Diretório de artigos
1. Declaração avançada do MySQL
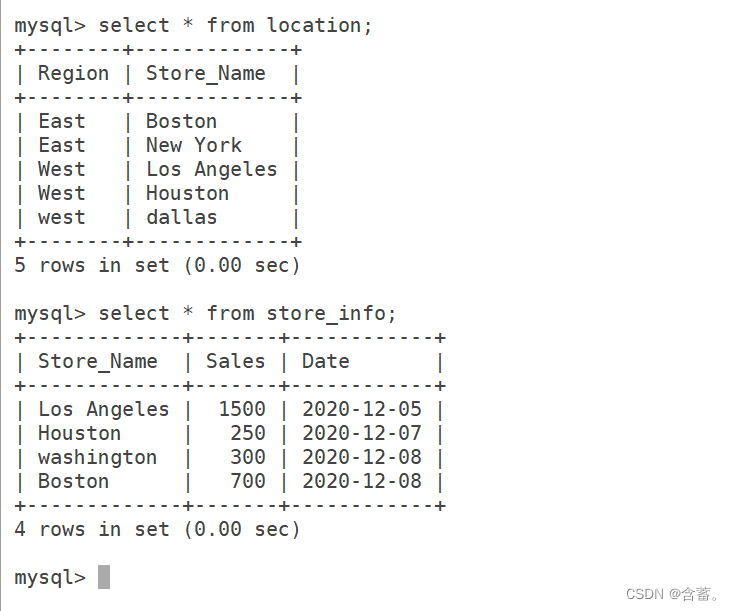
As duas tabelas a seguir serão usadas no próximo experimento
use KGCt;
create table location (Region char(20),Store_Name char(20));
insert into location values('East','Boston');
insert into location values('East','New York');
insert into location values('West','Los Angeles');
insert into location values('West','Houston');
create table store_info (Store_Name char(20),Sales int(10),Date char(10));
insert into store_info values('Los Angeles','1500','2020-12-05');
insert into store_info values('Houston','250','2020-12-07');
insert into store_info values('Los Angeles','300','2020-12-08');
insert into store_info values('Boston','700','2020-12-08');
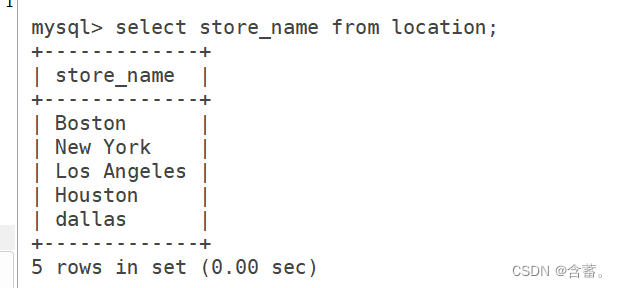
1, selecione
Exibir todos os registros de dados de um ou vários campos da tabela
语法:SELECT "字段" FROM "表名";
SELECT Store_Name FROM Store_Info;
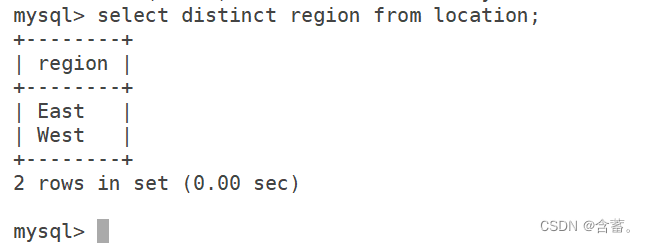
2、DISTINTO
Não exibir registros de dados duplicados
语法:SELECT DISTINCT "字段" FROM "表名";
SELECT DISTINCT Store_Name FROM Store_Info;
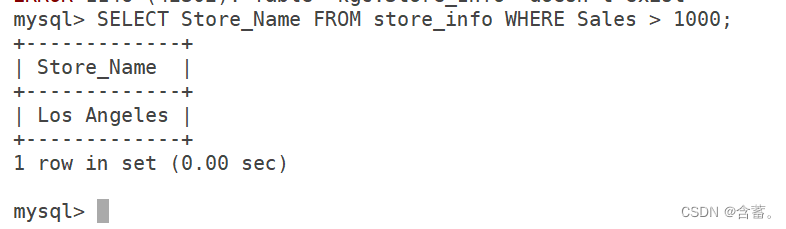
3. WHERE
instrução de consulta condicional
语法:SELECT "字段" FROM "表名" WHERE "条件";
SELECT Store_Name FROM Store_Info WHERE Sales > 1000;
4. E OU
e ou
语法:SELECT "字段" FROM "表名" WHERE "条件1" {[AND|OR] "条件2"}+ ;
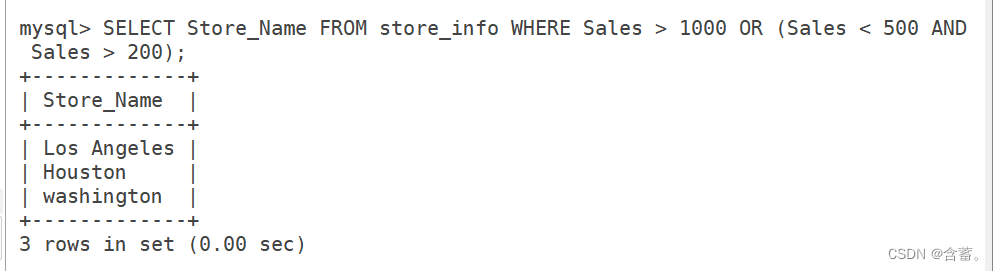
SELECT Store_Name FROM Store_Info WHERE Sales > 1000 OR (Sales < 500 AND Sales > 200);
5. IN
mostra o registro de dados do valor conhecido
语法:SELECT "字段" FROM "表名" WHERE "字段" IN ('值1', '值2', ...);
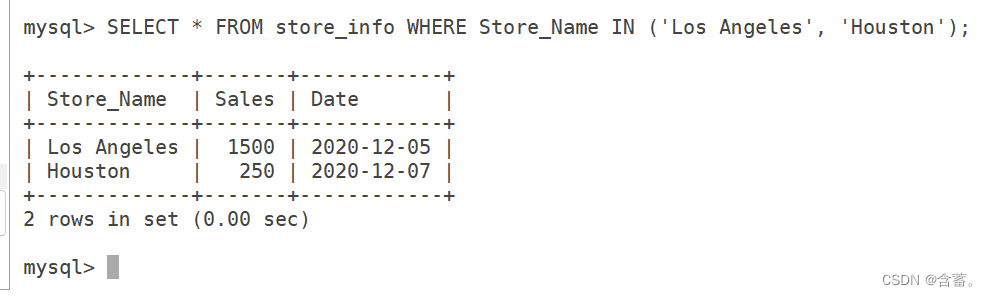
SELECT * FROM Store_Info WHERE Store_Name IN ('Los Angeles', 'Houston');
6. BETWEEN
exibe registros de dados dentro de dois intervalos de valores
语法:SELECT "字段" FROM "表名" WHERE "字段" BETWEEN '值1' AND '值2';
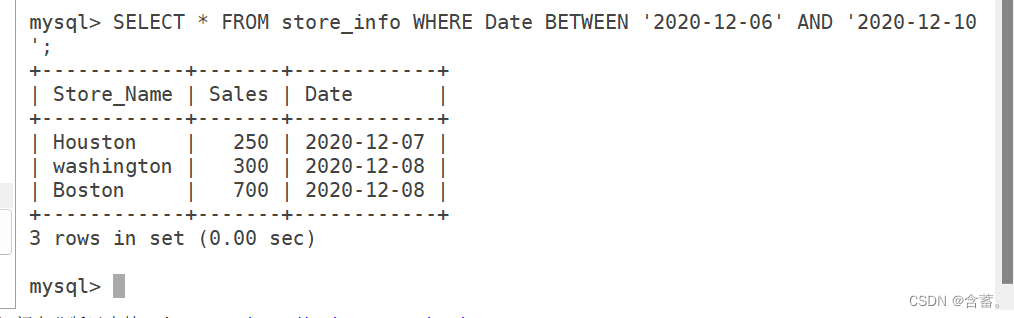
SELECT * FROM Store_Info WHERE Date BETWEEN '2020-12-06' AND '2020-12-10';
7. Curingas
Geralmente curingas são usados junto com LIKE
% :百分号表示零个、一个或多个字符
_ :下划线表示单个字符
'A_Z':所有以 'A' 起头,另一个任何值的字符,且以 'Z' 为结尾的字符串。例如,'ABZ' 和 'A2Z' 都符合这一个模式,而 'AKKZ' 并不符合 (因为在 A 和 Z 之间有两个字符,而不是一个字符)。
'ABC%': 所有以 'ABC' 起头的字符串。例如,'ABCD' 和 'ABCABC' 都符合这个模式。
'%XYZ': 所有以 'XYZ' 结尾的字符串。例如,'WXYZ' 和 'ZZXYZ' 都符合这个模式。
'%AN%': 所有含有 'AN'这个模式的字符串。例如,'LOS ANGELES' 和 'SAN FRANCISCO' 都符合这个模式。
'_AN%':所有第二个字母为 'A' 和第三个字母为 'N' 的字符串。例如,'SAN FRANCISCO' 符合这个模式,而 'LOS ANGELES' 则不符合这个模式。
8. LIKE
corresponde a um padrão para encontrar o registro de dados que queremos
语法:SELECT "字段" FROM "表名" WHERE "字段" LIKE {模式};
SELECT * FROM Store_Info WHERE Store_Name like '%os%';

9. ORDER BY
classificado por palavras-chave
语法:SELECT "字段" FROM "表名" [WHERE "条件"] ORDER BY "字段" [ASC, DESC];
#ASC 是按照升序进行排序的,是默认的排序方式。
#DESC 是按降序方式进行排序。
SELECT Store_Name,Sales,Date FROM Store_Info ORDER BY Sales DESC;

9. Função
(1) Funções matemáticas:
| função | significado |
|---|---|
| abs(x) | retorna o valor absoluto de x |
| rand() | Retorna um número aleatório entre 0 e 1 |
| mod(x,y) | Retorna o restante após a divisão de x por y |
| potência(x,y) | retorna x à potência de y |
| redondo(x) | retorna o inteiro mais próximo de x |
| redondo(x,y) | Valor arredondado com x a y casas decimais |
| quadrado(x) | retorna a raiz quadrada de x |
| truncar(x,y) | Retorna o valor do número x truncado para y casas decimais |
| teto(x) | retorna o menor inteiro maior ou igual a x |
| andar(x) | retorna o maior inteiro menor ou igual a x |
| maior(x1,x2…) | Retorna o maior valor da coleção e também pode retornar o maior valor de vários campos |
| menos(x1,x2…) | Retorna o menor valor na coleção e também pode retornar o menor valor de vários campos |
SELECT abs(-1), rand(), mod(5,3), power(2,3), round(1.89);
SELECT round(1.8937,3), truncate(1.235,2), ceil(5.2), floor(2.1), least(1.89,3,6.1,2.1);

(2) Função de agregação:
| função | significado |
|---|---|
| média() | Retorna a média da coluna especificada |
| contar() | Retorna o número de valores não NULL na coluna especificada |
| min() | Retorna o valor mínimo da coluna especificada |
| max() | Retorna o valor máximo da coluna especificada |
| soma(x) | Retorna a soma de todos os valores na coluna especificada |
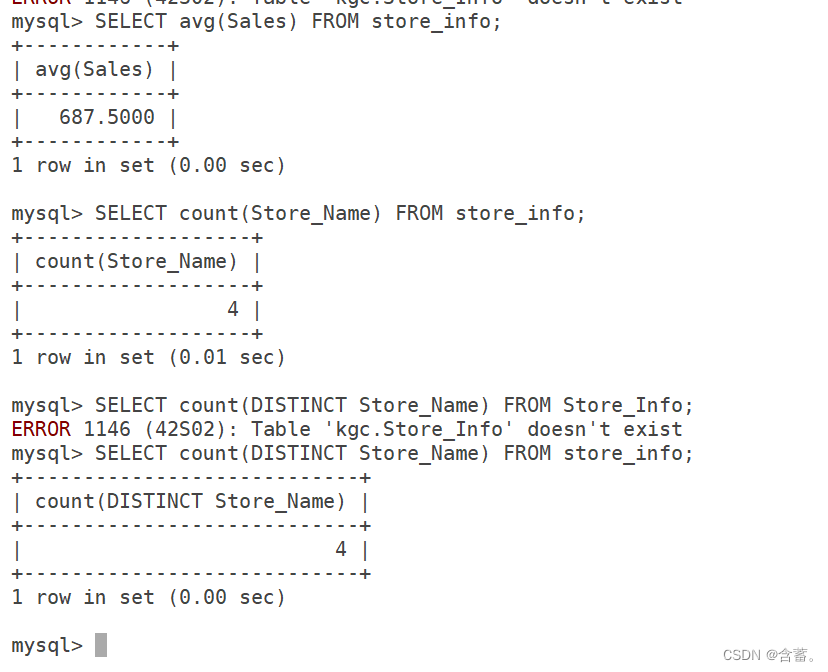
SELECT avg(Sales) FROM Store_Info;
SELECT count(Store_Name) FROM Store_Info;
SELECT count(DISTINCT Store_Name) FROM Store_Info;
SELECT max(Sales) FROM Store_Info;
SELECT min(Sales) FROM Store_Info;
SELECT sum(Sales) FROM Store_Info;
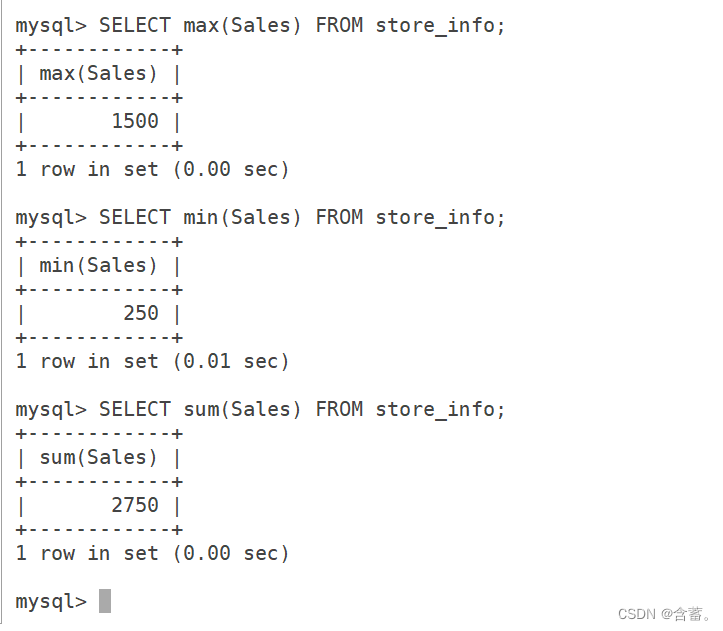
count(*) inclui o número de linhas de todas as colunas e não irá ignorar o valor da coluna NULL ao contar os resultados
count(nome da coluna) inclui apenas o número de linhas na coluna com o nome da coluna. Ao contar os resultados, as linhas cujo valor da coluna é NULL serão ignoradas
(3) Função de string:
| função | significado |
|---|---|
| aparar() | Retorna o valor com o formato especificado removido |
| concat(x,y) | Concatene os parâmetros fornecidos x e y em uma string |
| substr(x,y) | Obtenha a string começando na posição y na string x, que tem o mesmo efeito que a função substring() |
| substr(x,y,z) | Obtém uma string de comprimento z começando na posição y na string x |
| comprimento(x) | Retorna o comprimento da string x |
| substituir(x,y,z) | substitua a string z pela string y na string x |
| superior(x) | converter todas as letras da string x para maiúsculas |
| inferior(x) | Converter todas as letras da string x para minúsculas |
| esquerda(x,y) | Retorna os primeiros y caracteres da string x |
| direita(x,y) | Retorna os últimos y caracteres da string x |
| repita(x,y) | repita a string x y vezes |
| espaço(x) | retorna x espaços |
| strcmp(x,y) | Compare x e y, o valor retornado pode ser -1,0,1 |
| reverso(x) | inverta a string x |
SELECT concat(Region, Store_Name) FROM location WHERE Store_Name = 'Boston';
#如sql_mode开启了PIPES_AS_CONCAT,"||"视为字符串的连接操作符而非或运算符,和字符串的拼接函数Concat相类似,这和Oracle数据库使用方法一样的
SELECT Region || ' ' || Store_Name FROM location WHERE Store_Name = 'Boston';
SELECT substr(Store_Name,3) FROM location WHERE Store_Name = 'Los Angeles';
SELECT substr(Store_Name,2,4) FROM location WHERE Store_Name = 'New York';
SELECT TRIM ([ [位置] [要移除的字符串] FROM ] 字符串);
#[位置]:的值可以为 LEADING (起头), TRAILING (结尾), BOTH (起头及结尾)。
#[要移除的字符串]:从字串的起头、结尾,或起头及结尾移除的字符串。缺省时为空格。
SELECT TRIM(LEADING 'Ne' FROM 'New York');
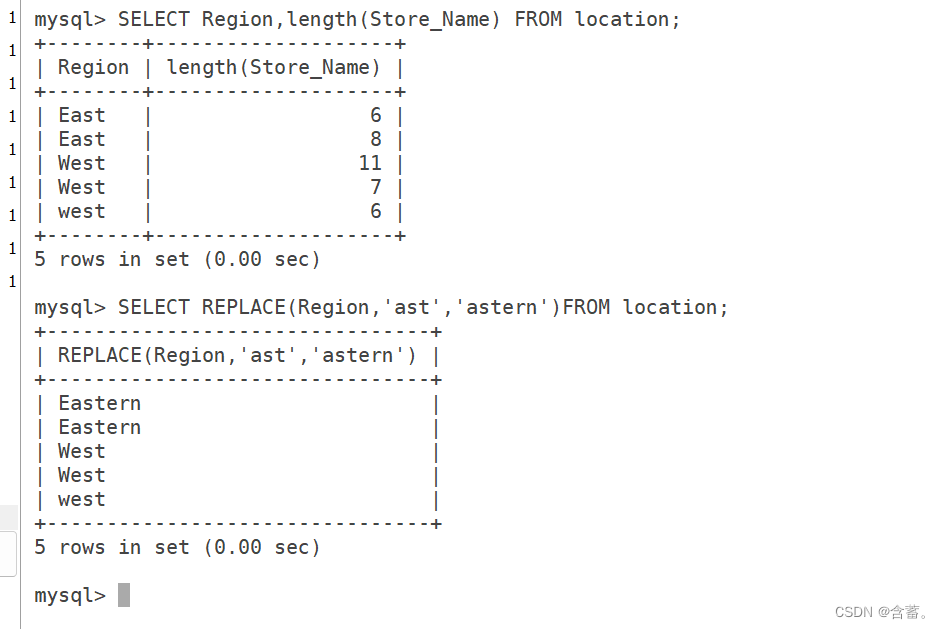
SELECT Region,length(Store_Name) FROM location;
SELECT REPLACE(Region,'ast','astern')FROM location;

2. Consulta de declaração avançada
2.1 GRUPO POR
Resuma e agrupe os resultados da consulta dos campos atrás de GROUP BY, que geralmente é usado em combinação com funções de agregação. Há
um princípio em GROUP BY de que todos os campos que aparecem após GROUP BY devem aparecer após SELECT;
todos os campos que aparecem após SELECT e Campos que não aparecem em funções agregadas devem aparecer após GROUP BY
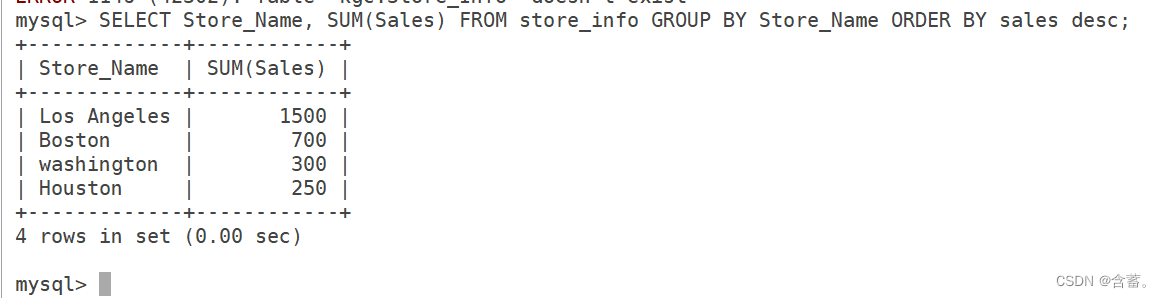
语法:SELECT "字段1", SUM("字段2") FROM "表名" GROUP BY "字段1";
SELECT Store_Name, SUM(Sales) FROM Store_Info GROUP BY Store_Name ORDER BY sales desc;
2.2 TENDO
Usado para filtrar o conjunto de registros retornado pela instrução GROUP BY, geralmente usada em conjunto com a instrução GROUP BY. A
existência da instrução HAVING compensa a deficiência de que a palavra-chave WHERE não pode ser usada em conjunto com a função agregada.
语法:SELECT "字段1", SUM("字段2") FROM "表格名" GROUP BY "字段1" HAVING (函数条件);
SELECT Store_Name, SUM(Sales) FROM Store_Info GROUP BY Store_Name HAVING SUM(Sales) > 1500;

2.3 Aliases
alias de campo alias de tabela
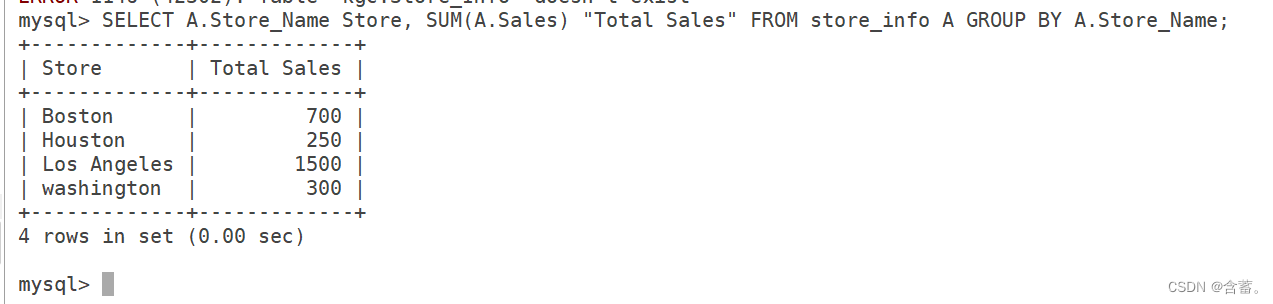
语法:SELECT "表格別名"."字段1" [AS] "字段別名" FROM "表格名" [AS] "表格別名";
SELECT A.Store_Name Store, SUM(A.Sales) "Total Sales" FROM Store_Info A GROUP BY A.Store_Name;
2.4 Subconsultas
Junte tabelas, insira outra instrução SQL na cláusula WHERE ou na cláusula HAVING
语法:SELECT "字段1" FROM "表格1" WHERE "字段2" [比较运算符] #外查询
(SELECT "字段1" FROM "表格2" WHERE "条件"); #内查询
#可以是符号的运算符,例如 =、>、<、>=、<= ;也可以是文字的运算符,例如 LIKE、IN、BETWEEN
SELECT SUM(Sales) FROM Store_Info WHERE Store_Name IN
(SELECT Store_Name FROM location WHERE Region = 'West');
SELECT SUM(A.Sales) FROM Store_Info A WHERE A.Store_Name IN
(SELECT Store_Name FROM location B WHERE B.Store_Name = A.Store_Name);


2.5EXISTE
É usado para testar se a consulta interna produz algum resultado, semelhante a se o valor booleano é verdadeiro
# Se sim, o sistema executará a instrução SQL na consulta externa. Caso contrário, toda a instrução SQL não produzirá nenhum resultado.
语法:SELECT "字段1" FROM "表格1" WHERE EXISTS (SELECT * FROM "表格2" WHERE "条件");
SELECT SUM(Sales) FROM Store_Info WHERE EXISTS (SELECT * FROM location WHERE Region = 'West');
