PyTorch-Studiennotizen (18) – Skriptdatei zum Teilen von Trainingssatz und Testsatz
Bei diesem Blog-Beitrag handelt es sich um die Studiennotizen von PyTorch, den 18. Inhaltsdatensatz, der hauptsächlich aufzeichnet, wie der Trainingssatz und der Testsatz automatisch aufgeteilt werden. Es umfasst hauptsächlich zwei Methoden. Die erste Methode zielt darauf ab, Datensätze in mehreren Ordnern nach Kategorien zu speichern, was für Klassifizierungsprobleme geeignet ist. Die Bilder derselben Kategorie werden in Trainingssätze und Testsätze unterteilt. Die zweite Methode zielt darauf ab Die Daten werden nicht nach Klassifizierung gespeichert, sondern direkt im selben Ordner abgelegt und in Trainingssatz und Testsatz unterteilt.
Inhaltsverzeichnis
1. Nach Kategorie speichern
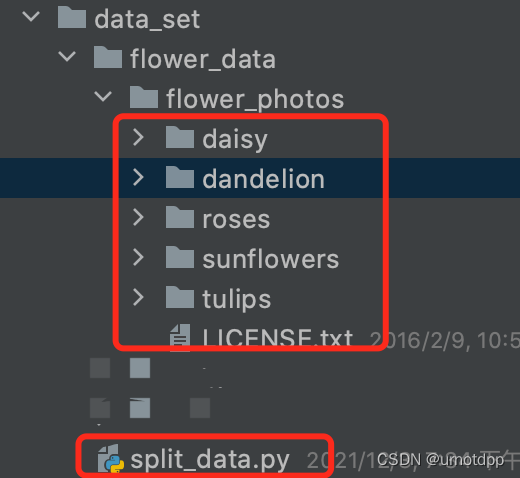
Bei der Aufteilung des Trainingssatzes und des Testsatzes muss der Ordner „flower_data/flower_photos“ unterteilt werden. Darunter befinden sich 5 klassifizierte Ordner, nämlich: Gänseblümchen, Löwenzahn, Rosen, Sonnenblumen, Tulpen, und das Klassifizierungsskript lautet „split_data“. py, die Skriptdatei „split_data.py“ und der Datenordner „flower_photos“ stehen in einer parallelen Beziehung und werden alle im Ordner „flower_data“ abgelegt, wie in der folgenden Abbildung dargestellt: Der Code
der Skriptdatei „split_data.py“ lautet wie folgt:
# coding :UTF-8
# 文件功能: 代码实现自动将数据集划分为训练集和验证集的功能
# 开发人员: XXX
# 开发时间: 2021/12/3 6:07 下午
# 文件名称: split_data.py
# 开发工具: PyCharm
import os
from shutil import copy, rmtree
import random
def mk_file(file_path: str):
if os.path.exists(file_path):
# 如果文件夹存在,则先删除原文件夹再重新创建
rmtree(file_path)
os.makedirs(file_path)
def main():
# 保证随机可复现
random.seed(0)
# 将数据集中10%的数据划分到验证集中
split_rate = 0.1
# 指向你解压后的flower_photos文件夹
cwd = os.getcwd() # 用于返回当前工作目录
data_root = os.path.join(cwd, "flower_data")
origin_flower_path = os.path.join(data_root, "flower_photos")
assert os.path.exists(origin_flower_path), "path '{}' does not exist.".format(origin_flower_path)
flower_class = [cla for cla in os.listdir(origin_flower_path)
if os.path.isdir(os.path.join(origin_flower_path, cla))]
# 建立保存训练集的文件夹
train_root = os.path.join(data_root, "train")
mk_file(train_root)
for cla in flower_class:
# 建立每个类别对应的文件夹
mk_file(os.path.join(train_root, cla))
# 建立保存验证集的文件夹
val_root = os.path.join(data_root, "val")
mk_file(val_root)
for cla in flower_class:
# 建立每个类别对应的文件夹
mk_file(os.path.join(val_root, cla))
for cla in flower_class:
cla_path = os.path.join(origin_flower_path, cla)
images = os.listdir(cla_path)
num = len(images)
# 随机采样验证集的索引
eval_index = random.sample(images, k=int(num * split_rate))
for index, image in enumerate(images):
if image in eval_index:
# 将分配至验证集中的文件复制到相应目录
image_path = os.path.join(cla_path, image)
new_path = os.path.join(val_root, cla)
copy(image_path, new_path)
else:
# 将分配至训练集中的文件复制到相应目录
image_path = os.path.join(cla_path, image)
new_path = os.path.join(train_root, cla)
copy(image_path, new_path)
print("\r[{}] processing [{}/{}]".format(cla, index + 1, num), end="") # processing bar
print()
print("processing done!")
if __name__ == '__main__':
main()
2. Alle werden in einem Ordner gespeichert
Wenn alle Bilder in einem Ordner gespeichert sind, werden die Bilder in diesem Ordner in Trainingssatz und Testsatz unterteilt. Der Windows-Versionscode lautet wie folgt:
# -*- coding: utf-8 -*-
"""
Created on Tue Jul 20 16:28:13 2021
@author: NN
"""
import os
import random
import shutil
# 原始数据集路径
# origion_path = r'D:\蓝藻门'
origion_path = r'E:\BaiduNetdiskDownload\data_20211112_train_new'
names = os.listdir(origion_path)
# 保存路径
# save_train_dir = r'D:\藻类识别神经网络\分类网络\train'
# save_test_dir = r'D:\藻类识别神经网络\分类网络\test'
# 数据集类别及数量
for i in names:
file_list = origion_path + '\\' + i
image_list = os.listdir(file_list) # 获取图片的原始路径
image_number = len(image_list)
train_number = int(image_number * 0.75)
train_sample = random.sample(image_list, train_number) # 从image_list中随机获取0.8比例的图像.
test_sample = list(set(image_list) - set(train_sample))
# 创建保存路径
save_train_dir = r'D:\藻类数据\data_20211112\train' + '\\' + i
save_test_dir = r'D:\藻类数据\data_20211112\test' + '\\' + i
if not os.path.isdir(save_train_dir):
os.makedirs(save_train_dir)
if not os.path.isdir(save_test_dir):
os.makedirs(save_test_dir)
# 复制图像到目标文件夹
for j in train_sample:
shutil.copy(file_list + '\\' + j, save_train_dir)
for k in test_sample:
shutil.copy(file_list + '\\' + k, save_test_dir)