Descrição do contexto : A fim de prevenir potenciais riscos de segurança causados pelo comportamento do pessoal de serviço que dorme no posto, foi identificada e tratada a situação do pessoal de serviço que dorme no posto.
Objetivo do algoritmo : identificar o pessoal de plantão que está deitado de bruços ou deitado e dormindo e gerar um alarme.
Análise do conjunto de dados
-
De acordo com a postura humana, as seis categorias a seguir são definidas:
(1) suporte de pessoa em pé
(2) As pessoas sentadas sentam-se
(3) agachamento agachado
(4) Uma pessoa que dorme de bruços (sobre uma mesa ou mesa) prostrate_sleep
(5) Pessoas que sentam e dormem sit_sleep
(6) Uma pessoa que dorme deitada (de lado) lie_sleep
-
Rótulo de ponto de esqueleto humano
Existem 17 pontos-chave no total, conforme mostrado na figura abaixo:

-
Dimensões e estatísticas de categoria do conjunto de dados

Padrão de avaliação
 Esquema de algoritmo
Esquema de algoritmo
Seleção de algoritmo
A partir da análise da competição, a tarefa pertence à detecção de alvo + estimativa de pose. Não há uma correlação particularmente forte entre essas duas tarefas. Dois modelos podem ser usados para analisar imagens ao mesmo tempo, mas a desvantagem é que consome muitos recursos. Claro, também pode ser implementado por um algoritmo de modelo único, como YOLOv8-pose, que pode reduzir a ocupação de recursos do algoritmo. Levando em consideração os recursos e o desempenho, o autor escolheu o YOLOv8-pose como a linha de base do esquema. whaosoft aiot http://143ai.com
O YOLOv8 foi aberto pela ultralytics em 10 de janeiro de 2023. Atualmente, ele oferece suporte à classificação de imagens, detecção de objetos, segmentação de instâncias e tarefas de estimativa de pose. É um modelo SOTA. 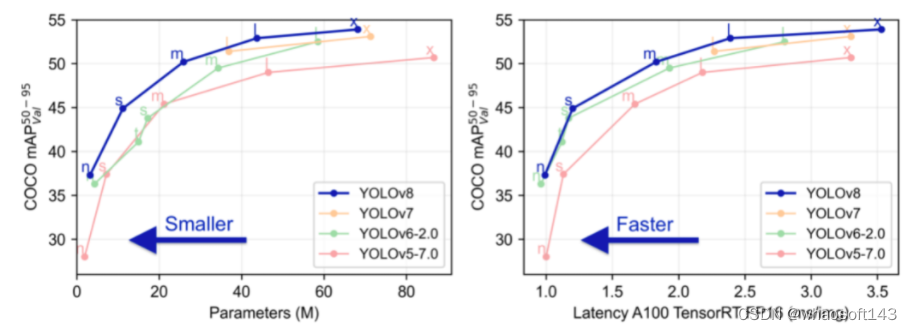 estratégia de treinamento
estratégia de treinamento
-
Usando o modelo YOLOv8m-pose
-
Ajustar categoria de treinamento
-
Remova a categoria agachar e mescle-a na categoria sentar
-
-
Estratégias de Treinamento Flexível
-
O primeiro estágio, semente de número aleatório 1, usando o modelo de pré-treinamento YOLOv8m-pose, conjunto de treinamento: conjunto de validação = 4: 1, usando forte aprimoramento de dados
-
O segundo estágio, semente de número aleatório 2, usa o modelo do primeiro estágio como modelo de pré-treinamento, conjunto de treinamento: conjunto de verificação = 4:1, usa aprimoramento de dados fraco, baixa taxa de aprendizado
-
O terceiro estágio, semente de número aleatório 3, usando o modelo do segundo estágio como modelo de pré-treinamento, conjunto de treinamento: conjunto de verificação = 1: 3, aprimoramento de dados desativado, baixa taxa de aprendizado
-
plano de preparação
A implantação do algoritmo utiliza o uYOLODeploy, que é desenvolvido pela equipe do autor e possui as seguintes características: 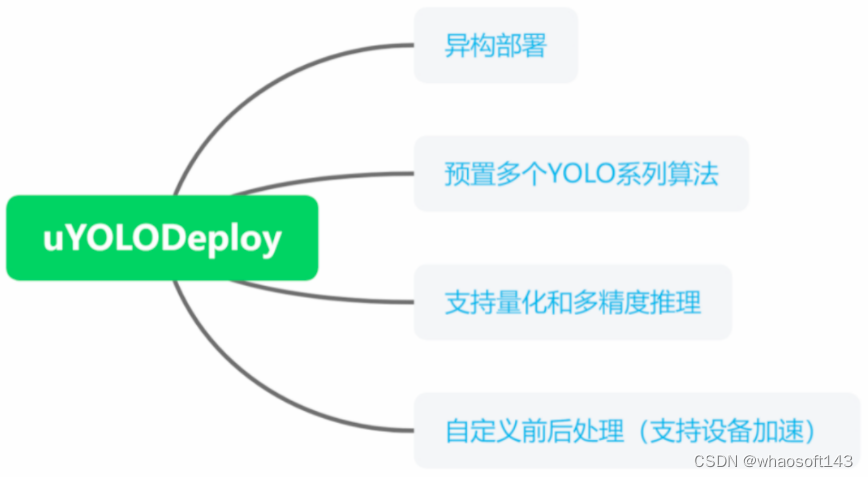 uYOLODeploy é fácil de usar e rápido de implantar. Segue um exemplo de aplicação:
uYOLODeploy é fácil de usar e rápido de implantar. Segue um exemplo de aplicação: 
\#include \<iostream\>\
\#include \"uyolo_deploy.h\"\
\
// Detector\
auto mDetector = std::make_shared\<Detector\>();\
\
// Init\
mDetector-\>Init(\"model file path\");\
mDetector-\>UpdateLabelsNames(\"coco.names\");\
mDetector-\>UpdateThresh(confThresh, nmsThresh);\
\
// Process\
for (;;)\
{\
\...\
mDetector-\>ProcessImage(inMat);\
// handle results \...\
mDetector-\>detectResults;\
}
 Resumo dos resultados do teste
Resumo dos resultados do teste
1. A análise de dados é crucial para modelos de treinamento.
2. Para a compensação entre precisão e desempenho do algoritmo, você pode primeiro experimentar a influência do tamanho da rede e do tamanho da imagem de entrada nos resultados do modelo.Tarefas diferentes e situações de dados diferentes têm uma grande diferença entre os dois. Portanto, você não pode simplesmente comprimir o tamanho da rede para melhorar a velocidade;
3. Para requisitos de desempenho, o modelo pode ser implantado usando métodos como TensorRT e também pode ser usada a compactação do modelo. Dessa forma, uma rede maior pode ser usada para melhorar a precisão do modelo e, ao mesmo tempo, garantir a velocidade.