Este artigo resume os mecanismos de atenção comumente usados no campo CV nos últimos anos, incluindo: SE (Squeeze and Excitation), ECA (Efficient Channel Attention), CBAM (Convolutional Block Attention Module), CA (Coordene a atenção para um design de rede móvel eficiente)
1. SE
O objetivo é atribuir diferentes pesos a diferentes canais no mapa de recursos, as etapas são as seguintes:
- Aperte o mapa de recursos. Esta etapa é converter o mapa de recursos de tamanho (N, C, H, W) para (N, C, 1, 1) por meio do agrupamento de média global, de modo a obter a fusão de informações de contexto global
- Operação de excitação, esta etapa usa duas camadas totalmente conectadas, a primeira camada totalmente conectada usa a função de ativação ReLU e a segunda camada totalmente conectada usa a função de ativação Sigmoid para mapear os pesos entre (0, 1). Vale ressaltar que para reduzir a quantidade de cálculo para redução de dimensionalidade, a saída da primeira conexão completa utiliza 1/4 ou 1/16 da entrada
- O peso é multiplicado pelo mapa de recursos de entrada por meio do mecanismo de transmissão para obter o mapa de recursos sob diferentes pesos
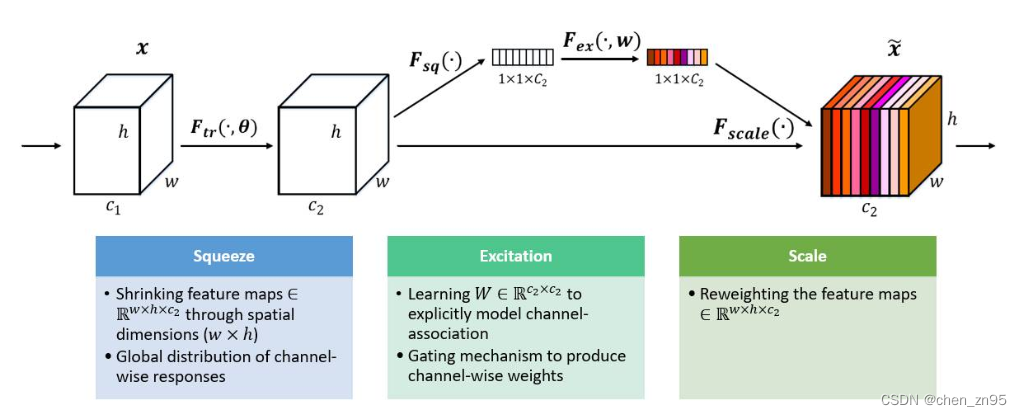
O código é implementado da seguinte forma,
import torch
import torch.nn as nn
class Se(nn.Module):
def __init__(self, in_channel, reduction=16):
super(Se, self).__init__()
self.pool = nn.AdaptiveAvgPool2d(output_size=1)
self.fc = nn.Sequential(
nn.Linear(in_features=in_channel, out_features=in_channel//reduction, bias=False),
nn.ReLU(),
nn.Linear(in_features=in_channel//reduction, out_features=in_channel, bias=False),
nn.Sigmoid()
)
def forward(self,x):
out = self.pool(x)
out = self.fc(out.view(out.size(0),-1))
out = out.view(x.size(0),x.size(1),1,1)
return out*x2. CEA
Você pode consultar " Mecanismo de Atenção ECA-Net Learning Record_eca Attention Mechanism_chen_zn95's Blog-CSDN Blog "
O ECA também é um mecanismo de atenção do canal. Este algoritmo fez algumas melhorias com base no SE. Primeiro, o autor do ECA acredita que a redução total da dimensionalidade da conexão no SE pode reduzir a complexidade do modelo, mas também destrói a correspondência direta entre os canais e seus pesos. A redução da dimensionalidade é primeiro seguida pelo aprimoramento da dimensionalidade, de modo que a correspondência entre os pesos e os canais seja indireta. Para resolver os problemas acima, o autor propõe um método de convolução unidimensional para evitar o impacto da redução de dimensionalidade nos dados. Os passos são os seguintes:
- Aperte o mapa de recursos. Esta etapa é converter o mapa de recursos de tamanho (N, C, H, W) para (N, C, 1, 1) por meio do agrupamento de média global, de modo a obter a fusão de informações de contexto global (igual à etapa 1 do SE)
- Calcule o tamanho do kernel de convolução adaptável, ,
onde, C: o número de canais de entrada, b=1, γ=2; execute uma operação de convolução unidimensional nos recursos processados na etapa 1 (para obter informações locais entre canais) e, em seguida, use a função de ativação Sigmoid para mapear o peso entre 0 e 1
- O peso é multiplicado pelo mapa de recursos de entrada por meio do mecanismo de transmissão para obter o mapa de recursos sob diferentes pesos
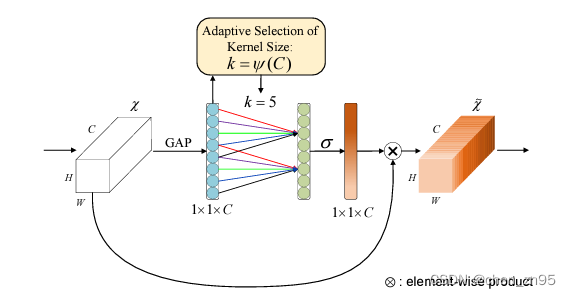
O código é implementado da seguinte forma,
import torch
import torch.nn as nn
import math
class ECA(nn.Module):
def __init__(self, in_channel, gamma=2, b=1):
super(ECA, self).__init__()
k = int(abs((math.log(in_channel,2)+b)/gamma))
kernel_size = k if k % 2 else k+1
padding = kernel_size//2
self.pool = nn.AdaptiveAvgPool2d(output_size=1)
self.conv = nn.Sequential(
nn.Conv1d(in_channels=1, out_channels=1, kernel_size=kernel_size, padding=padding, bias=False),
nn.Sigmoid()
)
def forward(self,x):
out=self.pool(x)
out=out.view(x.size(0), 1, x.size(1))
out=self.conv(out)
out=out.view(x.size(0), x.size(1), 1, 1)
return out*x3. CBAM
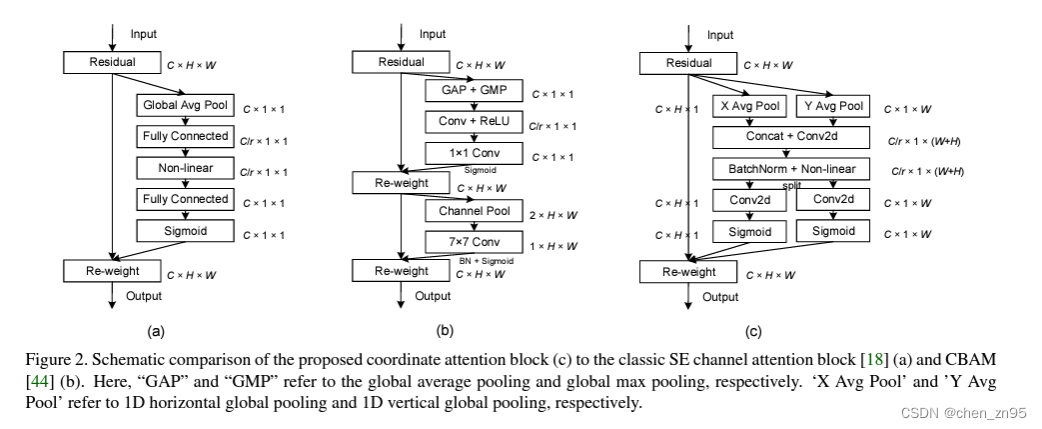
O CBAM é um algoritmo que combina o canal e o mecanismo de atenção espacial. O mapa de recursos de entrada é submetido primeiro ao mecanismo de atenção do canal e depois à operação do mecanismo de atenção espacial. Dessa forma, o objetivo de fortalecer a região de interesse é alcançado tanto do canal quanto do espaço.
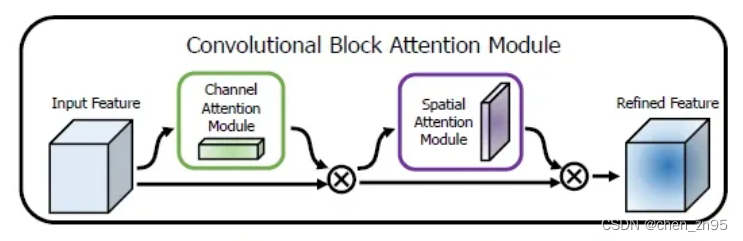
As etapas de implementação do mecanismo de atenção do canal são as seguintes:
- Aperte o mapa de recursos. Esta etapa usa agrupamento de média global e agrupamento máximo global para converter o mapa de recursos de tamanho (N, C, H, W) para (N, C, 1, 1), obtendo assim a fusão de informações de contexto global
- Os resultados de pooling máximo global e pooling de média global são, respectivamente, submetidos a operações MLP. MLP é definido aqui como a operação de camada totalmente conectada de SE. É uma camada totalmente conectada de duas camadas com ativação ReLU no meio. Finalmente, os dois são adicionados e ativados pela função Sigmoid.
- O peso é multiplicado pelo mapa de recursos de entrada por meio do mecanismo de transmissão para obter o mapa de recursos sob diferentes pesos

As etapas de implementação do mecanismo de atenção espacial são as seguintes:
- Execute o agrupamento máximo e o agrupamento médio na dimensão do canal para os resultados da operação de atenção do canal acima, ou seja, converta o mapa de recursos por meio do mecanismo de atenção do canal de (N, C, H, W) para (N, 1, H, W), una as informações de diferentes canais e, em seguida, concatene os resultados do agrupamento máximo e agrupamento médio na dimensão do canal
- Execute a operação de convolução nos resultados dos 2 canais sobrepostos, o canal de saída é 1, o tamanho do kernel da convolução é 7 e, finalmente, o resultado da saída é processado pelo Sigmoid
- O peso é multiplicado pelo mapa de recursos de entrada por meio do mecanismo de transmissão para obter o mapa de recursos sob diferentes pesos
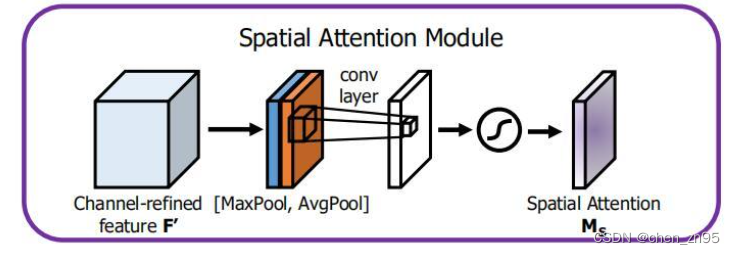
O código é implementado da seguinte forma,
import torch
import torch.nn as nn
import math
class CBAM(nn.Module):
def __init__(self, in_channel, reduction=16, kernel_size=7):
super(CBAM, self).__init__()
# 通道注意力机制
self.max_pool = nn.AdaptiveMaxPool2d(output_size=1)
self.avg_pool = nn.AdaptiveAvgPool2d(output_size=1)
self.mlp = nn.Sequential(
nn.Linear(in_features=in_channel, out_features=in_channel//reduction, bias=False),
nn.ReLU(),
nn.Linear(in_features=in_channel//reduction, out_features=in_channel,bias=False)
)
self.sigmoid = nn.Sigmoid()
# 空间注意力机制
self.conv = nn.Conv2d(in_channels=2, out_channels=1, kernel_size=kernel_size , stride=1, padding=kernel_size//2, bias=False)
def forward(self,x):
# 通道注意力机制
max_out = self.max_pool(x)
max_out = self.mlp(max_out.view(maxout.size(0), -1))
avg_out = self.avg_pool(x)
avg_out = self.mlp(avg_out.view(avgout.size(0), -1))
channel_out = self.sigmoid(max_out+avg_out)
channel_out = channel_out.view(x.size(0), x.size(1),1,1)
channel_out = channel_out*x
# 空间注意力机制
max_out, _ = torch.max(channel_out, dim=1, keepdim=True)
mean_out = torch.mean(channel_out, dim=1, keepdim=True)
out = torch.cat((max_out, mean_out), dim=1)
out = self.sigmoid(self.conv(out))
out = out*channel_out
return out4. CA
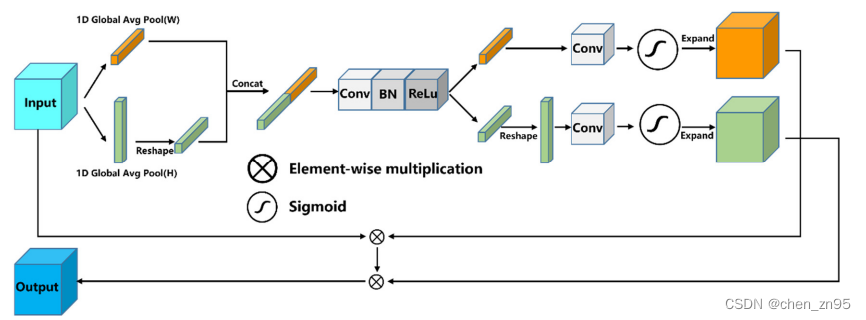
Os SEs são notavelmente eficazes em melhorar o desempenho do modelo, mas geralmente ignoram as informações de localização. A CA usa o agrupamento global nas direções x e y para agregar os recursos de entrada nas direções vertical e horizontal em dois mapas de recursos com reconhecimento de direção independentes e incorpora as informações de posição do mapa de recursos de entrada no vetor de recursos agregados da atenção do canal. Esses dois mapas de recursos que incorporam informações específicas de direção são codificados em dois mapas de atenção, respectivamente, e então esses dois mapas de atenção são aplicados ao mapa de recursos de entrada por multiplicação para fortalecer a representação da região de interesse. As etapas de implementação são as seguintes:
- Realize operações de agrupamento adaptativo no mapa de recursos de entrada ao longo das direções xey, altere o tamanho do mapa de recursos de (N,C,H,W) para (N,C,H,1), (N,C,1,W), execute uma operação de permuta no recurso com um tamanho de (N,C,1,W), de modo que o tamanho do recurso se torne (N,C,W,1) e, em seguida, concatene esses dois recursos junto (dim=2) para obter um mapa de recursos com um tamanho de (N,C,H+ W, 1 )
- Execute uma operação de convolução 1*1 nos recursos processados na etapa 1 (para redução de dimensionalidade) e, em seguida, passe pelas funções de ativação BN e h_swish
- Realize uma operação de divisão (torch.split) nos recursos processados na etapa 2 ao longo de dim=2 e divida os recursos em (N,C/r,H,1), (N,C/r,W,1), onde r é o fator de redução da dimensionalidade do canal. Em seguida, a operação de permuta é realizada no recurso de tamanho (N, C/r, W, 1), que se torna (N, C/r, 1, W). Por fim, uma operação de convolução 1*1 é realizada nos dois recursos acima (o objetivo é alterar o número de canais do mapa de recursos) e processada pelo Sigmoid
- Multiplique os dois recursos da etapa 3 com o mapa de recursos de entrada por meio do mecanismo de transmissão (out = identity * a_w * a_h) para obter o mapa de recursos com diferentes pesos
[Há um pequeno problema na figura abaixo, deve ser a operação de permuta no recurso 1D Global Avg Pool(W) ]
O código é implementado da seguinte forma,
import torch
import torch.nn as nn
import math
import torch.nn.functional as F
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)
class CoordAtt(nn.Module):
def __init__(self, inp, oup, reduction=32):
super(CoordAtt, self).__init__()
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
mip = max(8, inp // reduction)
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.act = h_swish()
self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
def forward(self, x):
identity = x
n,c,h,w = x.size()
x_h = self.pool_h(x)
x_w = self.pool_w(x).permute(0, 1, 3, 2)
y = torch.cat([x_h, x_w], dim=2)
y = self.conv1(y)
y = self.bn1(y)
y = self.act(y)
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
a_h = self.conv_h(x_h).sigmoid()
a_w = self.conv_w(x_w).sigmoid()
out = identity * a_w * a_h
return out