
Convidado compartilhado | Liu Huanyong
Arranjo manuscrito | William
1. Observando a origem e a essência do ChatGPT a partir de um modelo de linguagem em larga escala
O ChatGPT pode ser dividido em Chat e GPT para entender. O primeiro representa um formulário de inscrição e o último é um modelo generativo. É definido na Enciclopédia Baidu como ChatGPT é uma ferramenta de processamento de linguagem natural impulsionada pela tecnologia de inteligência artificial. Ele pode conduzir conversas aprendendo e compreendendo a linguagem humana e também pode interagir de acordo com o contexto do bate-papo. Converse e se comunique como humanos e pode até mesmo escrever alguns e-mails, scripts de vídeo, copywriting, tradução, código, escrever papéis e outras tarefas. No momento, todos estão fazendo interpretações e algumas suposições, e não há relatórios ou papéis oficiais. Alguns termos-chave aqui precisam ser entendidos primeiro:

Figura 1 Termos-chave
O ChatGPT é essencialmente um modelo de processamento de linguagem natural baseado no GPT, usando um transformador para prever a distribuição de probabilidade da próxima palavra e, em seguida, aprendendo esse padrão em um corpus de texto em grande escala. A inteligência de GPT1 para GPT3 está melhorando constantemente. Naquela época, GPT1 tinha apenas 117 milhões de parâmetros, depois GPT2 se tornou 1,5 bilhão de parâmetros e GPT3 atingiu 175 bilhões. Até mais tarde, começamos a ajustar as instruções por causa da qualidade gerada Às vezes não é particularmente bom, deixe-o obedecer o máximo possível a um critério de 600H, ou seja, aprender mais habilidades e melhorar seus resultados por meio do aprendizado por feedback.
O desenvolvimento e as mudanças de todo o ChatGPT são mudanças na série de transformadores como um todo. Ao executar tarefas de NLP desde 1950, é uma pequena quantidade de processamento de dados com base em regras e, em seguida, o aprendizado de máquina é usado para classificar os parâmetros de acordo com um determinado intervalo de dados. Mais tarde, a CNN é usada para codificação para representar recursos e, em seguida, é descoberto que a atenção multifacetada A capacidade de codificação da força é obviamente mais forte que a da rede neural e, em seguida, é dividida em três rotas: uma é a série GPT, que é basicamente uma iteração por ano, a segunda é T5 e o terceiro é BERT. Atualmente, as duas principais são mostradas na Figura 2. A única diferença entre as duas arquiteturas reside na camada de entrada, cada uma delas relacionada apenas às anteriores, de modo que as informações contextuais podem ser totalmente capturadas, facilitando a entender.
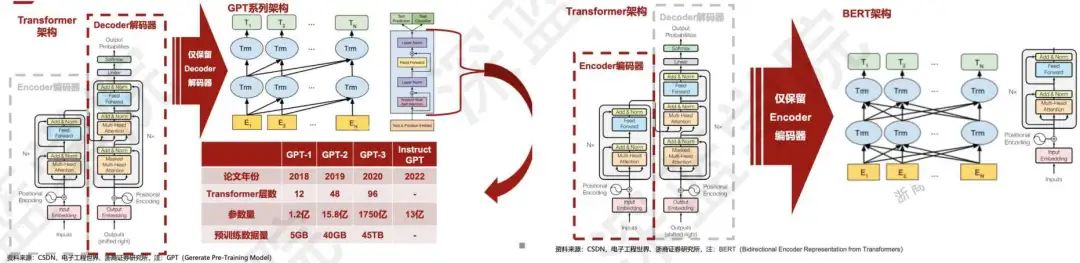
Figura 2 Duas arquiteturas convencionais
Quando você experimenta o ChatGPT, seu princípio de funcionamento interno é um método comparativo. Por exemplo, deixe o ChatGPT escrever um artigo. É essencialmente uma maneira de repetir qual deve ser a próxima palavra no texto atual e calcular aquela com maior probabilidade. Finalmente , para concluir a tarefa. Na verdade, isso é controlado por uma probabilidade, mas a essência dessa probabilidade é controlada por um modelo de linguagem.
Não sei o que escrevi, mas estou muito confiante de que a palavra seguinte tem a maior probabilidade de corresponder à palavra anterior.
Portanto, isso leva a um absurdo sério que pode ser visto no atual ChatGPT.
Vamos dar uma olhada no GPT1 da série GPT primeiro.Na verdade, é um pré-treinamento multitarefa de uso geral para criar um paradigma de ajuste fino. Comparado com o transformador, ele fez mudanças significativas. O primeiro aspecto é que apenas um decodificador de 12 camadas é treinado. O segundo é que, comparado ao BERT do Google, ele realmente usa apenas as previsões acima e não verá informações contextuais. Portanto, apenas a parte do decodificador é usada e sua estrutura é simples o suficiente para executar bem a compreensão da linguagem e é adequada para o campo de geração de texto, mas há defeitos relativamente grandes na linguagem geral e na comunicação conversacional.
O GPT2 fez muitas melhorias com base no GPT1. A primeira é que há mais fontes de informação e os dados de todo o fluxo de dados foram expandidos para 40G. A segunda é que o número de camadas aumentou para 48 , e a dimensão da camada oculta aumentou para 1600, atingindo 1,5 bilhão de parâmetros. A terceira é não mais ajustar a modelagem para diferentes tarefas e apenas modelá-la como uma tarefa de classificação. Mas também existem alguns problemas. Em primeiro lugar, do ponto de vista prático, cada nova tarefa requer grandes dados rotulados, o que limita a aplicabilidade do modelo de linguagem. O segundo aspecto é a forma de pré-treinamento e ajuste entre Com eles, a capacidade de generalização será relativamente baixa. A terceira razão é que o aprendizado humano não requer grandes conjuntos de dados supervisionados, portanto, na verdade, existem certas limitações neste conceito.
Para resolver esses problemas, o GPT3 usou a ideia de aprendizado em contexto para fazer o modelo obter melhores resultados e, em seguida, produziu mais dados, puxando diretamente os parâmetros para uma escala de 175B.
2. Vários problemas técnicos importantes, projetos de código aberto e desafios de implementação do ChatGPT
2.1 O algoritmo central e os dados centrais do ChatGPT
O feedback humano é adicionado ao Instruct-GPT para orientar, então por que precisamos adicionar esse feedback? Porque existem alguns problemas com o GPT3 no momento, incluindo qualidade de geração desigual, fácil de produzir alguns resultados fluentes, mas inúteis ou mesmo prejudiciais, e baixa capacidade de compreensão de tiro zero. No entanto, simplesmente aumentar o tamanho do modelo de linguagem não pode resolver esses problemas, portanto, o aprendizado por reforço com feedback humano é necessário para o ajuste fino.
O ajuste fino inclui estas etapas: primeiro, alguns dados de ajuste fino são fornecidos, depois o modelo de recompensa é treinado e, em seguida, o aprendizado por reforço otimiza o STF e itera. No entanto, há muitas maneiras de as pessoas darem feedback. A primeira é marcar os prompts necessários e a outra é deixar o modelo classificar a qualidade dos resultados gerados e, em seguida, usar o aprendizado por reforço para guiar o modelo para uma direção melhor .
O Instruct-GPT é treinado com base no aprendizado por reforço do feedback humano. A Figura 3 mostra todo o processo com muita clareza. Existem três estágios principais aqui: o primeiro estágio é um modelo de estratégia de inicialização a frio, que extrai aleatoriamente instruções ou perguntas enviadas pelos usuários (ou seja, prompt ) e, em seguida, rotular manualmente, usar esses prompts especificados e respostas de alta qualidade para ajustar o modelo GPT3 para torná-lo o mais adequado possível para gerar um modelo; o segundo estágio é o estágio de recompensa de treinamento, pontuando a saída resultados do modelo pré-treinamento, quanto maior a pontuação, melhor a qualidade da resposta; a terceira etapa é usar o aprendizado por reforço para aumentar a capacidade do modelo pré-treinamento, o que equivale a retroalimentar a pontuação para o STF original para permitir que o modelo gere respostas de maior qualidade.
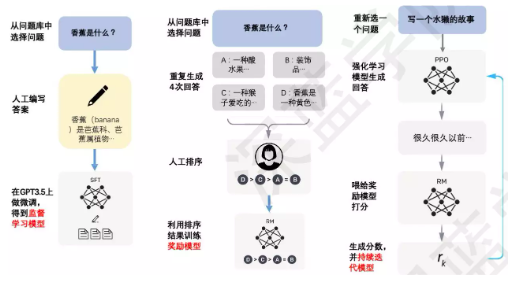
Figura 3 Processo Instruct-GPT
O aprendizado supervisionado SFT, como um algoritmo central no GPT, coleta principalmente o conjunto de dados de como o modelo esperado escrito manualmente é gerado, para que possa ser usado para treinar um modelo generativo. Os dados usados são um par de prompt e resposta. Parte da coleta desse conjunto de dados vem de usuários que usam o openAI e, por outro lado, virá de alguns engenheiros do openAI que os escreveram e contrataram anotadores. Na verdade, se você quiser fazer isso, há várias opções. Primeiro, você pode coletar dados do Baidu Zhizhi ou fóruns, mas precisa examiná-los cuidadosamente. Segundo, algumas pessoas na empresa têm algum conhecimento e requisitos para o código A terceira maneira menos econômica é contratar algumas pessoas para obter o conjunto de dados. ,
Outro algoritmo central é o modelo de recompensa, que na verdade é uma coleção de conjuntos de dados classificados entre várias saídas do modelo rotulado manualmente. Use o modelo de ajuste fino SFT para fazer previsões e obter resultados N para a saída. Os dados classificados são usados para treinar o modelo de recompensa, e a função de perda também é calculada com base nos resultados da seleção manual. perda de pares. Etapas específicas: a primeira etapa é gerar um modelo SFT, gerar aleatoriamente K candidatos para cada prompt, a segunda etapa é selecionar dois candidatos e formar uma tupla com o prompt e executar a expansão C(K,2) para gerar mais rotulados dados; a terceira etapa é classificar e pontuar os dois candidatos de acordo com a qualidade; a quarta etapa é enviar o grupo C(K,2) gerado de dados de treinamento como um lote para o modelo RM para treinamento pareado. Como a entrada da função de perda é uma tupla, a saída é a diferença entre as duas recompensas candidatas com valor sigmoide e, em seguida, logaritmo, portanto, pode ser considerado um modelo de regressão.
O último algoritmo central é o aprendizado por reforço PPO, que usa o modelo de recompensa como função de recompensa para ajustar o modelo gerado pelo aprendizado supervisionado na forma de PPO. Cada etapa calcula a divergência KL entre o modelo gerado treinado na primeira etapa. O objetivo é desviar do modelo de geração original sem aprendizado por reforço. A função de perda é a seguinte:
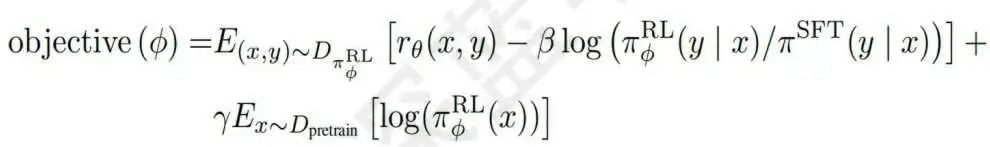
As etapas específicas são as seguintes: a primeira etapa é inicializar o modelo de estratégia PPO pelo modelo SFT ajustado e inicializar a função de valor pelo modelo RM gerado. A segunda etapa é amostrar aleatoriamente uma solicitação do conjunto de dados PPO e gerar um resultado de saída por meio do modelo de estratégia PPO da primeira etapa; a terceira etapa é trazer a solicitação e o resultado para o modelo RM para calcular o valor da recompensa recompensa; a quarta etapa é usar a recompensa Para atualizar os parâmetros do modelo de política PPO. Por fim, repita as etapas 2 a 4 até que o modelo de estratégia PPO converja
Em seguida, vamos falar sobre alguns problemas nos dados de treinamento. GPT3 é treinado em um total de 300B tokens, 60% dos quais vêm do rastreamento comum e outros incluem webtext2, books1, books2 e Wikipedia. Mas não é que quanto mais coisas nos dados, melhor, é mais inclinado para a qualidade dos dados.Se a qualidade for maior, o efeito será bom. Portanto, ao fazer dados de treinamento GPT3, há um conjunto de trabalho de engenharia de dados, incluindo três estágios de classificação de dados, como lavar dados e como buscar dados. A outra é desduplicar o conjunto de dados. A desduplicação ajuda a evitar que o modelo pré-treinado se lembre ou superajuste nos mesmos dados depois de enfrentar os mesmos dados muitas vezes, ajudando assim a melhorar a capacidade de generalização do modelo. Há outro aspecto da diversidade, incluindo diversidade de domínio, diversidade de formato e diversidade de idioma, incluindo tanto quanto possível uma variedade de dados.
Os dados de treinamento GPT3 têm um processo de processamento e limpeza. O primeiro é filtrar os dados do rastreador com base na comparação de similaridade com uma série de corpora de referência de alta qualidade. O outro é filtrar os documentos dentro do conjunto de dados e entre conjuntos de dados. A desduplicação é executado e, finalmente, um corpus de referência conhecido de alta qualidade é adicionado ao mix de treinamento para aumentar a diversidade do conjunto de dados.
A distribuição após a limpeza é mostrada na Figura 4.

Figura 4 Distribuição do conjunto de dados para treinamento GPT3
Como a proporção da entonação chinesa no GPT3 não é muito alta, por que o efeito mostrado em chinês é melhor do que alguns modelos grandes na China? A questão que surge disso é como adquirir a capacidade multilíngue do GPT? A partir dos dados oficiais do PPT, podemos ver que o chinês representa apenas 0,12% do número de documentos e, para a palavra inteira, representa 0,1%. Então, isso significa que muitas coisas em inglês foram registradas melhor? Sim, e então, durante o treinamento, o modelo fez automaticamente o alinhamento da tradução. Claro, isso é apenas um palpite.
A segunda é a capacidade de desenho da tabela. Ao usar o GPT, você pode descobrir que as coisas subjacentes são escritas na remarcação por meio da depuração. Se você usar esse código, poderá descobrir no código-fonte que ele usará alguns comentários oficiais ou algumas funções. Definida como uma pergunta, a resposta pode ser uma pergunta de função uma a uma e, em seguida, um grande número de conjuntos de dados pode ser gerado dessa maneira e depois treinado.
Outro ponto central é a construção de dados RLFH. O primeiro é controlar rigorosamente a qualidade da população rotulada e o segundo é rotular a fonte de dados. Esses dados incluem três tipos de dados. O primeiro é escrito manualmente, incluindo alguns aleatórios prompts, e ao mesmo tempo garantir a diversidade de tarefas, tanto quanto possível.Em segundo lugar, não só precisa escrever alguns prompts, mas também precisa escrever a resposta correspondente.O terceiro é projetar de acordo com um caso de uso. Depois, há três critérios de marcação: útil, verdadeiro e inofensivo. Ao rotular, três conjuntos de dados são marcados, um é o conjunto de dados SFT, que tem apenas cerca de 13K, o outro são dados RM, principalmente o prompt real, que tem cerca de 33K, e o último é o conjunto de dados PPO, que é prompt completamente real, baseado em 10 tipos diferentes de tarefas de geração fornecidas por diferentes usuários, com um total de 31K.
2.2 Algumas reflexões sobre o poder de computação, equipe e tecnologia do ChatGPT
Talvez todos se perguntem quanto custa o ChatGPT? A Guosheng Securities emitiu um relatório antes de que o custo do treinamento ChatGPT é de cerca de 1,4 milhão de dólares americanos. Para alguns modelos maiores, pode custar entre 2 milhões de dólares americanos e 12 milhões de dólares americanos. Com base no número médio de visitantes únicos do ChatGPT em janeiro de 13 milhões, a demanda de chip correspondente é de mais de 30.000 GPUs NVIDIA A100, o custo de investimento inicial é de cerca de 800 milhões de dólares americanos e o custo diário de eletricidade é de cerca de 50.000 dólares americanos. Se o ChatGPT atual for implantado em todas as pesquisas feitas pelo Google, serão necessários 512820,51 servidores A100 HGX e um total de 4102568 GPUs A100, e o custo total desses servidores e redes é superior a US$ 100 bilhões apenas em CAPEX. Uma série de processos de engenharia, como agrupamento de dados, limpeza e rotulagem manual no lado dos dados, também exige grande investimento.
A equipe openAI por trás dele é líder global em IA e também possui produtos para outras tarefas multimodais. A OpenAI foi criada no final de 2015. O objetivo da organização é abrir patentes e resultados de pesquisas ao público por meio de "cooperação livre" com outras instituições e pesquisadores. Em 2019, a OpenAI passou de uma organização sem fins lucrativos para uma organização com fins lucrativos "limitada", com um limite de lucro de 100 vezes qualquer investimento.
Vamos ver por que o ChatGPT é eficaz? O primeiro é o valor do ajuste fino da instrução, ele não vai injetar novos recursos no modelo, ou seja, como a qualidade do modelo determina diretamente o resultado do ChatGPT, e o segundo ponto é que ele será diferenciado em diferentes habilidades árvores, como aprendizado de contexto, diálogo, etc. Então, a capacidade de responder a comandos humanos também é um produto do ajuste fino de comando. Além disso, a rastreabilidade do modelo, incluindo capacidade de geração de linguagem, conhecimento básico do mundo e aprendizado de contexto, tudo vem do modelo pré-treinado. Além disso, a capacidade de seguir instruções e generalizar para novas tarefas vem da expansão do número de instruções no aprendizado de instruções. Além disso, a capacidade do modelo de executar raciocínio complexo provavelmente vem do treinamento de código.
Por que não Chat-BERT? Este tipo de AE (Auto Encoder) do BERT coopera com a tarefa de pré-treinamento do Mask LM. Embora possa ver melhor o acima e o abaixo, também há uma lacuna entre o treinamento e a inferência, porque o AR a arquitetura está muito em conformidade com o processo de pensamento e resposta humanos, está em conformidade com o "primeiro princípio" e pode responder a muitas perguntas.
O InstructGPT trouxe alguns benefícios, em primeiro lugar, seu efeito será mais realista e, em seguida, sua inofensividade será aprimorada e possui uma capacidade de codificação muito poderosa. Claro, também existem algumas desvantagens. Primeiro, reduzirá o efeito do modelo em tarefas gerais de PNL. Segundo, dará uma saída absurda, porque a tarefa do modelo de linguagem supervisionada que mais afeta o efeito do modelo, os humanos só jogam uma função corretiva. , portanto, é provável que seja limitado pelos dados de correção limitados, resultando em conteúdo gerado falso. A terceira é que ela é muito sensível aos indicadores, principalmente devido à quantidade insuficiente de dados rotulados pelo rotulador. A quarta é uma interpretação exagerada de conceitos simples, provavelmente porque o rotulador tende a dar maiores recompensas a um conteúdo de saída mais longo ao comparar o conteúdo gerado. O último ponto é que instruções prejudiciais podem gerar respostas prejudiciais.
Existem três direções principais para a melhoria posterior do Chat-GPT: primeiro, a redução de custos e o aumento da eficiência da anotação manual, como permitir que humanos forneçam métodos de feedback mais eficazes e a combinação orgânica e engenhosa de desempenho humano e desempenho do modelo são muito importante. O segundo ponto é a capacidade do modelo de generalizar e corrigir instruções.Como melhorar a capacidade de generalização do modelo e a capacidade de corrigir instruções de erro é uma tarefa muito importante para melhorar a experiência do modelo. O terceiro ponto é evitar a degradação do desempenho de tarefas gerais.Aqui pode ser necessário projetar uma maneira mais razoável de usar o feedback humano ou uma estrutura de modelo mais avançada.
Na verdade, além dos problemas mencionados agora, o que mais me deixa insatisfeito agora é a pontualidade e a precisão, o que leva diretamente ao absurdo. O Bing apareceu e resolveu esse problema até certo ponto. Como ele o resolve? O primeiro ponto é que ele integrará a pesquisa do Bing, agregará todas as respostas relevantes e fará alguns resumos e classificações; o segundo método é resolver a pontualidade e pesquisar rapidamente as perguntas publicadas atualmente.
2.3 Implementação do ChatGPT, análise, detecção, projetos de código aberto relacionados a aplicativos
Primeiro, uma estrutura de implementação de baixo custo é o ColossIAI, que propõe um processo de implementação equivalente ao ChatGPT de código aberto e de baixo custo, fornecendo código de treinamento ChatGPT pronto para uso. O endereço está em https://github.com/hpcaitech/ColossalAI. Também inclui a implementação de código aberto do RLHF, para sentir como e o que deve ser marcado nos dados. Existe também o PaLM-rlhf-pytorch, que implementa RLHF (human feedback reforço learning) em cima da arquitetura PaLM, basicamente equivalente ao ChatGPT, a diferença é o uso do PaLM, endereço do projeto: https://github.com /lucidrains/PaLM-rlhf-pytorch.
Há também um projeto ChatGPT-Comparison-Detection. Ao coletar dezenas de milhares de dados comparativos de perguntas e respostas de especialistas humanos e ChatGPT, o corpus comparativo HumanChatGPT estuda as características das respostas do ChatGPT, bem como as diferenças e a lacuna, e o detector ChatGPT é fornecido, o endereço do projeto está no endereço do projeto: https://github.com/Hello-SimpleAI/chatgpt-comparison-detection. Depois, houve algumas descobertas surpreendentes: primeiro, as respostas do ChatGPT geralmente se concentravam estritamente nas perguntas dadas, enquanto as respostas artificiais eram divergentes e facilmente voltadas para outros tópicos. Em segundo lugar, o ChatGPT fornece respostas objetivas, enquanto os humanos preferem expressões subjetivas. Em terceiro lugar, as respostas do ChatGPT são geralmente formais, enquanto as respostas humanas são mais coloquiais. Os humanos também adoram usar humor, sarcasmo, metáforas e exemplos, enquanto o ChatGPT nunca usa ironia. Por fim, o ChatGPT expressa menos emoção em suas respostas, enquanto os humanos selecionam muitos recursos de pontuação e gramaticais no contexto para transmitir seus sentimentos.
Existem também alguns projetos de código aberto orientados a aplicativos que executam diretamente algumas tarefas de NLP. O primeiro é unlocking-the-power-of-llms, o endereço do projeto é https://github.com/howl-anderson/unlocking-the-power-of-llms. Este projeto envolve principalmente a operação de aprimoramento de dados da expansão do corpus e também pode realizar a limpeza do corpus, corrigir erros de dados e fornecer instruções para cada correção. Existem também alguns projetos de aplicativos de prompt. Devido à mesma tarefa, prompts diferentes trarão efeitos diferentes, portanto, como encontrar um prompt para uma tarefa específica é muito importante. O endereço do projeto está no endereço do projeto: https://github. com/f /awesome-chatgpt-prompts. Existem alguns outros projetos de código aberto do lado do aplicativo, conforme mostrado na Figura 5.

Figura 5 Outros projetos de software livre relacionados ao lado do aplicativo
3. A direção de relacionamento e combinação de ChatGPT, NLP e KG
3.1 ChatGPT e NLP: visão geral básica dos modelos de pré-treinamento
O modelo de pré-treinamento é, na verdade, um conceito derivado do aprendizado de transferência. Ele usa modelos grandes e grande poder de computação para utilizar dados não rotulados ou fracamente rotulados. Ele também tem a capacidade de aprendizado de poucas amostras e zero amostras e também pode executar multi- interação modal. A arquitetura de linguagem do NLP é mostrada na Figura 6.
Figura 6 Arquitetura do Processamento de Linguagem Natural NLP
O modelo de linguagem pré-treinado é baseado em dados não rotulados em grande escala. O aprendizado automático do modelo de linguagem geral é forte em generalização e pode ser usado para uma variedade de tarefas posteriores. O aprendizado de transferência usa o "pré-treinamento-ajuste fino "framework para alcançar" transferência de conhecimento de aquisição de conhecimento, incluindo recurso Existem dois tipos de migração de representação e migração de parâmetro e, em seguida, incluem aprendizagem auto-supervisionada de imagens.
O próprio modelo de linguagem resolve o problema de representação de linguagem. No início, one-hot é usado para representação e, posteriormente, o modelo grande é usado para substituir a camada de codificação de recursos intermediária para fazer uma representação distribuída e, em seguida, executar algumas tarefas posteriores A evolução é mostrada na Figura 7. mostrada.

Figura 7 Evolução da representação de linguagem para processamento de linguagem natural
O núcleo do modelo de linguagem é a maximização de toda a probabilidade, ou seja, a probabilidade de estimar a geração da próxima palavra no texto. Mas há um grande problema, a quantidade de excesso é grande e o contexto é particularmente grande, e haverá um estado não adquirido, então me pergunto se posso usar o modelo para aprender o modelo de contexto. No início, baseava-se na representação simbólica, depois passou a fazer modelos estatísticos de linguagem, decompondo o texto da matriz, podemos obter o modelo bag-of-words para fazer isso. A incorporação é usada posteriormente, e um vetor denso, contínuo e de baixa dimensão é usado diretamente para representar palavras. Outro é o modelo NNLM, que pode gerar alguns modelos modelando modelos de linguagem. O ELMO pode obter uma solução para o problema de vetores de palavras dinâmicas, treinar o modelo de linguagem direta e o modelo de linguagem reversa, respectivamente, e resolver a forma de polissemia de uma palavra.
Atualmente, o modelo de linguagem pré-treinado tornou-se um novo paradigma para o processamento de NLP.Primeiro, construa algumas tarefas de sinalizador e, em seguida, use os dados do sinalizador como um contraste. Atualmente, o ajuste de prompt é popular e você pode escolher diferentes prompts para diferentes tarefas.
Para resolver o problema da unificação do NLP até certo ponto, mas há um grande problema na construção do modelo. A estrutura do modelo é diferente e os resultados gerados serão diferentes. O núcleo do modelo de linguagem pré-treinado é o tarefa de aprendizagem auto-supervisionada.
3.2 ChatGPT e KG: um modelo de linguagem pré-treinado que integra gráficos de conhecimento
Gráfico de conhecimento: Uma base de conhecimento baseada em relacionamentos binários, usada para descrever entidades ou conceitos no mundo real e seus relacionamentos, a unidade básica é o trio [entidade-relacionamento-entidade]. Fundamentalmente falando, o mapa de conhecimento é essencialmente um método de representação de conhecimento, que define a ontologia de domínio para realizar a estrutura de conhecimento (conceito, atributo de entidade, relacionamento de entidade, atributo de evento e relacionamento entre eventos) de um determinado domínio de negócios. é uma representação canônica do conhecimento em um domínio específico. A comparação entre conhecimento de entidade e gráfico de conhecimento de evento é a seguinte:
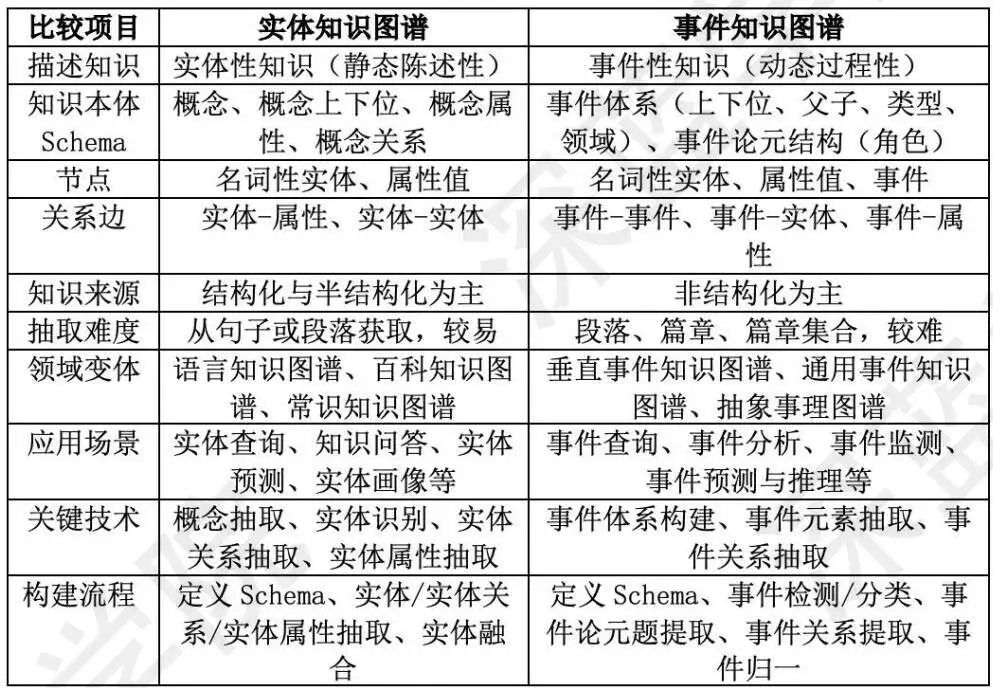
Figura 8 Comparação de gráficos de conhecimento de entidade e conhecimento de evento
Quais são as diferenças e combinações entre o gráfico de conhecimento e o ChatGPT? A diferença é que eles não são uma relação de substituição, mas uma relação paralela. A essência é que o gráfico de conhecimento é uma representação formal do conhecimento e o ChatGPT é um modelo de linguagem, que é conhecimento parametrizado. A vantagem do KG é É explicável, na verdade, também pode ser usado posteriormente para explicar por que o ChatGPT é eficaz. O ponto de combinação primeiro inclui a troca de raciocínio, seguida pelo mapeamento de várias tarefas gráficas e a realização do aprendizado profundo.
A outra é que o cálculo de dados é relativamente bom e há alguns desafios no raciocínio, portanto, os gráficos de conhecimento são usados atualmente para resolver problemas de raciocínio. Normalmente, o conhecimento estruturado é difícil de construir, mas fácil de raciocinar, e o conhecimento não estruturado é fácil de construir (basta armazená-lo diretamente), mas é difícil de usar para raciocinar. No entanto, os modelos de linguagem fornecem uma nova maneira de extrair facilmente o conhecimento do texto não estruturado e raciocinar sobre ele com eficiência, sem a necessidade de esquemas predefinidos.
Outra é a capacidade do sistema de integrar conhecimento externo. Pode levar muita energia para resolver fundamentalmente as deficiências do ChatGPT. É melhor combiná-lo com seu próprio mecanismo de conhecimento Wolfram|Alpha, porque o último possui uma estrutura poderosa. , mas também entender a linguagem natural.
A integração de gráficos de conhecimento no ChatGPT pode ser realizada de várias maneiras. Forneça conhecimento correto suficiente e, em seguida, introduza tecnologias de gerenciamento de conhecimento e injeção de informações, como gráficos de conhecimento, e também limite seu intervalo de dados e cenários de aplicação para tornar o conteúdo gerado mais confiável.
Em primeiro lugar, há uma representação de incorporação do gráfico de conhecimento.As entidades e relacionamentos no gráfico de conhecimento podem ser representados como vetores de incorporação, que podem ser incorporados ao modelo como recursos adicionais para melhorar o desempenho do modelo. A segunda é a compreensão do contexto com base no gráfico de conhecimento, que pode ajudar o modelo a entender o contexto da conversa e fornecer informações mais precisas para responder às perguntas. Há também geração automática de perguntas com base em gráficos de conhecimento.Ao combinar informações de gráficos de conhecimento, as perguntas podem ser geradas automaticamente para ajudar os usuários a entender melhor a semântica e o contexto entre entidades e relacionamentos. Atualmente, o modelo de linguagem pré-treinado que integra principalmente o conhecimento é mostrado na Figura 9.

Figura 9 Modelo de linguagem pré-treinado com fusão de conhecimento
4. A possibilidade e perspectiva de aplicação do ChatGPT
O ChatGPT tem a capacidade de continuar várias rodadas de diálogo e oferece suporte a várias tarefas. A implementação do aplicativo depende primeiro da empresa. O modelo de negócios da openAI é taxas de associação, APIs abertas e cooperação estratégica com a Microsoft.
O próprio ChatGPT é um modelo de pré-treinamento, que pode aprender com alguns modelos de implementação do pré-modelo atual. No ano passado, o Instituto de Pesquisa em Inteligência Artificial divulgou um relatório, que dividiu a implementação da indústria inteligente de ultragrande escala em três Um é o upstream, que inclui principalmente algum treinamento de baixo nível, arquitetura, um midstream, incluindo pesquisa e desenvolvimento de tecnologia, gerenciamento e desenvolvimento de operação e manutenção, e um downstream, que se concentra na melhoria de modelos de grande escala.
Outro modo de pouso é o código aberto, que pode ser feito por meio de registro ou associação. O terceiro é o modelo PaaS, que integra algum software específico.
Após a implementação do aplicativo, a distribuição específica do que os usuários desejam fazer é mostrada na Figura 10.
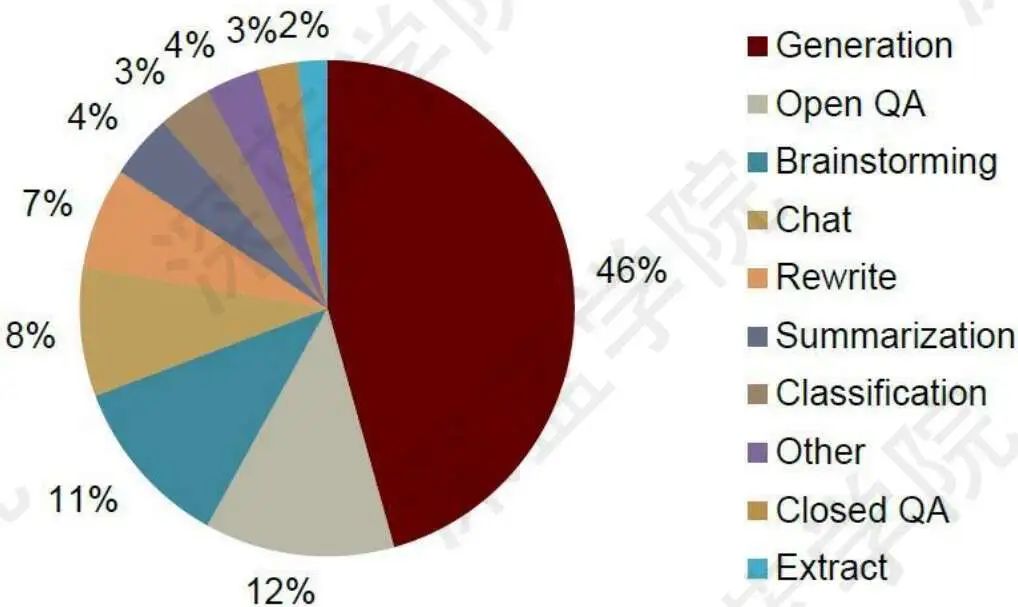
Figura 10 Funções e frequência de uso dos usuários
Claro que algumas empresas querem integrar no documento, para responder e-mails, fazer cotações, e assim por diante. Em seguida, você também pode combinar com os mecanismos de pesquisa, responder a algumas consultas de pesquisa por meio do ChatGPT e melhorar a eficiência dos mecanismos de pesquisa de forma inovadora.
Há também alguns de aprendizado, pesquisando artigos publicados, encontrando os resumos mais relevantes de um grande número de trabalhos de pesquisa e sendo capaz de fazer correções gramaticais; também há os criativos, que são os tópicos mais populares no Google pesquisando por conteúdo de palavras-chave, gerar conteúdo com base nos dados adquiridos para obter maior volume de leitura e também pode executar a escrita automática AI.
Na categoria de entretenimento, a IA pode gerar histórias automaticamente, fornecer feedback de eventos e experiência de jogo totalmente novos e ser capaz de dialogar com os usuários. Na categoria vida, existem assistentes fiscais, que podem utilizar diferentes modelos para extrair informações de texto e classificar tipos de transações.
Atualmente, os produtos concorrentes com ChatGPT são mostrados na Figura 11. Claro, isso também promove o desenvolvimento do ChatGPT.
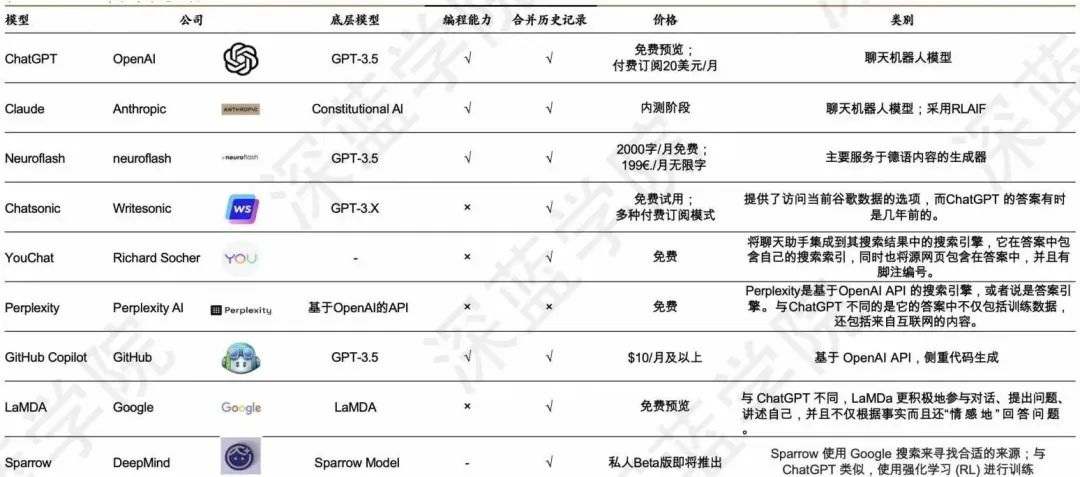
Figura 11 Produtos concorrentes do ChatGPT