O MIM não se beneficia de dados maiores? Este artigo estuda sistematicamente a capacidade de escalonamento de dados do método MIM sob diferentes tamanhos de modelo e comprimentos de treinamento e verifica se a modelagem de imagem mascarada (MIM) não apenas tem a capacidade de escalonamento de modelo, mas também tem a capacidade de escalonamento de dados.
Este artigo é um trabalho de pesquisa experimental, o problema de pesquisa é o problema de escalonamento de dados de aprendizado auto-supervisionado (método de modelagem de imagem de máscara).
Um objetivo importante do aprendizado autossupervisionado é permitir que modelos pré-treinados se beneficiem de grandes quantidades de dados. Mas uma abordagem auto-supervisionada recente, modelagem de imagem mascarada (MIM), era suspeita de não se beneficiar de dados maiores.
Neste trabalho, o autor quebrou esse mal-entendido por meio de um grande número de experimentos. A escala de dados varia de 10% do ImageNet-1K ao ImageNet-22K completo, o tamanho do modelo varia de 49 milhões a 1 bilhão e o comprimento do treinamento varia de 125 mil iterações a 500 mil iterações. A pesquisa do autor mostra que:
-
A modelagem de imagem de máscara também requer dados maiores: os autores observam que modelos muito grandes tendem a se sobreajustar com dados relativamente pequenos.
-
A questão do tempo de treinamento: modelos grandes treinados por modelagem de imagem de máscara podem se beneficiar de mais dados por meio de treinamento mais longo.
-
A perda de validação no pré-treinamento é uma boa medida de quão bem um modelo é ajustado em várias tarefas: essa observação nos permite pré-avaliar de forma barata nosso modelo pré-treinado sem ter que avaliá-lo todas as vezes em tarefas posteriores, o que seria muito caro.
1 Dimensionamento de dados na modelagem de imagem de máscara
Nome do artigo: On Data Scaling in Masked Image Modeling (CVPR 2023)
Endereço de papel:
https://arxiv.org/pdf/2206.04664.pdf
1.1 Histórico e motivação
No campo da NLP, dimensionar a capacidade do modelo e o tamanho dos dados levou a melhorias significativas nos modelos de linguagem nos últimos anos. O método por trás dele é Masked Image Modeling (MIM). Parte do motivo do sucesso desse método pode ser que ele pode se beneficiar de uma quantidade quase ilimitada de dados.
No campo do CV, devido à falta de métodos auto-supervisionados eficazes, muitos trabalhos são baseados principalmente em tarefas de classificação de imagens, o enorme custo de rotulagem e a quantidade limitada de informações no rótulo limitam o dimensionamento do modelo visual das pessoas, de modo que o progresso da visão computacional fica muito atrás do campo do NLP.
Os métodos de pré-treinamento de visão autossupervisionada para Masked Image Modeling (MIM) alcançaram um desempenho impressionante em uma variedade de tarefas de visão computacional downstream graças ao MAE e ao SimMIM. Dada a sua alta semelhança com Masked Language Modeling, MLM, o principal método de pré-treinamento em PNL, este artigo espera que a modelagem de imagens mascaradas possa melhorar o desempenho de escala dos modelos de visão. Especificamente, os autores se concentram em dois aspectos dos recursos de dimensionamento, a saber: dimensionamento de modelo e dimensionamento de dados .
Os métodos de MIM demonstraram escalar bem a capacidade do modelo, mas sua capacidade de se beneficiar de dados maiores é menos clara. Mas os métodos MIM podem se beneficiar de grandes conjuntos de dados? Esta questão é crítica, pois uma característica importante do aprendizado auto-supervisionado é a capacidade de utilizar dados virtualmente ilimitados , e a falha em se beneficiar de dados maiores pode prejudicar o potencial futuro da modelagem de imagem de máscara.
Portanto, este artigo estuda sistematicamente as capacidades de escalonamento de dados dos métodos MIM sob diferentes tamanhos de modelo e comprimentos de treinamento . Por meio de extensos experimentos, este artigo descobriu que:
-
A modelagem de imagem de máscara também requer dados maiores: os autores observaram que modelos grandes superajustam quando treinados com dados relativamente pequenos, aumentando a perda do conjunto de validação. O problema de overfitting levará a um desempenho de ajuste fino ruim.
-
A questão do tempo de treinamento: modelos grandes treinados por modelagem de imagem de máscara podem se beneficiar de mais dados por meio de treinamento mais longo. Quando a duração do treinamento é curta, a diferença no desempenho usando conjuntos de dados grandes e pequenos não é significativa. Porém, se o treinamento for suficiente, o desempenho do modelo obtido por treinamento com mais dados será melhor. Além disso, à medida que a quantidade de dados aumenta, a taxa de saturação de desempenho de ajuste fino de modelos grandes é mais lenta do que a de modelos pequenos.
-
A perda no conjunto de validação durante o pré-treinamento é um bom indicador de quão bem um modelo é ajustado em várias tarefas: os autores observam uma forte correlação entre a perda de validação durante o pré-treinamento e o desempenho de ajuste fino em várias tarefas. Essa descoberta mostra que a perda do conjunto de validação é um bom indicador do grau de treinamento do modelo e pode ser usado para avaliar facilmente se o modelo é adequado para tarefas posteriores sem ajuste fino, o que pode economizar sobrecarga de avaliação.
Esses resultados demonstram que o Masked Image Modeling (MIM) é capaz de dimensionar não apenas o modelo, mas também os dados. Este artigo quebra o equívoco em estudos anteriores de que a modelagem de imagem mascarada não se beneficia de mais dados. Esperamos que essas descobertas aprofundem a compreensão da modelagem de imagem de máscara.
1.2 Método de Modelagem de Imagem de Máscara

1.3 Arquitetura do Modelo
Este estudo usa o Swin Transformer V2[1] como codificador visual. Devido à sua generalidade e escalabilidade, os autores avaliam o modelo SwinV2 em uma variedade de tamanhos de modelo (número de parâmetros variando de ~50M a ~1B, FLOPs variando de ~9G a ~190G) em várias tarefas downstream. A especificação detalhada do modelo é mostrada na Figura 1 abaixo. Os autores usaram uma nova variante, SwinV2-g (gigante), com um número de parâmetros entre SwinV2-L e o parâmetro de 3 bilhões SwinV2-G (Gigante).
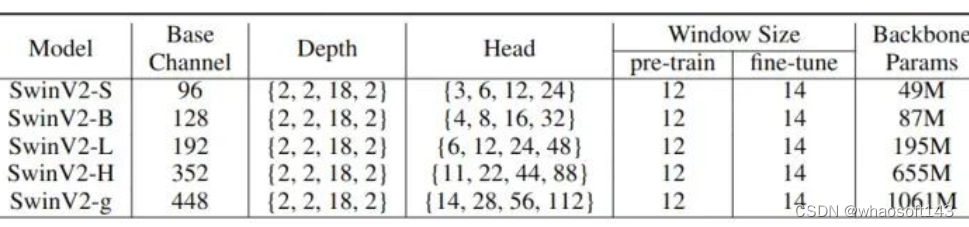
Figura 1: Arquitetura do modelo utilizado neste estudo
1.4 Conjunto de dados pré-treinamento
Para estudar o efeito do tamanho dos dados na modelagem de imagem de máscara, o autor construiu conjuntos de dados de tamanhos diferentes, usando os conjuntos de treinamento de ImageNet-1K e ImageNet-22K como dois conjuntos de dados de grande escala e selecionou aleatoriamente 10%, 20% e 50% das imagens no conjunto de treinamento ImageNet-1K como conjuntos de dados menores. Os detalhes e estatísticas de todos os conjuntos de dados pré-treinamento usados neste estudo são mostrados na Figura 2 abaixo.  Figura 2: conjunto de dados pré-treinamento usado neste estudo
Figura 2: conjunto de dados pré-treinamento usado neste estudo
1.5 Detalhes pré-treinamento
O número de iterações para todo o treinamento experimental é {125K, 250K, 500K} e o tamanho do lote é 2048. Na fase de pré-treinamento, os mesmos hiperparâmetros são usados para todos os modelos. Os detalhes do treinamento e os hiperparâmetros do pré-treinamento são mostrados na Figura 3 abaixo. Devido ao grande número de experimentos, o autor utiliza um escalonador de passos para a taxa de aprendizado no pré-treinamento. Para diferentes iterações de treinamento, o primeiro 7/8 é o primeiro passo e o último 1/8 é o segundo passo. A diferença entre os dois é que a taxa de aprendizado é multiplicada por 0,1. Este artigo usa a mesma estratégia de aprimoramento de dados do SimMIM: a escala de corte é [0,67,1], a taxa de redimensionamento é [3/4,4/3] e a probabilidade de inversão aleatória é de 0,5.
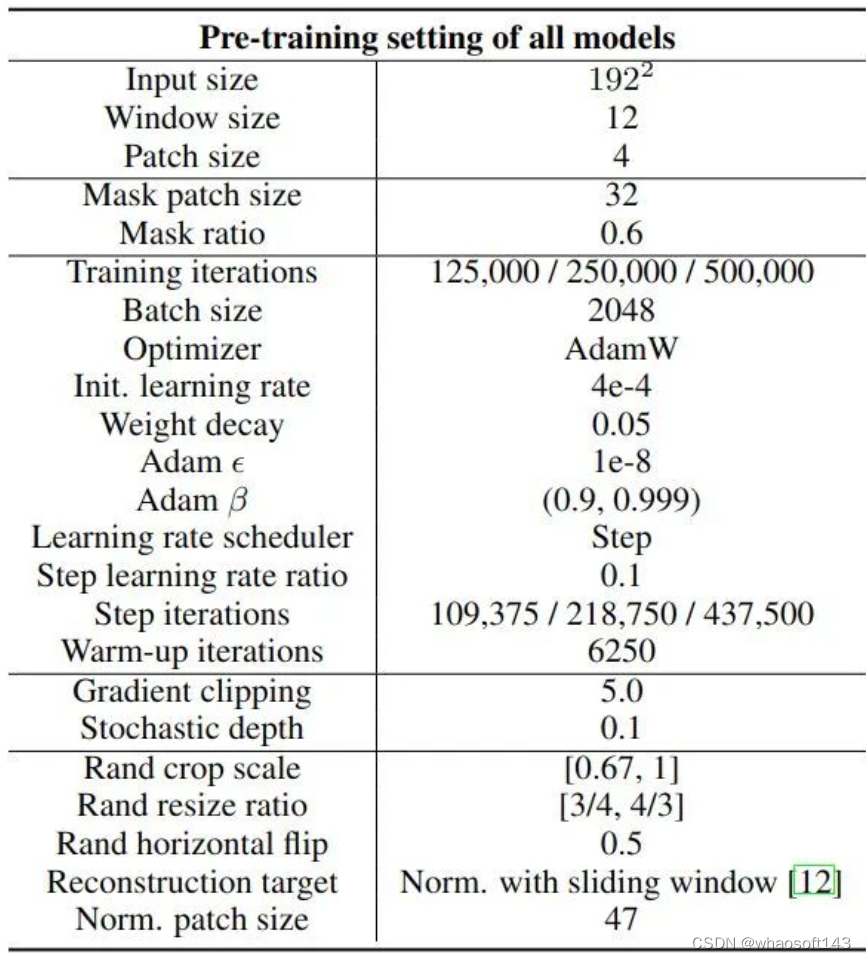
Figura 3: Detalhes do treinamento pré-treinado e hiperparâmetros
1.6 Tarefas downstream para ajuste fino
As tarefas downstream de ajuste fino para avaliar modelos pré-treinados são:
Classificação de imagens ImageNet-1K
hiperparâmetros de treinamento
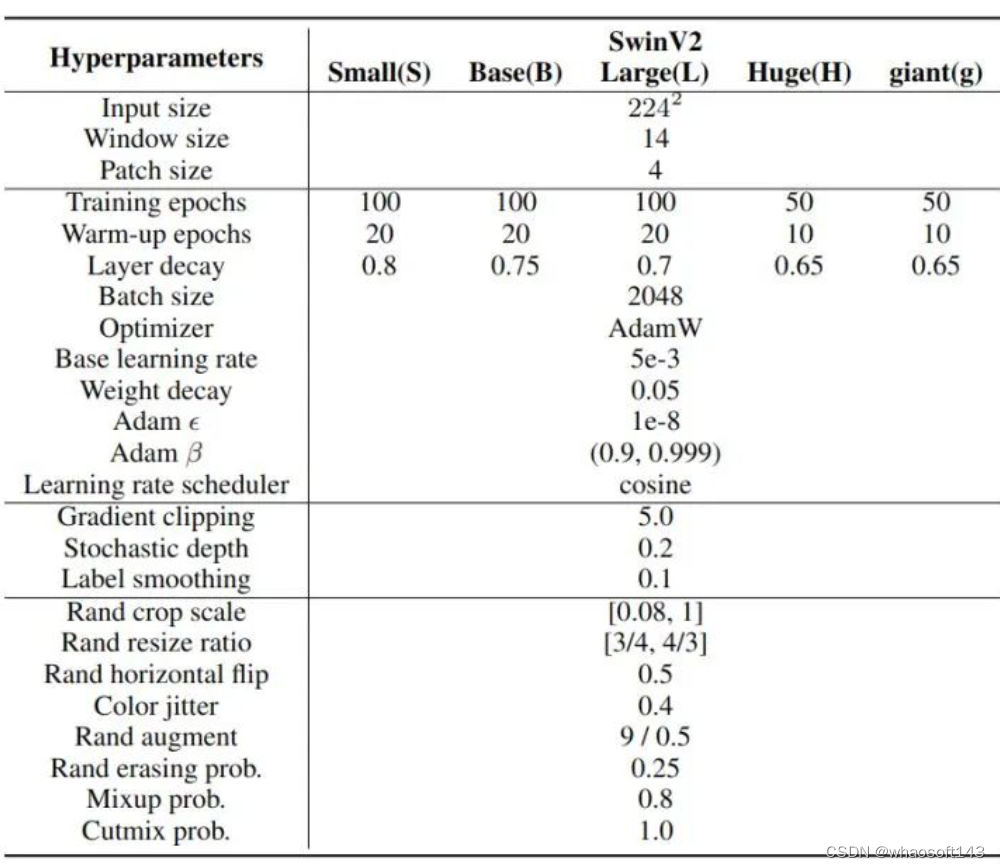 Figura 4: hiperparâmetros de treinamento de classificação de imagem ImageNet-1K
Figura 4: hiperparâmetros de treinamento de classificação de imagem ImageNet-1K
Conjunto de dados de classificação de imagem granulada de cauda longa iNaturalist 2018
Hiperparâmetros de treinamento 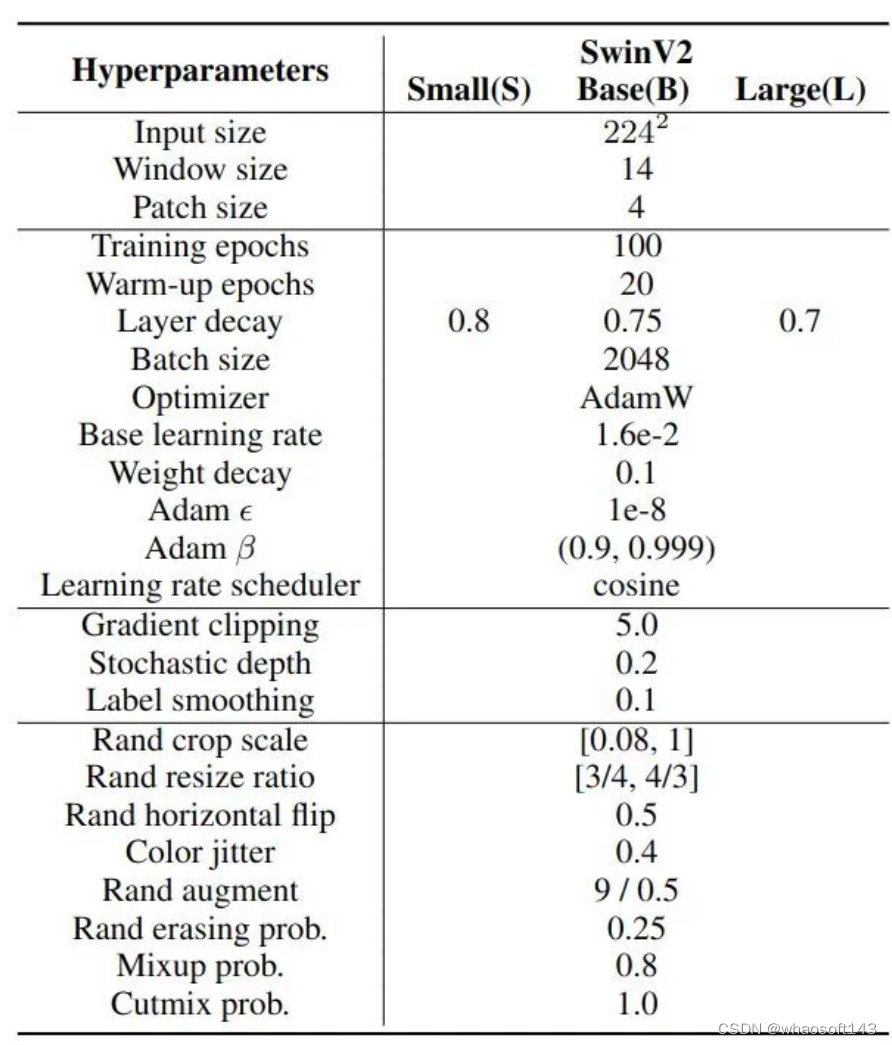 Figura 5: Hiperparâmetros de treinamento de classificação de imagem do conjunto de dados de cauda longa do iNaturalist 2018
Figura 5: Hiperparâmetros de treinamento de classificação de imagem do conjunto de dados de cauda longa do iNaturalist 2018
Detecção de objetos COCO e segmentação de instâncias
Hiperparâmetros de Treinamento 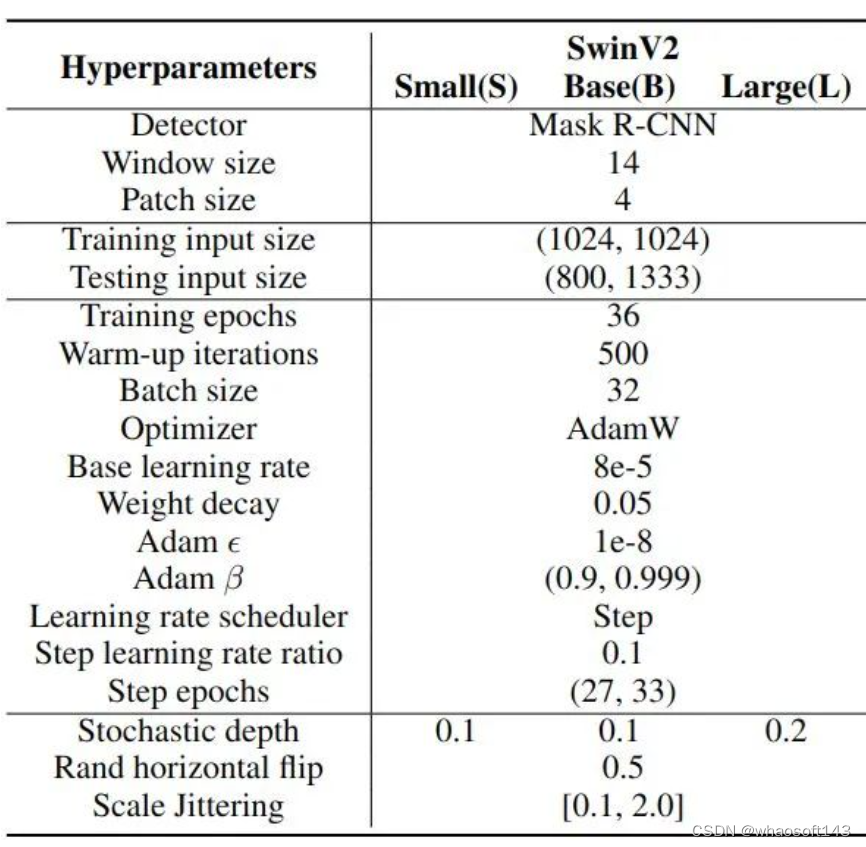 Figura 6: Detecção de Objeto COCO e Segmentação de Instância
Figura 6: Detecção de Objeto COCO e Segmentação de Instância
Segmentação Semântica ADE20K
Hiperparâmetros de treinamento 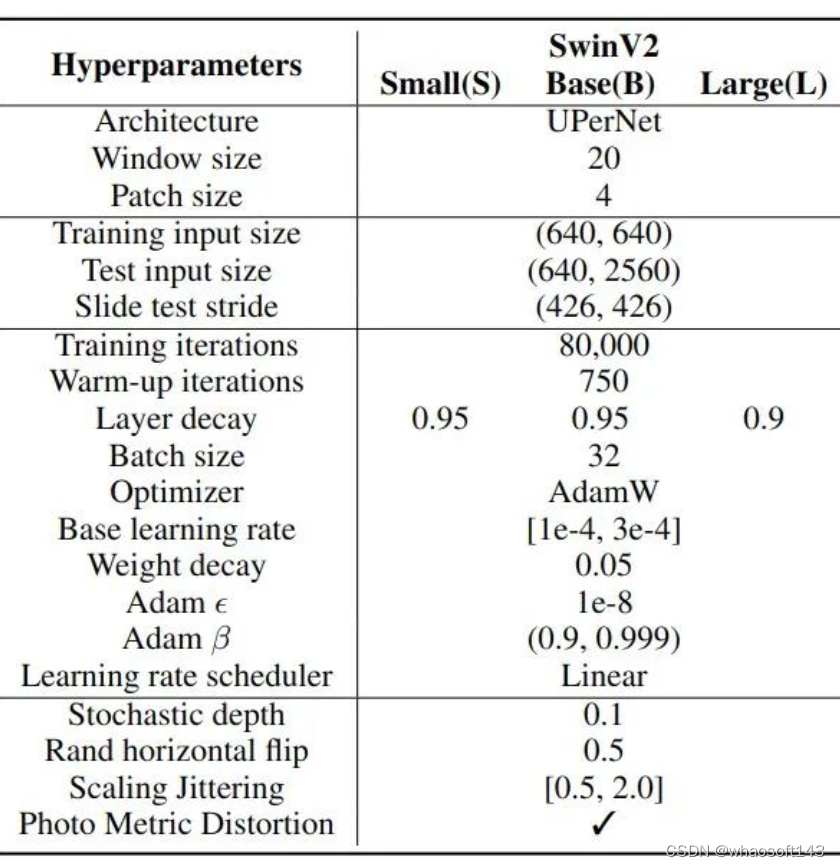 Figura 7: Hiperparâmetros de treinamento de segmentação semântica ADE20K
Figura 7: Hiperparâmetros de treinamento de segmentação semântica ADE20K
1.7 Resultado experimental 1: o MIM ainda tem altos requisitos para grandes conjuntos de dados
As Figuras 8 e 9 abaixo mostram a relação entre perda de treinamento e perda de validação e precisão de ajuste fino do ImageNet-1K.
 Figura 8: A relação entre perda de treinamento, perda de validação, precisão de ajuste fino do ImageNet-1K e comprimento de treinamento em diferentes modelos, tamanhos de dados e comprimentos de treinamento. Pontos maiores representam modelos maiores.
Figura 8: A relação entre perda de treinamento, perda de validação, precisão de ajuste fino do ImageNet-1K e comprimento de treinamento em diferentes modelos, tamanhos de dados e comprimentos de treinamento. Pontos maiores representam modelos maiores.
Pode-se observar na Figura 8 que à medida que o custo de treinamento aumenta, a perda de treinamento de alguns modelos diminui significativamente, mas a perda de validação aumenta significativamente Mesmo que 50% das imagens no ImageNet-1K sejam usadas, ainda há overfitting. A partir da Figura 9, pode ser visto que o desempenho do ajuste fino causado pelo overfitting cai significativamente.
 Figura 9: A relação entre perda de treinamento, perda de validação, precisão de ajuste fino do ImageNet-1K e duração do treinamento em diferentes modelos, tamanhos de dados e durações de treinamento
Figura 9: A relação entre perda de treinamento, perda de validação, precisão de ajuste fino do ImageNet-1K e duração do treinamento em diferentes modelos, tamanhos de dados e durações de treinamento
Além disso, os autores apresentam o melhor desempenho de ajuste fino de cada modelo na Figura 10 abaixo. Pode-se constatar que, quando treinado com um pequeno conjunto de dados, o desempenho do modelo grande é ainda pior do que o do modelo pequeno. Por exemplo, a melhor precisão top 1 do SwinV2-H em IN1K (20%) é 84,4, que é 0,3 pior do que o melhor desempenho do SwinV2-L. Além disso, um melhor desempenho pode ser alcançado com mais dados. Essas observações sugerem que os métodos de pré-treinamento MIM também requerem grandes conjuntos de dados.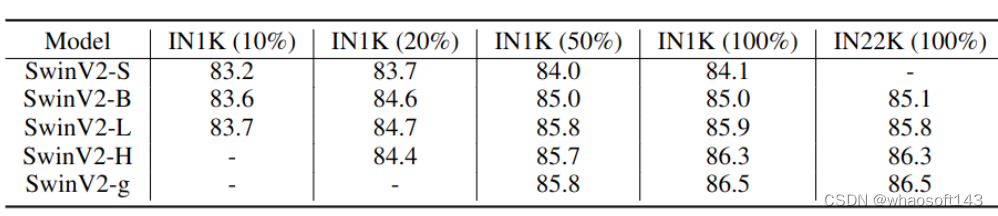
Figura 10: Melhor desempenho de ajuste fino do ImageNet-1K para cada modelo
1.8 Resultado experimental 2: A duração do treinamento também é importante, e modelos maiores podem se beneficiar de mais dados em durações de treinamento mais longas
Conforme mostrado na linha 3 da Figura 9 acima, comparando o desempenho de modelos pré-treinados com tamanhos de dados diferentes, os autores descobriram que o desempenho de ajuste fino de modelos grandes satura mais lentamente à medida que o tamanho dos dados aumenta em comparação com modelos menores . Por exemplo, um modelo SwinV2-S pré-treinado em IN1K (50%) tem desempenho de ajuste fino muito semelhante a um modelo pré-treinado em IN1K (100%). Em contraste, a diferença de desempenho entre os modelos SwinV2-H pré-treinados em IN1K (50%) e IN1K (100%) é próxima a 0,5, o que é uma lacuna significativa para a classificação ImageNet-1K.
Além disso, a melhoria do pré-treinamento com mais dados não é significativa em treinamentos mais curtos. Por exemplo, ao treinar iterações de 500K, há uma lacuna de desempenho significativa entre os resultados experimentais de SwinV2-H em IN1K (50%) e IN1K (100%). Mas ao treinar iterações de 120K, a diferença entre os resultados experimentais de SwinV2-H em IN1K (50%) e IN1K (100%) é menor que 0,1. Essa observação sugere que, embora modelos maiores possam se beneficiar de mais dados, a duração do treinamento também deve aumentar em paralelo.
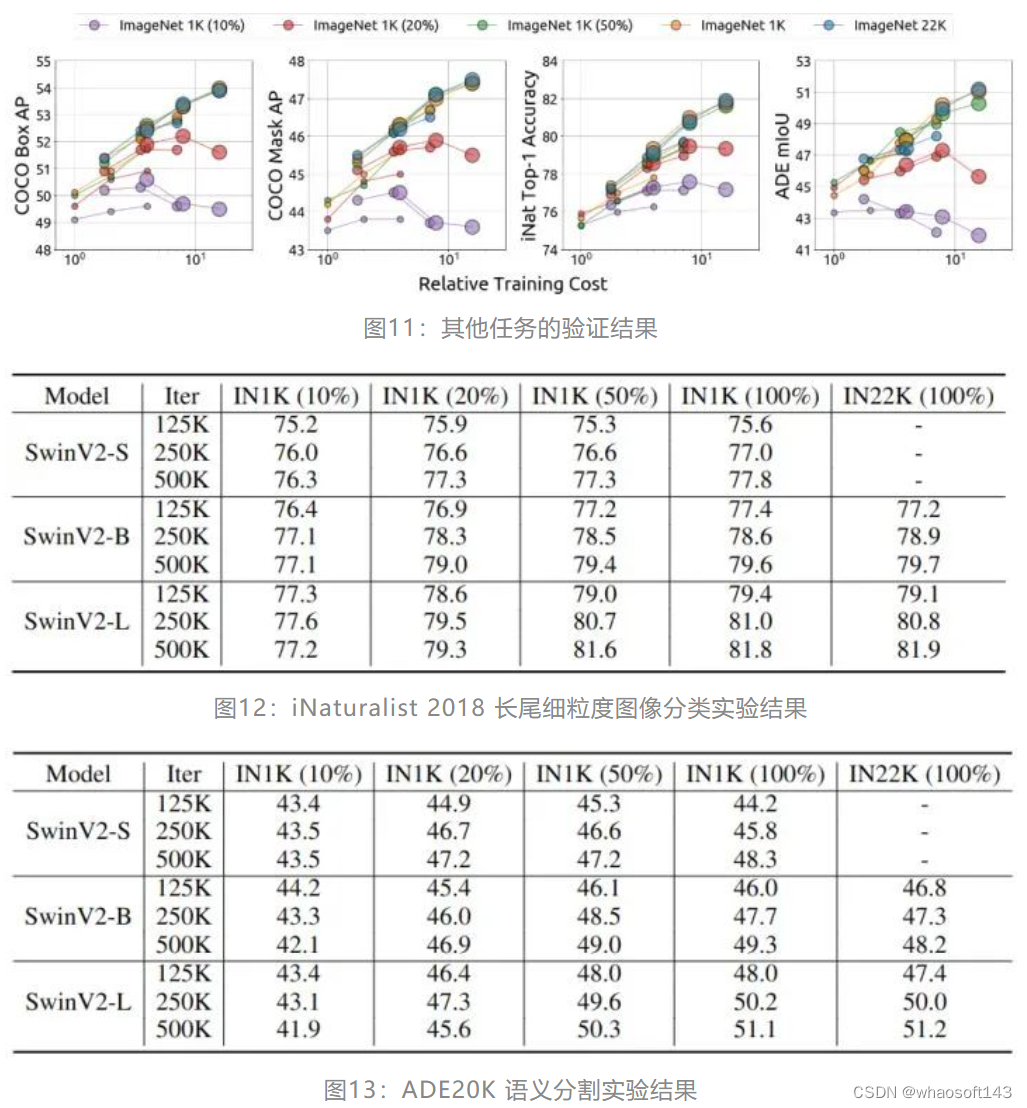
1.9 Resultado experimental 3: Verificação de outras tarefas
Além da classificação de imagem ImageNet-1K, o autor também avaliou o efeito de SwinV2-S, SwinV2-B e SwinV2-L pré-treinados com MIM na classificação de imagem granular iNaturalist 2018, segmentação semântica ADE20K e detecção de objeto COCO e segmentação de instância. Conforme mostrado na Figura 11 abaixo, à medida que o custo de treinamento aumenta, alguns modelos mostram sinais de overfitting. Além disso, conforme mostrado nas Figuras 12, 13 e 14, à medida que a quantidade de dados aumenta, modelos menores atingem rapidamente a saturação, enquanto modelos maiores podem se beneficiar continuamente de mais dados após treinamento suficiente. Esses resultados mostram que as conclusões tiradas no ImageNet-1K são amplamente aplicáveis a outras tarefas de visão.
 1.10 Relação entre perda pré-treinamento e desempenho de ajuste fino
1.10 Relação entre perda pré-treinamento e desempenho de ajuste fino
Os autores também exploram se a perda pré-treinada no treinamento MIM é um bom indicador de seu desempenho de ajuste fino. Conforme mostrado na Figura 15 abaixo, estão as curvas de perda de treinamento e validação de todos os modelos.
Para o modelo overfit (círculo verde), a correlação entre perda de treinamento e desempenho de ajuste fino em tarefas downstream é negativa, e a correlação entre perda de validação e desempenho de ajuste fino em tarefas downstream é positiva.
Para modelos sem overfitting (círculos vermelhos), a correlação entre perda de treinamento e desempenho de ajuste fino em tarefas downstream é negativa, e a correlação entre perda de validação e desempenho de ajuste fino em tarefas downstream é positiva. Tanto a perda de treinamento quanto a perda de validação estão positivamente correlacionadas com o desempenho de ajuste fino em tarefas a jusante.
Os resultados acima mostram que em múltiplas tarefas, a perda de validação no pré-treinamento é um bom indicador para medir o efeito de ajuste fino do modelo em múltiplas tarefas.
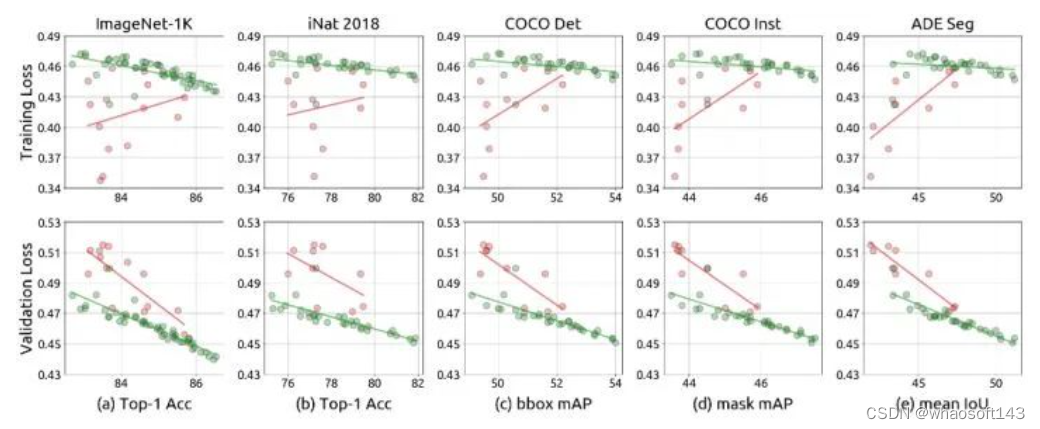 Figura 15: Relação entre perda pré-treinamento e desempenho de ajuste fino
Figura 15: Relação entre perda pré-treinamento e desempenho de ajuste fino
Os indicadores quantitativos encontrados acima são mostrados na Figura 16. Os dados na tabela da Figura 16 são os coeficientes de correlação de Pearson das perdas pré-treinamento e os resultados de ajuste fino das cinco tarefas posteriores. Pode ser visto que para as cinco tarefas downstream na Figura 16, a correlação de Pearson da correlação negativa entre a perda de validação pré-treinada e o desempenho de ajuste fino das tarefas downstream é baixa.

Figura 16: Coeficientes de correlação de Pearson de perdas pré-treinamento e resultados de ajuste fino de 5 tarefas a jusante
Resumo whaosoft aiot http://143ai.com
Este artigo é um trabalho de pesquisa experimental.O problema de pesquisa é o problema de escalonamento de dados de aprendizado auto-supervisionado (método de modelagem de imagem de máscara) e explora sistematicamente a capacidade de escalonamento de dados da modelagem de imagem de máscara sob diferentes tamanhos de modelo e comprimentos de treinamento. Os autores demonstram que a abordagem de aprendizado autossupervisionado do MIM não é apenas escalável por modelo, mas também escalável por dados. Isso desafia a conclusão da literatura anterior de que o MIM pode não exigir grandes conjuntos de dados. A razão por trás disso é que eles negligenciaram um fator crucial, a duração do treinamento. Além disso, uma forte correlação entre a perda de validação e o desempenho de ajuste fino do MIM também é observada. Essa observação sugere que a perda de validação pode ser considerada uma boa métrica proxy para avaliar modelos pré-treinados, portanto, essa observação nos permite pré-avaliar de forma barata nossos modelos pré-treinados sem ter que avaliar cada vez em tarefas downstream, o que seria muito caro.