Índice
Capítulo 1 Introdução ao sistema operacional
Capítulo 2 Descrição do Processo e Controle/Threads
Capítulo 3 Controle de Simultaneidade - Exclusão Mútua e Sincronização
Capítulo 4 Tratamento de Impasses
Capítulo 5 Gerenciamento de Memória
Capítulo 6 Agendamento do Processador
Capítulo 7 Gerenciamento de dispositivos de E/S
Capítulo 1 Introdução ao sistema operacional
1. Definição de sistema operacional
OS é um conjunto de programas que controlam e gerenciam os recursos de hardware e software do computador , agendam razoavelmente vários trabalhos e facilitam o uso dos computadores pelos usuários. Ou seja, fornece serviços para programas de usuários e é a interface entre usuários e sistemas de hardware.
2. O papel do sistema operacional
O sistema operacional é o núcleo do sistema de computador. É responsável por gerenciar os recursos de software e hardware de todo o sistema de computador, formular estratégias de alocação para vários recursos, agendar programas de usuário em execução no sistema e coordenar as necessidades de recursos do usuário, para que todo o sistema de computador possa funcionar de forma eficiente e ordenada.
3. Classificações comuns de sistemas operacionais
①Sistema operacional de processamento em lote: processamento em lote de canal único (automático, sequencial e canal único), processamento em lote multicanal (paralelo no nível macro, serial no nível micro, alta utilização de recursos e alto rendimento do sistema; longo tempo de resposta do usuário e capacidade de interação com o drone)
② Sistema operacional de compartilhamento de tempo: rotação de fatia de tempo; simultâneo, interativo, independente e pontualidade
③Sistema operacional em tempo real: responda a eventos dentro de um tempo predefinido; oportuno e confiável
④SO de rede SO distribuído e SO incorporado
4. A definição de tecnologia de multiprogramação, o motivo e o propósito de introduzir a tecnologia de multiprogramação
A tecnologia de multiprogramação permite que vários programas entrem na memória ao mesmo tempo e permite que eles sejam executados alternadamente na CPU. Quando um programa é suspenso devido a uma solicitação de I/O, a CPU imediatamente passa a executar outros programas, aproveitando todos os recursos e dobrando a eficiência do trabalho.
Introduzir a tecnologia de multiprogramação para melhorar ainda mais a utilização de recursos e a taxa de transferência do sistema, e aproveitar ao máximo o paralelismo dos componentes do sistema de computador
5. A relação entre o sistema operacional e o hardware, outro software do sistema e usuários
O sistema operacional é a primeira camada de software que cobre o hardware, que gerencia diretamente os recursos de hardware e software do computador e fornece uma boa interface aos usuários;
O sistema operacional é um software de sistema especial. Outro software de sistema é executado com base no sistema operacional e pode obter um grande número de serviços fornecidos pelo sistema operacional. Ou seja, o sistema operacional é a interface entre outro software de sistema e hardware;
Além do suporte ao sistema operacional, os usuários em geral também precisam usar um grande número de outros softwares de sistema e aplicativos para tornar seu trabalho mais conveniente e eficiente.
6. A definição de tecnologia de multiprogramação e os benefícios trazidos pela introdução desta tecnologia em SO
A tecnologia de multiprogramação refere-se ao armazenamento de vários trabalhos na memória e ao agendamento automático de outro trabalho na memória para ser executado quando a operação for concluída ou ocorrer um erro. As principais vantagens da multiprogramação são as seguintes:
(1) Alta utilização de recursos. Como vários programas são carregados na memória, eles compartilham recursos e mantêm os recursos do sistema ocupados, para que vários recursos possam ser totalmente utilizados.
(2) A taxa de transferência do sistema é grande. Como a CPU e outros recursos do sistema permanecem "ocupados" e alternam apenas quando o trabalho é concluído ou não pode continuar, a sobrecarga do sistema é pequena e, portanto, a taxa de transferência é alta.
7. A principal força motriz para a formação e desenvolvimento de sistemas de processamento em lote e sistemas de tempo compartilhado
(1) A principal força motriz para a formação e desenvolvimento de sistemas de processamento em lote: melhoria contínua da utilização de recursos do sistema e taxa de transferência do sistema: a aplicação de tecnologia de entrada/saída offline e transição automática de tarefas melhora muito a velocidade de E/S e o grau de trabalho paralelo entre dispositivos de E/S e CPU, reduzindo o tempo ocioso da CPU host; a aplicação da tecnologia de multiprogramação melhora ainda mais a utilização da CPU, memória e dispositivos de E/S e a taxa de transferência do sistema.
(2) A principal força motriz para a formação e desenvolvimento do sistema de compartilhamento de tempo é atender melhor às necessidades dos usuários: o uso de compartilhamento de tempo da CPU reduz o tempo médio de execução dos trabalhos; o fornecimento de recursos de interação humano-computador permite que os usuários controlem diretamente seus próprios trabalhos; o compartilhamento de hosts permite que vários usuários usem o mesmo computador ao mesmo tempo para processar seus trabalhos de forma independente e sem interferir uns com os outros.
8. Os principais problemas na realização do sistema de compartilhamento de tempo
A questão-chave na realização do sistema de compartilhamento de tempo é permitir que o usuário interaja com seu próprio trabalho, ou seja, o sistema pode receber e processar o comando a tempo após o usuário inserir um comando em seu próprio terminal para solicitar o serviço do sistema e retornar o resultado ao usuário dentro de um atraso aceitável para o usuário. É relativamente fácil receber comandos e retornar resultados de saída em tempo hábil. Geralmente, você só precisa configurar um cartão multicanal no sistema e configurar um buffer para cada terminal para armazenar temporariamente os comandos digitados pelo usuário e os resultados de saída.
9. O princípio da divisão de fatias de tempo
A fatia de tempo é o tempo alocado pela CPU para cada programa, ou seja, o tempo que o processo pode rodar, de forma que cada programa pareça estar rodando ao mesmo tempo. Se o processo ainda estiver em execução quando a fatia de tempo terminar, a CPU será retirada e atribuída a outro processo. Se o processo bloquear ou terminar antes do término da fatia de tempo, a CPU comuta imediatamente. Sem causar desperdício de recursos da CPU.
10. A partir dos três aspectos de interatividade, pontualidade e confiabilidade, compare o sistema de compartilhamento de tempo e o sistema de tempo real.
① pontualidade. Os requisitos de tempo real do sistema de processamento de informações em tempo real são semelhantes aos do sistema de compartilhamento de tempo, que são determinados pelo tempo de espera aceitável para os humanos; enquanto a pontualidade do sistema de controle em tempo real é determinada pelo prazo de início ou prazo de conclusão exigido pelo objeto de controle. Geralmente, está no nível de segundos a milissegundos, e alguns são até menores que 100 microssegundos.
② Interatividade. Embora o sistema de processamento de informações em tempo real também seja interativo, a interação entre o usuário e o sistema é limitada ao acesso a alguns programas de serviços especiais específicos no sistema. Ele não fornece serviços como processamento de dados e compartilhamento de recursos para usuários finais como um sistema de compartilhamento de tempo.
③Confiabilidade. Embora o sistema de tempo compartilhado também exija que o sistema seja confiável, em contraste, o sistema de tempo real exige que o sistema tenha um alto grau de confiabilidade. Como qualquer erro pode trazer enormes perdas econômicas, até mesmo consequências catastróficas imprevisíveis, em sistemas de tempo real, medidas de tolerância a falhas em vários níveis são frequentemente tomadas para garantir a segurança do sistema e a segurança dos dados.
11. Características do sistema operacional
(1) simultâneo
Dois ou mais eventos ocorrem no mesmo intervalo de tempo.
(A diferença é diferente do paralelismo: paralelismo significa que o sistema operacional tem as características de executar cálculos ou operações ao mesmo tempo e executar duas ou mais tarefas ao mesmo tempo.)
(2) Compartilhamento
① Compartilhamento mutuamente exclusivo: apenas um processo pode usá-lo por um período de tempo e outros jobs podem usá-lo somente após a liberação do job atual.
② Compartilhamento simultâneo: os recursos do sistema permitem acesso simultâneo (macroscópico) por vários processos em um período de tempo e acesso alternativo em nível microscópico
(3) virtuais
Transforme uma entidade física em várias funções logicamente correspondentes por meio de uma determinada tecnologia.
(4) assíncrono
Em um ambiente de multiprogramação, vários programas são executados simultaneamente, mas devido aos recursos limitados, a execução do processo não é consistente até o fim, mas avança em uma velocidade imprevisível.
12. Vantagens da estrutura do microkernel
A estrutura do microkernel é baseada na arquitetura cliente/servidor e adota a estrutura da tecnologia orientada a objetos.
①Flexibilidade. O microkernel é curto e enxuto, fornecendo apenas os serviços mais básicos e necessários.
② Abertura. As funções do sistema operacional, exceto o kernel, podem ser construídas no kernel na forma de um servidor.Com base nessa estrutura estrutural, os desenvolvedores de sistemas podem facilmente projetar, desenvolver e integrar seus próprios novos sistemas.
③ escalabilidade. É muito fácil implementar, instalar e depurar um sistema usando um sistema operacional microkernel. Os usuários podem reescrever serviços insatisfatórios que já possuem
Capítulo 2 Descrição e Controle do Processo /Threads
1. O estado básico do processo
① Criar estado. O estado do processo quando acabou de ser criado e ainda não entrou no estado pronto.
② Estado pronto. O processo obtém todos os recursos, exceto o processador , ele só precisa fazer com que o processador seja executado e, se vários processos estiverem no estado pronto, eles serão colocados na fila pronto.
③Estado em execução. O processo faz com que o processador seja executado. Apenas um processo pode ser executado em um único processador por vez
④ estado de bloqueio. O estado em que o processo está aguardando um recurso e suspendendo a operação, como aguardar um recurso ou aguardar a conclusão da entrada e saída, se houver vários processos bloqueados, armazene-os na fila de bloqueio.
⑤ estado final. O processo está desaparecendo do sistema e pode terminar normalmente ou passivamente. O sistema precisa colocar o processo em um estado final para recuperar os recursos relacionados.
2. Diagrama de transição de estado do processo

①Estado pronto→estado em execução: o processo no estado pronto é agendado pelo processador, obtém recursos do processador e pode ser executado
②Estado em execução→estado pronto: Em um sistema operacional não preemptivo, a fatia de tempo é consumida; em um sistema operacional preemptivo, um processo com maior prioridade entra e ele irá interromper o processador, fazendo com que o processo original retorne ao estado pronto
③Estado de execução → estado de bloqueio: o processo em execução precisa de outros recursos, ele entrará no estado de bloqueio
④Blocking state→ready state: Depois que os recursos necessários anteriormente forem obtidos, ele entrará novamente no estado pronto
3. Definição de travamento do processo
Trocar um processo no estado pronto ou bloqueado da memória para a memória externa
4. A causa do travamento

5. As primitivas usadas para controle de processo no sistema operacional, o papel dessas primitivas
①criar primitiva: cria um novo processo
② cancelar o idioma original: encerrar o processo
③ Bloco primitivo de bloqueio: altera o processo do estado em execução para o estado de bloqueio
④Primeira ativação: remove o processo da fila de espera e define seu estado como pronto
6. A estrutura do processo
Um processo é uma unidade operacional independente e a unidade básica para alocação de recursos e escalonamento pelo sistema operacional, geralmente inclui três partes: um bloco de controle de processo, um segmento de programa e um segmento de dados.
7. Definição do bloco de controle de processo
O PCB é uma parte da entidade do processo, o único sinal da existência do processo e a estrutura de dados do tipo registro mais importante no sistema operacional
8. A composição do bloco de controle de processo
① Identificador do processo
②Processamento e Status
③Informações de agendamento do processo
④ informações de controle de processo
9. O papel do PCB
O papel do PCB é fazer com que um programa que não pode ser executado de forma independente em um ambiente multiprogramas se torne uma unidade básica que possa ser executada de forma independente e possa ser executada simultaneamente com outros processos.
10. Que tipo de informação deve ter uma PCB clássica?
Informações de status do processador; informações de agendamento de processos; informações de controle de processos
11. Os principais passos para criar um novo processo
① Atribua um número de identificação de processo exclusivo ao novo processo e solicite um PCB em branco .
② Aloque recursos para o processo e aloque o espaço de memória necessário para o programa e os dados do novo processo e da pilha do usuário. Se os recursos forem insuficientes (como espaço de memória), não é que a criação falhe, mas sim um estado bloqueado, aguardando recursos de memória.
③Inicializar o PCB inclui principalmente informações de sinalizador de inicialização, informações de status do processador de inicialização, informações de controle do processador de inicialização e definição de prioridade do processo.
④ Insira o novo processo na fila de prontos, aguardando ser agendado para execução .
1 2. A diferença entre um processo e um programa
(1) Processo é um conceito dinâmico, enquanto programa é um conceito estático.Um programa é uma coleção ordenada de instruções sem significado de execução, enquanto um processo enfatiza o processo de execução.
(2) O processo tem características paralelas (independência, assincronia), mas o programa não.
(3) Processos diferentes podem conter o mesmo programa, e o mesmo programa também pode gerar vários processos durante a execução
1 3. O modo de execução do processo
modo de usuário; modo kernel
14. Comparar processos e threads em termos de agendamento, simultaneidade, propriedade de recursos, independência, sobrecarga do sistema e suporte para multiprocessadores
1) Agendamento. Em um sistema operacional que introduz threads, um thread é a unidade básica de agendamento independente e um processo é a unidade básica que possui recursos; a troca de threads no mesmo processo não causará troca de processo. Alternar threads em diferentes processos, como alternar de um thread em um processo para um thread em outro processo, causará uma alternância de processo.
2) Simultaneidade. Em sistemas operacionais que introduzem threads. Não apenas os processos podem ser executados simultaneamente, mas também vários threads podem ser executados simultaneamente, para que o sistema operacional tenha uma melhor simultaneidade. O rendimento do sistema é melhorado.
3) Recursos próprios. Seja um sistema operacional tradicional ou um sistema operacional sem threads, um processo é a unidade básica que possui recursos; enquanto um thread não possui recursos do sistema (apenas alguns recursos essenciais), mas um thread pode acessar os recursos do sistema pertencentes ao processo.
4) Sobrecarga do sistema. Como o sistema deve alocar ou recuperar recursos, como espaço de memória, dispositivos de IO, etc., ao criar ou cancelar um processo, o overhead pago pelo sistema operacional é muito maior do que o overhead ao criar ou cancelar uma thread; enquanto a troca de threads precisa apenas salvar e definir uma pequena quantidade de conteúdo de registrador, o overhead é muito pequeno. Como vários threads no mesmo processo têm o mesmo espaço de endereço, a realização da sincronização e a comunicação entre eles se tornam mais fáceis. E sem a intervenção do sistema operacional.
15 , a definição de thread ULT em nível de usuário
Um encadeamento de nível de usuário refere-se a um encadeamento que não depende do núcleo do sistema operacional e é controlado pelo processo do aplicativo usando a biblioteca de encadeamentos para fornecer funções para criar, sincronizar, agendar e gerenciar encadeamentos.
16. A definição do thread de suporte do kernel KLT
Os threads no nível do kernel referem-se aos threads que dependem do kernel e são criados e revogados pelo kernel do sistema operacional.
17. A relação entre threads e processos
①Um processo pode ter vários threads, mas pelo menos um thread; e um thread só pode estar ativo no espaço de endereço de um processo.
②Os recursos são alocados aos processos e todos os threads do mesmo processo compartilham todos os recursos do processo.
③A CPU é alocada para o thread, ou seja, o thread está realmente rodando no processador.
④Threads precisam cooperar e sincronizar durante o processo de execução, e os threads de diferentes processos precisam usar comunicação de mensagem para alcançar a sincronização.
Capítulo 3 Controle de Simultaneidade - Exclusão Mútua e Sincronização
1. Princípios básicos a serem seguidos no uso de recursos críticos
O acesso a recursos críticos deve ser mutuamente exclusivo
2. Definição de seção crítica
O código que acessa recursos críticos no processo.
3. Os princípios que um processo deve seguir ao acessar a seção crítica
1) Ceda quando livre. Quando a seção crítica está livre, um processo que solicita a entrada na seção crítica pode ser autorizado a entrar na seção crítica imediatamente.
2) Aguarde se estiver ocupado. Quando um processo existente entra na seção crítica, outros processos que tentam entrar na seção crítica devem esperar.
3) Espera limitada. O processo que solicita o acesso deve ter a garantia de entrar na seção crítica dentro de um tempo limitado.
4) Abra mão do direito de esperar. Quando o processo não pode entrar na seção crítica, o processador deve ser liberado imediatamente para evitar que o processo fique em espera ocupada.
4. Interrompa o processamento
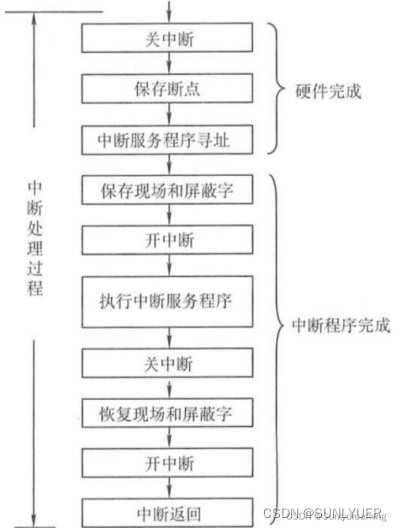
① Desligar interrupções : Após a CPU responder às interrupções, ela deve primeiro proteger o status do programa no local. Durante o processo de proteção, a CPU não pode responder a solicitações de interrupção de prioridade mais alta. Se um programa de maior prioridade for respondido, o programa de baixa prioridade não será salvo completamente e, após o processamento da interrupção, ele não poderá retornar ao estado anterior à interrupção.
② Salve o ponto de interrupção : Para garantir que o programa de serviço de interrupção possa retornar ao programa original corretamente após a execução, o ponto de interrupção do programa (o valor do PC do contador do programa) deve ser salvo
③ Encontre o endereço de entrada do programa de serviço de interrupção : a essência é retirar o endereço de entrada do programa de serviço de interrupção e enviá-lo para o PC do contador de programa. Aquisição do endereço de entrada: consulte a "tabela de vetores de interrupção" para encontrar o local de armazenamento do manipulador de interrupção correspondente na memória
Entre na rotina de serviço de interrupção e comece a executar a rotina de serviço de interrupção
④ Proteger a cena e a palavra de máscara : A primeira coisa após entrar na rotina do serviço de interrupção é proteger a cena e a palavra de máscara, principalmente para salvar a palavra de status do programa PSWR e o conteúdo de alguns registradores gerais
⑤Ativar interrupção : permite responder a interrupções de alto nível Se uma interrupção de alto nível chegar neste momento, você pode executar a interrupção de alto nível, porque as informações do site do programa interrompido foram salvas e responder à interrupção de alto nível não fará com que as informações do site do programa interrompido sejam restauradas. Incompleto
⑥ Processamento do programa de serviço de interrupção : Executa o programa de serviço de interrupção, que também é o objetivo da interrupção
⑦ Interrupção desligada : Após executar o programa de serviço de interrupção, antes do final do programa, a cena precisa ser restaurada, e esta operação não pode ser interrompida
⑧ Restaurar a cena : o programa de serviço de interrupção restaura os valores salvos anteriormente dos registros relevantes ao seu estado original
⑨Abrir interrupção : A rotina de serviço de interrupção está prestes a terminar, reabra a interrupção e permita responder a outras interrupções
⑩ Retorno ao ponto de interrupção para continuar a execução : a última instrução da rotina de serviço de interrupção geralmente é uma instrução de retorno de interrupção, fazendo com que ela retorne ao ponto de interrupção do programa para que o programa original possa continuar a ser executado
5. Como garantir que os processos tenham acesso mutuamente exclusivo a recursos críticos?
ceder se ocioso; esperar se ocupado; espera limitada; esperar se ocupado
6. Como resolver exclusão mútua com método de hardware (incluindo dois métodos)
①Mascaramento de interrupção: a comutação do processo da CPU é concluída por meio de interrupções, portanto, as interrupções de blindagem podem permitir que o processo em execução seja executado sem problemas, impedir que outros processos entrem na seção crítica e, em seguida, garantir a realização da exclusão mútua. As etapas típicas são: desligar a interrupção → seção crítica → abrir a interrupção.
Este método é simples e eficiente, mas só se aplica ao processo do kernel do sistema operacional, não ao processo do usuário; a eficiência de execução do processador diminui; se a interrupção não for habilitada após o desligamento da interrupção, o sistema pode ser encerrado.
②Instrução de hardware: Instrução TestAndSet: Esta instrução é uma operação atômica (o processo de execução não pode ser interrompido) e é usada para definir o sinalizador especificado de leitura como verdadeiro; Instrução de troca: Usada para trocar o conteúdo de dois bytes
7. O que é "espera ocupada" e suas desvantagens
A "espera ocupada" refere-se à espera de "não abrir mão do direito", ou seja, quando o processo não pode continuar executando devido à ocorrência de determinado evento, ele ainda ocupa a UCP e aguarda a conclusão do evento executando continuamente instruções de teste de loop.
A principal desvantagem da "espera ocupada" é que ela desperdiça tempo da CPU e também pode causar consequências inesperadas.
Por exemplo, considere um sistema que adota um princípio de escalonamento de alta prioridade.Existem atualmente dois processos A e B compartilhando um determinado recurso crítico.A tem uma prioridade mais alta e B tem uma prioridade mais baixa.
8. Como usar semáforos para resolver problemas de exclusão mútua «
Exclusão mútua significa que processos diferentes executam operações PV no mesmo semáforo; resolver exclusão mútua significa que apenas um processo tem permissão para acessar recursos críticos por unidade de tempo
Os processos P1 e P2 são executados simultaneamente e ambos têm suas próprias seções críticas, mas o sistema requer que apenas um processo entre em sua própria seção crítica por vez, então o valor inicial do semáforo S é definido como 1 (o número de recursos disponíveis é 1) e a seção crítica é colocada entre as operações P e V para realizar acesso mutuamente exclusivo a recursos críticos por dois processos:
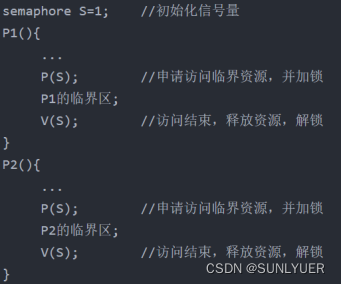
Se não houver processo na área crítica, qualquer processo entra para executar a operação P, trava S-- em 0 e depois entra; se houver processo na área crítica, S é 0 neste momento, e se você quiser executar a operação P, você se bloqueará até que o processo na área crítica saia, obtendo assim a exclusão mútua.
9. P, V operação do semáforo
P operação (espera(s), valor--), significa que o processo se aplica a um recurso desse tipo;
V operação (sinal(es), valor++), indicando que o processo libera um recurso;
10. Composição do monitor
①O nome do tubo
②Descrição dos dados da estrutura compartilhada localizados dentro do monitor
③ Um conjunto de procedimentos (ou funções) que operam na estrutura de dados
④ Uma instrução que define o valor inicial para os dados compartilhados que são locais para o monitor
11. Características do monitor
① Variáveis locais no monitor só podem ser acessadas por processos limitados ao monitor; e vice-versa, ou seja, processos locais ao monitor só podem acessar variáveis no monitor.
② Qualquer processo só pode entrar no monitor chamando a entrada do processo fornecida pelo monitor. Para o exemplo acima, o processo externo só pode solicitar um recurso por meio do processo take_away().
③ A qualquer momento, no máximo um processo pode ser executado no monitor, de forma a realizar a exclusão mútua de processos. Um monitor é um componente de uma linguagem de programação e sua implementação requer o suporte de um compilador
12. Primitivas de passagem de mensagens
Primitivas de envio e primitivas de recebimento: aparecem em pares, geralmente combinadas como bloqueio de envio, bloqueio de recebimento; envio sem bloqueio, recebimento com bloqueio; envio sem bloqueio, recebimento sem bloqueio
Capítulo 4 Tratamento de Impasses
1. Definição de impasse
Deadlock refere-se a um impasse (esperando um pelo outro) causado por vários processos competindo por recursos. Sem forças externas, esses processos não podem continuar avançando.
2. Quatro condições necessárias para o impasse
① Exclusão mútua : apenas um processo ocupa recursos no mesmo intervalo de tempo
② Inalienável : Os recursos obtidos pelo processo só podem ser liberados por ele mesmo, não podendo ser ocupados à força por outros processos
③Request and hold : Um processo que já possui um recurso faz uma nova solicitação de recurso, mas o recurso já está ocupado por outro processo, o processo está bloqueado, mas o recurso obtido ainda está retido
④Espera circular : Existe uma cadeia de espera circular de recursos do processo, e os recursos obtidos por cada processo na cadeia são solicitados simultaneamente pelo próximo processo
3. A causa raiz do impasse
①Competição por recursos do sistema: Como os recursos inalienáveis não podem atender às necessidades de vários processos a serem executados, esses processos ficam em um impasse na competição por recursos inalienáveis, resultando em um impasse.
② Avanço ilegal do processo: Quando dois processos P1 e P2 ocupam os recursos 1 e 2 respectivamente, se P1 solicitar o recurso 2 e P2 solicitar o recurso 1 novamente, os dois processos entrarão em deadlock por falta de recursos, ou seja, a ordem inadequada de solicitação e liberação de recursos durante a execução do processo também levará ao deadlock.
4. Três maneiras de resolver impasses
①Prevenção de impasse: defina condições para destruir uma ou mais das quatro condições geradas pelo impasse
②Evitação de impasse: no processo de alocação dinâmica de recursos, adote uma certa estratégia para evitar que o sistema entre em um estado inseguro
③ Detecção e liberação de impasse: Durante o processo de execução do processo, se ocorrer um impasse em execução, o impasse é detectado pelo mecanismo de detecção e medidas como privar recursos e cancelar o processo são tomadas para liberar o sistema do impasse
5. Estratégia de alocação de recursos estáticos
Destrua a solicitação e mantenha as condições, adote a alocação estática e solicite todos os recursos necessários ao processo de uma só vez quando o processo estiver no estado pronto. Se todos os recursos forem solicitados, o processo será executado imediatamente e todos os recursos serão de propriedade apenas do processo atual durante o período de execução e não serão solicitados por outros processos.
6. Métodos para evitar impasses
Adotar estratégia de alocação estática de recursos;
Adote uma estratégia de alocação de recursos sob demanda
7. O que é um estado seguro
O estado seguro é que, em um determinado momento, o sistema pode alocar os recursos necessários para cada processo em uma determinada ordem ou sequência (por exemplo: P1, P2, ..Pn), até que cada processo possa obter a demanda máxima de recursos e garantir que todos os processos sejam concluídos sequencialmente. Nesse momento, a sequência é chamada de sequência segura. Enquanto uma sequência segura puder ser encontrada, o sistema estará em um estado seguro; se não houver uma sequência segura no sistema, o sistema estará em um estado inseguro.
8. Como saber se o sistema está em um estado seguro «
Exemplo : T0 é um estado seguro? Em caso afirmativo, forneça uma sequência segura
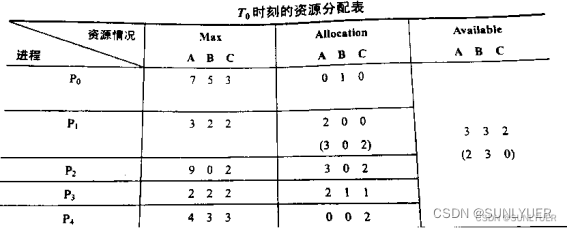

9. A ideia básica do algoritmo do banqueiro
Ideia central: Antes de executar o processo, declare a demanda máxima de vários recursos. Quando o processo continuar solicitando recursos durante a execução, primeiro teste se a soma do número de recursos ocupados pelo processo e o número de recursos solicitados desta vez excede a demanda máxima declarada pelo processo. Se exceder, recuse a alocação de recursos; se não exceder, então teste se os recursos existentes do sistema podem atender ao máximo de recursos que o processo ainda precisa; se puder atender, aloque recursos de acordo com o valor atual da aplicação; caso contrário, a alocação também será postergada.
10. Gráfico de alocação de recursos e sua simplificação
No gráfico de alocação de recursos, encontre um processo que não esteja bloqueado nem isolado (ou seja, encontre uma aresta direcionada conectada a ela e o número de aplicativos de recursos correspondentes à aresta direcionada seja menor ou igual ao número de recursos ociosos no sistema). Elimine todas as arestas de solicitação e arestas de alocação, tornando-o um nó isolado. Para julgar se um recurso tem espaço, aplique sua quantidade de recursos menos seu grau de saída no gráfico de alocação de recursos. Após uma série de simplificações de acordo com o método acima, se todas as arestas do grafo puderem ser eliminadas, diz-se que o grafo está completamente simplificado.
Capítulo 5 Gerenciamento de Memória
1. Definição de memória virtual
O armazenamento virtual é um sistema de armazenamento que carrega apenas parte de um trabalho na memória para executá-lo. Especificamente, refere-se a um sistema de armazenamento que tem a função de transferência e substituição de solicitações e pode expandir logicamente a capacidade de memória.
2. Principais tecnologias para a realização da memória virtual
A realização da memória virtual é baseada nos métodos de gerenciamento de armazenamento de alocação discreta, como paginação de solicitação , segmentação de solicitação e página de segmento de solicitação três métodos de gerenciamento de armazenamento; ao mesmo tempo, é necessária a realocação dinâmica, ou seja, tecnologia de realocação e registros de realocação.
3. Mude a tecnologia
A tecnologia de troca é mover uma parte ou a totalidade de um programa e dados que não são usados temporariamente da memória para a memória externa para liberar o espaço de memória necessário; ou ler o programa ou dados especificados da memória externa para a memória correspondente e transferir o controle para ela
Swap out - mova o processo no estado de espera (bloqueado) da memória para a memória externa para liberar espaço na memória
Swapping in — move um processo que está pronto para competir pela CPU do armazenamento externo para a memória principal
4. Definição de endereço lógico e endereço físico
① Endereço lógico: Após a compilação do código-fonte, o endereço usado no programa de destino é o endereço lógico. Cada módulo de destino começa a endereçar a partir da unidade 0 e sua faixa de endereço correspondente é o espaço de endereço lógico; diferentes processos podem ter o mesmo endereço lógico e podem ser mapeados para diferentes locais da memória principal
②Endereço físico: a coleção de unidades físicas na memória, o endereço final da tradução de endereços, as instruções de execução do processo e os dados de acesso devem ser acessados da memória principal por meio do endereço físico
5. Definição de realocação
Tradução de endereços que converte o endereço lógico usado no espaço de endereços para o endereço físico no espaço de memória, também chamado de mapeamento de endereços
De acordo com o tempo e os meios de conversão de endereço, a realocação é dividida em realocação estática e realocação dinâmica.
6. Três métodos de zoneamento
① Método de partição fixa: divide a memória do usuário em várias áreas de tamanho fixo e cada área carrega apenas um trabalho
②Método de partição dinâmica: A alocação de partição dinâmica não pré-divide a memória. Quando um processo é carregado na memória, as partições são estabelecidas dinamicamente de acordo com o tamanho do processo, de modo que o tamanho da partição seja ideal para as necessidades do processo.
③ Método de partição relocável:
7. O que é Patchwork
Para fazer uso razoável de áreas livres dispersas e menores, junte todos os fragmentos em uma área contínua, ou seja, mova o conteúdo de algumas áreas alocadas, de modo que todas as partições de trabalho sejam conectadas e deixe a área livre na outra extremidade
8. Recuperação e alocação de espaço de armazenamento no algoritmo de primeiro ajuste, algoritmo de melhor ajuste e algoritmo de pior ajuste
① Adaptação pela primeira vez: as partições livres são vinculadas em ordem crescente de endereço. Quando um trabalho chega, ele é pesquisado sequencialmente nessa tabela para localizar a primeira partição livre do tamanho necessário. As partições vazias restantes permanecem. Se não houver nenhuma partição elegível do começo ao fim, a alocação falhará.
②Melhor Adaptação: As partições livres formam uma cadeia de partições na forma de aumento de capacidade.Quando um trabalho chega, a primeira partição livre que atende aos requisitos é recuperada da tabela e atribuída a ela. Este método tem a menor fragmentação e, se a partição livre restante for muito pequena, toda a partição será alocada para ela.
③Pior adaptação: as partições livres são vinculadas em ordem decrescente de capacidade. Quando um job chega, a primeira partição livre que pode atender aos requisitos é recuperada da tabela, ou seja, a maior partição é selecionada. Este método tem a maior fragmentação, mas as partições livres restantes podem ser usadas novamente.
9. Definição de páginas
Divida o espaço de endereço lógico de um processo em partes de tamanho igual, cada uma chamada de página
10. Como dividir o tamanho da página?
O tamanho da página também deve ser moderado, geralmente uma potência inteira de 2 (518B~8KB). Se a página for muito pequena, o processo terá muitas páginas, fazendo com que a tabela de páginas seja muito longa para ocupar uma grande quantidade de memória e aumentar a sobrecarga da conversão de endereço de hardware. Se a página for muito grande, aumentará a fragmentação na página e reduzirá a utilização da memória.
11. Definição de bloqueio físico
Divida o espaço de memória em vários blocos de armazenamento do mesmo tamanho da página, que são blocos físicos ou molduras de página
12. O que é uma tabela de páginas? Qual é a função da tabela de páginas? estrutura da tabela de páginas?
Para saber onde as páginas de cada processo estão armazenadas na memória, o sistema operacional cria uma tabela de páginas para cada processo, um processo corresponde a uma tabela, cada página do processo corresponde a uma entrada da tabela de páginas (número da página + número do bloco) e registra a correspondência entre a página do processo e o bloco de memória real armazenado
13. O que é um sistema de paginação puro
O sistema de paginação pura significa que, ao agendar um trabalho, todas as suas páginas devem ser carregadas no bloco físico da memória de uma só vez. Quando o bloco físico é insuficiente, o trabalho deve aguardar até que haja blocos físicos suficientes e, em seguida, o sistema agenda outro trabalho.
14. Estrutura de endereço lógico no sistema de gerenciamento de memória de paginação

15. Processo de tradução de endereços no sistema de paginação de solicitação
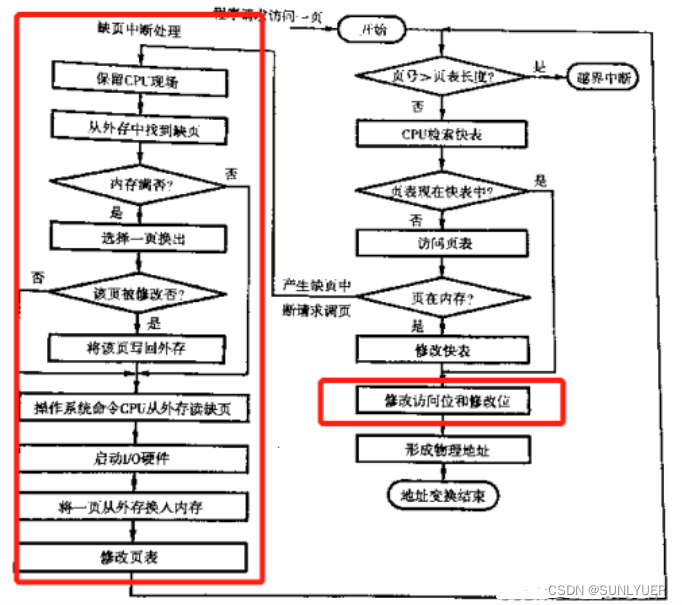
16. O que é gerenciamento de armazenamento segmentado
Ele divide o espaço de endereçamento do processo em vários segmentos de acordo com seu próprio relacionamento lógico. Cada segmento pode definir um conjunto relativamente completo de informações lógicas. Cada segmento é endereçado a partir de 0 (o nome do segmento pode ser programado pelo programador); a memória é alocada em unidades de segmentos. Cada segmento ocupa um espaço contínuo na memória, mas pode ser não adjacente (alocação discreta)
17. Definição de segmento
Um segmento é uma coleção de informações lógicas. Cada segmento tem seu próprio nome e endereçamento de comprimento a partir de 0, e um número de segmento é frequentemente usado em vez do nome do segmento
18. Como dividir o tamanho do segmento
O tamanho do segmento é determinado pelo comprimento do grupo de informações lógicas correspondente, portanto, o comprimento de cada segmento pode ser diferente
19. Estrutura da tabela de segmentos
Cada processo possui uma tabela de segmentos que mapeia o espaço lógico e o espaço de memória.Cada entrada da tabela de segmentos corresponde a um segmento do processo e registra o comprimento do segmento e a posição inicial do segmento na memória.
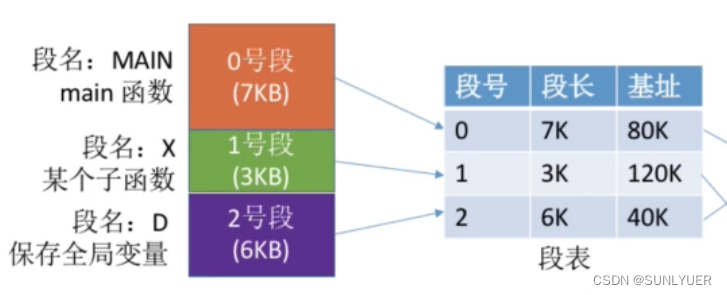
20. Estrutura Lógica de Endereços em Sistemas Segmentados

21. A diferença entre paginação e gerenciamento de memória segmentada
1) Uma página é uma unidade física de informação, e a paginação é devida às necessidades de gerenciamento do sistema, e não às necessidades do usuário, a fim de obter alocação discreta e melhorar a utilização da memória; segmento é uma unidade lógica de informação e o principal objetivo da segmentação é atender melhor às necessidades do usuário e ser visível para os usuários.
2) O tamanho da página é fixado pelo sistema, enquanto o comprimento do segmento não é fixo, depende do programa escrito pelo usuário.
3) O espaço de endereço do trabalho paginado é unidimensional, ou seja, um único espaço de endereço linear; enquanto o espaço de endereço do trabalho segmentado é bidimensional, para identificar um endereço, o número do segmento deve ser fornecido além do endereço do segmento fornecido
4) Em um processo, existe apenas uma tabela de segmentos, mas pode haver várias tabelas de páginas.
5) A segmentação é mais fácil de compartilhar e proteger informações do que a paginação.
6) Tanto a tabela de página de nível único quanto o acesso segmentado a um endereço lógico requerem dois acessos à memória.
23. Como lidar com a interrupção do segmento
No sistema de segmento de solicitação, sempre que o segmento a ser acessado pelo processo não tiver sido transferido para a memória, o mecanismo de interrupção de segmento gerará um sinal de interrupção de segmento e, em seguida, o sistema operacional transferirá o segmento necessário para a memória por meio do manipulador de interrupção de segmento. Como o mecanismo de interrupção de falha de página, o mecanismo de interrupção de segmento de falha gera e manipula interrupções durante a execução de uma instrução, e múltiplas interrupções de segmento de falha podem ser geradas durante a execução de uma instrução. Ao contrário de uma página, um segmento tem comprimento indefinido, portanto, o tratamento de interrupções de falta de segmento é muito mais complicado do que o de interrupções de falta de página.
24. O que é gerenciamento de armazenamento de página de segmento
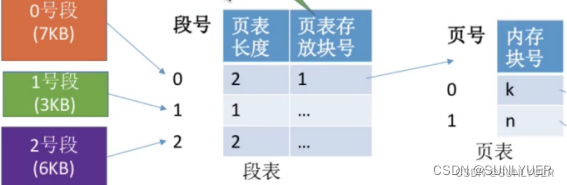
O gerenciamento de armazenamento de página de segmento é uma combinação de métodos de gerenciamento de página e segmento, segmentado por programa e, em seguida, paginado dentro do segmento. Ou seja, o programa do usuário é logicamente dividido em vários segmentos, cada segmento é dividido em várias páginas e a memória é dividida em blocos de tamanhos correspondentes
25. Tabela de segmentos e estrutura da tabela de páginas no gerenciamento de armazenamento de páginas de segmentos
Cada segmento no processo corresponde a uma entrada da tabela de segmentos, e cada entrada da tabela de segmentos consiste em um número de segmento, um comprimento da tabela de páginas e um número de bloco de armazenamento da tabela de páginas (endereço inicial da tabela de páginas). Cada entrada da tabela de segmentos tem comprimento igual e o número do segmento está implícito.
Cada página corresponde a uma entrada da tabela de páginas e cada entrada da tabela de páginas consiste em um número de página e um número de bloco de memória onde a página é armazenada. Cada entrada da tabela de páginas tem o mesmo comprimento e o número da página está implícito.
26. Algoritmo de substituição de página (requer domínio da abreviação em inglês do algoritmo)
①OPT de substituição ideal: Selecione as páginas que nunca serão usadas depois de eliminadas, ou páginas que não serão acessadas por mais tempo, de modo a garantir a menor taxa de falha de página. Mas o sistema operacional não pode prever qual página será acessada a seguir, então, na verdade, o OPT não pode ser realizado
②FIFO First-in-first-out: Elimine as páginas que entram na memória primeiro (ou as que permanecem na memória por mais tempo), classifique as páginas de acordo com a ordem em que são carregadas na memória e selecione a página inicial ao substituir
③ LRU há mais tempo sem uso: Cada vez que for eliminada a página que não foi utilizada há mais tempo, o campo acesso no item tabela de páginas pode ser utilizado para registrar o tempo que a página passou desde a última visita, sendo selecionada para eliminação a página com maior valor entre as páginas existentes.
④ Substituição do relógio CLOCK27.
27. O que é jitter
Para a página que acabou de ser trocada, ela será trocada para a memória imediatamente, e a página que acabou de ser trocada será trocada para fora da memória imediatamente. Esse comportamento frequente de troca de página é chamado de jitter
O principal motivo do jitter é que existem poucos blocos físicos alocados para o processo, e o número de páginas frequentemente acessadas pelo processo é maior do que o número de blocos físicos disponíveis, o que faz com que o processo gaste mais tempo na troca do que o tempo de execução, e o processo fica em estado de jitter
28. Definição da taxa de falta de página
Número de faltas de página/número de acessos ao processo
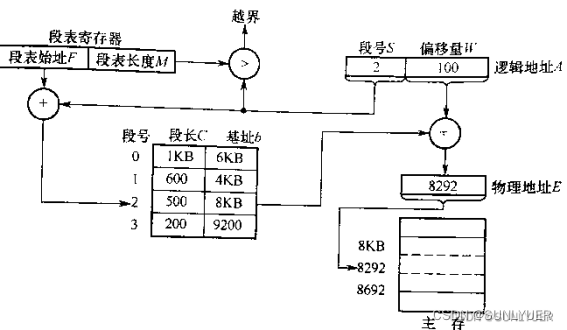
29. Processo de tradução de endereços em sistema de memória segmentada
Obtenha o número do segmento e o deslocamento de acordo com o endereço lógico, compare o número do segmento S com o comprimento da tabela de segmentos M, se S>=M estiver fora dos limites, caso contrário, continue;
Consulte a tabela de segmentos, o endereço da entrada da tabela de segmentos correspondente a S = o endereço inicial da tabela de segmentos F + o número do segmento S * o comprimento da tabela de segmentos M, de modo a retirar o comprimento do segmento C, se C <= deslocamento W, então o limite é interrompido, caso contrário, continue;
Obtenha o endereço físico E=b+W, acesse a memória;
Capítulo 6 Agendamento do Processador
1. Tarefas para agendamento avançado, agendamento intermediário e agendamento de baixo nível
2. Quais são os fatores que causam escalonamento de processos?
(1) O processo de execução termina normalmente ou anormalmente.
(2) O processo de execução está bloqueado por algum motivo.
(3) Em sistemas que introduzem fatias de tempo, as fatias de tempo se esgotam.
(4) No método de escalonamento preemptivo, a prioridade de um processo na fila de prontos torna-se maior do que a do processo em execução no momento, ou um processo com maior prioridade entra na fila de prontos.
3. Todos os algoritmos de agendamento de processo de P159
(1) Primeiro a chegar, primeiro a ser servido FCFS: Cada vez que o processo que primeiro entra na fila é selecionado da fila de prontos, o processador é atribuído a ele e é colocado em operação, e o processador não é liberado até que seja concluído ou bloqueado por algum motivo.
O FCFS é um algoritmo inalienável com um algoritmo simples, mas de baixa eficiência; é benéfico para jobs longos, mas desfavorável para jobs curtos (em comparação com SPF e alta taxa de resposta).
(2) Tarefas curtas primeiro SJF: Selecione um ou vários processos com o menor tempo estimado de execução da fila de prontos, atribua processadores a eles e execute-os imediatamente e libere os processadores até que sejam concluídos ou bloqueados por um evento.
① O algoritmo é desfavorável para trabalhos longos e o tempo de retorno de trabalhos longos no algoritmo de agendamento SJF aumentará. Se um trabalho longo entrar na fila de backup do sistema, como o agendador sempre prioriza o agendamento de trabalhos curtos, o trabalho longo não será agendado por muito tempo e pode ocorrer "inanição".
② A urgência do trabalho não é considerada, pelo que não há garantia de que o trabalho urgente será processado a tempo.
③ A duração do trabalho é determinada apenas de acordo com o tempo de execução estimado fornecido pelo usuário, e o usuário pode encurtar o tempo de execução estimado de seu trabalho intencionalmente ou não, e o algoritmo pode não ser capaz de realmente atingir o agendamento de prioridade de trabalho curto.
④ O tempo médio de espera e o tempo médio de retorno do algoritmo de escalonamento SJF são os menores.
(3) Prioridade de alta taxa de resposta HRRN: primeiro calcule a taxa de resposta de cada tarefa na fila de tarefas de backup e selecione a tarefa com a taxa de resposta mais alta e coloque-a em operação.
Taxa de resposta = (tempo de espera + tempo de atendimento solicitado) / tempo de atendimento solicitado
① Quando o tempo de espera do trabalho é o mesmo, quanto menor o tempo de serviço, maior a taxa de resposta, o que é benéfico para o trabalho curto.
②Quando é necessário que o tempo de serviço seja o mesmo, a taxa de resposta do trabalho é determinada pelo tempo de espera. Quanto maior o tempo de espera, maior a taxa de resposta. Portanto, o algoritmo realiza primeiro a chegar, primeiro a ser atendido.
③ Para trabalhos longos, a taxa de resposta do trabalho pode aumentar com o aumento do tempo de espera. Quando o tempo de espera é longo o suficiente, a taxa de resposta pode ser aumentada para um nível alto e um processador também pode ser obtido. Portanto, o estado de fome é superado e os empregos de longo prazo são levados em consideração.
(4) Escalonamento de prioridade: Selecione o processo com a maior prioridade da fila de prontos.Se o novo processo de maior prioridade pode antecipar o processo em execução, ele pode ser dividido em algoritmo de escalonamento de prioridade não preemptiva e algoritmo de escalonamento de prioridade preemptiva.
(5) Rotação da fatia de tempo: O escalonador de processos sempre seleciona o primeiro processo da fila de prontos para executar de acordo com a ordem de chegada, ou seja, o princípio do primeiro a chegar, primeiro a ser atendido, mas executa apenas uma fatia de tempo. Após utilizar uma fatia de tempo, mesmo que o processo não tenha concluído sua execução, ele deve liberar (privar) o processador para o próximo processo pronto, e o processo privado retorna ao final da fila de prontos e reenfileira, esperando para executar novamente.
① Se a fatia de tempo for grande o suficiente para que todos os processos possam ser executados em uma fatia de tempo, degenere no algoritmo FCFS.
②Se a fatia de tempo for pequena, o processador alterna com frequência, a sobrecarga aumenta e o tempo de uso do processo diminui.
(6) Fila de feedback de vários níveis FB: O algoritmo de agendamento de fila de feedback de vários níveis é a síntese e o desenvolvimento do algoritmo de agendamento round-robin de fatia de tempo e o algoritmo de agendamento de prioridade. Ao ajustar dinamicamente a prioridade do processo e o tamanho da fatia de tempo, o algoritmo de agendamento de fila de feedback de vários níveis pode levar em consideração vários objetivos do sistema.
4. Quais são os algoritmos de escalonamento preemptivo? O que são escalonamentos não preemptivos?
①Preempção: rotação de fatia de tempo; fila de feedback de vários níveis; prioridade de tarefa curta; agendamento de prioridade
②Não preemptivo: prioridade de trabalho curta; prioridade de alta taxa de resposta; agendamento prioritário
5. Vantagens do algoritmo de agendamento de prioridade de alta taxa de resposta
① Quando o tempo de espera do trabalho é o mesmo, quanto menor o tempo de serviço, maior a taxa de resposta, o que é benéfico para o trabalho curto.
③ Para trabalhos longos, a taxa de resposta do trabalho pode aumentar com o aumento do tempo de espera. Quando o tempo de espera é longo o suficiente, a taxa de resposta pode ser aumentada para um nível alto e um processador também pode ser obtido. Portanto, o estado de fome é superado e os empregos de longo prazo são levados em consideração.
6. Tempo de resposta, tempo de resposta ponderado
①Tempo de execução: o tempo consumido desde o envio do trabalho até a conclusão do trabalho. Incluindo a soma do tempo gasto esperando por trabalhos, enfileirando-se na fila de prontos para executar no processador e realizando operações de entrada/saída.
Tempo de resposta T = tempo de conclusão do trabalho - tempo de envio do trabalho
③ Tempo de execução ponderado: O tempo de execução ponderado refere-se à relação entre o tempo de execução do trabalho e o tempo real de execução do trabalho.
Tempo de execução ponderado da tarefa w = tempo de execução da tarefa T/tempo real de execução Ts
Capítulo 7 Gerenciamento de dispositivos de E/S
1. Independência do dispositivo
O equipamento usado na programação do usuário não tem nada a ver com o equipamento real usado.Quando o programa do usuário executa entrada/saída, ele não precisa considerar dispositivos de entrada/saída específicos, mas pode usar um método geral para executar entrada/saída.
2. Nome lógico do dispositivo, nome físico do dispositivo
3. As funções que o mecanismo de comunicação da fila do buffer de mensagens deve ter
(1) Forme uma mensagem. O processo de envio define a área de envio a em sua própria área de trabalho e preenche o corpo da mensagem e as informações de controle relacionadas.
(2) Envie uma mensagem. Copie a mensagem da área de envio a para o buffer de mensagens e insira-a na fila de mensagens do processo de destino.
(3) Receber mensagens. O processo de destino encontra o primeiro buffer de mensagem de sua própria fila de mensagens e copia o conteúdo da mensagem para a área receptora b do processo.
(4) Exclusão e sincronização mútuas. A exclusão mútua refere-se à garantia de que apenas um processo opere na fila de mensagens dentro de um período de tempo; a sincronização refere-se à coordenação entre o processo de recebimento e o processo de envio. Para tanto, um semáforo para exclusão mútua e sincronização deve ser definido na PCB do processo receptor.
4. Definição e classificação dos canais de I/O
(1) O canal de E/S é um processador especialmente responsável pela entrada e saída. Ele pode reconhecer e executar uma série de instruções de canal. Com base no método DMA, reduzir ainda mais a intervenção da CPU, ou seja, reduzir a intervenção de leitura e gravação de um bloco de dados para a leitura e gravação de um grupo de blocos de dados e gerenciamento de controle relacionado e melhorar ainda mais a taxa de utilização da CPU.
(2) ①Byte multicanal: É adequado para conectar dispositivos de E/S de baixa ou média velocidade, como impressoras e terminais. Este canal funciona intercalado em unidades de bytes: quando um byte é transmitido para um dispositivo, ele é imediatamente transferido para transmitir um byte para outro dispositivo.
②Canal de seleção de matriz: É adequado para conectar dispositivos de alta velocidade, como discos e fitas. Esse tipo de canal funciona em "modo de grupo" e transmite um lote de dados por vez com uma alta taxa de transmissão, mas pode atender apenas um dispositivo por vez. Sempre que uma solicitação de I/O é processada, outro dispositivo é selecionado e atendido por ela. Pode-se observar que a utilização do canal é muito baixa
③Array multicanal: Este canal combina as características de trabalho de compartilhamento de tempo multicanal de bytes e alta taxa de transmissão de canais selecionados. Sua essência é: usar tecnologia de programação multicanal para programas de canal, para que os dispositivos conectados aos canais possam funcionar em paralelo.
5. Razões para introduzir a tecnologia de buffer na gestão de equipamentos
① Alivie a contradição entre a incompatibilidade de velocidade entre a CPU e os dispositivos de E/S
②Reduza a frequência de interrupção da CPU e relaxe as restrições na resposta à interrupção
③ Melhorar o paralelismo entre a CPU e os dispositivos de E/S
6. Classificação da tecnologia de buffer
①Buffer único: Portanto, a estratégia de buffer único é adotada e o tempo médio gasto no processamento de um dado é Max(C, T)+M
②Buffer duplo: adote a estratégia de buffer duplo, o máximo de tempo médio (M+C, T) para processar um dado
③Buffer circular
④ conjunto de buffers
7. Algoritmo de agendamento de disco
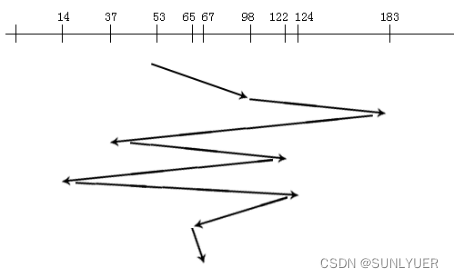
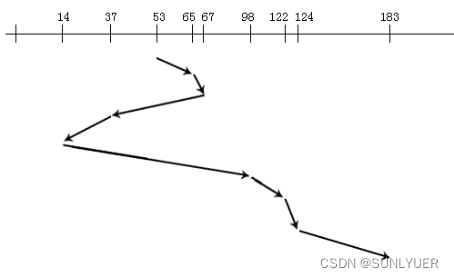
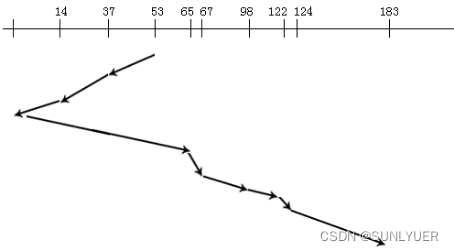
Suponha uma sequência de acessos ao disco: 98, 183, 37, 122, 14, 124, 65, 67. Posição inicial da cabeça de leitura/gravação: 53
①FCFS First-in-first-out: O processo é muito simples de manusear, mas o comprimento médio da busca será muito longo, o que é adequado para situações em que não há muitos pedidos de acesso
②Prioridade de tempo mais curta: Se a posição inicial da cabeça magnética for conhecida, o processo mais próximo da posição da cabeça magnética será processado primeiro e, em seguida, o processo mais próximo da faixa atual será processado após a conclusão do processamento, até que todos os processos sejam processados. A vantagem desse algoritmo é que o tamanho médio da busca será bastante reduzido, e a desvantagem é que os serviços que estão longe do cabeçalho inicial não podem ser processados por muito tempo, resultando em um fenômeno de "inanição".
③Estratégia de varredura: O cabeçote varre apenas em uma direção e completa todas as solicitações inacabadas durante a varredura até que o cabeçote alcance a última trilha do disco nessa direção ou a trilha onde a última solicitação nessa direção está localizada.
④Estratégia de varredura circular: Altere o caminho de varredura da cabeça magnética com base no algoritmo de varredura de disco: após a varredura para a camada mais interna, continue a varredura da camada mais externa para dentro, ou seja, a direção da varredura é a mesma.
