Frases comumente usadas em bancos de dados relacionais e alguns agrupamentos de conhecimento de banco de dados
- (1) Declarações de banco de dados comuns
-
- 〇, classificação sql
- 1. O CRUD mais básico
- 2. Adicione condições e operações, consulte por grupo ou janela
- Três, consulta de várias tabelas
- 4. Consultar os dados da árvore associados ao campo PID
- 5. Converta o valor de retorno de acordo com a condição (caso quando)
- #Outras condições de consulta
- #Construir tabela, alterar tabela, criar visualização e adicionar comentários
- #Modo de construção e alterar permissões
- #Importar e exportar biblioteca
- # Tabelas de sistema comumente usadas no banco de dados
- # algumas funções
- #Mesas temporárias
- # acionar processo/pacote
- #MySql Instalação e redefinição e redefinição de senha
- (2) Conhecimento básico de banco de dados
(1) Declarações de banco de dados comuns
Crie um ambiente de teste
Banco de dados online http://sqlfiddle.com/
Conhecimento introdutório primário para o background: [Tutorial de banco de dados relacional "Aprenda MySQL com Sun Xinghua" [Fim do capítulo primário] - 哔哩哔哩] https://b23. tv /nStbOCd
〇, classificação sql
DDL (Data Definition Language
): Linguagem de definição de dados, usada para definir objetos de banco de dados: bibliotecas, tabelas, colunas, etc.;
DML (Data Manipulation Language): Linguagem de manipulação de dados, usada para definir registros de banco de dados (dados);
DCL (Data Control Language): Data Control Language, usada para definir direitos de acesso e níveis de segurança;
DQL (importante) (Data Query Language): Data Query Language, usada para consultar registros (dados). Observação: a instrução sql termina com;
1. O CRUD mais básico
Link: CRUD de declarações comuns do banco de dados
select 'A'||name||'A' ana, concat('A',name) an, lastname, firstname from persons
insert into persons values ('gates', 'bill', 'xuanwumen 10', 'beijing')
update person set firstname = 'fred' where lastname = 'wilson'
delete from person where lastname = 'wilson'
--子查询
select a.name,a.age from (select t.name,t1.age from workerid t left join workerinfo t1 on t.id=t1.id) a --表
Select * from People where PeopleAddress = (select PeopleAddress from People where PeopleName = '赵云') --值
1 Desduplicação de campo
Se houver dados históricos em uma tabela, como
(meu programador masculino 100.000 no ano passado)
(meu programador masculino 200.000 este ano)
para o campo de nome, se você não quiser que apareça repetidamente no resultado, então
select distinct name, sex from worker;
2 mais condições de paginação
1,
habilidades de uso do oracle wording rownum
select * from table1 where rownum <=20;
A maneira de escrever oracle, em particular, rownum<=1 pode ser usada para verificar se há dados na tabela. Ao escrever uma consulta simples de tabela única, você não pode usar > (um valor maior ou igual a 1) >= (um valor maior que 1) ou = (um valor maior que 1) para rownum.
Como rownum é uma pseudocoluna, ele é usado como o valor incremental da linha de registro dos resultados retornados que atendem às condições da consulta. Somente os resultados que atendem às condições da consulta serão contados como uma linha e o rownum retornado será aumentado em 1 , ou seja, a condição rownum>1 é usada para descobrir O resultado rownum não pode ser maior que 1 e é descartado. Conforme escrito abaixo, o resultado da contagem é 0.
select count(*)from people where rownum >1;
Obviamente, >0 retorna o número correto de linhas.
Se você deseja verificar a coluna 5, pode usar o seguinte método
select object_id,object_name
from (select object_id,object_name, rownum as rn from t_test1)
where rn = 5;
Para consultar as colunas 6 a 10, use o seguinte método
select * from
(
select a.*, rownum as rn from css_bl_view a
where capture_phone_num = '(1) 925-4604800'
) b
where b.rn between 6 and 10;
Também é preciso ficar atento ao uso do order by: para o order by primary key, é primeiro ordenar e depois calcular ROWNUM. Mas se o order by não for a chave primária, o Oracle primeiro buscará os registros que satisfazem a condição rownum de acordo com o local de armazenamento físico (rowid), ou seja, os 5 primeiros dados no local físico e, em seguida, classificará os dados de acordo com o campo Ordenar por. Portanto, precisamos fazer algum processamento na escrita, como segue
select object_id,object_name
from (select object_id,object_name from t_test1
order by object_name)
where rownum <= 5;
--主键是object_id,排序用非主键object_name时
2. Método de escrita Mysql - use limite
de consulta de paginação MySql
# 放在查询语句的末尾
LIMIT 【位置偏移量off,】 行数n
--位置偏移量off值可不写,则取前n行。相当于每n行为1页时,取第1页。
Observe que off é o número de linhas ignoradas, que pode ser 0, e a consulta retorna resultados a partir da linha off+1.
20 linhas por página, pegue a página 3:
SELECT
employee_id,
last_name
FROM
employees
LIMIT 40, 20 ;
Fórmula de consulta de paginação:
(número da página atual-1) * o número de entradas por página, o número de entradas por página
ocupa as 32ª e 33ª linhas
SELECT
*
FROM
employees
LIMIT 31, 2 ;
Nova forma de escrever MySql8.x
SELECT
*
FROM
employees
LIMIT 2 OFFSET 31 ;
3 campos são concatenados em um campo
concat(campo 1, campo 2, ...) como novo campo
use || : col1||'string arbitrária'||col2 ...
4 campos deixados preencher
lpad (campo a, 8, '*') Preencha vários asteriscos para tornar o comprimento da string 8
5 Interceptar
substr (campo a, 3, 3) Interceptar 3
substr (campo a, 3) do terceiro ao final
2. Adicione condições e operações, consulte por grupo ou janela
Em aplicações práticas, geralmente adicionamos instruções ou funções como classificação, agrupamento, consulta de ponteiro e cálculo para atingir o objetivo de consultar os dados necessários.
SQL Server: Oito, consulta condicional: onde, operador de comparação, subconsulta, instrução condicional
select * from People where PeopleAddress in('武汉','北京')
select * from People where PeopleSalary >= 10000 and PeopleSalary <= 20000
select * from People where PeopleSalary between 10000 and 20000
select * from People where PeopleSalary <> 10000 --不等于
select top 5 * from People order by PeopleSalary desc --前5行
select top 10 percent * from People order by PeopleSalary desc --前百分之10
select * from People where PeopleAddress is not null
//获取时间的月 select to_char(sysdate,'dd') as nowDay from dual
查询消费者总消费额
select customer,sum(cost) from costrecord
where year>2021 and type='厨卫'
group by customer
order by viplevel
查询消费者总消费次数
select customer,count(cost) from costrecord
group by customer order by viplevel
agrupar por (agrupamento), ordenar por (classificar), onde (condição)
explica a relação entre agrupar agrupar por, ordenar por e condição onde
Método de escrita: group by deve estar localizado depois de where e antes de order by.
Isso é de > onde > agrupar por > tendo > ordem
- group é geralmente usado junto com order by, execute group by primeiro e depois execute order by.
- Depois de usar o group by, se quiser filtrar novamente, pode usar o have, ou seja, ter é filtrado após o agrupamento.
- Usado junto com where: executa primeiro a condição do filtro e depois agrupa.
- Tendo opera em um conjunto de dados; where opera em linhas.
Função de janela PARTITION BY() introdução da função
partição por e grupo por partição por só pode agrupar e classificar
determinados campos com base na retenção de todos os dados e não agregará dados semelhantes, que são usados para filtrar o intervalo de cálculo ; agrupar por apenas retém Os campos envolvidos no agrupamento e o resultado da função de agregação
# 查询每种商品的id,name,同类型商品数量(ps:感觉这个应用的有点问题)
select id,name,count(*) over (partition by type) from product;
# 查询每个城市每个类型价格最高的商品名称
select
name,
price, --这里的列应该是address?
type,
max(price) over (partition by address,type) as 'max_price'
from product;
Detalhes da função da janela sobre (partição por _ ordem por _ )
1. Significado da palavra-chave:
partição por: agrupar por um determinado campo, semelhante a agrupar por, mas não agregará dados semelhantes, usado para filtrar a
ordem do intervalo de cálculo por: após agrupar Classificar
LINHAS de acordo com um campo: dimensão física da linha, faixa de cálculo do filtro.
RANGE: De acordo com o valor da coluna, para filtrar o intervalo de linhas
CURRENT ROW: linha atual
UNBOUNDED PRECEDING: todas as linhas acima da linha atual
UNBOUNDED FOLLOWING: todas as linhas abaixo da linha atual
__ PRECEDING: __ linha acima da linha atual (__ pode ser um número ou uma expressão)
__ SEGUINTE: __ linha abaixo da linha atual (__ pode ser um número ou uma expressão)
2. Use funções de janela para classificar e combinar funções agregadas
(após agrupar e classificar, calcule pela soma da janela + linhas/intervalo)
ps: O método de escrita a seguir é possível, mas a interpretação do significado parece um pouco problemática, por isso não tentei.
-- 根据用户id分组,分数排序,当前行的sum()
sum(sroce) over(partition by user_id order by sroce rows current row) as sum1
-- 根据用户id分组,分数排序,从 组内首行? 到当前行的sum()
如果解释没错,那在统计每个人截止不同时间的总收入时可用
sum(sroce) over(partition by user_id order by sroce rows between 1 preceding and current row) as sum4
-- 根据用户id分组,分数排序,当前行且 相邻上下? 分数相等的sum()
sum(sroce) over(partition by user_id order by sroce range current row) as sum2
--根据用户id分组,分数排序,当前行且 相邻上下? 当前分数-1 和 当前分数+1之间
sum(sroce) over(partition by user_id order by sroce range between 1 preceding and 1 following) as sum3
3. Use a função de janela para classificar e obter o número de série do grupo.
O número de série do grupo
- se houver dois empatados na pontuação mais alta do grupo
--顺序排序,顺序为1,2,3
ROW_NUMBER() over (partition by user_id order by score) as rn1
--并列排序,跳过重复序号,顺序为1,1,3
RANK() over (partition by user_id order by score) as rn2
--并列排序,不跳过重复序号,顺序为1,1,2
DENSE_RANK() over (partition by user_id order by score) as rn3
Ao usar a função row_number() over(), a execução do agrupamento e classificação em over() é posterior a where e group by, mas não posterior à execução de order by.
Outras referências para funções de janela 1
Outras referências para funções de janela 2
Três, consulta de várias tabelas
soletrar junção esquerda
select
a.schoolid,b.schoolname,b.schoolorder,
a.teacherid,c.teachername,d.teachersalary
from
schoolteacher a
left join school b on a.schoolid=b.schoolid
left join teacher c on a.teacherid=c.teacherid
left join teacherinfo d on a.teacherid=d.teacherid
Composição onde (+) --oracle
esquerda e direita se juntam no oracle
--(+)在哪一边,则返回另一边所有的记录。(+)在右面是左连接
select
a.schoolid,b.schoolname,b.schoolorder,
a.teacherid,c.teachername,d.teachersalary
from
schoolteacher a
school b
teacher c
teacherinfo d
where
a.schoolid=b.schoolid(+) and
a.teacherid=c.teacherid(+) and
a.teacherid=d.teacherid(+)
Ortografia union / union all
veja a diferença entre union e union all
4. Consultar os dados da árvore associados ao campo PID
Consulte o nó atual e todos os nós filhos:
SELECT * FROM YW_XYZB
CONNECT BY PRIOR ID = PARENT_ID
START WITH ID = '***';
Consulte o nó atual e todos os nós pais:
SELECT * FROM YW_XYZB
CONNECT BY PRIOR PARENT_ID = ID
START WITH ID = '***'
5. Converta o valor de retorno de acordo com a condição (caso quando)
caso quando então senão terminar
select name ,
(case when age>65 then 2 when age<35 then 0 else 1 end) as type
from workerinfo;
Leitura recomendada: SQL- case when then else end use resumo da experiência
SELECT a.*,
CASE
WHEN a.age BETWEEN 0 and 20 THEN '青年'
WHEN a.age BETWEEN 20 and 40 THEN '中年'
ELSE '非人类'
END AS '描述'
FROM c_20170920 a
select country,
sum( case when sex = '1' then
population else 0 end), --男性人口
sum( case when sex = '2' then
population else 0 end) --女性人口
from table_a
group by country;
Análise comparativa do caso de decodificação exclusivo da Oracle quando e decodificar
#Outras condições de consulta
1. Consulta difusa como, qualquer número de caracteres na frente do campo num na tabela de pesquisa, o caractere do meio a e um caractere depois dele (vários _ significa quantos caracteres existem)
select num from table1 where num like '%a_';
2. Especifique o intervalo a ser consultado e pesquise o valor fornecido
select * from table1 where id in ('11','13','a1');
3. O valor vazio é nulo
4. O valor do meio está entre 1 e 5. Se inclui o limite depende do banco de dados
5. <> não é igual a e ou não e ou não (escrita sugerida)
6. O dia chinês de a semana pode ser ordenada por instr ('sexta, quinta, quarta', dia) Desta forma, instr retorna a posição de param2 em param1, contando a partir de 1, e retornando 0 se não for encontrado.
#Construir tabela, alterar tabela, criar visualização e adicionar comentários
criar ou substituir
comentário em
#Modo de construção e alterar permissões
??
concessão
#Importar e exportar biblioteca
imp/impdp e exp/expdp
# Tabelas de sistema comumente usadas no banco de dados
user_tables user_tab_columns user_tab_cols
user_tab_comments user_col_comments
Obtenha o nome da tabela e o comentário da tabela de propriedade do usuário atual
select a.table_name as name,b.comments as remark
from (select table_name from user_tables ) a
inner join (select table_name,comments from user_tab_comments) b
on a.table_name=b.table_name
order by a.table_name
# algumas funções
SYSTIMESTAMP SYSDATE TRUNC ROUND dbms_random(oracle) to_char to_date
#Mesas temporárias
com queryname1 como (instrução de consulta SQL) selecione * de queryname1;
# acionar processo/pacote
um pouco
#MySql Instalação e redefinição e redefinição de senha
MySql install 5.x
MySql install 8.x
mysql redefinir banco de dados
mysql redefinir banco de dados 2
Mysql esqueceu a senha e redefinir a senha
(2) Conhecimento básico de banco de dados
1. Princípios de Design de Banco de Dados (Paradigma)
Explicação detalhada dos seis paradigmas do banco de dados
sobre se os paradigmas devem ser seguidos:
https://www.bilibili.com/video/BV1J94y1y75k/?spm_id_from=333.337.search-card.all.click&vd_source=6debe81be6c46d072d7be3a28fc4790e 
Cada paradigma é progressivo em turno, e se atender a este último, deve estar alinhado com o anterior.
"Dependência" neste contexto refere-se à existência de uma função discreta y=f(x1, x2).
- 1NF é uma restrição atômica em atributos, e os atributos são indivisíveis
- 2NF é a restrição de exclusividade do registro. Em termos de implementação, deve haver uma chave primária (composta por um ou mais atributos) na tabela e os atributos não primários devem depender da chave candidata
- 3NF significa que cada atributo não principal não depende de outros atributos não principais, atributos não principais não podem ser informações derivadas de outros atributos não principais e devem estar diretamente relacionados ao atributo principal (removendo a redundância de atributos não principais informações de atributos)
- O BCNF é um atributo não-chave e não pode ter dependências funcionais parciais do código candidato, ou seja, não pode determinar o valor do atributo não-chave tomando apenas parte dos atributos em um código candidato (removendo a redundância do atributo principal informações de atributo na tabela). "Dependência funcional parcial" significa que "um determinado valor de atributo pode depender de uma parte dos atributos do grupo de atributos em vez do todo".
Em relação à melhoria do BCNF para 3NF:
o resultado de seguir o BCNF é que os códigos candidatos na tabela são determinados exclusivamente e usados como a chave primária da tabela, e os códigos candidatos do subconjunto não podem ser separados dos códigos candidatos para não candidatos códigos nos quais confiar. Caso contrário, na chave primária composta por vários atributos, deve haver uma correspondência um-para-um entre os atributos, ou o valor do atributo primário não tem sentido no negócio descrito na tabela. atributos primários redundantes são descritos nesta tabela.Os dados de negócios devem ser informações redundantes e apenas um dos atributos deve ser retido. Também é possível que os dados dessa correspondência um-para-um não possam ser totalmente refletidos nos dados da tabela devido ao volume insuficiente de dados. Não importa como você olhe, deve ser uma tabela relacional separada e a chave primária de a tabela de negócios deve ser uma coleção de atributos o menor possível.
Estendendo a situação de "correspondência um-para-um de atributos na chave primária" que acabamos de discutir, pode-se pensar em correspondência um-para-muitos. Acho que esse "muitos" não deveria ser um atributo na chave primária, mas um não - atributo primário. - 4NF remove muitos-para-muitos. Eu pensei sobre uma situação, se as várias orientações em "orientação para compras" K tiverem dependências multivaloradas não triviais com "ocupação" A, "interesse" B, "idade" C, etc. -many relacionamento, então não deve aparecer em uma tabela.
- 5NF realmente não entendi.
Convenção de nomenclatura recomendada:

2. Minha experiência e compreensão do design e uso de tabelas de dados relacionais
De acordo com minha experiência (divisão não universal), ao projetar tabelas, existem tabelas de códigos, tabelas de relacionamentos, tabelas de registros etc.
Tabela de códigos: A tabela de códigos no sentido estrito geralmente armazena informações que podem extrair o valor do código (a tabela é composta de código, nome e número de série), e a tabela de situação básica armazena basicamente informações relacionadas fixas e inalteradas. Por exemplo, o armazém com código 001 está localizado em Pequim com código 0101. Distrito, capacidade 1023 e assim por diante. A tabela de códigos no sentido amplo pode combinar a tabela de códigos no sentido estrito com a tabela de situação básica e usar as descrições físicas basicamente fixas, como posição e capacidade, como as colunas estendidas da tabela de códigos para reduzir o número de tabelas.
Tabela de relacionamento: armazena relacionamentos de associação de variáveis. Descrever a relação de associação entre os atributos da tabela de códigos (associar vários atributos principais da tabela de códigos em uma tabela, destacando uma relação de associação, em vez de usá-los como atributo principal/código candidato de outra tabela como identificação de dados). Quando os atributos básicos não mudam, o relacionamento correspondente pode mudar, mas geralmente o número de entradas nesse relacionamento não muda muito. O relacionamento de associação geralmente reflete as características de negócios. Por exemplo, a tabela de relacionamento do gerente de depósito reflete a característica de negócios de que o depósito é gerenciado por pessoas e a tabela de relacionamento de marca de blog reflete a característica de negócios da divisão de domínio.
Tabela de registro: use atributos múltiplos ou atributos únicos como a chave primária (o único código candidato aceitável para uma tabela), registre o estado atual relevante ou mude o estado, com o passar do tempo, os dados da chave não primária mudarão (tabela de status ) ou adicionar novas linhas Registrar novos dados (tabela de alteração de estado).
Análise mais específica:
tabela de códigos:
como tabela de códigos de armazém. Geralmente, o nome completo do armazém não será repetido ou alterado, mas ainda pode mudar; e o nome é mais longo e o nome do armazém de armazenamento repetido ocupa mais espaço. Portanto, a tabela de códigos é projetada e os códigos são usados para se referir a armazéns em outras tabelas. Latitude e longitude, capacidade (100 metros quadrados e 101 metros quadrados são valores armazenados diretamente, armazéns grandes e armazéns pequenos são valores de código para armazenar os níveis de capacidade do armazém) podem ser considerados como informações/atributos físicos associados fixos de armazéns e podem ser colocados na tabela de códigos de armazém para evitar muitas tabelas.
Por exemplo, a tabela de códigos do gerente. O que mais nos preocupa é o nome do administrador, mas pode ser repetido, sendo necessária a informação do bilhete de identidade para esclarecer melhor os dados. O cartão de identificação pode ser usado diretamente como código e o nome do gerente depende do cartão de identificação. Neste caso, mesmo que um administrador seja responsável vitalício por um armazém, não é conveniente colocar na tabela de armazém a relação correspondente entre o cartão de cidadão e o nome Lista de códigos de administrador a guardar. Se você se preocupa apenas com o nome do gerente e não com o cartão de identificação, mas o gerente não é um sistema de responsabilidade vitalício, essa correspondência variável também deve ser contada como uma tabela de relacionamento, em vez de informações relacionadas fixas na tabela de códigos do depósito. Se você se preocupa apenas com o nome do gerente e é fixo para toda a vida, então pode-se considerar que o nome do gerente é um atributo inerente ao armazém e colocado diretamente na tabela de códigos).
Além disso, existem tabelas de codificação de materiais, tabelas de codificação de gênero (97 gêneros-soja suada), etc. Há casos em que os códigos são significativos (como carteiras de identidade) e sem sentido (como códigos aleatórios).
Tabela relacional:
O relacionamento correspondente entre as chaves primárias de várias tabelas de códigos reflete certa lógica de negócios, em vez de mudanças no tempo e no espaço. A afiliação de pode mudar ao longo do tempo devido à delegação e nomeação. Embora o warehouse e o administrador possam ser um para um, considerando a reforma comercial e a mudança do administrador, é melhor armazenar o relacionamento correspondente por meio da tabela de relacionamento do administrador do warehouse, em vez de colocar o administrador no código do warehouse como um atributo associado.
Tabela de registro:
incorpora a natureza do tempo e do espaço. Por exemplo, a quantidade atual e o espaço ocupado por um determinado material em um determinado depósito, o número atual de trabalhadores em um determinado depósito, o status do check-in ou o número de materiais que entram e saem do depósito hoje, etc. Um valor que é usado para alterações frequentes de inserção ou atualização. Esses valores geralmente correspondem a chaves candidatas compostas por vários atributos principais.
3. Entenda o funcionamento do banco de dados
https://www.bilibili.com/video/BV12t4y1H7by/?spm_id_from=333.788&vd_source=6debe81be6c46d072d7be3a28fc4790e
O que aconteceu ao consultar:
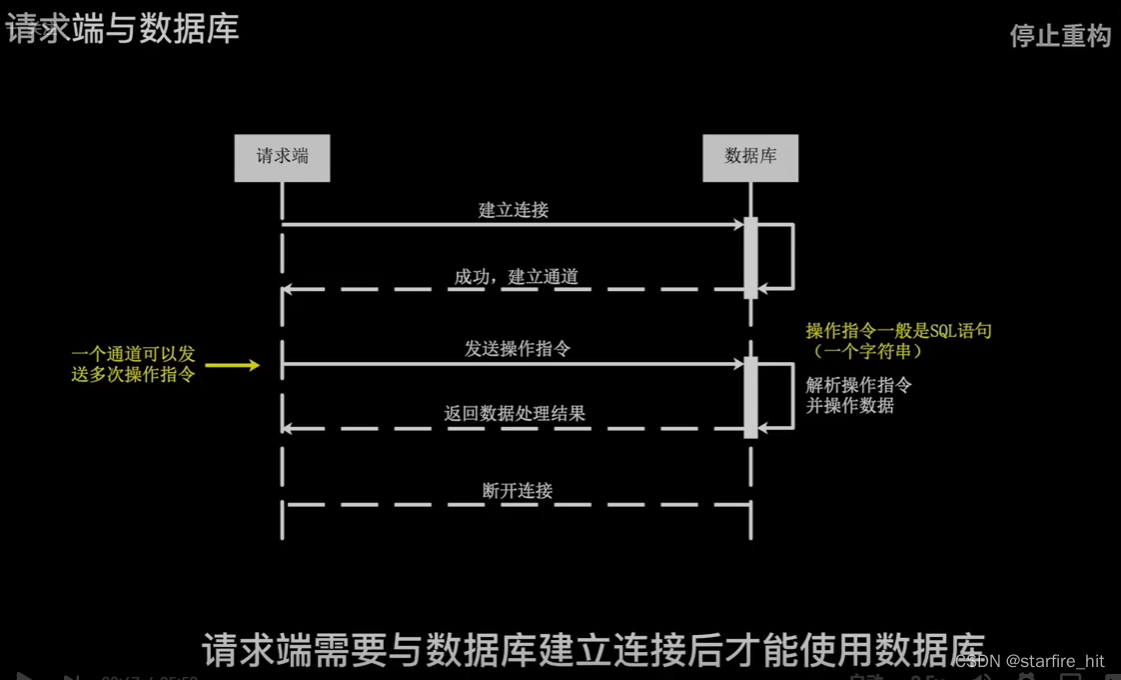
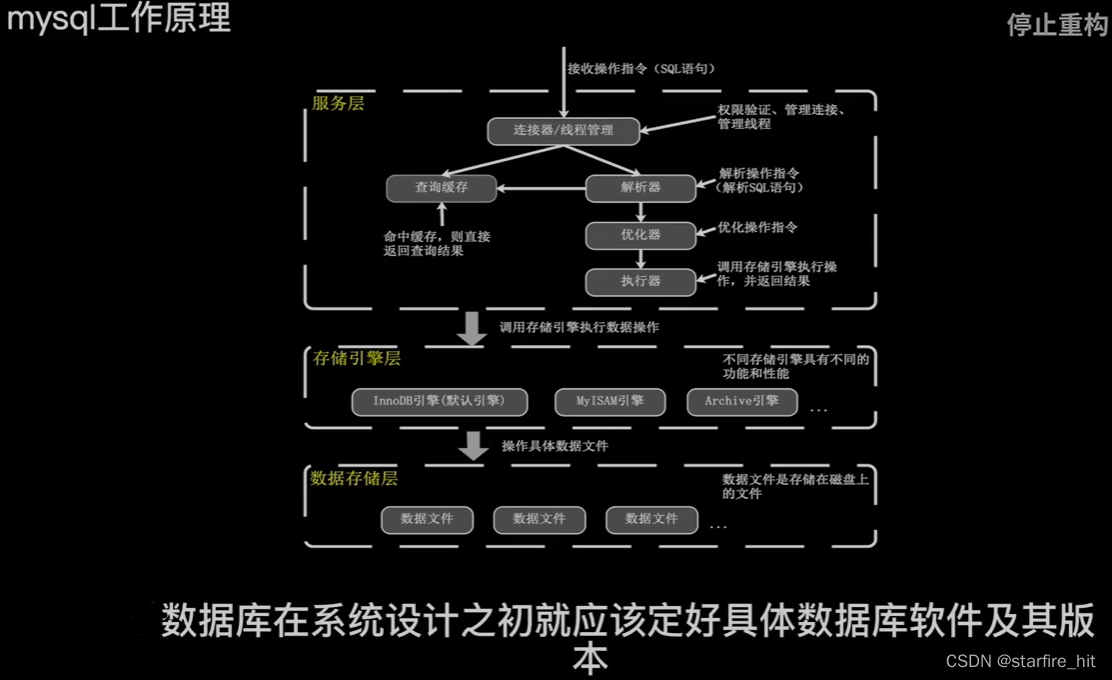
ajuste de desempenho, de acordo com o desempenho do servidor, determine os parâmetros ideais por meio de testes:
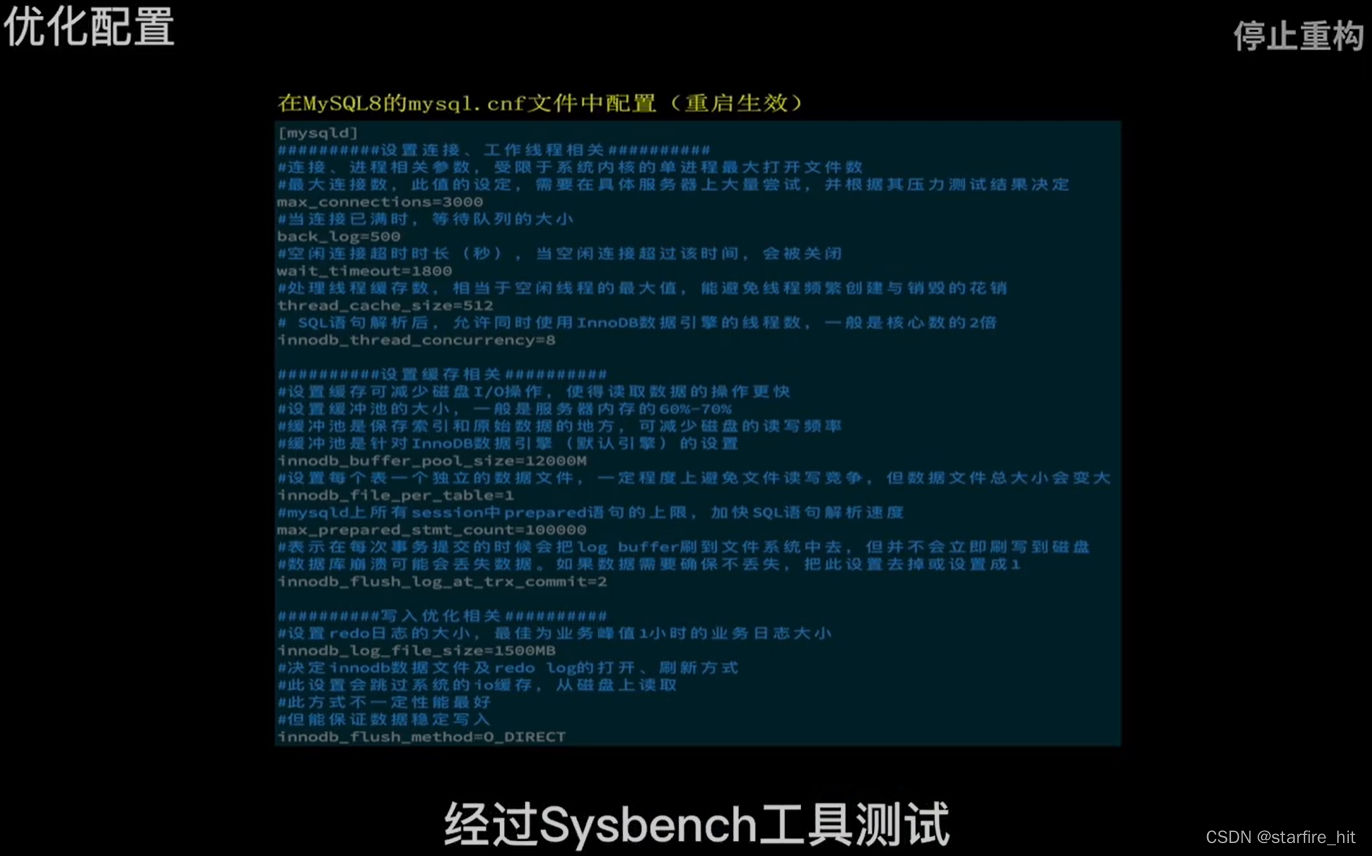
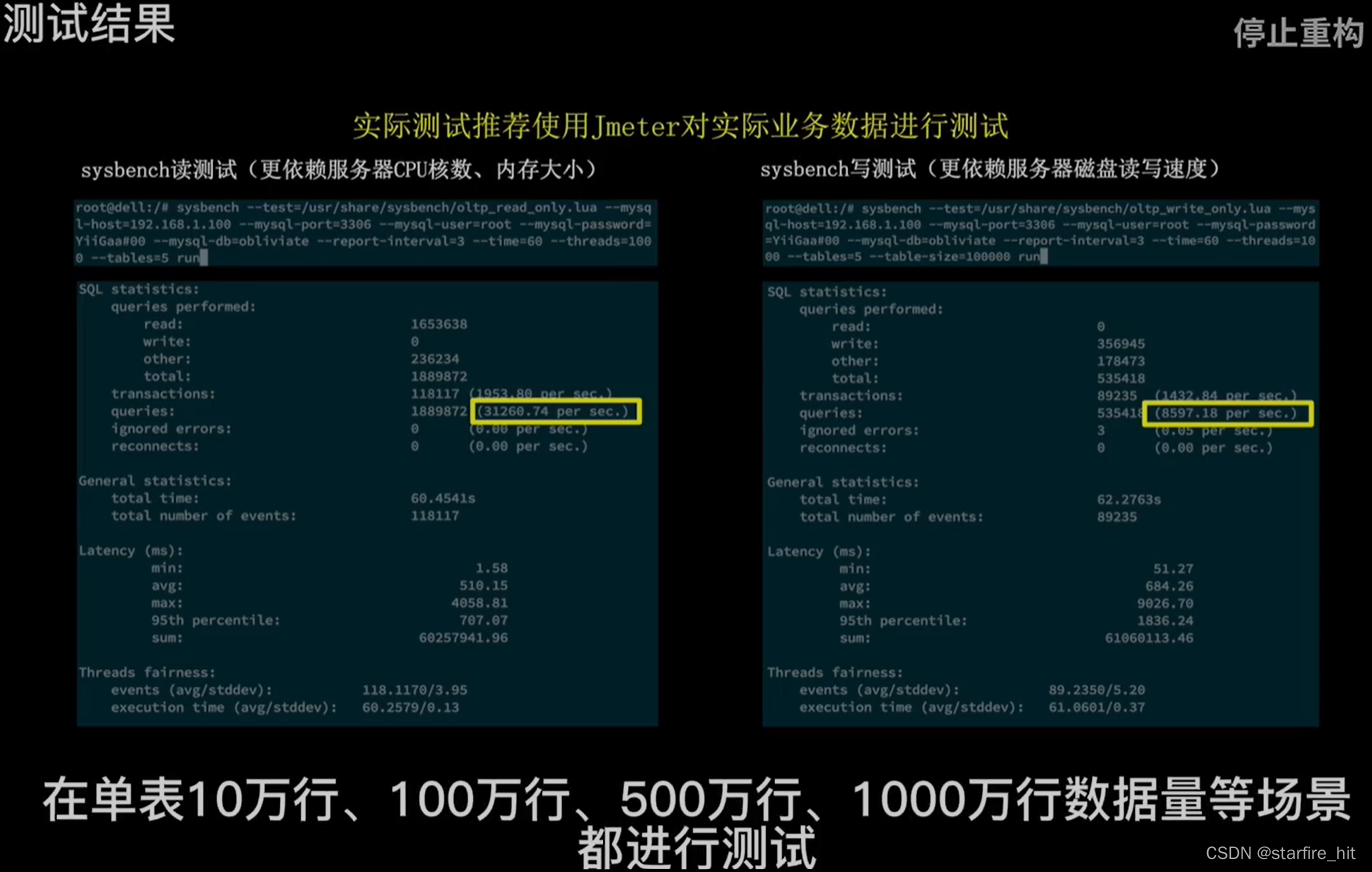
Por meio de testes de vários cenários, prevê-se que o número de servidores de banco de dados precisará ser aumentado para separar leituras e gravações e armazenamento de fragmentos para reduzir a pressão em um único servidor quando o negócio crescer. O desempenho de uma única tabela MySQL que exceda 1kW linhas cairá drasticamente.
Em quarto lugar, a diferença entre documento e banco de dados relacional
https://www.bilibili.com/video/BV1aL411G7Z9/?spm_id_from=333.999.0.0&vd_source=6debe81be6c46d072d7be3a28fc4790e
Vários tipos de bancos de dados

#outro:
índice?