No último artigo, aprendemos e entendemos alguns conceitos básicos e operações básicas de fluxo óptico (Optical Flow), mas o método tradicional de estimativa de fluxo óptico é computacionalmente complexo e caro. Nos últimos anos, com o contínuo desenvolvimento e maturidade da rede neural convolucional CNN, ela alcançou grande sucesso em várias tarefas de visão computacional (usadas principalmente para tarefas relacionadas ao reconhecimento). Portanto, a série de artigos FlowNet foi proposta combinando a estimativa de fluxo óptico com o aprendizado profundo da CNN. Pela primeira vez, a CNN foi aplicada à previsão de fluxo óptico, para que a rede possa prever o campo de fluxo óptico a partir de um par de imagens, atingindo um taxa de 5 a 10 quadros por segundo. E a precisão atingiu o padrão da indústria.
1. FlowNet
FlowNet (ou FlowNet 1.0) é a primeira rede de estimativa de fluxo óptico proposta pela série FlowNet, e é também a rede mais importante e básica. Sua ideia vem do artigo "FlowNet: Learning Optical Flow with Convolutional Networks", publicado Na Conferência Internacional IEEE sobre Visão Computacional (ICCV), 2015.
Este artigo primeiro propõe uma estrutura de rede neural fim-a-fim para aprendizado de estimativa de fluxo óptico, que geralmente é uma estrutura Codificador/Decodificador . A informação é primeiramente submetida à compressão espacial e extração de características na parte menor da rede, e então refinada na parte em expansão. A entrada da rede FlowNet é um par de imagens (incluindo dois quadros adjacentes) e seu fluxo óptico correspondente. Em segundo lugar, como o conjunto de dados de fluxo óptico existente não é suficiente para treinar uma grande rede, este artigo também sintetizou um conjunto de dados de imagens de cadeiras chamado Flying Chairs por meio de síntese virtual , que obteve melhores resultados no processo de treinamento da rede.
1. Estrutura da rede
De acordo com a diferença na estrutura de rede da parte de codificação/encolhimento, o artigo subdivide FlowNet em duas estruturas, FlowNet-Simple (FlowNet-S) e FlowNet-Correlation (FlowNet-C), que são consistentes na parte decodificação/extensão .Vamos apresentá-los, respectivamente, da seguinte forma.
1.1 Codificação da parte contraída/peça contraída
(1)FlowNet-S
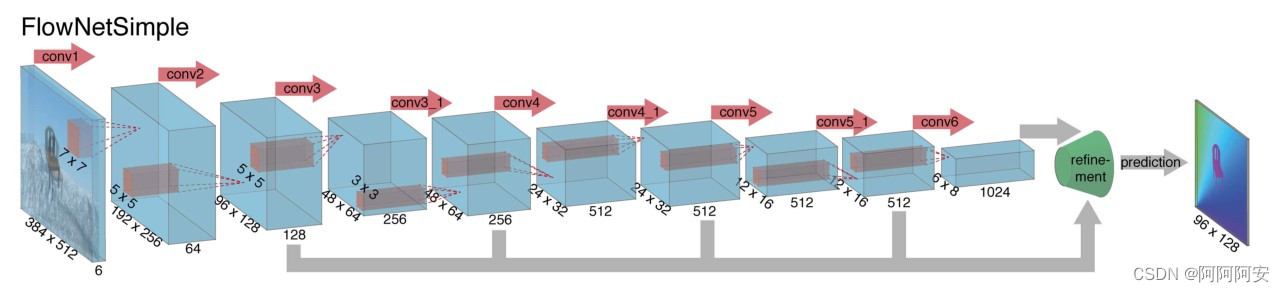
FlowNetSimple é a estrutura de rede mais simples e rude. A rede empilha (costura) diretamente a entrada de dois quadros de imagens na dimensão geral e, em seguida, usa uma série de camadas convolucionais para reduzir a amostra e extrair recursos, permitindo que a rede decida como para lidar com isso, pares de imagens para extrair informações de movimento deles, e a estrutura da rede é mostrada na figura acima.
(2)FlowNet-C
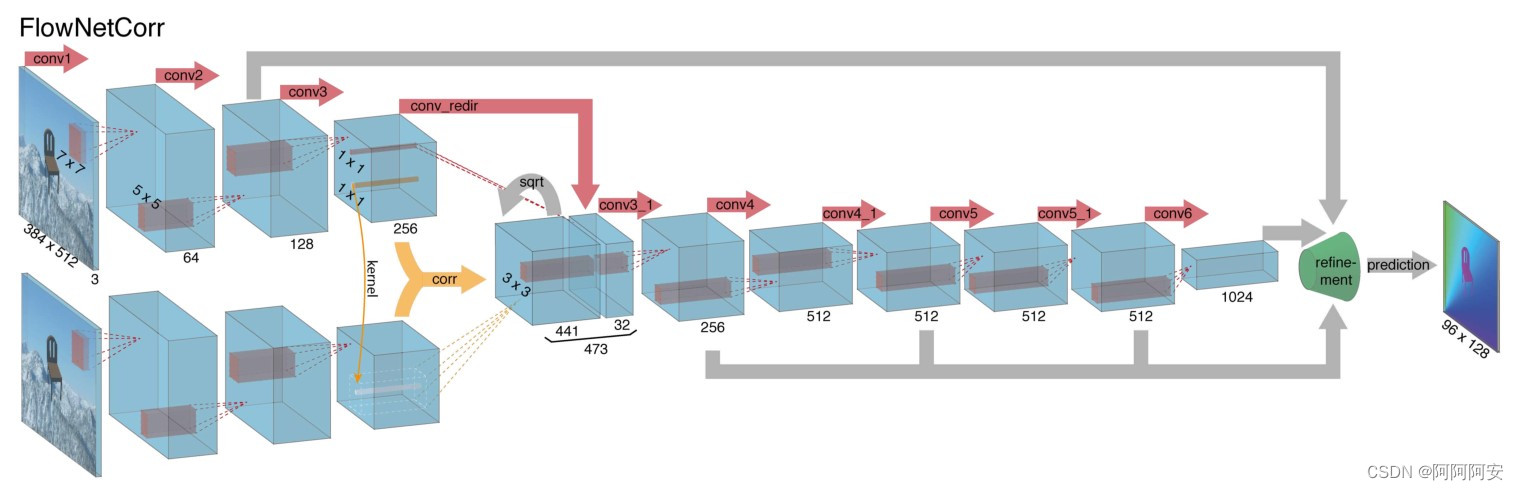
A diferença entre FlowNetCorrelation e FlowNet-S é que FlowNet-C primeiro estabelece dois fluxos de processamento independentes, mas idênticos, para duas imagens de entrada e extrai representações de recursos significativos das duas imagens por meio de uma série de camadas convolucionais . Essas representações significativas de recursos são então combinadas em para o processo de redução de amostragem subsequente.A estrutura da rede é mostrada na figura acima.
No entanto, a combinação de recursos de alto nível de duas imagens não é um simples empilhamento de dimensões, mas uma camada de associação é usada para facilitar o processo de correspondência da rede. Sabemos que o objetivo final da rede é prever o fluxo óptico entre duas imagens, e o fluxo óptico é essencialmente uma relação de correspondência correspondente entre imagens diferentes. Para "ajudar" a rede a acelerar o cálculo dessa relação de correspondência e melhorar o desempenho da rede e melhorar a precisão da estimativa, introduzimos uma "camada de correlação" para combinar recursos . A operação de "correlação" é um tipo de cálculo de correlação (explicaremos em detalhes mais adiante), que é usado para calcular a correlação entre diferentes recursos/blocos de imagem , e o índice de resultado é usado para refletir o grau de correspondência. cálculo de correspondência avançado Pode-se dizer que a combinação de recursos de alto nível fornece uma orientação forte para o aprendizado de relacionamento de correspondência subsequente da rede.
Em resumo, o FlowNet-C primeiro extrai recursos de duas imagens e, em seguida, compara esses vetores de recursos semelhantes ao método de correspondência padrão, imitando artificialmente o processo de correspondência padrão.
1.2 Parte de expansão decodificação/parte de expansão
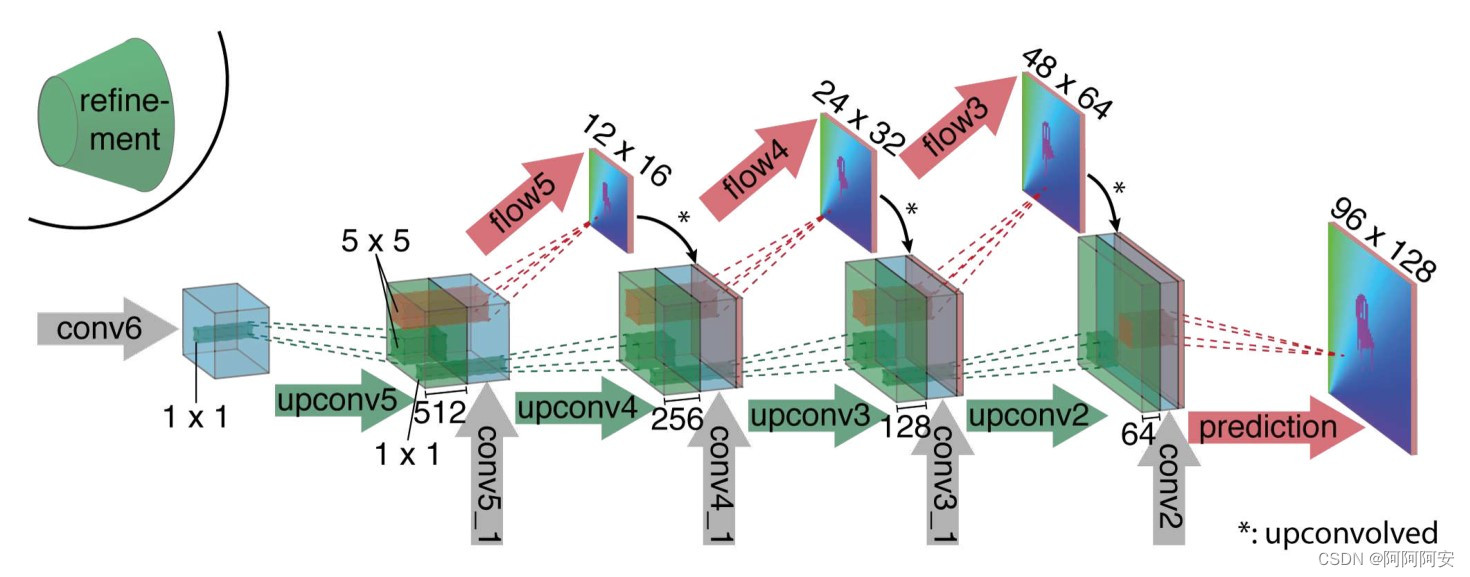
No estágio de decodificação/expansão (como mostrado na figura acima), este estágio inclui principalmente várias operações de upsampling para restaurar o tamanho e as informações da imagem. Para melhor fundir as informações semânticas de diferentes camadas, além da saída da camada anterior , a entrada de cada camada também possui o "fluxo óptico" previsto pela saída da camada anterior e os recursos da camada correspondente da camada codificador . Dessa forma, preservamos as informações de alto nível transmitidas pelos mapas de recursos mais grosseiros e as informações locais fornecidas pelos mapas de recursos da camada inferior.
Cada upsampling dobra a resolução e repete o processo 4 vezes, resultando em um fluxo de saída previsto. Observe que sua resolução ainda é 4 vezes menor que o tamanho original da imagem de entrada , podendo ser restaurada por interpolação bilinear posteriormente . Como o artigo constatou que, em comparação com o upsampling de interpolação bilinear com menor custo computacional da resolução total da imagem, o aprendizado de rede contínuo a partir dessa resolução não melhorará muito os resultados; portanto, a interpolação bilinear direta pode ser obtida e inserir o mapa de previsão de fluxo óptico no mesma resolução.
2. Explicação detalhada da camada de Correlação
A operação de correlação é um cálculo de correspondência de correlação e o resultado do cálculo indica o grau de correspondência de duas manchas de imagem . Comparado com o FlowNetS, o FlowNetC não simplesmente empilha as imagens de entrada, mas precisa fornecer artificialmente à rede informações de orientação sobre como combinar os detalhes da imagem e mesclar e ativar os recursos extraídos de alto nível nas duas imagens, por isso introduz Correlação camada.
O processo de cálculo específico da operação de correlação é essencialmente uma operação de convolução em uma CNN de uma etapa , mas em comparação com a CNN usando um kernel de convolução específico para convolução, aqui um dado (patch image1) é usado para fazer outro dado (patch image2) Operação de convolução , portanto, esta operação não inclui parâmetros de treinamento . Para o bloco de imagem retangular (patch) em image1(w,h,c) que se estende para cima e para baixo com comprimento k (o comprimento e largura do bloco retangular é 2k+1) centrado em x1, é o mesmo que em image2(w,h, c ) entreUm cálculo de correlação pode ser expresso como:
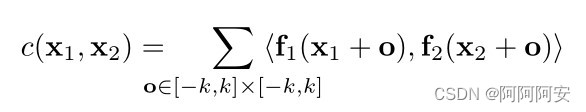
Na verdade, o patch da primeira imagem é usado para convoluir o patch da segunda imagem (correspondente ao produto interno), e um cálculo de correlação gera um número de resultado , indicando o grau de correspondência dos dois patches. Então, para um patch de um determinado pixel x1 na image1, teoricamente ele deve ser combinado com todos os patches de pixel na image2 (um total de w*h patches) , então x1 irá gerar um comprimento correspondente de w*h O vetor correspondente , então para toda a image1 e image2, o resultado da correlação é quadridimensional .
Calcular a correlação uma vez gerará multiplicação. Em teoria, para cada patch de pixel na imagem1, precisamos realizar cálculos de correspondência com todos os patches na image2. A comparação de todos os patches envolverá
tais cálculos de multiplicação. Mas o problema é que tal cálculo é enorme , então precisamos otimizar esse processo.
O artigo assume que o deslocamento do pixel correspondente só existe dentro de um intervalo fixo . Desta forma, ao calcular as informações associadas, o modelo só precisa manter uma janela de pesquisa de tamanho fixo , e coisas além do alcance da janela de pesquisa não serão consideradas. Dado o alcance máximo de busca d, para cada posição x1, podemos limitar x2 para calcular a correlação c(x1, x2) apenas na janela de busca retangular cujo tamanho (comprimento e largura) é D = 2d + 1 . Ao mesmo tempo, o artigo usa passos s1 e s2, quantiza x1 globalmente e quantiza e calcula x2 na vizinhança centrada em x1 . Desta forma, para o patch de um determinado pixel x1 na image1, após a otimização, ele deve ser correspondido com o patch do pixel na image2 dentro do intervalo da janela de pesquisa correspondente (um total de patches D*D) , então x1 será gerado correspondentemente Um vetor correspondente com um comprimento de D*D , para toda a imagem1 e imagem2, o resultado da correlação pode ser expresso como . No artigo original, defina os parâmetros k = 0, d = 20, s1 = 1, s2 = 2 , no código implementado por c++, alguns códigos-fonte importantes são os seguintes:
template<typename scalar_t>
//一次 Correlation Operation 计算过程
__global__ void correlation_forward(scalar_t* __restrict__ output, const int nOutputChannels,
const int outputHeight, const int outputWidth, const scalar_t* __restrict__ rInput1,
const int nInputChannels, const int inputHeight, const int inputWidth,
const scalar_t* __restrict__ rInput2, const int pad_size, const int kernel_size,
const int max_displacement, const int stride1, const int stride2) {
int32_t pInputWidth = inputWidth + 2 * pad_size;
int32_t pInputHeight = inputHeight + 2 * pad_size;
int32_t kernel_rad = (kernel_size - 1) / 2;
int32_t displacement_rad = max_displacement / stride2;
int32_t displacement_size = 2 * displacement_rad + 1;
int32_t n = blockIdx.x;
int32_t y1 = blockIdx.y * stride1 + max_displacement;
int32_t x1 = blockIdx.z * stride1 + max_displacement;
int32_t c = threadIdx.x;
int32_t pdimyxc = pInputHeight * pInputWidth * nInputChannels;
int32_t pdimxc = pInputWidth * nInputChannels;
int32_t pdimc = nInputChannels;
int32_t tdimcyx = nOutputChannels * outputHeight * outputWidth;
int32_t tdimyx = outputHeight * outputWidth;
int32_t tdimx = outputWidth;
int32_t nelems = kernel_size * kernel_size * pdimc;
// element-wise product along channel axis
for (int tj = -displacement_rad; tj <= displacement_rad; ++tj) {
for (int ti = -displacement_rad; ti <= displacement_rad; ++ti) {
//get center x2,y2 in image2
int x2 = x1 + ti * stride2;
int y2 = y1 + tj * stride2;
float acc0 = 0.0f;
for (int j = -kernel_rad; j <= kernel_rad; ++j) {
for (int i = -kernel_rad; i <= kernel_rad; ++i) {
// THREADS_PER_BLOCK
#pragma unroll
for (int ch = c; ch < pdimc; ch += blockDim.x) {
int indx1 = n * pdimyxc + (y1 + j) * pdimxc
+ (x1 + i) * pdimc + ch;
int indx2 = n * pdimyxc + (y2 + j) * pdimxc
+ (x2 + i) * pdimc + ch;
acc0 += static_cast<float>(rInput1[indx1] * rInput2[indx2]);
}
}
}
if (blockDim.x == warpSize) {
__syncwarp();
acc0 = warpReduceSum(acc0);
} else {
__syncthreads();
acc0 = blockReduceSum(acc0);
}
if (threadIdx.x == 0) {
int tc = (tj + displacement_rad) * displacement_size
+ (ti + displacement_rad);
const int tindx = n * tdimcyx + tc * tdimyx + blockIdx.y * tdimx
+ blockIdx.z;
output[tindx] = static_cast<scalar_t>(acc0 / nelems);
}
}
}
}A implementação original do c++ é mais complicada de usar, portanto, também existem muitos pacotes Python de terceiros para cálculos de Correlação, que podemos usar diretamente importando-os, como espacial_correlação_sampler/espacial_correlação_amostra e assim por diante.
(1)space_correlation_sampler/spatial_correlation_sample
entrada (B x C x A x W) -> saída (B x PatchH x PatchW x oH x oW)
- O tamanho do patch
patch_sizerepresenta o comprimento e a largura de todo o patch retangular, não apenas o raio.stride1Agora éstride,stride2é agoradilation_patch, que se comporta como uma convolução dilatada- O equivalente
max_displacementédilation_patch * (patch_size - 1) / 2.- Para obter os parâmetros corretos para flownetc, você precisa definir
kernel_size=1 patch_size=21, stride=1, padding=0, dilation_patch=2
def correlate(input1, input2):
out_corr = spatial_correlation_sample(input1,
input2,
kernel_size=1,
patch_size=21,
stride=1,
padding=0,
dilation_patch=2)
# collate dimensions 1 and 2 in order to be treated as a
# regular 4D tensor
b, ph, pw, h, w = out_corr.size()
out_corr = out_corr.view(b, ph * pw, h, w)/input1.size(1)
return F.leaky_relu_(out_corr, 0.1)3. Mais detalhes de implementação
FlowNet-S e FlowNet-C são aproximadamente os mesmos na estrutura da rede: eles têm 9 camadas convolucionais na parte de contração, 6 das quais têm um passo de 2, e cada convolução tem uma função de ativação não linear ReLU. O tamanho do núcleo de convolução é 7 × 7 na primeira camada de convolução, 5 × 5 nas próximas duas camadas e 3 × 3 da quarta camada em diante. O número de canais do mapa de recursos dobra aproximadamente após cada camada com um passo de 2.
A rede usa erro de ponto final (EPE) como perda de treinamento, que é uma métrica de erro padrão para estimativa de fluxo óptico. Seu significado é a distância euclidiana entre o vetor de fluxo óptico previsto e a verdade fundamental correspondente, e é calculada a média de todos os pixels.
O artigo escolhe Adam como método de otimização do gradiente descendente, onde os parâmetros de Adam são fixados como: β1 = 0,9 e β2 = 0,999. Além disso, o número de mini-lotes de imagens de entrada para a rede é definido em 8 pares de imagens. Para a taxa de aprendizado, a estrutura de rede do FlowNet-C inicia o treinamento com uma baixa taxa de aprendizado de λ = 1e−6, aumenta lentamente após 10k iterações para atingir λ = 1e−4 e, em seguida, a cada 100k vezes após os primeiros 300k Iterate to divide por 2.
O artigo também descobriu que aumentar a imagem de entrada durante o teste pode melhorar o desempenho, portanto, para FlowNetS, o artigo não aumenta, mas para FlowNetC, o artigo escolhe aumentar em 1,25 vezes. Como os conjuntos de dados usados variam muito em termos de tipos de objeto e informações de movimento contidas, etc., uma solução padrão é ajustar continuamente a rede e os parâmetros no conjunto de dados de destino.
4. Implementação do código-chave (use FlowNet-C como exemplo)
(1) Definição da estrutura da rede
# 下采样卷积层结构定义
def conv(batchNorm, in_planes, out_planes, kernel_size=3, stride=1):
if batchNorm:
return nn.Sequential(
nn.Conv2d(in_planes, out_planes, kernel_size=kernel_size, stride=stride, padding=(kernel_size-1)//2, bias=False),
nn.BatchNorm2d(out_planes),
nn.LeakyReLU(0.1,inplace=True)
)
else:
return nn.Sequential(
nn.Conv2d(in_planes, out_planes, kernel_size=kernel_size, stride=stride, padding=(kernel_size-1)//2, bias=True),
nn.LeakyReLU(0.1,inplace=True)
)
# 上采样反卷积层结构定义
def deconv(in_planes, out_planes):
return nn.Sequential(
nn.ConvTranspose2d(in_planes, out_planes, kernel_size=4, stride=2, padding=1, bias=False),
nn.LeakyReLU(0.1,inplace=True)
)
# 光流估计的输出层
def predict_flow(in_planes):
return nn.Conv2d(in_planes,2,kernel_size=3,stride=1,padding=1,bias=False)
# corrlation 相关性计算: 引用第三方 spatial_correlation_sample 包
def correlate(input1, input2):
out_corr = spatial_correlation_sample(input1,
input2,
kernel_size=1,
patch_size=21,
stride=1,
padding=0,
dilation_patch=2)
# collate dimensions 1 and 2 in order to be treated as a
# regular 4D tensor
b, ph, pw, h, w = out_corr.size()
out_corr = out_corr.view(b, ph * pw, h, w)/input1.size(1)
return F.leaky_relu_(out_corr, 0.1)
class FlowNetC(nn.Module):
expansion = 1
def __init__(self,batchNorm=True):
super(FlowNetC,self).__init__()
self.batchNorm = batchNorm
# image 的特征提取流(两输入图象处理流一致)
self.conv1 = conv(self.batchNorm, 3, 64, kernel_size=7, stride=2)
self.conv2 = conv(self.batchNorm, 64, 128, kernel_size=5, stride=2)
self.conv3 = conv(self.batchNorm, 128, 256, kernel_size=5, stride=2)
self.conv_redir = conv(self.batchNorm, 256, 32, kernel_size=1, stride=1)
# 收缩部分的后处理下采样流
self.conv3_1 = conv(self.batchNorm, 473, 256)
self.conv4 = conv(self.batchNorm, 256, 512, stride=2)
self.conv4_1 = conv(self.batchNorm, 512, 512)
self.conv5 = conv(self.batchNorm, 512, 512, stride=2)
self.conv5_1 = conv(self.batchNorm, 512, 512)
self.conv6 = conv(self.batchNorm, 512, 1024, stride=2)
self.conv6_1 = conv(self.batchNorm,1024, 1024)
# 扩张部分的上采样流
self.deconv5 = deconv(1024,512)
self.deconv4 = deconv(1026,256)
self.deconv3 = deconv(770,128)
self.deconv2 = deconv(386,64)
# 扩张部分的光流估计层
self.predict_flow6 = predict_flow(1024)
self.predict_flow5 = predict_flow(1026)
self.predict_flow4 = predict_flow(770)
self.predict_flow3 = predict_flow(386)
self.predict_flow2 = predict_flow(194)
# 光流上采样操作
self.upsampled_flow6_to_5 = nn.ConvTranspose2d(2, 2, 4, 2, 1, bias=False)
self.upsampled_flow5_to_4 = nn.ConvTranspose2d(2, 2, 4, 2, 1, bias=False)
self.upsampled_flow4_to_3 = nn.ConvTranspose2d(2, 2, 4, 2, 1, bias=False)
self.upsampled_flow3_to_2 = nn.ConvTranspose2d(2, 2, 4, 2, 1, bias=False)
for m in self.modules():
if isinstance(m, nn.Conv2d) or isinstance(m, nn.ConvTranspose2d):
kaiming_normal_(m.weight, 0.1)
if m.bias is not None:
constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
constant_(m.weight, 1)
constant_(m.bias, 0)
def forward(self, x):
x1 = x[:,:3]
x2 = x[:,3:]
# 1.提取 image1 的高层特征 (batch,h,w,3) -> (batch,h/8,w/8,256)
out_conv1a = self.conv1(x1)
out_conv2a = self.conv2(out_conv1a)
out_conv3a = self.conv3(out_conv2a)
# 2.提取 image2 的高层特征 (batch,h,w,3) -> (batch,h/8,w/8,256)
out_conv1b = self.conv1(x2)
out_conv2b = self.conv2(out_conv1b)
out_conv3b = self.conv3(out_conv2b)
# 3.进一步提取 image1 与 corr 匹配后的特征融合 (batch,h/8,w/8,256) -> (batch,h/8,w/8,32)
out_conv_redir = self.conv_redir(out_conv3a)
# 4. corr 相关性匹配计算 (batch,h/8,w/8,D*D)
out_correlation = correlate(out_conv3a,out_conv3b)
# 5. 在 channel 方向将进一步提取的特征与corr融合作为后续输入 (batch,h/8,w/8,c)
in_conv3_1 = torch.cat([out_conv_redir, out_correlation], dim=1)
# 6. 下采样操作 (batch,h/8,w/8,c) -> (batch,h/64,w/64,1024)
out_conv3 = self.conv3_1(in_conv3_1)
out_conv4 = self.conv4_1(self.conv4(out_conv3))
out_conv5 = self.conv5_1(self.conv5(out_conv4))
out_conv6 = self.conv6_1(self.conv6(out_conv5))
# 7.refinement 上采样/扩张部分
# (1)upconv1: 输出本层预测光流flow6+本层的上采样输出
# - flow6 (batch,h/64,w/64,2)
# - out_deconv5 (batch,h/32,w/32,,512)
flow6 = self.predict_flow6(out_conv6)
flow6_up = self.upsampled_flow6_to_5(flow6)
out_deconv5 = self.deconv5(out_conv6)
concat5 = torch.cat((out_conv5, out_deconv5, flow6_up), 1) # 拼接下层输入 = 本层输出deconv + 收缩部分上下文输出 + 本层输出预测光流
# (2)upconv2: 输出本层预测光流flow5+本层的上采样输出
# - flow5 (batch,h/32,w/32,2)
# - out_deconv4 (batch,h/16,w/16,256)
flow5 = self.predict_flow5(concat5)
flow5_up = self.upsampled_flow5_to_4(flow5)
out_deconv4 = self.deconv4(concat5)
concat4 = torch.cat((out_conv4, out_deconv4, flow5_up), 1)
# (3)upconv3: 输出本层预测光流flow4+本层的上采样输出
# - flow4 (batch,h/16,w/16,2)
# - out_deconv3 (batch,h/8,w/8,256)
flow4 = self.predict_flow4(concat4)
flow4_up = self.upsampled_flow4_to_3(flow4)
out_deconv3 = self.deconv3(concat4)
concat3 = torch.cat((out_conv3, out_deconv3, flow4_up), 1)
# (4)upconv4: 输出本层预测光流flow3+本层的上采样输出
# - flow3 (batch,h/8,w/8,2)
# - out_deconv2 (batch,h/4,w/4,256)
flow3 = self.predict_flow3(concat3)
flow3_up = self.upsampled_flow3_to_2(flow3)
out_deconv2 = self.deconv2(concat3)
concat2 = torch.cat((out_conv2a, out_deconv2, flow3_up), 1)
# 输出最终预测光流 flow2 (batch,h/4,w/4,2)
flow2 = self.predict_flow2(concat2)
if self.training:
return flow2,flow3,flow4,flow5,flow6
else:
return flow2
def weight_parameters(self):
return [param for name, param in self.named_parameters() if 'weight' in name]
def bias_parameters(self):
return [param for name, param in self.named_parameters() if 'bias' in name](2) Treinamento de rede
# EPE Loss
def EPE(input_flow, target_flow):
return torch.norm(target_flow-input_flow,p=2,dim=1).mean()
def realEPE(output, target):
b, _, h, w = target.size()
upsampled_output = F.interpolate(output, (h,w), mode='bilinear', align_corners=False)
return EPE(upsampled_output, target)
# 多尺度训练损失(flow2~flow6的EPE损失求和权重不同)
def multiscaleEPE(network_output, target_flow, weights=None):
def one_scale(output, target):
b, _, h, w = output.size()
# 为防止 target 和 output 尺寸不一,使用插值方式来统一图像尺寸
target_scaled = F.interpolate(target, (h, w), mode='area')
return EPE(output, target_scaled)
loss = 0
for output, weight in zip(network_output, weights):
loss += weight * one_scale(output, target_flow)
return loss
# 网络训练主体框架
def run(train_loader,val_loader,model):
best_EPE = -1
# 定义 Adam 优化器
param_groups = [{'params': model.bias_parameters(), 'weight_decay': args.bias_decay},
{'params': model.weight_parameters(), 'weight_decay': args.weight_decay}]
optimizer = torch.optim.Adam(params=param_groups,lr=0.0001,betas=(0.9, 0.999))
# optimizer = torch.optim.Adam(model.parameters(), lr=1e-4, betas=(0.9, 0.999), amsgrad=False)
# 定义学习率调整策略 lr_scheduler.MultiStepLR
# milestones : epochs at which learning rate is divided by 2
scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[100,150,200], gamma=0.5)
for epoch in range(args.start_epoch, args.epochs):
# 调整学习率 lr
scheduler.step()
# train for one epoch
train_loss, train_EPE = train(train_loader, model, optimizer, epoch)
print(train_loss,train_EPE)
# evaluate on validation set
with torch.no_grad():
EPE = validate(val_loader, model, epoch)
if best_EPE < 0:
best_EPE = EPE
best_EPE = min(EPE, best_EPE)
# 单轮训练
def train(train_loader, model, optimizer, epoch):
global n_iter, args
# training weight for each scale, from highest resolution (flow2) to lowest (flow6)
multiscale_weights = [0.005, 0.01, 0.02, 0.08, 0.32]
# value by which flow will be divided. Original value is 20 but 1 with batchNorm gives good results
div_flow = 20.0
losses = 0.0
flow2_EPEs = 0.0
epoch_size = len(train_loader) if args.epoch_size == 0 else min(len(train_loader), args.epoch_size)
# switch to train mode
model.train()
for i, (input, target) in enumerate(train_loader):
target = target.to(device)
input = torch.cat(input,1).to(device)
# compute output
output = model(input)
# compute loss
loss = multiscaleEPE(output, target, weights=multiscale_weights) # 多尺度训练损失
flow2_EPE = div_flow * realEPE(output[0], target) # 最终输出光流flow2的单独损失
# record loss and EPE
losses += loss.item()
flow2_EPEs += flow2_EPE.item()
# compute gradient and do optimization step
optimizer.zero_grad()
loss.backward()
optimizer.step()
n_iter += 1
if i >= epoch_size:
break
return losses, flow2_EPEs2. FlowNet 2.0 e sua continuação
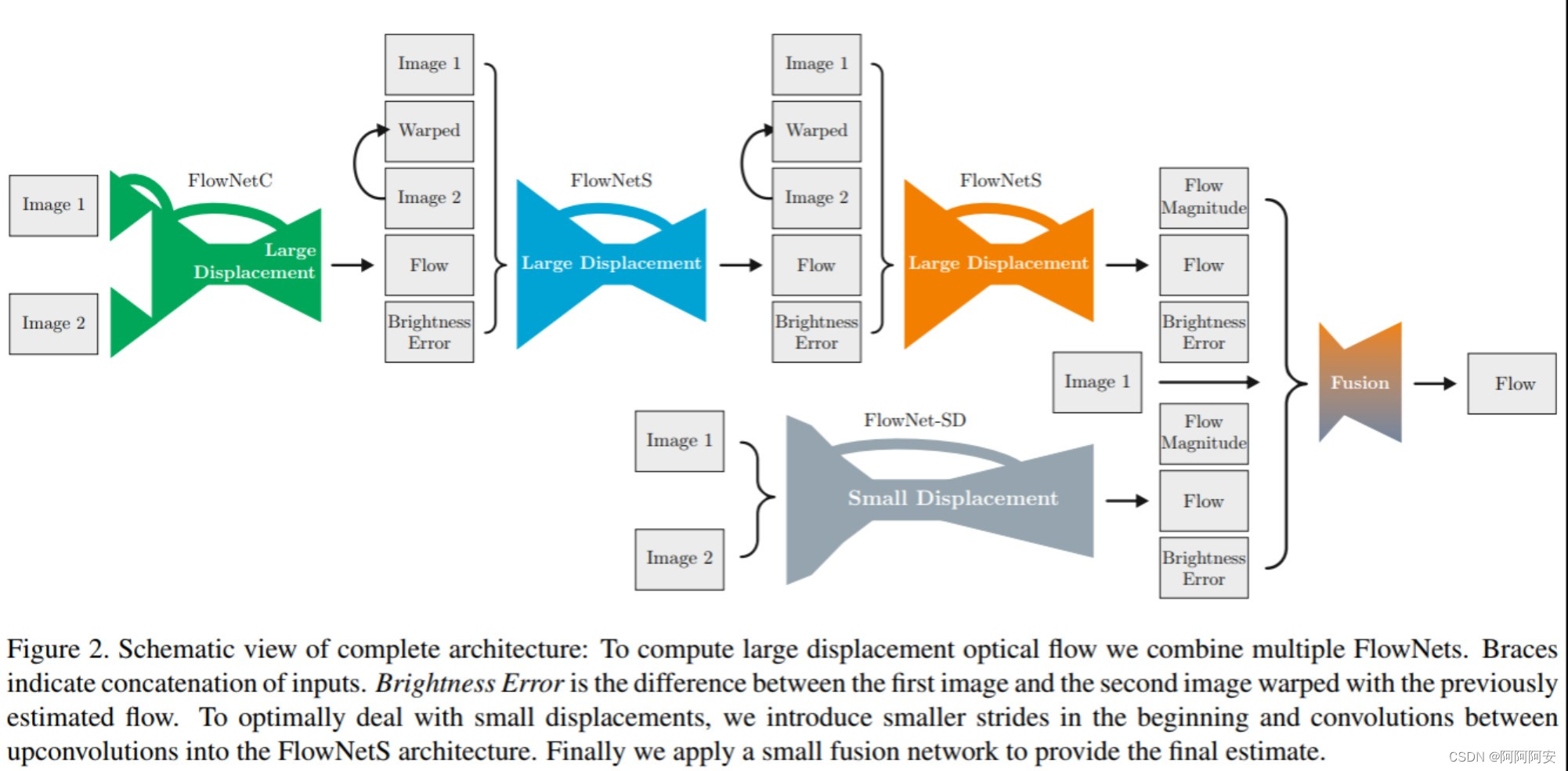
Comparado com o FlowNet, o FlowNet 2.0 é caracterizado por empilhar várias sub-redes FlowNetC/FlowNetS para construir uma estrutura de rede maior, refinando gradualmente o fluxo de saída e obtendo melhores resultados. A estrutura da rede é a seguinte. Mais tarde, com o desenvolvimento do aprendizado profundo de fluxo óptico, um grande número de novas redes e novas ideias de otimização surgiram, como PWC-Net, etc., que explicaremos e analisaremos com mais detalhes em artigos subsequentes.