Reimpresso de: Heart of the Machine | Editores: Du Wei, Chen Ping
Mova o mouse para tornar a imagem "viva" e se tornar o que você deseja.
No mundo mágico do AIGC, podemos alterar e sintetizar a imagem que queremos "arrastando" na imagem. Por exemplo, para fazer um leão virar a cabeça e abrir a boca:
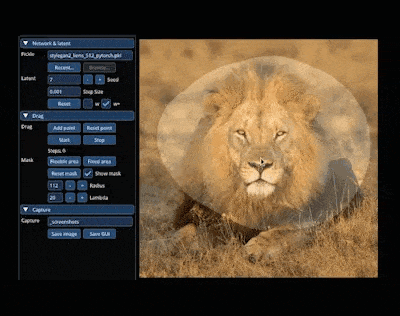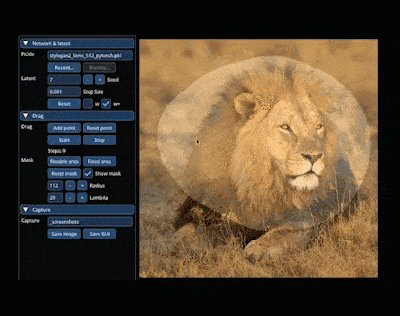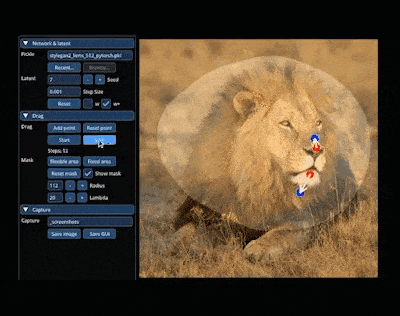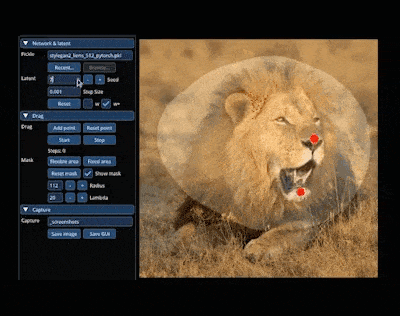
A pesquisa para alcançar esse efeito vem do artigo "Drag Your GAN", liderado por um autor chinês, lançado no mês passado e aceito pela conferência SIGGRAPH 2023.
Mais de um mês se passou e a equipe de pesquisa divulgou recentemente o código oficial. Em apenas três dias, o número de estrelas ultrapassou 23k, o que mostra o quão popular é.
Endereço do GitHub: https://github.com/XingangPan/DragGAN
Coincidentemente, outra pesquisa semelhante——DragDiffusion chamou a atenção das pessoas hoje. O DragGAN anterior realizou edição de imagem interativa baseada em pontos e alcançou efeitos de edição de precisão em nível de pixel. Mas também há deficiências. DragGAN é baseado na rede de confrontação de geração (GAN), e sua versatilidade será limitada pela capacidade do modelo GAN pré-treinado.
No novo estudo, vários pesquisadores da Universidade Nacional de Cingapura e da ByteDance estenderam essa estrutura de edição ao modelo de difusão e propuseram o DragDiffusion. Usando um modelo de difusão pré-treinado em grande escala, eles melhoraram muito a aplicabilidade da edição interativa baseada em pontos em cenários do mundo real.
Embora a maioria dos métodos atuais de edição de imagens baseados em difusão sejam adequados para incorporação de texto, DragDiffusion otimiza a representação latente de difusão para controle espacial preciso.

Endereço do artigo: https://arxiv.org/abs/2306.14435
Endereço do projeto: https://yujun-shi.github.io/projects/dragdiffusion.html
Os pesquisadores disseram que o modelo de difusão gera imagens de maneira iterativa, e a otimização de "uma etapa" da representação latente de difusão é suficiente para gerar resultados coerentes, permitindo que o DragDiffusion conclua com eficiência a edição de alta qualidade.
Eles conduzem experimentos extensos em vários cenários desafiadores (por exemplo, múltiplos objetos, diferentes categorias de objetos), verificando a plasticidade e generalidade do DragDiffusion. O código relevante também será lançado em breve,
Vamos ver como funciona o DragDiffusion.
Primeiramente queremos levantar um pouco mais a cabeça do gatinho da figura abaixo, bastando o usuário arrastar o ponto vermelho até o ponto azul:

A seguir, queremos deixar a montanha um pouco mais alta, não tem problema, basta arrastar o ponto chave vermelho:

Também quero virar a cabeça da escultura, basta arrastar e soltar:

Deixe as flores da margem florescerem em uma gama mais ampla:

introdução do método
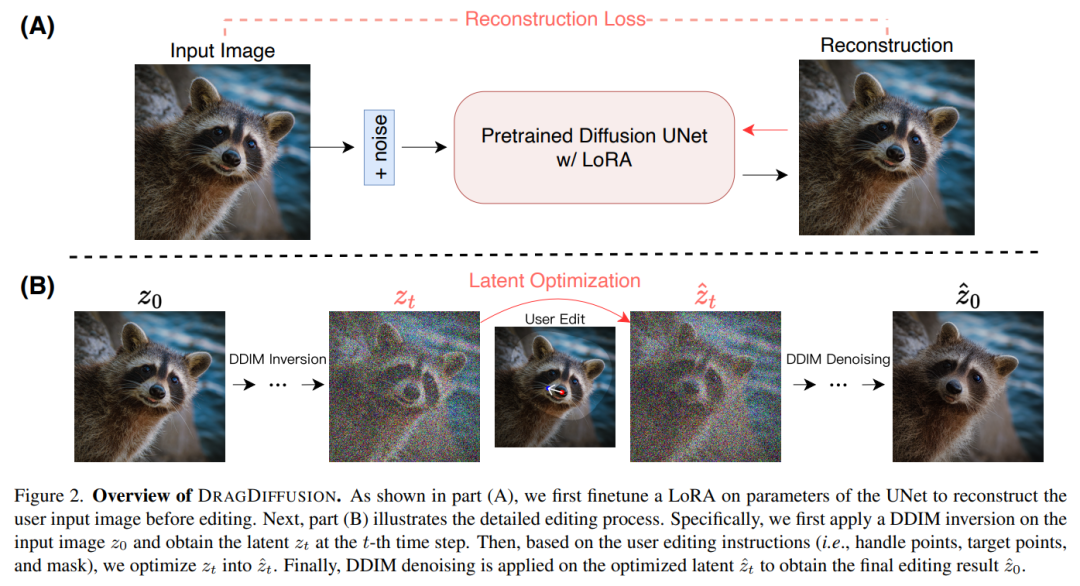
O DRAGDIFFUSION proposto neste artigo tem como objetivo otimizar variáveis latentes de difusão específicas para edição de imagens interativas baseadas em pontos.
Para atingir esse objetivo, o estudo primeiro ajusta o LoRA com base no modelo de difusão para reconstruir as imagens de entrada do usuário. Isso pode garantir que o estilo das imagens de entrada e saída permaneça consistente.
Em seguida, aplicamos a inversão DDIM (um método que explora a transformação inversa e a manipulação do espaço latente dos modelos de difusão) à imagem de entrada para obter variáveis latentes de difusão específicas da etapa.
Durante o processo de edição, aplicamos iterativamente supervisão de ação e rastreamento de ponto para otimizar as t-ésimas variáveis latentes de difusão obtidas anteriormente para "arrastar" o conteúdo do ponto processado para o local de destino. O processo de edição também aplica um termo de regularização para garantir que as regiões não mascaradas da imagem permaneçam inalteradas.
Finalmente, as variáveis latentes otimizadas do t-ésimo passo são eliminadas por DDIM para obter os resultados editados. O diagrama de visão geral é o seguinte:
Resultados experimentais
Dada uma imagem de entrada, DRAGDIFFUSION "arrasta" o conteúdo dos pontos-chave (vermelho) para os pontos-alvo correspondentes (azul). Por exemplo, na figura (1), a cabeça do cachorro está virada, na figura (7), a boca do tigre está fechada, e assim por diante.

Abaixo estão mais alguns exemplos de demonstrações. Conforme mostrado na Figura (4), o pico da montanha ficará mais alto, a Figura (7) aumentará o tamanho da caneta e assim por diante.

Preste atenção à conta oficial [Machine Learning and AI Generation Creation], coisas mais interessantes estão esperando por você para ler
Explicação detalhada do ControlNet, um algoritmo de geração de pintura AIGC controlável!
Classic GAN tem que ler: StyleGAN
 Clique em mim para ver os álbuns da série GAN~!
Clique em mim para ver os álbuns da série GAN~!
Uma xícara de chá com leite, torna-se a fronteira da visão AIGC+CV!
O resumo 100 mais recente e completo! Gerar Modelos de Difusão Modelos de Difusão
ECCV2022 | Resumo de alguns trabalhos sobre geração de rede de confronto GAN
CVPR 2022 | Mais de 25 direções, os últimos 50 documentos do GAN
ICCV 2021 | Resumo dos artigos do GAN sobre 35 temas
Mais de 110 artigos! CVPR 2021 penteadeira de papel GAN mais completa
Mais de 100 artigos! CVPR 2020 penteadeira de papel GAN mais completa
Desmontando o novo GAN: dissociando a representação MixNMatch
StarGAN versão 2: geração de imagens de diversidade de vários domínios
Download em anexo | Versão chinesa de "Explainable Machine Learning"
Download em anexo | "Algoritmos de aprendizado profundo do TensorFlow 2.0 na prática"
Download em anexo | "Métodos Matemáticos em Visão Computacional" share
"Uma revisão dos métodos de detecção de defeitos de superfície com base no aprendizado profundo"
Uma pesquisa de classificação de imagens Zero-Shot: uma década de progresso
"Uma pesquisa de aprendizagem de poucos tiros baseada em redes neurais profundas"
"Livro dos Ritos·Xue Ji" tem um ditado: "Aprender sozinho sem amigos é solitário e ignorante."
Clique em uma xícara de chá com leite e torne-se o vacilante da fronteira da visão AIGC+CV! , junte-se ao planeta da criação gerada por IA e conhecimento de visão computacional!