비디오 키프레임 AI의 논리는 비디오를 프레임으로 나눈 다음 SD 페인팅을 사용하여 스타일을 수정하고 마지막으로 함께 연결하여 새로운 비디오를 형성하는 것입니다.
Mov2Mov와 Multi Frame 모두 이런 종류의 비디오를 만들 수 있습니다. 그러나 이러한 작업은 번거롭기 때문에 보다 안정적인 방법으로 처리 를 시도한 후 제어 복구 및 일괄 처리를 수행 할 수 있으므로 작업이 매우 간단해집니다 img2im.batch_sizeControlNetADetailer
Stable Diffusion 방법
비디오 변환 플러그인을 설치하고 SD 디렉토리 아래의 scripts폴더에 convert.py 파일을 만들고 다음 코드를 파일에 복사합니다.
import cv2
import gradio as gr
import os
from tqdm import tqdm
from modules import script_callbacks
def add_tab():
with gr.Blocks(analytics_enabled=False) as ui:
with gr.Row().style(equal_height=False):
with gr.Column(variant='panel'):
gr.HTML(value="<p>Extract frames from video</p>")
input_video = gr.Textbox(label="Input video path")
output_folder = gr.Textbox(label="Output frames folder path")
output_fps = gr.Slider(minimum=1, maximum=120, step=1, label="Save every N frame", value=1)
extract_frames_btn = gr.Button(label="Extract Frames", variant='primary')
with gr.Column(variant='panel'):
gr.HTML(value="<p>Merge frames to video</p>")
input_folder = gr.Textbox(label="Input frames folder path")
output_video = gr.Textbox(label="Output video path")
output_video_fps = gr.Slider(minimum=1, maximum=60, step=1, label="Video FPS", value=30)
merge_frames_btn = gr.Button(label="Merge Frames", variant='primary')
extract_frames_btn.click(
fn=extract_frames,
inputs=[
input_video,
output_folder,
output_fps
]
)
merge_frames_btn.click(
fn=merge_frames,
inputs=[
input_folder,
output_video,
output_video_fps
]
)
return [(ui, "视频<->帧", "vf_converter")]
def extract_frames(video_path: str, output_path: str, custom_fps=None):
"""从视频文件中提取帧并输出为png格式
Args:
video_path (str): 视频文件的路径
output_path (str): 输出帧的路径
custom_fps (int, optional): 自定义输出帧率(默认为None,表示与视频帧率相同)
Returns:
None
"""
cap = cv2.VideoCapture(video_path)
fps = int(cap.get(cv2.CAP_PROP_FPS))
custom_fps = int(custom_fps)
frame_count = 0
print(f"Extracting {
video_path} to {
output_path}...")
while True:
ret, frame = cap.read()
if not ret:
break
if custom_fps:
if frame_count % custom_fps == 0:
output_name = os.path.join(output_path, '{:06d}.png'.format(frame_count))
cv2.imwrite(output_name, frame)
else:
output_name = os.path.join(output_path, '{:06d}.png'.format(frame_count))
cv2.imwrite(output_name, frame)
frame_count += 1
cap.release()
print("Extract finished.")
def merge_frames(frames_path: str, output_path: str, fps=None):
"""将指定文件夹内的所有png图片按顺序合并为一个mp4视频文件
Args:
frames_path (str): 输入帧的路径(所有帧必须为png格式)
output_path (str): 输出视频的路径(需以.mp4为文件扩展名)
fps (int, optional): 输出视频的帧率(默认为None,表示与输入帧相同)
Returns:
None
"""
# 获取所有png图片
frames = [f for f in os.listdir(frames_path) if f.endswith('.png')]
img = cv2.imread(os.path.join(frames_path, frames[0]))
height, width, _ = img.shape
fps = fps or int(cv2.CAP_PROP_FPS)
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
video_writer = cv2.VideoWriter(output_path, fourcc, fps, (width, height))
print(f"Merging {
len(frames)} frames to video...")
for f in tqdm(frames):
img = cv2.imread(os.path.join(frames_path, f))
video_writer.write(img)
video_writer.release()
print("Merge finished")
script_callbacks.on_ui_tabs(add_tab)
AI 처리에 필요한 짧은 영상을 준비하고, 영상 저장 경로에 중국인이 없도록 주의하세요. 여기에서 비디오의 고화질 해상도를 선택하십시오. 그렇지 않으면 최종 합성된 비디오 문자가 변형됩니다.
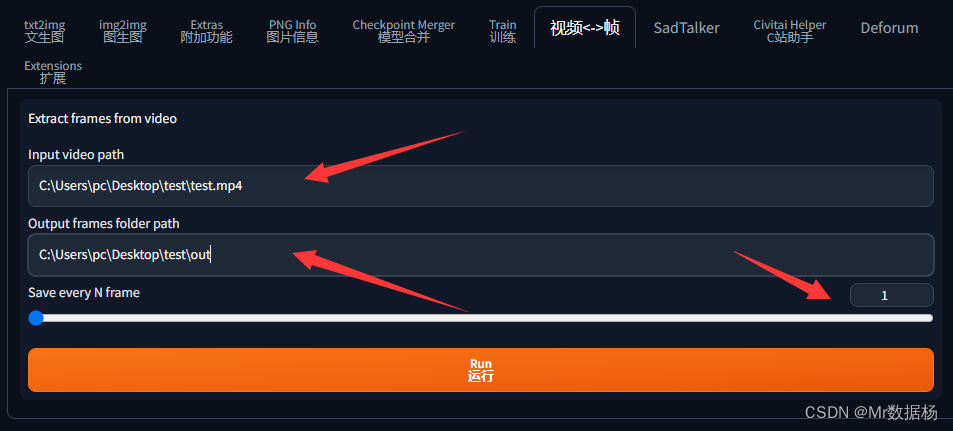
SD를 열어 비디오 및 프레임 스왑 탭을 선택하고 비디오 경로와 프레임을 변환하여 사진을 저장하는 경로를 입력합니다. 아래의 숫자 1은 모든 프레임을 가로채는 것을 의미합니다. 즉, 60프레임 비디오가 1초면 60장의 사진이 됩니다.
클릭하여 실행하면 각 프레임의 그림이 해당 폴더 아래에 나타납니다.

사진 중 하나를 선택하여 img2img탭으로 드래그하고 모델을 선택한 다음 기본 설정에 따라 해당 키워드를 출력합니다. 처음 처리된 이미지는 원본 이미지와 아무 관련이 없음을 알 수 있습니다.
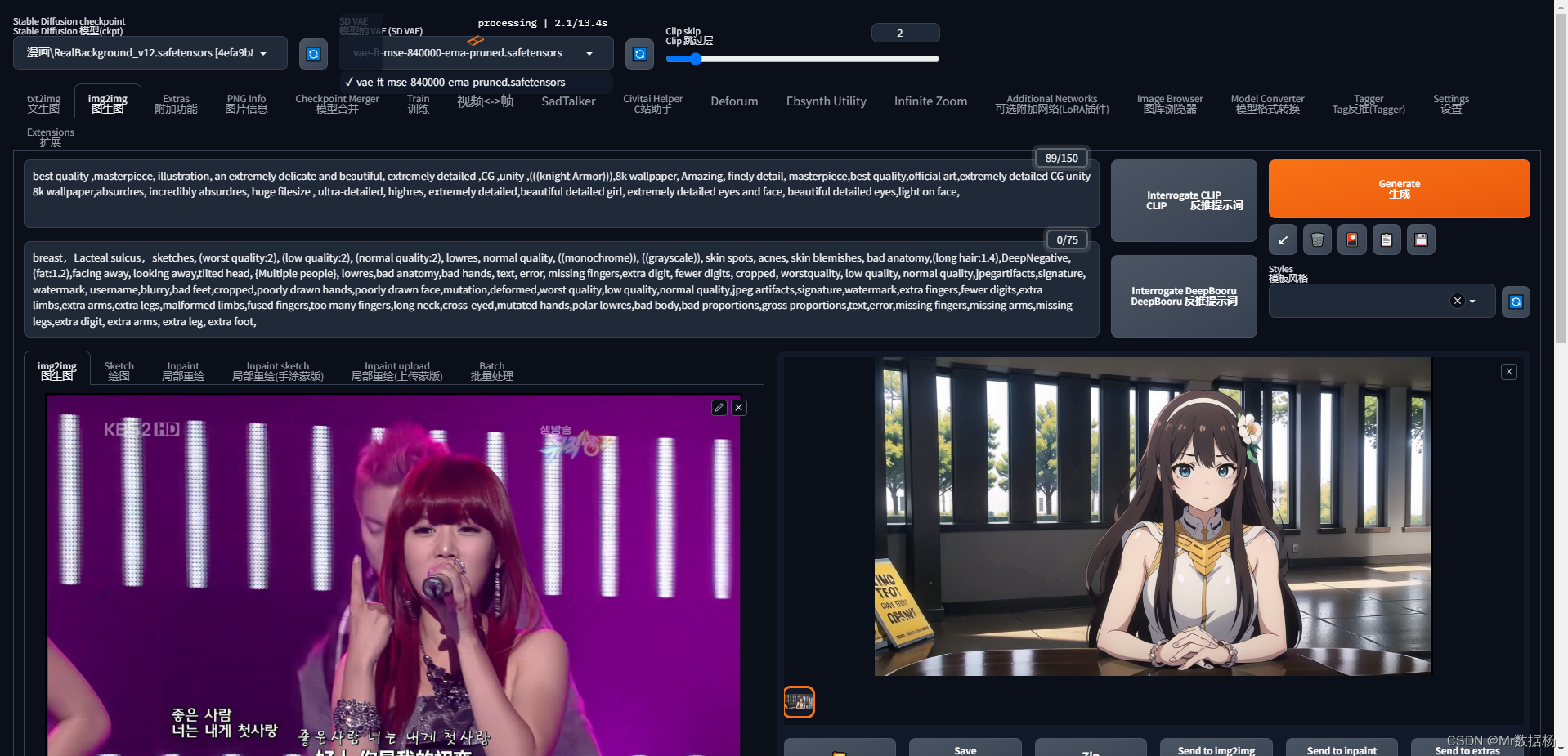
ControlNet이 제어 대상으로 선택되지 않았기 때문에 아래의 ControlNet 탭을 클릭하여 Canny를 설정합니다.
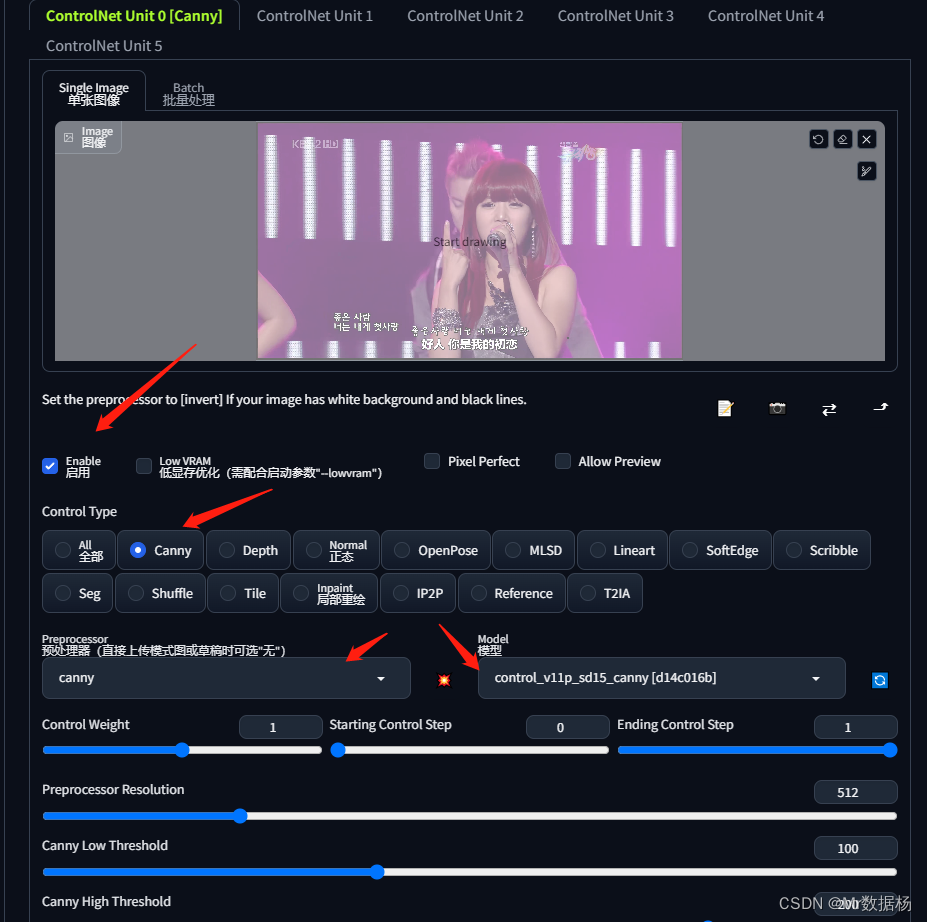
그런 다음 이미지 생성을 다시 클릭하면 이미지가 변경되었음을 알 수 있습니다.
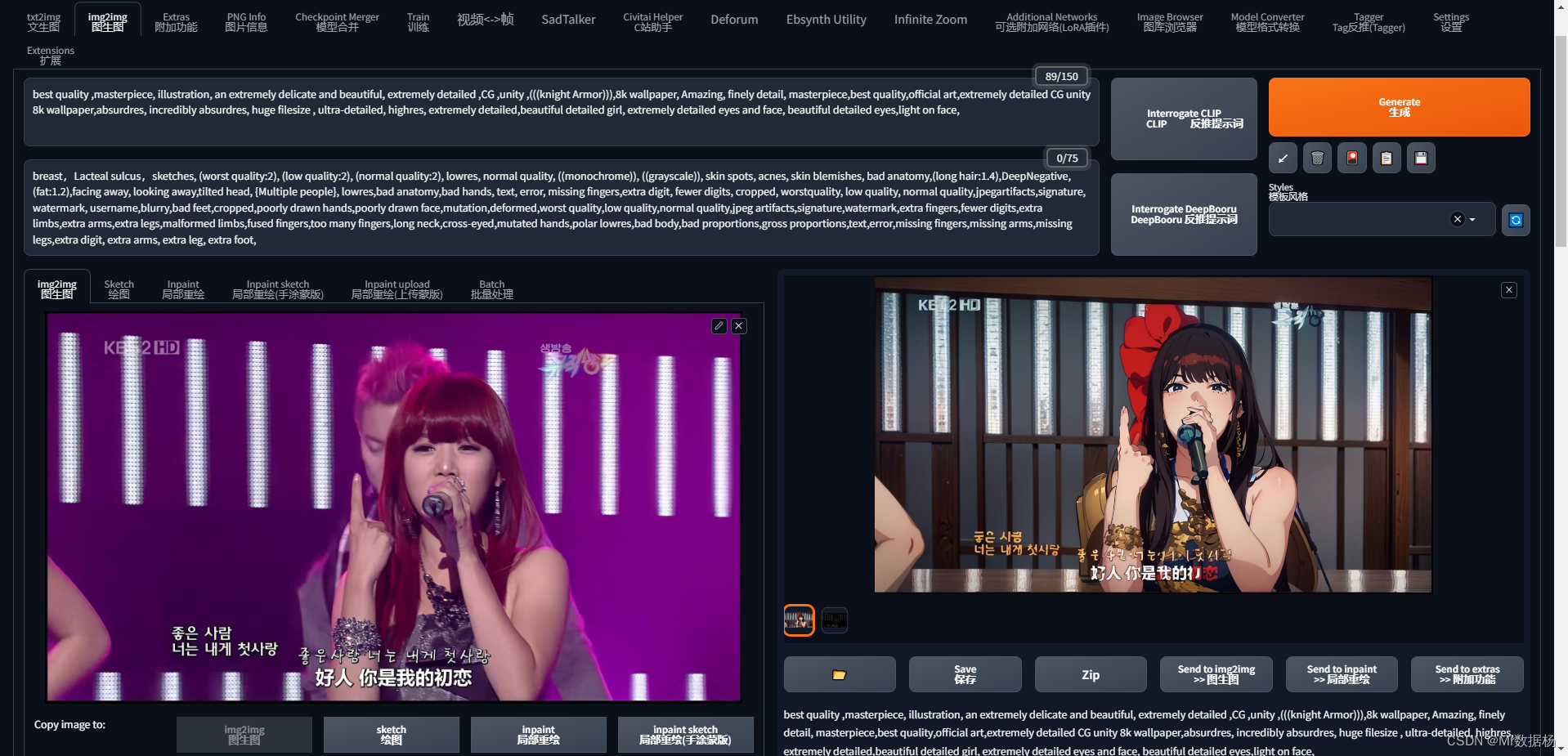
그러나 여전히 손발이 부러지는 경우가 있을 것이며, ADetailer에서 손발 수리 기능을 설정해야 합니다.
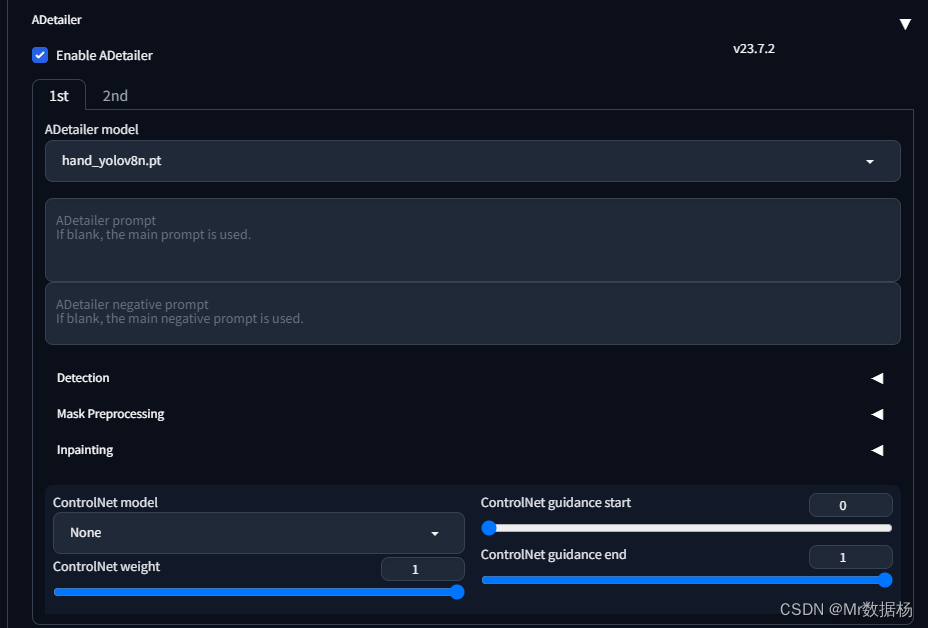
설정 후 Generate를 다시 클릭하면 효과를 볼 수 있습니다.
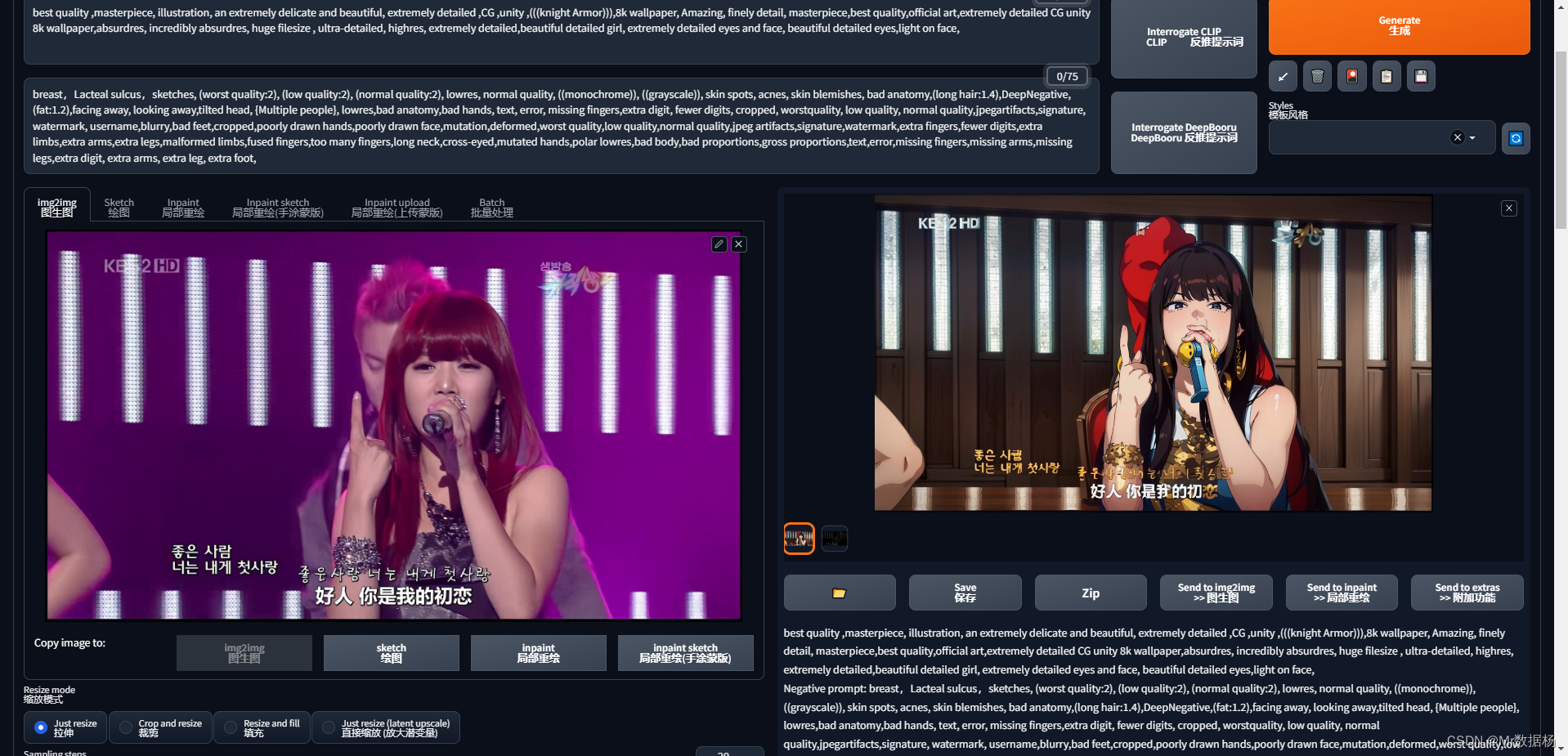
여기에서 여러 번 생성하여 만족스러운 종자 종자를 기록하고 종자를 저장하고 수정하는 것을 잊지 마십시오.
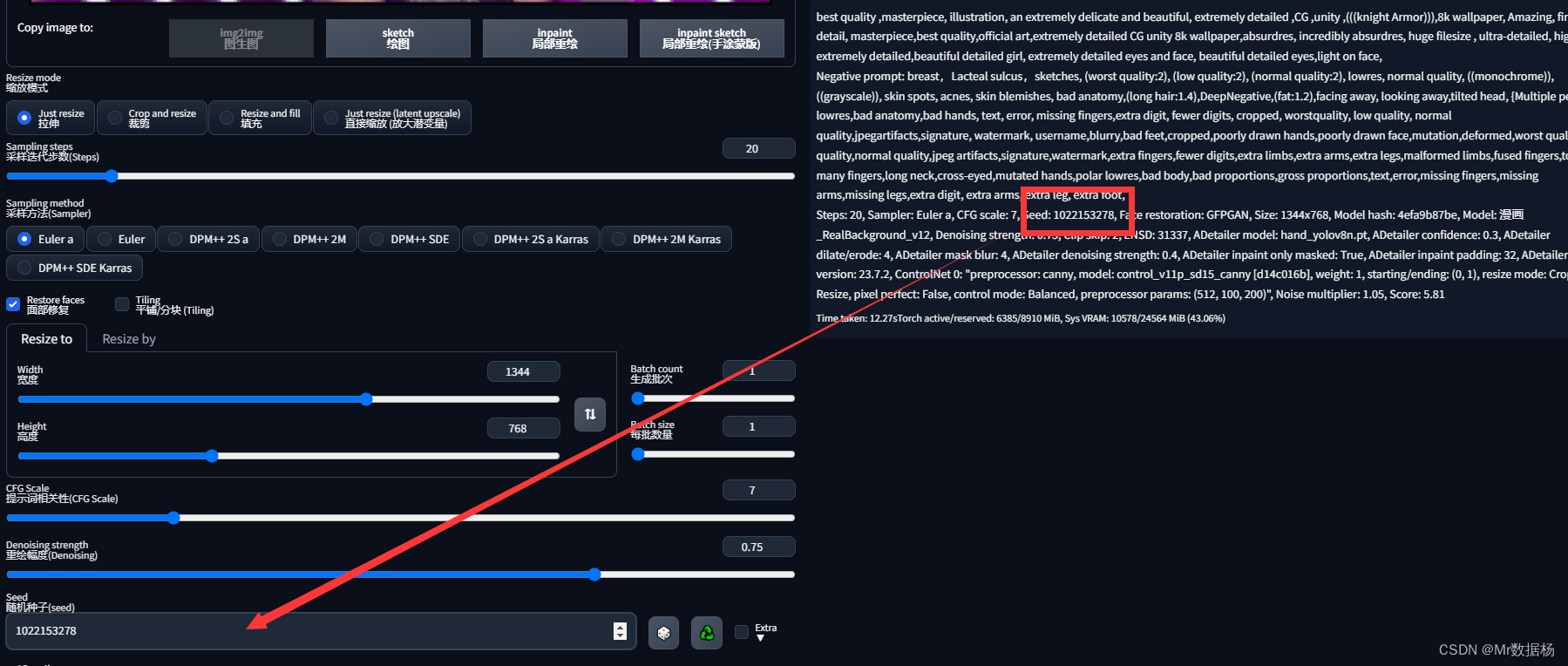
전처리가 완료되더라도 다음을 클릭하면 Batch批处理选项卡ControlNet에 있는 이미지가 먼저 분기되어야 합니다. 그런 다음 그림 입력 및 출력 경로를 선택합니다.
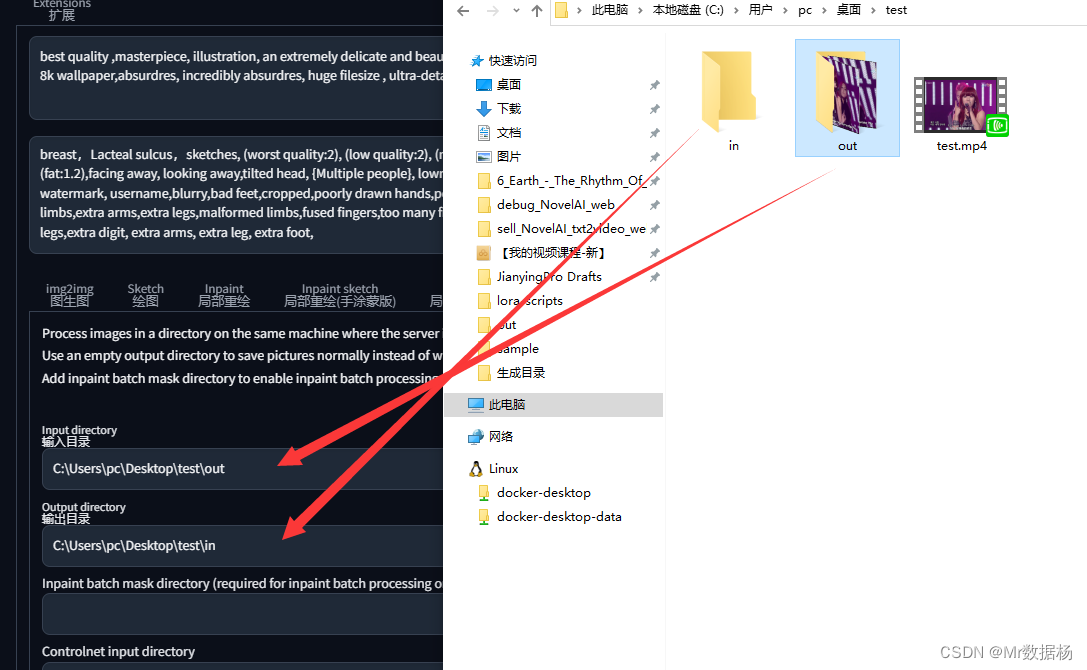
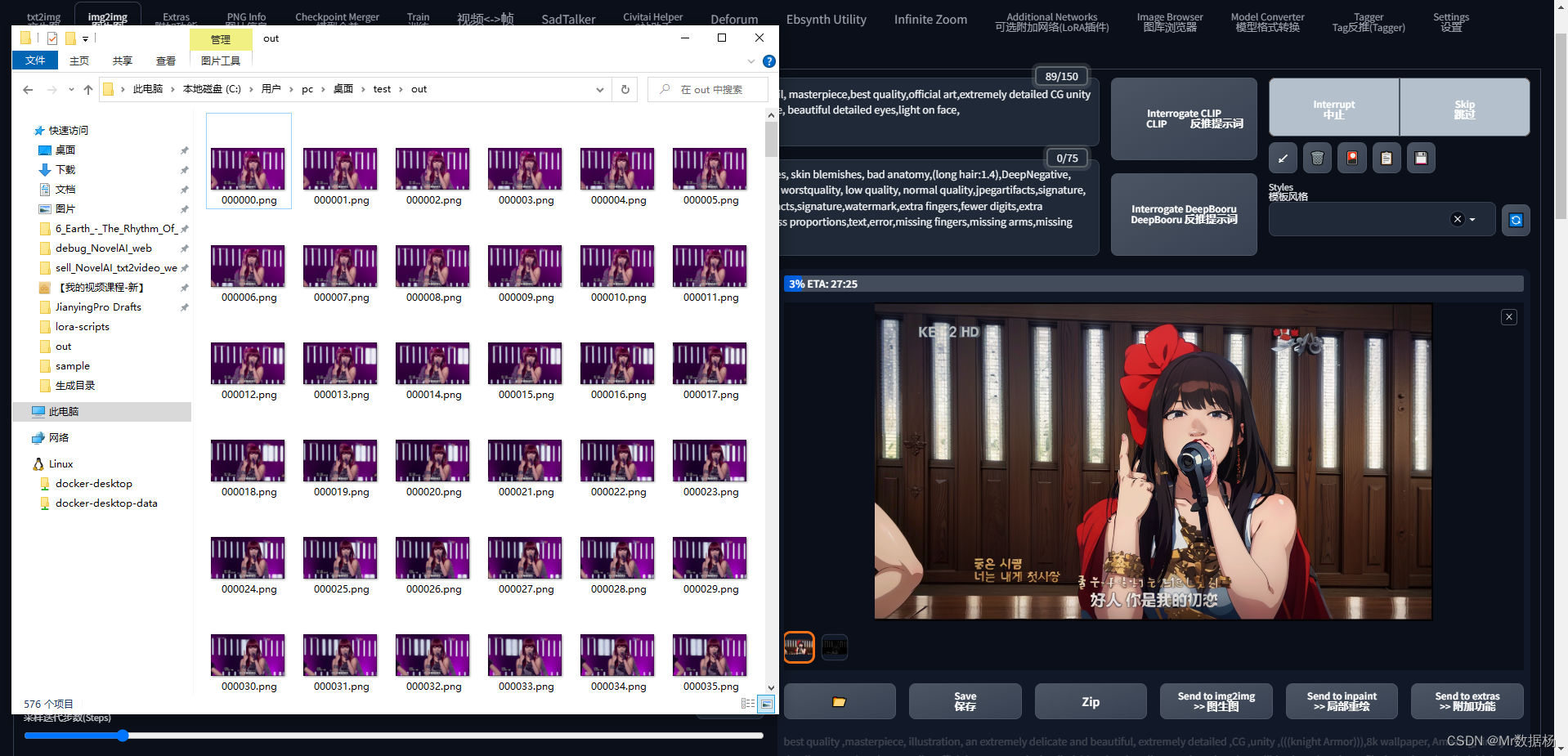
이 작업은 out 폴더의 이미지를 일괄 처리하고 in 폴더에 저장한 다음 실행을 클릭하여 이미지를 하나씩 처리하는 것입니다. 이 과정은 그래픽 카드가 좋지 않은 사람들에게 더 고통스럽습니다. 576장의 사진을 처리하는 데 30분이 걸립니다.
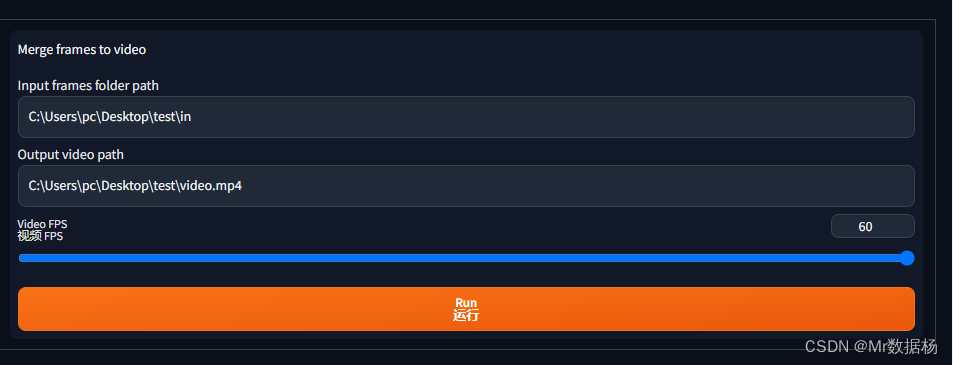
모든 이미지가 생성되면 in 폴더에서 접미사가 붙은 외곽선 이미지를 삭제합니다 -1.png. 비디오 프레임 스왑 탭으로 돌아가서 스플 라이스가 필요한 이미지 디렉토리, 즉 SD로 그린 그림 폴더와 비디오가 저장되는 디렉토리를 설정하고 원본 비디오에 따라 비디오 프레임 번호를 선택하십시오. 프레임 번호.

실행을 클릭하면 테스트 폴더 아래에 video.mp4 비디오가 생성되며 이것이 우리가 원하는 결과입니다.
생성된 영상은 깜박임 문제가 발생하며, 이 문제를 해결하기 위해 지속적으로 콘텐츠를 업데이트하겠습니다.
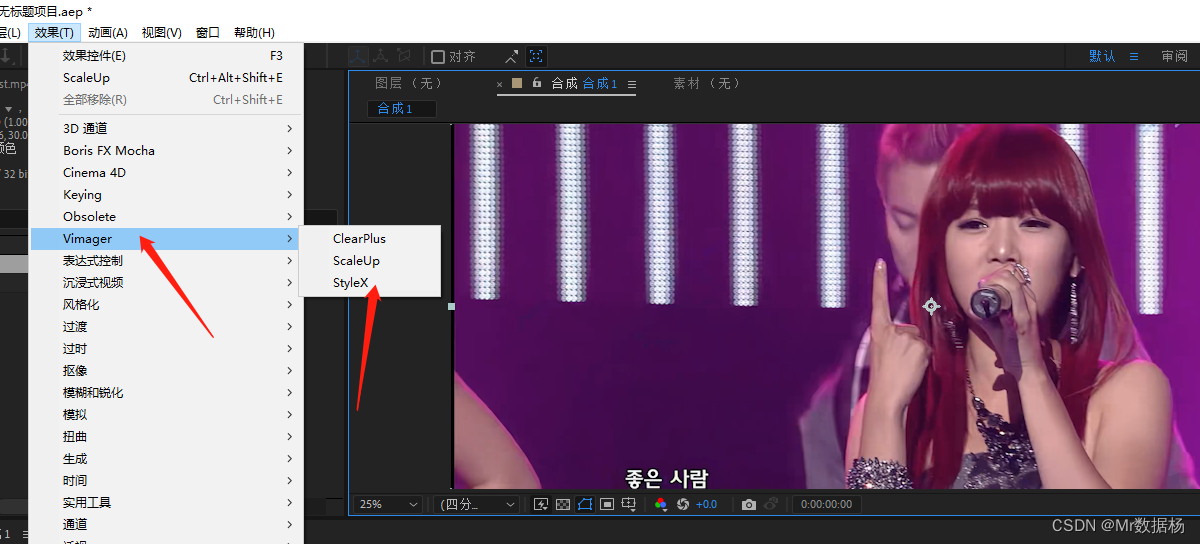
After Effects 방법
AE 변환을 사용하려면 StyleX 플러그인을 다운로드해야 합니다.
그런 다음 미리 볼 매개변수를 설정합니다.
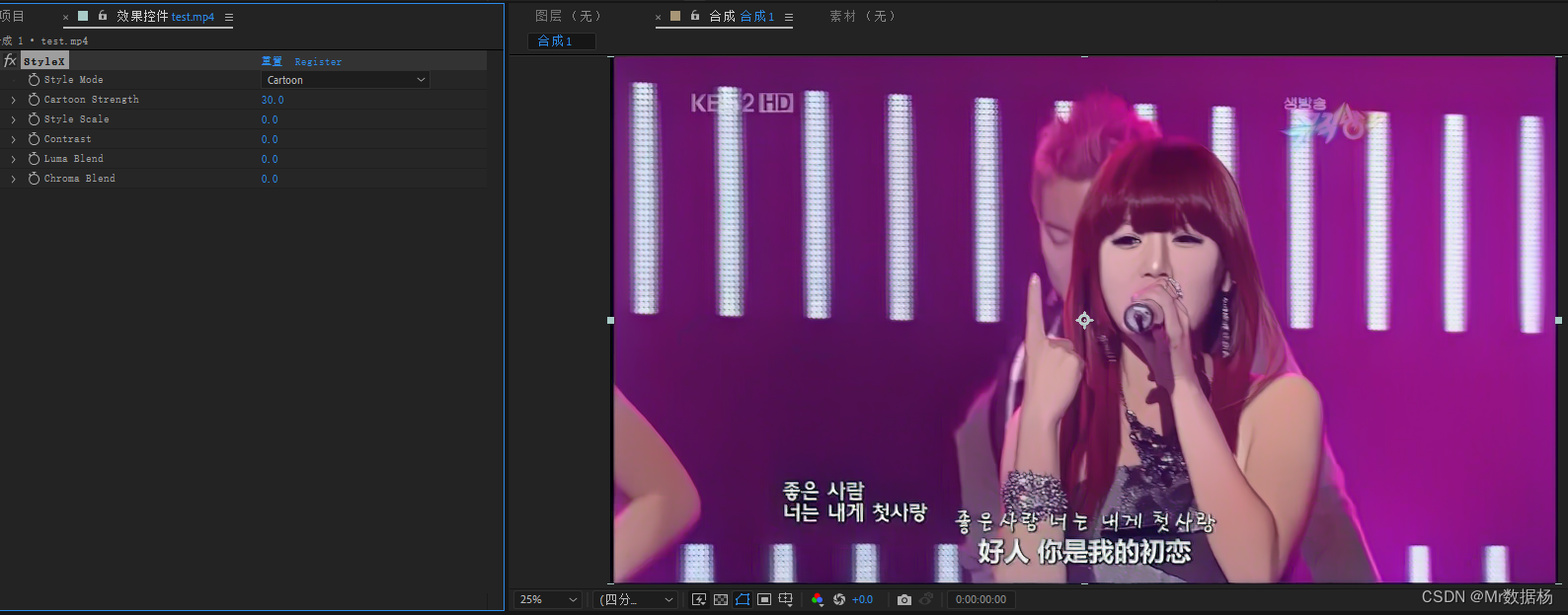
전반적인 효과는 실제로 SD와 비교할 수 없으며 간단한 필터가 처리에 사용된다는 것을 이해할 수 있습니다. 마지막으로 렌더링 대기열 출력에 추가합니다.
엡신스 방법
Ebsynth는 주로 SD에서 생성된 애니메이션 비디오의 깜박임 문제를 처리할 수 있습니다.
자식 설치 주소https://gitcode.net/ranting8323/ebsynth_utility.git
SD 확장 프로그램에 이 URL을 입력하여 설치하십시오. 설치가 완료된 후 SD를 다시 시작하면 탭이
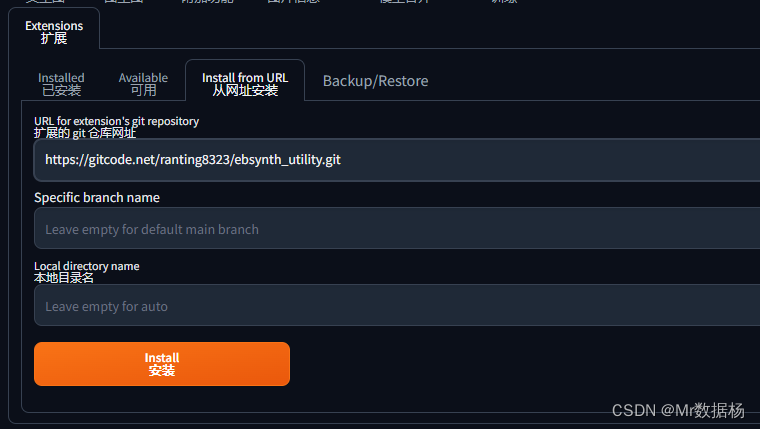
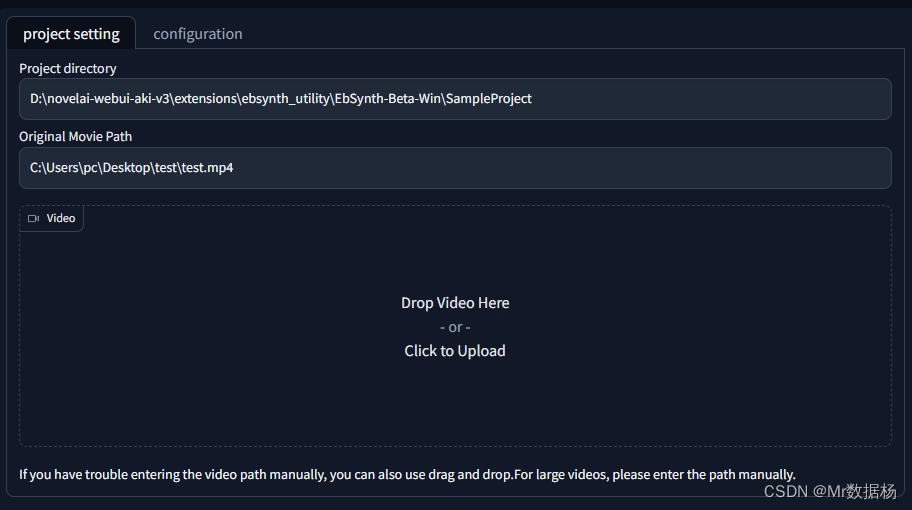
나타납니다 . 시스템에 따라 설치 프로그램을 다운로드하려면 Ebsynth 공식 웹사이트 에 들어가십시오 . 그런 다음 확장 디렉토리에서 엽니다. SD 처리 방법과 동일하게 먼저 비디오를 프레임 단위로 일괄 변환하고 먼저 비디오를 드래그한 다음 키 프레임을 추출할 디렉토리를 지정합니다. 비디오의 디렉토리는 수동으로 입력할 수도 있습니다.Ebsynth Utility
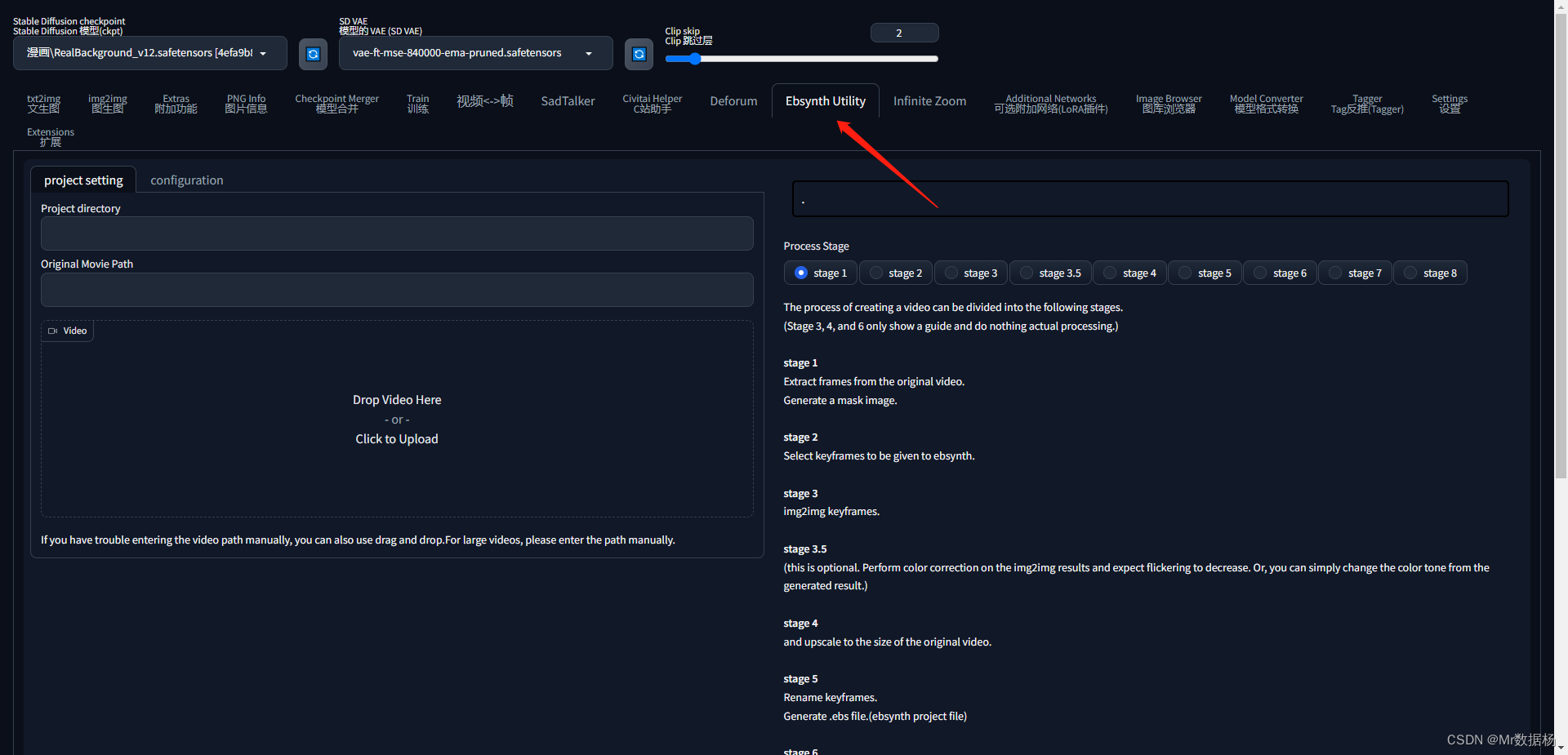

configuration선택 중 stage1. 원본 비디오 크기를 유지하려면 기본적으로 -1을 선택합니다. 다른 것들은 작동할 필요가 없으며 생성을 클릭합니다.
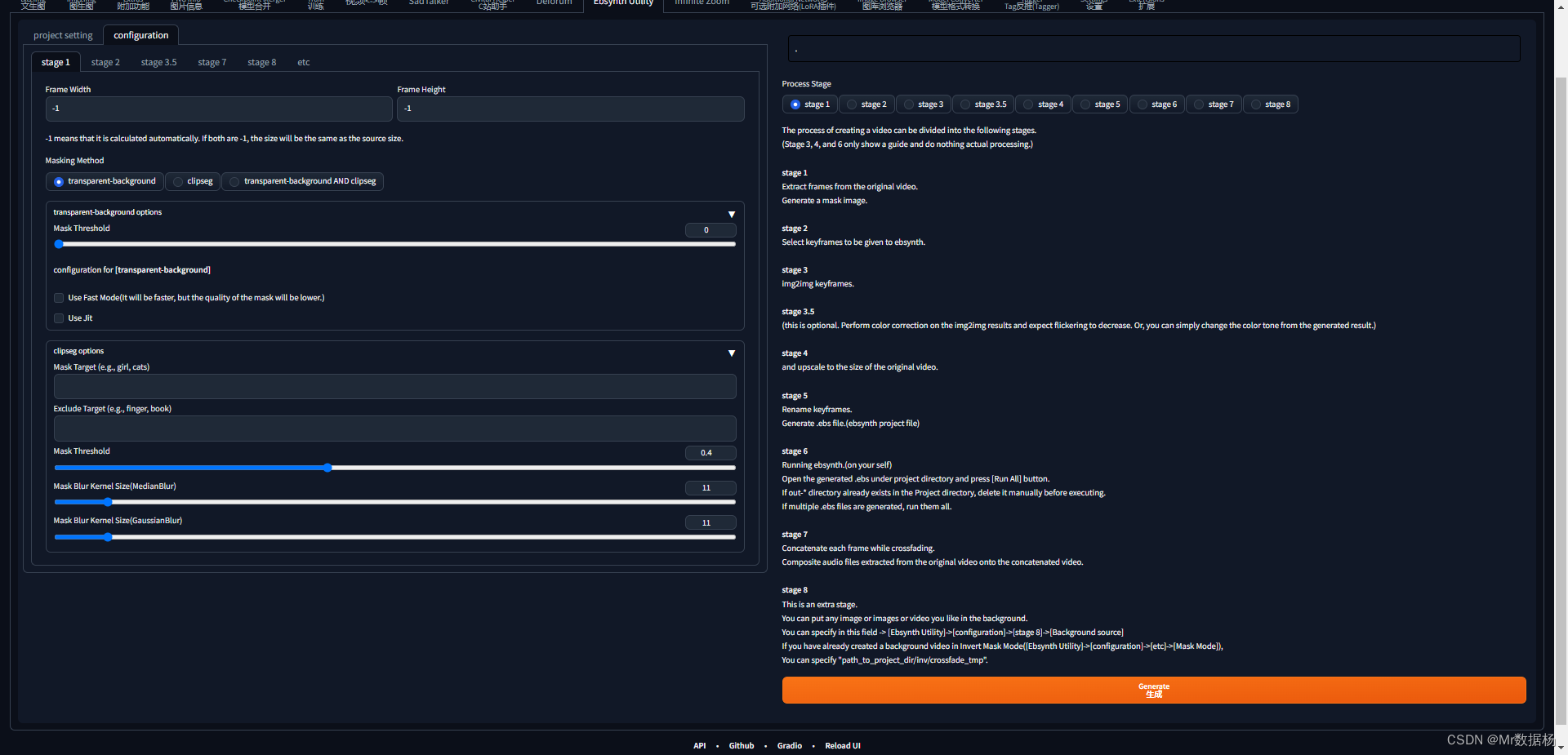
프로젝트 폴더 아래에 자동으로 video_frame폴더가 생성되고, 프레임별로 생성된 사진이 이 폴더에 저장되며 효과는 이전 비디오 프레임 변환과 동일합니다. 선택
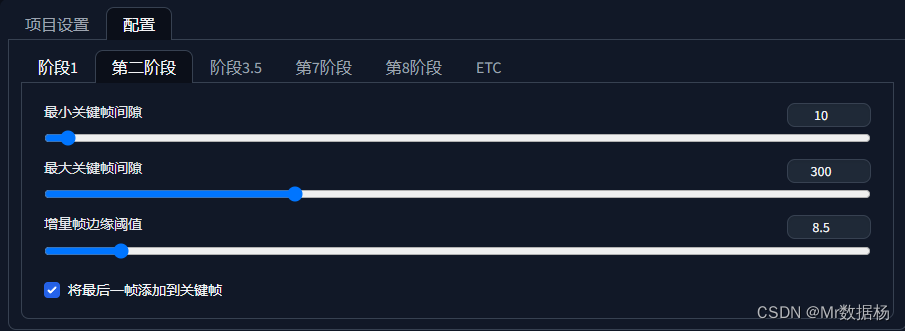
중 . 이 단계는 추출된 키 프레임을 간격에 따라 Ebsynth로 추출하는 단계이며, 키 프레임 간격은 프레임에 따라 간격을 추출한 후 Generate를 클릭합니다. 키프레임 설정 구성에 따라 키프레임 키를 로 추출합니다 . SD 페인팅으로 돌아가서 Stable Diffusion 방법과 같은 방식으로 이 그림을 일괄 다시 그립니다. 생성된 이미지는 img2img_key에 저장됩니다. 선택 영역 에서 마스크를 추출 할지 여부.configurationstage2
video_key

img2img
configurationstage3.5
configuration선택 에서 이미지를 확대하거나 처리하지 않을 수 있습니다 stage4.Extras
키프레임으로 처리된 이미지 파일을 에 배치하도록 configuration선택 하고 폴더가 없으면 수동으로 생성합니다. 그런 다음 빌드를 실행하여 해당 파일을 생성합니다.stage5img2img_upscale_key.ebs
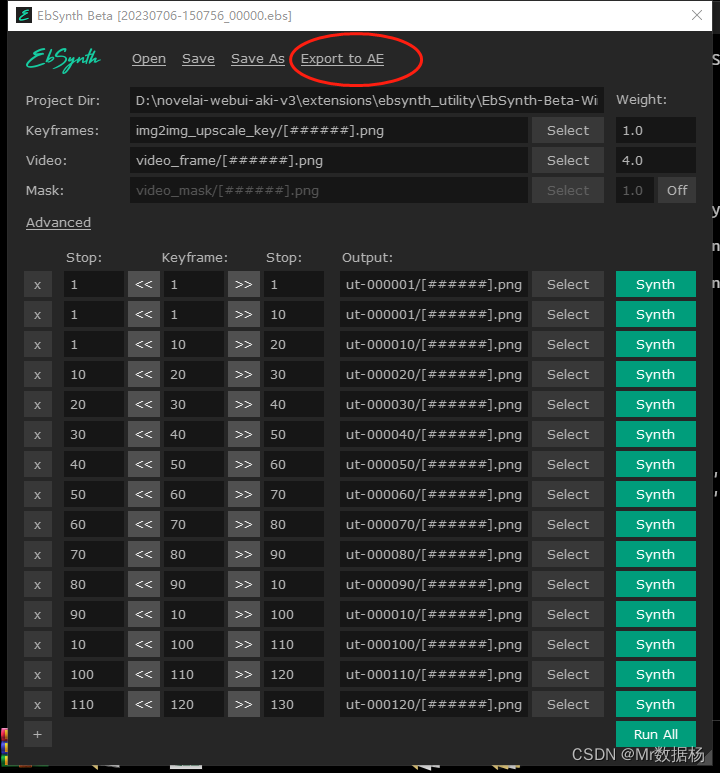
열기 를 configuration선택한 후 해당 파일을 순서대로 드래그 앤 드롭합니다 . 마스크를 닫고 을 클릭한 다음 키프레임이 생성될 때까지 기다립니다. 키프레임을 생성하는 처리된 배치 이미지입니다.stage6EbSynth.exe.ebsonRun All
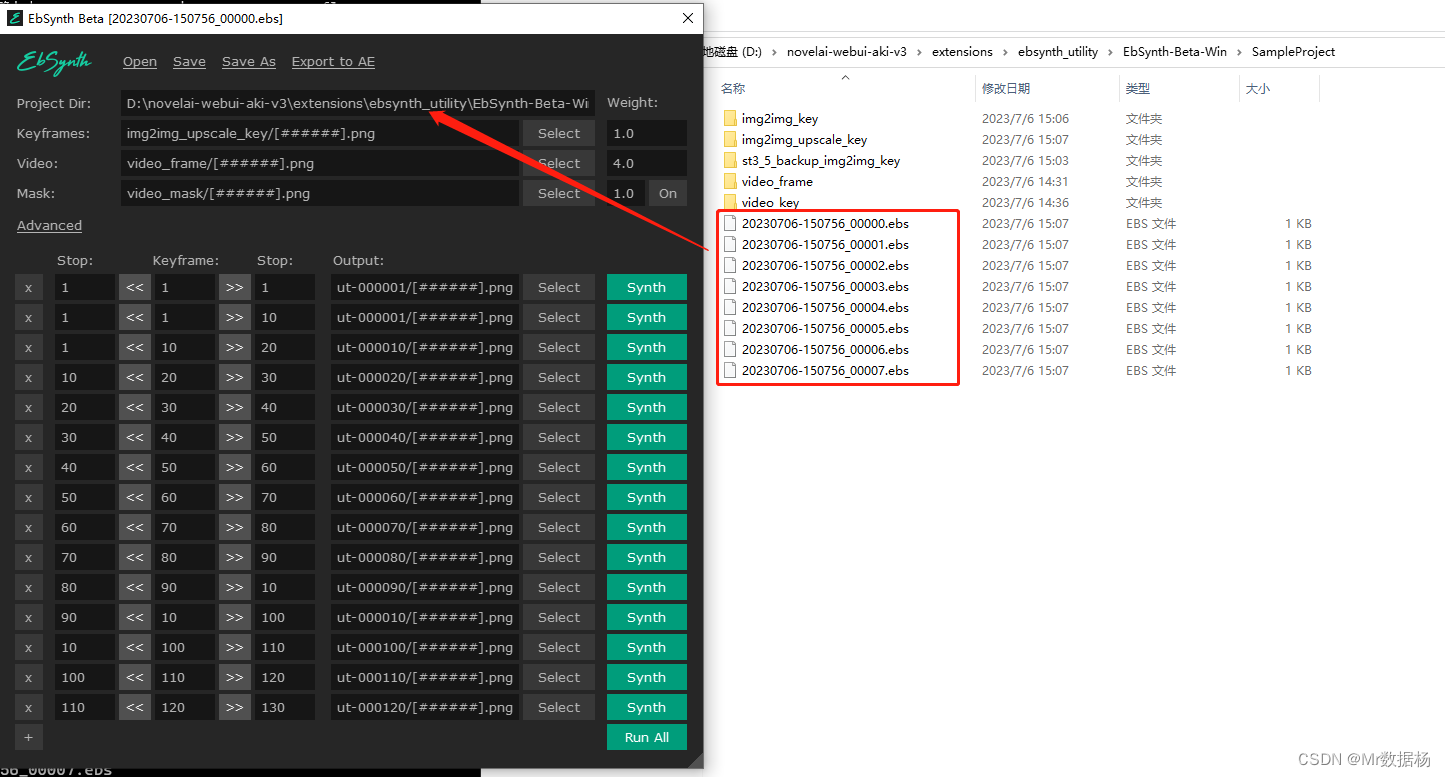
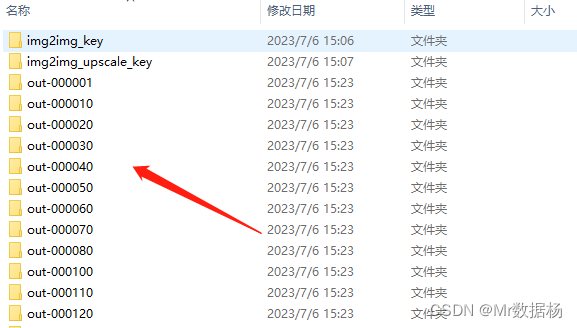
일괄 처리 후 클릭하여 Export to AE합성합니다.