Índice
1. Banco de dados não relacional NoSQL
2. A diferença entre banco de dados relacional e banco de dados não relacional
(1) Diferentes métodos de armazenamento de dados
(2) Diferentes métodos de expansão
(3) Suporte diferente para transações
3. Cenários de uso de banco de dados não relacional
3. A razão pela qual o Redis lê e escreve rápido
3. Instalação e configuração do Redis
Em quarto lugar, o uso de Redis
1. Ferramenta de linha de comando redis-cli (login)
2. Ferramenta de teste redis-benchmark (teste)
4. Comandos comuns de vários bancos de dados do Redis
Cinco, gerenciamento de desempenho do Redis
2. Limpe fragmentos de memória
(1) Como ocorre a fragmentação da memória
(2) Taxa de fragmentação de memória
(3) Limpe fragmentos de memória
4. Chave de recuperação interna
1. Banco de dados não relacional NoSQL
1. Visão geral do NoSQL
NoSQL (Not Only SQL) é o termo geral para bancos de dados não relacionais. Bancos de dados que não sejam bancos de dados relacionais convencionais são considerados não relacionais.
Não há necessidade de pré-criar bancos de dados e tabelas para definir a estrutura da tabela de armazenamento de dados. Cada registro pode ter diferentes tipos de dados e número de campos (como texto, imagens, vídeos, música, etc. em bate-papos em grupo do WeChat).
Os principais bancos de dados NoSQL incluem Redis, MongBD, Hbase, Memcached, ElasticSearch, TSD, etc.
2. A diferença entre banco de dados relacional e banco de dados não relacional
(1) Diferentes métodos de armazenamento de dados
A principal diferença entre bancos de dados relacionais e não relacionais é a forma como os dados são armazenados.
Bancos de dados SQL são tabulares por natureza , então eles são armazenados em linhas e colunas de tabelas de dados . As tabelas de dados podem ser associadas entre si e armazenadas de forma colaborativa, e também é fácil extrair dados.
Os dados do tipo NoSQL não são adequados para armazenamento nas linhas e colunas da tabela de dados, mas agrupados em grandes blocos. Os dados não relacionais geralmente são armazenados em conjuntos de dados , como documentos, pares chave-valor ou estruturas gráficas. Seus dados e suas características são o fator de influência número um na escolha de como armazenar e extrair seus dados.
(2) Diferentes métodos de expansão
A maior diferença entre bancos de dados relacionais e não relacionais está na forma de expansão.Para atender a demanda crescente, claro, a expansão é necessária.
Os bancos de dados SQL escalam verticalmente , o que significa aumentar o poder de processamento e usar computadores mais rápidos para que o mesmo conjunto de dados possa ser processado mais rapidamente. Como os dados são armazenados em tabelas relacionais, os gargalos de desempenho para operações que podem envolver muitas tabelas precisam ser superados aumentando o desempenho do computador. Embora o banco de dados sql tenha muito espaço para expansão, ele definitivamente atingirá o limite superior de expansão vertical no final.
Os bancos de dados NoSQL escalam horizontalmente . Como o armazenamento de dados não relacionais é distribuído naturalmente, a expansão dos bancos de dados NoSQL pode ser feita adicionando mais servidores de banco de dados comuns (nós) ao pool de recursos para compartilhar a carga.
(3) Suporte diferente para transações
Se as operações de dados exigirem alta transacionalidade ou consultas de dados complexas precisarem controlar o plano de execução, o banco de dados SQL tradicional é sua melhor escolha em termos de desempenho e estabilidade.
O banco de dados SQL oferece suporte ao controle refinado sobre a atomicidade da transação e é fácil reverter as transações.
Embora os bancos de dados NoSQL também possam usar operações de transação, eles não podem ser comparados aos bancos de dados relacionais em termos de estabilidade. Portanto, seu valor real é em termos de escalabilidade operacional e processamento de grande volume de dados.
3. Cenários de uso de banco de dados não relacional
Ele pode ser usado para lidar com os três principais problemas (alta simultaneidade, alto desempenho e alta disponibilidade) dos tipos de sites puramente dinâmicos da web 2.0.
- Alto desempenho - altos requisitos simultâneos de leitura e gravação para o banco de dados;
- Armazenamento Enorme——Requisitos para armazenamento eficiente e acesso de dados massivos;
- Alta Escalabilidade e Alta Disponibilidade——Requisitos para alta escalabilidade e alta disponibilidade do banco de dados.
Bancos de dados relacionais e bancos de dados não relacionais têm suas próprias características e cenários de aplicação. A estreita combinação dos dois trará novas ideias para o desenvolvimento de bancos de dados web 2.0:
Bancos de dados relacionais focam em relacionamentos e garantias de consistência de dados;
Os bancos de dados não relacionais se concentram no armazenamento e na alta eficiência.
Por exemplo: no ambiente de banco de dados Mysql, onde a leitura e a gravação são separadas, os dados acessados com frequência podem ser armazenados em um banco de dados não relacional para melhorar a velocidade de acesso.
2. Visão geral do Redis
1. Introdução
Redis (Remote Dictionary Server) é um banco de dados NoSQL de código aberto escrito em linguagem C.
O Redis é executado com base na memória e suporta persistência. Ele adota a forma de armazenamento chave-valor (par chave-valor), que é uma parte indispensável da atual arquitetura distribuída.
O programa do servidor Redis é um modelo de processo único, ou seja, vários processos Redis podem ser iniciados em um servidor ao mesmo tempo, e a velocidade real de processamento do Redis depende inteiramente da eficiência de execução do processo principal.
2. Vantagens
Alta velocidade de leitura e gravação de dados : a velocidade de leitura de dados pode atingir até 110.000 vezes/s, e a velocidade de gravação de dados pode atingir até 81.000 vezes/s.
Suporte a tipos de dados ricos : suporte a operações de tipo de dados, como valor-chave, Strings, Listas, Hashes, Conjuntos e Conjuntos Classificados.
Persistência de dados de suporte : os dados na memória podem ser salvos no disco e podem ser carregados novamente para uso ao reiniciar.
Atomicidade : todas as operações do Redis são atômicas.
Suporta backup de dados : suporta backup de dados no modo master-salve.
3. A razão pela qual o Redis lê e escreve rápido
O Redis é executado na memória , evitando operações demoradas, como E/S de disco.
O módulo principal do processamento de comandos do Redis é de thread único , o que reduz o custo da concorrência de bloqueio, criação e destruição frequentes de threads e reduz o consumo de troca de contexto de thread.
Observação: o multiencadeamento recém-adicionado no Redis 6.0 usa apenas multilinearidade para processar solicitações de rede, enquanto os comandos de leitura e gravação de dados ainda são processados por um único encadeamento.
O mecanismo de multiplexação de I/O é adotado para reduzir o consumo de I/O da rede e melhorar consideravelmente a eficiência da simultaneidade.
4. Cenários aplicáveis
Como um banco de dados baseado em memória, o Redis é um cache de alto desempenho geralmente usado em caches de sessão, filas
, tabelas de classificação, contadores, artigos mais recentes, comentários mais recentes, assinaturas de publicação, etc.
O Redis é adequado para cenários com altos requisitos de dados em tempo real, armazenamento de dados com características de expiração e eliminação, sem necessidade de persistência ou apenas
consistência fraca e lógica simples.
3. Instalação e configuração do Redis
#将安装包放在/opt下
cd /opt
tar xf redis-5.0.7.tar.gz
cd redis-5.0.7/
#编译
make
#安装到指定目录
make install PREFIX=/usr/local/redis
Você também precisa ir para utils/ no pacote de instalação e executar install_server.sh

Em seguida, modifique o endereço de escuta no arquivo de configuração /etc/redis/6379.conf


Em quarto lugar, o uso de Redis
| ferramenta | efeito |
|---|---|
| servidor redis | Ferramenta para iniciar redis |
| redis-benchmark | Usado para detectar a eficiência operacional do redis na máquina |
| redis-check-aof | Corrigir arquivo persistente AOF |
| redis-check-rdb | Reparar arquivos persistentes RDB |
| redis-cli | ferramenta de linha de comando redis |
1. Ferramenta de linha de comando redis-cli (login)

2. Ferramenta de teste redis-benchmark (teste)
redis-benchmark [opção] [valor da opção]
-h especifica o nome do host do servidor
-p especifica a porta do servidor
-s especifica o soquete do servidor
-c especifica o número de conexões simultâneas
-n especifica o número de solicitações
-d especifica o SET/ GET valor em bytes Tamanho dos dados
-k 1 significa manter vivo para manter a conexão; 0 significa reconectar reconexão
-r SET, GET, INCR usar chave aleatória; SADD usar valor aleatório
-P transmitir <numreg> solicitação através do pipeline
-q forçar sair do redis exibir apenas o valor da consulta/s
--saída csv no formato CSV (, dividir o texto do campo)
-l gerar um loop, executar testes para sempre
-t apenas executar uma lista separada por vírgulas de comandos de teste
-I modo ocioso (somente abrir N conexões ociosas e aguardar)
#向IP地址为192.168.109.133、端口为6379的Redis服务器发送100个并发连接与100000个请求测试性能
redis-benchmark -h 192.168.116.10 -p 6379 -c 100 -n 100000
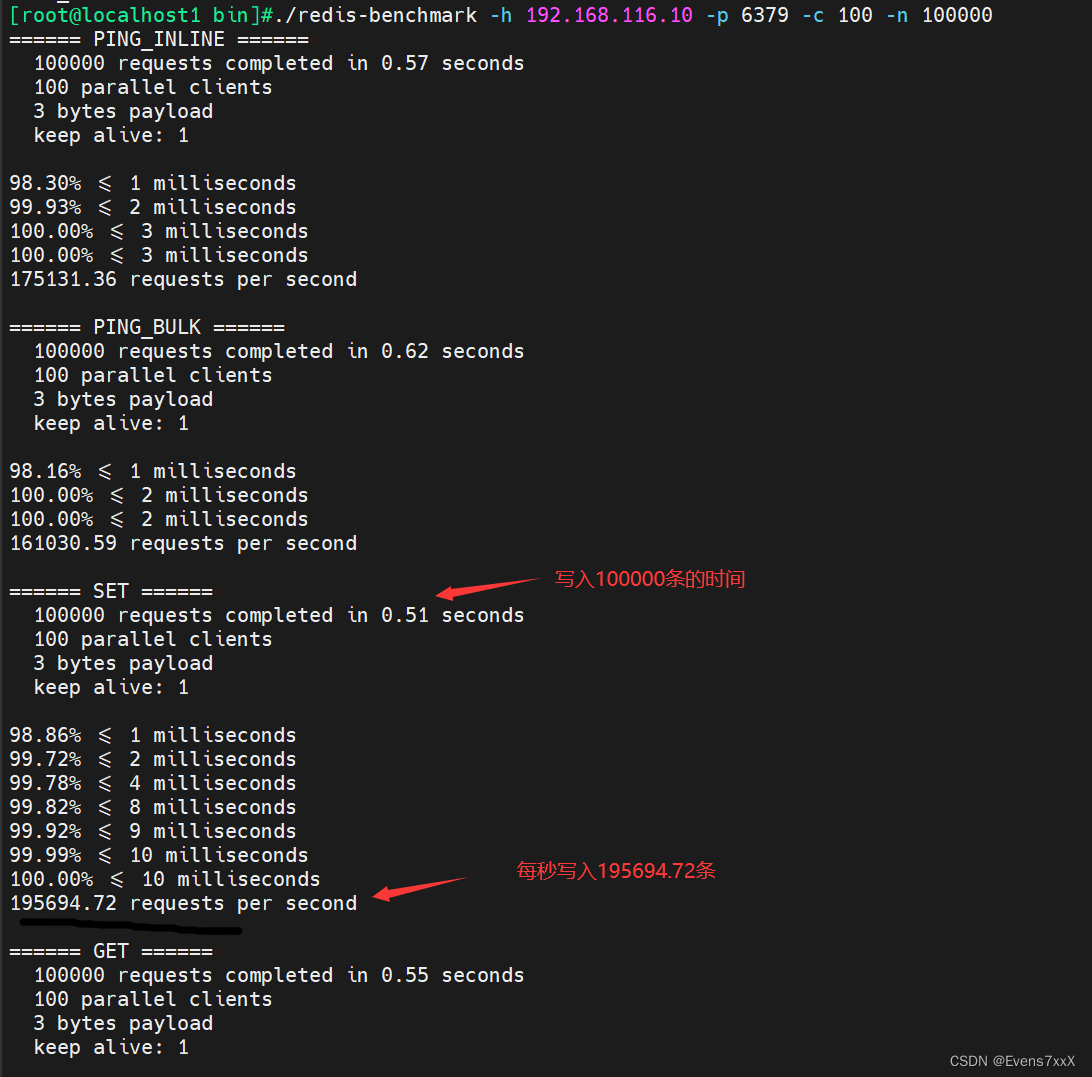
#测试存取大小为100字节的数据包的性能
redis-benchmark -h 192.168.116.10 -p 6379 -q -d 100
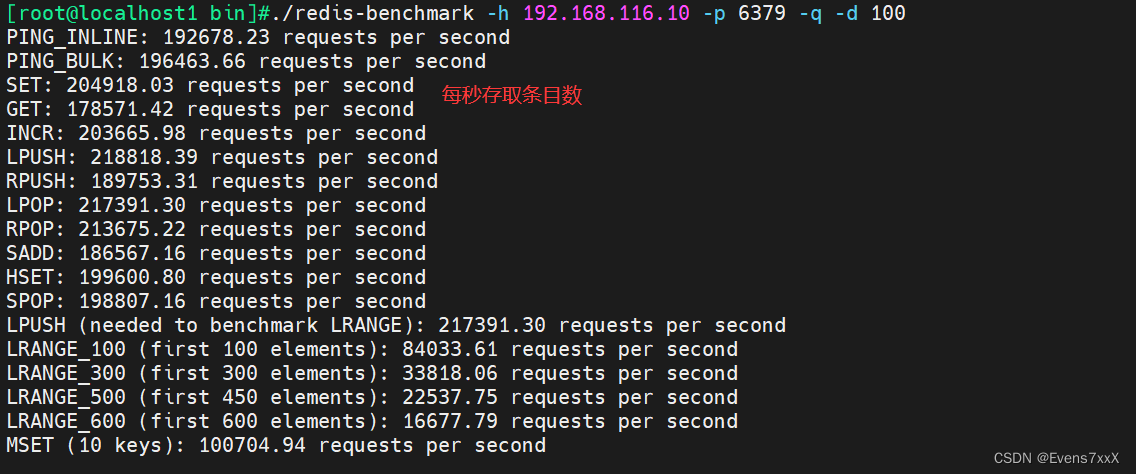
#测试本机上Redis服务在进行set与lpush操作时的性能
redis-benchmark -t set,lpush -n 100000 -q
3. Uso do comando redis
(1) Armazenar pares chave-valor
DEFINIR valor da chave

(2) Obtenha o valor da chave
OBTER chave

(3) Determine o tipo de dados da chave (o tipo de dados padrão do redis é string)
tecla TIPO

Cinco tipos de dados no Redis
| nome | tipo |
|---|---|
| Corda | corda |
| Lista | a lista |
| Cerquilha | cerquilha |
| Definir | coleção não ordenada |
| Conjunto classificado | conjunto ordenado |
(4) Tecla de visualização
CHAVES * Ver todas as chaves
KEYS curingas Exibir chaves especificadas correspondidas por curingas

(5) Determine se a chave existe
EXISTE chave

(6) Tecla Excluir
tecla DEL

(7) Modifique o nome da chave
RENAME nome da chave original novo nome da chave
O novo nome de chave a ser alterado já existe, o valor deste nome de chave será substituído (recomenda-se existir antes de alterar o nome) ou use:
RENAMENX nome da chave original novo nome da chave // julgando se o novo nome da chave existe antes da modificação, se existir, retorna 0, se não existe, retorna 1 e executa a modificação



(8) Número de chaves estatísticas
DBSIZE

(9) Definir senha
DEFINIR CONFIG REQUER PASS senha
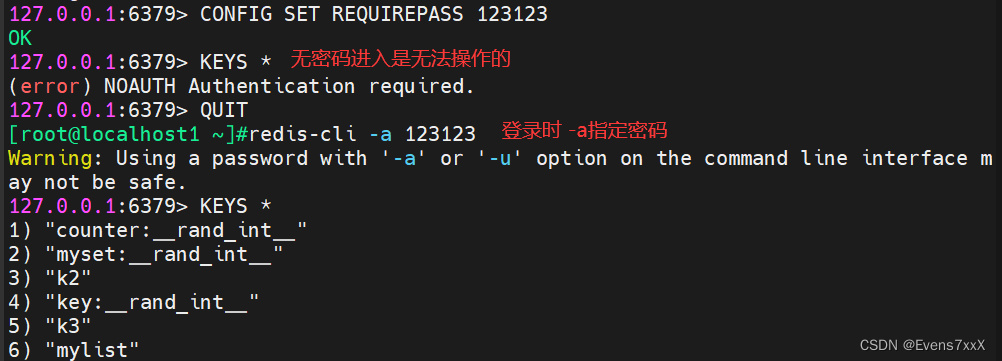
Verifique após o login com a senha AUTH

(10) Veja a senha atual
CONFIG OBTER REQUISITO PASSO

(11) Excluir senha
CONFIG SET REQUER PASS ''

4. Comandos comuns de vários bancos de dados do Redis
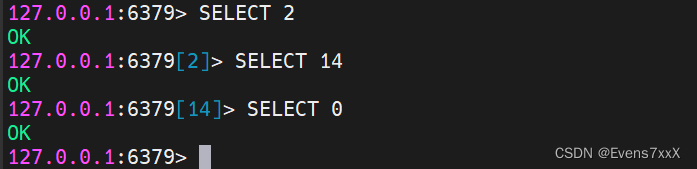
O Redis suporta vários bancos de dados. O Redis contém 16 bancos de dados por padrão e os nomes dos bancos de dados são nomeados sequencialmente com números de 0 a 15 (o login padrão é o banco de dados 0). Vários bancos de dados são independentes uns dos outros e não interferem entre si.
(1) Alternar banco de dados
SELECIONE o número da biblioteca
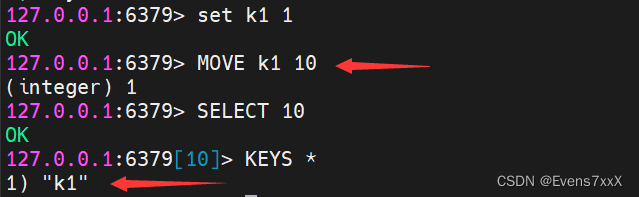
(2) Mova os dados para a biblioteca especificada
MOVER número do banco chave
Cinco, gerenciamento de desempenho do Redis
1. Veja o uso da memória
memória de informações
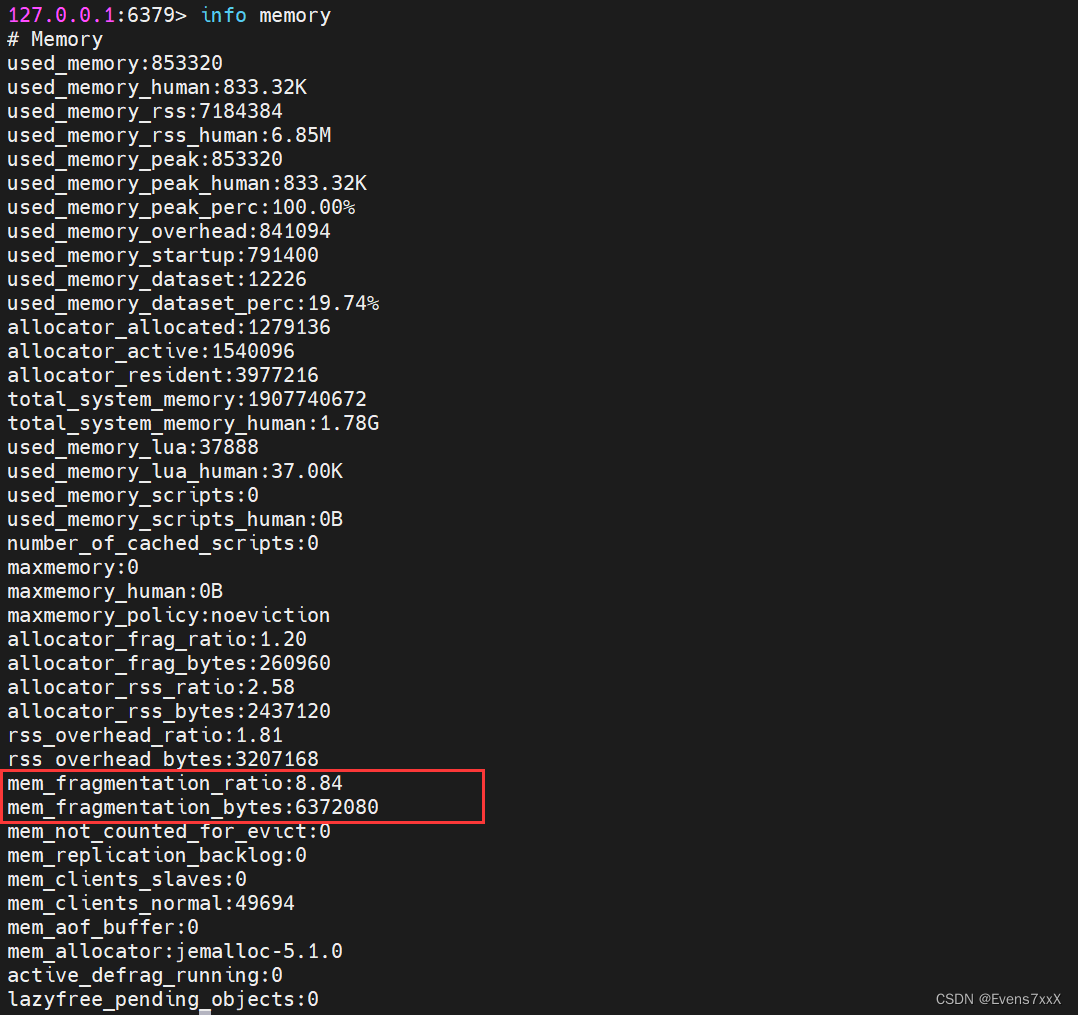
fragmentação de memória _ratio # taxa de fragmentação de memória = memória_rss usada / memória usada usada
memory _rss # é a memória que o Redis aplica ao sistema operacional.
used memory # é a memória ocupada pelos dados no Redis.
pico de memória usado # O valor de pico do uso de memória redis.
2. Limpe fragmentos de memória
(1) Como ocorre a fragmentação da memória
O Redis possui seu próprio gerenciador de memória interna para gerenciar o aplicativo e a liberação de memória para melhorar a eficiência do uso da memória.
Quando o valor no Redis é excluído, a memória não é liberada diretamente e retornada ao sistema operacional, mas ao gerenciador de memória interna do Redis.
Ao solicitar memória no Redis, primeiro verifique se há memória suficiente disponível em seu próprio gerenciador de memória.
Esse mecanismo do Redis melhora a taxa de utilização da memória, mas fará com que alguma memória no Redis não seja usada por si só, mas não seja liberada, resultando em fragmentação da memória.
(2) Taxa de fragmentação de memória
O rastreamento da taxa de fragmentação da memória é muito importante para entender o desempenho dos recursos da instância do Redis
- É normal que a taxa de fragmentação da memória esteja entre 1 e 1,5 . Esse valor indica que a taxa de fragmentação da memória é relativamente baixa e também indica que o Redis não troca memória.
- Se a taxa de fragmentação da memória exceder 1,5 , isso significa que o Redis consome 150% da memória física real necessária , dos quais 50% é a taxa de fragmentação da memória.
- Se a taxa de fragmentação da memória for menor que 1 , significa que a alocação de memória Redis excede a memória física e o sistema operacional está trocando memória . Necessidade de aumentar a memória física disponível ou reduzir o uso de memória do Redis.
(3) Limpe fragmentos de memória
Versão Redis abaixo de 4.0
Você precisa inserir o comando shutdown save na ferramenta redis-cli para permitir que o banco de dados Redis execute a operação de salvamento, feche o serviço Redis e reinicie o servidor. Após a reinicialização do servidor Redis, o Redis retornará a memória inútil ao sistema operacional e a taxa de fragmentação cairá.
Redis versão 4.0 ou superior
Execute config set activedefrag yes para habilitar a desfragmentação automática;
Executar limpeza de memória , desfragmentação manual.
3. Uso de memória
Se o uso de memória da instância redis exceder o máximo de memória disponível, o sistema operacional começará a trocar memória e espaço de troca, resultando em desempenho bastante reduzido.
Maneiras de evitar a troca de memória
- Escolha instalar uma instância do Redis para o tamanho dos dados em cache
- Use o armazenamento de estrutura de dados Hash tanto quanto possível
- Defina o ciclo de vida TTL da chave (setex key name time(s) value)
4. Chave de recuperação interna
A estratégia de limpeza de memória garante uma alocação razoável de recursos de memória limitados do Redis. Por padrão, a estratégia de recuperação é proibir a exclusão. Quando o limite máximo definido é atingido, uma estratégia de recuperação de chave precisa ser selecionada.
Modifique o valor do atributo maxmemory-policy no arquivo de configuração
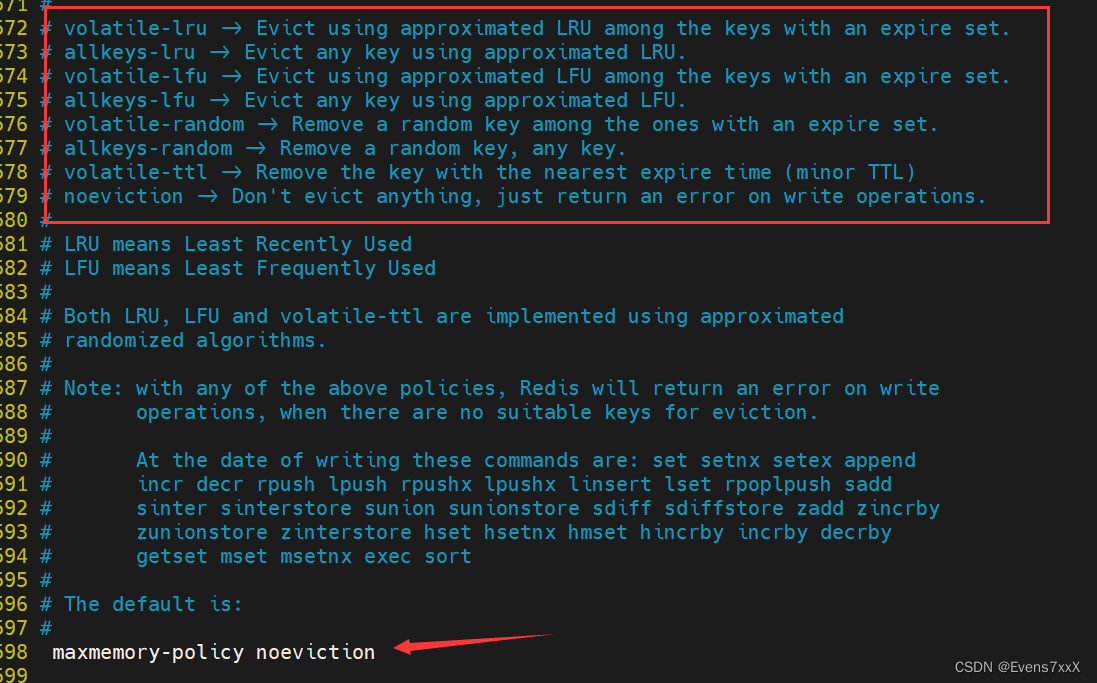
| volátil-lru | Use o algoritmo LRU para eliminar dados do conjunto de dados com o tempo de expiração definido (remova a chave usada menos recentemente, para a chave com TTL definido) |
| volátil-ttl | Escolha os dados que estão prestes a expirar da coleta de dados que definiu o tempo de expiração (remova a chave expirada mais recentemente) |
| volátil-aleatório | Selecione aleatoriamente os dados a serem eliminados da coleta de dados com um tempo de expiração definido (removido aleatoriamente da chave com TTL definido) |
| allkeys-lru | Use o algoritmo LRU para eliminar dados de todos os conjuntos de dados (remova a chave menos usada, para todas as chaves) |
| allkeys-random | Selecione aleatoriamente a eliminação de dados do conjunto de dados (remova a chave aleatoriamente) |
| noenviction | É proibido eliminar dados (não apague até que esteja cheio e reporte um erro) |