Este blog é principalmente sobre o resumo de erros e soluções comuns de código CUDA ~
1. Erro de execução RuntimeError
1.1.RuntimeError: erro CUDA: memória insuficiente
Os erros do kernel CUDA podem ser relatados de forma assíncrona em alguma outra chamada de API, portanto, o stacktrace abaixo pode estar incorreto.
Para depuração, considere passar CUDA_LAUNCH_BLOCKING=1.

Erro ao analisar:
O programa estava funcionando bem, o código estava bom, a memória de vídeo ainda era inútil e a memória de vídeo era suficiente, a GPU pode estar ocupada,
Pode ser devido ao problema de cache do treinamento anterior, porque ele está sendo executado no contêiner docker, então pare o contêiner docker primeiro e depois inicie o contêiner~
1.2.RuntimeError: erro cuDNN: CUDNN_STATUS_INTERNAL_ERROR

possíveis erros
A versão do pytorch e cuda está errada
Memória de vídeo insuficiente
Consulte outro código de teste de blog
# True:每次返回的卷积算法将是确定的,即默认算法。
torch.backends.cudnn.deterministic = True
# 程序在开始时花额外时间,为整个网络的每个卷积层搜索最适合它的卷积实现算法
# 实现网络的加速。
torch.backends.cudnn.benchmark = Truesolução final
Definir numwork para 0
1.3.RuntimeError: CUDA sem memória
①RuntimeError: CUDA sem memória. Tentei alocar 152,00 MiB (GPU 0; 23,65 GiB de capacidade total; 13,81 GiB já alocado; 118,44 MiB livre; 14,43 GiB reservado no total pelo PyTorch) Se a memória reservada for >> memória alocada, tente definir max_split_size_mb para evitar a fragmentação. Consulte a documentação para gerenciamento de memória e PYTORCH_CUDA_ALLOC_CONF

Excedendo a memória ocupada pela GPU, os recursos da GPU local devem ser totalmente suficientes. No entanto, durante o processo de treinamento do pytorch, devido à retropropagação e parâmetros de avanço dos parâmetros da rede neural, como gradiente descendente , uma grande quantidade de memória da GPU será ocupada , por isso precisa ser reduzido. batch.
Solução:
Reduza o lote, ou seja, reduza o tamanho da amostra do treinamento de palavras
Liberar memória de vídeo: arch.cuda.empty_cache()
②torch.cuda.OutOfMemoryError : CUDA sem memória. Tentei alocar 128,00 MiB (GPU 0; 23,65 GiB de capacidade total; 22,73 GiB já alocados; 116,56 MiB livres; 22,78 GiB reservados no total pelo PyTorch) Se a memória reservada for >> memória alocada, tente definir max_split_size_mb para evitar a fragmentação. Consulte a documentação para gerenciamento de memória e PYTORCH_CUDA_ALLOC_CONF
arch.cuda.OutOfMemoryError: CUDA não tem memória. Tentando alocar 128,00 MiB (GPU 0; 23,65 GiB total; 22,73 GiB alocado; 116,56 MiB livre; 22,78 GiB total reservado pelo PyTorch) Se a memória reservada >> memória alocada, tente definir max_split_size_mb para evitar a fragmentação. Consulte a documentação para gerenciamento de memória e PYTORCH_CUDA_ALLOC_CONF.
Análise da causa do erro:
Durante o treinamento do modelo de aprendizado profundo, o código não libera a memória de vídeo toda vez que é treinado
solução:
ver nvidia-smi
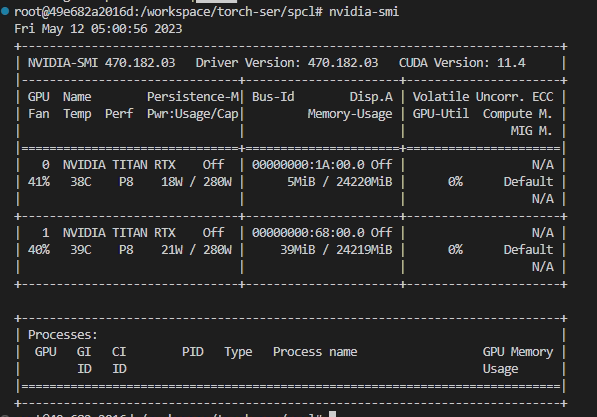
Neste momento , a GPU está rodando sem programa, e a memória de vídeo ainda está ocupada, conforme mostra a figura
Usar consulta de fusor
fuser -v /dev/nvidia*(Opção) Se você inserir o comando acima e ele informar que não há fusor, instale
apt-get install psmiscSe não for possível localizar o pacote XXX aparecer, então
apt-get update
Força (-9) para matar o processo, digite o seguinte comando
kill -9 PIDDiagrama de exemplo

Apenas libere a memória de vídeo~