《Rumo à vetorização de imagens em camadas》(CVPR 2022)
GitHub: github.com/ma-xu/LIVE
Instalação
Sugerimos que os usuários usem o conda para criar um novo ambiente python.
Requisito: 5,0<GCC<6,0; nvcc >10,0.
git clone [email protected]:ma-xu/LIVE.gitcd LIVE
conda create -n live python=3.7
conda activate live
conda install -y pytorch torchvision -c pytorch
conda install -y numpy scikit-image
conda install -y -c anaconda cmake
conda install -y -c conda-forge ffmpeg
pip install svgwrite svgpathtools cssutils numba torch-tools scikit-fmm easydict visdom
pip install opencv-python==4.5.4.60 # please install this version to avoid segmentation fault.cd DiffVG
git submodule update --init --recursive
python setup.py installcd ..Executar experimentos
conda activate live
cd LIVE
# Please modify the paramters accordingly.
python main.py --config <config.yaml> --experiment <experiment-setting> --signature <given-folder-name> --target <input-image> --log_dir <log-dir>
# Here is an simple example:
python main.py --config config/base.yaml --experiment experiment_5x1 --signature smile --target figures/smile.png --log_dir log/《Fusão de token multimodal para transformadores de visão》(CVPR 2022)
GitHub: github.com/yikaiw/TokenFusion

《PointAugmenting: Aumento Cross-Modal para Detecção de Objetos 3D》(CVPR 2022)
GitHub: github.com/VISION-SJTU/PointAugmenting


《Perguntas fantásticas e onde encontrá-las: FairytaleQA -- Um conjunto de dados autêntico para compreensão narrativa.》(ACL 2022)
GitHub: github.com/uci-soe/FairytaleQAData
《LUNAR: Unificando métodos de detecção de outliers locais por meio de redes neurais de gráfico》(AAAI 2022)
GitHub: github.com/agoodge/LUNAR
Firstly, extract data.zip
To replicate the results on the HRSS dataset with neighbour count k = 100 and "Mixed" negative sampling scheme
Extract saved_models.zip
Run:
python3 main.py--datasetHRSS--samplesMIXED--k 100To train a new model:
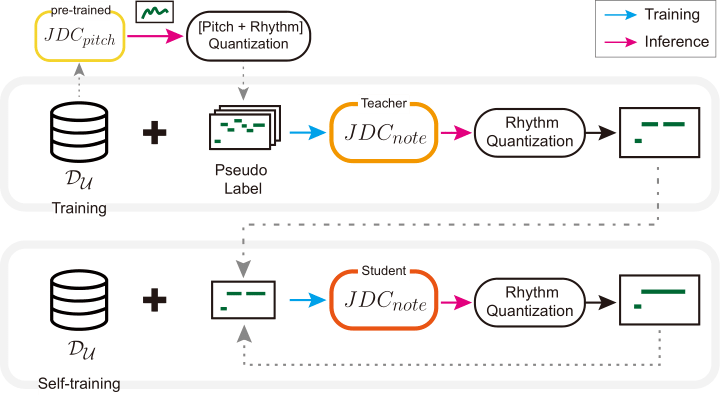
python3 main.py--datasetHRSS--samplesMIXED--k 100 --train_new_model《Pseudo-Label Transfer from Frame-Level to Note-Level in a Teacher-Student Framework for Singing Transcription from Polyphonic Music》(ICASSP 2022)
GitHub: github.com/keums/icassp2022-vocal-transcription

《Robust Disentangled Variational Speech Representation Learning for Zero-shot Voice Conversion》(ICASSP 2022)
GitHub: github.com/jlian2/Robust-Voice-Style-Transfer
Demo:https://jlian2.github.io/Robust-Voice-Style-Transfer/

《HandoverSim: A Simulation Framework and Benchmark for Human-to-Robot Object Handovers》(ICRA 2022)
GitHub: github.com/NVlabs/handover-sim
2022-06-03 16:13:46: Running evaluation for results/2022-02-28_08-57-34_yang-icra2021_s0_test
2022-06-03 16:13:47: Evaluation results:
| success rate | mean accum time (s) | failure (%) |
| (%) | exec | plan | total | hand contact | object drop | timeout |
|:---------------:|:------:|:------:|:-------:|:---------------:|:---------------:|:--------------:|
| 64.58 ( 93/144) | 4.864 | 0.036 | 4.900 | 17.36 ( 25/144) | 11.81 ( 17/144) | 6.25 ( 9/144) |
2022-06-03 16:13:47: Printing scene ids
2022-06-03 16:13:47: Success (93 scenes):
--- --- --- --- --- --- --- --- --- --- --- --- --- --- --- --- --- --- --- ---
0 1 2 3 4 5 6 7 8 9 10 12 13 15 16 17 18 19 21 22
23 25 26 27 28 30 33 34 35 36 37 38 42 43 46 49 50 53 54 56
59 60 62 63 64 66 68 69 70 71 72 77 81 83 85 87 89 91 92 93
94 95 96 98 103 106 107 108 109 110 111 112 113 114 115 116 117 120 121 123
125 126 127 128 130 131 132 133 137 138 139 141 143
--- --- --- --- --- --- --- --- --- --- --- --- --- --- --- --- --- --- --- ---
2022-06-03 16:13:47: Failure - hand contact (25 scenes):
--- --- --- --- --- --- --- --- --- --- --- --- --- --- --- --- --- --- --- ---
11 14 20 29 39 40 41 44 45 47 51 55 57 58 65 67 74 80 82 88
102 105 118 124 136
--- --- --- --- --- --- --- --- --- --- --- --- --- --- --- --- --- --- --- ---
2022-06-03 16:13:47: Failure - object drop (17 scenes):
--- --- --- --- --- --- --- --- --- --- --- --- --- --- --- --- ---
24 31 32 52 61 78 79 84 86 97 101 104 119 122 134 140 142
--- --- --- --- --- --- --- --- --- --- --- --- --- --- --- --- ---
2022-06-03 16:13:47: Failure - timeout (9 scenes):
--- --- --- --- --- --- --- --- ---
48 73 75 76 90 99 100 129 135
--- --- --- --- --- --- --- --- ---
2022-06-03 16:13:47: Evaluation complete.《CDLM: Cross-Document Language Modeling》(EMNLP 2021)
GitHub: github.com/aviclu/CDLM
You can either pretrain by yourself or use the pretrained CDLM model weights and tokenizer files, which are available on HuggingFace.
Then, use:
from transformers import AutoTokenizer, AutoModel
# load model and tokenizer
tokenizer = AutoTokenizer.from_pretrained('biu-nlp/cdlm')
model = AutoModel.from_pretrained('biu-nlp/cdlm')
《Continual Learning for Task-Oriented Dialogue Systems》(EMNLP 2021)
GitHub: github.com/andreamad8/ToDCL

《Torsional Diffusion for Molecular Conformer Generation》(2022)
GitHub: github.com/gcorso/torsional-diffusion

《MMChat: Multi-Modal Chat Dataset on Social Media》(2022)
GitHub: github.com/silverriver/MMChat

《Can CNNs Be More Robust Than Transformers?》(2022)
GitHub: github.com/UCSC-VLAA/RobustCNN

《Revealing Single Frame Bias for Video-and-Language Learning》(2022)
GitHub: github.com/jayleicn/singularity

《Progressive Distillation for Fast Sampling of Diffusion Models》(2022)
GitHub: github.com/Hramchenko/diffusion_distiller

《Neural Basis Models for Interpretability》(2022)
GitHub: github.com/facebookresearch/nbm-spam
《Scalable Interpretability via Polynomials》(2022)
GitHub: github.com/facebookresearch/nbm-spam
《Infinite Recommendation Networks: A Data-Centric Approach》(2022)
GitHub: github.com/noveens/infinite_ae_cf
《The GatedTabTransformer. An enhanced deep learning architecture for tabular modeling》(2022)
GitHub: github.com/radi-cho/GatedTabTransformer
Usage:
import torch
import torch.nn as nn
from gated_tab_transformer import GatedTabTransformer
model = GatedTabTransformer(
categories = (10, 5, 6, 5, 8), # tuple containing the number of unique values within each category
num_continuous = 10, # number of continuous values
transformer_dim = 32, # dimension, paper set at 32
dim_out = 1, # binary prediction, but could be anything
transformer_depth = 6, # depth, paper recommended 6
transformer_heads = 8, # heads, paper recommends 8
attn_dropout = 0.1, # post-attention dropout
ff_dropout = 0.1, # feed forward dropout
mlp_act = nn.LeakyReLU(0), # activation for final mlp, defaults to relu, but could be anything else (selu, etc.)
mlp_depth=4, # mlp hidden layers depth
mlp_dimension=32, # dimension of mlp layers
gmlp_enabled=True # gmlp or standard mlp
)
x_categ = torch.randint(0, 5, (1, 5)) # category values, from 0 - max number of categories, in the order as passed into the constructor above
x_cont = torch.randn(1, 10) # assume continuous values are already normalized individually
pred = model(x_categ, x_cont)
print(pred)
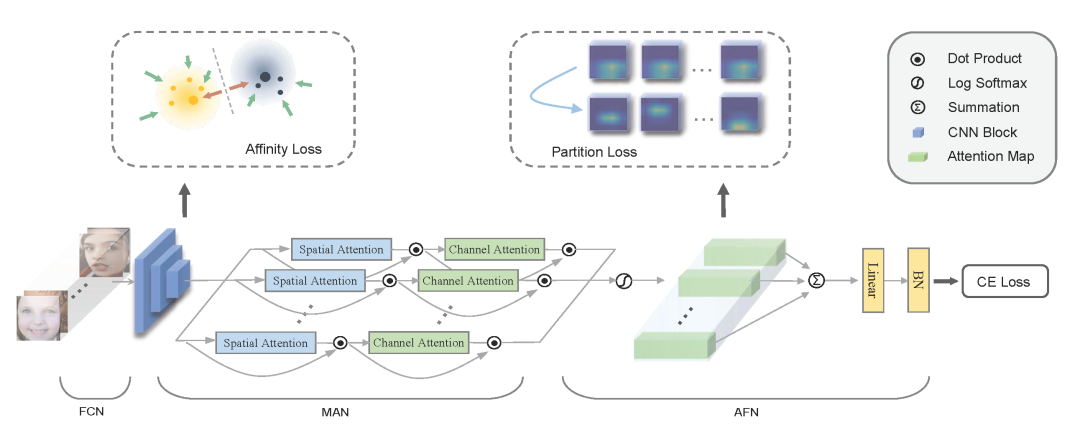
《Distract Your Attention: Multi-head Cross Attention Network for Facial Expression Recognition》(2022)
GitHub: github.com/yaoing/DAN
《Towards Principled Disentanglement for Domain Generalization》(2021)
GitHub: github.com/hlzhang109/DDG
《SoundStream: An End-to-End Neural Audio Codec》(2021)
GitHub: github.com/wesbz/SoundStream