1. Übersicht
Flink CDC ist eine Reihe von Quellkonnektoren für Apache Flink®, die Change Data Capture (CDC) verwenden, um Änderungen aus verschiedenen Datenbanken abzurufen. CDC Connectors für Apache Flink integriert Debezium als Engine zur Erfassung von Datenänderungen. So können die Möglichkeiten von Debezium voll ausgeschöpft werden.
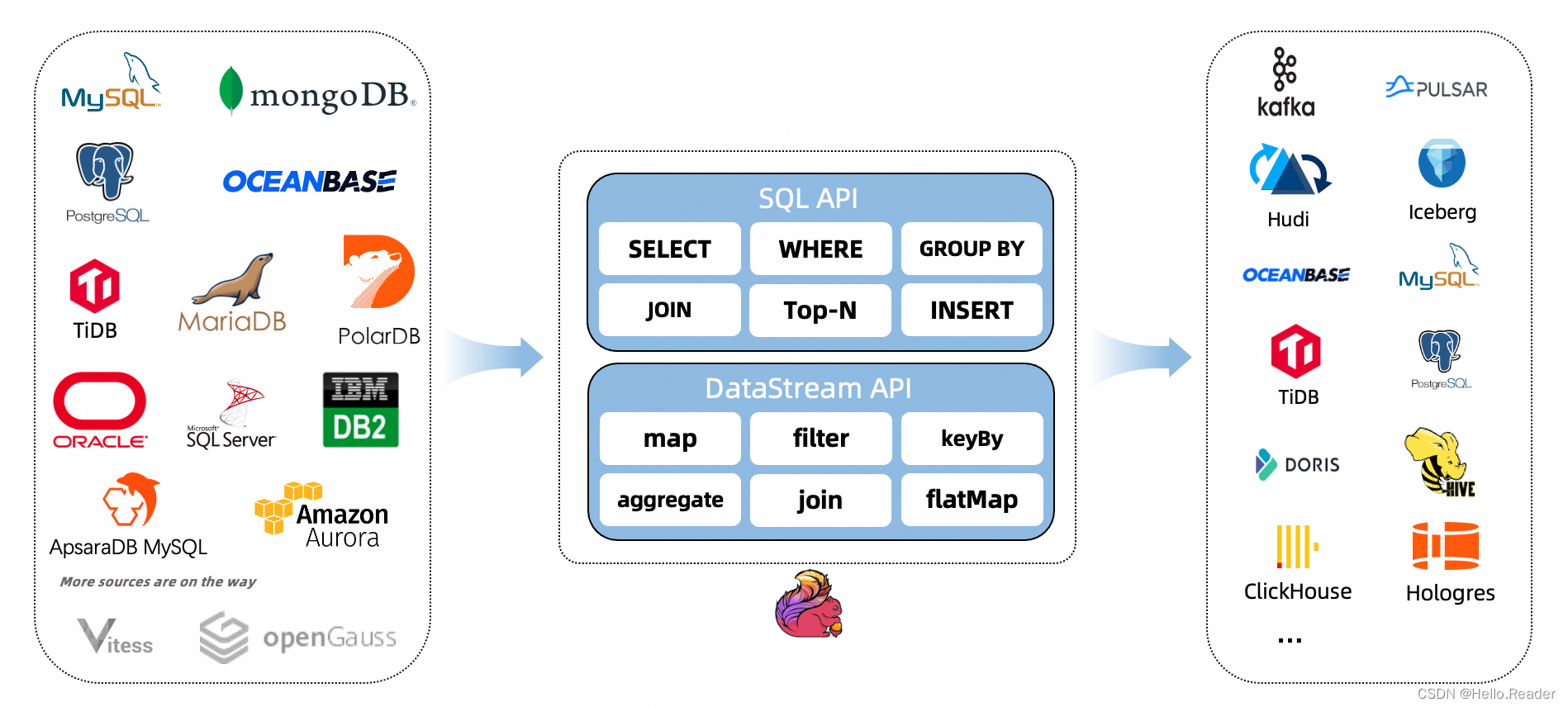
2. Unterstützte Anschlüsse
| Verbinder | Datenbank | Antrieb |
|---|---|---|
| mongodb-cdc | MongoDB: 3.6, 4.x, 5.0 | MongoDB-Treiber: 4.3.4 |
| mysql-cdc | MySQL: 5.6, 5.7, 8.0.x、RDS MySQL: 5.6, 5.7, 8.0.x、PolarDB MySQL: 5.6, 5.7, 8.0.x、Aurora MySQL: 5.6, 5.7, 8.0.x、MariaDB: 10.x、PolarDB X: 2.0.1 | JDBC-Treiber: 8.0.28 |
| ozeanbasis-cdc | OceanBase CE: 3.1.x, 4.x、OceanBase EE: 2.x, 3.x, 4.x | OceanBase-Treiber: 2.4.x |
| oracle-cdc | Orakel: 11, 12, 19, 21 | Oracle-Treiber: 19.3.0.0 |
| postgres-cdc | PostgreSQL: 9.6, 10, 11, 12, 13, 14 | JDBC-Treiber: 42.5.1 |
| sqlserver-cdc | SQL Server: 2012, 2014, 2016, 2017, 2019 | JDBC-Treiber: 9.4.1.jre8 |
| tidb-cdc | TiDB: 5.1.x, 5.2.x, 5.3.x, 5.4.x, 6.0.0 | JDBC-Treiber: 8.0.27 |
| db2-cdc | Db2: 11,5 | Db2-Treiber: 11.5.0.0 |
| vitess-cdc | Geschwindigkeit: 8.0.x, 9.0.x | MySql JDBC-Treiber: 8.0.26 |
3. Unterstützte Flink-Versionen
Die folgende Tabelle zeigt die Versionskorrespondenz zwischen Flink CDC Connectors und Flink®:
| Flink CDC-Version_ | Flink-Version_ |
|---|---|
| 1.0.0 | 1.11.* |
| 1.1.0 | 1.11.* |
| 1.2.0 | 1.12.* |
| 1.3.0 | 1.12.* |
| 1.4.0 | 1.13.* |
| 2.0.* | 1.13.* |
| 2.1.* | 1.13.* |
| 2.2.* | 1.13.*、1.14.* |
| 2.3.* | 1.13.*、1.14.*、1.15.*、1.16.0 |
| 2.4.* | 1.13.*、1.14*、1.15.*、1.16.*、1.17.0 |
4. Funktionen
Unterstützt das Lesen von Datenbank-Snapshots und kann Binlog auch dann weiter lesen, wenn ein Fehler auftritt, und eine genau einmalige Verarbeitung durchführen.
Mit dem CDC-Connector für die DataStream-API können Benutzer mehrere Datenbank- und Tabellenänderungen in einem einzigen Job verwenden, ohne Debezium und Kafka bereitzustellen.
Mit dem CDC-Connector für die Tabellen-/SQL-API können Benutzer mithilfe von SQL DDL CDC-Feeds erstellen, um Änderungen an einer einzelnen Tabelle zu überwachen.
5. Verwendung der Tabellen-/SQL-API
Wir benötigen ein paar Schritte, um einen Flink-Cluster mit den bereitgestellten Konnektoren einzurichten.
Zuerst haben wir die Version 1.17+ des Flink-Clusters (Java 8+) installiert.
Hinweis : Wenn Sie Flink installieren müssen, lesen Sie bitte den entsprechenden Blog des Autors zur Flink-Hochverfügbarkeitsclusterkonstruktion (Standalone-Modus).
Die in diesem Artikel verwendeten JAR-Pakete sind flink-connector-jdbc-3.1.1-1.17.jar und flink -sql-connector-mysql-cdc -2.2.1.jar
Laden Sie das Connector-SQL-JAR herunter (oder erstellen Sie es selbst ).
Legen Sie das heruntergeladene JAR-Paket in FLINK_HOME/lib/ ab.
Starten Sie den Flink-Cluster neu.
Hinweis : Derzeit müssen Versionen über 2.4 selbst kompiliert und erstellt werden. Der Autor dieses Artikels erstellt und lädt ihn selbst hoch
6. Verwenden Sie Flink CDC, um Streaming-ETL auf MySQL durchzuführen
Dieses Tutorial zeigt, wie Sie mit Flink CDC schnell ein Streaming-ETL für MySQL erstellen.
Angenommen, wir speichern Produktdaten in MySQL und synchronisieren sie mit einem anderen MySQL
In den folgenden Abschnitten stellen wir vor, wie Sie Flink Mysql CDC verwenden, um dies zu erreichen. Alle Übungen in diesem Tutorial werden in der Flink SQL-CLI durchgeführt und der gesamte Prozess verwendet die Standard-SQL-Syntax ohne Java/Scala-Code oder IDE-Installation.
Die Architektur wird wie folgt beschrieben:

7. Vorbereitung der Umgebung
Sie müssen die installierte MySQL-Datenbank vorbereiten. Einzelheiten zur Installation von MySQL-Daten finden Sie im Blog des Autors Ubuntu-Datenbankinstallation (MySQL)
Hinweis: Für andere Betriebssysteme lesen Sie bitte das Tutorial zur Datenbankinstallation entsprechend anderen Blogs
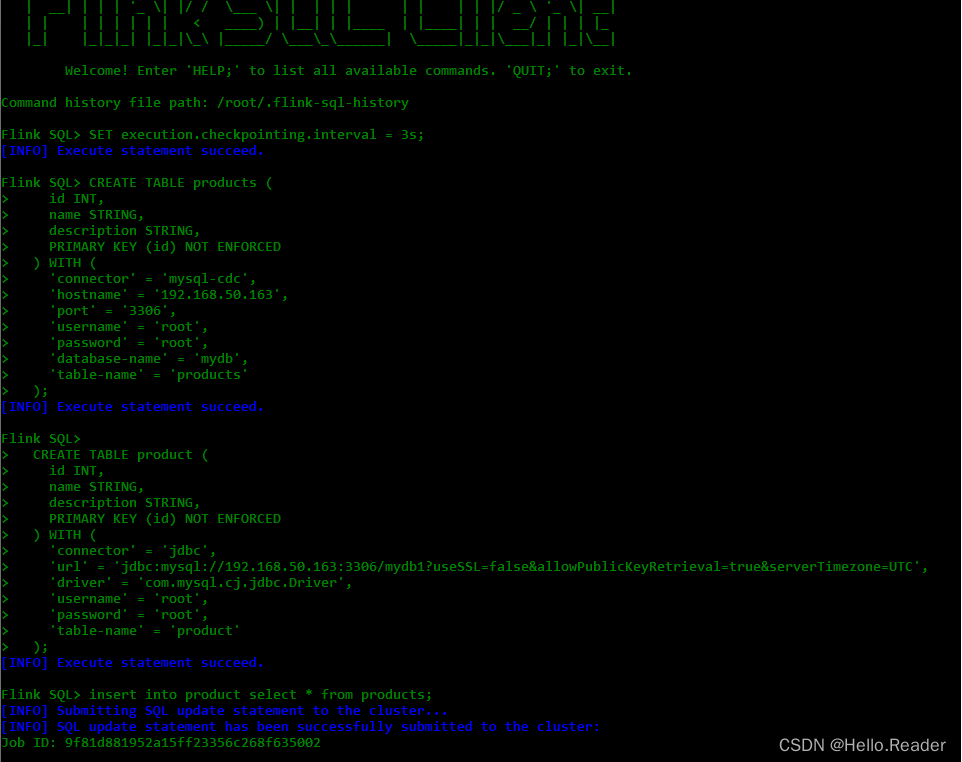
8. Erstellen Sie Tabellen mit Flink DDL in der Flink SQL CLI
Starten Sie die Flink SQL CLI mit dem folgenden Befehl:
./bin/sql-client.sh
Wir sollten den Begrüßungsbildschirm des CLI-Clients sehen.
 Aktivieren Sie zunächst das Checkpointing alle 3 Sekunden
Aktivieren Sie zunächst das Checkpointing alle 3 Sekunden
-- Flink SQL
Flink SQL> SET execution.checkpointing.interval = 3s;
Bearbeiten Sie den Flink-SQL-Code der Quelldatenbank wie folgt:
CREATE TABLE products (
id INT NOT NULL,
name STRING,
description STRING,
PRIMARY KEY(id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc', #引入的CDC jar包驱动,没有引入会报错提示需要引入
'hostname' = '192.168.50.163',#源数据库连接host地址,可以根据自己的具体设置,此处为笔者本机的
'port' = '3306', #源数据库端口
'username' = 'root',#源数据库账号
'password' = '*****',#源数据库密码
'database-name' = 'mydb',#源数据库
'table-name' = 'products'#源数据库表
);
Führen Sie die folgende Anweisung in Flink SQL aus, um eine Tabelle zu erstellen, die geänderte Daten aus der entsprechenden Datenbanktabelle erfasst
-- Flink SQL
Flink SQL> CREATE TABLE products (
id INT,
name STRING,
description STRING,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = '192.168.50.163',
'port' = '3306',
'username' = 'root',
'password' = '****',
'database-name' = 'mydb',
'table-name' = 'products'
);
Bearbeiten Sie den Flink-SQL-Code der Zieldatenbank wie folgt:
CREATE TABLE product (
id INT,
name STRING,
description STRING,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
#引入的jdbc jar包驱动,没有引入会报错提示需要引入 flink-connector-jdbc
'connector' = 'jdbc',
#目标数据库连接url地址,可以根据自己的具体设置,此处为笔者本机的。部分高版本的MySQL需要添加useSSL=false&allowPublicKeyRetrieval=true&serverTimezone=UTC
'url' = 'jdbc:mysql://192.168.50.163:3306/mydb1?useSSL=false&allowPublicKeyRetrieval=true&serverTimezone=UTC',
#需要访问的数据库驱动
'driver' = 'com.mysql.cj.jdbc.Driver',
#目标数据库账号
'username' = 'root',
#目标据库密码
'password' = '***',
#目标数据库表
'table-name' = 'product'
);
Führen Sie die folgende Anweisung in Flink SQL aus, um eine Zuordnungsbeziehung zwischen der Tabelle, die die geänderten Daten erfasst, und der Zieldatenbanktabelle zu erstellen
-- Flink SQL
Flink SQL> CREATE TABLE product (
id INT,
name STRING,
description STRING,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://192.168.50.163:3306/mydb1?useSSL=false&allowPublicKeyRetrieval=true&serverTimezone=UTC',
'driver' = 'com.mysql.cj.jdbc.Driver',
'username' = 'root',
'password' = 'root',
'table-name' = 'product'
);
9. Laden Sie die Quelldatentabelle in das Ziel-MySQL
Verwenden Sie Flink SQL, um die Tabellenprodukt- und Tabellenabfrageprodukttabelle in das Ziel-MySQL zu schreiben.
-- Flink SQL
Flink SQL> insert into product select * from products;
Die spezifischen Betriebsschritte sind wie folgt:
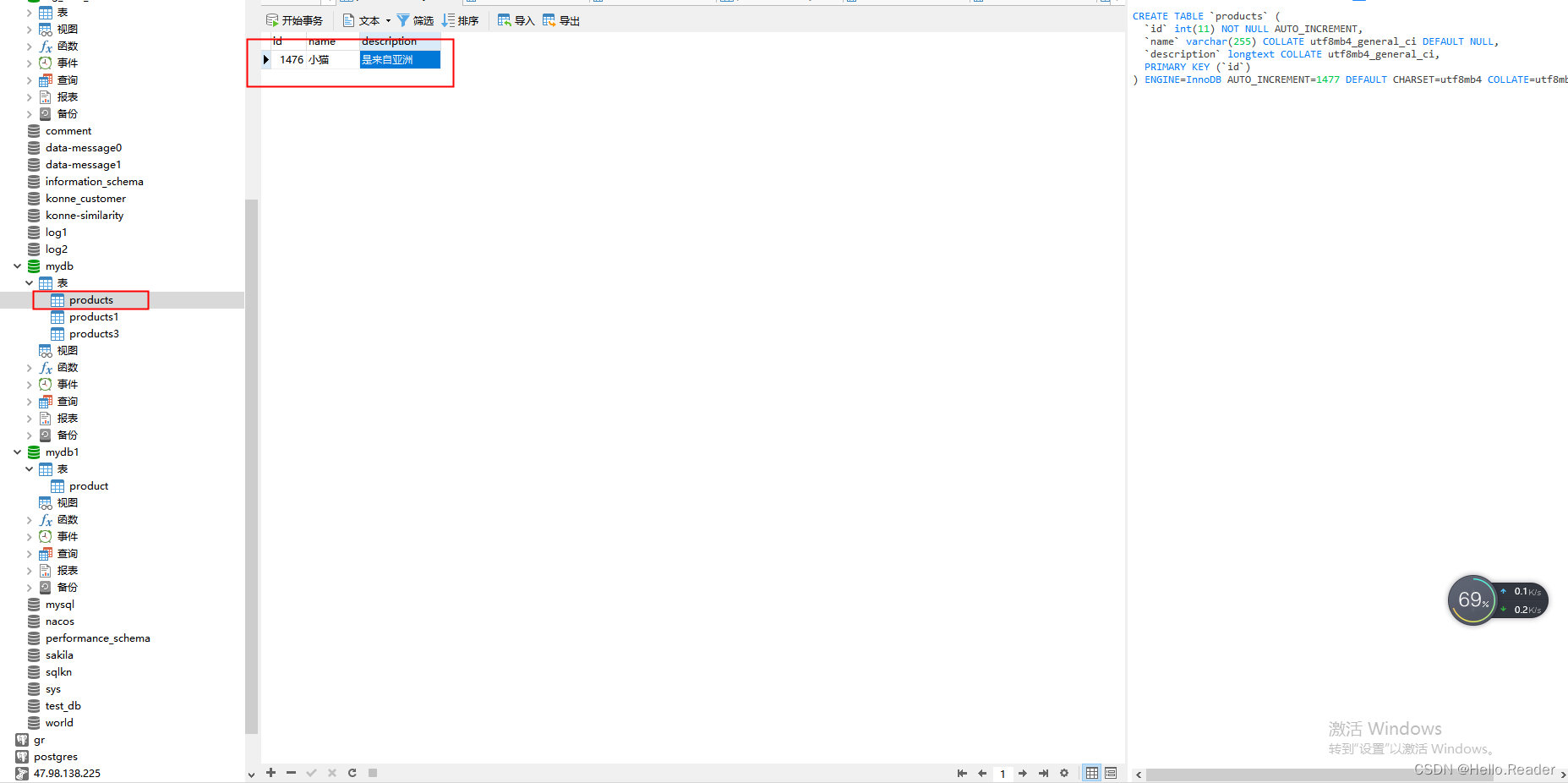
Dies ist die Quelldatenbank. Der Vorgang fügt Daten hinzu, wie in der folgenden Abbildung dargestellt:
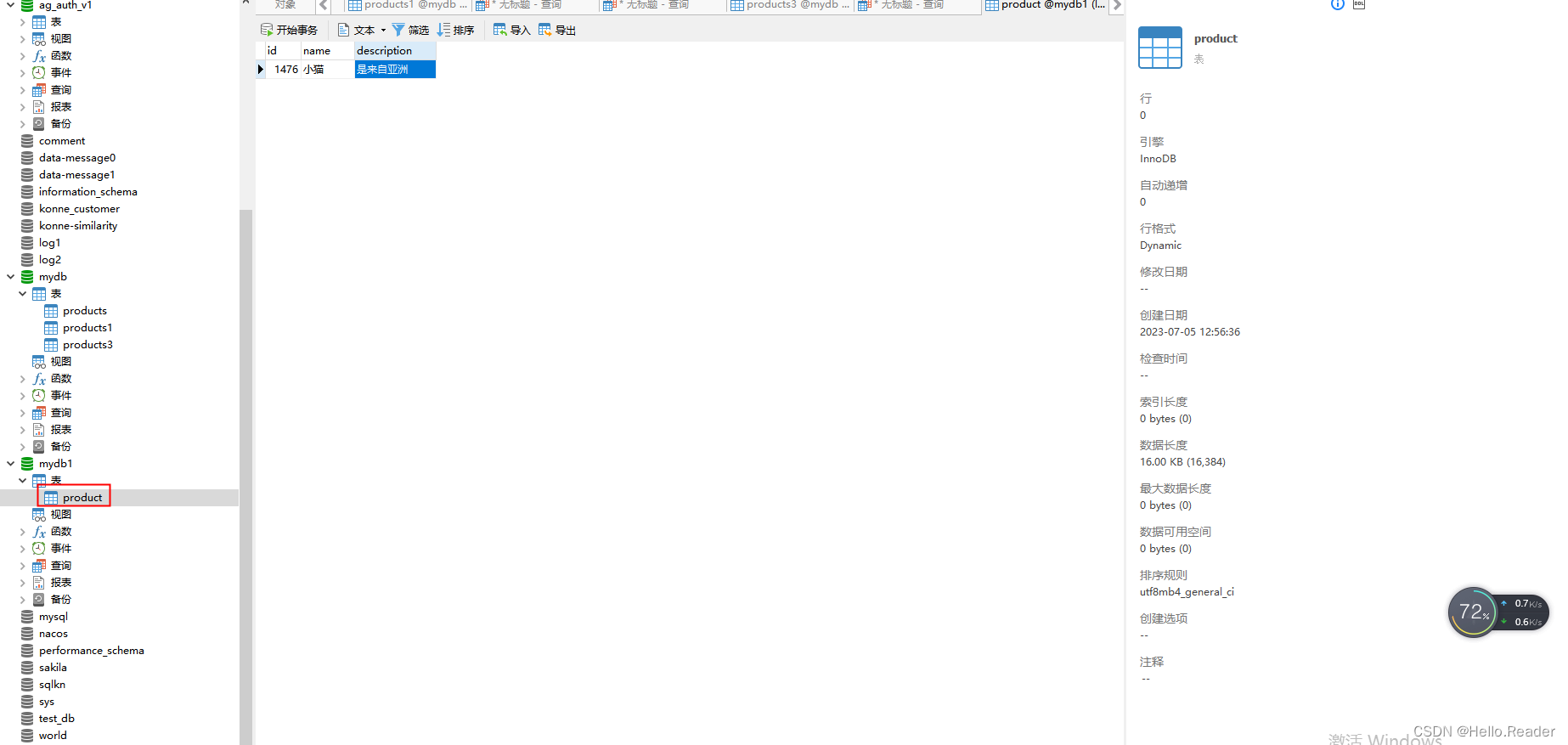
Der Synchronisierungsvorgang der Zieldatenbank ist wie in der folgenden Abbildung dargestellt
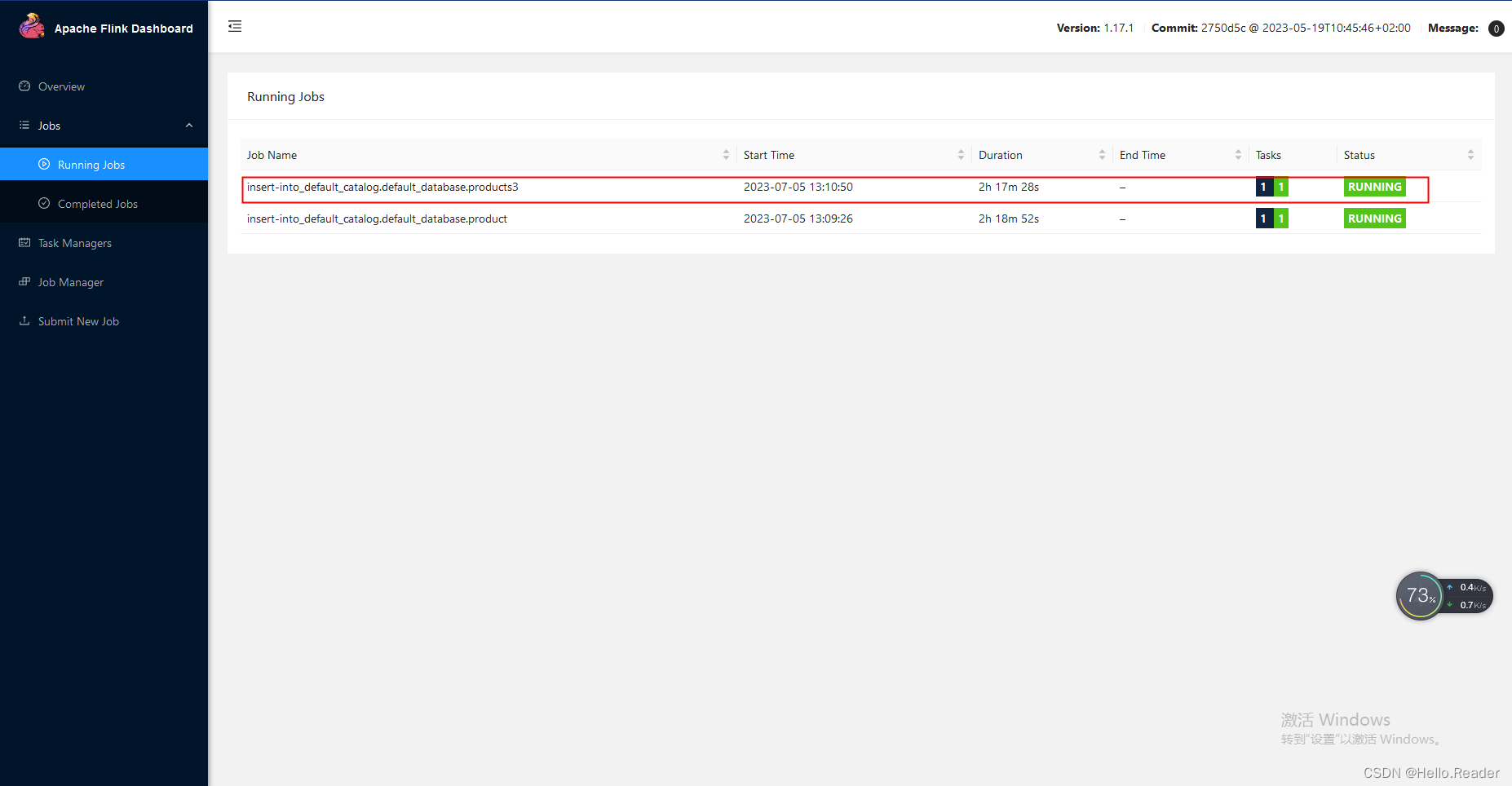
10. Flinken Sie über die visuelle Oberfläche, um laufende JOBS anzuzeigen
Aktivieren Sie das rote Kästchen als laufende Synchronisierungsaufgabe.
Bisher wurde der erste Abschnitt der MySQL-Synchronisierung mit Flink CDC erklärt, und seine komplexen Vorgänge werden später aktualisiert