Einzelheiten zum vollständigen Projekt/Code von Yiru finden Sie auf Github: https://github.com/yiru1225 (nachgedruckt und mit der Quelle gekennzeichnet, nicht für Projekte markieren, danke)
Inhaltsverzeichnis
1. Das Konzept und Prinzip von LDA
3. Unzulänglichkeit und Optimierung von LDA
2. LDA wird bei der Gesichtserkennung verwendet
1.1 Datenimport und -verarbeitung
1.2 Berechnung verschiedener Mittelwerte, Interklassenstreuung Sb und Intraklassenstreuung Sw
2. LDA-Kern (konstruieren Sie die Zielfunktion und führen Sie eine Eigenzerlegung darauf durch)
4. LDA- und PCA-Bilddimensionalitätsreduzierung und Visualisierungsvergleich
5. Zusammenfassung der Ähnlichkeiten und Unterschiede zwischen LDA und PCA
6.1 Interne Funktionsdefinition
Artikelverzeichnis der Serie
Diese Blogreihe konzentriert sich auf die Konzepte, Prinzipien und Codepraktiken des maschinellen Lernens und enthält keine langwierigen mathematischen Ableitungen (wenn Sie Fragen haben, diskutieren Sie diese bitte im Kommentarbereich oder kontaktieren Sie mich direkt per privater Nachricht) .
Der Code kann vollständig kopiert werden und es ist sinnvoll, dass jeder das Prinzip und den Prozess zur Reproduktion versteht! ! !
Kapitel 1 Maschinelles Lernen – PCA (Hauptkomponentenanalyse) und Gesichtserkennung_@李忆如的博客-CSDN博客
Kapitel 2 LDA und Gesichtserkennung
Zusammenfassung
Dieser Blog stellt hauptsächlich den LDA-Algorithmus (Linear Discriminant Analysis) vor und verwendet LDA und seine verschiedenen äquivalenten Modelle zur Gesichtserkennung, Reduzierung der Bilddimensionalität und Visualisierung und vergleicht LDA mit PCA (beiliegender Datensatz und Matlab-Code).
1. Das Konzept und Prinzip von LDA
1. Einführung in LDA
LDA (Linear Discriminant Analysis) ist ein gängiger Algorithmus zur linearen Dimensionsreduktion . Geleitet von dem Ziel, „ die Varianz innerhalb der Klasse zu minimieren und die Varianz zwischen den Klassen zu maximieren “, wird durch Dimensionsreduktion (Projektion) der Zweck der Dimensionsreduktion erreicht, um Stichproben besser zu klassifizieren.
2. LDA-Algorithmusmodell
Die klassische LDA-Problemlösung kann in die folgenden Schritte unterteilt werden
1. Klassifizieren Sie den Datensatz und berechnen Sie den Mittelwert jeder Klasse (LDA verwendet die Kategorie (Daten) der Stichprobe, bei der es sich um überwachtes Lernen handelt).
2. Berechnen Sie die klassenübergreifende Streumatrix Sb und die klasseninterne Streumatrix Sw.
3. Konstruieren Sie die Zielfunktion (eine Vielzahl unterschiedlicher Zielfunktionen) und führen Sie eine Eigenzerlegung darauf durch.
4. Nehmen Sie eine bestimmte Anzahl von Eigenvektoren heraus, um die Projektionsmatrix zu erhalten.
5. Projizieren Sie die Testdaten in den Unterraum und verwenden Sie KNN zur Klassifizierung (im eigentlichen Problem).
3. Unzulänglichkeit und Optimierung von LDA
1. Problem der endlichen Projektionsachse (≤ Anzahl der Kategorien - 1)
2. Kleines Beispielproblem
3. Beim Umgang mit hochdimensionalen Daten ist der Berechnungsaufwand sehr hoch
Optimierung: Vorverarbeitung mit PCA vor der Verwendung von LDA oder Hinzufügen einer Regularisierungsstörung zur Zielfunktion
4. Kann nichtlineare Probleme nicht gut beschreiben
Optimierung: Datenverarbeitung mittels LDA mit Kernel-Attributen
2. LDA wird bei der Gesichtserkennung verwendet
1. Vorbehandlung
1.1 Datenimport und -verarbeitung
Verwenden Sie imread, um die Gesichtsdatenbank stapelweise zu importieren, oder laden Sie direkt die entsprechende Mat-Datei und ziehen Sie die Gesichter beim Importieren kontinuierlich in Spaltenvektoren, um umgeformte_Gesichter zu bilden. Nehmen Sie 30 % als Testdaten und die restlichen 70 % als Trainingsdaten heraus. Wiederholen Sie dies. Der erste Schritt besteht darin, die importierten Daten in ein Framework zu abstrahieren, das dem Import verschiedener Datensätze entsprechen kann (das experimentelle Framework eignet sich für ORL-, AR- und FERET-Datensätze).
clear;
% 1.人脸数据集的导入与数据处理框架
reshaped_faces=[];
% 声明数据库名
database_name = "ORL";
% ORL5646
if (database_name == "ORL")
for i=1:40
for j=1:10
if(i<10)
a=imread(strcat('C:\Users\hp\Desktop\face\ORL56_46\orl',num2str(i),'_',num2str(j),'.bmp'));
else
a=imread(strcat('C:\Users\hp\Desktop\face\ORL56_46\orl',num2str(i),'_',num2str(j),'.bmp'));
end
b = reshape(a,2576,1);
b=double(b);
reshaped_faces=[reshaped_faces, b];
end
end
row = 56;
column = 46;
people_num = 40;
pic_num_of_each = 10;
train_pic_num_of_each = 7; % 每张人脸训练数量
test_pic_num_of_each = 3; % 每张人脸测试数量
end
%AR5040
if (database_name == "AR")
for i=1:40
for j=1:10
if(i<10)
a=imread(strcat('C:\AR_Gray_50by40\AR00',num2str(i),'-',num2str(j),'.tif'));
else
a=imread(strcat('C:\AR_Gray_50by40\AR0',num2str(i),'-',num2str(j),'.tif'));
end
b = reshape(a,2000,1);
b=double(b);
reshaped_faces=[reshaped_faces, b];
end
end
row = 50;
column = 40;
people_num = 40;
pic_num_of_each = 10;
train_pic_num_of_each = 7;
test_pic_num_of_each = 3;
end
%FERET_80
if (database_name == "FERET")
for i=1:80
for j=1:7
a=imread(strcat('C:\Users\hp\Desktop\face\FERET_80\ff',num2str(i),'_',num2str(j),'.tif'));
b = reshape(a,6400,1);
b=double(b);
reshaped_faces=[reshaped_faces, b];
end
end
row = 80;
column = 80;
people_num = 80;
pic_num_of_each = 7;
train_pic_num_of_each = 5;
test_pic_num_of_each = 2;
end
% 取出前30%作为测试数据,剩下70%作为训练数据
test_data_index = [];
train_data_index = [];
for i=0:people_num-1
test_data_index = [test_data_index pic_num_of_each*i+1:pic_num_of_each*i+test_pic_num_of_each];
train_data_index = [train_data_index pic_num_of_each*i+test_pic_num_of_each+1:pic_num_of_each*(i+1)];
end
train_data = reshaped_faces(:,train_data_index);
test_data = reshaped_faces(:, test_data_index);
dimension = row * column; %一张人脸的维度1.2 Berechnung verschiedener Mittelwerte, Interklassendivergenz Sb und Intraklassendivergenz Sw
Die Zwischenklassen-Streuungsmatrix Sb und die Intraklassen-Streuungsmatrix Sw der Stichprobe sind definiert als:


Abbildung 1 Definition von Sb und Sw
Teilen Sie den Gesichtsdatensatz entsprechend der Anzahl der Personen n in n Kategorien auf, berechnen Sie den Durchschnittswert jeder Kategorie und erhalten Sie die entsprechende Matrix gemäß der Definition und mathematischen Ableitung von Sb und Sw.
% 算每个类的平均
k = 1;
class_mean = zeros(dimension, people_num);
for i=1:people_num
% 求一列(即一个人)的均值
temp = class_mean(:,i);
% 遍历每个人的train_pic_num_of_each张用于训练的脸,相加算平均
for j=1:train_pic_num_of_each
temp = temp + train_data(:,k);
k = k + 1;
end
class_mean(:,i) = temp / train_pic_num_of_each;
end
% 算类类间散度矩阵Sb
Sb = zeros(dimension, dimension);
all_mean = mean(train_data, 2); % 全部的平均
for i=1:people_num
% 以每个人的平均脸进行计算,这里减去所有平均,中心化
centered_data = class_mean(:,i) - all_mean;
Sb = Sb + centered_data * centered_data';
end
Sb = Sb / people_num;
% 算类内散度矩阵Sw
Sw = zeros(dimension, dimension);
k = 1; % p表示每一张图片
for i=1:people_num % 遍历每一个人
for j=1:train_pic_num_of_each % 遍历一个人的所有脸计算后相加
centered_data = train_data(:,k) - class_mean(:,i);
Sw = Sw + centered_data * centered_data';
k = k + 1;
end
end
Sw = Sw / (people_num * train_pic_num_of_each);2. LDA-Kern (konstruieren Sie die Zielfunktion und führen Sie eine Eigenzerlegung darauf durch)
Tipps: Dieses Experiment verwendet pinv (Matrix-Pseudo-Inverse) anstelle von Inv (Matrix-Inverse), um den Einfluss einiger singulärer Werte auf das Experiment zu eliminieren
Jede Zielfunktion entspricht dem äquivalenten Modell verschiedener LDA-Modelle ( Division, Subtraktion und ihre Austauschposition usw. ) und PCA-Modellen (die Zielfunktion und das spezifische Prinzip können im entsprechenden Blog eingesehen werden) , und anschließend wird die Eigenzerlegung durchgeführt die Zielfunktion wird bestimmt.
% 目标函数一:经典LDA(伪逆矩阵代替逆矩阵防止奇异值)
target = pinv(Sw) * Sb;
% 目标函数二:不可逆时需要正则项扰动
% Sw = Sw + eye(dimension)*10^-6;
% target = Sw^-1 * Sb;
% 目标函数三:相减形式
% target = Sb - Sw;
% 目标函数四:相除
% target = Sb/Sw;
% 目标函数五:调换位置
% target = Sb * pinv(Sw);
%PCA
% centered_face = (train_data - all_mean);
% cov_matrix = centered_face * centered_face';
% target = cov_matrix;
% 求特征值、特征向量
[eigen_vectors, dianogol_matrix] = eig(target);
eigen_values = diag(dianogol_matrix);
% 对特征值、特征向量进行排序
[sorted_eigen_values, index] = sort(eigen_values, 'descend');
eigen_vectors = eigen_vectors(:, index);3. Gesichtserkennung
Der Dimensionsreduktionsprozess LDA ist im Grunde derselbe wie PCA. Die ersten n größten Eigenvektoren werden aus den nach Eigenwerten sortierten Eigenvektoren entnommen, um eine Projektionsmatrix zu erstellen, um eine Dimensionsreduktion (Dimensionalitätsreduktion auf n Dimensionen) zu erreichen, und KNN wird dafür verwendet Klassifizierungsvorhersage zur Erzielung einer Gesichtserkennung und Vergleich der Gesichtserkennungsgenauigkeit verschiedener äquivalenter Modelle und regulärer PCA- und LDA- Modelle unter verschiedenen Datensätzen.
Tipps: Ein einzelner Lauf ist die Gesichtserkennungsrate, die der ausgewählten Zielfunktion entspricht.
% 人脸识别
index = 1;
X = [];
Y = [];
% i为降维维度
for i=1:5:161
% 投影矩阵
project_matrix = eigen_vectors(:,1:i);
projected_train_data = project_matrix' * (train_data - all_mean);
projected_test_data = project_matrix' * (test_data - all_mean);
% KNN的k值
K=1;
% 用于保存最小的k个值的矩阵
% 用于保存最小k个值对应的人标签的矩阵
minimun_k_values = zeros(K,1);
label_of_minimun_k_values = zeros(K,1);
% 测试脸的数量
test_face_number = size(projected_test_data, 2);
% 识别正确数量
correct_predict_number = 0;
% 遍历每一个待测试人脸
for each_test_face_index = 1:test_face_number
each_test_face = projected_test_data(:,each_test_face_index);
% 先把k个值填满,避免在迭代中反复判断
for each_train_face_index = 1:K
minimun_k_values(each_train_face_index,1) = norm(each_test_face - projected_train_data(:,each_train_face_index));
label_of_minimun_k_values(each_train_face_index,1) = floor((train_data_index(1,each_train_face_index) - 1) / pic_num_of_each) + 1;
end
% 找出k个值中最大值及其下标
[max_value, index_of_max_value] = max(minimun_k_values);
% 计算与剩余每一个已知人脸的距离
for each_train_face_index = K+1:size(projected_train_data,2)
% 计算距离
distance = norm(each_test_face - projected_train_data(:,each_train_face_index));
% 遇到更小的距离就更新距离和标签
if (distance < max_value)
minimun_k_values(index_of_max_value,1) = distance;
label_of_minimun_k_values(index_of_max_value,1) = floor((train_data_index(1,each_train_face_index) - 1) / pic_num_of_each) + 1;
[max_value, index_of_max_value] = max(minimun_k_values);
end
end
% 最终得到距离最小的k个值以及对应的标签
% 取出出现次数最多的值,为预测的人脸标签
predict_label = mode(label_of_minimun_k_values);
real_label = floor((test_data_index(1,each_test_face_index) - 1) / pic_num_of_each)+1;
if (predict_label == real_label)
correct_predict_number = correct_predict_number + 1;
end
end
correct_rate = correct_predict_number/test_face_number;
X = [X i];
Y = [Y correct_rate];
fprintf("k=%d,i=%d,总测试样本:%d,正确数:%d,正确率:%1f\n", K, i,test_face_number,correct_predict_number,correct_rate);
if (i == 161)
waitfor(plot(X,Y));
end
end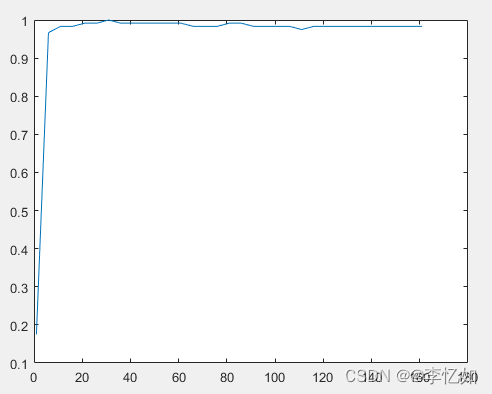
Abbildung 2 Die Beziehung zwischen der Gesichtserkennungsrate und der Dimension des klassischen LDA, verbessert durch pinv unter ORL

Abbildung 3 Vergleich der Gesichtserkennungsrate zwischen den einzelnen LDA- und PCA-Modellen in FERET
Analyse: Wenn FERET über einen großen Datensatz verfügt, schwankt die Erkennungsrate von Transpositions-LDA, Divisions-LDA und PCA stark und ist niedriger als bei den anderen drei Modellen, während die Leistung von regulärem LDA und klassischem LDA in jedem Datensatz relativ stabil ist (Andere Zahlen werden nicht angezeigt), die Erkennungsrate ist höher als die der klassischen PCA, insbesondere bei großen Datensätzen, und LDA hat offensichtliche Vorteile gegenüber PCA.
4. LDA- und PCA-Bilddimensionalitätsreduzierung und Visualisierungsvergleich
Verwenden Sie PCA und LDA, um die Dimensionalität des Gesichtsbilds auf zwei und drei Dimensionen zu reduzieren, nehmen Sie die Verteilung der ersten drei Kategorien und verwenden Sie das erste Bild jeder Kategorie als repräsentatives Bild.
Tipps: Dieses Experiment dient als Beispiel für die 2D- und 3D-Visualisierung des Testsatzes
% 二三维可视化
class_num_to_show = 3;
pic_num_in_a_class = pic_num_of_each;
pic_to_show = class_num_to_show * pic_num_in_a_class;
for i=[2 3]
% 取出相应数量特征向量
project_matrix = eigen_vectors(:,1:i);
% 投影
projected_test_data = project_matrix' * (reshaped_faces - all_mean);
projected_test_data = projected_test_data(:,1:pic_to_show);
color = [];
for j=1:pic_to_show
color = [color floor((j-1)/pic_num_in_a_class)*20];
end
% 显示
if (i == 2)
subplot(1, 7, [1, 2, 3, 4]);
scatter(projected_test_data(1, :), projected_test_data(2, :), [], color, 'filled');
for j=1:3
subplot(1, 7, j+4);
fig = show_face(test_data(:,floor((j - 1) * pic_num_in_a_class) + 1), row, column);
end
waitfor(fig);
else
subplot(1, 7, [1, 2, 3, 4]);
scatter3(projected_test_data(1, :), projected_test_data(2, :), projected_test_data(3, :), [], color, 'filled');
for j=1:3
subplot(1, 7, j+4);
fig = show_face(test_data(:,floor((j - 1) * pic_num_in_a_class) + 1), row, column);
end
waitfor(fig);
end
end

Abbildung 4 2D- und 3D-Visualisierung von LDA unter dem ORL-Datensatz


Abbildung 5 Zweidimensionale und dreidimensionale Visualisierung von PCA unter dem ORL-Datensatz
Analyse: Abbildung 4 und Abbildung 5 (Sie können die Zielfunktion oder den Rahmen für andere Datensätze und Modelle selbst ändern) zeigen die Verteilung der Bilder PCAundLDAnach Dimensionsreduzierung durch PCA hingegen ist relativ gemischt und hat keine klaren Regeln. Gemäß dem Zweck und Prinzip der beiden Algorithmen kann der Unterschied zwischen PCA und LDA verglichen werden (dh der Unterschied zwischen Eigenface und Fisherface ) .
5. Zusammenfassung der Ähnlichkeiten und Unterschiede zwischen LDA und PCA
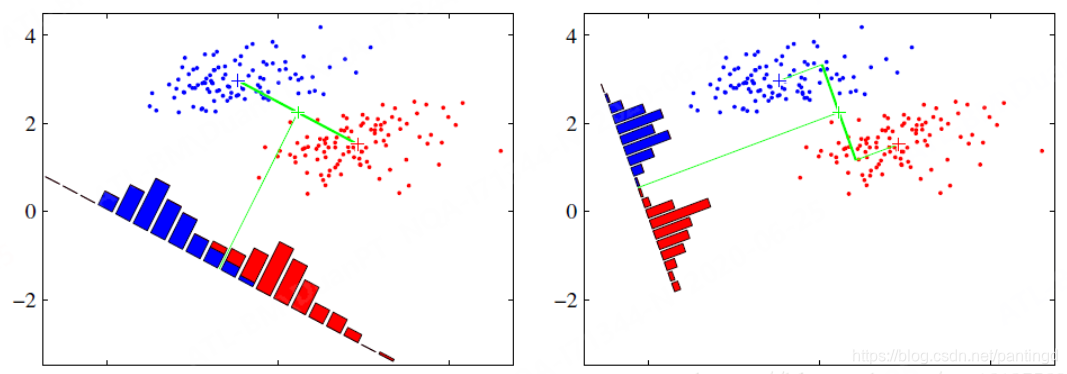
PCA LDA
Analyse: Sowohl PCA als auch LDA sind gängige lineare Dimensionsreduktionsalgorithmen, aber die Prinzipien und Zwecke der Dimensionsreduktion der beiden Algorithmen sind unterschiedlich . Die Kernidee von LDA besteht darin, „die Varianz innerhalb der Klasse zu minimieren und die Varianz zwischen den Klassen zu maximieren“. ", um die Daten besser zu vervollständigen Die Klassifizierung und Identifizierung von PCA und die Kernidee von PCA besteht darin, „die Kovarianzmatrix zu minimieren (den Rekonstruktionsfehler zu minimieren)", um eine Datenkomprimierung und Hauptkomponentenrekonstruktion zu erreichen. Im Allgemeinen ist die Wirkung von PCA und LDA in kleinen Datensätzen ähnlich oder übertrifft die von LDA. In großen Datensätzen ist LDA jedoch deutlich besser als PCA. Darüber hinaus verwendet LDA die Label-(Kategorie-)Informationen der Daten, bei denen es sich um überwachtes Lernen handelt, während PCA nicht verwendet wird, bei dem es sich um unüberwachtes Lernen handelt.
6. Sonstiges
6.1 Interne Funktionsdefinition
In diesem Experiment wird die Gesichtsbildanzeige in eine Funktion abstrahiert und die Funktion wie folgt definiert:
% 输入向量,显示脸
function fig = show_face(vector, row, column)
fig = imshow(mat2gray(reshape(vector, [row, column])));
end6.2 Datensätze und Ressourcen
Dieses Experiment verwendet den ORL5646-Datensatz als Demonstration und der Code kann auf mehrere Datensätze angewendet werden.
Die am häufigsten verwendeten Gesichtsdatensätze sind wie folgt (nicht prostituieren, hahaha)
Link: https://pan.baidu.com/s/12Le0mKEquGMgh5fhNagZGw
Extraktionscode: yrnb
Vollständiger LDA-Code: Li Yiru/Yirus maschinelles Lernen – Gitee.com
6.3 Referenzen
1. Lai Zhihuis Klasse
2. LDA-Algorithmusprinzip und Matlab-Implementierung_dulingtingzis Blog-CSDN blog_lda matlab
3. LDA-basierte Gesichtserkennungsmethode –fisherface – Zhihu (zhihu.com)
4. „Maschinelles Lernen“ von Zhou Zhihua
Zusammenfassen
Als klassischer linearer Dimensionsreduktionsalgorithmus projiziert LDA die Daten, um eine Dimensionsreduktion durch „Minimierung der Varianz innerhalb der Klasse und Maximierung der Varianz zwischen den Klassen“ als Ziel zu erreichen und die Datenklassifizierung besser abzuschließen. In vielen Bereichen des maschinellen Lernens (Datenklassifizierung, Sprachbildverarbeitung, Empfehlungssystem) weist es immer noch eine hervorragende Leistung auf. Und als überwachte Lernmethode (unter Verwendung der Originalinformationen der Daten) kann LDA die Dateninformationen besser behalten. Allerdings weist LDA immer noch das oben erwähnte Problem der begrenzten Projektionsachse, das Problem kleiner Stichproben, die Verarbeitung hochdimensionaler Daten, das Problem großer Berechnungskosten, schwer zu beschreibende nichtlineare Probleme usw. auf. Darüber hinaus geht LDA davon aus, dass die Daten jeder Klasse a sind Gaußsche Verteilung Diese Eigenschaft wurde im Rahmen von entwickelt und fehlt in realen Problemen häufig. Ohne diese Eigenschaft kann die Trennbarkeit verschiedener Klassen nicht gut durch Streuung zwischen Klassen beschrieben werden , was Auswirkungen auf die experimentellen Ergebnisse hat . Nachfolgende Blogs werden andere Algorithmusoptimierungen analysieren oder die oben genannten Probleme lösen.