Artikelverzeichnis
Einführung in die stabile Diffusion
Stable Diffusion ist ein latentes Text-zu-Bild-Diffusionsmodell, das in Zusammenarbeit zwischen Runway und der Universität München entwickelt wurde und dessen erste Version 2021 veröffentlicht wird. Zu den aktuellen Mainstream-Versionen gehören v1.5, v2 und v2.1. Es wird hauptsächlich zum Generieren detaillierter Bilder auf der Grundlage von Textbeschreibungen verwendet, kann aber auch für andere Aufgaben verwendet werden, z. B. für das Einmalen von Bildern, das Generieren von Bild-zu-Bild-Übersetzungen anhand von Texthinweisen usw.
In diesem Artikel wird hauptsächlich die kostenlose Bereitstellung der Web-UI von Stable Diffusion in Alibaba Cloud Interactive Modeling (PAI-DSW) und die Feinabstimmung von Stable Diffusion basierend auf LoRA vorgestellt.
Der Bereitstellungseffekt ist in der folgenden Abbildung dargestellt:
Umgebungs- und Ressourcenvorbereitungsprozess
Versuch der interaktiven Modellierung (PAI-DSW)
Vor der Nutzung müssen Sie sich bei Alibaba Cloud registrieren und sich bei Ihrem Konto anmelden: https://free.aliyun.com/ Wählen Sie nach
der Anmeldung die API der Plattform für maschinelles Lernen in der Produktkategorie links aus

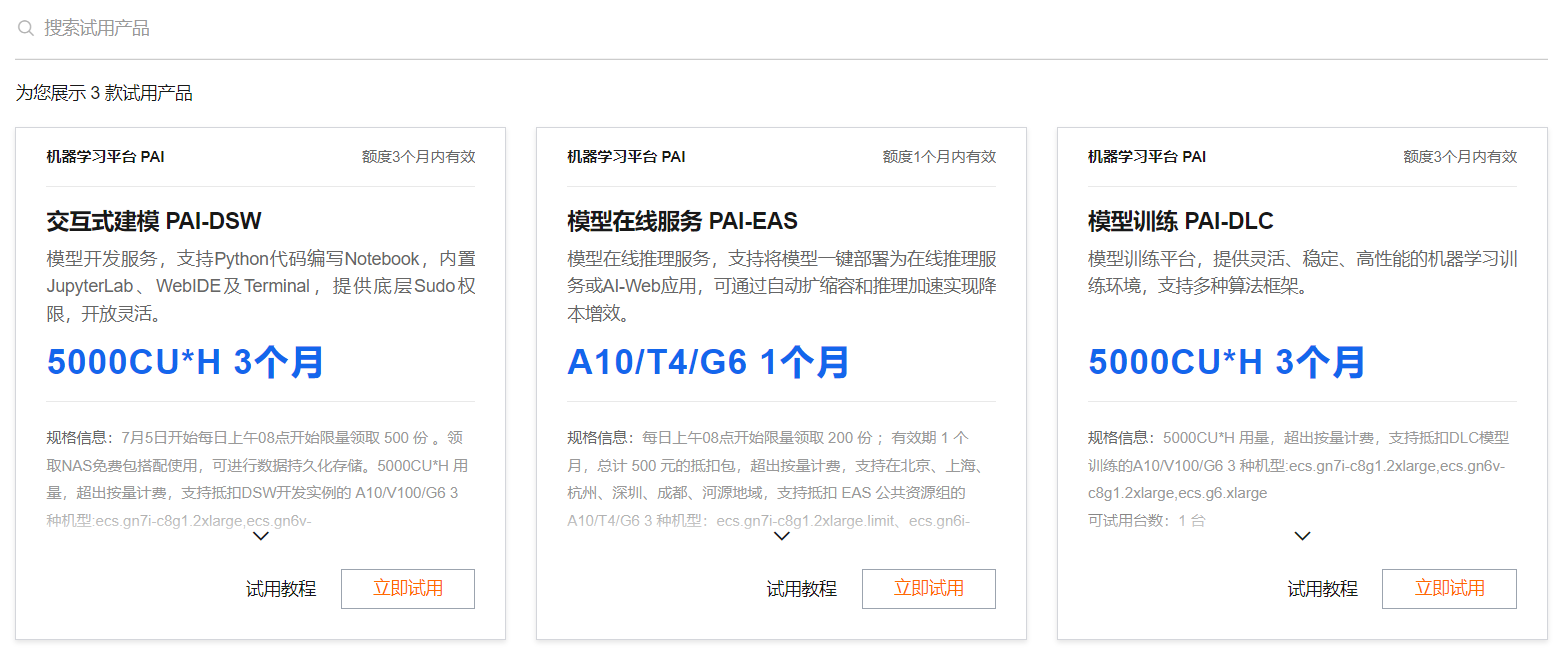
oder klicken Sie direkt auf den Link . Sie können sich die drei Testprodukte ansehen, die Alibaba Cloud auf der Plattform für maschinelles Lernen PAI bereitstellt.
Wählen Sie „Interactive Modeling-PAI-DSW“ und klicken Sie auf „Jetzt testen“.
Wählen Sie, ob Sie der Servicevereinbarung zustimmen möchten, und klicken Sie auf „Jetzt testen“.
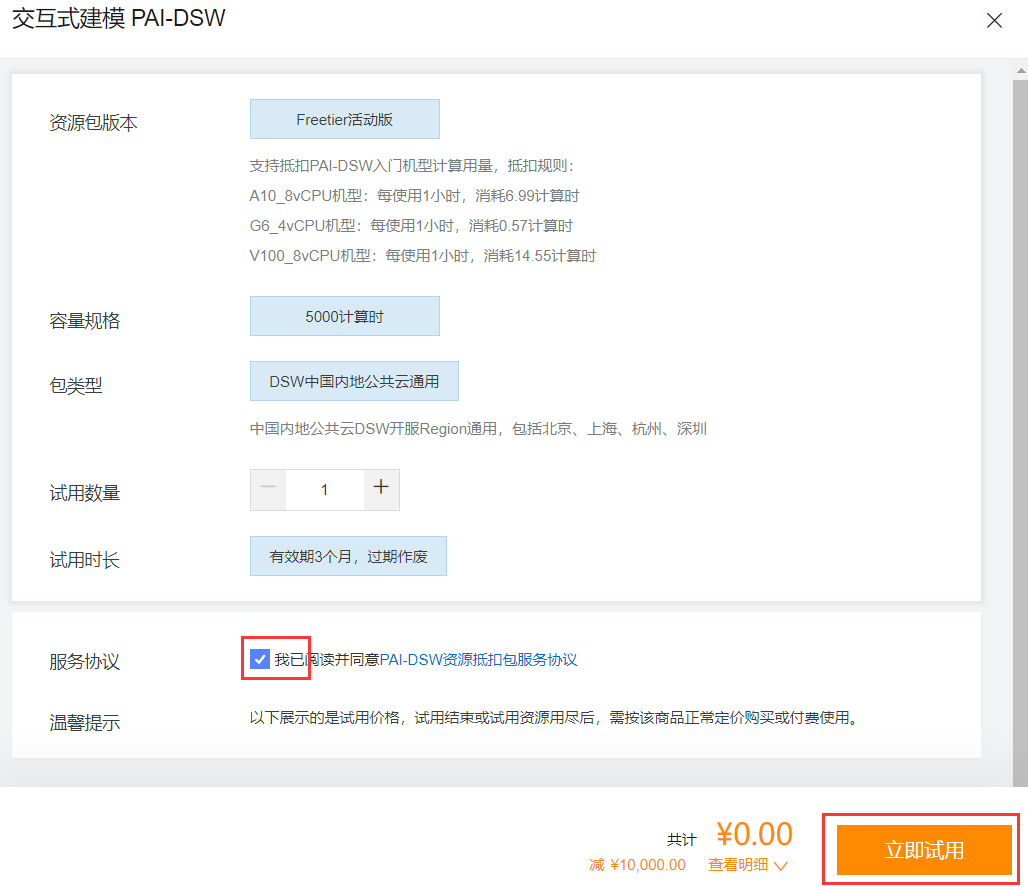
Klicken Sie auf PAI aktivieren und erstellen Sie einen Standardarbeitsbereich.
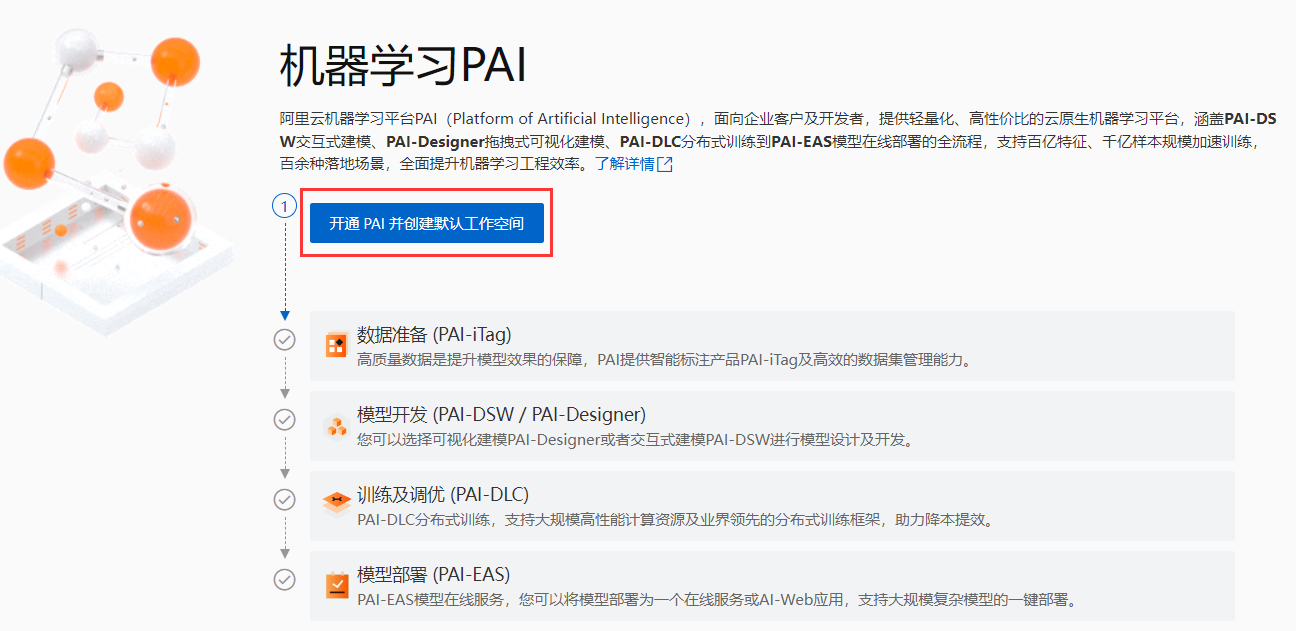
Klicken Sie auf Autorisierung abschließen (ich habe sie hier autorisiert) und klicken Sie auf Bestätigen, um einen Vertrag zu öffnen und einen Standardarbeitsbereich zu erstellen. Hinweis: Es gibt hier keine Möglichkeit, OSS zu aktivieren. Wenn Sie eine Langzeitspeicherung benötigen, müssen Sie OSS aktivieren (möglicherweise fällt eine Gebühr an).
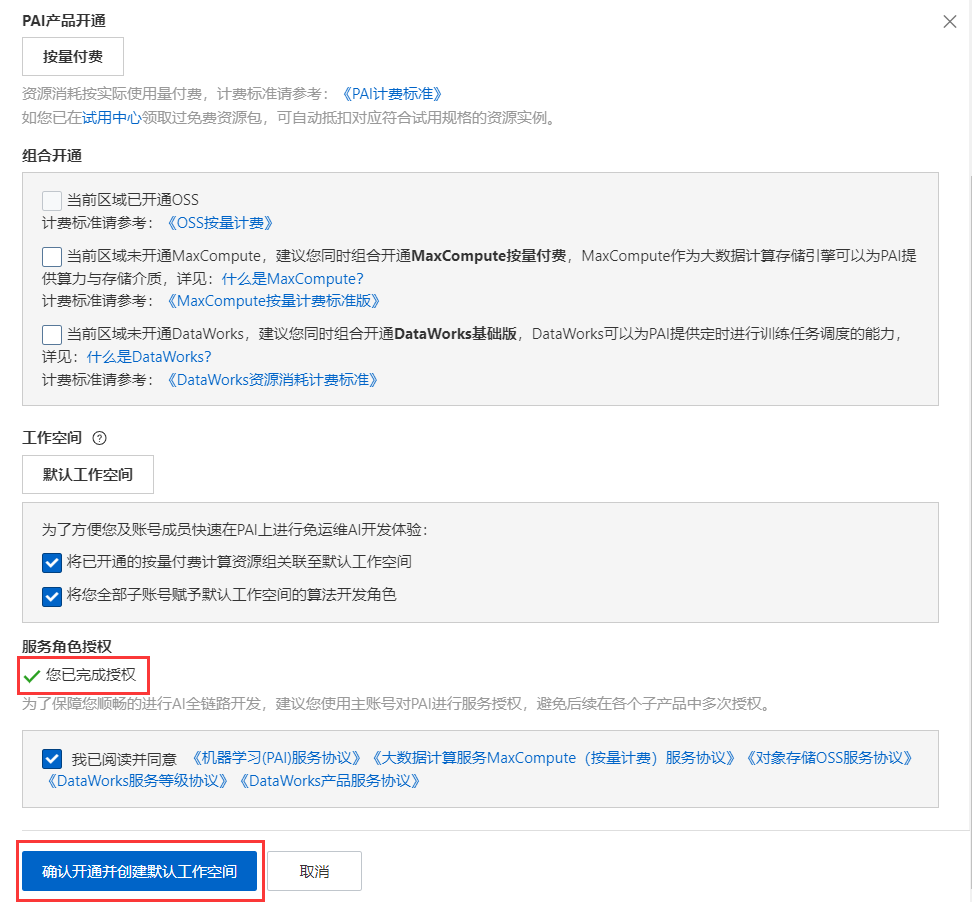
Es wird angezeigt, dass die Aktivierung abgeschlossen ist. Klicken Sie hier, um die PAI-Konsole aufzurufen.
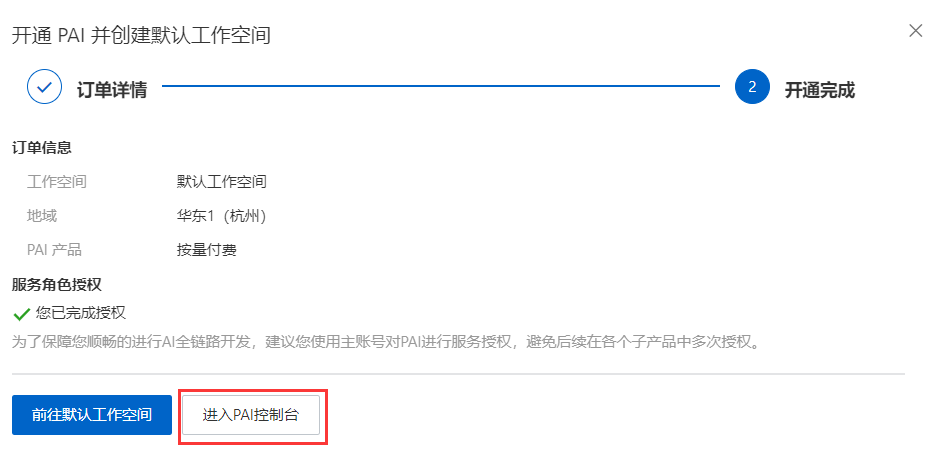
Klicken Sie in der PAI-Konsole auf den erstellten Arbeitsbereich.
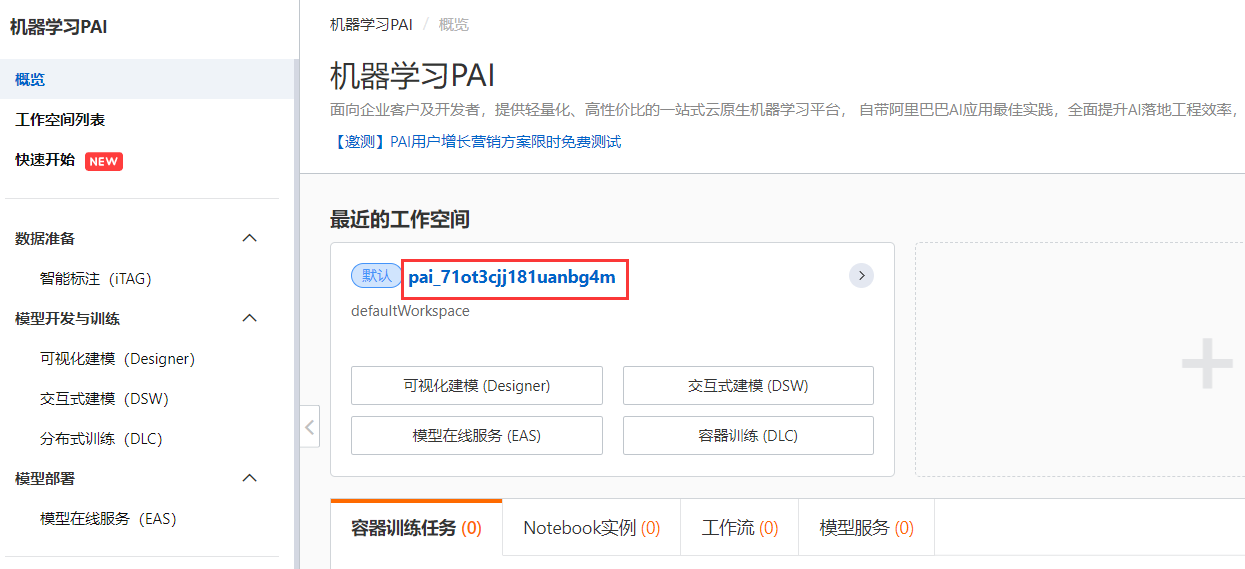
Klicken Sie nach der Eingabe links auf „Interaktive Modellierung“ und dann auf „Instanz erstellen“, um mit der Erstellung einer Instanz zu beginnen.
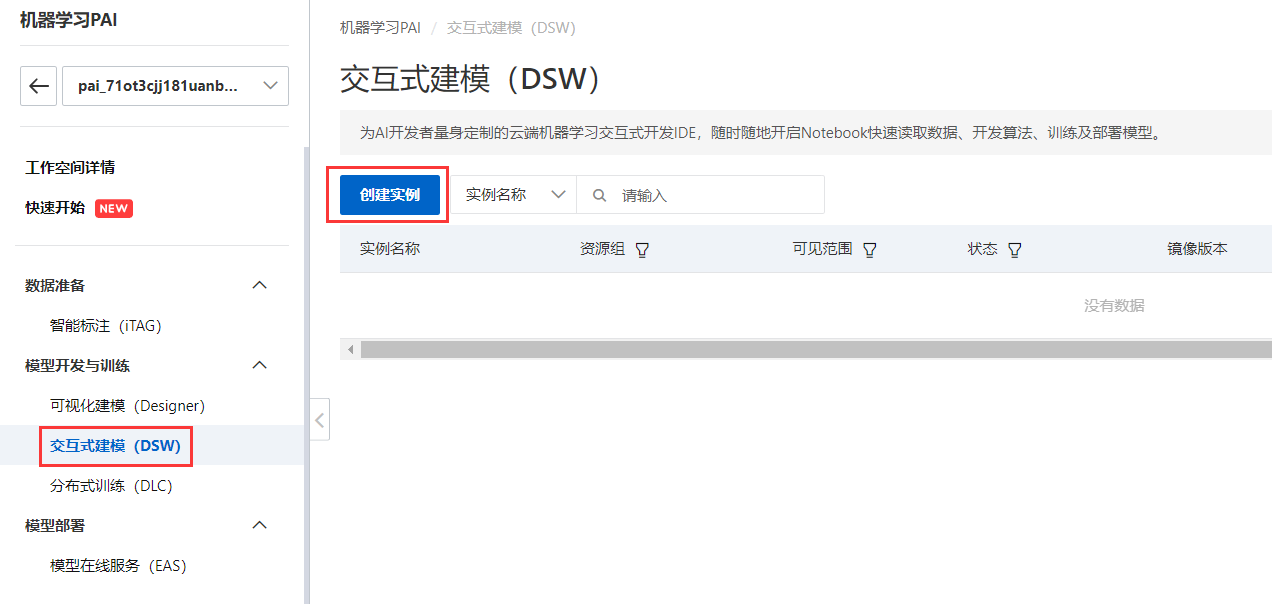
Erstellen Sie eine Instanz im erstellten Arbeitsbereich
Geben Sie den Instanznamen ein und wählen Sie die GPU-Spezifikation aus. Der Spezifikationsname lautet ecs.gn7i-c8g1.2xlarge.
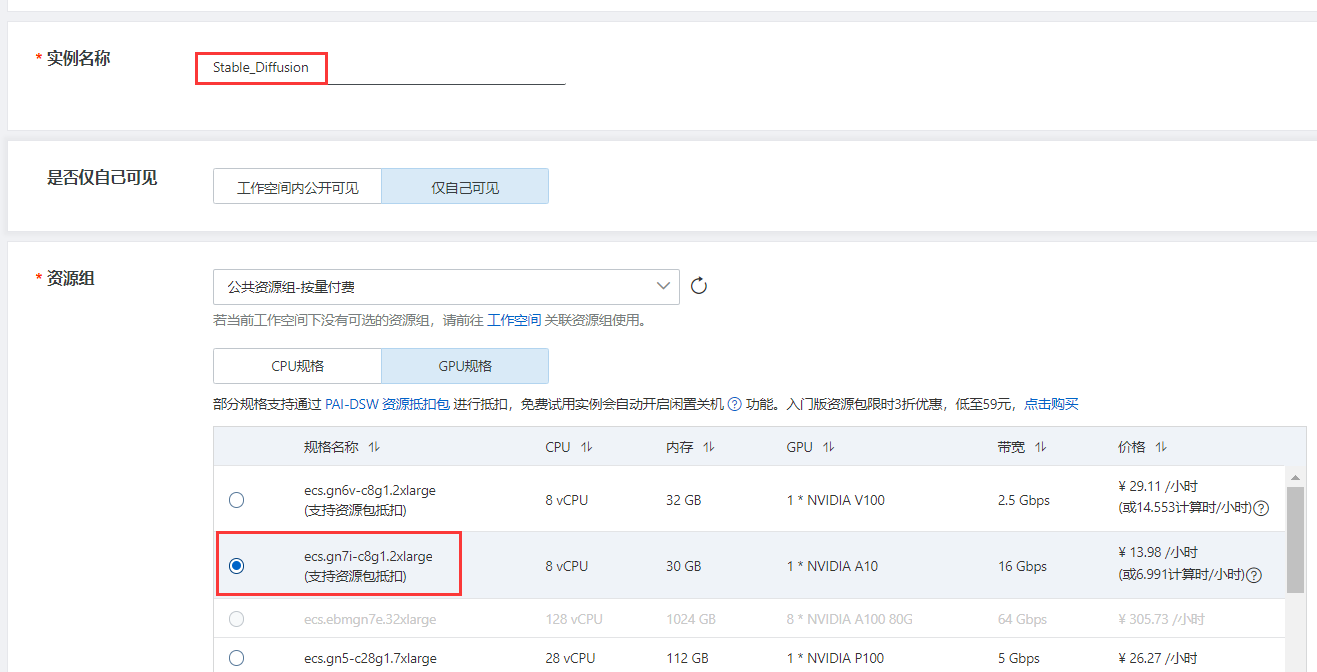
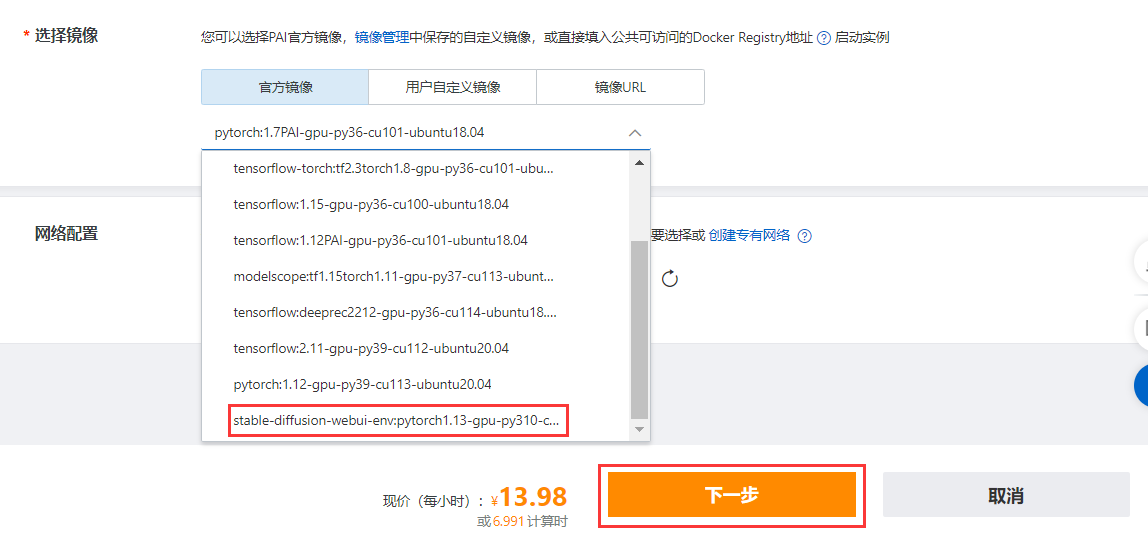
Wählen Sie im offiziellen Bild „stable-diffusion-webui-env:pytorch1.13-gpu-py310-cu117-ubuntu22.04“ aus, klicken Sie auf „Weiter“ und dann auf „Instanz erstellen“.
Hinweis : Das Erstellen einer DSW-Instanz dauert einige Zeit, normalerweise etwa 2 bis 15 Minuten.
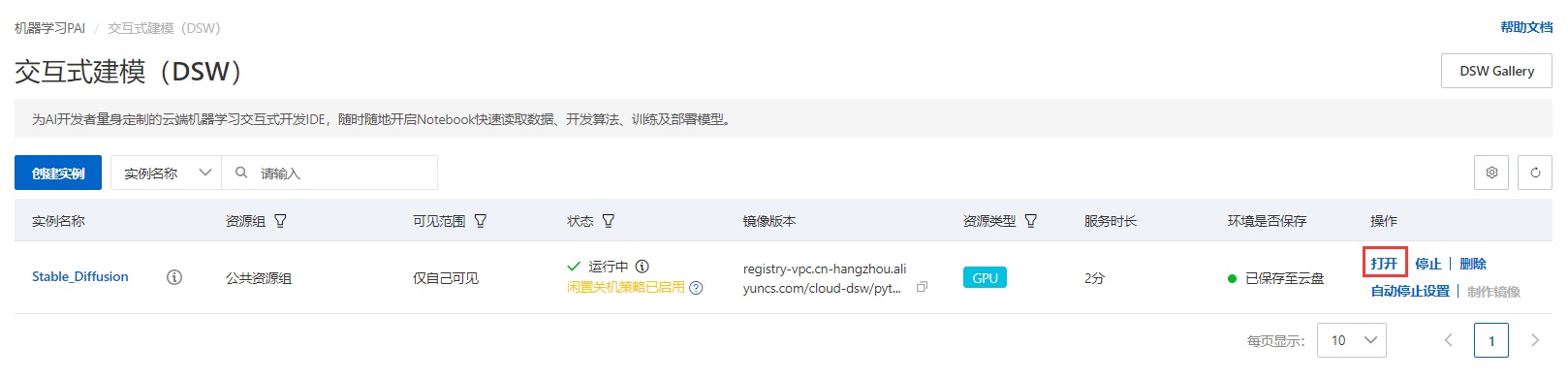
Klicken Sie nach erfolgreicher Erstellung auf Öffnen, um die PAI-DSW-Entwicklungsumgebung aufzurufen.
Web-UI-Bereitstellung von Stable Diffusion
Wählen Sie im Launcher der AI-DSW-Entwicklungsumgebung unter „Tool“ die Option „DSW-Galerie“
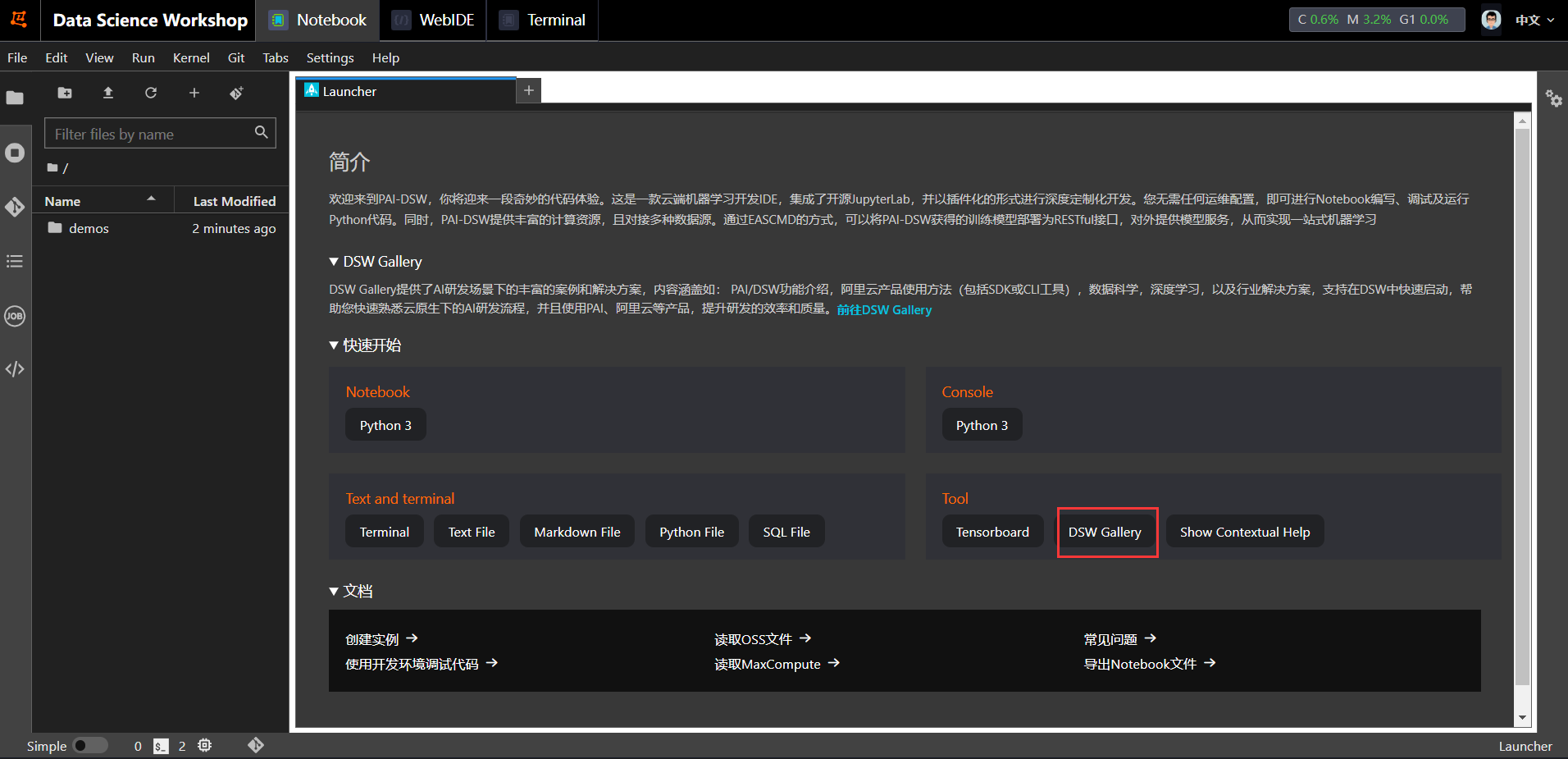
aus , um nach Stable Diffusion WebUI-Nutzungsbeispielen zu suchen oder zu suchen, und klicken Sie, um sie in DSW zu öffnen .
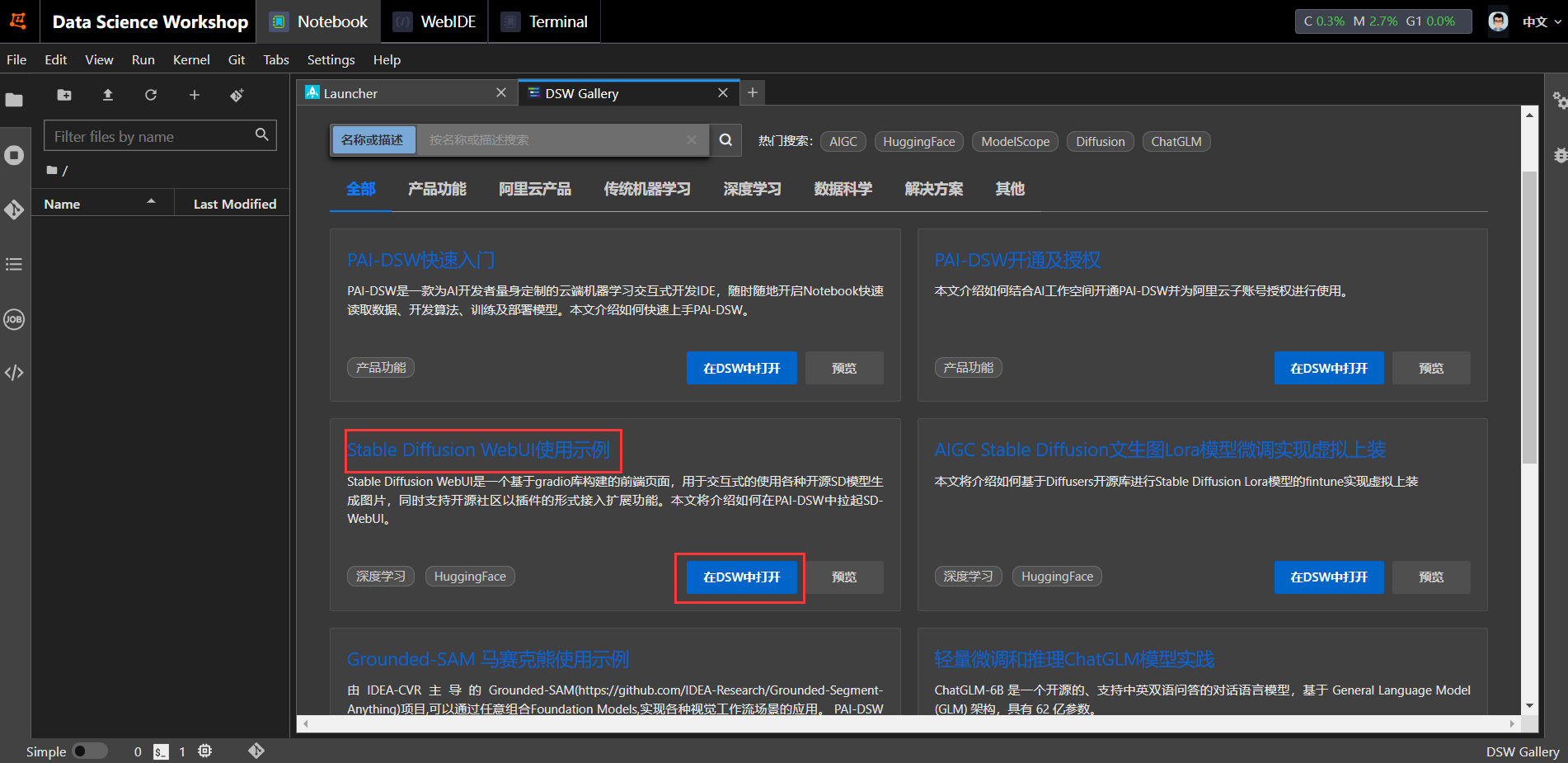
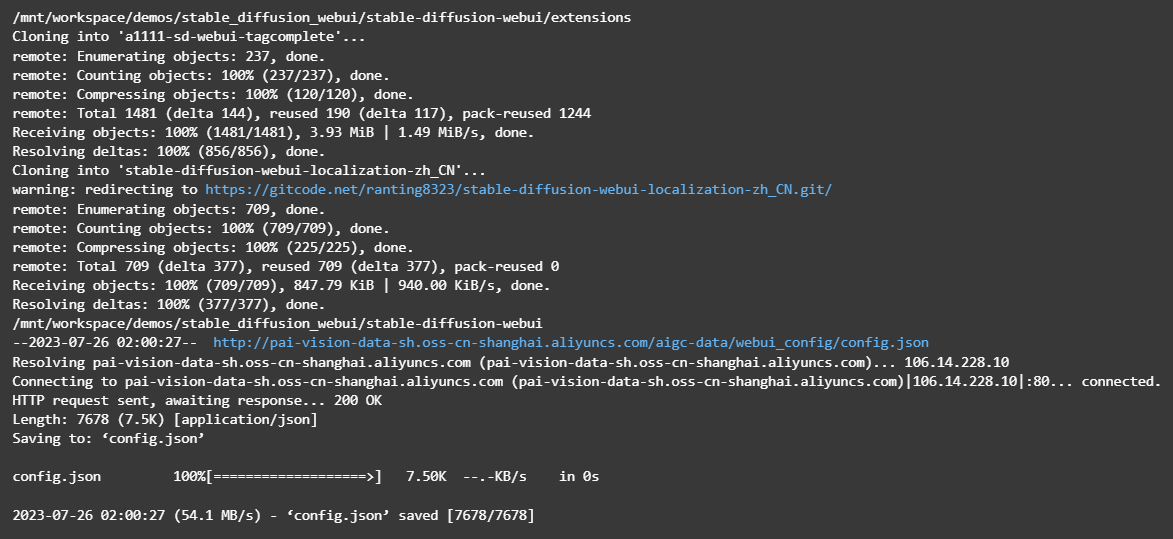
Laden Sie die Open-Source-Bibliothek „stable-diffusion-webui“ und andere Abhängigkeiten herunter
Führen Sie die entsprechenden Befehle im Notebook aus, um die Open-Source-Bibliothek „stable-diffusion-webui“ und andere Abhängigkeiten herunterzuladen.
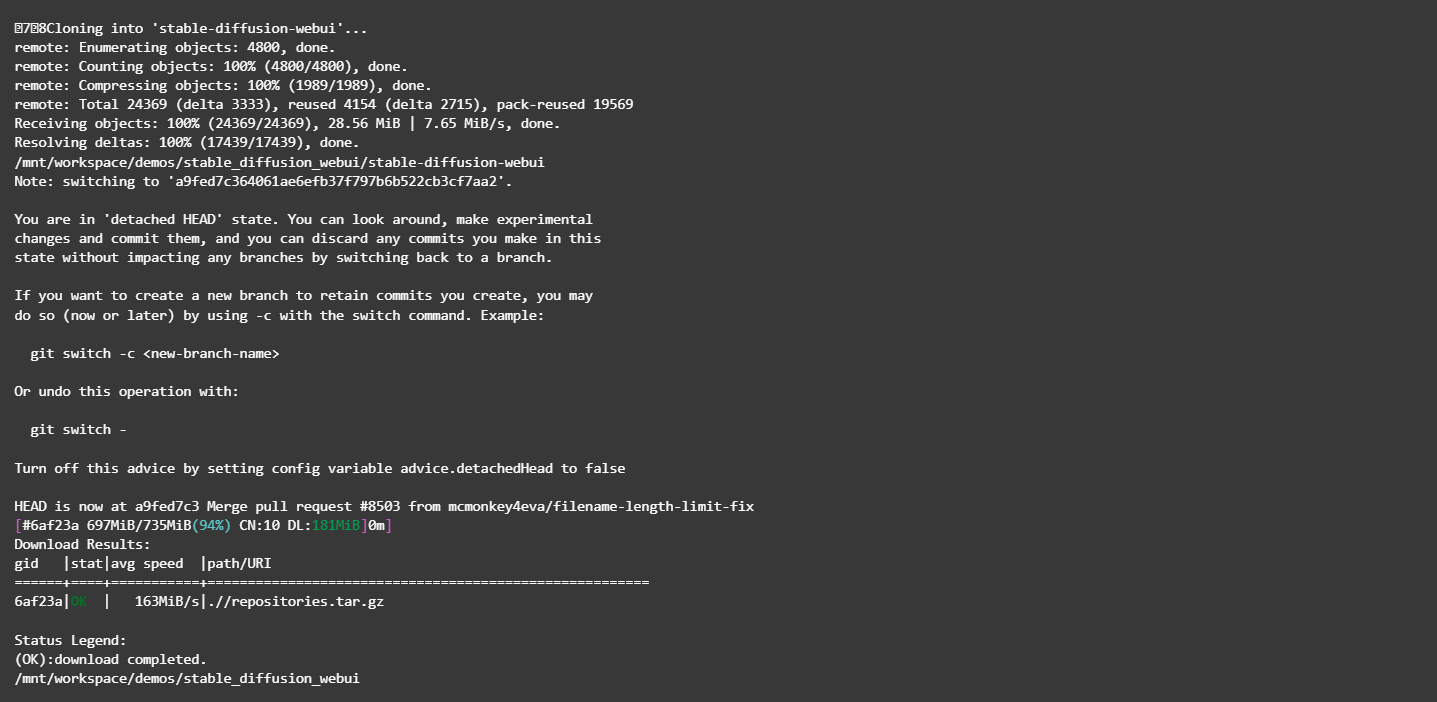
Nachdem Sie den Befehl ausgeführt haben (siehe Abbildung unten), bedeutet dies, dass der Download abgeschlossen ist.
Installieren Sie gängige Plugins
Führen Sie den entsprechenden Befehl in Notebook aus, installieren Sie tagcomplete und das chinesische Plugin.

Nachdem Sie den Befehl ausgeführt haben (siehe Abbildung unten), bedeutet dies, dass die Installation abgeschlossen ist.
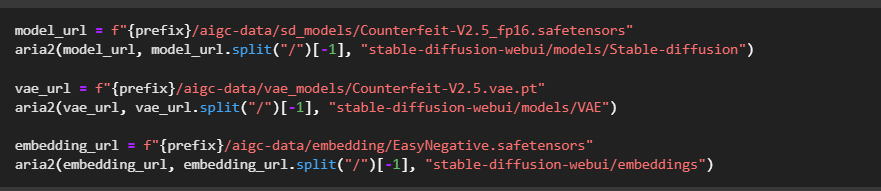
Modell herunterladen
Verwenden Sie das Open-Source-SD-Modell Counterfeit-v2.5 als Basismodell.
Führen Sie den entsprechenden Befehl in Notebook aus, um das Modell herunterzuladen.
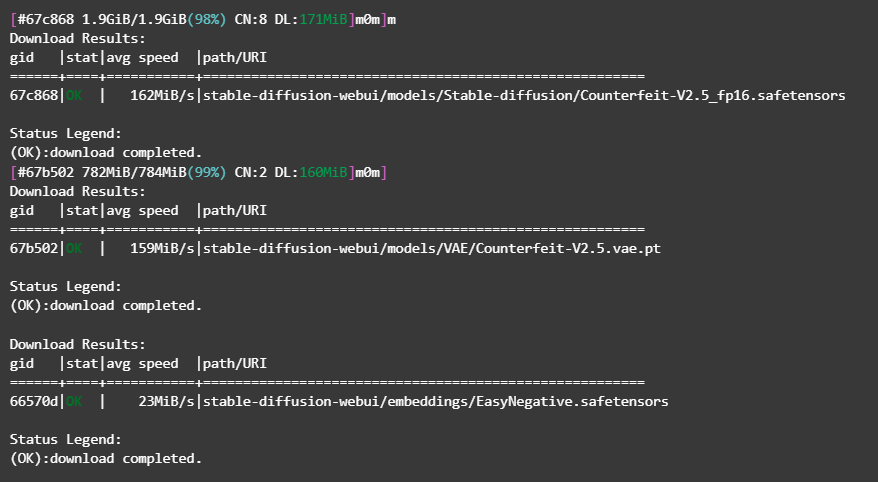
Starten Sie WebUI in DSW
Führen Sie den entsprechenden Befehl im Notebook aus, um den WebUI-Dienst zu starten.

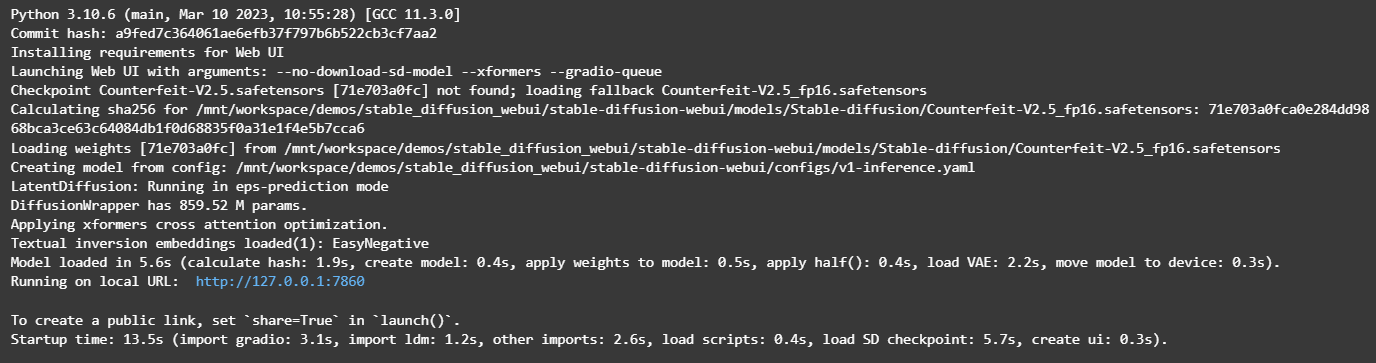
Klicken Sie im zurückgegebenen Ergebnis auf den URL-Link (http://127.0.0.1:7860), um die WebUI-Seite aufzurufen, auf der Inferenz durchgeführt werden kann.
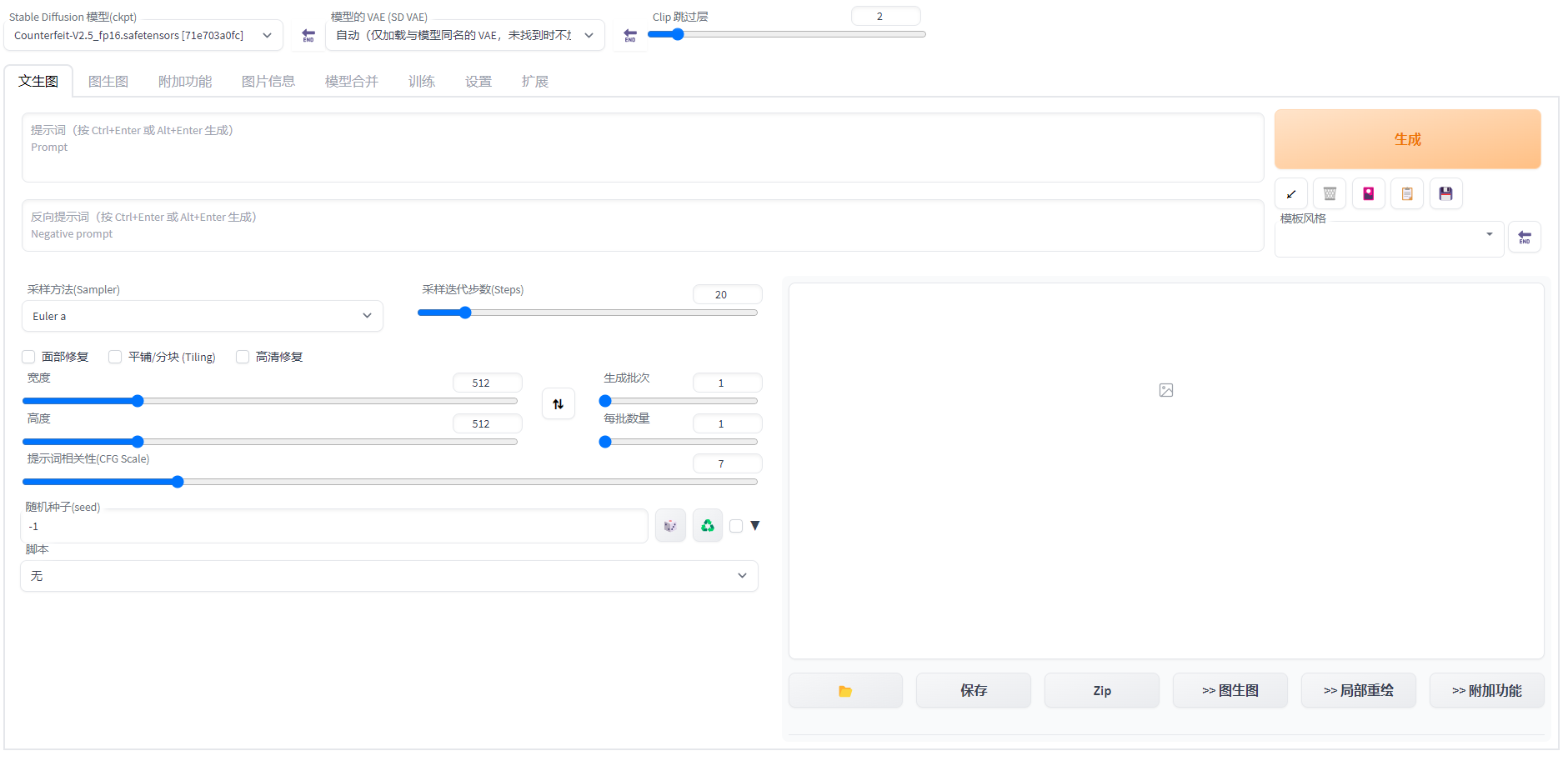
Konfigurieren Sie die folgenden Parameter auf der Vincent-Diagrammseite:
- 正向prompt:
((Meisterwerk, beste Qualität)), 1 Mädchen, Solo, Tierohren, Kaninchen, barfuß, Knie hoch, Kleid, sitzend, Hasenohren, kurze Ärmel, Blick auf den Betrachter, Gras, kurzes Haar, Lächeln, weißes Haar , Puffärmel, draußen, Puffärmel, Pony, am Boden, Ganzkörper, Tier, weißes Kleid, Sonnenlicht, braune Augen, gesprenkeltes Sonnenlicht, Tag, Tiefenschärfe - Negative Aufforderung:
- EasyNegative, zusätzliche Finger, weniger Finger
- Stichprobenmethode: DPM++2M Karras
- HD-Reparatur: prüfen
- Amplitude neu zeichnen: 0,6
- Vergrößerung: 1,8
- Höhe: 832
- Schnelle Wortkorrelation (CFG-Skala): 10
Andere verwandte Parameter können ebenfalls nach Bedarf eingestellt werden.
Klicken Sie auf „Generieren“, um die Inferenzergebnisse wie in der Abbildung gezeigt auszugeben und das Speichern von Bildern zu unterstützen.
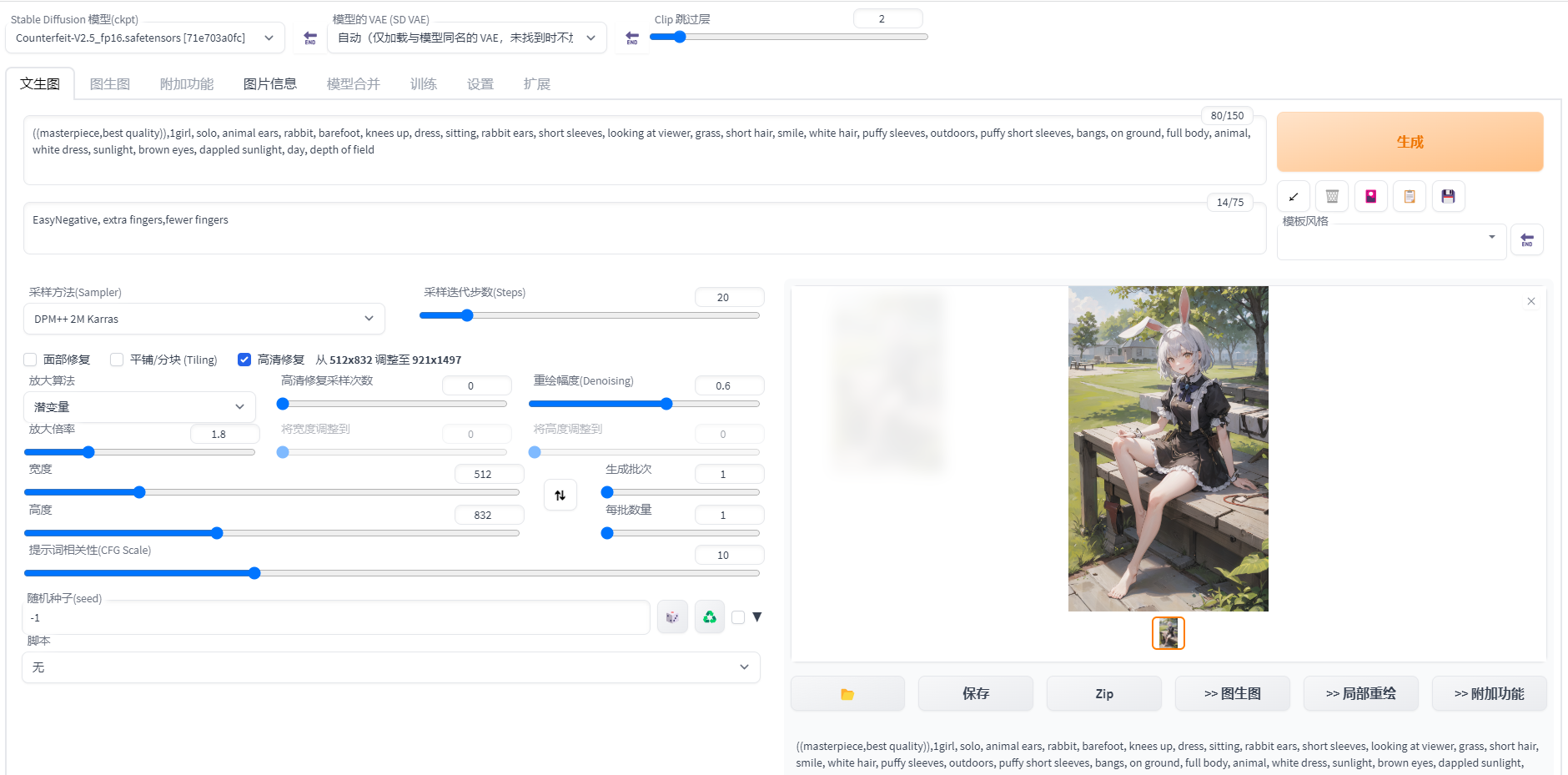
Feinabstimmung der stabilen Verbreitung und der Web-UI-Bereitstellung
Installieren Sie Diffusoren
Erstellen Sie eine neue Zelle in Notebook und laden Sie das zu verwendende Differs-Warehouse herunter
! git clone https://github.com/huggingface/diffusers
! cd diffusers && git checkout e126a82cc5d9afbeb9b476455de24dd3e7dd358a
! cd diffusers && pip install .

Stellen Sie sicher, dass die Installation erfolgreich war
import diffusers

Beschleunigung konfigurieren.
! mkdir -p /root/.cache/huggingface/accelerate/
! wget -c http://pai-vision-data-sh.oss-cn-shanghai.aliyuncs.com/aigc-data/accelerate/default_config.yaml -O /root/.cache/huggingface/accelerate/default_config.yaml
Die Beschleunigungskonfiguration ist erfolgreich.

Installieren Sie verwandte Abhängigkeiten
! cd diffusers/examples/text_to_image && pip install -r requirements.txt
Feinabstimmung des Stable Diffusion-Modells
Führen Sie den folgenden Code im Notebook aus, um den Bekleidungsdatensatz und den Code basierend auf der LoRA-Feinabstimmung herunterzuladen.
! wget http://pai-vision-data-hz.oss-cn-zhangjiakou.aliyuncs.com/EasyCV/datasets/try_on/cloth_train_example.tar.gz && tar -xvf cloth_train_example.tar.gz
! wget http://pai-vision-data-hz.oss-cn-zhangjiakou.aliyuncs.com/EasyCV/datasets/try_on/train_text_to_image_lora.py
Nachdem Sie den Befehl ausgeführt haben (siehe Abbildung unten), bedeutet dies, dass der Download abgeschlossen ist.
Führen Sie den folgenden Code in Notebook aus, um das Beispielbild anzuzeigen
from PIL import Image
display(Image.open("cloth_train_example/train/20230407174421.jpg"))

Führen Sie den folgenden Code in Notebook aus, laden Sie das vorab trainierte Modell herunter und konvertieren Sie es in das Diffusorformat.
safety_checker_url = f"{prefix}/aigc-data/hug_model/models--CompVis--stable-diffusion-safety-checker.tar.gz"
aria2(safety_checker_url, safety_checker_url.split("/")[-1], "./")
! tar -xf models--CompVis--stable-diffusion-safety-checker.tar.gz -C /root/.cache/huggingface/hub/
clip_url = f"{prefix}/aigc-data/hug_model/models--openai--clip-vit-large-patch14.tar.gz"
aria2(clip_url, clip_url.split("/")[-1], "./")
! tar -xf models--openai--clip-vit-large-patch14.tar.gz -C /root/.cache/huggingface/hub/
model_url = f"{prefix}/aigc-data/sd_models/chilloutmix_NiPrunedFp32Fix.safetensors"
aria2(model_url, model_url.split("/")[-1], "stable-diffusion-webui/models/Stable-diffusion/")
! python diffusers/scripts/convert_original_stable_diffusion_to_diffusers.py \
--checkpoint_path=stable-diffusion-webui/models/Stable-diffusion/chilloutmix_NiPrunedFp32Fix.safetensors \
--dump_path=chilloutmix-ni --from_safetensors
Nachdem Sie den Befehl ausgeführt haben, wie in der Abbildung unten gezeigt, bedeutet dies, dass die Datei heruntergeladen und konvertiert wurde.
Feinabstimmung des Modells. Setzen Sie num_train_epochs auf 200 und führen Sie den folgenden Code für LoRA-basiertes Feinabstimmungstraining aus. Nach Abschluss der Feinabstimmung wird die Modelldatei im Verzeichnis „cloth-model-lora“ generiert
! export MODEL_NAME="chilloutmix-ni" && \
export DATASET_NAME="cloth_train_example" && \
accelerate launch --mixed_precision="fp16" train_text_to_image_lora.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--dataset_name=$DATASET_NAME --caption_column="text" \
--width=640 --height=768 --random_flip \
--train_batch_size=1 \
--num_train_epochs=200 --checkpointing_steps=5000 \
--learning_rate=1e-04 --lr_scheduler="constant" --lr_warmup_steps=0 \
--seed=42 \
--output_dir="cloth-model-lora" \
--validation_prompt="cloth1" --validation_epochs=100
Sie können direkt auf die Feinabstimmung bezogene Informationen wie Epochen, Batch-Größe usw. sehen. Aufgrund der geringen Stichprobengröße gibt es nur 11 Stichproben und der Feinabstimmungsprozess dauert etwa 16 Minuten.
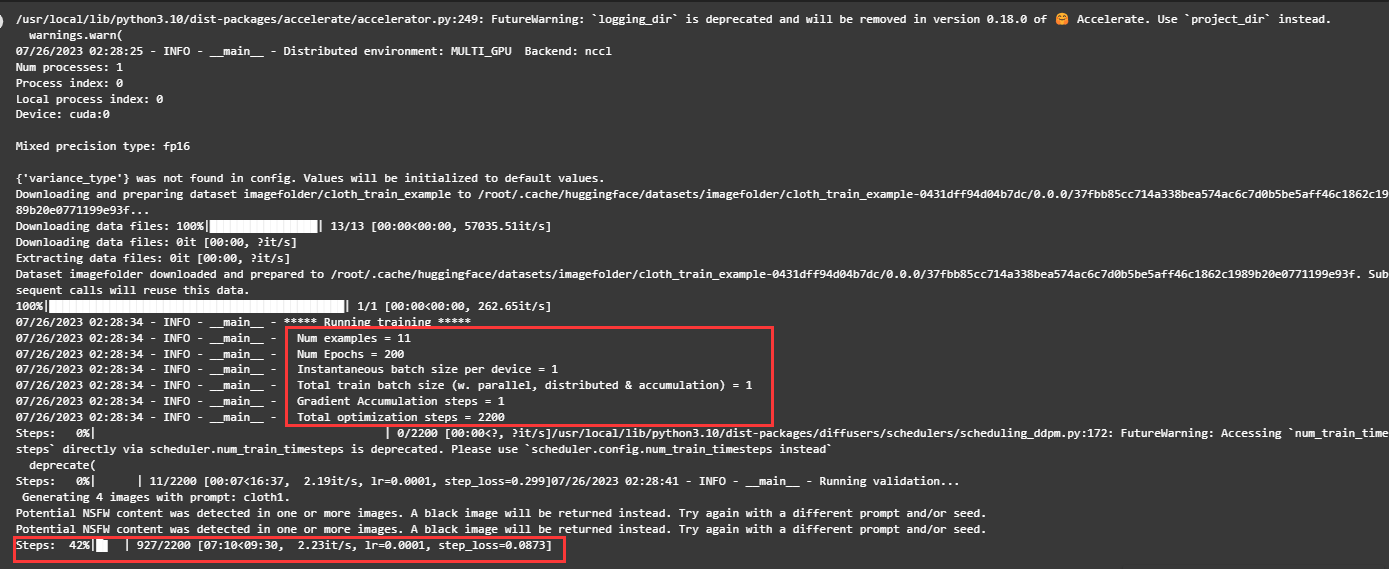
Während des Trainingsprozesses können Sie Terminal öffnen und den Befehl nvidia-smi eingeben, um die Videospeichernutzung zu überprüfen.
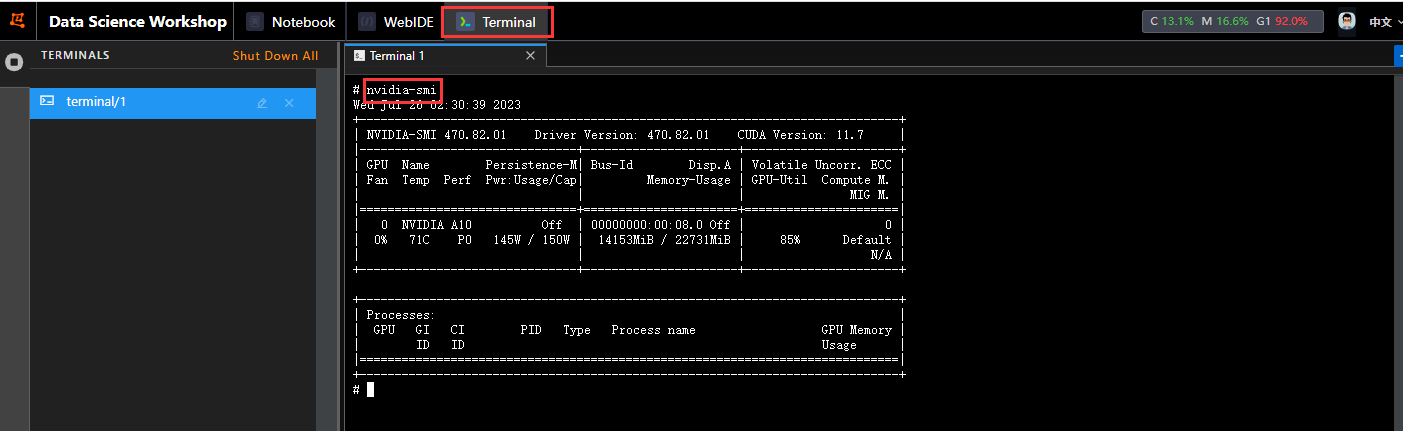
Es ist ersichtlich, dass der Videospeicher etwa 14 GB belegt.
Bereiten Sie die für WebUI erforderlichen Modelldateien vor
Konvertieren Sie die Lora-Modelldatei in ein von WebUI unterstütztes Format und kopieren Sie sie in das Verzeichnis, in dem sich WebUI befindet.
! wget -c http://pai-vision-data-hz.oss-cn-zhangjiakou.aliyuncs.com/EasyCV/datasets/convert-to-safetensors.py
! python convert-to-safetensors.py --file='cloth-model-lora/pytorch_lora_weights.bin'
! mkdir stable-diffusion-webui/models/Lora
! cp cloth-model-lora/pytorch_lora_weights_converted.safetensors stable-diffusion-webui/models/Lora/cloth_lora_weights.safetensors
Bereiten Sie zusätzliche Modelldateien vor. Um den Download zu beschleunigen, können Sie den folgenden Befehl ausführen, um zusätzliche Modelldateien direkt herunterzuladen.
detection_url = f"{prefix}/aigc-data/codeformer/detection_Resnet50_Final.pth"
aria2(detection_url, detection_url.split("/")[-1], "stable-diffusion-webui/repositories/CodeFormer/weights/facelib/")
parse_url = f"{prefix}/aigc-data/codeformer/parsing_parsenet.pth"
aria2(parse_url, parse_url.split("/")[-1], "stable-diffusion-webui/repositories/CodeFormer/weights/facelib/")
codeformer_url = f"{prefix}/aigc-data/codeformer/codeformer-v0.1.0.pth"
aria2(codeformer_url, codeformer_url.split("/")[-1], "stable-diffusion-webui/models/Codeformer/")
embedding_url = f"{prefix}/aigc-data/embedding/ng_deepnegative_v1_75t.pt"
aria2(embedding_url, embedding_url.split("/")[-1], "stable-diffusion-webui/embeddings/")
model_lora_url = f"{prefix}/aigc-data/lora/koreanDollLikeness_v10.safetensors"
aria2(model_lora_url, model_lora_url.split("/")[-1], "stable-diffusion-webui/models/Lora/")
Starten Sie WebUI in DSW
Führen Sie den folgenden Befehl in Notebook aus, um WebUI zu starten.
! cd stable-diffusion-webui && python -m venv --system-site-packages --symlinks venv
! cd stable-diffusion-webui && \
sed -i 's/can_run_as_root=0/can_run_as_root=1/g' webui.sh && \
./webui.sh --no-download-sd-model --xformers
Klicken Sie im zurückgegebenen Ergebnis auf den URL-Link (http://127.0.0.1:7860), um die WebUI-Seite aufzurufen.
Nach dem Klicken auf den Link kann die Inferenz auf der WebUI-Seite durchgeführt werden.
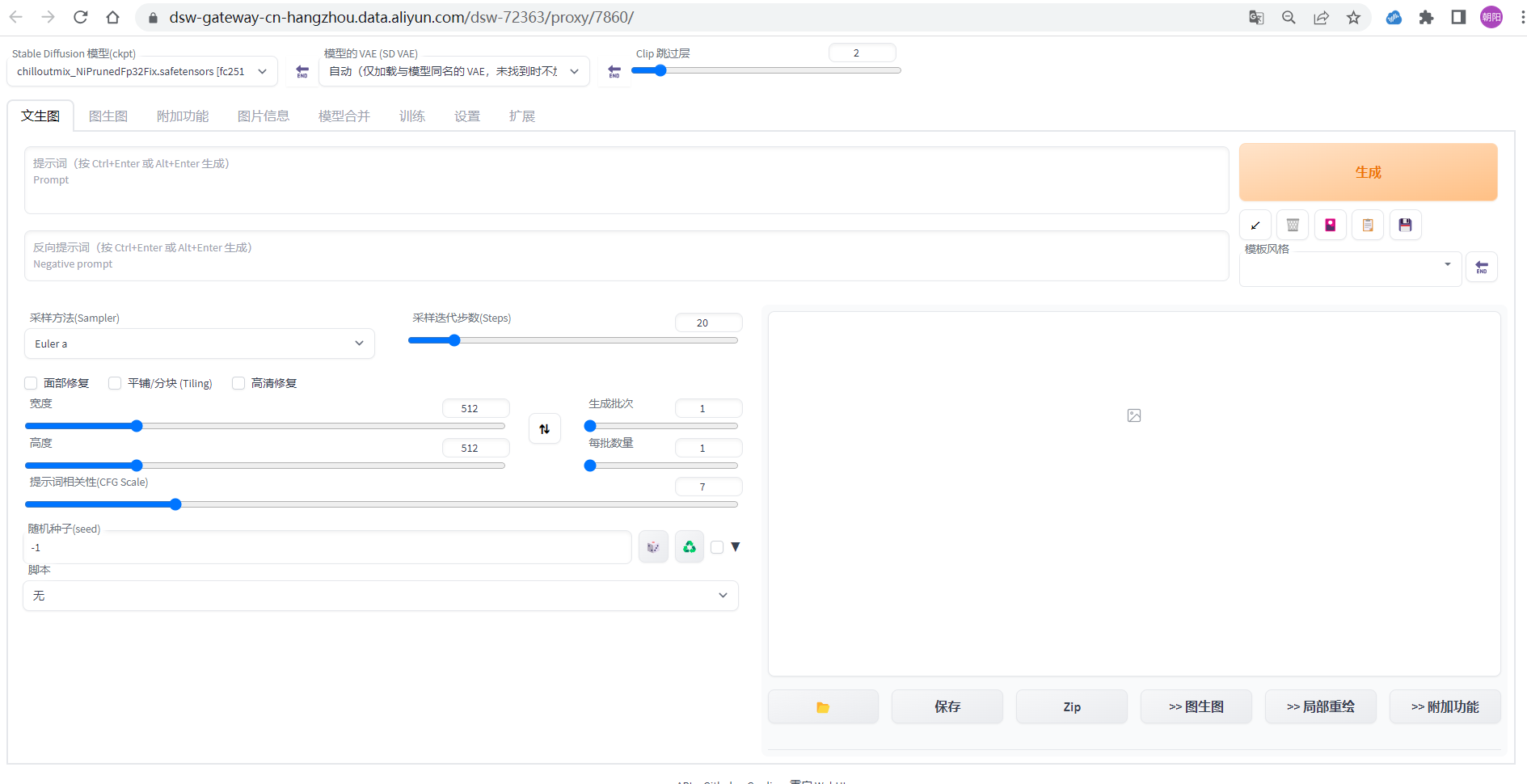
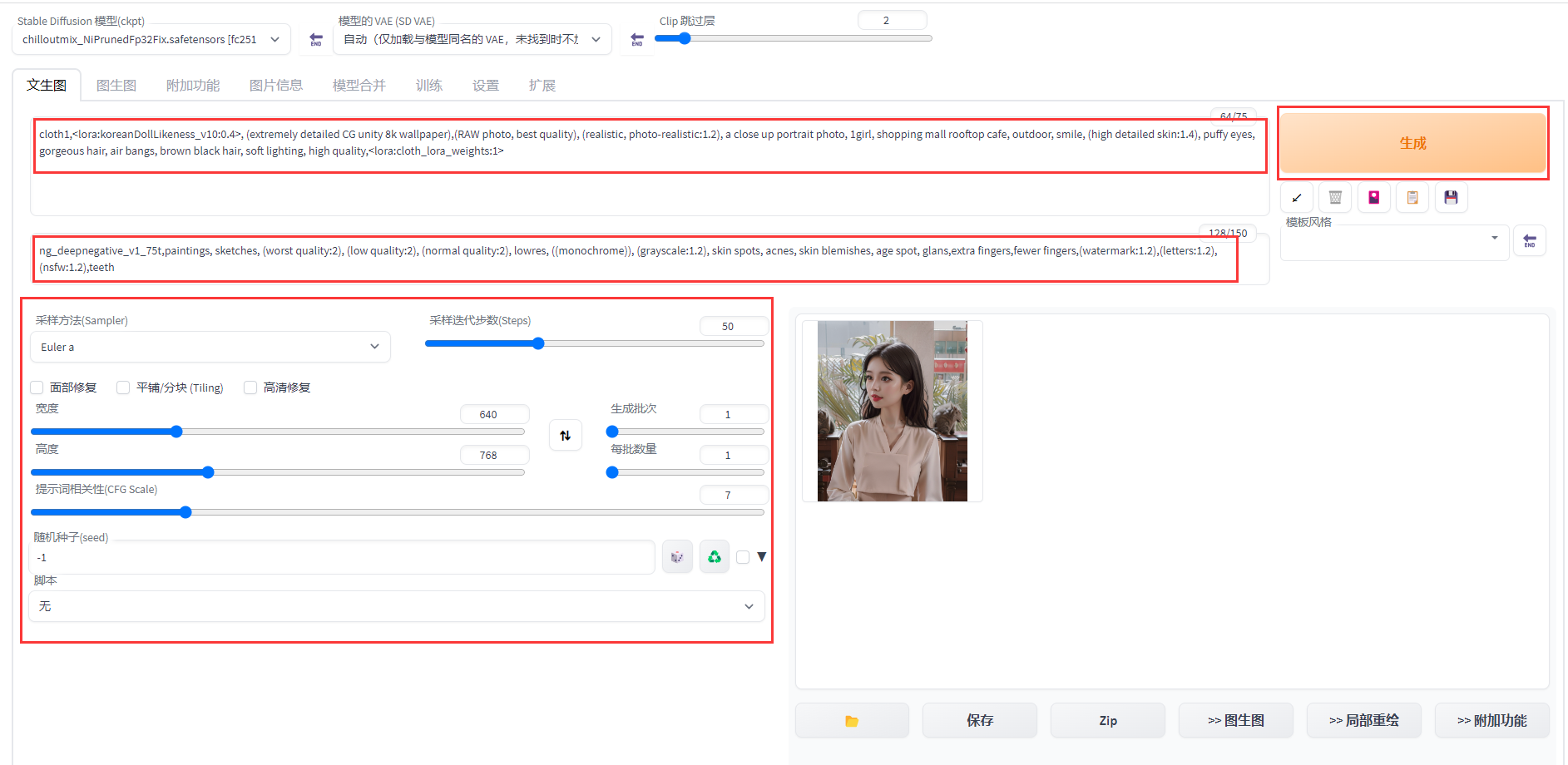
Konfigurieren Sie die folgenden Parameter auf der Vincent-Diagrammseite:
-
Eingabeaufforderung :cloth1,lora:koreanDollLikeness_v10:0.4, (extrem detailliertes CG Unity 8k-Hintergrundbild),(RAW-Foto, beste Qualität), (realistisch, fotorealistisch:1.2), ein Nahaufnahme-Porträtfoto, 1 Mädchen, Café auf dem Dach eines Einkaufszentrums, Im Freien, Lächeln, (hochdetaillierte Haut: 1,4), geschwollene Augen, wunderschönes Haar, luftiger Pony, braunes schwarzes Haar, sanfte Beleuchtung, hohe Qualität,lora:cloth_lora_weights:1
-
Negative Eingabeaufforderung : ng_deepnegative_v1_75t, Gemälde, Skizzen, (schlechteste Qualität: 2), (niedrige Qualität: 2), (normale Qualität: 2), niedrige Auflösung, ((monochrom)), (Graustufen: 1,2), Hautflecken, Akne, Haut Hautunreinheiten, Altersflecken, Eichel, zusätzliche Finger, weniger Finger, (Wasserzeichen: 1.2), (Buchstaben: 1.2), (nsfw: 1.2), Zähne
Stichprobenmethode (Sampler): Euler-a-
Sampling-Iterationsschritte (Schritte): 50
Breite und Höhe : 640, 768
Andere verwandte Parameter können ebenfalls nach Bedarf eingestellt werden.
Klicken Sie auf „Generieren“, um die Inferenzergebnisse wie in der Abbildung gezeigt auszugeben und das Speichern von Bildern zu unterstützen.
Hinweis
Nachdem Sie das kostenlose Ressourcenpaket erhalten haben, nutzen Sie es bitte innerhalb des kostenlosen Kontingents und des gültigen Testzeitraums. Wenn Sie weiterhin Computerressourcen nutzen, nachdem das kostenlose Kontingent erschöpft ist oder der Testzeitraum endet, wird eine Postpaid-Rechnung erstellt. Sie können zur Ressourceninstanzverwaltungsseite
gehen, um die Ressourcenpaketnutzung zu überprüfen .
Wenn Sie die DSW-Instanz nicht weiter verwenden müssen, können Sie die folgenden Schritte ausführen, um die DSW-Instanz zu stoppen.
-
Melden Sie sich bei der PAI-Konsole an .
-
Klicken Sie auf die Arbeitsbereichsliste in der linken Navigationsleiste und dann auf den Standardarbeitsbereichsnamen auf der Arbeitsbereichslistenseite, um den entsprechenden Arbeitsbereich aufzurufen.
-
Wählen Sie in der linken Navigationsleiste der Arbeitsbereichsseite Modellentwicklung und Training > Interaktive Modellierung (DSW) aus, um die Seite „Interaktive Modellierung (DSW)“ aufzurufen.
-
Klicken Sie in der Spalte „Vorgang“ der Zielinstanz auf „Stopp“, um den Ressourcenverbrauch nach einem erfolgreichen Stopp zu stoppen.