Resumo dos três métodos de upsampling
Upsampling é essencial em redes como GANs, segmentação de imagem, etc. Aqui está um registro dos três métodos de upsampling que aprendi: deconvolução (convolução transposta), interpolação bilinear + convolução e anti-pooling.
Deconvolução (convolução transposta)
A convolução apenas reduz ou não altera o tamanho da entrada, e a convolução transposta é usada para aumentar o tamanho da entrada. Usado para refinar mapas de recursos grosseiros, etc., existem aplicações em FCN. Uma foto aqui pode facilmente mostrar o que ele fez. É como fazer o inverso da convolução. Convoluções transpostas podem ser aprendidas.
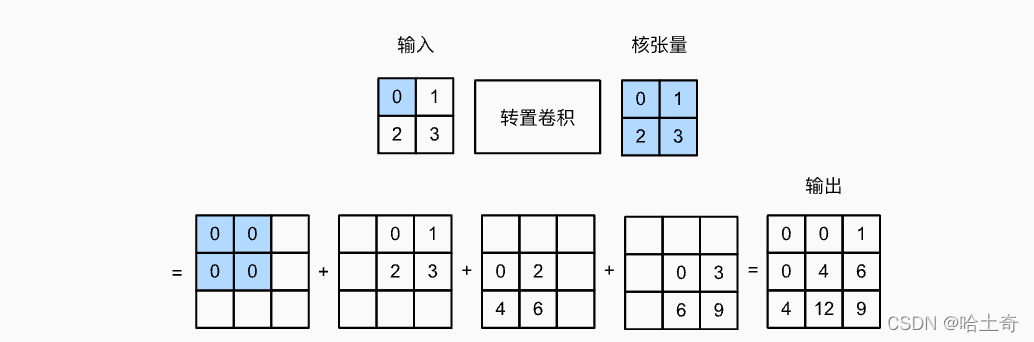
O tensor kernel é multiplicado elemento a elemento pelo tensor de entrada e colocado no local correspondente. Ou seja, o primeiro elemento é 0, ou seja, 0 é multiplicado por todo o tensor nuclear e colocado na posição correspondente. O segundo elemento é 1, que é multiplicado pelo tensor kernel e colocado no slide correspondente à próxima posição. e assim por diante. Quatro gráficos são obtidos e a saída final é obtida adicionando os quatro gráficos. O passo de exemplo aqui é 1, então o passo deslizante é 1.
A fórmula resumida é:
Y [ i : i + h , j : j + w ] + = X [ i , j ] ∗ KY[i:i+h, j:j + w] += X[i,j ] * KS [ eu:eu+h ,j:j+w ] +=X [ eu ,j ]∗K
onde o tamanho de Y é o tamanho da convolução e a fórmula de cálculo é invertida:
Convolução: out = (Input - kernel + 2*padding) / stride + 1
Deconvolução: out = (Input - 1) * stride + kernel - 2*padding
Stride é o tamanho do passo deslizante do kernel. Este é um bom entendimento do
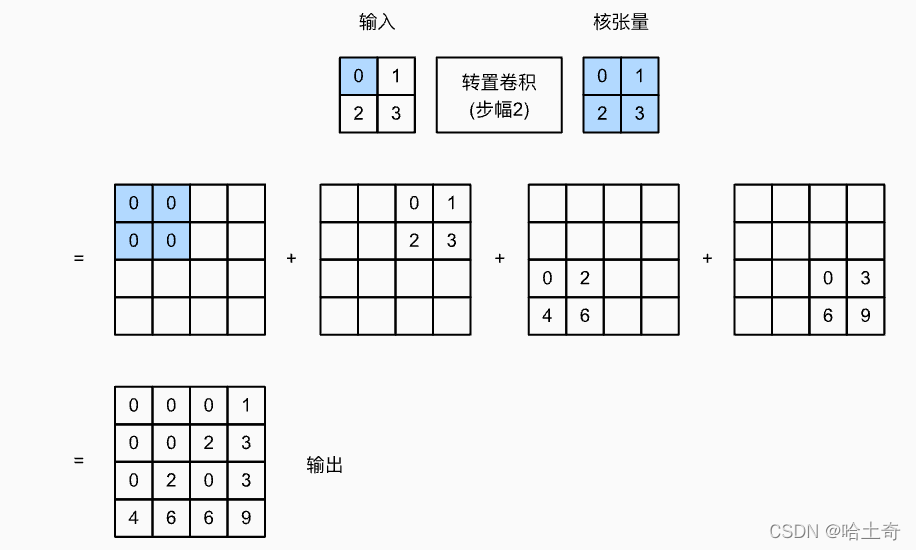
preenchimento: o preenchimento aqui é diferente da convolução, e a convolução é adicionar um círculo de 0 fora. A convolução transposta é subtrair um círculo da parte de saída como a saída.
A razão pela qual é chamada de transposta:
Para convolução Y = X ⊙ W, expanda Y e X em um vetor, Y', X' respectivamente. W é equivalente a um V tal que Y' = V * X'
A convolução transposta é equivalente a X' = VT * Y', e muitos blogs na Internet escreveram em detalhes. Convolução transposta fácil de entender
Implementação manuscrita
import torch
def trans_conv(X, K):
h, w = K.shape
Y = torch.zeros((X.shape[0] + h - 1, X.shape[1] + w - 1))
for i in range(X.shape[0]):
for j in range(X.shape[1]):
Y[i:i+h, j:j+w] += X[i, j] * K
return Y
# 手写计算
X = torch.tensor([[0.0, 1.0], [2.0, 3.0]])
K = torch.tensor([[0.0, 1.0], [2.0, 3.0]])
print(trans_conv(X,K))
# torch的ConvTranspose2d
X, K = X.reshape(1, 1, 2, 2), K.reshape(1, 1, 2, 2)
tconv = torch.nn.ConvTranspose2d(1, 1, kernel_size=2, bias=False)
tconv.weight.data = K
print(tconv(X))
fora:
tensor([[ 0., 0., 1.],
[ 0., 4., 6.],
[ 4., 12., 9.]])
tensor([[[[ 0., 0., 1 .],
[ 0., 4., 6.],
[ 4., 12., 9.]]]], grad_fn=< SlowConvTranspose2DBackward>)
Ambas as saídas são iguais.
mais configuração de passo
...
def trans_conv(X, K, stride=1):
h, w = K.shape
Y = torch.zeros(((X.shape[0] - 1) * stride + h, (X.shape[1] - 1) * stride + w))
for i in range(X.shape[0]):
for j in range(X.shape[1]):
Y[i * stride:i * stride +h, j * stride:j * stride +w] += X[i, j] * K
return Y
...
Defina o passo no ConvTransposed2d correspondente como 2 e o passo em trans_conv() como 2
fora:
tensor([[0., 0., 0., 1.],
[0., 0., 2., 3.],
[0., 2., 0., 3.],
[4., 6 ., 6., 9.]])
tensor([[[[0., 0., 0., 1.],
[0., 0., 2., 3.],
[0., 2., 0., 3.],
[4., 6., 6., 9.]]]], grad_fn=<SlowConvTranspose2DBackward>)
Padding é definido como 1, stride é definido como 1, pode-se concluir que
fora:
tensor([[[[4.]]]], grad_fn=<SlowConvTranspose2DBackward>)
Interpolação bilinear + convolução
Embora a convolução transposta anterior possa expandir o tamanho do mapa e refinar o mapa de recursos grosseiro. Mas há um problema de efeito xadrez.
Efeito checkerboard: causado pela sobreposição irregular da convolução transposta, fazendo com que a imagem tenha blocos de pixels como um tabuleiro de damas

A solução é usar a interpolação bilinear para expandir a imagem primeiro e depois usar a convolução. O seguinte introduz a interpolação linear simples primeiro e depois a interpolação bilinear.
interpolação linear simples
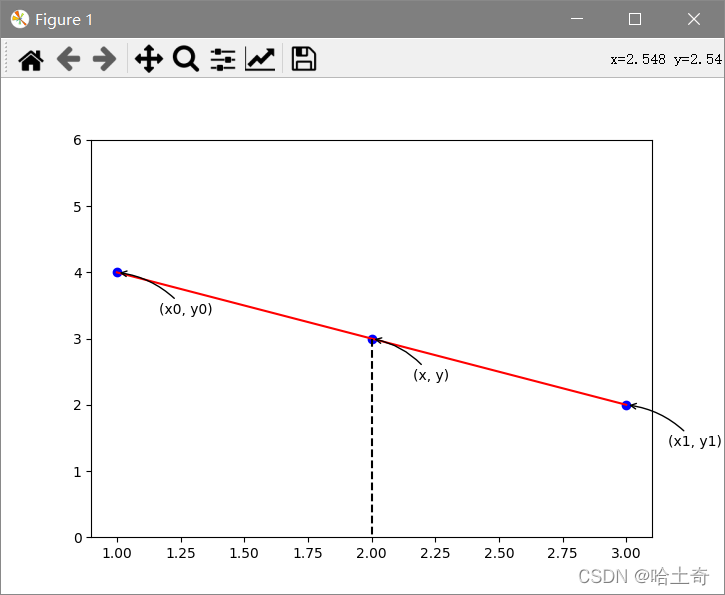 Muito simples, pode-se dizer que os alunos do ensino médio podem lidar com isso. Dados dois pontos, calcule a equação e, em seguida, encontre qualquer ponto y no meio. A fórmula é a seguinte
Muito simples, pode-se dizer que os alunos do ensino médio podem lidar com isso. Dados dois pontos, calcule a equação e, em seguida, encontre qualquer ponto y no meio. A fórmula é a seguinte
y 1 − y 0 x 1 − x 0 = y − y 0 x − x 0 \frac {y_1 - y_0}{x_1 - x_0} = \frac {y - y_0}{x - x_0}x1−x0y1−y0=x−x0y−y0
Em seguida, insira o valor y correspondente.
interpolação bilinear
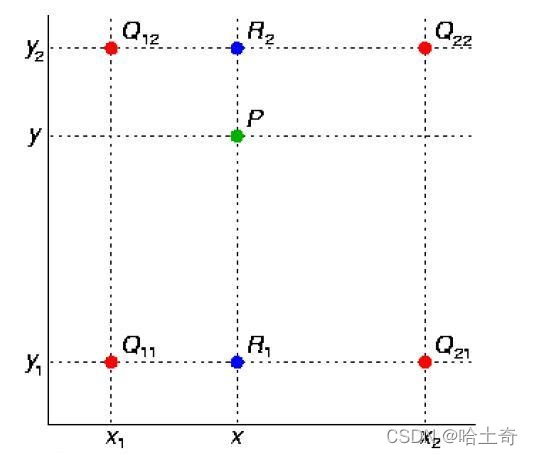
Conforme mostrado na figura, o valor do ponto médio P(x, y) é obtido através dos quatro pontos conhecidos Q11, Q12, Q21 e Q22. Agora execute a interpolação linear na direção x para obter R1 e R2 e, em seguida, execute a interpolação linear na direção y para obter f(x, y) para obter o ponto P.
A fórmula é a seguinte
Encontre R1 na direção x e R2
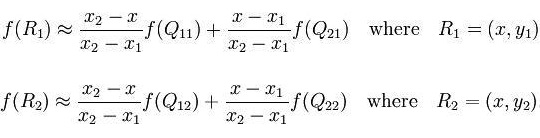 na direção y depois que P
na direção y depois que P
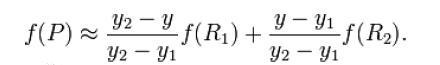
for ampliado e, em seguida, execute a convolução para completar o upsampling
o código
import torch.nn as nn
...
upsample_bil = nn.UpsamplingBilinear2d(scale_factor=2)
# or
net = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
# or
F.interpolate(input, size, scale_factor, mode, align_corners)
...
# 都有size参数,可以指定放大的大小。scale_factor指定放大倍数。mode指定放大模式
Anti-pooling
Os primeiros artigos a ver anti-pooling foram em DeConvolution Network e SegNet, que são bastante semelhantes. Aqui falamos apenas de unpooling (Unpooling)
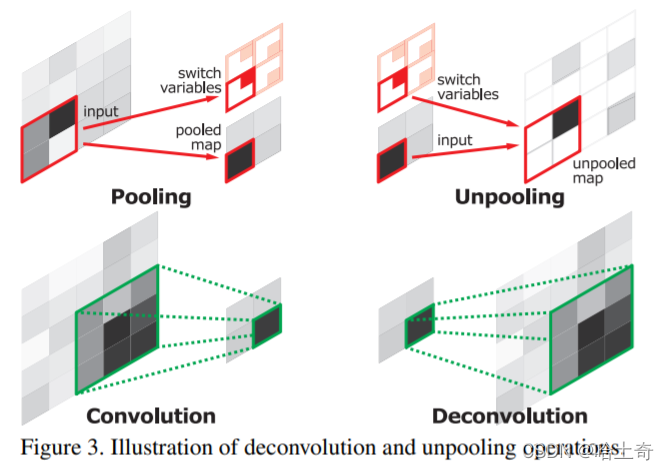 Simplificando, no processo de downsampling, quando maxpool registra um índice pooled, significa que o valor registrado está naquela posição. Durante o unpooling, o valor de entrada é colocado de volta em sua posição original de acordo com o índice e uma matriz esparsa é obtida. Em seguida, aprenda a refinar o mapa de recursos grosseiro por meio da camada convolucional subsequente (DeconvNet usa convolução transposta, SegNet usa convolução). Nesta operação anti-pooling, o índice registra mais informações de borda, o que pode aprimorar a capacidade de descrever objetos e fortalecer as informações de posição de limite precisas reutilizando essas informações de borda. Ajuda a produzir divisões mais suaves ao dividir.
Simplificando, no processo de downsampling, quando maxpool registra um índice pooled, significa que o valor registrado está naquela posição. Durante o unpooling, o valor de entrada é colocado de volta em sua posição original de acordo com o índice e uma matriz esparsa é obtida. Em seguida, aprenda a refinar o mapa de recursos grosseiro por meio da camada convolucional subsequente (DeconvNet usa convolução transposta, SegNet usa convolução). Nesta operação anti-pooling, o índice registra mais informações de borda, o que pode aprimorar a capacidade de descrever objetos e fortalecer as informações de posição de limite precisas reutilizando essas informações de borda. Ajuda a produzir divisões mais suaves ao dividir.
usar código
test = torch.rand((2, 3, 128, 128))
print("Original Size -> ", test.size())
# maxPool池化
maxpool = nn.MaxPool2d(2, 2)
# 设定要返回索引
maxpool.return_indices = True
# 记录池化结果,索引结果
mp, indices = maxpool(test)
print("MaxPool -> ", mp.size())
# 设置MaxUnpool反池化
unpooling = nn.MaxUnpool2d((2, 2), stride=2)
# 传入参数和索引
upsamle = unpooling(mp, indices)
print("MaxUnpool -> ", upsamle.size())
fora:
Tamanho original -> tocha.Size([2, 3, 128, 128])
MaxPool -> tocha.Size([2, 3, 64, 64])
MaxUnpool -> tocha.Size([2, 3, 128, 128 ])
Referências
Convolução transposta [aprendizado profundo prático v2]