O desempenho é fundamental, e a melhoria do desempenho do sistema é a busca de todos os engenheiros. Atualmente, a otimização de desempenho se concentra na remoção de ineficiências na pilha de software do sistema ou em contornar operações de sistema de alta sobrecarga. Por exemplo, o desvio do kernel atinge esse objetivo movendo várias operações no espaço do usuário e refatorando o sistema operacional subjacente para certas classes de aplicativos.
Em muitas áreas, a especialização parece ser a resposta para um melhor desempenho, tanto na aplicação quanto no kernel, e até mesmo entre diferentes subsistemas do kernel. Em particular, a especialização pode construir o contexto no qual um aplicativo solicita determinada funcionalidade do sistema. Embora a especialização de aplicativos e o kernel ignorem o armazenamento, a rede e os aceleradores, o controle de simultaneidade no kernel pode ser crítico para o desempenho geral.

1. O desempenho do sistema operacional: bloqueio do kernel
Os bloqueios de kernel são um mecanismo para controlar o acesso do processo aos recursos compartilhados. No kernel do Linux, os bloqueios do kernel são implementados atribuindo um bloqueio especial no momento da criação do processo. Quando um processo precisar acessar um recurso compartilhado, o kernel verificará se o processo já possui o bloqueio, caso contrário, o processo será adicionado à fila aguardando o bloqueio e aguardará que outros processos liberem o bloqueio.
Bloqueios de kernel são críticos para alcançar um bom desempenho e escalabilidade de aplicativos.No entanto, as primitivas de sincronização de kernel geralmente são invisíveis e fora do alcance dos desenvolvedores de aplicativos. Projetar algoritmos de bloqueio e verificar sua exatidão já é um desafio, e aumentar a heterogeneidade do hardware torna ainda mais desafiador. A falta de conhecimento dos desenvolvedores sobre o ambiente no qual o bloqueio está operando, questões como inversão de prioridade e prioridade do detentor do bloqueio, é essencialmente uma falta de contexto.
Existe uma maneira de os aplicativos de espaço do usuário ajustarem o controle de simultaneidade no kernel?
Por exemplo, um usuário pode priorizar tarefas específicas ou chamadas de sistema que contêm um conjunto de bloqueios. Os usuários podem impor políticas específicas de hardware, como bloqueio com reconhecimento de multiprocessamento assimétrico, e podem priorizar leituras e gravações com base em uma determinada carga de trabalho. Pode ser possível melhorar ainda mais o desempenho do sistema se os desenvolvedores puderem ajustar os vários bloqueios no kernel, alterar seus parâmetros e comportamento e até mesmo alterar entre diferentes implementações de bloqueio.
A especialização de pilha de software é uma nova maneira de melhorar o desempenho do aplicativo, que propõe enviar código para o núcleo para fins de desempenho e melhorar a escalabilidade do aplicativo, evitando o gargalo de aumentar o número de núcleos. Com o tempo, até mesmo um kernel monolítico como o Linux começou a permitir que os aplicativos do espaço do usuário personalizem o comportamento do kernel. Os desenvolvedores podem usar o eBPF para personalizar o kernel para fins de rastreamento, segurança e até mesmo desempenho.
Além do eBPF, os desenvolvedores do Linux também estão usando o io_uring, um buffer de anel de memória compartilhado entre o espaço do usuário e o kernel, para acelerar as operações IO assíncronas. Além disso, os aplicativos de hoje podem lidar com paginação sob demanda inteiramente no espaço do usuário.
Os aplicativos controlam os mecanismos de simultaneidade do kernel subjacente, o que oferece várias oportunidades para designers de bloqueio e desenvolvedores de aplicativos.

2. Fechaduras: passado, presente e futuro
O hardware é um fator importante na determinação da escalabilidade dos bloqueios, afetando assim a escalabilidade do aplicativo. Por exemplo, com bloqueios baseados em fila, o tráfego excessivo pode ser reduzido quando vários encadeamentos adquirem bloqueios ao mesmo tempo. Ao mesmo tempo, os bloqueios hierárquicos usam lotes para minimizar o problema de quebra de linha de cache.
SHFLLock propõe uma nova ideia de projetar algoritmos de bloqueio ao desacoplar estratégias e implementações de bloqueio para obter menos sobrecarga de memória do kernel e degradação de desempenho. Principalmente introduz o conceito de um programa shuffler, que reordena a fila ou modifica o estado dos threads em espera. Embora o ShflLocks forneça uma maneira de aplicar a política, também há uma tentativa de focar em políticas comuns em um conjunto simples de APIs de aquisição/liberação de bloqueio. Para atender às necessidades do aplicativo, analisando os bloqueios de kernel específicos que afetam uma determinada carga de trabalho, os desenvolvedores de aplicativos devem definir suas políticas de maneira controlada e segura e atualizar dinamicamente as políticas de aquisição de bloqueio, usando o embaralhador para impor políticas.
3 Cenário Típico: Agendamento de Threads Aguardando Bloqueios
Os encadeamentos que aguardam um bloqueio podem ser escalonados de duas maneiras diferentes: escalonamento com reconhecimento de aquisição com base na ordem em que os bloqueios são adquiridos e escalonamento com reconhecimento de ocupação com base no tempo que o encadeamento gasta dentro da seção crítica.
3.1 Agendamento da percepção de aquisição
Interruptores de bloqueio, permitindo que os desenvolvedores alternem entre vários algoritmos de bloqueio. Destacam-se três situações:
Alterne de um design de bloqueio de leitor-gravador neutro para um design de leitor por CPU ou baseado em NUMA para cargas de trabalho de leitura intensiva. Por exemplo, falhas de página e enumeração de arquivos em um diretório. O outro caso é de um comutador de bloqueios de leitura/gravação neutro para bloqueios de gravação puros; um exemplo é criar vários arquivos em um diretório.
Mude de um design de bloqueio baseado em Numa para uma abordagem combinada com reconhecimento de Numa, em que o detentor do bloqueio executa operações em nome de threads em espera. Essa abordagem tem melhor desempenho porque remove pelo menos uma transferência em cache.
Alterne entre bloqueios bloqueadores e não bloqueadores e vice-versa, por exemplo, desativando a estratégia de parada/ativação da função de embaralhamento do SHFLLock, alternando leituras bloqueadoras para bloqueios leitura/gravação não bloqueadores (rwlock).
Essa abordagem traz dois benefícios: primeiro, os desenvolvedores podem remover a sincronização temporária, como usar bloqueios sem bloqueio e usar eventos de espera para implementar estratégias de parada/ativação, que são comumente usadas em sistemas de arquivos Btrfs. Em segundo lugar, permite que os desenvolvedores unifiquem o design de bloqueios multiplexando dinamicamente várias políticas.

3.1.1 Herança de bloqueio
Um processo pode adquirir vários bloqueios para executar uma operação. Por exemplo, um processo no Linux pode adquirir até 12 bloqueios (por exemplo, uma operação de renomeação) ou uma média de 4 bloqueios para executar operações de gerenciamento de memória ou metadados de arquivos.
Infelizmente, esse modo de bloqueio levanta o problema do bloqueio baseado em fila, onde alguns encadeamentos precisam esperar mais tempo para adquirir o bloqueio de nível superior, que é feito por outro encadeamento aguardando outro bloqueio. Por exemplo, suponha que o thread t1 deseja adquirir dois bloqueios, L1 e, em seguida, L2 como uma operação e t2 deseja apenas recuperar a operação em L1. Como esses protocolos de bloqueio são baseados em fifo, t1 pode obter L2 no final da fila enquanto t2 está esperando para obter L1. O desenvolvedor pode fornecer mais contexto ao kernel: ou t1 adquire todos os bloqueios juntos ou t1 declara os bloqueios que já possui, o que pode dar a ele uma prioridade mais alta para adquirir o próximo bloqueio L2.
Um aplicativo pode desejar priorizar um caminho de chamada do sistema ou um conjunto de tarefas para obter melhor desempenho. Os desenvolvedores podem fazer isso codificando o contexto de prioridade da tarefa e passando essas informações para os bloqueios afetados. Para chamadas de sistema, os desenvolvedores podem compartilhar informações sobre um conjunto de bloqueios e encadeamentos prioritários no caminho crítico. O programa shuffler priorizará esses threads sobre outros threads que aguardam o bloqueio do aplicativo especificado.
3.1.2 Expondo a Semântica do Agendador
Em geral, o excesso de recursos de hardware, como CPU ou memória, resulta em melhor utilização de recursos, tanto para sistemas de tempo de execução do espaço do usuário quanto para máquinas virtuais. Embora o excesso de assinaturas melhore a utilização do hardware, também introduz um problema de agendamento duplo. O hipervisor pode agendar uma vCPU para servir como detentor do bloqueio ou o próximo bloqueio na VM. O hipervisor pode expor informações de agendamento de vCPU ao programa shuffler para priorizar serviços com base em suas cotas de tempo de execução.
3.1.3 Estratégia de parada/vigília adaptável
Todas as fechaduras fechadas seguem a estratégia de estacionar após o rodízio, ou seja, param sozinhas após rodar por um determinado período de tempo. Esse tempo de rotação é principalmente ad-hoc, ou seja, o garçom gira por um determinado período de tempo de acordo com a cota de tempo ou continua girando se não houver tarefas a serem executadas. Os desenvolvedores de aplicativos agora podem expor o contexto temporal depois de analisar o comprimento de uma seção crítica para minimizar o consumo de energia e informações de ativação para agendar o próximo garçom no horário para minimizar a latência de ativação. Além disso, os desenvolvedores podem codificar ainda mais as informações do sono para ativar os garçons antes de bloquear para reduzir os longos atrasos no despertar. Essa abordagem também funciona com spinlocks paravirtualizados para evitar efeitos de comboio.
3.2 Agendamento de Ocupação
3.2.1 Herança Prioritária
A inversão de prioridade ocorre quando uma tarefa de baixa prioridade que mantém um bloqueio é agendada por uma tarefa de prioridade normal para aguardar o mesmo bloqueio. O problema é declarado na pilha de E/S do Linux: ao agendar uma solicitação de E/S, uma tarefa normal que deseja adquirir um bloqueio pode agendar uma tarefa em segundo plano de prioridade mais baixa que mantém o mesmo bloqueio. A programação de bloqueios é uma tarefa em segundo plano, o que leva a uma diminuição no desempenho do IO.
3.2.2 Agendamento cooperativo para justiça de tarefas
Isso introduz uma nova classe de problemas conhecida como problema de subversão do escalonador, em que duas tarefas adquirem bloqueios em momentos diferentes. Tarefas mantidas por muito tempo subvertem os objetivos de agendamento do sistema operacional. O sistema operacional resolve esse problema acompanhando os tamanhos das regiões críticas e penalizando as tarefas de execução longa. Embora essa solução resolva o problema, ela reforça a justiça de agendamento mesmo para aplicativos que podem não se beneficiar dela.
3.2.3 Bloqueio Justo de Tarefas em Máquinas Multiprocessadoras Assimétricas (AMP)
Com núcleos de diferentes potências computacionais em um processador, as primitivas básicas de travamento usadas nesta arquitetura sofrem de um problema de subversão do agendador onde a taxa de transferência do aplicativo pode colapsar devido à potência computacional mais lenta do núcleo mais fraco. Para obter processos mais rápidos, os desenvolvedores podem alocar bloqueios críticos em núcleos mais rápidos ou reordenar a fila de threads aguardando para adquirir bloqueios para melhorar o bloqueio geral.
3.2.4 Agendamento em tempo real
Semelhante ao agendamento em sistemas em tempo real, os desenvolvedores de aplicativos podem criar políticas de bloqueio que sempre agendam threads para garantir SLOs. Aqui, o bloqueio pode ser projetado como um algoritmo baseado na imparcialidade de fase. Essa abordagem também permite eliminar o jitter e garante um limite superior na latência de cauda para aplicativos de latência crítica.
3.3 Análise do bloqueio dinâmico
Os desenvolvedores de aplicativos podem configurar informações de arquivo sobre quaisquer bloqueios de kernel. Selecionar quais bloqueios configurar permite que os desenvolvedores configurem em diferentes níveis de granularidade. Por exemplo, eles podem configurar todos os spinlocks em execução no kernel, bloqueios em funções específicas, caminhos de código ou namespaces ou até mesmo instâncias de bloqueio individuais. Essa abordagem beneficia os desenvolvedores de aplicativos por serem capazes de entender melhor a sincronização subjacente, analisando apenas as partes de interesse.
Os desenvolvedores também podem raciocinar sobre contratos de desempenho que afetam o desempenho do aplicativo com base em certas garantias fornecidas por várias políticas de embaralhamento ou até mesmo conjuntos de políticas.
4. Uma estrutura de otimização para bloqueios de kernel
Redefina as decisões e os comportamentos usados pelos bloqueios do kernel e os exponha como APIs. O código definido pelo usuário substitui essas APIs expostas e os usuários podem personalizar a função de bloqueio de acordo com suas necessidades. Por exemplo, rodar antes de entrar na fila de espera pode ser uma API para que o usuário tome essa decisão. O usuário primeiro escreve seu próprio código para modificar o protocolo de bloqueio no kernel de acordo com o caso de uso e, em seguida, o sistema operacional substitui a função de bloqueio anotada dentro do kernel. O diagrama de fluxo é o seguinte:
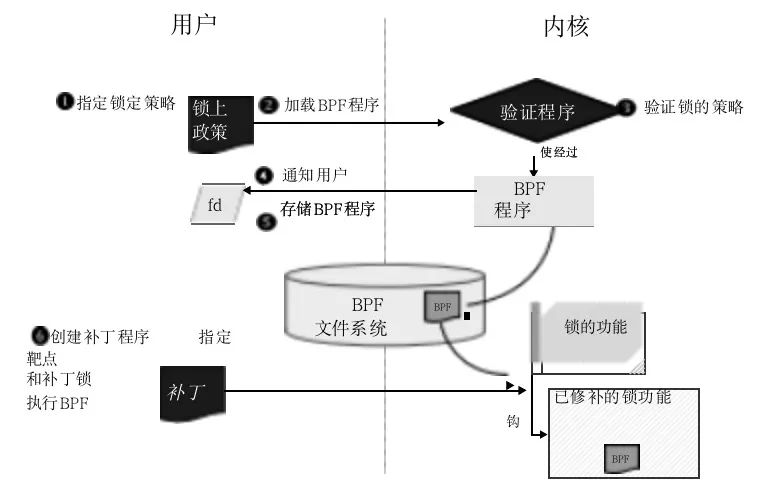
O usuário especifica uma política de bloqueio (1) e o verificador eBPF a verifica após a compilação, levando em consideração as restrições do eBPF e as propriedades de segurança de exclusão mútua (2, 3). O verificador notificará o usuário sobre o resultado da verificação (4) e, se for bem-sucedido, armazenará o código eBPF compilado no sistema de arquivos (5). Por fim, substitua a função anotada especificando a trava (6) pelo módulo de patch de campo.
4.1 API
Várias APIs oferecem suporte à implementação flexível de políticas de bloqueio, garantindo a segurança. A implementação subjacente do sistema operacional depende do eBPF para modificar o bloqueio do kernel. Usando eBPF e a API de bloqueio, a política desejada é implementada para um conjunto de instâncias de bloqueio no kernel. Um usuário pode codificar várias políticas, que são convertidas em código nativo e verificadas quanto à segurança pelos verificadores eBPF. Os verificadores executam a execução simbólica antes de carregar o código nativo no kernel, como controle de acesso à memória ou apenas funções auxiliares na lista de permissões.

4.2 Segurança
Além dos validadores eBPF, o ShflLocks possui uma fase separada para aquisição de bloqueio e uma fase para reordenar a fila de espera. O usuário depende da função da API para comparar o nó atual e o nó do shuffler e se deve reordenar o nó atual, e também pode projetar um bloqueio cooperativo do agendador para priorizar os nós com um tamanho de fatia crítico menor, reduzindo assim a prioridade do nó aula.
Embora as implementações de usuário incorretas possam quebrar a política garantida de equidade, a propriedade mutex pode ser verificada e garantida em tempo de execução. Além disso, o kernel não apresenta problemas de deadlock, a API não modifica o comportamento do bloqueio, apenas retorna a decisão de mover o nó. Os desenvolvedores podem configurar seus bloqueios de maneira refinada, implementando o comportamento desejado para cada chamada. Embora não altere o comportamento da função de bloqueio, a estratégia de análise do perfil de peso pode aumentar o comprimento da seção crítica, causando degradação do desempenho.
Além disso, o eBPF expõe a capacidade de encadear vários programas eBPF que os usuários podem usar para escrever políticas. Finalmente, também contamos com estruturas de dados de despacho de campo para modificar as estruturas de dados usadas pelas primitivas de bloqueio. Por exemplo, a estrutura de dados do nó de bloqueio baseada em fila pode ser estendida com informações adicionais usadas para codificar informações para casos de uso específicos. No pior caso, sem executar o código de espaço do usuário, modificar dinamicamente o algoritmo de bloqueio pode gerar até 20% de sobrecarga.
4.3 Estratégia de combinação
Ao ajustar os controles de simultaneidade do kernel, os aplicativos podem ter mais controle sobre a pilha de software. Os desenvolvedores de aplicativos fornecem um conjunto de políticas que requerem um bloqueio de aplicativo. Combinar várias estratégias é uma tarefa difícil, especialmente quando algumas estratégias podem entrar em conflito. Aproveitando a composição do programa para automatizar esse processo, pode ser possível mover as propriedades de segurança inteiramente para verificação no espaço do usuário e também fornecer uma maneira segura de compor políticas conflitantes.
Os usuários não podem adicionar muitas políticas porque sua execução pode cair no caminho crítico. Permite que um usuário privilegiado modifique o bloqueio do kernel, o modelo é apenas para um usuário usando todo o sistema. No entanto, para lidar com a multilocação em um ambiente de nuvem, é necessário um gravador de política com reconhecimento de locatário que não viole o isolamento entre os usuários. Sintetize as políticas no espaço do usuário para evitar tais conflitos e adicione verificações de tempo de execução aos algoritmos de bloqueio que são usados apenas quando as políticas podem afetar determinados comportamentos.
Além dos bloqueios, existem outros mecanismos de sincronização muito utilizados no kernel, como RCU, seqlocks, wait events e outras extensões que permitirão ainda mais que os aplicativos melhorem seu desempenho. Dito isso, os aplicativos de espaço do usuário também têm seus próprios bloqueios de natureza genérica. Por outro lado, as técnicas existentes, como a interpolação de bibliotecas, permitem apenas uma única alteração para diferentes implementações de bloqueio quando o aplicativo inicia a execução.
5. Resumo
As primitivas de sincronização bloqueadas pelo kernel têm um grande impacto no desempenho e na escalabilidade de alguns aplicativos; no entanto, o controle das primitivas de sincronização do kernel está fora do alcance dos desenvolvedores de aplicativos. Se o controle de simultaneidade contextual for usado, ele permite que os aplicativos do espaço do usuário ajustem as primitivas de simultaneidade do kernel. Essa é uma forma de pensar na especialização da pilha de software, que em parte acelera a inovação na área de sincronização de núcleo.
[Materiais de referência e leitura relacionada]
https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux. git/tree/include/uapi/linux/bpf.h?h=v5.4.
https://www.kernel.org/doc/html/latest/livepatch/shadow-vars.html.
https://github.com/antonblanchard/will-it-scale.
https://doi.org/10.1109/ECRTS.2009.14
https://www.kernel.org/doc/Documentation/locking/mutex-design.txt.
Kernel Live Patching, https://lwn.net/Articles/619390/
lockstat: documentação. https://lwn.net/Articles/252835/
http://www.brendangregg.com/blog/2019-12-02/ bpf-a-new-type-of-software.html.
Uma otimização de desempenho do python da perspectiva de um compilador
Um estudo preliminar sobre o Linux Kernel Clipping Framework