Diretório de artigos
introdução de fundo
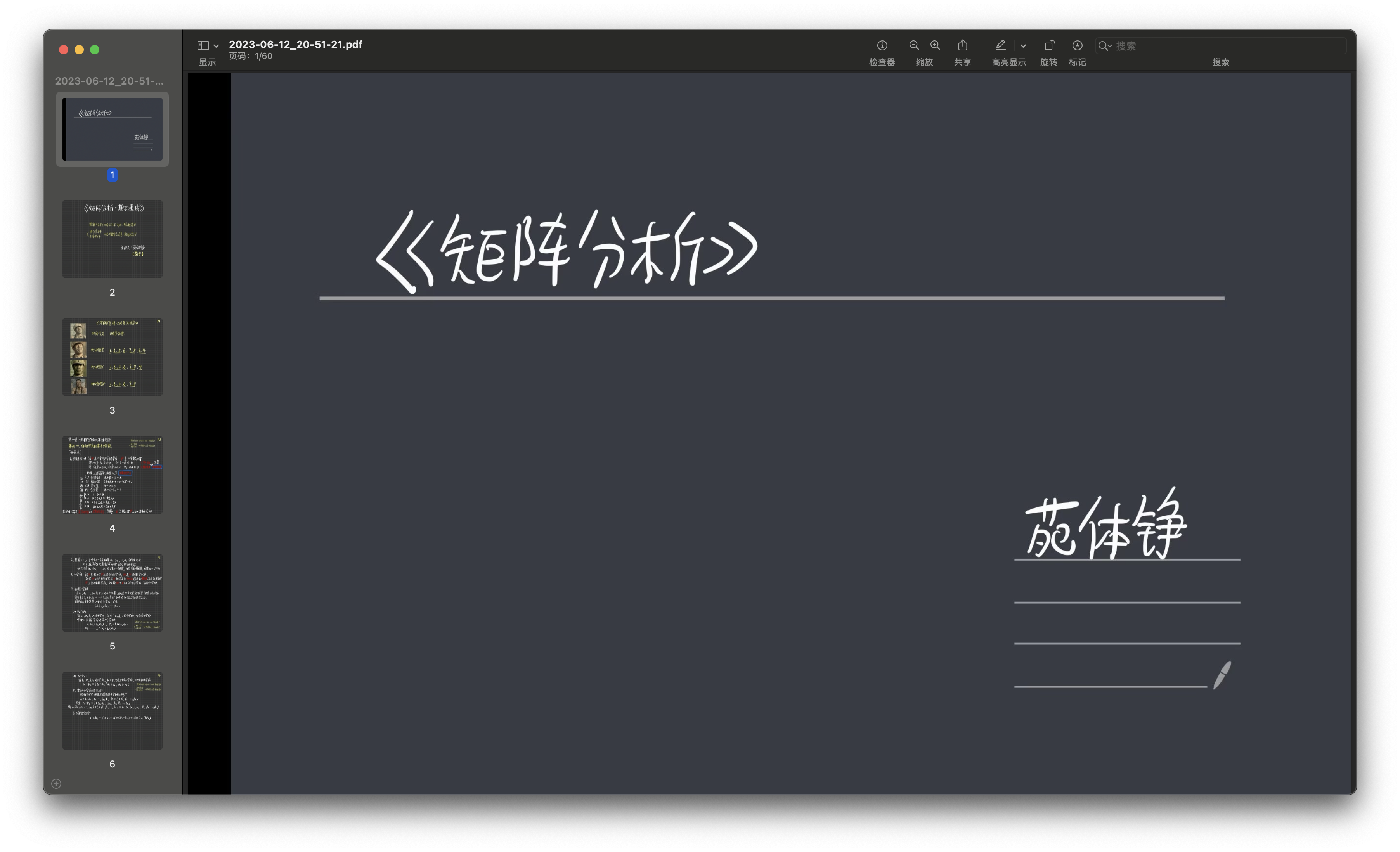
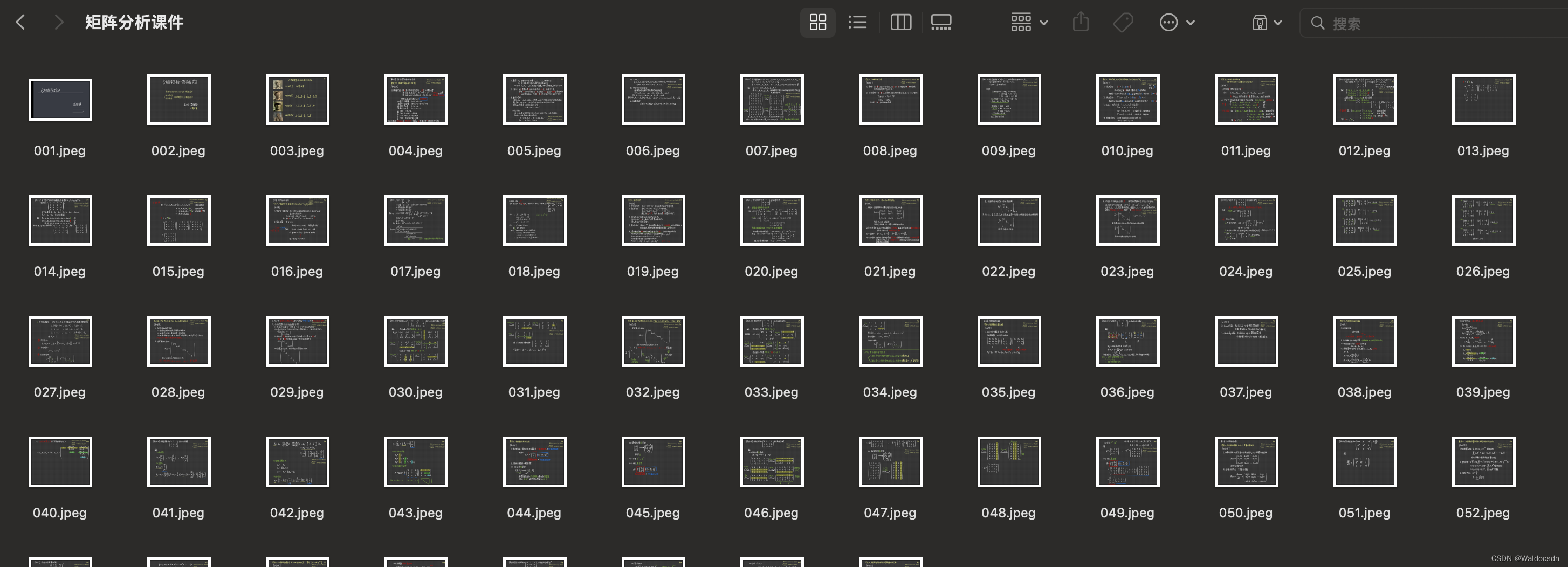
Ao assistir a um curso de "análise de matrizes" de um up master, o curso do up master é salvo no Qzone na forma de imagens. O formulário de imagem não é fácil de aprender, então eu quero converter as imagens salvas no "curso de análise de matriz" para pdf através do código Python, e manter a proporção da imagem inalterada, e o arquivo pdf é ordenado no momento atual . Classifique os nomes dos arquivos de imagem antes de adicioná-los para que a ordem das páginas no PDF corresponda à ordem das imagens.
o código
import os
import datetime
from PIL import Image
from fpdf import FPDF
# 图片所在文件夹路径
img_folder = "矩阵分析课件"
# 获取文件夹中的所有文件
images = [img for img in os.listdir(img_folder) if img.endswith(".jpg") or img.endswith(".png") or img.endswith(".jpeg")]
# 按照文件名排序
images.sort()
# 创建一个pdf对象
pdf = FPDF(unit="mm")
# 遍历每一个图片
for i in range(len(images)):
img_path = os.path.join(img_folder, images[i])
# 使用PIL库打开图片并获取尺寸
img = Image.open(img_path)
width, height = img.size
# 转换尺寸单位到毫米
width_mm = width * 0.264583
height_mm = height * 0.264583
# 把图片添加到pdf
pdf.add_page(format=(width_mm, height_mm))
pdf.image(img_path, x = 0, y = 0, w = width_mm, h = height_mm)
# 以当前时间命名PDF文件
now = datetime.datetime.now()
pdf_name = now.strftime("%Y-%m-%d_%H-%M-%S") + ".pdf"
# 保存pdf文件
pdf.output(pdf_name, "F")
análise de código
A seguir, uma explicação detalhada de cada parte do código:
-
Importe as bibliotecas necessárias:
import os import datetime from PIL import Image from fpdf import FPDFAqui importamos quatro bibliotecas: os, datetime, PIL e fpdf. As bibliotecas os e datetime são bibliotecas internas do Python para lidar com o sistema operacional e operações relacionadas ao tempo. PIL (Pillow) é uma biblioteca de processamento de imagem que usamos para obter as dimensões de uma imagem. A biblioteca FPSF é usada para criar e editar arquivos PDF.
-
Especifique a pasta onde as imagens estão localizadas e obtenha todos os arquivos de imagem:
# 图片所在文件夹路径 img_folder = "矩阵分析课件" # 获取文件夹中的所有文件 images = [img for img in os.listdir(img_folder) if img.endswith(".jpg") or img.endswith(".png") or img.endswith(".jpeg")] # 按照文件名排序 images.sort()Esta parte do código primeiro define o caminho para a pasta onde as imagens estão localizadas e, em seguida, usa a função listdir da biblioteca do os para obter todos os nomes de arquivo nessa pasta. A compreensão da lista é usada para filtrar arquivos de imagem .jpg, .png e .jpeg e adicionar seus nomes à lista. Por fim, classifique os nomes de arquivo na lista.
-
Crie um objeto FPDF e itere sobre cada imagem:
# 创建一个pdf对象 pdf = FPDF(unit="mm") # 遍历每一个图片 for i in range(len(images)): img_path = os.path.join(img_folder, images[i]) # 使用PIL库打开图片并获取尺寸 img = Image.open(img_path) width, height = img.size # 转换尺寸单位到毫米 width_mm = width * 0.264583 height_mm = height * 0.264583 # 把图片添加到pdf pdf.add_page(format=(width_mm, height_mm)) pdf.image(img_path, x = 0, y = 0, w = width_mm, h = height_mm)Primeiro, crie um objeto FPDF e defina a unidade em mm. Em seguida, percorra cada imagem, abra a imagem usando a biblioteca PIL e obtenha as dimensões e, em seguida, converta as dimensões da imagem de pixels para milímetros. Por fim, adicione uma nova página para cada imagem e adicione a imagem a essa página. O tamanho de cada página será definido de acordo com o tamanho de sua imagem correspondente.
-
Use a hora atual para nomear e salvar o arquivo PDF:
# 以当前时间命名PDF文件 now = datetime.datetime.now() pdf_name = now.strftime("%Y-%m-%d_%H-%M-%S") + ".pdf" # 保存pdf文件 pdf.output(pdf_name, "F")Esta parte do código primeiro obtém a data e hora atuais e, em seguida, usa a função strftime para formatar a hora em uma string e usá-la como o nome do arquivo PDF. Finalmente, salve o arquivo PDF usando o método de saída do objeto FPDF.
Exibir