Os dados são a base do aprendizado profundo . De um modo geral, quanto maior a quantidade de dados, mais poderoso será o modelo treinado. Se você tiver alguns dados agora, como adicionar esses dados ao modelo? Pytorch fornece conjunto de dados e carregador de dados , vamos aprender juntos, blogueiros de conjunto de dados e carregador de dados usarão alguns exemplos para ilustrar, obrigado por seu apoio!

Diretório de artigos
1. conjunto de dados
Forneça uma maneira de obter dados e seu rótulo
● Como obter cada dado e seu rótulo
● Diga-nos quantos dados existem
para ver se o pytorch está disponível
print(torch.cuda.is_available()) # 查看当前cuda是否可用
True
Em segundo lugar, visualize o conjunto de dados
from torch.utils.data import Dataset
help(Dataset) # 用帮助文档查看Dataset
Ajuda sobre a classe Dataset no módulo arch.utils.data.dataset:
class Dataset(typing.Generic)
| Dataset(*args, **kwds)
|
| Uma classe abstrata que representa uma :class:Dataset.
|
| Todos os conjuntos de dados que representam um mapa de chaves para amostras de dados devem subclasse
| isto. Todas as subclasses devem sobrescrever :meth:__getitem__, suportando a busca de
| amostra de dados para uma determinada chave. As subclasses também podem sobrescrever opcionalmente
| :meth:__len__, que deve retornar o tamanho do conjunto de dados por muitos
| :class:~torch.utils.data.Samplerimplementações e as opções padrão
| de :classe:~torch.utils.data.DataLoader.
|
| … nota::
| :class:~torch.utils.data.DataLoaderpor padrão constrói um índice
| amostrador que produz índices integrais. Para fazê-lo funcionar com um estilo de mapa
| conjunto de dados com índices/chaves não integrais, um amostrador personalizado deve ser fornecido.
|
| Ordem de resolução do método:
| Conjunto de dados
| digitação.Genérico
| builtins.object
|
| Métodos definidos aqui:
|
| add (self, other: 'Dataset[T_co]') -> 'ConcatDataset[T_co]'
|
| getattr (self, attribute_name)
|
| getitem (auto, índice) -> +T_co
|
| ---------------------------------------------------------------------------
| Métodos de classe definidos aqui:
|
| register_datapipe_as_function(function_name, cls_to_register, enable_df_api_tracing=False) de builtins.type
|
| register_function(function_name, function) de builtins.type
|
| ---------------------------------------------------------------------------
| Descritores de dados definidos aqui:
|
| ditado
| dicionário para variáveis de instância (se definido)
|
| fracaref
| lista de referências fracas ao objeto (se definido)
|
| ---------------------------------------------------------------------------
| Dados e outros atributos definidos aqui:
|
| anotações= {'funções': digitação.Dict[str, digitação.Callable]}
|
| orig_bases = (typing.Generic[+T_co],)
|
| parâmetros = (+T_co,)
|
| functions = {'concat': functools.partial(<function Dataset.register_da…
|
| ---------------------------------------------------------------------------
| Métodos de classe herdados da digitação.Generic:
|
| class_getitem (params) de builtins.type
|
| init_subclass (*args, **kwargs) de builtins.type
| Este método é chamado quando uma classe é subclassificada.
|
| A implementação padrão não faz nada. Pode ser
| substituído para estender subclasses.
|
| ---------------------------------------------------------------------------
| Métodos estáticos herdados da digitação.Generic:
|
| novo (cls, *args, **kwds)
| Crie e retorne um novo objeto. Consulte a ajuda (tipo) para obter uma assinatura precisa.
3. A operação os lê os objetos na pasta
import os
dir_path = "hymenoptera_data\\hymenoptera_data\\train\\ants" # 文件夹目录
data_dir = os.listdir(dir_path) # 获取文件夹目录中的对象
data_dir
[‘0013035.jpg’,
‘1030023514_aad5c608f9.jpg’,
‘1095476100_3906d8afde.jpg’,
‘1099452230_d1949d3250.jpg’,
‘116570827_e9c126745d.jpg’,
‘1225872729_6f0856588f.jpg’,
‘1262877379_64fcada201.jpg’,
‘1269756697_0bce92cdab.jpg’,
‘1286984635_5119e80de1.jpg’,
‘132478121_2a430adea2.jpg’,
‘1360291657_dc248c5eea.jpg’,
‘1368913450_e146e2fb6d.jpg’,
‘1473187633_63ccaacea6.jpg’,
‘148715752_302c84f5a4.jpg’,
‘1489674356_09d48dde0a.jpg’,
‘149244013_c529578289.jpg’,
‘150801003_3390b73135.jpg’,
‘150801171_cd86f17ed8.jpg’,
‘154124431_65460430f2.jpg’,
‘162603798_40b51f1654.jpg’,
‘1660097129_384bf54490.jpg’,
‘167890289_dd5ba923f3.jpg’,
‘1693954099_46d4c20605.jpg’,
‘175998972.jpg’,
‘178538489_bec7649292.jpg’,
‘1804095607_0341701e1c.jpg’,
‘1808777855_2a895621d7.jpg’,
‘188552436_605cc9b36b.jpg’,
‘1917341202_d00a7f9af5.jpg’,
‘1924473702_daa9aacdbe.jpg’,
‘196057951_63bf063b92.jpg’,
‘196757565_326437f5fe.jpg’,
‘201558278_fe4caecc76.jpg’,
‘201790779_527f4c0168.jpg’,
‘2019439677_2db655d361.jpg’,
‘207947948_3ab29d7207.jpg’,
‘20935278_9190345f6b.jpg’,
‘224655713_3956f7d39a.jpg’,
‘2265824718_2c96f485da.jpg’,
‘2265825502_fff99cfd2d.jpg’,
‘226951206_d6bf946504.jpg’,
‘2278278459_6b99605e50.jpg’,
‘2288450226_a6e96e8fdf.jpg’,
‘2288481644_83ff7e4572.jpg’,
‘2292213964_ca51ce4bef.jpg’,
‘24335309_c5ea483bb8.jpg’,
‘245647475_9523dfd13e.jpg’,
‘255434217_1b2b3fe0a4.jpg’,
‘258217966_d9d90d18d3.jpg’,
‘275429470_b2d7d9290b.jpg’,
‘28847243_e79fe052cd.jpg’,
‘318052216_84dff3f98a.jpg’,
‘334167043_cbd1adaeb9.jpg’,
‘339670531_94b75ae47a.jpg’,
‘342438950_a3da61deab.jpg’,
‘36439863_0bec9f554f.jpg’,
‘374435068_7eee412ec4.jpg’,
‘382971067_0bfd33afe0.jpg’,
‘384191229_5779cf591b.jpg’,
‘386190770_672743c9a7.jpg’,
‘392382602_1b7bed32fa.jpg’,
‘403746349_71384f5b58.jpg’,
‘408393566_b5b694119b.jpg’,
‘424119020_6d57481dab.jpg’,
‘424873399_47658a91fb.jpg’,
‘450057712_771b3bfc91.jpg’,
‘45472593_bfd624f8dc.jpg’,
‘459694881_ac657d3187.jpg’,
‘460372577_f2f6a8c9fc.jpg’,
‘460874319_0a45ab4d05.jpg’,
‘466430434_4000737de9.jpg’,
‘470127037_513711fd21.jpg’,
‘474806473_ca6caab245.jpg’,
‘475961153_b8c13fd405.jpg’,
‘484293231_e53cfc0c89.jpg’,
‘49375974_e28ba6f17e.jpg’,
‘506249802_207cd979b4.jpg’,
‘506249836_717b73f540.jpg’,
‘512164029_c0a66b8498.jpg’,
‘512863248_43c8ce579b.jpg’,
‘518773929_734dbc5ff4.jpg’,
‘522163566_fec115ca66.jpg’,
‘522415432_2218f34bf8.jpg’,
‘531979952_bde12b3bc0.jpg’,
‘533848102_70a85ad6dd.jpg’,
‘535522953_308353a07c.jpg’,
‘540889389_48bb588b21.jpg’,
‘541630764_dbd285d63c.jpg’,
‘543417860_b14237f569.jpg’,
‘560966032_988f4d7bc4.jpg’,
‘5650366_e22b7e1065.jpg’,
‘6240329_72c01e663e.jpg’,
‘6240338_93729615ec.jpg’,
‘649026570_e58656104b.jpg’,
‘662541407_ff8db781e7.jpg’,
‘67270775_e9fdf77e9d.jpg’,
‘6743948_2b8c096dda.jpg’,
‘684133190_35b62c0c1d.jpg’,
‘69639610_95e0de17aa.jpg’,
‘707895295_009cf23188.jpg’,
‘7759525_1363d24e88.jpg’,
‘795000156_a9900a4a71.jpg’,
‘822537660_caf4ba5514.jpg’,
‘82852639_52b7f7f5e3.jpg’,
‘841049277_b28e58ad05.jpg’,
‘886401651_f878e888cd.jpg’,
‘892108839_f1aad4ca46.jpg’,
‘938946700_ca1c669085.jpg’,
‘957233405_25c1d1187b.jpg’,
‘9715481_b3cb4114ff.jpg’,
‘998118368_6ac1d91f81.jpg’,
‘ant photos.jpg’,
‘Ant_1.jpg’,
‘army-ants-red-picture.jpg’,
‘formica.jpeg’,
‘hormiga_co_por.jpg’,
‘imageNotFound.gif’,
‘kurokusa.jpg’,
‘MehdiabadiAnt2_600.jpg’,
‘Nepenthes_rafflesiana_ant.jpg’,
‘swiss-army-ant.jpg’,
‘termite-vs-ant.jpg’,
‘trap-jaw-ant-insect-bg.jpg’,
‘VietnameseAntMimicSpider.jpg’]
注意在windows下,路径使用双斜线\
4. Conjunto de dados
Prática um do conjunto de dados
from torch.utils.data import Dataset
import os
from PIL import Image
class Mydata(Dataset):
def __init__(self,root_path,label_path):
self.root_path = root_path # hymenoptera_data/hymenoptera_data/train
self.label_path = label_path # /ants
self.path = os.path.join(self.root_path,self.label_path) # 从根目录开始的绝对路径
self.image_path = os.listdir(self.path) # 从根目录开始绝对路径文件夹下的对象 hymenoptera_data/hymenoptera_data/train/ants下的图片 type--> list
def __getitem__(self, idx):
image_name = self.image_path[idx] # 单一的图片名称
image_item_path = os.path.join(self.root_path,self.label_path,image_name)
img = Image.open(image_item_path)
label = self.label_path
return img,label
def __len__(self):
return len(self.image_path)
ants_root_path = "hymenoptera_data\\hymenoptera_data\\train"
ants_label_path = "ants"
Ants = Mydata(ants_root_path,ants_label_path)
Ants[0][0].show() # 第一个0是索引,拿到第一个图像和标签,第二个0是拿到第一个图像,并显示出来
D:\anaconda\envs\Gpu-Pytorch\lib\site-packages\tqdm\auto.py:21: TqdmWarning: IProgress não encontrado. Atualize jupyter e ipywidgets. Consulte https://ipywidgets.readthedocs.io/en/stable/user_install.html
em .autonotebook import tqdm como notebook_tqdm
bee_label_path = "bees"
Bees = Mydata(bee_root_path,bee_label_path)
Bees[0][0].show()
# 创建训练集
train = Ants + Bees # 直接将数据集加起来
print("the length of Ants is ",Ants.__len__())
print("the length of Bees is ",Bees.__len__())
print("the length of train is ",train.__len__())
the length of Ants is 124
the length of Bees is 121
the length of train is 245
# 查看是否正确
train[123][0].show() # 应该为蚂蚁
train[124][0].show() # 应该为蜜蜂
Operação prática do conjunto de dados 2
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
"""
@Project :Pytorch学习
@File :task_3.py
@IDE :PyCharm
@Author :咋
@Date :2023/6/29 14:29
"""
from torch.utils.data import Dataset
import os
from PIL import Image
class Mydata(Dataset):
def __init__(self,root_path,image_path,label_path):
self.root_path = root_path
self.image_path = image_path
self.label_path = label_path
self.A_image_path = os.path.join(self.root_path,self.image_path)
self.A_label_path = os.path.join(self.root_path,self.label_path)
self.img_item = os.listdir(self.A_image_path)
self.label_item = os.listdir(self.A_label_path)
def __getitem__(self, idx):
img_name = self.img_item[idx]
img_path = os.path.join(self.A_image_path, img_name)
label_list = [i.split(".")[0] for i in self.label_item if i.count(".") == 1]
# print(label_list)
if img_name.split(".")[0] in label_list:
img = Image.open(img_path)
label_path = os.path.join(self.A_label_path,img_name.split(".")[0])
label_path += ".txt"
file = open(label_path, 'r')
label = file.read()
file.close()
return img,label
else:
print("{0}没有对应的标签".format(img_name))
return 0
def __len__(self):
return len(self.img_item)
train_ants_root_path = "练手数据集\\train"
train_ants_image_path = "ants_image"
train_ants_label_path = "ants_label"
Ants = Mydata(train_ants_root_path,train_ants_image_path,train_ants_label_path)
for i in range(Ants.__len__()):
try:
print(Ants[i][1])
except TypeError:
print("跳过此张图片!")
# Ants[122][0].show()
# print(Ants[122][1])
formigas formigas formigas formigas formigas formigas formigas formigas formigas formigas formigas formigas formigas formigas
formigas formigas formigas formigas formigas formigas formigas formigas formigas formigas formigas formigas formigas formigas formigas formigas formigas formigas formigas formigas formigas formigas formigas formigas _ _ _ _ _ _ _ _ _
formigas formigas formigas formigas formigas formigas formigas formigas formigas formigas formigas formigas formigas formigas
formigas formigas formigas formigas formigas formigas formigas formigas formigas formigas formigas formigas formigas formigas formigas formigas formigas formigas formigas formigas formigas formigas formigas formigas _ _ _ _ _ _ _ _ _
formigas
formigas
formigas formigas formigas formigas formigas formigas formigas formigas formigas formigas de formigas.jpeg sem etiqueta
correspondente Pule esta imagem ! _ formigas imageNotFound.gif não tem tag correspondente Pular esta imagem! formigas formigas formigas formigas formigas adiciona captura de exceção, o que resolve o problema de a imagem não ter um rótulo correspondente !
conjunto de dados operação prática três
Crie um conjunto de dados usando o conjunto de dados em Torchvision
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
"""
@Project :Pytorch_learn
@File :dataset_3.py
@IDE :PyCharm
@Author :咋
@Date :2023/7/2 14:58
"""
import torchvision
from torch.utils.data import DataLoader
from tensorboardX import SummaryWriter
from torchvision import transforms
dataset = torchvision.datasets.MNIST("./Mnist",train=True,download=True,transform=transforms.ToTensor())
dataloader = DataLoader(dataset,batch_size=64,shuffle=False,num_workers=0)
# 使用tensorboard将dataloader展示出来
'''方式一
# write = SummaryWriter("log_2")
# count = 0
# for data in dataloader:
# image,label = data
# # print(data[1])
# # print(image.shape)
# write.add_images("dataloader",image,count)
# count += 1
'''
# 方式二
write = SummaryWriter("log_3")
for i,data in enumerate(dataloader):
image,label = data
write.add_images("dataloader",image,i)
write.close()
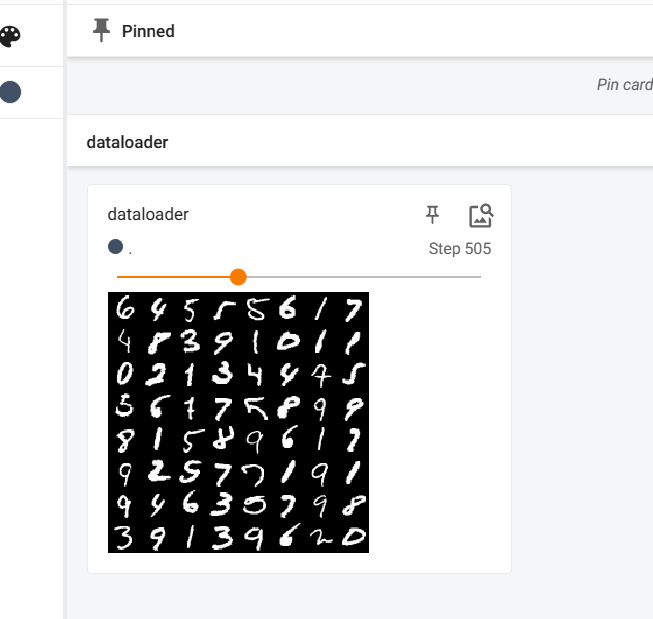
enumerate retorna o conteúdo de um objeto iterável junto com seu índice:
例如对于一个seq,得到:
(0, seq[0]), (1, seq[1]), (2, seq[2])
五、carregador de dados
Forneça diferentes tipos de dados para redes subsequentes
Personalize o conjunto de dados e carregue-o com datalodar
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.autograd import Variable
from net import Net
import softmax
from torch.utils.data import Dataset
import os
from PIL import Image
import numpy as np
transform_tool = transforms.ToTensor() # 创建一个transform工具
# # image_tensor = transform_tool(image)
with open("mnist-label.txt", 'r') as f:
label_str = f.read().strip() # 打开文件读入缓存
class Mydata(Dataset):
def __init__(self,image_path):
self.image_path = image_path
# self.label_path = label_path # /ants
self.image = os.listdir(self.image_path) # 从根目录开始绝对路径文件夹下的对象 hymenoptera_data/hymenoptera_data/train/ants下的图片 type--> list
def __getitem__(self, idx):
image_name = self.image[idx] # 单一的图片名称
image_item_path = os.path.join(self.image_path,image_name)
img = Image.open(image_item_path)
# transform_tool = transforms.ToTensor() # 创建一个transform工具
img = transform_tool(img)
labels_list = [int(label) for label in label_str.split(',')] # 读取标签,不用每次都打开
labels = np.array(labels_list)
label = labels[idx]
return img,label
def __len__(self):
return len(self.image)
# trainset = Mydata("mnist-dataset")
# 设置训练参数
batch_size = 32
epochs = 5
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 数据集
# transform = transforms.Compose([transforms.ToTensor(),
# transforms.Normalize((0.5,), (0.5,))])
# trainset =
# trainset = datasets.MNIST('~/.pytorch/MNIST_data/', download=True, train=True, transform=transform)
trainset = Mydata("mnist-dataset")
trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size, shuffle=False,num_workers=0)
print(len(trainloader))
# 输出提示信息
print("batch_size:", batch_size)
print("data_batches:", len(trainloader))
print("epochs:", epochs)
# 神经网络
net = Net().to(device)
# net.load_state_dict(torch.load('./model/model.pth'))
# 损失函数和优化器
# 负对数似然损失
criterion = nn.NLLLoss()
optimizer = optim.SGD(net.parameters(), lr=0.0005, momentum=0.9)
total_correct = 0
total_samples = 0
# 训练网络
```python
for epoch in range(epochs):
running_loss = 0.0
for i, data in enumerate(trainloader):
inputs, labels = data
inputs, labels = Variable(inputs).to(device), Variable(labels).to(device)
# 反向传播优化参数
optimizer.zero_grad()
outputs = net(inputs)
# outputs = int(net(inputs))
# print(outputs)
labels = labels.long()
# print(labels)
# print(type(labels))
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
# 计算每个batch的准确率
_, predicted = torch.max(outputs.data, 1)
total_samples += labels.size(0)
total_correct += (predicted == labels).sum().item()
if i % 5 == 0: # 每轮输出损失值
accuracy = 100.0 * total_correct / total_samples
print('[epoch: %d, batches: %d] loss: %.5f accuracy: %.2f%%' %
(epoch + 1, i + 1, running_loss / 2000, accuracy))
total_correct = 0
total_samples = 0
running_loss = 0.0
torch.save(net.state_dict(), 'model.pth') # 每轮保存模型参数
print('Finished Training')
Você pode abrir o arquivo antes de definir a classe, ler as informações do arquivo no cache e ler cada rótulo em __getitem__, sem abrir o arquivo toda vez que executar __getitem__.
Seis, algumas operações de os
windows使用两个\\表示路径
import os
dir_path = "/home/aistudio" # 文件夹目录
data_dir = os.listdir(dir_path) # 获取文件夹目录中的对象
label_path = "label"
all_path = os.path.join(dir_path,label_path)