前过滤器业务结束
*/
Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain);
}
在filter中编写自定义逻辑,可以实现下列功能:
- 登录状态判断
- 权限校验
- 请求限流等
8.5.2、自定义全局过滤器
需求:定义全局过滤器,拦截请求,判断请求的参数是否满足下面条件:
-
参数中是否有authorization,
-
authorization参数值是否为admin
如果同时满足则放行,否则拦截
实现:
在gateway中定义一个过滤器:
@Order(-1)
@Component
public class AuthorizeFilter implements GlobalFilter {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
// 1.获取请求参数
MultiValueMap<String, String> params = exchange.getRequest().getQueryParams();
// 2.获取authorization参数
String auth = params.getFirst("authorization");
// 3.校验
if ("admin".equals(auth)) {
// 放行
return chain.filter(exchange);
}
// 4.拦截
// 4.1.禁止访问,设置状态码
exchange.getResponse().setStatusCode(HttpStatus.FORBIDDEN);
// 4.2.结束处理
return exchange.getResponse().setComplete();
}
}
全局过滤器的作用是什么?
- 对所有路由都生效的过滤器,并且可以自定义处理逻辑
实现全局过滤器的步骤?
- 实现GlobalFilter接口
- 添加@Order注解或实现Ordered接口
- 编写处理逻辑
8.5.3、过滤器执行顺序
请求进入网关会碰到三类过滤器:当前路由的过滤器、DefaultFilter、GlobalFilter
请求路由后,会将当前路由过滤器和DefaultFilter、GlobalFilter,合并到一个过滤器链(集合)中,排序后依次执行每个过滤器:
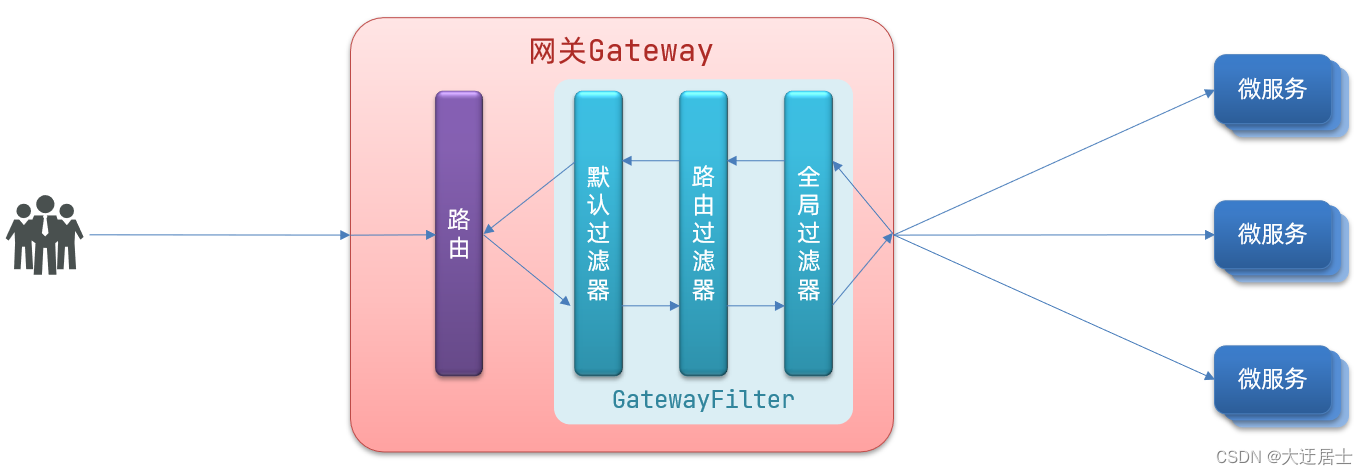
排序的规则是什么呢?
- 每一个过滤器都必须指定一个int类型的order值,order值越小,优先级越高,执行顺序越靠前。
- GlobalFilter通过实现Ordered接口,或者添加@Order注解来指定order值,由我们自己指定
- 路由过滤器和defaultFilter的order由Spring指定,默认是按照声明顺序从1递增。
- 当过滤器的order值一样时,会按照 defaultFilter > 路由过滤器 > GlobalFilter的顺序执行。
Para obter detalhes, você pode ver o código-fonte:
org.springframework.cloud.gateway.route.RouteDefinitionRouteLocator#getFilters()O método é carregar os defaultFilters primeiro, depois carregar os filtros de uma determinada rota e depois mesclá-los.
org.springframework.cloud.gateway.handler.FilteringWebHandler#handle()O método carregará o filtro global, classificará de acordo com a ordem após mesclar com o filtro anterior e organizará a cadeia de filtros
Resumo:
ordem de execução do filtro de roteamento, defaultFilter e filtro global?
- Quanto menor o valor do pedido, maior a prioridade
- Quando o valor do pedido é o mesmo, o pedido é o defaultFilter primeiro, depois o filtro de roteamento local e, finalmente, o filtro global
8.6. Problemas entre domínios
8.6.1. O que é um problema entre domínios
Entre domínios: nomes de domínio inconsistentes são entre domínios, incluindo principalmente:
-
Nomes de domínio diferentes: www.taobao.com e www.taobao.org e www.jd.com e miaosha.jd.com
-
Mesmo nome de domínio, portas diferentes: localhost:8080 e localhost8081
Problema entre domínios: o navegador proíbe o originador da solicitação de fazer uma solicitação ajax entre domínios com o servidor e a solicitação é interceptada pelo navegador
Solução: CORS, isso já deveria ter sido aprendido antes, então não vou repetir aqui. Amigos que não sabem podem conferir https://www.ruanyifeng.com/blog/2016/04/cors.html
8.6.2. Simulação de problemas entre domínios
Acesse localhost:10010 de localhost:8090, a porta é diferente, obviamente é uma solicitação entre domínios.
8.6.3. Resolver problemas entre domínios
No arquivo application.yml do serviço de gateway, adicione a seguinte configuração:
spring:
cloud:
gateway:
# 。。。
globalcors: # 全局的跨域处理
add-to-simple-url-handler-mapping: true # 解决options请求被拦截问题
corsConfigurations:
'[/**]':
allowedOrigins: # 允许哪些网站的跨域请求
- "http://localhost:8090"
allowedMethods: # 允许的跨域ajax的请求方式
- "GET"
- "POST"
- "DELETE"
- "PUT"
- "OPTIONS"
allowedHeaders: "*" # 允许在请求中携带的头信息
allowCredentials: true # 是否允许携带cookie
maxAge: 360000 # 这次跨域检测的有效期
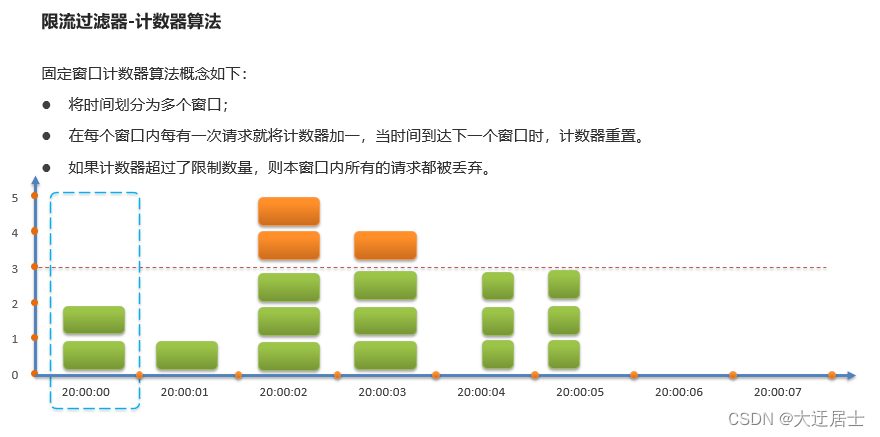
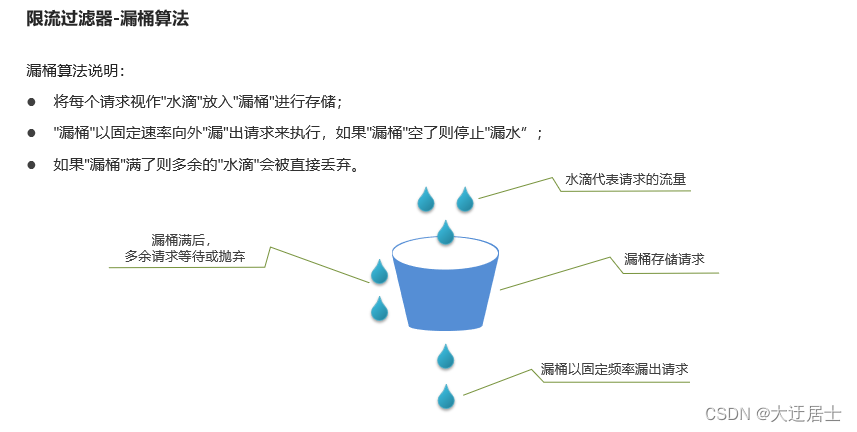
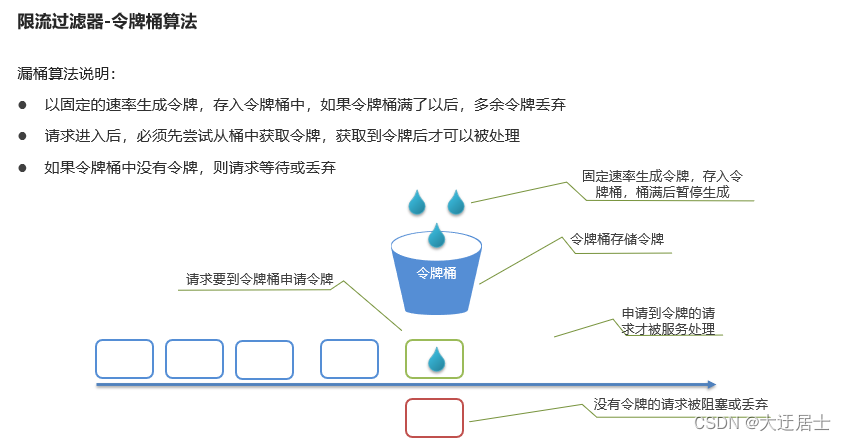
8.7. Filtro limitador
Limitação de corrente: Limite as requisições do servidor de aplicação para evitar sobrecarga ou mesmo indisponibilidade do servidor por excesso de requisições. Existem dois algoritmos comuns de limitação de corrente:
- Algoritmo de contador, incluindo algoritmo de contador de janela, algoritmo de contador de janela deslizante
- Balde Furado
- Algoritmo do Token Bucket (Token Bucket)