Conteúdo do trabalho
Dividir o sistema de e-commerce em microsserviços.
Histórico: suponha que você seja o CTO de uma empresa iniciante agora. A equipe de desenvolvimento tem cerca de 30 pessoas, incluindo 5 front-ends e 25 back-ends. Os desenvolvedores de back-end são todos Java. Agora você iniciará uma pequeno programa e-commerce de 0 Business, por favor, projete a arquitetura de divisão de microsserviços e a seleção de infraestrutura de microsserviços.
Exigir:
É necessário esclarecer a ideia de divisão de serviço e desenhar uma imagem da arquitetura do sistema dividido;
É necessário esclarecer a seleção da infraestrutura de microsserviços e escolher um framework de microsserviços;
Use 1 a 2 páginas de PPT.
Método de divisão de resposta
- divisão por empresa
Como começa em 0, escolha dividir por empresa.
Divida os limites de negócios
Independentemente de haver especialistas em negócios ou não, o sistema de comércio eletrônico é um sistema com um modelo relativamente claro, portanto, consulte diretamente a implementação da indústria da seguinte maneira!
jpeg

Divisão de serviços
De acordo com o princípio dos três mosqueteiros, em média três desenvolvedores são responsáveis por um microsserviço. Agora existem 25 back-ends, então pode haver no máximo 25/3 = 8 microsserviços.
Como dividir as 5 pontas dianteiras? Como os microsserviços estão localizados principalmente na camada de negócios de serviços em camadas de ponta a ponta e têm pouco relacionamento com a camada de usuário e a camada de apresentação, o número de desenvolvedores de front-end não é considerado aqui.
Atualmente, dez domínios de negócios estão divididos e dois deles precisam ser mesclados. Como geralmente é dividido por negócios, os subdomínios pertencentes a um mesmo grande domínio de negócios são mesclados de acordo com a similaridade dos negócios:
Combinando itens e carrinhos de compras em um serviço;
Combinar pedido e pagamento em um único serviço, porque pedido e pagamento geralmente precisam estar em uma transação, pode reduzir a complexidade do sistema. Ao mesmo tempo, devido à alta complexidade interna após a fusão, quatro desenvolvedores foram designados como responsáveis por este serviço.
A divisão final do serviço e a arquitetura do sistema são as seguintes
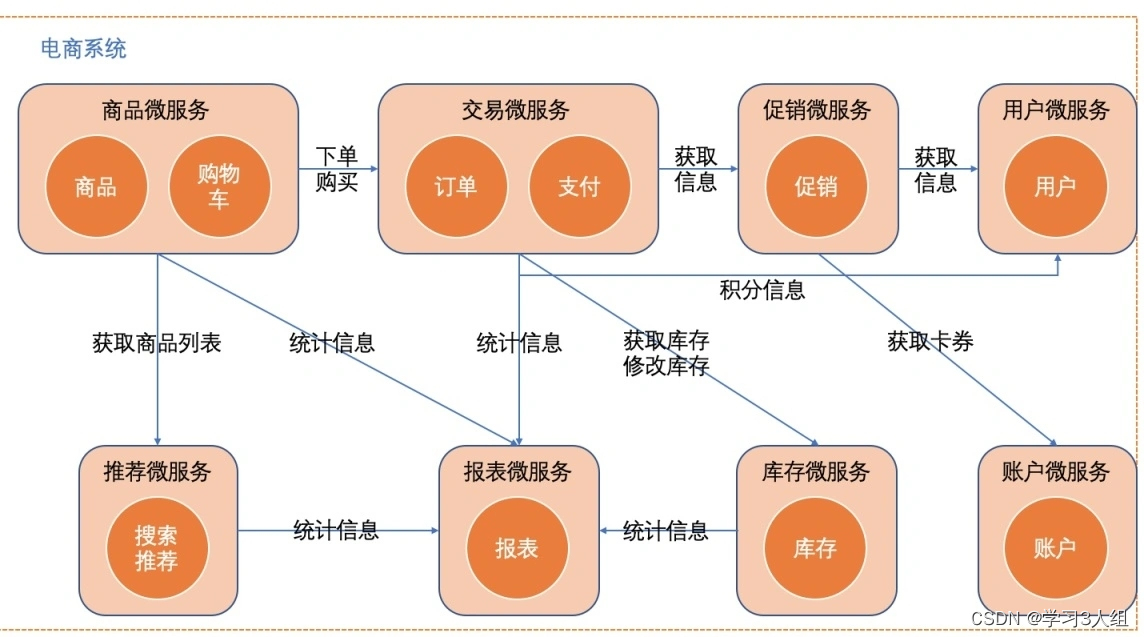
Método de implementação
Por começar do zero, é escolhido para ser realizado em uma etapa.
Seleção de infraestrutura de microsserviço
Todos os desenvolvedores de back-end usam a linguagem Java;
Por se tratar de uma startup de pequena escala, e para evitar gastos desnecessários com manutenção, opte por Spring Cloud ou Dubbo;
O Spring Cloud tem aplicabilidade mais ampla e componentes mais abrangentes, portanto, o Spring Cloud é escolhido como a infraestrutura de microsserviço.
Observações Parte
Arquitetura de microsserviço Explicação detalhada
Microsserviço e SOA
O objetivo de SOA é conectar os sistemas de TI heterogêneos existentes dentro da empresa e reduzir a construção redundante. O meio é acoplar livremente os vários sistemas por meio do ESB. O resultado é uma lógica ESB inchada, baixo desempenho e escalonamento de dificuldade. Pipes inteligentes e endpoints burros.
Para microsserviços, nas palavras de Martine Fowler, o objetivo é dividir um grande sistema em serviços menores, comunicar-se entre si por meio de mecanismos leves e enfatizar que os serviços podem ser implantados automaticamente. Endpoints inteligentes e pipes burros.
Em relação à ligação entre os dois, existem várias visões a seguir, mas a última é precisa, ou seja, existem muitas diferenças entre eles, mas são iguais em termos de orientação de serviço.

De acordo com a explicação do Sr. Qin Jinwei, a arquitetura geral de SOA e microsserviços é diferente
SOA/ESB: invocação de proxy, aprimoramento direto

Serviço distribuído: chamada direta, reforço lateral
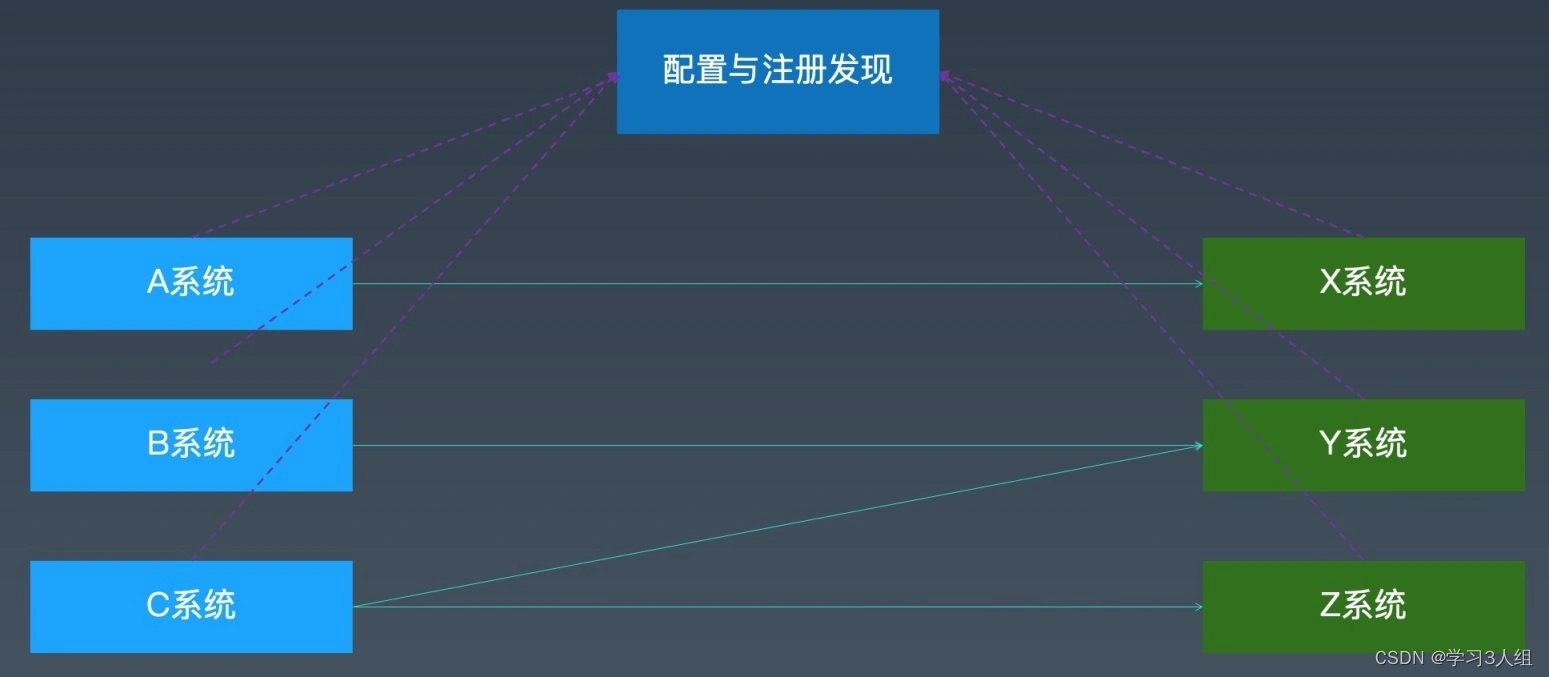
Com o desenvolvimento de microsserviços, a infraestrutura de microsserviços tornou-se poderosa e complexa.
Arquitetura monolítica, SOA e arquitetura de microsserviços são vários estágios diferentes na evolução da arquitetura do lado do servidor.
A relação entre microsserviços e outras arquiteturas escaláveis
Hua Tsai, como o “Curso Prático DDD”, considera a arquitetura limpa como uma forma arquitetônica de implementação de microsserviços.
No entanto, a perspectiva do "Curso Prático DDD" é um pouco diferente. A arquitetura DDD de quatro camadas também é usada como uma forma específica de microsserviços, e a arquitetura em camadas aqui é um sentido mais geral.
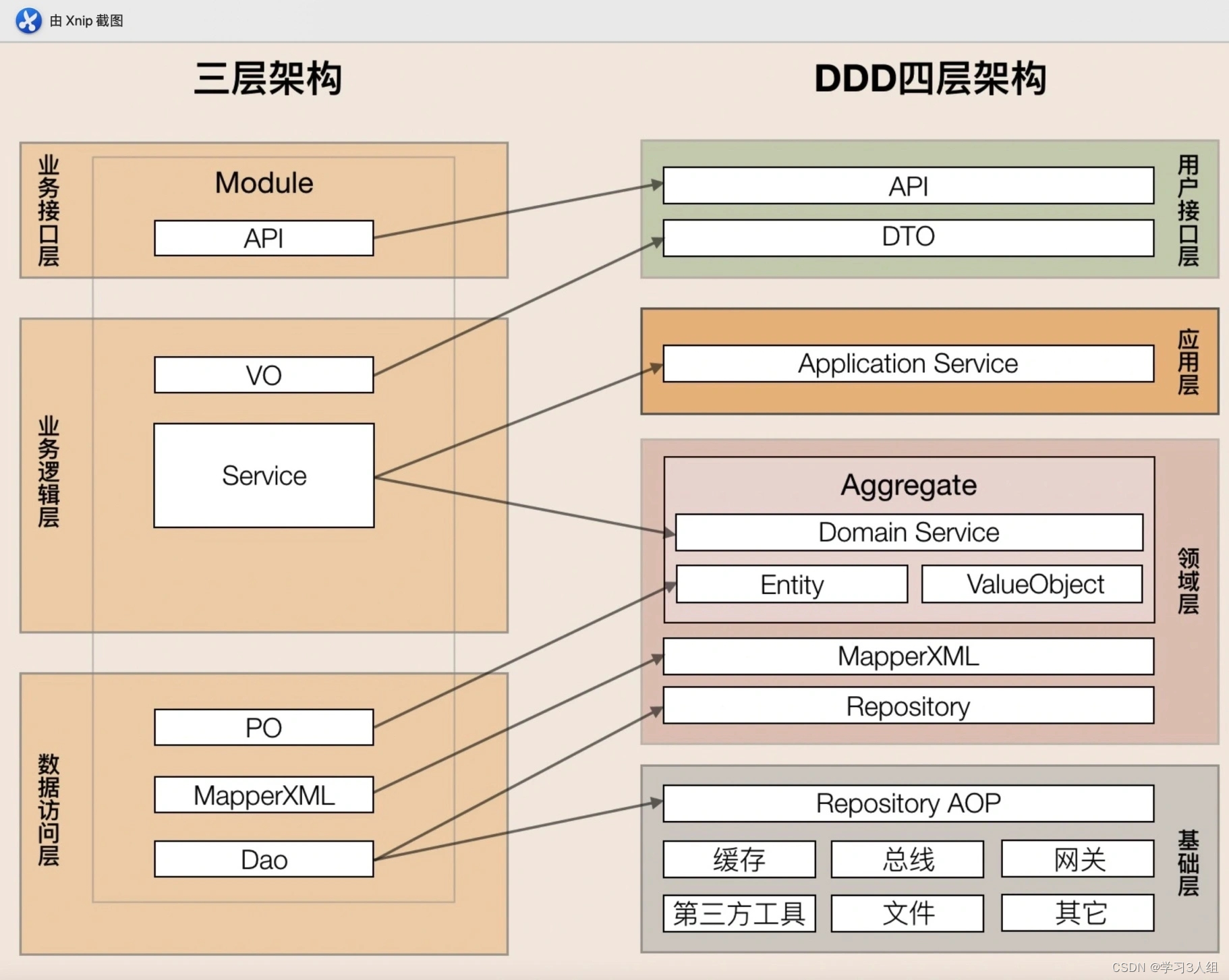
Relação com a arquitetura em camadas
Uma arquitetura em camadas é uma arquitetura de ponta a ponta ou a arquitetura interna de um único sistema, que é dividida em diferentes níveis de acordo com certas regras. J2EE também é um tipo de arquitetura em camadas.
Os microsserviços são a arquitetura da camada de negócios em uma arquitetura em camadas de ponta a ponta:
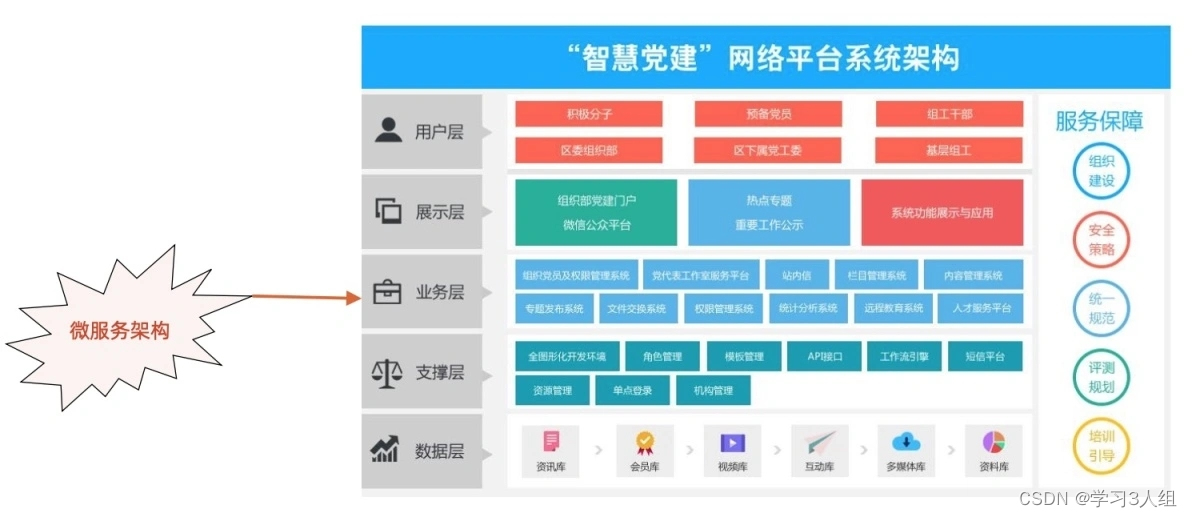
No "Curso Prático DDD", a arquitetura em camadas do DDD é dada diretamente
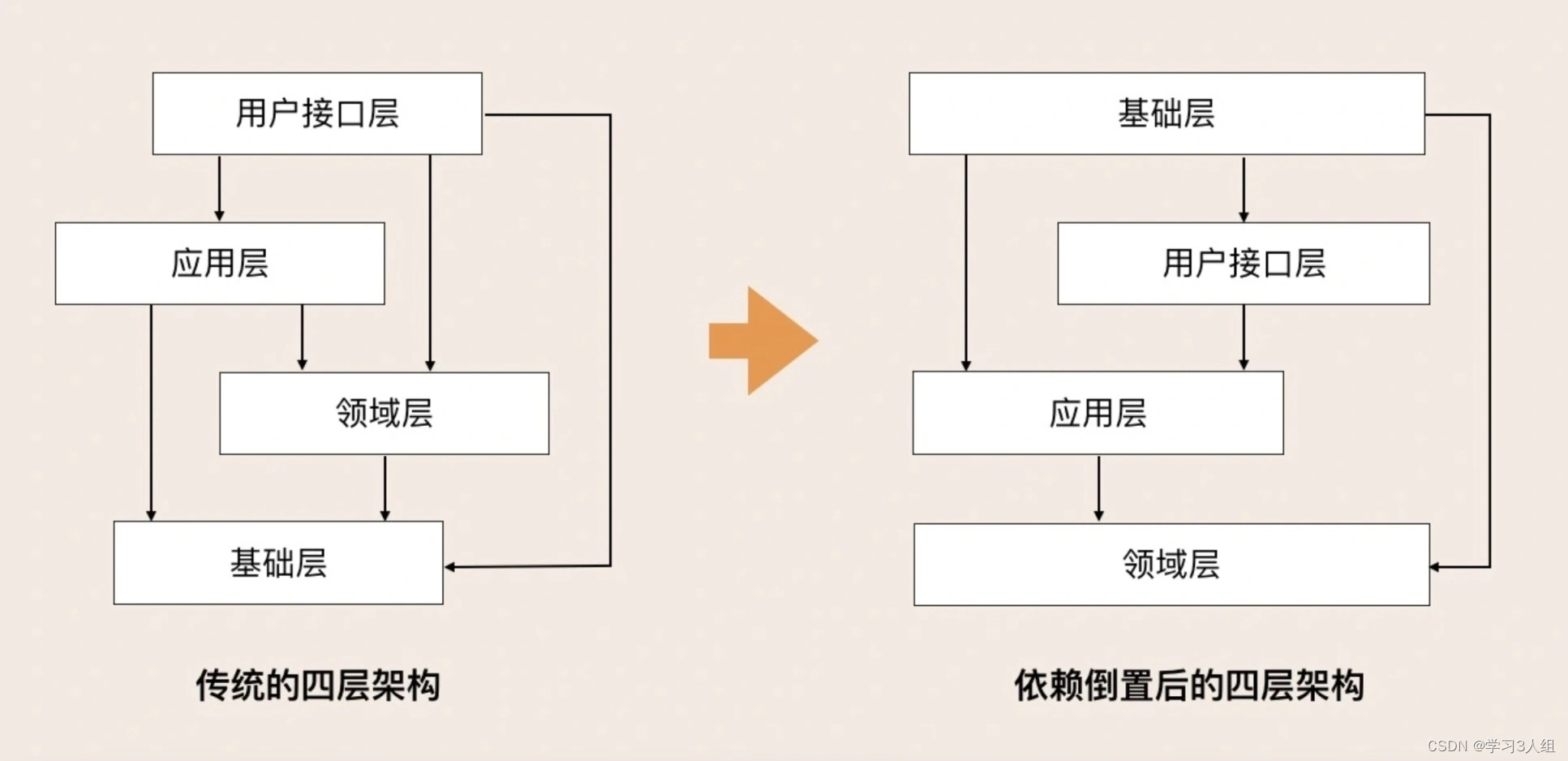
E compare a arquitetura de três camadas do serviço de back-end único com a arquitetura de quatro camadas acima
Relação com a Arquitetura Limpa
A arquitetura de um único microsserviço pode ser uma arquitetura limpa.
Relação com a arquitetura do microkernel
A arquitetura de um único microsserviço pode ser uma arquitetura de microkernel, como controle de risco, marketing e microsserviços de fluxo de trabalho.
O "Curso Prático DDD" também disponibiliza um modelo arquitetural para microsserviços - arquitetura hexagonal (também conhecida como "arquitetura do adaptador de porta")
Perguntas para reflexão
Em comparação com a arquitetura SOA, qual é o custo dos microsserviços ou quais são suas desvantagens?
Acho que o custo dos microsserviços é que o relacionamento entre os nós do sistema se torna muito complicado.Um negócio pode passar por muitos nós de serviço e uma conexão de malha é formada entre os nós. Mas SOA é diferente, ao introduzir o ESB como um nó intermediário, a conexão mesh é transformada em um link do tipo "hub-spoke".
Isso levou a mais conexões na arquitetura e a mais custos de comunicação na organização.
Armadilhas e desafios da arquitetura de microsserviços
Seis armadilhas principais
Pessoalmente, acho que essas armadilhas são causadas pelo aumento da complexidade do sistema causado pela conexão de rede geral dos microsserviços.
granularidade muito fina
1. Relacionamento de serviço complicado
Reduz a complexidade interna de um único serviço pequeno, mas aumenta a complexidade externa da conexão entre sistemas. Análise de requisitos, desenho da solução, testes, implantação... A dificuldade vai aumentar.
2. Diminuição da eficiência da equipe
Análise de requisitos, projeto de solução, teste, implantação... a carga de trabalho aumentará. Esse é o impacto na organização.
3. É difícil localizar o problema
A conectividade entre os nós é muito alta e a falha de um único nó causará problemas para muitos nós.
4. Declínio do desempenho do sistema
Quanto mais longa a cadeia de chamadas, mais demorado será para uma única solicitação. Após a divisão, o desempenho do processamento de um único serviço será melhorado, o que não pode compensar o consumo causado pela cadeia de chamadas. Como o principal fator que determina o consumo de tempo é a chamada do sistema de armazenamento, após a divisão em um único serviço, a melhoria de um único serviço é limitada; e o desempenho consumido na cadeia de chamadas excederá a melhoria de desempenho de um único serviço .
falta de infraestrutura
5. Incapaz de entregar rapidamente
Sem suporte de teste automatizado, um grande número de interfaces precisa ser testado para cada teste;
Sem suporte de implantação automática, operação e manutenção humana, as mãos ficam dormentes;
Sem monitoramento automatizado, cada local de falha requer verificação manual de vários estados e vários arquivos de log de dezenas de máquinas e centenas de microsserviços.
6. O gerenciamento de serviços é caótico
rota de serviço é necessária
precisa de isolamento de falhas
Requer registro e descoberta de serviço
Para as armadilhas acima, é necessário
granularidade adequada
Serviço básico perfeito
Quatro desafios da arquitetura de microsserviços
Desafios trazidos pela distribuição de dados
1. Os dados são distribuídos em diferentes nós de serviço, o que gerará coisas distribuídas
A agregação em microsserviços é a unidade básica de modificação e persistência de dados, e cada agregação corresponde a um warehouse para alcançar a persistência de dados;
Se entidades e objetos de valor forem entendidos como uma tabela de banco de dados ou um objeto de uma tabela de banco de dados, então a agregação é um banco de dados ou um esquema;
Se o serviço for entendido como regras mais dados, então porque a agregação tem um warehouse correspondente, a agregação corresponde teoricamente a um serviço.
Microsserviços e agregação não são um-para-um, mas um-para-muitos. A agregação pode ser migrada entre microsserviços conforme necessário, por exemplo, de acordo com as necessidades de negócios ou de acordo com os atributos de qualidade (migrar agregações altamente visitadas para microsserviços independentes) ou de acordo com o grau de alterações frequentes Separação (dividir serviços alterados frequentemente e serviços alterados com pouca frequência em diferentes serviços).
Forte consistência de dados dentro da agregação e consistência final de dados entre agregações;
O estado de no máximo um agregado pode ser alterado em uma transação.
2. É preciso garantir a idempotência global. Como as chamadas distribuídas podem falhar e repetir, a idempotência precisa ser garantida.
Desafios colocados pela distribuição de serviços
3. As interfaces precisam ser compatíveis
4. Para resolver os problemas causados pela chamada de loop de interface
Respondendo aos quatro grandes desafios de
BASE, CAP e linearizabilidade
Como mencionado acima, os dados na agregação não são fortemente consistentes, e os dados entre as agregações adotam o modelo de consistência final. Existe uma teoria BASE sobre consistência eventual.
BASE:Basically Available (basicamente disponível), Soft State (estado suave) e Eventualmente Consistente (consistência final). A consistência eventual é descrita pela teoria CAP de sistemas distribuídos.
O CAP consiste em três propriedades: Consistência, Disponibilidade e Tolerância de partição. Entre eles, a tolerância a falhas de partição refere-se a um problema na rede, que divide as máquinas originalmente conectadas pela rede em várias partes independentes, o que também é chamado de cérebro dividido.
Se você abrir mão da tolerância à partição, então é um banco de dados autônomo e é impossível abrir mão de P em um sistema distribuído. Sob a premissa de que as partições ocorrerão, você precisa escolher uma de consistência e disponibilidade, em vez de combinar as três propriedades em AP e CP. Escolha uma das três de CA e CA (CA é equivalente a um banco de dados independente).
Além disso, o C em CAP refere-se à linearizabilidade (Linearizability).Em um ambiente distribuído, não há apenas consistência e inconsistência, mas também outras opções no meio, como se é objetivamente consistente ou parece consistente.
A consistência do estado refere-se à consistência refletida no estado objetivo e real dos dados;
A consistência operacional refere-se à consistência dos dados que podem ser lidos por usuários externos por meio de operações acordadas pelo protocolo. Por exemplo, várias consistências de sessão, ou seja, parece consistente do cliente.
A consistência/linearização linear
vem do "Curso de Arquitetura Financeira Distribuída".
O nome em inglês de consistência linear é Linearizability. A consistência linear é a consistência mais importante em sistemas distribuídos. Pode-se entender que a consistência linear é Serializabilidade em um ambiente distribuído.
serializável
Várias transações no banco de dados podem ser executadas simultaneamente e a serialização especifica os resultados dessas transações em execução simultânea, o que requer que os resultados finais dessas transações executadas simultaneamente sejam sempre iguais aos resultados de sua execução sequencial.
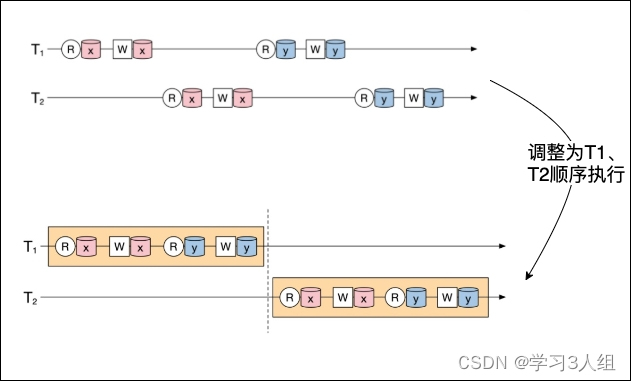
Conforme acima, após ajustar a ordem de execução das transações T1 e T2, não há sobreposição de tempo entre essas duas transações. Neste momento, essas duas transações são executadas sequencialmente.
Ao mesmo tempo, após ajustar a ordem de execução das transações, os resultados finais de leitura e gravação são exatamente os mesmos de antes do ajuste.
Finalmente, este resultado de ajuste não é único.
Serialização de conflito
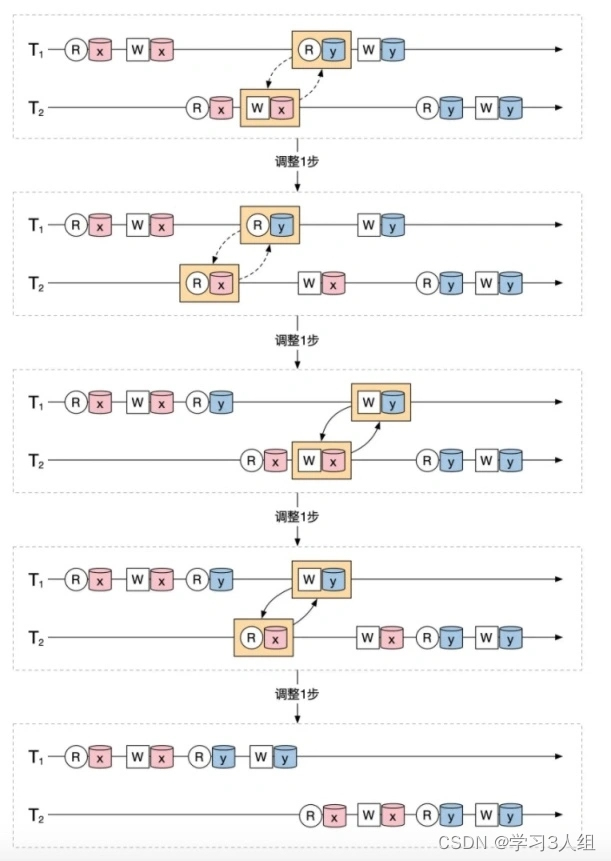
"Conflito" refere-se aos três conflitos de ler e escrever, ler e escrever e escrever e escrever. A serialização conflitante ainda requer o resultado de ser equivalente à serialização de uma transação. Mas não é o mesmo que serialização. A serialização exige apenas que você encontre um resultado serial equivalente, enquanto a serialização de conflito exige que você altere a sequência de execução original por meio de uma série de processos de intercâmbio sem conflito para uma execução serial equivalente.
Se não houver conflito entre as duas operações, sua ordem pode ser trocada, também conhecido como processo de troca sem conflito. Existem dois casos de não conflito
Os objetos das duas operações são diferentes
Ambas as operações são operações de leitura
Um exemplo é o seguinte:
No processo de implementação do banco de dados, a ordem de execução das transações geralmente é ajustada por meio de bloqueios, e o uso de bloqueios geralmente pode alcançar a serialização de conflitos. A forma de conseguir a serialização através de bloqueios é chamada de 2PL (Two Phase Lock).
2PL (Bloqueio de duas fases)
O processo de 2PL é muito simples. Requer que para qualquer transação, esta transação primeiro bloqueie todos os recursos acessados, depois acesse todos os recursos e finalmente libere todos os bloqueios. O processo de bloqueio e desbloqueio não pode ser alternado.

O processo de alteração do número de bloqueios no processo 2PL (o seguinte é o processo mais geral e existem outras variantes, como a seguinte, o MySQL usa uma variante), o que significa que os bloqueios são adquiridos continuamente sob demanda até que as Operações possam só pode ser executado depois que todos os bloqueios forem mantidos.
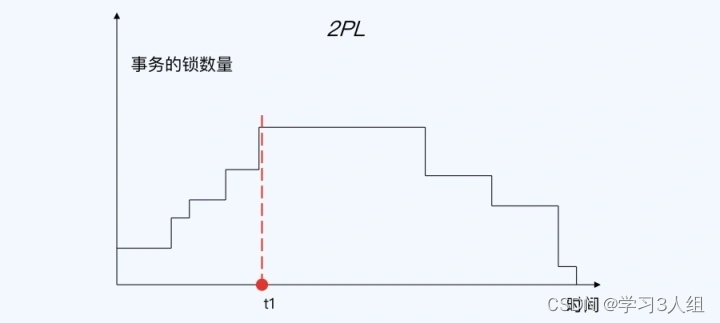
Serialização de conflito usando 2PL
O princípio básico é que a transação bloqueada primeiro tem um bloqueio e a transação subsequente não pode gravar no mesmo recurso sem manter o bloqueio, ou seja, não há conflito entre as duas transações, portanto, elas são naturalmente intercambiáveis Ordem de execução, alcançando assim a serialização de conflito.
Porque pode haver mais de um bloqueio mantido, mais especificamente: antes da primeira transação liberar o primeiro bloqueio, ele não tem conflito com todas as operações de todas as outras transações, portanto pode ser trocado por meio de operações sem conflito Procedimento que avança todas as operações de a primeira transação antes de outras transações. Desta forma, podemos separar a primeira transação das transações restantes.
O 2PL exige que saibamos com antecedência quais são todos os dados acessados, para que possamos bloquear tudo antes de desbloqueá-lo. Depois de liberar qualquer bloqueio, não podemos mais adicionar outros recursos bloqueados, que é a limitação do 2PL.
Mas o MySQL parece ter melhorado no fato de que deve ser conhecido com antecedência e bloqueia sob demanda.
Bloqueio de dois estágios no MySQL (o conteúdo é resumido de "45 Lectures of MySQL Actual Combat", "30 Lectures of Distributed Database")
Como o exemplo a seguir

Na figura acima, o comando update da transação B será bloqueado, pois na transação InnoDB, o bloqueio de linha é adicionado quando necessário, mas não é liberado imediatamente quando não é necessário, mas não é liberado até o final da transação . Também é um protocolo de bloqueio de duas fases, ou um protocolo de bloqueio de duas fases estrito variante (Strict 2PL, S2PL, ou seja, a transação sempre mantém todos os bloqueios de gravação adquiridos até que a transação seja encerrada), como segue
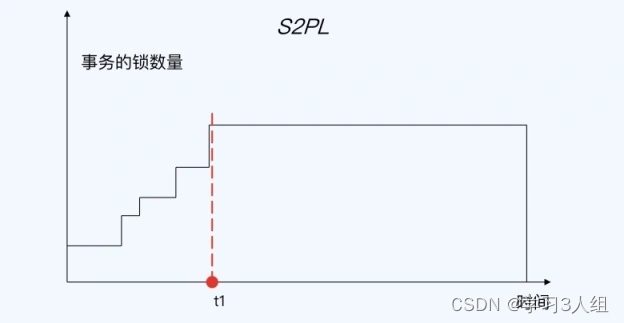
Portanto, se várias linhas precisarem ser bloqueadas em uma transação, os bloqueios com maior probabilidade de causar conflitos de bloqueio e afetar a simultaneidade devem ser colocados o mais longe possível. Por exemplo, o cenário de negócios de compra de ingressos de cinema:
-
Deduzir o preço do ingresso de cinema do saldo da conta do Cliente A;
-
Adicione o preço do ingresso de cinema ao saldo da conta do teatro B;
-
Mantenha um registro de transações.
Imagine se houver outro cliente C que deseja comprar um ingresso no teatro B ao mesmo tempo, então a parte do conflito entre essas duas transações é a declaração 2. Como eles desejam atualizar o saldo da mesma conta do teatro, eles precisam modificar a mesma linha de dados.
De acordo com o protocolo de bloqueio de duas fases, não importa como você organiza a ordem das instruções, os bloqueios de linha exigidos por todas as operações são liberados quando a transação é confirmada. Portanto, se você organizar a declaração 2 no final, por exemplo, na ordem de 3, 1, 2, o tempo de bloqueio da linha do saldo da conta do teatro será o menor. Isso minimiza a espera de bloqueio entre as transações e melhora a simultaneidade.
consistência linear
A serialização é um programa autônomo que ajusta a ordem de execução de várias transações, de modo que uma ordem razoável possa ser encontrada, de modo que os resultados da execução sequencial de transações simultâneas sejam consistentes com os resultados especificados pelas transações simultâneas.
E a consistência linear é o ambiente de vários programas, ajustando os horários de início e término de diferentes operações do programa para que não haja sobreposição de tempo entre essas operações.
A consistência linear também possui um requisito de ajuste de tempo, ou seja, se não houver sobreposição de tempo entre duas operações, a sequência de tempo entre essas duas operações não poderá ser alterada. Ao mesmo tempo, também é necessário verificar a exatidão dos resultados ajustados
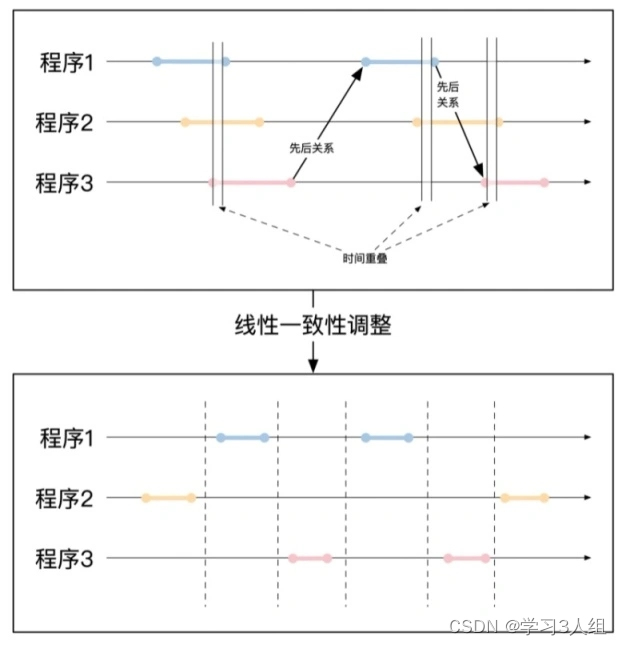
serialização estrita
A consistência mais forte no caso autônomo é a serialização, e a consistência mais importante no caso distribuído é a linearização. Em seguida, combine os dois para obter a consistência mais forte no caso distribuído, o que é chamado de serialização estrita (Strict Serializability).
Serializável significa que os resultados da execução de todas as operações em duas transações são equivalentes a um determinado resultado de execução de sequência dessas duas transações. Não há limitação em "um certo" aqui.
A serialização estrita faz provisões para esse "alguém", que requer que os resultados da execução de duas transações sejam equivalentes ao único resultado da execução sequencial. Nesse resultado, a transação de quem termina primeiro, então no caso de execução sequencial, todas as operações de quem termina primeiro.
Embora a serialização estrita tenha uma forte garantia de exatidão, sua eficiência operacional é extremamente baixa, por isso geralmente é raramente usada.
Transações distribuídas em nível de negócios - mensagens de transações locais
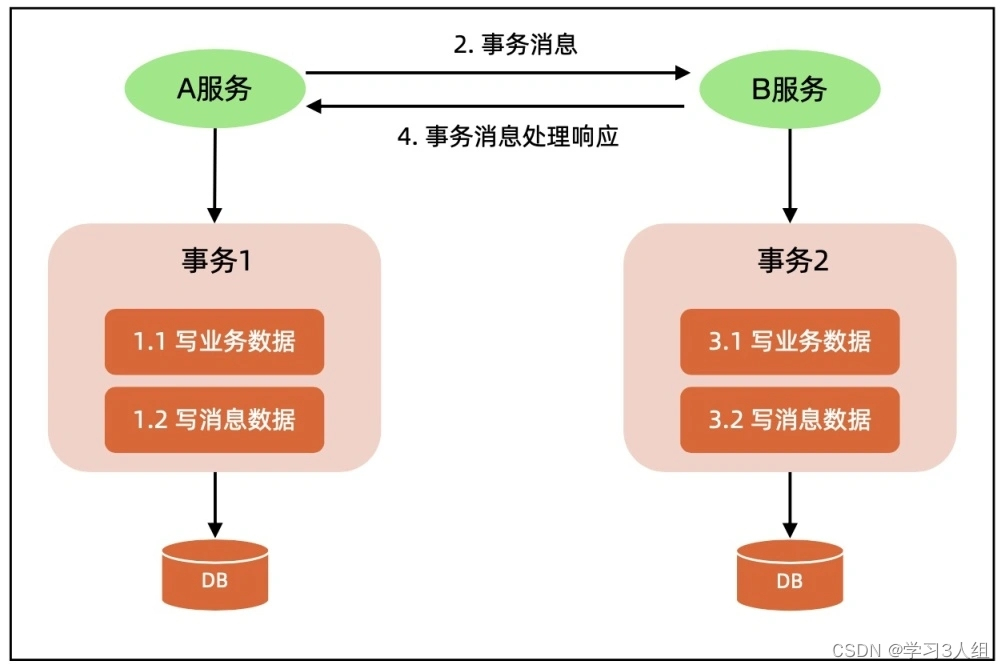
A chave é colocar os dados de negócios de gravação e os dados de mensagem de gravação na mesma transação local para garantir que ambos sejam bem-sucedidos ou falhem e, em seguida, contar com o encadeamento de segundo plano para tentar novamente continuamente para garantir que os dados da mensagem sejam enviados para outro serviço e executados com êxito .
Além de gravar dados de negócios, o serviço A também gravará dados de mensagem na tabela e, em seguida, um thread em segundo plano lerá continuamente os dados da mensagem e os enviará ao serviço B, para que o serviço B possa modificar os dados; esse thread em segundo plano está em sincronização com MySQL mestre/escravo/mestre-escravo O dumpthread do nó mestre é muito semelhante ao
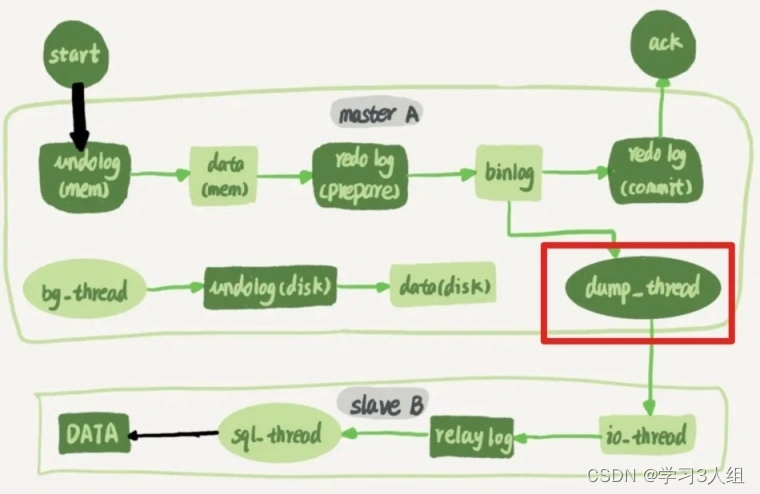
Depois que o serviço B recebe a mensagem de transação, ele também executa a gravação de dados de negócios e dados de mensagem ao mesmo tempo.Os dados da mensagem contêm o resultado da execução da mensagem de transação. Em seguida, envie a resposta de processamento da mensagem de transação para o serviço A.
Se "2. Mensagem de transação" for perdida, um serviço continuará tentando;
Se "4. Resposta de processamento" for perdida, um serviço continuará tentando;
O serviço B recebe a 2. mensagem de transação repetidamente e depois verifica se a tabela de mensagens foi processada. Se foi processada, retornará diretamente o resultado do processamento e, se não tiver sido processada, será processada normalmente (idempotente ).
Transações distribuídas em nível de negócios - mensagens de transação de fila de mensagens
É muito semelhante às mensagens de transação local, exceto que as mensagens são colocadas na fila de mensagens. O funcionamento do RocketMQ foi dado na aula do Andy:
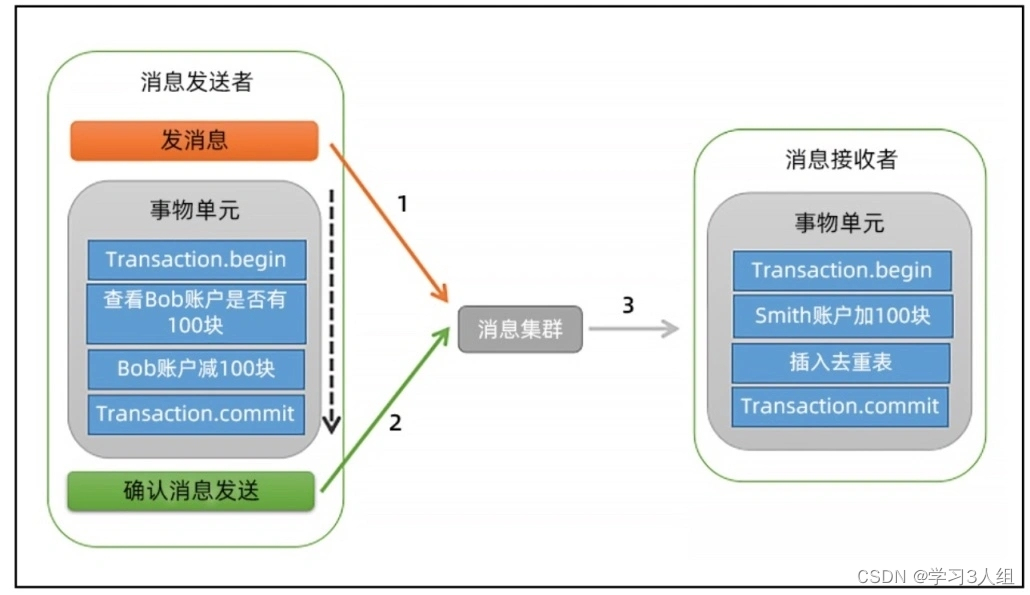
Ao enviar uma mensagem Preparada, você receberá o endereço da mensagem;
realizar transações locais;
Modifique o status da mensagem através do endereço obtido em 1;
O RocketMQ verificará periodicamente as mensagens de transação no cluster de mensagens. Se encontrar uma mensagem preparada, confirmará ao remetente da mensagem e o RocketMQ decidirá se reverterá ou continuará a enviar mensagens de confirmação de acordo com a política definida pelo remetente.
O princípio mais geral é o seguinte. (Citado da quarta palestra do "Message Queue Master Course": "Como usar mensagens de transação para implementar transações distribuídas?")
A essência é a mesma da "mensagem de transação local", que também garante que a execução de transações locais e o envio bem-sucedido de mensagens de transação serão bem-sucedidos ou falharão. A diferença é que a "mensagem de transação local" é resolvida por uma nova tentativa e a fila de mensagens é implementada contando com o nível de isolamento **"leitura confirmada" (isso é resumido por mim, que não está escrito no texto original), e a fila de mensagens transporta O nível de isolamento "leitura confirmada" é meia mensagem**.
Uma meia mensagem não significa que o conteúdo da mensagem está incompleto, ela contém o conteúdo completo da mensagem.A única diferença entre uma meia mensagem e uma mensagem normal é que a mensagem é invisível para os consumidores antes que a transação seja confirmada.
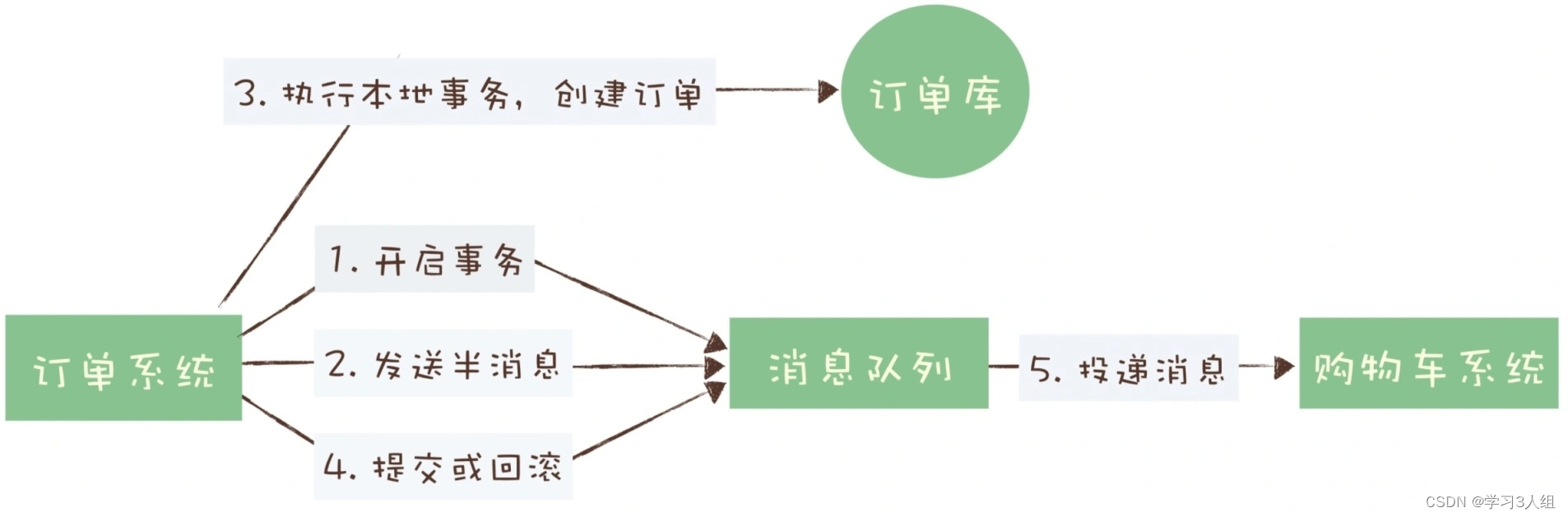
Se o pedido for criado com sucesso, envie a mensagem de transação e o sistema de carrinho de compras pode consumir essa mensagem para continuar o processo subsequente.
Se a criação do pedido falhar, a mensagem da transação será revertida e o sistema de carrinho de compras não receberá a mensagem.
Dessa forma, o requisito de consistência de "todos são bem-sucedidos ou ambos falham" é basicamente realizado.
E se houver uma falha na confirmação da mensagem de transação na quarta etapa?
A solução de Kafka é relativamente simples e rude, lançando uma exceção diretamente e deixando o usuário manipulá-la sozinho. Podemos repetir o envio repetidamente no código comercial até que o envio seja bem-sucedido ou excluir o pedido criado anteriormente para compensar.
Na implementação da transação no RocketMQ, um mecanismo de verificação reversa da transação é adicionado para resolver o problema de falha no envio da mensagem da transação. Se o produtor for o sistema de pedidos e ocorrer uma exceção de rede quando a mensagem da transação for enviada ou revertida, e o Broker do RocketMQ não receber a solicitação de envio ou rollback, o Broker verificará regularmente o status da transação local correspondente à transação no Produtor e, em seguida, de acordo com os resultados da verificação reversa, é decidido confirmar ou reverter a transação.
Para oferecer suporte a esse mecanismo de anti-verificação de transação, nosso código de negócios precisa implementar uma interface para o status de transação local anti-verificação para informar ao RocketMQ se a transação local foi bem-sucedida ou falhou. O RocketMQ confirmará ou reverterá automaticamente a mensagem da transação de acordo com o resultado da verificação reversa da transação.
Transações distribuídas em nível de negócios - TCC
registra principalmente os seguintes pontos:
É permitido cancelar uma transação inexistente, também chamada de rollback vazio. No momento, o método Try não recebeu um timeout devido a problemas de rede, e o gerenciador de transações emitirá um comando Cancel neste momento, portanto, ele precisa oferecer suporte ao Cancel para poder cancelar normalmente sem executar o Try.
Anti-enforcamento. O método Try aciona o gerenciador de transações para emitir o comando Cancel devido ao tempo limite de congestionamento da rede, mas depois que o comando Cancel é executado, a solicitação Try chega. Obviamente, o comando Try não deve ser executado neste momento. Como saber se ele deve ser executado? Veja o próximo item.
Cancel é seguido por Try. Para o gerenciador de transações, a transação termina neste momento, e a operação Cancel é "suspensa". Portanto, um rollback vazio precisa deixar um registro no sistema para evitar a re-invocação de Try.
Existem várias variantes do TCC:
TCC padrão
TCC sem tentar
TCC assíncrono
O TCC assíncrono é muito semelhante às mensagens de transação local e mensagens de transação de fila de mensagens. Durante Try, as mensagens são apenas escritas e não podem ser consumidas. Confirm é a operação de realmente enviar mensagens e Cancel é para cancelar o envio de mensagens. Isso é meio -mensagem.
Idempotência global A idempotência global
garante que cada operação idempotente seja globalmente exclusiva.
chave de design
ID exclusivo globalmente
máquina de estado
Compatibilidade de interface
Algumas interfaces de um microsserviço são atualizadas e os microsserviços que dependem dessas interfaces podem não ser todos atualizados ao mesmo tempo.
Solução:
Existem várias versões da interface, copie diretamente um código de interface antigo, modifique-o no código de interface antigo e adicione v1/v2 ao URL da interface;
Isso também tem algo a ver com a estrutura organizacional.Na empresa atual, a atualização da interface principal é forçar todos os sistemas dependentes a serem atualizados.
Andy enfatizou especificamente que copiar o código neste momento não é um princípio DRY. devido a esta:
Não afeta a funcionalidade existente;
É mais conveniente quando a interface antiga está offline e testes desnecessários podem ser evitados.
A lógica da interface é compatível, o mesmo código de interface é compatível com a lógica antiga e a nova, e é fácil afetar um ao outro, e o código precisa ser modificado quando a interface antiga está offline (não recomendado).
Chamada cíclica de interface
Por exemplo, durante um processo de negócios, A chama B e B chama A novamente, e o processamento de A entra na lógica de processamento anterior, resultando em chamadas cíclicas e todo o negócio entra em um loop infinito.
Solução: Quase não há boas soluções. Se você tiver sorte, poderá encontrá-la testando. Se não tiver sorte, poderá encontrá-la acessando a Internet.
Perguntas para reflexão
Lembre-se de quais armadilhas e desafios técnicos você encontrou no curso no trabalho e pense sobre quais são os principais motivos.
Que pena, o microsserviço da empresa acabou de começar...
Seleção de infraestrutura de microsserviço
Infraestrutura de microsserviço e sua prioridade
Existem 20 módulos no total, e o diagrama de classificação é o seguinte. A caixa verde é o núcleo da estrutura de microsserviço.
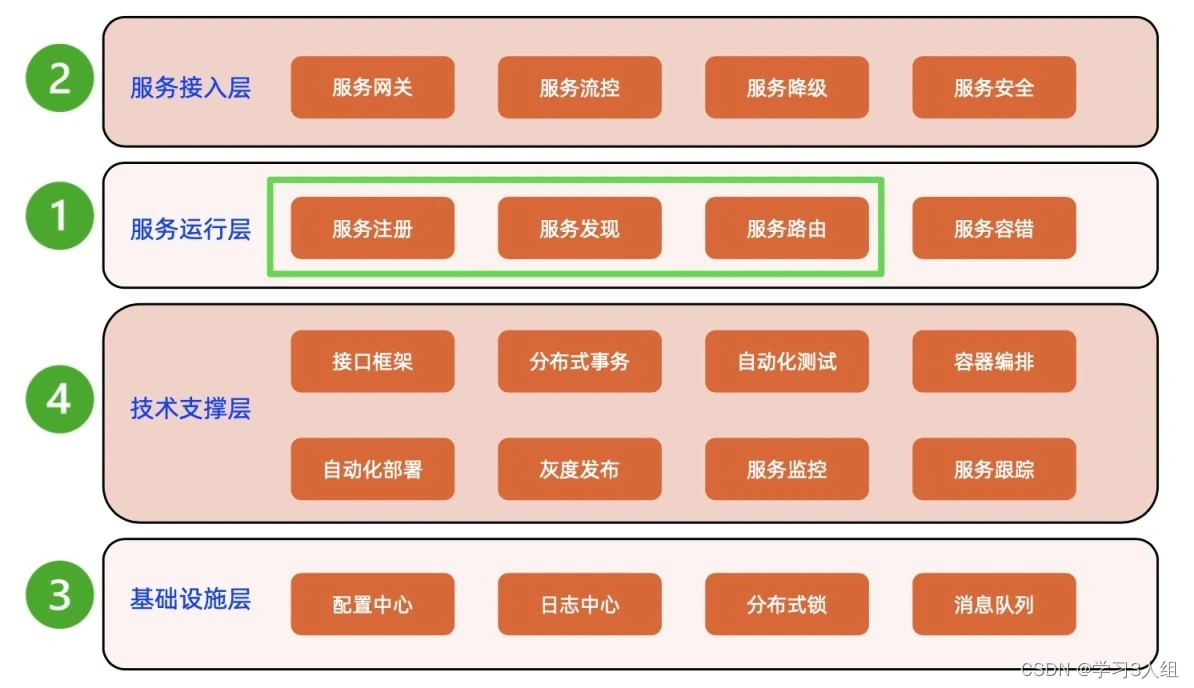
Modo de estrutura de microsserviço (núcleo)
Estilo de SDK incorporado
Como Dubbo e Spring Cloud.
proxy reverso
Como APISIX.
Proxy de rede (Service Mesh)
Como o Ístio.
Pode-se ver que o que a grade de serviço tem em comum com Spring Cloud ou Dubbo é que há uma sobreposição relativamente grande no registro de serviço, descoberta de serviço e roteamento de serviço. Então eles são comparados juntos.
Cada modo não é registrado separadamente, grave diretamente o gráfico de comparação
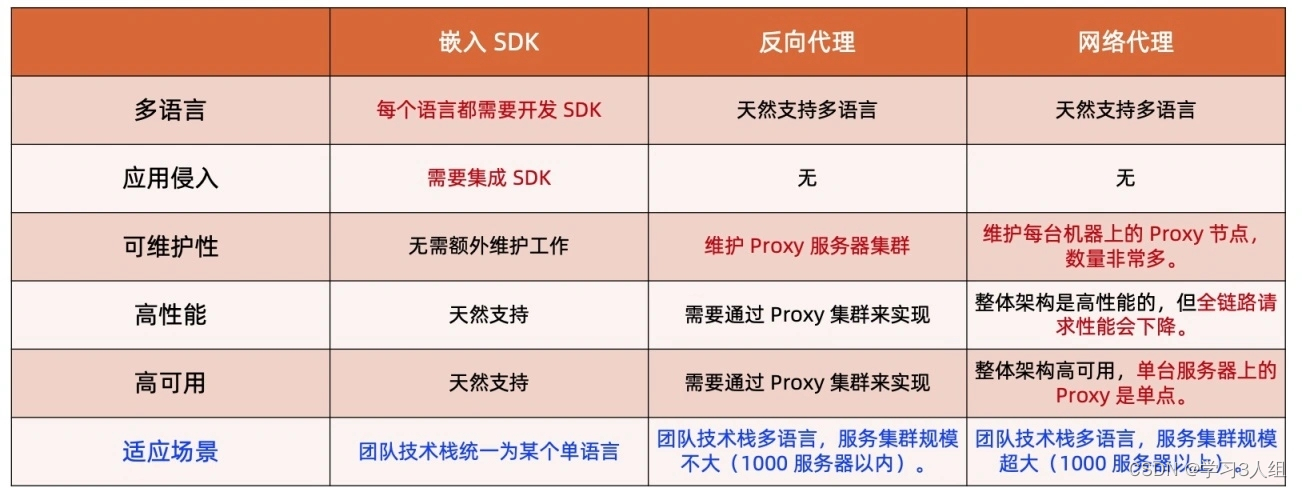
Como escolher um framework de microsserviços de código aberto
Questões para reflexão
Como a infraestrutura de microsserviços é mais complicada do que ESB, qual é a necessidade de microsserviços?
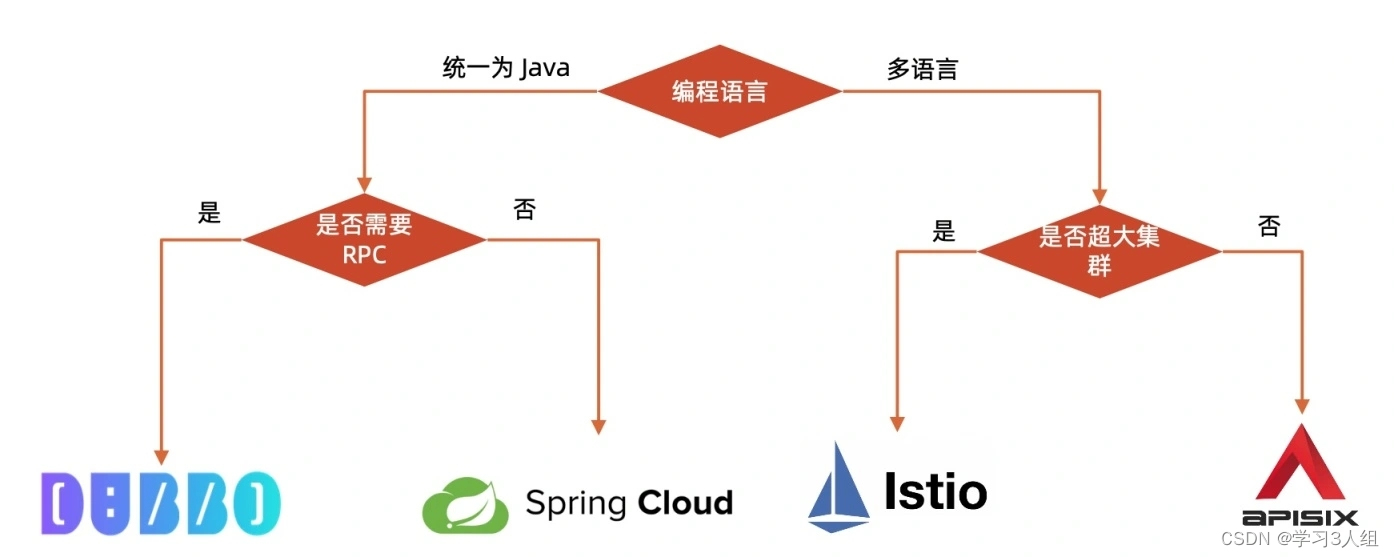
Como os microsserviços foram desenvolvidos e a tecnologia da Internet penetrou nas indústrias tradicionais, é impossível voltar atrás e se engajar em SOA novamente.
Habilidades de divisão de microsserviços
Três elementos relacionados à
habilidade Método de divisão Método de implementação
de infraestrutura Sugestões de implementação
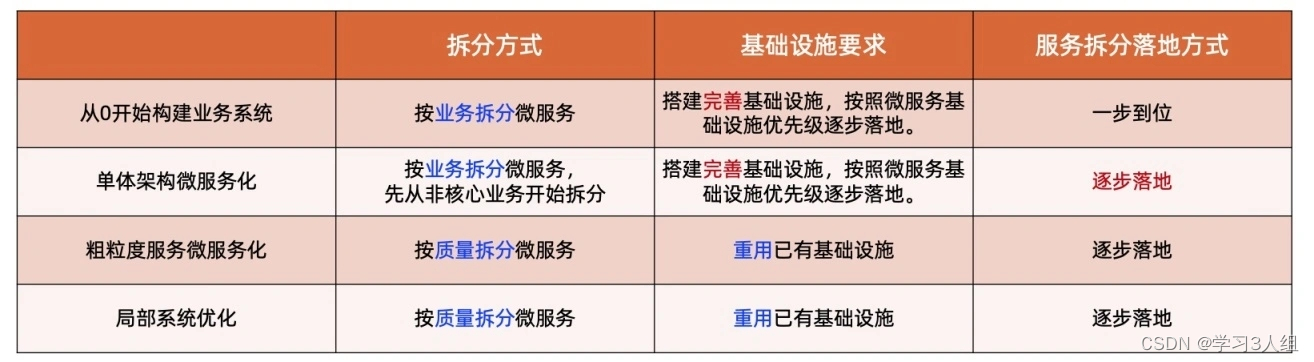
A tabela acima pode concluir que a divisão de microsserviços também segue os três princípios da arquitetura - o princípio da adequação, o princípio da evolução e o princípio da simplicidade. Ao mesmo tempo, também resolve a complexidade da arquitetura primeiro e então melhora a qualidade da arquitetura:
Ou seja, a divisão de microsserviços também exige primeiro a busca pela correção e depois a busca pela otimização
Se for um novo microsserviço (incluindo a construção de um sistema de negócios do 0 e a transformação de um único microsserviço), ele deve ser dividido de acordo com o negócio, porque o serviço em si é um conceito de negócio, que é realizado sob a orientação de DDD e DDD é exatamente Comece com negócios. (princípio da adequação)
Se for para otimizar microsserviços, pode ser dividido de acordo com a qualidade (princípio evolutivo)
infraestrutura é imprescindível
Ao criar um novo microsserviço, uma nova infraestrutura precisa ser construída, mas a infraestrutura também tem prioridades e deve ser implementada gradualmente de acordo com as prioridades (princípio simples, princípio evolutivo)
Ao otimizar microsserviços, reutilize a infraestrutura existente (princípio do ajuste)
Existem duas maneiras de implementar serviços (princípio da adequação, princípio da evolução)
completo em uma etapa
A abordagem de uma etapa é adotada ao construir um novo edifício.
passo a passo
Especialmente ao transformar uma única arquitetura, comece com módulos de negócios não essenciais
Explicação detalhada do método de divisão
Divisão de microsserviços de acordo com o negócio
Dificuldades em DDD
Teoricamente, a metodologia DDD deve ser usada para orientação.
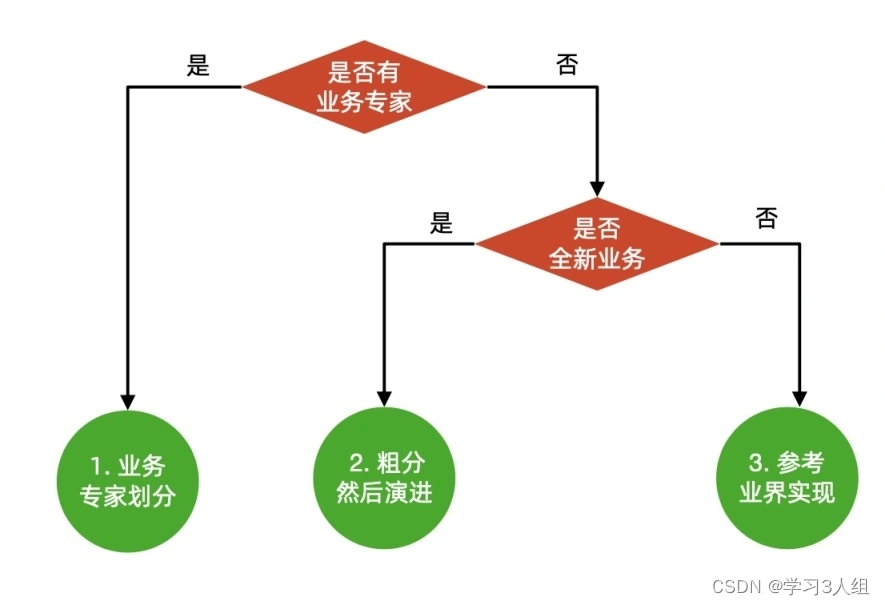
Mas o DDD é difícil de implementar porque:
A determinação da divisão do contexto limitado depende da influência de especialistas em negócios.
O contexto limitado é na verdade o "limite da equipe"
Os contextos limitados também são afetados pelas condições da equipe, como o tamanho da equipe
Em suma, é mais afetado pela forma organizacional.
O processo real de divisão de limites de negócios
O processo real de divisão não é DDD, mas o seguinte:
Observe que ele deve ser dividido grosseiramente primeiro e depois evoluído, não subdividido primeiro e depois mesclado. Por causa deste último:
Em primeiro lugar, a carga de trabalho será muito grande: para garantir o funcionamento correto e eficiente do negócio de microsserviços, é necessária uma grande quantidade de infraestrutura.
Em segundo lugar, a fusão em si é mais difícil do que a divisão gradual.
A relação correspondente entre o domínio de negócios real e o serviço - o conceito de divisão de serviço
DDD, existem os seguintes conceitos de baixo para cima, de pequeno a grande:
Entidade (a classe de entidade do modelo de hiperemia, uma entidade pode corresponder a 0, 1 ou mais objetos persistentes do banco de dados, a capacidade de realizar negócios individuais), objeto de valor (a classe correspondente ao objeto de anemia)
polimerização. Entidades e objetos de valor formam agregados. A lógica de negócios em várias entidades é implementada por meio de serviços de domínio, que ficam em agregados.
A agregação é a unidade básica de modificação e persistência de dados. Cada agregação corresponde a um warehouse para alcançar a persistência de dados: se entidades e objetos de valor são entendidos como uma tabela de banco de dados ou um objeto de uma tabela de banco de dados, então a agregação é um banco de dados ou um esquema .
Se o serviço for entendido como regras mais dados, porque a agregação tem um warehouse correspondente, a agregação corresponde teoricamente a um serviço, mas o microsserviço e a agregação não estão na forma um-para-um, mas existem vários relacionamentos, ou seja, um microsserviço Várias agregações podem estar contidas. Portanto, existem vários tipos de correspondência entre domínios de negócios e serviços. Na verdade, eles descrevem a granularidade da divisão do microsserviço, e o tamanho da granularidade deve seguir o princípio da adequação - deve ser adequado à situação atual da equipe. Consulte " O caso dos três mosqueteiros" ".
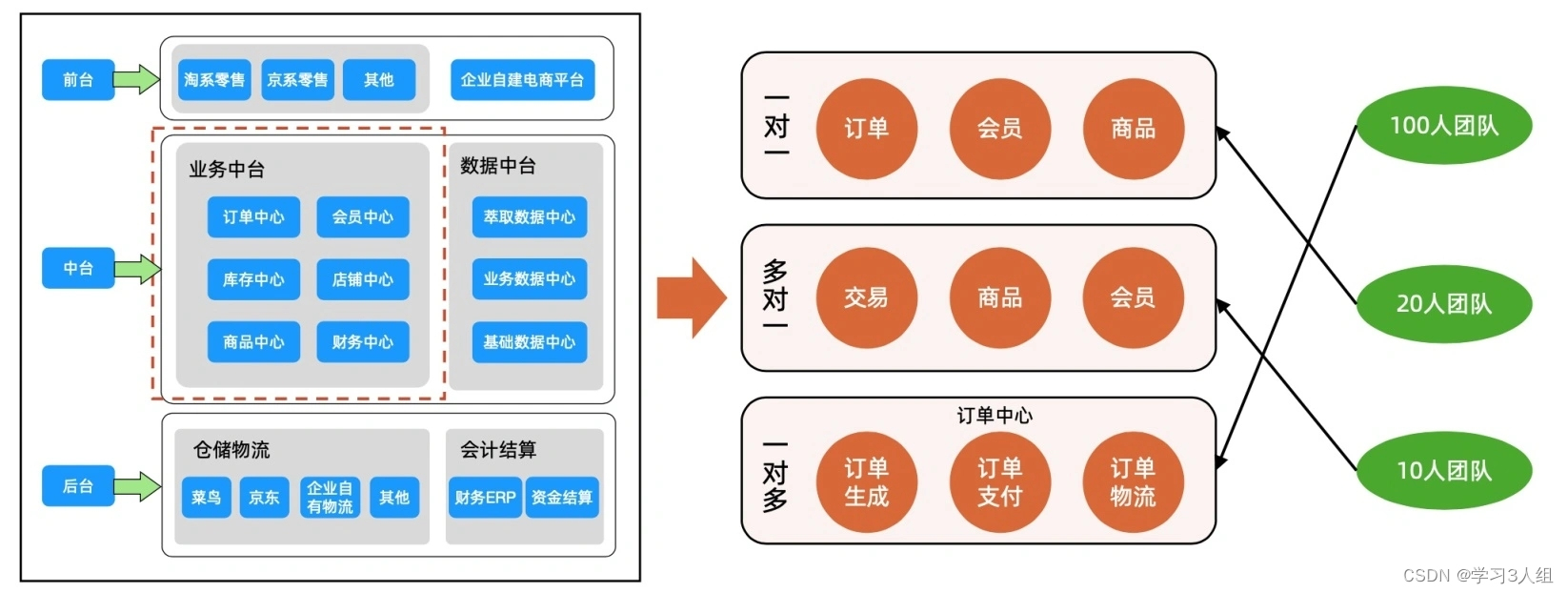
One-to-one: cada domínio de negócio corresponde a um microsserviço
Muitos para um: vários domínios de negócios são tratados por um microsserviço
Um-para-muitos: divisão de processos de negócios, listando o fluxo de processamento das principais funções de negócios e tomando as etapas de processamento no processo como a dimensão da divisão.
Além disso, a agregação também tem limites de contexto, e o modelo de domínio pode orientar o design de microsserviços para cima usando o contexto limitado, e o design de raízes agregadas, entidades e objetos de valor pode ser guiado para baixo por meio da agregação.
Finalmente, os dados dentro da agregação são fortemente consistentes e os dados entre as agregações são eventualmente consistentes.
A descrição acima pode ser resumida com a foto de Hua Tsai:

Definição do Princípio dos Três Mosqueteiros
: Em média, 3 desenvolvedores são responsáveis por um microsserviço.
Por que não sozinho?
Porque não há backup de pessoal e o pensamento de uma pessoa é limitado.
Por que não 2?
2 pessoas são responsáveis por manter um microsserviço e a complexidade do microsserviço é baixa. Não propício ao crescimento profissional pessoal!
Por que não 4 ou 5?
Se houver 4 ou mais, todos podem não conseguir entender todos os detalhes de um único serviço.
Número de microsserviços = número de desenvolvedores no lado do servidor/3;
Para serviços no período de manutenção, pode haver 2 funcionários de manutenção.
O caso dos três mosqueteiros
Dividir microsserviços por qualidade
significa migrar e mesclar agregados entre microsserviços conforme necessário.
Divida de acordo com o desempenho
Divida o negócio com o maior tráfego e o negócio com forte correlação para reduzir o grau de influência mútua do negócio, otimize o negócio com grande tráfego após a divisão, melhore o desempenho e reduza os custos.
Divida de acordo com a importância do negócio
Separe os negócios com alta importância (alta importância não significa necessariamente alto tráfego) para reduzir a influência mútua do negócio e melhorar a disponibilidade do negócio de alta importância após a divisão.
Divida de acordo com a disponibilidade
Divida o negócio que costuma apresentar problemas para reduzir o grau de interação comercial e, após a divisão, melhore o negócio com muitos problemas de maneira direcionada.
Dividir de acordo com a estabilidade
Dividir negócios estáveis para reduzir o grau de influência mútua entre os negócios. Após a divisão, é propício para uma rápida iteração de negócios em constante mudança.
Questões para reflexão
Ao dividir microsserviços de acordo com atributos de qualidade, precisamos seguir o princípio dos três mosqueteiros?
Ainda precisa ser seguido. Porque o objeto de divisão neste momento ainda é vários serviços comerciais, e a construção de serviços comerciais deve seguir os três mosqueteiros.
Análise aprofundada e habilidades de implementação
da plataforma intermediária O surgimento da plataforma intermediária é para lidar com a complexidade dos negócios.
O processo de desenvolvimento da arquitetura compartilhada
Não há arquitetura compartilhada, "há muitas chaminés", e elas são desenvolvidas repetidamente;
Recursos compartilhados - arquitetura Iaas;
Tempo de execução compartilhado, middleware, banco de dados, etc.
SaaS, todo o aplicativo é compartilhado.
Estrutura intermediária. Diferente de IaaS, PaaS e SaaS, ele compartilha o mesmo negócio e dados em cada negócio.
Compreendendo o conceito de Zhongtai
Hua Tsai apontou que existem dois tipos de Zhongtai - Zhongtai de negócios e Zhongtai de dados.
Plataforma intermediária de negócios A plataforma intermediária de negócios é um modelo de arquitetura que deposita os recursos gerais de negócios de vários negócios semelhantes em uma empresa na plataforma para reduzir a construção redundante e melhorar a eficiência do desenvolvimento de negócios . Três pontos-chave:
relacionado aos negócios. Isso distingue middle office de IaaS, PaaS de SaaS.
em vários negócios.
Várias empresas são semelhantes. Portanto, as empresas que são muito diferentes não podem ser forçadas a entrar no middle office.
Data center
Data center é um modelo de arquitetura que deposita todos os dados de negócios de uma empresa na mesma plataforma, oferece suporte à conexão e reutilização de dados entre empresas e melhora a eficiência operacional da empresa. Os três pontos principais são os seguintes
todos os negócios. O data center deve oferecer suporte a todos os negócios.
Os dados estão conectados. Dados entre empresas precisam estar conectados.
Reutilização de dados. Os dados entre diferentes empresas podem ser reutilizados para melhorar a eficiência operacional geral. A parte mais difícil das três, porque os dados são distribuídos em diferentes negócios, a diferença é relativamente grande e é difícil reutilizá-los entre os negócios.
O valor da plataforma intermediária
Plataforma intermediária de negócios. Seu valor reside no fato de que empresas semelhantes podem alavancar umas às outras e compartilhar recursos, evitando assim um grande número de desenvolvimentos repetidos e melhorando a eficiência do desenvolvimento. Portanto, quanto maior a similaridade de negócios, maior o valor de Taiwan no negócio. Hua Tsai sugeriu que várias empresas com uma similaridade de mais de 60% construíssem um middle office em conjunto.
Centro de dados. Seu valor está na conexão e reutilização de dados, evitando ilhas de dados e melhorando a eficiência operacional.
Quanto mais empresas usarem o data center, maior será o valor do data center.
O valor do data center se reflete em: plataforma de dados unificada, conexão de dados entre empresas e reutilização de dados entre empresas (mineração).
Mas a reutilização de dados nas empresas é difícil. A análise de dados é um processo de descoberta e extração de regras, e as diferenças entre os negócios são muito grandes. Como definir a meta de reutilização de dados é uma meta difícil por si só. Por exemplo, dois departamentos de negócios têm diferentes linguagens de negócios e modos de pensar, como extrair a correlação de dados? A comunicação é um grande problema.
O problema trazido pela plataforma intermediária
A pequena empresa abraça a coxa do estágio intermediário, e o estágio intermediário abraça a coxa da grande empresa. A construção do estágio intermediário é finalmente um problema de estrutura organizacional; para este ponto, não há nada bom maneira de lidar com isso.A construção do estágio intermediário é, em última análise, um problema.Questões Estruturais Organizacionais (Lei de Conway).
A fronteira entre a China e Taiwan é difícil de esclarecer. Isso é para determinar quais negócios são implementados pelo middle office e quais negócios são implementados por eles mesmos, e os limites não são claros. A parte mais difícil do projeto de middle office não é a divisão de domínio, mas a divisão de limites entre o middle office e o negócio! China e Taiwan são adequados para "inovação combinada", mas não para "inovação subversiva". Isso pode ser aliviado até certo ponto usando o Pipeline para encapsular diferentes processos de negócios.
A eficiência de todo o processo no middle office não é alta. A razão essencial é que, em termos de estrutura organizacional, o negócio corresponde a diferentes departamentos, e pode-se imaginar que o custo da comunicação interdepartamental seja relativamente alto.
Os limites são discutidos para cada função de negócios;
Cada função de negócios deve considerar o impacto em todos os negócios.
Isso pode ser aliviado até certo ponto usando o Pipeline para encapsular diferentes processos de negócios.
Habilidades de aterrissagem de meio-termo
Use microsserviços para construir o meio-termo. Como diz o ditado, "Microsserviços não são necessariamente Zhongtai, Zhongtai devem ser microsserviços!".
Use o Pipeline para encapsular diferentes processos de negócios, de modo a aliviar os problemas de difícil divisão de fronteiras entre o middle office e o negócio e a baixa eficiência de todo o processo.
Pipeline semelhante ao Netty usa o Handler para encapsular diferentes pontos de função em diferentes fluxos de processamento. É equivalente ao padrão de cadeia de responsabilidade no padrão de projeto, correspondendo à composição em orientação a objetos.
Diferentes serviços são encapsulados com SPI. É equivalente ao padrão de modelo no padrão de projeto, correspondendo à herança na orientação a objetos.
Comparação das soluções Pipeline e SPI
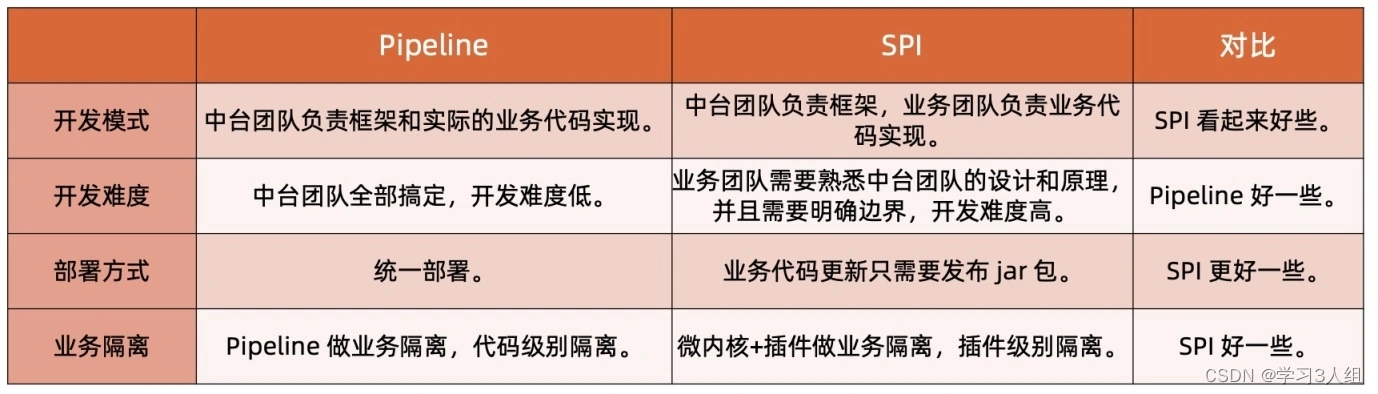
De acordo com a visão de que a composição é preferível à herança em padrões de projeto, parece que o Pipiline deve ser usado primeiro. Na verdade, Hua Tsai também disse que deveria ser usado primeiro
Pipiline, o principal motivo é que sua dificuldade de desenvolvimento é baixa, enquanto o SPI precisa esclarecer os limites entre a plataforma intermediária e o negócio, e a dificuldade de desenvolvimento é alta
Perguntas para reflexão
Se a empresa já possui um negócio on-line e agora planeja fazer um negócio semelhante, você precisa ir para o middle office neste momento?
De acordo com a situação, porque quanto mais negócios semelhantes no negócio, maior o valor, e neste momento existem apenas dois negócios semelhantes. De acordo com o princípio da adequação, se não houver muitos desses casos, não há necessidade de vá para a plataforma intermediária; se o desenvolvimento de negócios for muito rápido, você pode considerar criar uma plataforma intermediária simples, seguir o princípio de primeiro granular e depois dividir.
Combate Prático - Microsserviços para plataformas de e-commerce de jogos mobile
Se a arquitetura existente é monolítica, a transformação de microsserviços não é necessariamente a melhor e natural resposta para resolver os problemas da arquitetura existente, e problemas específicos precisam ser analisados detalhadamente.
Perguntas para reflexão
Quais são as vantagens e desvantagens do modelo de negócios altamente abstrato no negócio?
Vantagens: pode ser reutilizado. Os requisitos de design são relativamente altos.Se o design não for bom, a reutilização não é boa.
Desvantagens: Não pode ser usado diretamente para negócios específicos, requer maior desenvolvimento e o custo de comunicação é relativamente alto.