Os sistemas SIEM têm muitas regras escritas por especialistas para ajudar a rastrear comportamentos suspeitos. No entanto, existem muitos cenários de ataque que não podem ser descritos por regras rígidas e, portanto, podem ser rastreados com eficácia.
Dado o volume de dados que os sistemas SIEM processam diariamente e os desafios específicos de analisar esses dados (com o objetivo de encontrar o comportamento dos invasores), aplicar aprendizado de máquina hoje é necessário e muito eficaz.
detalhes da missão
Neste caso específico, abordamos o seguinte desafio: Uma vez que os invasores obtêm acesso a uma infraestrutura de TI, eles usam várias táticas e técnicas para se firmar e avançar ainda mais, todas as suas atividades deixam rastros de uma forma ou de outra, que então encontra seu caminho para o sistema SIEM.
O uso da maioria das táticas será registrado nos eventos de log do Windows relacionados ao início do processo (Sysmon EventID 1 e Windows Security Event ID 4688). Deixando de lado informações desnecessárias, nossos dados iniciais podem ser expressos na seguinte tabela:
| Nome de usuário |
Nome do processo |
| Ivan Ivan |
cmd.exe |
| Petrov Petr |
outlook.exe |
| Sidorov Nikolai |
whoami.exe |
Podemos ver uma lista de todos os processos e usuários em execução na infraestrutura, sob cuja conta eles estão sendo executados. É importante para nós ensinar o sistema SIEM a reconhecer quais processos são normais para um determinado usuário e quais são atípicos -- anormais. E, como você provavelmente pode imaginar, um processo anormal para um usuário pode parecer perfeitamente normal para outro.
Com esse recurso (capacidade de detectar processos anormais de usuários), poderemos detectar muitas tentativas de ataque em um estágio inicial. Por exemplo, imagine duas situações: um contador executa um utilitário em sua estação de trabalho para consultar informações do Active Directory Domain Services e uma secretária que costumava trabalhar apenas com software de escritório de repente executa um software de contabilidade. Provavelmente não é nada, o computador do contador é apenas um administrador de sistema sentado para diagnosticar problemas de rede, e a secretária recebe tarefas extras. Mas também pode haver outra explicação - a conta foi invadida por intrusos e procurada por uma promoção. Ou esta secretária é, na verdade, uma pessoa de dentro que está tentando roubar o banco de dados da empresa.
Tais casos certamente requerem a atenção e elaboração de um operador de SIEM, levando em consideração o contexto da situação e eventos de terceiros, independente do gatilho do evento específico.
Abordagem básica para resolução de problemas
Quais são as maneiras de resolver esse problema? A primeira coisa que vem à mente é controlar todos os processos iniciados por um determinado usuário e verificar suas permissões para esse usuário.
À primeira vista, um algoritmo tão simples parece resolver o problema. Mas quando testamos, obtivemos a seguinte situação.
Imagine que temos um programador em nossa organização que gosta de escrever código em seu IDE favorito - Visual Studio Code. Um dia, um amigo sugeriu que ele tentasse outra ferramenta - PyCharm, e ele seguiu seu conselho. Do ponto de vista do nosso algoritmo, existe uma anomalia, um comportamento atípico. Nossos usuários nunca trabalharam neste programa. Mas, do ponto de vista de um operador SIEM, não há nada a observar. Isso é falso positivo - um falso positivo. E haverá muitos desses casos, o que reduzirá a utilidade de nosso algoritmo a zero.
Como resolvemos este problema? Uma ideia veio imediatamente à mente: vamos operar não com aplicativos concretos, mas com sua finalidade funcional. Vamos categorizar todos os aplicativos e combiná-los em grupos. Por exemplo, PyCharm e Visual Studio Code estarão em um grupo chamado "Ferramentas do Desenvolvedor", e Microsoft Word e Microsoft Excel estarão no grupo "Programas do Office".
O mesmo pode ser feito para certificados de usuário. Nosso sistema não trata os usuários como indivíduos, mas sim como um conjunto de papéis funcionais. Por exemplo, um é desenvolvedor e administrador de sistema em meio período e o outro é contador. E o sistema aprenderá que os desenvolvedores podem usar ferramentas de desenvolvimento e os contadores podem usar software de contabilidade. E todos eles usam software de escritório também é possível.
Essa abordagem pode funcionar, mas infelizmente apenas em empresas onde o departamento de TI está constantemente atualizando a lista de funcionários e suas responsabilidades. Além disso, os inventários de software devem ser rastreados e atualizados, o que também é um desafio porque muitas agências usam software ad hoc ou desenvolvido internamente.
Uma abordagem de aprendizado de máquina
Então, quando as pessoas descobrem que algoritmos rigorosos padrão exigem muito esforço, é hora de usar a "mágica" do aprendizado de máquina. Precisamos aplicar um algoritmo que realmente "entenda" as responsabilidades funcionais de cada usuário e a finalidade de cada programa específico.
Isso parece complicado. Mas acontece que nossas necessidades podem ser totalmente satisfeitas por uma classe de algoritmos chamados sistemas de recomendação.
Um sistema de recomendação é uma classe de algoritmos de aprendizado de máquina projetados para recomendar produtos ou conteúdo aos usuários.
Como você pode imaginar, os sistemas de recomendação são difundidos em nossas vidas. Use um algoritmo sempre que quiser manter a atenção de um usuário com um novo conteúdo ou recomendar um novo produto para comprar.
Existem duas maneiras de construir um sistema de recomendação:
• baseado em conteúdo;
• filtragem colaborativa.
As técnicas baseadas em conteúdo requerem informações adicionais para funcionar. Nesse caso, é necessário descrever cada produto ou usuário com um conjunto de atributos. Por exemplo, no caso de selecionar um filme para o usuário, pode ser o gênero, atores dos papéis principais, ano de lançamento, país de produção. Como vimos, esse tipo de sistema de recomendação não atende aos nossos requisitos nessa tarefa específica.
As técnicas de filtragem colaborativa, por outro lado, usam apenas informações sobre o quanto um usuário gosta de determinado produto. Não precisamos coletar dados para cada atributo.
Vamos dar uma olhada em como a filtragem colaborativa funciona. Vamos imaginar que um produto premium tenha sido comprado por uma pequena porcentagem de usuários que compraram outros produtos premium. Faz sentido recomendar o produto para o restante desses usuários.
É claro que as pessoas que dão classificações semelhantes aos mesmos produtos têm gostos e preferências semelhantes. E o inverso também é verdadeiro: se um determinado grupo de usuários gosta de um conteúdo, ele está bem caracterizado. A filtragem colaborativa é baseada nesses princípios simples.
Nossa tarefa no treinamento do modelo é obter vetores para cada usuário e produto que, ao serem multiplicados entre si, nos darão a classificação do produto que o usuário daria na compra.
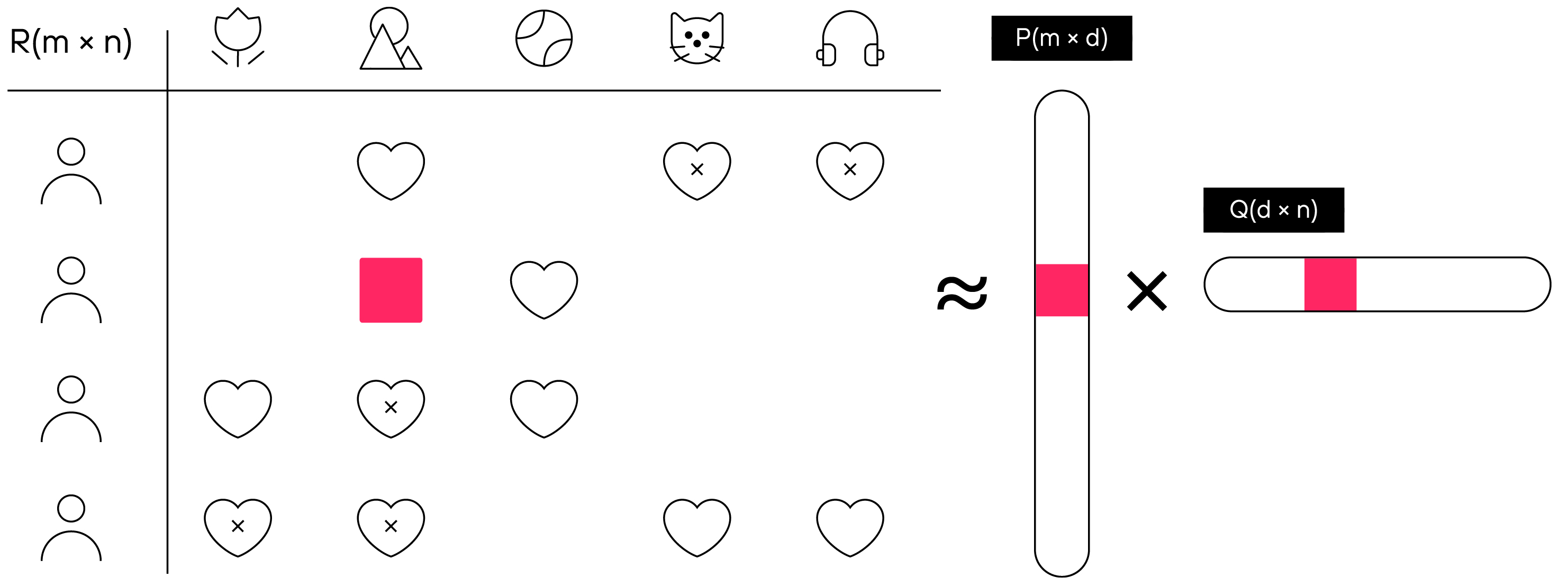
O princípio da tecnologia de filtragem colaborativa, onde P é uma matriz vetorial do usuário com dimensão m×d e Q é uma matriz vetorial produto com dimensão d×n.
A questão principal é: como fazemos esses vetores se não temos nenhuma informação sobre o usuário ou o conteúdo? Mas isso é apenas à primeira vista. Temos o histórico de classificação deles e isso é bom o suficiente para nós.
Por exemplo, podemos fazer isso usando o algoritmo de mínimos quadrados alternados (ALS). Sem entrar na matemática, podemos explicar o seu funcionamento da seguinte forma: fixamos uma matriz de vetores do usuário, otimizamos e variamos a matriz de conteúdo. Pegamos a derivada (gradiente) da função de perda e nos movemos na direção oposta do gradiente - na direção que queremos, onde está a "verdade" e nossas previsões não podem estar erradas. Em seguida, fixamos a matriz de conteúdo e fazemos o mesmo para a matriz de usuário. Repetimos várias vezes, aproximando-nos do valor desejado, "treinando" nosso modelo.
Desta forma, obteremos o vetor de que precisamos. Claro, se pegarmos um vetor concreto, não conseguiremos entender nada do ponto de vista humano. Para nós, será apenas um conjunto de números. Mas cada número neste vetor e as posições relativas entre esses números serão significativos e refletirão a situação real.
Uma questão razoável surge: como podemos usar sistemas de recomendação para detectar anomalias?
É lógico que, se um usuário executa um processo, ele gosta do processo. Se falarmos do ponto de vista do sistema de recomendação, esse processo terá uma pontuação alta.
E o inverso é o caso: se o processo for anormal, se este usuário em particular e outros usuários semelhantes nunca executaram este ou aquele processo, o sistema de recomendação dará uma pontuação baixa - dirá, nosso usuário não gostou do processo . Então ele/ela começa algo que gosta mesmo que não deva (de acordo com o sistema de recomendação) - isso é um outlier.
Essa abordagem provou funcionar bem durante os testes. Acontece que os vetores de usuário fazem um bom trabalho ao descrever as responsabilidades funcionais de um usuário, enquanto os vetores de aplicativo fazem um bom trabalho ao descrever o conjunto de recursos de um aplicativo. Os vetores do usuário refletem bem a realidade, como pode ser visto nos exemplos a seguir.
Vamos refletir todos os vetores do usuário em um espaço bidimensional. Temos uma imagem como esta.

Exibição 2D de contas de usuário
Um ponto é um usuário específico e a cor do ponto é sua responsabilidade funcional, que é extraída da tabela de pessoal. Podemos observar que usuários de um mesmo departamento estão agrupados lado a lado, o que significa que nosso modelo está bem treinado e seu estado interno reflete a realidade. Claro, haverá exceções neste caso, mas elas estão relacionadas ao comportamento específico de uma determinada pessoa.
Outro recurso de perspectiva importante a ser observado é o movimento de pontos (usuários) neste gráfico. Se um usuário estiver envolvido aproximadamente na mesma atividade, ele estará na mesma posição no espaço. No entanto, se uma atividade atípica começar em sua conta, veremos um "salto" acentuado nos pontos. Fazer uma ferramenta útil para detectar e analisar tais "saltos" seria útil para proteger os operadores.
Vejamos agora como seria o uso tradicional do modelo na prática.

Uma série temporal de previsões de modelo para um usuário
Este gráfico plota as leituras do modelo para um usuário específico. Quanto menor o número no eixo y, menos "normal" é o comportamento do usuário. Antes de 7 de julho, não havia nada incomum no comportamento desse usuário - nenhum dos outliers caiu abaixo de 0,9. Porém, no dia 11 de julho, um intruso tomou conta da conta – e o modelo passou a gerar valores baixos.
para concluir
Neste experimento, utilitários foram usados para conduzir o reconhecimento da infraestrutura. Este certamente não é um comportamento típico de um usuário. Aplicamos um sistema de referência simples e básico. Para desenvolver ainda mais essa ideia, podemos avançar na direção de sistemas de recomendação conjunta usando filtragem colaborativa e baseada em conteúdo, e também podemos implementar sistemas de aprendizado profundo. A principal conclusão tirada de nossos experimentos é que o uso de sistemas de recomendação para encontrar anomalias tem grande potencial para ajudar a resolver uma ampla gama de problemas de segurança cibernética.