Vorwort
In den frühen Stadien der Containerisierung ist geplant, Ceph als Lager für Container zu nutzen. Es wird gesagt, dass Speicher die Mutter der Virtualisierung ist. Im Vergleich zu Containern spielt Speicher auch eine entscheidende Rolle.
Die Gründe für die Wahl von Ceph als Containerspeicher sind folgende:
- Erleichtern Sie eine spätere horizontale Erweiterung;
- Ceph kann gleichzeitig schnellen Speicher, Objektspeicher und Dateispeicher unterstützen. Container verwenden Blockspeicher, und Objektspeicher wird später verwendet, um OSS-Dienste zu ersetzen.
Aus den oben genannten Gründen sollte es eine gute Wahl sein, den verteilten Ceph-Speicher zu übernehmen. Der erste Schritt bei der Containerisierung beginnt mit der Lagerung.
Offizielle Ceph-Dokumentation (auf Englisch): Einführung in Ceph – Ceph-Dokumentation
Offizielle Ceph-Dokumentation (Chinesisch): http://docs.ceph.org.cn/start/intro/
Einführung in Ceph
Unabhängig davon, ob Sie Ceph-Objektspeicher oder Blockgeräte für die Cloud-Plattform bereitstellen oder ein Ceph-Dateisystem bereitstellen möchten, beginnt die Bereitstellung aller Ceph-Speichercluster mit einem einzigen Ceph-Knoten, Netzwerk und Ceph-Speichercluster.
Um Ceph-Speicher zu erstellen, sind mindestens die folgenden Dienste erforderlich:
- Ein Ceph-Monitor
- Zwei OSD-Daemons
Wenn Sie den Ceph-Dateisystem-Client ausführen, müssen Sie über einen Metadatenserver (Metadata Server) verfügen. Es sollte nicht viele Szenarien für die Verwendung von Ceph als Dateisystem geben, und dieses Containerisierungsprojekt umfasst keinen Dateisystemspeicher. Gehen Sie also nicht näher darauf ein

Ceph OSDs: Die Funktion des Ceph OSD-Daemons (Ceph OSD) besteht darin, Daten zu speichern, die Datenreplikation, Wiederherstellung, Auffüllung und Neuverteilung zu verwalten und Ceph-Monitoren einige Überwachungsinformationen bereitzustellen, indem der Heartbeat anderer OSD-Daemons überprüft wird. Wenn der Ceph-Cluster auf 2 Kopien eingestellt ist, sind mindestens 2 OSD-Daemons erforderlich, damit der Cluster den Active+Clean-Status erreicht (Ceph verfügt standardmäßig über 3 Kopien, Sie können die Anzahl der Kopien jedoch anpassen).
Dies kann folgendermaßen verstanden werden: Ceph speichert Daten einzeln über OSDs. Das Standard-OSD von Ceph ist 3, kann jedoch manuell auf 2 eingestellt werden. Mindestens 2 können dazu führen, dass der Cluster einen fehlerfreien und verfügbaren Zustand erreicht und verwendet wird OSD zur Datenspeicherung. Hohe Verfügbarkeit.
Monitore: Ceph Monitor verwaltet verschiedene Diagramme, die den Status des Clusters zeigen, einschließlich Monitordiagramme, OSD-Diagramme, Platzierungsgruppendiagramme (PG) und CRUSH-Diagramme. Ceph speichert historische Informationen (Epoche genannt) über jede Zustandsänderung, die auf Monitoren, OSDs und PGs auftritt.
Dies kann folgendermaßen verstanden werden: Monitor ist ein Monitor von Ceph. Wenn Ceph Daten speichert, werden verschiedene Datenindikatoren aufgezeichnet und angezeigt. Was PG/CURSH betrifft, wird später besprochen.
Ceph speichert Clientdaten als Objekte in Speicherpools. Mithilfe des CRUSH-Algorithmus kann Ceph berechnen, welche Platzierungsgruppe (PG) das angegebene Objekt (Object) enthalten soll, und dann weiter berechnen, welcher OSD-Daemon-Prozess die Platzierungsgruppe enthält. Der CRUSH-Algorithmus ermöglicht Ceph-Speicherclustern die dynamische Skalierung, Neuverteilung und Reparatur.
In einem Satz fasst das offizielle Dokument die Prinzipien von Ceph zusammen, aber für diejenigen, die neu bei Ceph sind, ist es einfach ruckelig und schwer zu verstehen. Fassen Sie mehrere Schlüsselwörter zusammen: Objekt, CRUSH-Algorithmus, Platzierungsgruppe (PG), dynamische Skalierung
An diesem Punkt müssen wir verstehen, was das allgemeine Funktionsprinzip von Ceph ist. Ansonsten wird uns diese Frage immer umgeben.
Einführung in die Ceph-Speicherprinzipien
Nachdem ich die Informationen durchsucht hatte, stellte ich fest, dass der Artikel von Fat Brother sehr gut ist und es wert ist, wiederholt gelesen zu werden: Großes Gerede über Ceph – CRUSH
[Das folgende theoretische Wissen stammt aus dem Artikel von Fat Brother und einigen meiner eigenen Erkenntnisse]
Zunächst stellt sich die Frage: Wie viele Schritte sind erforderlich, um ein Datenelement im Ceph-Cluster zu speichern?
Cephs Antwort besteht aus zwei Schritten:
- Berechnen Sie PG, die Platzierungsgruppe im offiziellen Dokument
- OSD berechnen
Da von Berechnung die Rede ist, muss es einen Algorithmus geben. Ist der Algorithmus der sogenannte CRUSH?
Berechnen Sie PG
Zunächst muss eine Bestimmung von Ceph klargestellt werden: Bei Ceph ist alles ein Objekt. (Hier wird das Objekt erwähnt, was mit dem offiziellen Dokument übereinstimmt. Es ist nicht schwer zu verstehen, dass alles ein Objekt ist. Wie Python ist alles ein Objekt.)
Hier ist ein Beispiel zur Veranschaulichung: Alles ist ein Objekt, egal ob es sich um Video-, Foto-, Text- oder andere Formatdateien handelt:
Unabhängig von den Daten in irgendeinem Format wie Video, Text, Foto usw. betrachtet Ceph sie einheitlich als Objekt, da alle Daten auf der Festplatte gespeicherte Binärdaten sind und daher jedes Binärdatenelement als Objekt betrachtet wird. Sie werden nicht anhand ihres Formats unterschieden.
Da es sich um ein Objekt handelt, sollte das Objekt einen Objektnamen haben. Der Unterschied zwischen den beiden Objekten liegt im Objektnamen. Was ist, wenn die Dateinamen der beiden Objekte identisch sind?
Nun stellt sich zunächst die Frage: Wie viele Schritte sind erforderlich, um ein Objekt in einem Ceph-Cluster zu speichern?
Bekannt: Der Ceph-Cluster besteht aus mehreren Servern, genauer gesagt aus einer Reihe von Festplatten, und jede Festplatte in Ceph wird als OSD betrachtet.
Die Datei kann wie folgt vereinfacht werden: Wie viele Schritte sind erforderlich, um ein Objekt im OSD zu speichern?
Logische Schichten in Ceph
Um ein Objekt zu speichern, erstellt Ceph eine logische Schicht, also einen Pool (Pool). Dies ist nicht schwer zu verstehen, genau wie der Speicherpool in der Virtualisierung, der zum Speichern von Objekten verwendet wird. Vergleicht man den Pool mit B. ein chinesisches Schachbrett, ähnelt der Vorgang des Speicherns eines Objekts dem Platzieren eines Sesamsamens auf einem Schachbrett
Einfach wie in der Abbildung gezeigt:
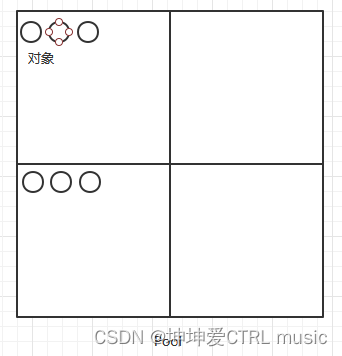
Der Pool wird noch einmal unterteilt, das heißt, ein Pool wird in mehrere PGs (Platzierungsgruppen) unterteilt, die den Feldern auf einem Schachbrett ähneln. Alle Felder bilden das gesamte Schachbrett, das heißt, alle PGs bilden einen Pool.
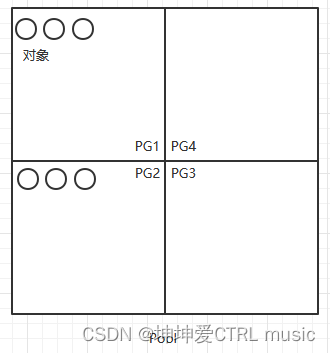
Anhand dieser beiden Diagramme können wir zusammenfassen: Eine Datei ist ein Objekt, und das Objekt wird in jedem PG gespeichert, und mehrere PGs bilden einen Pool
Nun stellt sich wieder die Frage: Woher weiß das Objekt, auf welchem PG es speichern soll? Nehmen wir hier an, dass unser Pool rbd heißt und es insgesamt 256 PGs gibt und die Nummern für jedes PG 0, 1, 2, 3, 4 heißen
Um dieses Problem zu lösen, schauen Sie sich zunächst an, was derzeit vorhanden ist.
- unterschiedliche Objektnamen
- andere PG-Nummer
Hier ist die Einführung von Cephs erstem Algorithmus: HASH
Berechnen Sie für zwei Objekte, deren Objektnamen bar und foo sind, einfach deren Objektnamen:
- HASH('bar') = 0x3E0A4162
- HASH('foo') = 0x7FE391A0
- HASH('bar') = 0x3E0A4162
Der HASH-Algorithmus sollte der am häufigsten verwendete Algorithmus sein. Nach dem HASHing des Objektnamens wird eine Zeichenfolge hexadezimaler Ausgabewerte erhalten, das heißt, wir konvertieren einen Objektnamen über HASH und dann die erste Zeile in eine Zahlenfolge oben und Warum ist die dritte Zeile dieselbe? Das bedeutet, dass für denselben Objektnamen das berechnete Ergebnis immer dasselbe ist , der HASH-Algorithmus jedoch eine Zufallszahl aus dem Objektnamen berechnet. Teilen Sie diese Zufallszahl mit dieser Zufallszahl durch die Gesamtzahl der PGs, z. B. 256, und der Rest muss zwischen 1 und 256 liegen, was einer der 256 PGs ist.
Formel: HASH('bar') % Anzahl der PGs
- 0x3E0A4162 % 0xFF ===> 0x62
- 0x7FE391A0 % 0xFF ===> 0xA0
Durch die obige Berechnung wird die Objektleiste im PG mit der Nummer 0x62 und das Objekt foo im PG mit der Nummer 0xA0 gespeichert. Die Objektleiste wird immer im PG 0x62 gespeichert! Objekt foo wird immer in PG 0xA0 gespeichert!
Derzeit ist es möglich, zusammenzufassen, wie ein Objekt in einem PG gespeichert wird:
Führen Sie HASH für den Objektnamen aus, um eine Zufallszahl zu erhalten, und verwenden Sie dann diese Zufallszahl, um den Rest der Gesamtzahl der PGs zu ermitteln. Der erhaltene Wert muss zwischen 1 und der Gesamtzahl der PGs sowie den Daten zur Änderung des Objekts liegen Der Name wird für immer in diesem PG gespeichert.
Da der Objektname bestimmt wird, wird daher auch der PG bestimmt, in dem das Objekt Daten speichert.
Daraus ergibt sich die Frage: Bestimmt der Objektname die Eindeutigkeit, unabhängig von der Größe der Objektdaten?
Die Antwort lautet „Ja“, das heißt, Ceph unterscheidet nicht zwischen der tatsächlichen Größe und dem Inhalt des Objekts und irgendeiner Form von Format, sondern nur zwischen dem Objektnamen.
Hier ist eine weitere Ceph-Erklärung. Tatsächlich gibt es in Ceph mehrere Pools und in jedem Pool gibt es mehrere PGs. Wenn die PG-Nummern in den beiden Pools gleich sind, wie unterscheidet Ceph sie dann? Also, Ceph Jeder Pool ist nummeriert. Beispielsweise erhält der RBD-Pool gerade die Nummer 0 und ein anderer Pool die Nummer 1. Dann setzt sich in Ceph die tatsächliche Nummer des PG zusammen, das heißt, das Objekt wird gerade pool_id+.+PG_idgespeichert In diesem PG wird dieses Objekt in diesem PG gespeichert. Der PG-Name in anderen Pools kann usw. sein.bar0.62foo0.A01.12f, 2.aa1,10.aa1
Physikalische Schicht in Ceph
In der Logikschicht ist bereits bekannt, wie eine Datei im PG in Ceph gespeichert wird. Einfach ausgedrückt, indem der Objektname gehasht und dann der Rest der Gesamtzahl der PG genommen wird, ist der Rest das entsprechende PG und wird dann gespeichert die Daten in dieser PG-Platzierungsgruppe.
Schauen Sie sich als Nächstes die physische Ebene in Ceph an. Es gibt mehrere Server und mehrere Festplatten auf dem Server. Normalerweise betrachtet Ceph eine Festplatte als OSD (tatsächlich ist OSD ein Programm, das Festplatten verwaltet) , sodass die physische Schicht aus mehreren OSDs besteht. Unser ultimatives Ziel ist um Objekte auf der Festplatte zu speichern. In der logischen Schicht werden Objekte im PG gespeichert, daher besteht die Aufgabe nun darin, den Tunnel zwischen PG und OSD zu öffnen. PG entspricht der Kombination einer Reihe von Objekten mit dem gleichen Rest. PG packt diesen Teil der Objekte. Jetzt müssen wir viele Pakete gleichmäßig auf jedes OSD legen. Das macht der CRUSH-Algorithmus: CRUSH berechnet die PG -> OSD- Zuordnung Beziehung
An diesem Punkt können durch Hinzufügen des Algorithmus vom Objekt der Logikschicht zum PG gerade zwei Formeln zusammengefasst werden:
- Pool-ID+HASH('Objektname') % PG_num --> PG_ID
- CRUSH(PG_ID) -> OSD
Hier werden zwei Algorithmen verwendet, HASH und CRUSH. Was ist der Unterschied zwischen diesen beiden Algorithmen? Warum können wir HASH(PG_ID) nicht direkt für das entsprechende OSD verwenden?
CURSH(PG_ID) ==> Wechsel zu HASH(PG_ID) % OSD_num ==> OSD
Das Folgende ist die Schlussfolgerung von Fat Brother:
- Wenn ein OSD aufgehängt ist, OSD_num = 1, ändert sich der Rest aller PG % OSD_num, dh die von diesem PG gespeicherte Festplatte hat sich geändert. Die einfachste Erklärung ist, dass die Daten auf diesem PG übertragen werden müssen Von einer Festplatte auf eine andere Festplatte sollte eine hervorragende Speicherarchitektur das Ausmaß der Datenmigration minimieren, wenn die Festplatte beschädigt ist. CRUSH kann dies tun.
- Wenn mehrere Kopien gespeichert werden, hoffen wir, mehrere OSD-Ergebnisausgaben zu erhalten. HASH kann nur eine erhalten, CRUSH jedoch eine beliebige Anzahl.
- Wenn die Anzahl der OSDs erhöht wird, erhöht sich OSD_num, was ebenfalls zu einer zufälligen Migration von PGs zwischen OSDs führt, CRUSH kann jedoch sicherstellen, dass die Daten gleichmäßig auf die neu hinzugefügten Maschinen verteilt werden.
Zusammenfassend lässt sich sagen, dass der HASH-Algorithmus nur für eine 1-zu-1-Zuordnungsbeziehung geeignet ist und die beiden berechneten Werte nicht geändert werden können, sodass er nicht für die PG -> OSD-Zuordnungsberechnung geeignet ist. Daher wird hier der CRUSH-Algorithmus vorgestellt.
CRUSH-Algorithmus
Ziel ist es hier nicht, den CRUSH-Quellcode im Detail vorzustellen, sondern den CRUSH-Algorithmus beispielhaft zu verstehen.
Schauen wir uns zunächst an, was zu tun ist:
- Ordnen Sie die vorhandene PG_ID dem OSD zu, und mit der Zuordnungsbeziehung kann ein PG auf einer Festplatte gespeichert werden.
- Wenn Sie drei Kopien speichern möchten, können Sie ein PG drei verschiedenen OSDs zuordnen und die drei OSDs speichern genau den gleichen PG-Inhalt.
Mal sehen, was da ist:
- PG_IDs, die sich voneinander unterscheiden;
- Wenn das OSD ebenfalls nummeriert ist, gibt es unterschiedliche OSD_IDs;
- Der größte Unterschied zwischen den einzelnen OSDs ist ihre Kapazität, d. h. die Kapazität von 4T oder 800 GB. Wir bezeichnen die Kapazität jedes OSD als das Gewicht des OSD. Es wird festgelegt, dass das Gewicht von 4T 4 und das von 800G beträgt ist 0,8, d. h. T Wert in Biteinheiten.
Jetzt wird das Problem wie folgt umgewandelt: Wie ordnet man PG_ID dem OSD mit seinem eigenen Gewicht zu? Der Strohalgorithmus im CRUSH-Algorithmus wird hier direkt verwendet, was in Lotterie übersetzt wird. Um es ganz klar auszudrücken: Es bedeutet, die längste Lotterie auszuwählen. Die Lotterie bezieht sich hier auf das Gewicht von OSD.
Dann können wir nicht jedes Mal das OSD mit der größten Kapazität auswählen. Können wir die Daten jede Minute im größten OSD speichern? Reiben Sie diese OSDs also ab, bevor Sie sie auswählen. Hier finden Sie eine direkte Einführung in den CRUSH-Algorithmus:
- CRUSH_HASH( PG_ID, OSD_ID, r ) ===> zeichnen
- (draw &0xffff) * osd_weight ===> osd_straw
- nimm high_osd_straw
Lassen Sie uns in der ersten Zeile r als Konstante behandeln, und die erste Zeile führt tatsächlich eine Reibungssache aus: Nehmen Sie PG_ID, OSD_ID und r zusammen als Eingabe von CRUSH_HASH und suchen Sie eine hexadezimale Ausgabe, die mit HASH (Objektname) identisch ist ) ist bis auf zwei weitere Eingaben genau gleich. Daher muss betont werden, dass für dieselben drei Eingaben die berechneten drawWerte gleich sein müssen.
Was nützt das draw? Tatsächlich hofft CRUSH, eine Zufallszahl zu erhalten, die hier ist draw, und diese Zufallszahl dann zu verwenden, um das Gewicht des OSD zu multiplizieren, sodass die Zufallszahl und das Gewicht des OSD aneinander gerieben werden, um die tatsächliche Signaturlänge zu erhalten Jedes OSD und jedes Zeichen hat eine andere Länge (große Wahrscheinlichkeit), sodass es einfach ist, das längste auszuwählen.
Um es ganz klar auszudrücken: CRUSH hofft, 随机ein OSD auszuwählen, muss aber auch das OSD mit einem größeren Gewicht zufriedenstellen, damit die Wahrscheinlichkeit, ausgewählt zu werden, größer ist. Um den Zweck der Zufälligkeit zu erreichen, lässt es jedes OSD sein eigenes Gewicht annehmen und multipliziere es mit einer Zufallszahl und nimm dann die Zahl mit dem größten Produkt. Deshalb haben wir uns hier ein kleines Ziel gesetzt: 100 Millionen Mal eines auswählen! Aus makroökonomischer Sicht wird es auch mit einer Zufallszahl multipliziert. Sobald die Stichprobengröße groß genug ist, hat die Zufallszahl keinen Einfluss mehr auf die Auswahlergebnisse. Der entscheidende Einfluss ist das Gewicht des OSD, d. h. Je höher das Gewicht des OSD ist, desto größer ist die Wahrscheinlichkeit, aus der Makroperspektive ausgewählt zu werden.
Es spielt keine Rolle, ob Sie den obigen Inhalt nicht verstehen. Hier finden Sie eine kurze Zusammenfassung dessen, was PG bei der Auswahl eines OSD tut:
- Geben Sie eine PG_ID als Eingabe von CRUSH_HASH an;
- CRUSH_HASH(PG_ID, OSD_ID, r) um eine Zufallszahl zu erhalten (der Schwerpunkt liegt auf Zufallszahlen, nicht auf HASH);
- Multiplizieren Sie für alle OSDs ihre Gewichte mit der Zufallszahl, die jeder OSD_ID entspricht, um das Produkt zu erhalten.
- Wählen Sie das OSD mit dem größten Produkt aus;
- Das PG wird im OSD gespeichert.
Durch die obige Beschreibung kann das Problem der Zuordnung eines PG zu mehreren OSDs bereits gelöst werden. Wenn r + 1 ist, berechnet die Konstante r die Zufallszahl erneut, multipliziert dann das Gewicht jedes OSD und wählt dann das größte Produkt If aus Die OSD-Nummer unterscheidet sich von der vorherigen OSD-Nummer. Wählen Sie sie aus. Wenn sie mit der vorherigen OSD-Nummer identisch ist, fügen Sie r+2 hinzu und wählen Sie erneut eine Zufallszahl, bis die drei verschiedenen Nummern ausgewählt sind, die wir benötigen. OSD bisher !
Natürlich ist der eigentliche Auswahlprozess etwas komplizierter. Ich verwende nur die einfachste Methode, um zu erklären, was CRUSH bei der Auswahl des OSD tut.
Anwendung des CRUSH-Algorithmus
Nachdem wir oben den Prozess der CRUSH-Auswahl des OSD verstanden haben, ist es für uns einfach, den CRUSH-Algorithmus weiter mit der tatsächlichen Struktur zu kombinieren. Hier ist ein Baumstrukturdiagramm, das Sage in seiner Doktorarbeit gezeichnet hat:
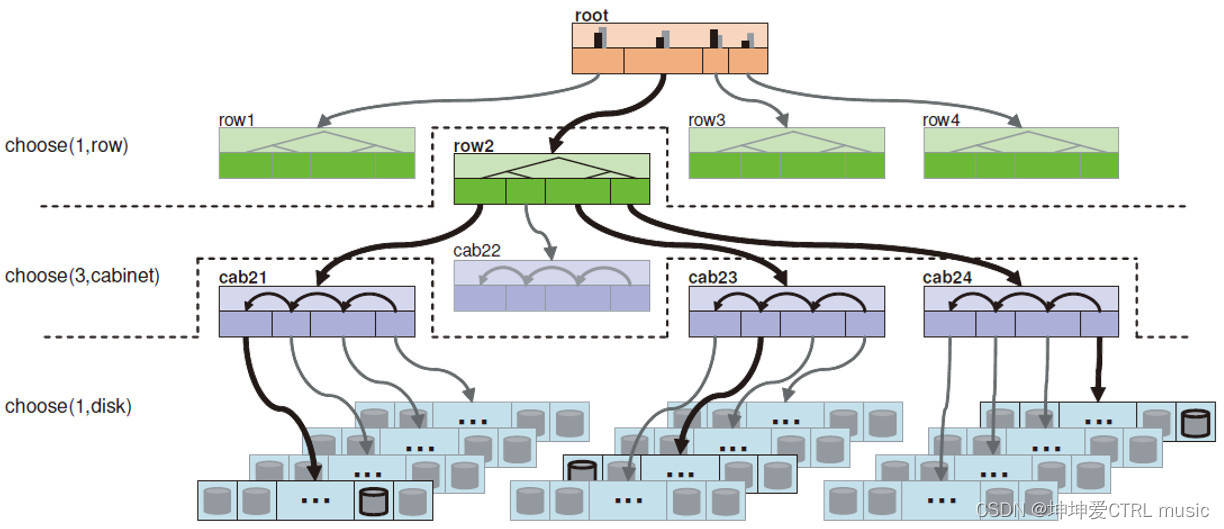
Die blauen Streifen unten können als Hosts betrachtet werden, die grauen Zylinder im Inneren können als OSDs betrachtet werden, die violetten Schränke können als Schränke betrachtet werden, die grüne Reihe kann als Schrankreihe betrachtet werden und die Wurzel oben ist Unser Wurzelknoten hat keine praktische Bedeutung. Sie können ihn sich als Rechenzentrum oder Computerraum vorstellen, aber er dient nur als Wurzelknoten einer Baumstruktur.
Basierend auf einer solchen Struktur zur Auswahl von OSD stellen wir neue Anforderungen:
- Insgesamt wurden drei OSDs ausgewählt;
- Diese drei OSDs müssen sich unter einer Reihe befinden;
- In jedem Schrank befindet sich höchstens ein OSD.
Wenn wir für solche Anforderungen die CRUSH-Methode zur Auswahl von OSD im vorherigen Abschnitt verwenden, können die zweite und dritte Anforderung nicht erfüllt werden, da die Verteilung von OSD zufällig ist.
Um eine solche Anforderung zu erfüllen, schauen Sie sich zunächst an, was dort steht:
- Das Gewicht jedes OSD;
- Jeder Host kann auch eine Gewichtung haben, die durch die Akkumulation der Gewichtungen aller OSDs im Host ermittelt wird;
- Das Gewicht jedes Schranks wird durch die Akkumulation der Gewichte aller Hosts ermittelt. Dies ist tatsächlich die Summe der Gewichte aller OSDs unter diesem Schrank.
- Auf die gleiche Weise wird das Gewicht jeder Reihe vom Schrank akkumuliert;
- Das Gewicht von Root ist eigentlich die Summe der Gewichte aller OSDs.
Daher hat in dieser Baumstruktur jeder Knoten sein eigenes Gewicht, und das Gewicht jedes Knotens wird 下一层durch Akkumulieren der Gewichte der Knoten erhalten. Daher ist das Gewicht des Wurzelknotens die Summe der Gewichte aller OSDs im Cluster. Wie wählen wir dann bei so vielen Gewichtungen diese drei OSDs aus?
Befolgen Sie die CRUSH-Methode, um das OSD auszuwählen:
- CRUSH wählt eine Zeile aus allen Zeilen unter root aus;
- Unter allen Schränken unter der Reihe wählt CRUSH gerade drei Schränke aus;
- Unter allen OSDs unter den drei Schränken wählt CRUSH gerade jeweils ein OSD aus.
Da jede Zeile ihre eigene Gewichtung hat, ist die Methode zur Auswahl einer Zeile mit CRUSH genau die gleiche wie die Methode zur Auswahl mit OSD. Multiplizieren Sie die Gewichtung der Zeile mit einer Zufallszahl, um das Maximum zu erhalten. Wählen Sie dann weiterhin drei Schränke unter dieser Reihe aus und wählen Sie dann unter jedem Schrank ein OSD aus.
Die grundlegende Bedeutung dabei ist, dass die Daten gleichmäßig auf alle OSDs im Cluster verteilt werden. Wenn das Gewicht der beiden Maschinen 16:32 beträgt, beträgt die Datenmenge, die auf die beiden Maschinen verteilt ist, ebenfalls 1:2. Gleichzeitig wurden durch diese Wahl die drei OSDs auf drei verschiedene Gehäuse verteilt.
In Kombination mit der Legende ist hier der Ablauf des CRUSH-Algorithmus:
- take(root) ============> [root]
- wähle(1, Zeile) ========> [Zeile2]
- wähle(3, Schrank) =====> [cab21, cab23, cab24] unter [Zeile2]
- Choose(1, osd) ========> [osd2107, osd2313, osd2437] unter drei Kabinen
- emittieren ================> [osd2107, osd2313, osd2437]
Hier sind zwei wichtige Konzepte des CRUSH-Algorithmus:
- BUCKET/OSD: OSD entspricht nacheinander unserer Festplatte, und Bucket besteht aus allen nicht untergeordneten Knoten außer OSD, wie z. B. Schrank, Zeile, Root usw. oben;
- REGEL: Die CRUSH-Auswahl folgt einem Auswahlpfad, und ein Auswahlpfad ist eine Regel.
REGEL ist im Allgemeinen in drei Schritte unterteilt: Nehmen -> N auswählen -> Ausgeben.
Der Take-Schritt ist für die Auswahl eines Wurzelknotens verantwortlich. Dieser Wurzelknoten muss nicht der Wurzelknoten sein, sondern kann auch ein beliebiger Bucket sein.
Was Choose N tut, ist die Auswahl qualifizierter Buckets entsprechend der Gewichtung jedes Buckets und jeder Choose-Anweisung, und das Auswahlobjekt der nächsten Auswahl ist das im vorherigen Schritt erhaltene Ergebnis.
emit dient dazu, das Endergebnis auszugeben, was dem Öffnen des Stapels entspricht.
Ceph-Architektur
Durch das obige Verständnis des Prinzips ist die Ceph-Architektur in der folgenden Abbildung leicht zu verstehen
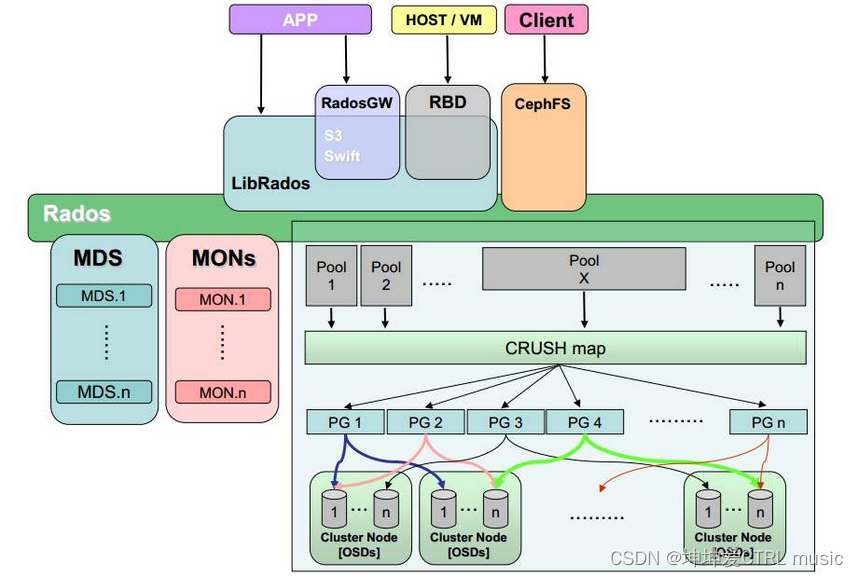
Von oben nach unten:
1. Ceph bietet 4 externe Schnittstellen:
- Die Anwendung greift direkt auf RADOS zu, was eine selbst entwickelte Aufrufschnittstelle erfordert, die für selbst entwickelte Zwecke geeignet ist.
- Objektspeicherschnittstelle, unterstützt (Amazon) S3- und Swift-Aufrufmethoden, geeignet zum Speichern von Objektspeichern wie Bildern, Videos usw.;
- Blockspeicherschnittstelle (RBD), die hauptsächlich externen Blockspeicher bereitstellt, z. B. Blockgerätespeicher für virtuelle Maschinen;
- Dateispeicher (CephFS), ähnlich dem über NFS bereitgestellten Verzeichnisspeicher.
2. Direkter Anwendungszugriff, Objektspeicher und Blockspeicher hängen alle von LibRados-Bibliotheksdateien ab
3. Die unterste Ebene von Ceph ist ein RADOS-Objektspeichersystem, das externe Dienste über das RADOS-Objektspeichersystem bereitstellt
4. MDS-Metadatenknoten, MON-Verwaltungskontrollknoten, viele Poolspeicherpools
5. Viele PG-Platzierungsgruppen werden in den Pool-Speicherpool aufgenommen, und dann werden die Daten im PG über den CRUSH-Algorithmus in jeder OSD-Gruppe gespeichert.
In den obigen Schritten müssen wir uns auf Punkt 5 konzentrieren. Wie oben erwähnt, ist in Ceph alles ein Objekt. Erhalten Sie zunächst eine Hexadezimalzahl, indem Sie den Objektnamen durch den HASH-Algorithmus übergeben, und nehmen Sie dann den Rest aus der Gesamtzahl der PGs im Pool. Der Rest muss auf einen Knoten in der Gesamtzahl der PGs fallen, und Ceph speichert ihn Daten des Objektnamens in In diesem PG wird ein Wert durch CRUSH_HASH(PG_ID, OSD_ID, r) berechnet, sodass die Daten auf OSD abgelegt werden können, und in Ceph ist OSD gleichbedeutend mit Festplatte. Dieser Vorgang wird grafisch dargestellt
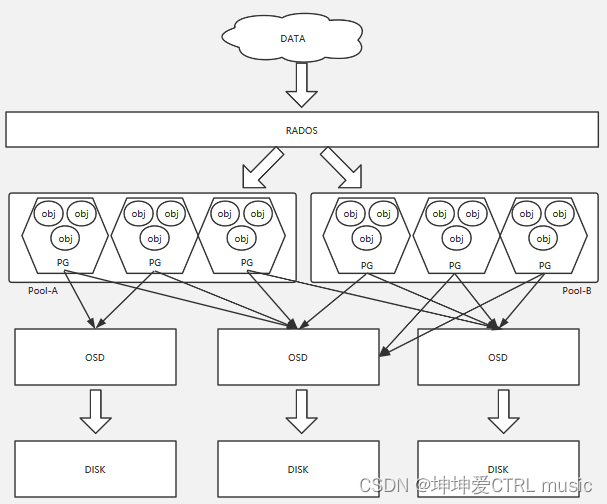
Ceph-Funktionen und Kernkomponenten
Ceph-Funktionen:
Hochleistung
- Durch den Verzicht auf das herkömmliche Adressierungsschema für zentralisierte Speichermetadaten und die Verwendung des CRUSH-Algorithmus ist die Datenverteilung ausgeglichen und der Grad der Parallelität hoch.
- Unter Berücksichtigung der Isolierung von Disaster-Recovery-Domänen ist es möglich, Replikatplatzierungsregeln für verschiedene Lasten zu implementieren;
- Es kann die Größe von Tausenden von Speicherknoten unterstützen und Daten auf TB- bis PB-Ebene unterstützen.
hohe Verfügbarkeit
- Die Anzahl der Kopien ist flexibel steuerbar;
- Unterstützt die Trennung von Fehlerdomänen und eine starke Datenkonsistenz.
- Automatische Reparatur und Selbstheilung in verschiedenen Fehlerszenarien;
- Kein Single Point of Failure, automatisch verwaltet.
hohe Expansion
- Native verteilte Dezentralisierung;
- Flexible Erweiterung;
- Sie wächst linear mit der Anzahl der Knoten.
Umfangreiche Funktionen
- Unterstützt drei Speicherschnittstellen: Blockspeicher, Objektspeicher und Dateispeicher;
- Unterstützt benutzerdefinierte Benutzeroberfläche und mehrere Sprachen.
Kernkomponenten:
Monitor
- Ein Ceph-Cluster erfordert einen kleinen Cluster aus mehreren Monitoren, um OSD-Metadaten zu speichern.
OSD
- Der vollständige Name von OSD lautet Object Storage Device. Dabei handelt es sich um den Prozess, der für die Rückgabe spezifischer Daten als Reaktion auf Client-Anfragen verantwortlich ist. Ein Ceph-Cluster verfügt im Allgemeinen über viele OSDs, und die endgültigen Ceph-Daten werden auch vom OSD auf der Festplatte gespeichert.
MDS
- Der vollständige Name von MDS lautet Ceph Metadata Server. Dabei handelt es sich um den Metadatendienst, von dem der CephFS-Dienst abhängt. Wenn Sie keinen Dateispeicher verwenden, ist keine Installation erforderlich.
Objekt
- Die Speichereinheit am unteren Ende von Ceph ist das Objektobjekt, und jedes Objekt enthält Metadaten und Originaldaten.
PG
- Der vollständige Name von PG lautet Placement Groups, was ein logisches Konzept ist. Ein PG enthält mehrere OSDs. Der Zweck der Einführung der PG-Schicht besteht darin, Daten besser zuzuordnen und zu lokalisieren.
ERSTELLT
- Der vollständige Name von RADOS lautet Reliable Autonomic Distributed Object Store und stellt die Essenz des Ceph-Clusters dar. Benutzer können Datenverteilung, Failover und andere Clustervorgänge implementieren.
Bibliothek
- Librados ist die von Rados bereitgestellte Bibliothek. Da RADOS ein Protokoll ist, auf das nur schwer direkt zugegriffen werden kann, erfolgt der Zugriff auf die obere Schicht RBD, RGW und CephFS alle über librados. Derzeit sind dies PHP, Ruby, Java, Python, C und C++ unterstützt.
ZERKLEINERN
- CRUSH ist ein von Ceph verwendeter Datenverteilungsalgorithmus, der dem konsistenten Hashing ähnelt und die Verteilung von Daten an den erwarteten Ort ermöglicht.
RBD
- Der vollständige Name von RBD lautet RADOS Block Device, ein von Ceph bereitgestellter Blockgerätedienst.
RGW
- Der vollständige Name von RGW lautet RADOS Gateway. Es handelt sich um einen von Ceph bereitgestellten Objektspeicherdienst. Die Schnittstelle ist mit S3 und Swift kompatibel. Wenn Sie keinen Objektspeicher verwenden, müssen Sie ihn nicht installieren.
CephFS
- Der vollständige Name von CephFS ist Ceph File System, ein von Ceph bereitgestellter Dateisystemdienst.