Artikelverzeichnis
Vorwort
Die Diskretisierung ist ein sehr wichtiger Teil der Datenbereinigung. Nachfolgende Standardisierung, Ausreißerverarbeitung, Modelle usw. müssen alle einige Textdaten diskretisieren. Hier teile ich die Diskretisierung in zwei Kategorien ein: die Diskretisierung numerischer Daten und die Diskretisierung von Zeichendaten
1. Diskretisierung von Zeichendaten
Der Zweck der Diskretisierung von Zeichen besteht darin, sicherzustellen, dass die nachfolgende Datenbereinigung normal durchgeführt werden kann, da Daten mit Zeichen nicht für viele Datenbereinigungsvorgänge verwendet werden können. Hier werden die Daten „Berichtstyp“, „Buchhaltungsstandard“ und „Währungscode“ verwendet. werden als Beispiele verwendet. Erklärt werden.
1.1 Onehot allein heiß
Verwenden Sie für die Verarbeitung eine One-Hot-Codierung und führen Sie eine One-Hot-Verarbeitung für die Zeichen durch, die scheinbar mehrdimensional geworden sind.
import pandas as pd
emb_dummies_df = pd.get_dummies(data['会计准则'],prefix=data[['会计准则']].columns[0])
#prefix表示列名在值的前面要添加的字符串
emb_dummies_df
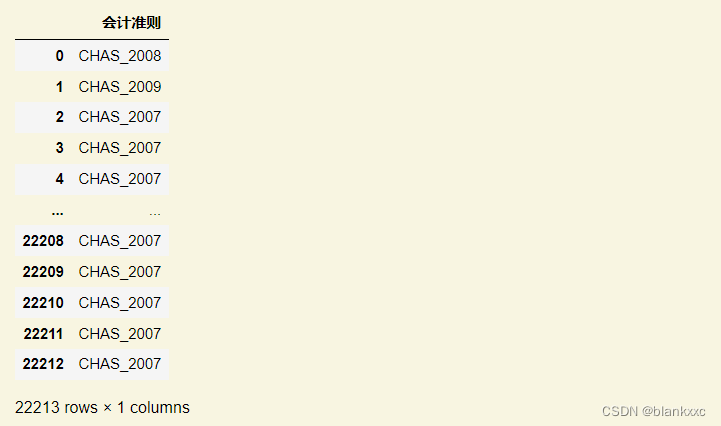
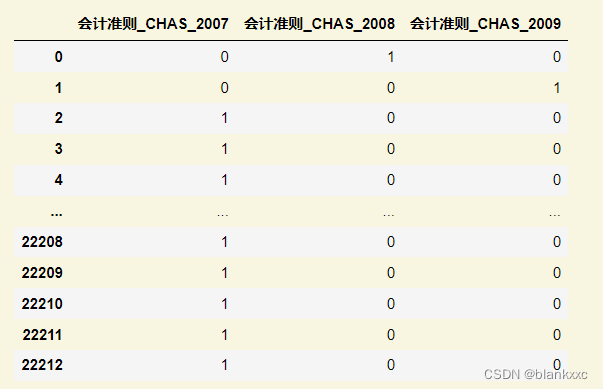
One-Hot-Codierung kann verwendet werden, um den Wert der Spalte in eine mehrdimensionale digitale Darstellung umzuwandeln, aber dadurch wird die Dimension vergrößert und der Rechenaufwand erhöht. Sie können k-means auch verwenden, um die Daten zunächst zu gruppieren und sie dann zu kodieren.
1.2 Faktorisieren der diskreten Codierung
Im Moment soll eine einzelne Spalte in mehrdimensionale Daten umgewandelt werden und mit 1 und 0 angegeben werden, ob es eine solche Zahl gibt. Und Factoring besteht darin, die Zahlen in dieser Spalte in 1, 2 ... n umzuwandeln, je nachdem, wie viele Klassen es gibt. Der Code und die Beispiele sind unten aufgeführt
data['会计准则'] = pd.factorize(data['会计准则'])[0]
data[['会计准则']]
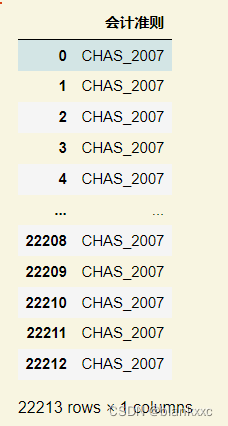
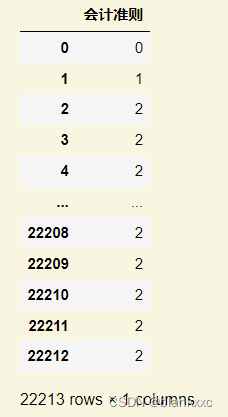
Phasenzusammenfassung: Hier handelt es sich um alle Einzelspalten-Diskretisierungsverarbeitungen. Darüber hinaus gibt es auch Codierungen wie TF-IDF, die häufig für die Textanalyse verwendet werden. Wenn später Zeit bleibt, wird möglicherweise weiterhin eine Welle aktualisiert.
2. Diskretisierung numerischer Daten
2.1 Binning (Datenbinning)
Dabei werden die Daten nach Flächen unterteilt, z. B. 1-30, 30-100, 100-1000, um unterschiedliche Flächenklassen zu erhalten, und diese entsprechend zu analysieren.
#与区间的数学符号一致, 小括号表示开放,中括号表示封闭, 可以通过right参数改变
print(pd.cut(ages, bins, right=False))#qcut函数是根据均等距离划分
#单个列进行划分
train_data['Fare_bin'] = pd.qcut(train_data['Fare'],5) #5是指分成五份
#自定义范围划分
bins = [0,59,70,80,100]
df['Categories'] = pd.cut(df['score'],bins) #bins的各值作为区间的边
# 可以通过labels自定义箱名或者区间名 用于多个列进行划分
group_names = ['Youth', 'YonngAdult', 'MiddleAged', 'Senior']
data = pd.cut(ages, bins, labels=group_names)
print(data)
print(pd.value_counts(data))
# 如果将箱子的边替代为箱子的个数,pandas将根据数据中的最小值和最大值计算出等长的箱子
data2 = np.random.rand(20)
print(pd.cut(data2, 4, precision=2)) # precision=2 将十进制精度限制在2位
# qcut是另一个分箱相关的函数, 基于样本分位数进行分箱。取决于数据的分布,使用cut不会使每个箱子具有相同数据数量的数据点,而qcut,使用
# 样本的分位数,可以获得等长的箱
data3 = np.random.randn(1000) # 正太分布
cats = pd.qcut(data3, 4)
print(pd.value_counts(cats))
Datenbinning ist eine Methode zur Diskretisierung kontinuierlicher Variablen, die den kontinuierlichen Datenbereich in mehrere geordnete, nicht überlappende Intervalle unterteilt und die Daten dann den entsprechenden Intervallen zuordnet.
Die Bedeutung des Datenbinnings ist:
Reduzierte Komplexität: Bei einigen Algorithmen für maschinelles Lernen kann die Verarbeitung kontinuierlicher Variablen die Rechenkomplexität erhöhen. Binning kann kontinuierliche Variablen in diskrete Variablen umwandeln, wodurch die Rechenkomplexität reduziert und die Handhabung fehlender Werte und Ausreißer erleichtert wird.
Vorhersagegenauigkeit verbessern: In einigen Szenarien können diskretisierte Daten die Beziehung zwischen Variablen besser aufzeigen und die Vorhersagegenauigkeit des Modells verbessern. Beispielsweise erfasst in einem Kreditbewertungsmodell die Aufteilung des Einkommens in Stufen die nichtlineare Beziehung zwischen Einkommen und Ausfallraten besser.
Einfache Interpretation und Visualisierung: Diskretisierte Daten sind einfacher zu interpretieren und zu visualisieren. Beispielsweise kann in der Marketinganalyse durch die Einteilung des Alters in mehrere Gruppen die demografische Verteilung und die Konsumgewohnheiten verschiedener Altersgruppen klarer dargestellt werden.
Zusammenfassen
Diskretisierung kontinuierlicher Variablen: Die Diskretisierung
kontinuierlicher Variablen unterteilt den kontinuierlichen Datenbereich in mehrere geordnete, nicht überlappende Intervalle und ordnet die Daten dann den entsprechenden Intervallen zu. Die diskretisierten Daten können die Beziehung zwischen Variablen besser aufzeigen und die Vorhersagegenauigkeit des Modells verbessern. Darüber hinaus kann die Diskretisierung kontinuierlicher Variablen auch die Rechenkomplexität verringern, den Umgang mit fehlenden Werten und Ausreißern erleichtern und die Interpretation und Visualisierung erleichtern.Zeichendiskretisierung:
Die Zeichendiskretisierung wandelt Zeichendaten in diskrete Daten um. Die diskretisierten Daten können besser auf Algorithmen wie Klassifizierung, Clustering und Assoziationsregel-Mining angewendet werden. Beispielsweise kann bei der Textklassifizierung nach der Konvertierung des Textes in ein Bag-of-Words-Modell jedes Wort durch Diskretisierung in ein Merkmal umgewandelt werden und der Text kann in einen Vektor umgewandelt werden. Darüber hinaus kann die Zeichendiskretisierung auch die Datenverarbeitung erleichtern, z. B. Datendeduplizierung, Datenkomprimierung usw.