Fio
YARN é um software de gerenciamento e agendamento de recursos projetado para atender às necessidades e deficiências de arquiteturas anteriores .
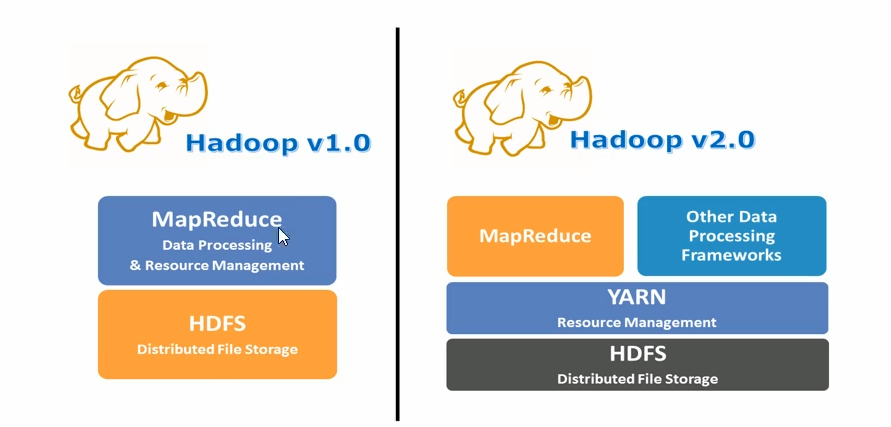
Apache Hadoop YARN (Yet Another Resource Negotiator, outro coordenador de recursos) é um novo gerenciador de recursos Hadoop. É um sistema geral de gerenciamento de recursos e plataforma de agendamento que pode fornecer gerenciamento de recursos unificado e agendamento para aplicativos de camada superior. É a introdução do cluster trouxe grandes benefícios em termos de utilização, gerenciamento unificado de recursos e compartilhamento de dados.
Sistema de gerenciamento de recursos: Os recursos de hardware do cluster estão relacionados à operação do programa, como memória, CPU, etc.
Plataforma de agendamento: como vários programas se aplicam a recursos de computação ao mesmo tempo, como alocar e regras de agendamento (algoritmos).
Geral: não só suporta programas MapReduce, mas também suporta teoricamente vários programas de computação. A YARN não se importa com o que você faz, só se importa se você precisa de recursos, dá a você em alguns casos e me devolve após o uso.
O Hadoop YARN pode ser entendido como uma plataforma de sistema operacional distribuído, enquanto programas de computação como o MapReduce são equivalentes a aplicativos executados no sistema operacional.YARN fornece a esses programas os recursos necessários para a computação (memória, CPU, etc.).
Sistema de arquitetura de fios
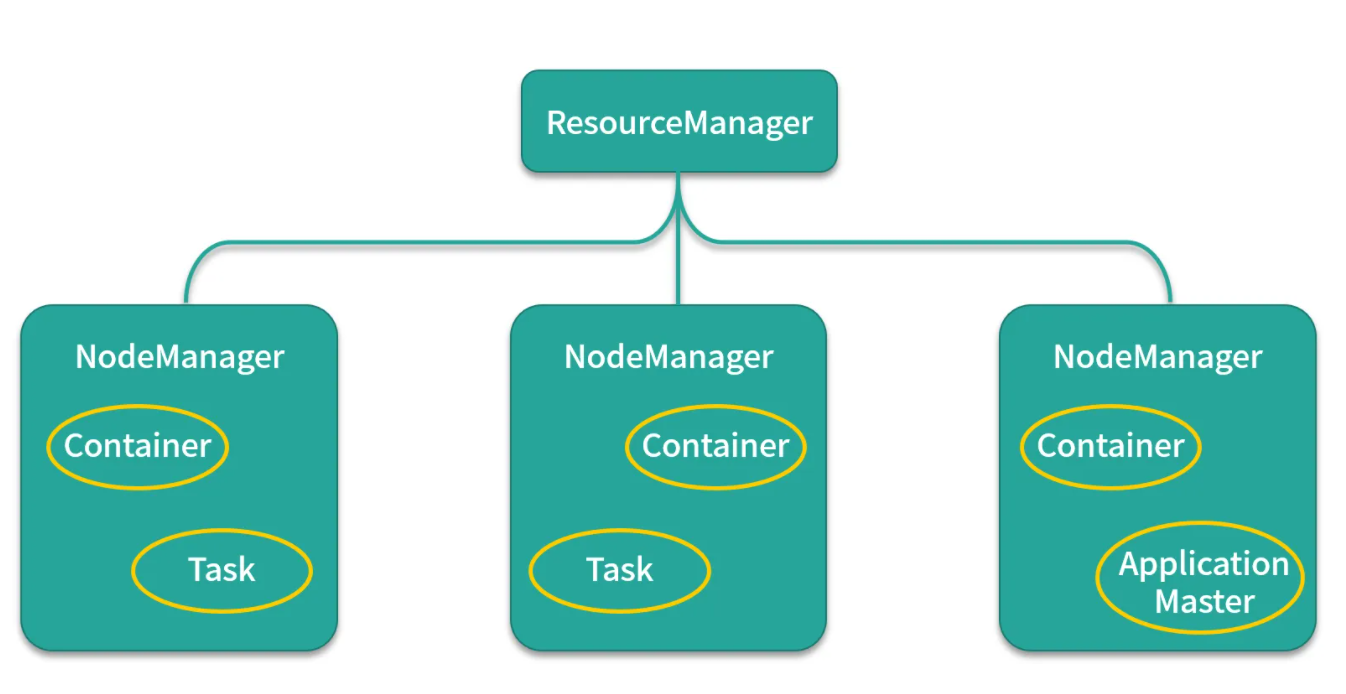
arquitetura mestre-escravo
Ele também adota a arquitetura master (Resource Manager)-slave (Node Manager) Existe apenas um Resource Manager em todo o cluster, que é um nó confiável.
1. Cada nó pode ser responsável pelo gerenciamento de recursos e agendamento de tarefas no nó. O gerente do nó relatará regularmente o uso de recursos e o status de execução da tarefa no nó ao gerente de recursos. 2. O gerente de recursos se reportará ao nó por meio de o mecanismo de resposta de pulsação
. O Gerente emite comandos ou distribui novas tarefas.
3. Após o Yarn atribuir um recurso ao aplicativo, o aplicativo iniciará um Application Master.
4. O Application Master é responsável por solicitar recursos do Resource Manager para o aplicativo.Comunique-se com o nó aplicado e execute tarefas internas.
Gerente de Recursos
RM é um gerenciador de recursos global responsável pelo gerenciamento de recursos e alocação de todo o sistema. Consiste principalmente em dois componentes: Scheduler (Scheduler) e Application Manager (Applications Manager, ASM).
O agendador de recursos do Schedule é um componente conectável. Os usuários podem projetar novos agendadores de recursos de acordo com suas necessidades. O YARN fornece vários agendadores de recursos que podem ser usados diretamente. O agendador de recursos aloca recursos no sistema para executar programas e não é responsável por monitorar ou rastrear o status de execução de aplicativos e não é responsável por reiniciar tarefas com falha .
Gerenciador de Aplicativos O gerenciador de aplicativos é responsável por gerenciar todos os aplicativos em todo o sistema, incluindo envio de aplicativos, negociação de recursos com o agendador para iniciar o ApplicationMaster, monitoramento do status de execução do ApplicationMaster e reinício em caso de falha, etc.
Gerenciador de nós
NM é o gerenciador de recursos e tarefas em cada nó. Por um lado, ele relata regularmente o uso de recursos neste nó e o status de execução de cada contêiner para RM; por outro lado, ele recebe e processa a inicialização do contêiner de AM /stop e outras várias solicitações.
ApplicationMaster
Cada aplicativo enviado pelo usuário contém um AM, as principais funções incluem:
1. Negociar com o escalonador de RM para obtenção de recursos (indicado por Container);
2. Atribua ainda mais as tarefas obtidas a tarefas internas
3. Comunique-se com o NM para iniciar/parar tarefas;
4. Monitore o status de execução de todas as tarefas e solicite novamente recursos para a tarefa para reiniciá-la quando a execução da tarefa falhar.
Nota: RM é responsável apenas por monitorar o AM, e inicia-o quando o AM falha.. O RM não é responsável pela tolerância a falhas das tarefas internas do AM, que é feito pelo AM.
Recipiente
Container é a abstração de recursos no YARN. Ele encapsula recursos multidimensionais em um determinado nó, como memória, CPU, disco, rede etc. . O YARN alocará um Container para cada tarefa, sendo que a tarefa poderá utilizar apenas os recursos descritos no Container. O container container do yarn é algo virtualizado pelo yarn, que pertence a virtualização. É composto de memória+vcore e é usado especialmente para executar tarefas
Instalar
O arquivo yarn-site.xml no diretório etc/hadoop/
cd /opt/apps/hadoop-3.1.1/etc/hadoop/
vi yarn-site.xml
<!-- resource,manager主节点所在机器 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>linux01</value>
</property>
<!-- 为mr程序提供shuffle服务 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 一台NodeManager的总可用内存资源 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
<!-- 一台NodeManager的总可用(逻辑)cpu核数 -->
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>4</value>
</property>
<!-- 是否检查容器的虚拟内存使用超标情况
vmem为true 指的是默认检查虚拟内存,容器使用的虚拟内存不能超过我们设置的虚拟内存大小
-->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 容器的虚拟内存使用上限:与物理内存的比率 -->
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
将 yarn-site.xml 同步给其他Linux
scp yarn-site.xml linux02:$PWD
scp yarn-site.xml linux03:$PWD
Configurar início e parada de uma tecla
cd /opt/apps/hadoop-3.1.1/sbin
vi start-yarn.sh
vi stop-yarn.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
start-yarn.sh 一键启动
启动后可以访问 http://linux01:8088 查看页面
解决linux连接不上 可能网卡出现问题
systemctl stop NetworkManager
systemctl diable NetworkManager
systemctl restart network
Programa de RM submetido ao Yarn
Use a ideia para enviar o programa
Adicione o arquivo mapred-site.xml de configuração ao diretório de recursos
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/opt/apps/hadoop-3.1.1</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/opt/apps/hadoop-3.1.1</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/opt/apps/hadoop-3.1.1</value>
</property>
</configuration>
day05.com.doit.demo06;
Modifique o código maven para criar o pacote jar para enviar a tarefa como pacote
public class Test02 {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
System.setProperty("HADOOP_USER_NAME", "root");
Configuration conf = new Configuration();
//操作HDFS数据
conf.set("fs.defaultFS", "hdfs://linux01:8020");
//设置运行模式
conf.set("mapreduce.framework.name", "yarn");
//设置ResourceManager位置
conf.set("yarn.resourcemanager.hostname", "linux01");
// 设置MapReduce程序运行在windows上的跨平台参数
conf.set("mapreduce.app-submission.cross-platform","true");
Job job = Job.getInstance(conf, "WordCount");
//设置jar包路径
job.setJar("D:\\IdeaProjects\\hadoop\\target\\test_yarn.jar");
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReduce.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//设置路径为HDFS路径
FileInputFormat.setInputPaths(job,new Path("/wc/input/word.txt"));
FileOutputFormat.setOutputPath(job,new Path("/wc/out4"));
job.waitForCompletion(true);
}
}
Envie o pacote jar diretamente no linux
public class Test02 {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration conf = new Configuration();
//设置运行模式
conf.set("mapreduce.framework.name", "yarn");
//设置ResourceManager位置
conf.set("yarn.resourcemanager.hostname", "linux01");
// 设置MapReduce程序运行在windows上的跨平台参数
conf.set("mapreduce.app-submission.cross-platform","true");
Job job = Job.getInstance(conf, "WordCount");
//设置jar包路径
//job.setJar("D:\\IdeaProjects\\hadoop\\target\\test_yarn.jar");
job.setJarByClass(Test02.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReduce.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//设置路径为HDFS路径
FileInputFormat.setInputPaths(job,new Path("/wc/input/word.txt"));
FileOutputFormat.setOutputPath(job,new Path("/wc/out5"));
job.waitForCompletion(true);
}
}
打成jar包后
linux上使用
需要查看 mapred-site.xml 如果没有配置 需要配置一下
hadoop jar jar包名 运行的类
hadoop jar test_yarn.jar day03.com.doit.demo02.Test02
Juntar-se ao Mapa
A junção do lado do mapa refere-se à mesclagem de dados antes de atingir a função de processamento do mapa. A eficiência é muito maior do que a junção do lado reduzido, porque a junção do lado reduzido é embaralhar todos os dados, o que consome muitos recursos.
order.txt
order011 u001
order012 u001
order033 u005
order034 u002
order055 u003
order066 u004
order077 u010
user.txt
u001,hangge,18,male,angelababy
u002,huihui,58,female,ruhua
u003,guanyu,16,male,chunge
u004,laoduan,38,male,angelababy
u005,nana,24,femal,huangbo
u006,xingge,18,male,laoduan
最终结果
u001,hangge,18,male,angelababy,order012
u001,hangge,18,male,angelababy,order011
u002,huihui,58,female,ruhua,order034
u003,guanyu,16,male,chunge,order055
u004,laoduan,38,male,angelababy,order066
u005,nana,24,femal,huangbo,order033
null,order077
Um usuário pode gerar vários pedidos. Pode haver poucos usuários em user.txt, mas os dados do pedido são muito, muito grandes. Neste momento, podemos considerar o uso da junção do lado do mapa. Quando um arquivo pequeno ou grande, você pode usar o Map side Join, para simplificar, é obter o resultado diretamente pelo Map sem usar a redução.
Princípio: Carregue o arquivo pequeno no cache distribuído para garantir que cada mapa possa acessar os dados completos do arquivo pequeno e, em seguida, conecte-se com os dados após o arquivo grande ser segmentado para obter o resultado final.

package hadoop06.com.doit.demo;
import hadoop03.com.doit.demo02.WordCountMapper;
import hadoop03.com.doit.demo02.WordCountReducer;
import hadoop05.com.doit.demo05.Test;
import org.apache.commons.lang.ObjectUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import java.util.HashMap;
import java.util.Map;
public class MapJoinDemo {
public static class JoinMapper extends Mapper<LongWritable,Text,Text, NullWritable>{
//定义集合用来存储user.txt的数据 键是uid 值是这一行记录
private Map<String,String> userMap = new HashMap<>();
private Text k2 = new Text();
@Override
protected void setup(Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException {
//读取本地user.txt文件 由于user.txt添加到了分布式缓存中,会将这个文件 缓存到执行maptask的计算机上
//由于这个文件和class文件放在一起 可以直接读取
BufferedReader br = new BufferedReader(new FileReader("user.txt"));
String line = null;
while((line = br.readLine())!=null){
//System.out.println(line);
String uid = line.split(",")[0];
//将uid 和 user的一行记录放入到map中
userMap.put(uid,line);
}
}
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException {
//得到order的一条记录
String line = value.toString();
//获取order的 uid
String uid = line.split("\\s+")[1];// u001
//获取map中 当前uid的 用户信息
String userInfo = userMap.get(uid);
//拼接字符串写出
k2.set(userInfo+","+line.split("\\s+")[0]);
context.write(k2, NullWritable.get());
}
}
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException, URISyntaxException {
System.setProperty("HADOOP_USER_NAME", "root");
Configuration con = new Configuration();
//配置到yarn上执行
con.set("mapreduce.framework.name", "yarn");
//配置操作HDFS数据
con.set("fs.defaultFS", "hdfs://linux01:8020");
//配置resourceManager位置
con.set("yarn.resourcemanager.hostname", "linux01");
//配置mr程序运行在windows上的跨平台参数
con.set("mapreduce.app-submission.cross-platform","true");
Job job = Job.getInstance(con,"wordcount");
//分布式缓存user.txt文件
job.addCacheFile(new URI("hdfs://linux01:8020/user.txt"));
//设置jar包的路径
job.setJar("D:\\IdeaProjects\\test_hadoop\\target\\test_hadoop-1.0-SNAPSHOT.jar");
//设置Mapper
job.setMapperClass(JoinMapper.class);
//设置最后结果的输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
//设置读取HDFS上的文件 的路径
//设置读取文件的位置 可以是文件 也可以是文件夹
FileInputFormat.setInputPaths(job,new Path("/join/order.txt"));
//设置输出文件的位置 指定一个文件夹 文件夹不已存在 会报错
FileOutputFormat.setOutputPath(job,new Path("/join/out"));
//提交任务 并等待任务结束
job.waitForCompletion(true);
}
}
Processo de envio do programa MR para o Yarn
