Para
uso pessoal Referência: http://dx.doi.org/10.1016/j.envsoft.2013.08.006
Uma abordagem de análise de cluster passo a passo para projeção climática reduzida - Um estudo de caso canadense
Xiuquan Wang a, Guohe Huang a, b, *, Qianguo Lin b, c, Xianghui Nie a, Guanhui Cheng a, Yurui Fan a, Zhong Li a, Yao Yao a, Meiqin Suo c
Técnicas de redução de escala são usadas para obter previsões climáticas de alta resolução para avaliar os impactos das mudanças climáticas em escala regional. Este estudo propõe uma ferramenta de redução de escala estatística SCAD baseada em um método de análise de agrupamento passo a passo. O SCDS usa árvores de agrupamento para representar relações complexas entre variáveis atmosféricas de grande escala (ou seja, preditores) e variáveis de superfície local (ou seja, preditores). Ele pode lidar eficientemente com variáveis contínuas e discretas, bem como preditores e relacionamentos não lineares entre preditores. Ao integrar módulos funcionais auxiliares, como detecção de dados ausentes, análise de correlação, calibração de modelo e desenho de árvore de cluster, o SCDS permite o rápido desenvolvimento de cenários de redução de escala para variáveis climáticas locais sob condições climáticas atuais e futuras . Usando o SCADS, as previsões de temperatura média diária e precipitação mensal para 10 km em Toronto, Canadá, foram obtidas de 2070 a 2099. Dados contemporâneos de reanálise do NARR foram usados para calibração do modelo (1981-1990) e validação (1991-2000). A árvore de agrupamento validada é então aplicada para gerar previsões climáticas futuras.
introduzir:
Projeções futuras de mudanças climáticas podem ser derivadas de modelos climáticos globais (GCMs) com base em uma variedade de cenários de emissão. No entanto, para avaliar os impactos das mudanças climáticas em escalas regionais, o resultado dos GCMs não pode ser usado diretamente devido à incompatibilidade na resolução espacial entre os GCMs e os modelos de avaliação de impacto (Hashmi et al., 2009; Willems e Vrac, 2011). Normalmente, o GCM tem uma resolução espacial de centenas de quilômetros, enquanto a análise de impacto requer uma resolução mais fina (dezenas de quilômetros ou até menos). Consequentemente, técnicas de redução de escala foram desenvolvidas nos últimos anos para lidar com incompatibilidades espaciais como uma alternativa para melhorar as estimativas regionais ou locais de variáveis de saída GCM (Hessami et al., 2008). De acordo com uma revisão de estudos anteriores (Hewitson e Crane, 1996; Wilby e Wigley, 1997; Wilby et al., 1998, 2004; Murphy, 1999; Mearns et al., 2003), as técnicas de downscaling podem ser divididas em dinâmicas e estatísticas. . Como um método típico de downscaling dinâmico, os modelos climáticos regionais (RCM) podem não apenas gerar séries temporais de precipitação e temperatura contendo correlações temporais e espaciais consistentes com mecanismos físicos, mas também ajudar a identificar condições e mecanismos climáticos fora da amostra anteriormente não observados. No entanto, é difícil para o RCM gerar rapidamente um grande número de resultados possíveis e fornecer dados de estação de alta resolução de forma econômica. Em contraste, o downscaling estatístico envolve principalmente o desenvolvimento de variáveis atmosféricas de grande escala (ou
preditores) e variáveis de superfície local (ou preditores), que são mais fáceis de implementar e têm requisitos computacionais muito menores (Wilby et al., 2004).
Portanto, métodos estatísticos de redução de escala são amplamente utilizados em estudos de impactos das mudanças climáticas (Heyen et al., 1996; Maak e von Storch, 1997; Beckmann e Adri Buishand, 2002; Huth, 2002; Wood et al., 2004; Fowler et al ., 2007; Timbal et al., 2009; Hashmi et al., 2011; Phatak et al., 2011; Mullan et al., 2012). Em geral, os métodos estatísticos de redução de escala podem ser divididos em três categorias: esquemas de classificação meteorológica (por exemplo, métodos de simulação, classificação fuzzy, métodos de Monte Carlo), modelos de regressão (por exemplo, regressão linear, modelos estocásticos, métodos de comprimento de período, modelagem híbrida), e geradores de clima (por exemplo, redes neurais, análise de correlação canônica).
Da mesma forma, várias ferramentas de redução de escala foram desenvolvidas recentemente para facilitar os estudos dos impactos das mudanças climáticas. Por exemplo, Wilby et al. (2002) desenvolveram uma ferramenta de downscaling baseada em regressão chamada SDSM ; Hersami et al. (2008) propuseram uma ferramenta Automatic Statistical Downscaling (ASD) baseada em SDSM ; Semenov e Barrow (1997) desenvolveram um modelo de gerador climático chamado Long Ashton Research Station Weather Generator (LARS-WG); Willems e Vrac (2011) desenvolveram um modelo artificial modelo baseado em dados de inteligência usando Gene Expression Programming (GEP) para criar funções de redução simbólica.
Entre esses métodos de redução de escala, a maioria deles assume que cada variável preditora de interesse é uma função da variável preditora. Isso é especialmente verdadeiro para modelos baseados em regressão. No entanto, não há garantia de que tal relacionamento funcional deva existir entre preditores e preditores . Embora possamos construir relacionamentos funcionais de forma restrita reduzindo o número de variáveis ou introduzindo mais suposições, isso pode não melhorar significativamente a qualidade da projeção em comparação com a saída grosseira do GCM.
Para este fim, este estudo proporá uma ferramenta de downscaling baseada em análise de cluster stepwise ( SCADAS ) que representa preditores e interações complexas entre preditores como árvores de cluster sem assumir relacionamentos funcionais. A ferramenta de redução proposta é inspirada no método Stepwise Cluster Analysis (SCA) introduzido pela primeira vez por Huang (1992).
Nos últimos anos, o SCA tem sido amplamente utilizado em estudos ambientais.
Por exemplo, Huang et al. (2006) desenvolveram um sistema preditivo baseado em SCA para dar suporte ao projeto de restauração e controle do processo; Qin et al. (2007) Aplicando o SCA para estabelecer um vínculo entre a ação corretiva e a resposta do sistema.
O principal objetivo deste estudo é desenvolver uma ferramenta de downscaling baseada em SCA e testar sua capacidade de obter cenas mais finas a partir da saída grosseira de GCM ou RCM. As seções a seguir primeiro descrevem a lógica, o processo de modelagem e a implementação de software do método SCA . Um exemplo ilustrativo é dado para obter um mapa de alta resolução de 10 km de Toronto, Canadá, 2070-2099, reduzindo o modelo PRECIS (Providing Regional Climate for Impact Studies) e o cenário de 25 km produzido pelo Regional Climate Modeling System desenvolvido por o Bureau de Meteorologia Hadley Center for Climate Prediction. A seção final apresenta as principais conclusões e recomendações quanto à aplicação do SCDS e suas limitações.
método
Princípios básicos do SCA
O algoritmo básico da SCA é baseado na teoria da análise multivariada de variância (Morrison, 1967; Cooley e Lohnes, 1971; Overall e Klett, 1972). No SCA, o conjunto de amostra da variável dependente será cortado ou mesclado em um novo conjunto (ou seja, subcluster) de acordo com os critérios fornecidos, e o valor da variável independente é usado como referência para determinar qual novo conjunto (ou seja, o cluster pai) é a amostra no conjunto original. cluster) entrará (Huang et al., 2006). A construção da árvore de agrupamento SCA requer múltiplas operações de corte e fusão.Este processo, na verdade, divide o conjunto original de variáveis dependentes em muitos subconjuntos irrelevantes de acordo com padrões específicos, que serão apresentados posteriormente nesta seção. A árvore de agrupamento resultante pode expressar preditores e relacionamentos complexos entre preditores e será usada para prever valores futuros dos preditores, com base na operação de corte ou mesclagem da estatística L de Wilks (Wilks, 1962), definida como
, 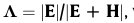
onde E e H são as matrizes internas e intermediárias de soma de quadrados e produtos cruzados, respectivamente. Deixe dois conjuntos de variáveis dependentes e e f conterem amostras ne e nf expressas como os seguintes vetores:

onde d é a dimensionalidade de e e f. Então H e E podem ser dados por:

Desenvolvimento de SCADS
Em geral, o processo de obtenção de previsões climáticas reduzidas pode ser resumido em quatro etapas:
1) Triagem de um conjunto de preditores para cada preditor de interesse, o que geralmente requer algumas correlações necessárias para cada par de preditores e preditores 2)
Estabelecer relações quantitativas entre preditores e preditores baseados em dados amostrais, referidos como “treinamento” neste estudo;
3) Validar relações estabelecidas com dados observados para avaliar seu desempenho na reprodução do clima histórico;
4) Gerar previsões climáticas locais com base em relações estabelecidas,
uma etapa referida em este estudo como "previsão". O roteiro de desenvolvimento do SCDS é mostrado na Figura 1.
O resultado do processo de treinamento é uma árvore de agrupamento que pode lidar com variáveis contínuas e discretas, bem como relacionamentos não lineares entre variáveis. A entrada para este trabalho de previsão é principalmente da produção de previsões climáticas em larga escala por GCM ou RCM. O SCADS é uma ferramenta de downscaling baseada na Web que pode ser acessada livremente pela Internet por usuários de qualquer país do mundo. Os usuários do SCDS precisam registrar uma conta para usar todas as funções fornecidas. A Figura 2 mostra a interface principal do SCADAS, por meio da qual o usuário pode efetuar login no sistema com as informações da conta criada por ele mesmo. Para evitar a lentidão do servidor web de hospedagem e gerenciar com eficiência todas as solicitações de downgrade, adotamos a disciplina de enfileiramento (ou seja, primeiro a chegar, primeiro a ser atendido) no desenvolvimento do SCAD para controlar as demandas do usuário em recursos de computação e consumo de tempo. As principais funções do SCDS serão apresentadas nas seções a seguir.
3.1 Detecção de dados ausentes
Dados ausentes aparecem em quase todas as análises estatísticas sérias (Gelman e Hill, 2006). Resultados não responsivos ou irracionais devido à falta de dados podem levar à interferência nos objetivos da pesquisa. Portanto, é necessário verificar se o conjunto de amostras contém dados ausentes e esclarecer sua distribuição em termos de séries temporais e estrutura da matriz de dados, de modo a escolher um método apropriado para lidar com os dados ausentes. O SCDS integra recursos de detecção de dados ausentes para ajudar os usuários a entender o número de elementos ausentes e como esses valores ausentes são distribuídos no conjunto de amostras. Conforme mostrado na Figura 3, o conjunto de dados original contém quatro elementos ausentes, indicados por "NA". O painel de visão geral ausente é fornecido pelo SCDS para visualizar os dados de entrada com os elementos ausentes destacados em vermelho (na versão da web). Ao mesmo tempo, o SCDS gera um relatório ausente, incluindo estatísticas detalhadas, como o número total de elementos ausentes, a localização dos ausentes (índice de linha e coluna).
3.2 Análise de correlação
A função de análise de correlação foi projetada para ajudar a rastrear com eficiência um conjunto de preditores para prever os valores dos preditores correspondentes. Neste estudo, usamos o coeficiente de correlação (também conhecido como R) como uma medida da associação entre cada par de preditores e preditores. O coeficiente de correlação é uma medida da força de uma relação direta ou linear entre duas variáveis (Rodgers e Nicewander, 1988), assumindo valores entre 1 e 1. O símbolo þ ou ? indica a direção relativa. Um sinal positivo indica uma correlação direta, enquanto um sinal negativo indica uma anticorrelação. Quanto mais próximo o número estiver de 1, mais forte será a correlação. Zero significa nenhuma correlação. Portanto, existem duas maneiras básicas de projetar um módulo de análise de correlação com base no coeficiente de correlação: determinar a capacidade preditiva da variável preditora e determinar a correlação entre a variável preditora e sua variável preditora correspondente. A Figura 4 mostra um diagrama do módulo de análise de correlação integrado na versão atual do SCDS. Os valores dos coeficientes de correlação calculados são destacados com uma cor de fundo diferente (na versão web). Mudar gradualmente a cor de amarelo (versão web) para vermelho (versão web) indica que o valor absoluto do coeficiente de correlação está aumentando gradualmente. Ao clicar em cada par de preditores e no valor do coeficiente de correlação dos preditores, uma janela pop-up contendo um gráfico de dispersão será exibida, o que é útil para entender o padrão de distribuição de todos os pontos de amostra e identificar efetivamente os pontos extremos.
3.3 Treinamento
O processo de treinamento é estabelecer preditores e a relação entre preditores e representá-los usando funções quantizadas ou outras formas. No SCDS, as transações relacionadas ao treinamento podem ser iniciadas e processadas criando um trabalho de treinamento. Preditores e relacionamentos complexos entre preditores são representados como árvores de cluster. A criação de um trabalho de treinamento na versão atual do SCDS requer três etapas:
1) Selecionar amostras,
2) Analisar amostras,
3) Confirmar e enviar.
Recomenda-se que os usuários verifiquem os dados de amostra antes de criar um novo trabalho de treinamento, com a ajuda dos módulos Missing Data Check e Correlation Analysis. Se uma amostra com dados ausentes for alimentada em um trabalho de treinamento sem nenhum pré-processamento , o SCDS eliminará toda a linha de dados, desde que pelo menos um elemento esteja ausente . Ao criar um novo trabalho de treinamento, o usuário será solicitado a especificar um nome amigável para identificar o trabalho. O tempo total consumido por um trabalho de treinamento geralmente varia muito. Em geral, depende do tamanho da amostra (ou seja, do número total de linhas no conjunto de amostra), do número de preditores e preditores e da correlação de cada par de preditores e preditores. Após o envio de um trabalho de treinamento, o SCDS decidirá se ele deve ser iniciado imediatamente. Se alguns trabalhos foram enviados antes deste e pelo menos um deles estiver aguardando ou em execução, o novo trabalho será adicionado à fila de espera. Caso contrário, ele começará a funcionar imediatamente. Após a conclusão do trabalho de treinamento, o SCDS produzirá dois arquivos de texto simples: treefile e mapfile, incluindo caminhos de árvore de cluster e nós de folha, respectivamente.
Um utilitário baseado em Windows, SCDS Cluster Tree Generator (CTGV1.0), foi desenvolvido com o SCADAS para facilitar a visualização da saída das árvores do cluster pelo processo de treinamento. A interface principal do CTG V1.0 é mostrada na Figura 5.
3.4. Calibração
Durante a calibração, várias partes do modelo, incluindo valores de entrada, são alteradas para combinar valores medidos (ou seja, valores observados) com valores simulados, com o objetivo de representar com precisão aspectos importantes do sistema real (Hill, 1998). No SCDS, apenas um parâmetro de entrada precisa ser calibrado, o nível de significância (a). Normalmente, seu valor inicial pode estar na faixa de 0,01 a 0,05. Quanto maior o nível de significância, menos sensível o modelo e menos nós de folha da árvore de agrupamento gerada. O nível de significância padrão no SCDS é 0,05. No entanto, o usuário pode ajustá-lo iterativamente até que a saída reduzida corresponda às previsões de amostra com precisão aceitável.
3.5 Verificação
A verificação é usada para determinar se um modelo é uma representação precisa do sistema real, geralmente por meio de um processo iterativo de comparação do modelo com o comportamento real do sistema (Kleijnen, 1995; Bennett et al., 2013). O uso de R ao quadrado (R2, coeficiente de determinação) está bem estabelecido na análise de regressão clássica (Rao, 1973). É definido como a proporção da variância explicada pelo modelo de regressão, tornando-o útil para medir o sucesso da previsão da variável dependente a partir da variável independente (Nagelkerke, 1991). Portanto, o SCADAS adota o coeficiente de determinação como critério chave para verificar o desempenho do modelo. Conforme mostrado na Figura 6, vários valores de R-quadrado foram calculados para cada par de preditores previstos e observados. Ao clicar em cada valor, uma janela superior é exibida contendo um gráfico de dispersão do previsto versus observado para ajudar a visualizar o desempenho do modelo.
3.6. Previsão
O módulo de previsão é usado para ajudar os usuários a desenvolver cenários de downscaling de alta resolução com base em árvores de cluster validadas. O processo de criação de um trabalho de previsão é simples. O usuário especifica o nome da tarefa de treinamento e os dados de entrada para os preditores. Em troca, o SCDS prevê os preditores correspondentes com base nas árvores de saída e nos arquivos de mapa durante o treinamento.
4 aplicações
O SCDS é aplicado em Toronto, Canadá. Os preditores de larga escala para o período 1981-2000 vêm do conjunto de dados North American Regional Reanalysis (NARR), originalmente produzido pelo National Center for Environmental Prediction (NCEP). O projeto NARR é uma extensão do NCEP Global Reanalysis na América do Norte. O modelo NARR usa o modelo NCEP Eta de altíssima resolução (32 km/45 camadas) e o Sistema Regional de Assimilação de Dados (RDAS), que assimila significativamente a precipitação e outras variáveis (Mesinger e coautores, 2006; Saha e coautores, 2010). Os dados coletados foram então refeitos na grade de 25 km do modelo PRECIS para previsão. Preditores em escala regional, como temperatura média diária do ar (°C) e precipitação mensal (mm) no mesmo período, foram extraídos de um conjunto de dados climáticos em grade de 10 km fornecidos pelo Serviço Nacional de Informações sobre Recursos Hídricos e Terrestres, Agricultura e Agricultura. Alimentos, Canadá. Os dados da grade foram interpolados a partir de observações diárias nas estações climáticas do Environment Canada pelo método de ajuste de superfície spline de suavização de placa fina implementado em ANUSPLIN V4.3 (NLWIS, 2008). Os dados dos primeiros dez anos (ou seja, 1981-1990) são usados para calibração do modelo, e os dados dos dez anos restantes (ou seja, 1991-2000) são usados para validação do modelo. Em segundo lugar, com a ajuda da análise de correlação do SCAD, um conjunto limitado de variáveis preditoras de grande escala é selecionado de um grande número de variáveis candidatas.
A Tabela 1 lista os coeficientes de correlação dos preditores candidatos com temperatura média diária e precipitação mensal. Os valores em negrito indicam os preditores selecionados para os procedimentos de treinamento e predição, representando as combinações mais promissoras de preditores e preditores correspondentes. O conjunto filtrado de preditores foi inserido no processo de treinamento para gerar árvores de cluster em diferentes níveis de significância (ou seja, 0,01, 0,02, 0,03, 0,04 e 0,05). Os resultados de temperatura média diária e precipitação mensal para o período 1981-1990 são reproduzidos com base na árvore de agrupamento gerada.
A Tabela 2 mostra os resultados da calibração para diferentes níveis de significância considerando o R-quadrado e a raiz quadrada média do erro (RMSE). Isso mostra uma ligeira melhora na estimativa da precipitação mensal, com o valor aumentando de 0,01 para 0,05. Quando ¼ 0,04, o melhor resultado de ajuste de precipitação pode ser obtido, R ao quadrado é 0,5279 e RMSE é 16,1787 mm. No entanto, a escolha de diferentes níveis de a não afetou significativamente os resultados de ajuste para a temperatura média diária (R-quadrado em um valor constante de 0,9710), exceto por uma leve melhora no RMSE quando ¼ 0,05.
Portanto, neste exemplo, os níveis de significância calibrados para temperatura e precipitação serão diferentes entre si; o valor previsto para a temperatura média diária do ar é 0,05, enquanto o valor previsto para a precipitação mensal é 0,04. Para verificar o desempenho do SCAD em retrospectiva do clima recente, a temperatura média diária do ar e os valores mensais de precipitação para o período de 1991 a 2000 foram reproduzidos por árvores de cluster calibradas.
A saída do SCDS foi comparada com dados observacionais recuperados do Environment Canada. A Figura 7 mostra os resultados da validação para a temperatura média diária do ar durante o período de validação 1991-2000. O alto valor de R-quadrado de 0,9705 indica que o SCAD pode reproduzir melhor a temperatura diária observada com um RSME tão baixo quanto 1,6689°C durante o período de 10 anos. A Figura 8 mostra os resultados da validação para a precipitação mensal. O desempenho geral do SCADA foi satisfatório em termos de retropolação da precipitação mensal total ao longo do período de validação (valor R-quadrado de 0,5156, RSME de 16,8004 mm), revelando a capacidade do SCADA de estimar valores extremos de precipitação, frequentemente associados a eventos extremos. precipitação .
Eventos climáticos, como inundações no verão e tempestades de neve no inverno.
Incorporando relações complexas entre preditores e temperatura média diária e precipitação mensal, a árvore de agrupamento validada foi então usada para reduzir preditores regionais equivalentes do modelo PRECIS. Os resultados do modelo Toronto PRECIS foram fornecidos pelo Centro de Energia e Meio Ambiente da Universidade de Regina (CSEE, 2010). Duas fatias de tempo de 30 anos são consideradas nesta ilustração para projetar cenários climáticos futuros para os anos de 1961-1990 e 2070-2099. O primeiro é geralmente definido como uma linha de base indicativa da forçante climática atual, enquanto o segundo é indicativo do clima futuro. A mudança climática futura em relação ao período de linha de base é então analisada para ajudar a entender mudanças futuras plausíveis na temperatura média diária e na precipitação mensal. A Figura 9 mostra a mudança na temperatura média mensal de Toronto de 2070-2099 em relação à média do período de linha de base. Ele relata uma tendência ascendente consistente na temperatura média em todos os meses, com uma variação média de cerca de ± 4°C. O aquecimento em janeiro, fevereiro e março foi bastante acentuado, com variações de até 5 a 6 graus Celsius, enquanto os demais meses apresentaram aumentos relativamente menores (iguais ou inferiores a 4,5 graus Celsius). No geral, a tendência de aquecimento projetada aumentará a temperatura média anual de 2070 a 2099 em uma grande margem. Por exemplo, as temperaturas médias no inverno (ou seja, dezembro, janeiro e fevereiro) serão acima de 0°C, enquanto no verão (ou seja, junho, julho e agosto) chegarão a 23°C. A Figura 10 mostra a mudança na precipitação mensal total em Toronto de 2070 a 2099 em relação ao período de linha de base. De janeiro a dezembro, a precipitação total muda muito. A precipitação total no inverno (ou seja, dezembro, janeiro e fevereiro) e na primavera (ou seja, março, abril e maio) aumentou significativamente de ±26 para ±46 mm, exceto em ). No entanto, espera-se que os totais mensais de precipitação de julho e setembro diminuam de 3 a 15 mm, sem mudanças significativas observadas em junho e outubro. De um modo geral, Toronto experimentará um aumento na precipitação anual, pois o aumento esperado na precipitação mensal é muito maior do que a diminuição esperada na precipitação mensal.
5. Aviso
A ferramenta de redução desenvolvida se baseia em uma série de suposições que podem impor sérias ressalvas em sua aplicação futura. Primeiro, o SCADAS ainda é uma ferramenta de redução de escala estatística. Em outras palavras, todas as suposições básicas do downscaling estatístico ainda se aplicam ao SCADA. Por exemplo, a suposição subjacente é que as relações estatísticas desenvolvidas para o clima atual também se mantêm no futuro e também se mantêm dentro das restrições dos modelos dinâmicos (Wilby et al., 2004); o conjunto de preditores deve ser capaz de representar adequadamente o relevância da variável preditora alvo e a representação precisa do modelo climático são usados para selecionar preditores (Wilby e Wigley, 2000; Giorgi et al., 2001)). Em segundo lugar, o SCADS assume que as variáveis locais são normalmente distribuídas, de modo que o processo de corte e fusão pode ser tratado com eficiência de acordo com as estatísticas de Wilk. Assim, os resultados para a precipitação diária serão ruins, pois a maioria dos dias do ano pode não ter precipitação (ou seja, 0 mm), o que resultaria em uma distribuição gama. Para resolver esta deficiência, a redução da precipitação diária pode ser melhorada pela introdução do modelo de ocorrência de precipitação e modelo de precipitação proposto por Fealy e Sweeney (2007). Em terceiro lugar, a árvore de agrupamento é treinada e calibrada com base no clima anterior da área alvo. Isso significa que as projeções futuras do preditor de destino não estarão fora dos limites da climatologia anterior; portanto, novos valores extremos não podem ser capturados. Além disso, trabalhos futuros se concentrarão em melhorar a capacidade do software de prever eventos extremos causados por processos locais não estacionários no contexto de mudanças climáticas, como extremos hidrometeorológicos (Khaliq et al., 2006).
6. Conclusão
Com base em um método de análise de cluster passo a passo, uma ferramenta de redução de escala estatística (SCADAS) foi desenvolvida para ajudar a obter cenários de mudança climática de alta resolução. O SCDS usa árvores de agrupamento para representar relacionamentos complexos entre variáveis atmosféricas de grande escala e variáveis de superfície locais. Ele pode lidar eficientemente com variáveis contínuas e discretas, bem como preditores e relacionamentos não lineares entre preditores. Ao integrar módulos funcionais auxiliares, como detecção de dados ausentes, análise de correlação, calibração de modelo e desenho de árvore de cluster, o SCDS pode desenvolver rapidamente cenários de redução de escala de variáveis climáticas locais sob condições climáticas atuais e futuras. O SCAD foi usado para gerar temperaturas médias diárias de 10 quilômetros e previsões mensais de precipitação para Toronto, Canadá. Duas árvores de agrupamento foram construídas com base em dados observacionais de 1981-1990, que foram então usados para reconstruir a climatologia histórica de 1991-2000 para validação. Os resultados mostram que a temperatura e a precipitação observadas durante o período de validação são bem previstas pelo SCADA. O modelo validado é então aplicado para obter previsões de temperatura e precipitação para o período 2070-2099.