Neste artigo, quero elaborar sobre a parte Vocoder da Síntese de Fala (TTS).
Índice
1. O papel do vocoder (Vocoder)
1. O papel do vocoder (Vocoder)
A síntese de fala neural é dividida principalmente em:
- Preveja representações de baixa resolução de texto , como mel-espectrogramas ou recursos linguísticos
- Preveja áudio de forma de onda bruta a partir de representações de baixa resolução
Alguns modelos comuns de síntese de fala Deep Voice, Tacotron e Fastspeech (TTS) são o processo de entrada de texto para gerar fala, e o Vocoder (Vocoder) converte o áudio original (.wav) em um espectrograma Mel (mel-espectrograma)
Para analisar o áudio no domínio da frequência, uma transformada de Fourier de curto prazo (STFT) pode ser realizada para extrair pontos de recursos correspondentes aos componentes de frequência. Dentre eles, o espectrograma de mel pode ser obtido aplicando um banco de filtros de mel usando valores de magnitude correspondentes aos componentes de magnitude e convertendo para uma escala de mel. De fato, se os valores de amplitude e fase dos componentes de frequência forem conhecidos, a transformada STFT pode ser transformada inversamente, de modo que a fala original possa ser restaurada sem perda de informações. No entanto, para modelos TTS que geralmente preveem e aprendem espectrogramas mel, apenas as informações de magnitude dos componentes de frequência podem ser encontradas, para prever a fala original, a informação de fase deve ser prevista e a fala original deve ser prevista com base nisso. Um vocoder executa esta função.
2. Vocoder clássico
Algoritmo Neural Vocoder: Vocoder usando Deep Learning. Atualmente, os principais modelos utilizados podem ser divididos nos seguintes tipos (alguns artigos são divididos em 3 tipos, e alguns são divididos em 5 tipos, este artigo é classificado de acordo com [4] artigos):
- Auto-regressivo: WaveNet, WaveRNN
- Baseado em fluxo (fluxos): WaveGlow, Parallel WaveNet
- Baseado no modelo de rede adversária generativa ( GAN): MelGAN, Parallel WaveGAN
- baseado em VAE
- Baseado em difusão: WaveGrid, DiffWave
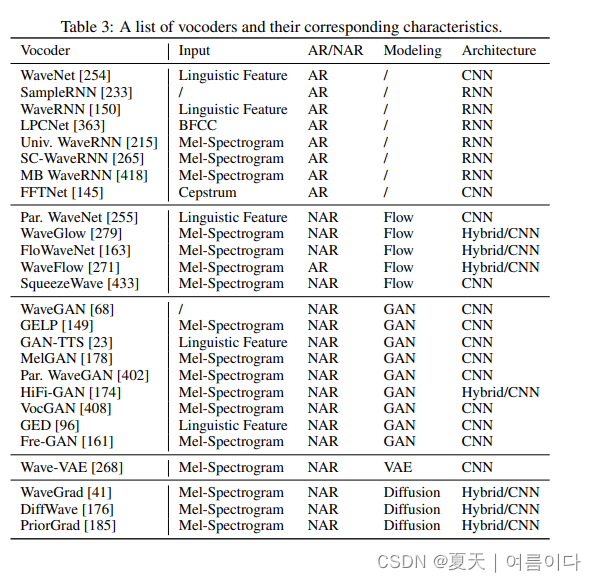
Este artigo explica principalmente alguns vocoders clássicos (o vermelho é obrigatório):

2.1.WaveNet
Modelo Gerativo Autorregressivo - WaveNet
O WaveNet usa o PixelCNN, um modelo generativo autorregressivo, para sintetizar a qualidade da fala no domínio da fala que é muito melhor do que a aprendida pelos modelos concatenados e paramétricos existentes. No entanto, devido à natureza dos modelos AR, há uma desvantagem de levar muito tempo para aprendizado e inferência, e pesquisas foram feitas para compensar isso.
2.2.WaveGlow
Modelo Gerativo Baseado em Stream
Com o advento de modelos baseados em fluxo, como Parallel WaveNet [6] e WaveGlow [7], a qualidade e a velocidade da fala sintetizada são capturadas. No entanto, uma desvantagem do WaveGlow é que o modelo requer muitos parâmetros.
2.3. MelGAN
Modelo de rede adversária generativa (GAN)
A fim de melhorar as deficiências dos modelos acima, a qualidade da fala sintetizada pode ser reduzida, mas pode efetivamente melhorar a velocidade e o número de parâmetros da pesquisa do modelo GAN.
2.4.VocGAN
Modelo de rede adversária generativa (GAN)
Com base no vocoder Melgan, é proposto um vocoder multiescala VocGan, que resolve o problema da baixa qualidade do som sintetizado de Melgan. A qualidade do som pode ser melhorada mantendo a velocidade de síntese do melgan, e o design de Loss pode ser usado como referência em outros vocoders, como os vocoders da série multibanda.
2.5.HiFi-GAN
Modelo de rede adversária generativa (GAN)
HiFi-GAN melhora as deficiências de baixa qualidade de voz em trabalhos anteriores baseados em GAN, combinando alta eficiência computacional e qualidade de voz,
referências
[1] [Resumo] Aprenda sobre Neural Vocoder
【2】Uma rápida olhada na síntese de voz usando Deep Learning (TTS) (Vocoder) (tistory.com)
【3】Text To Speech — Conhecimento Fundamental (Parte 2) | por Aaron Brown | Rumo à ciência de dados
【4】A Survey on Neural Speech Synthesis:2106.15561.pdf (arxiv.org)
Referência
[1] Kong, Jungil, Jaehyeon Kim e Jaekyoung Bae. "HiFi-GAN: Redes Adversárias Generativas para Síntese de Fala Eficiente e de Alta Fidelidade." pré-impressão arXiv arXiv:2010.05646 (2020).
[2] Ping, Wei, e outros. "Voz profunda 3: dimensionando a conversão de texto em fala com aprendizado de sequência convolucional." pré-impressão arXiv arXiv:1710.07654 (2017).
[3] Shen, Jonathan, e outros. "Síntese natural de tts condicionando wavenet em previsões de espectrograma de mel." 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) . IEEE, 2018.
[4] librosa.org/doc/main/generated/librosa.griffinlim.html
[5] Oord, Aaron van den, e outros. "Wavenet: um modelo generativo para áudio bruto." pré-impressão arXiv arXiv:1609.03499 (2016).
[6] Oord, Aaron, e outros. "Wavenet paralela: Síntese de fala rápida de alta fidelidade." Conferência Internacional sobre Aprendizado de Máquina . PMLR, 2018.
[7] Prenger, Ryan, Rafael Valle e Bryan Catanzaro. "Waveglow: Uma rede generativa baseada em fluxo para síntese de fala." ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) . IEEE, 2019.
[8] Kumar, Kundan, e outros. "Melgan: redes adversárias generativas para síntese de forma de onda condicional." pré-impressão arXiv arXiv:1910.06711 (2019).
[9] Bińkowski, Mikołaj, et al. "Síntese de fala de alta fidelidade com redes adversárias." pré-impressão arXiv arXiv:1909.11646 (2019).
[10] Yang, Jinhyeok, e outros. "VocGAN: um Vocoder em tempo real de alta fidelidade com uma rede adversária hierarquicamente aninhada." arXiv preprint arXiv:2007.15256 (2020).