Introdução
Este projeto usa o conjunto de dados de atributos faciais CelebA para treinar o modelo de classificação de atributos faciais, usa mediapipe para detecção facial, usa onnxruntime para raciocínio de modelo e, finalmente, realiza um sistema completo de reconhecimento de atributos faciais em tempo real com 30-100 quadros na CPU Pentium da Intel . ps: originalmente planejei escrevê-lo como uma coluna paga. Afinal, este é um sistema que pode ser comercializado com uma pequena modificação. Não é um exemplo de brinquedo, mas considerando que o número de visualizações em breve ultrapassará 100.000, irei publicá-lo como um trabalho comemorativo.
ambiente de pacote python
Ambiente de treinamento:
python 3.9.12
maçarico 1.12.0+cu116
maçarico 0.13.0+cu116
modelo de exportação relacionado:
onnx 1.12.0
onnxruntime 1.14.0
ambiente do modelo de implantação:
onnxruntime 1.14.0
cv2(opencv-python) 4.7.0
mediapipe 0.9 .0.1
python3.10.6
Nota: Não há nenhum requisito específico para a versão. Ele foi escrito apenas para facilitar a verificação de bugs. Geralmente, você pode concluir este projeto com os pacotes acima. Se não houver pacotes, instale-o você mesmo com pip.
Preparação do conjunto de dados
Baixe manualmente o conjunto de dados CelebA

Digite o URL acima da captura de tela (o URL não é postado diretamente porque o link externo será reconhecido como uma regra estranha de artigos de baixa qualidade), clique no drive baidu na imagem e digite o código de extração:
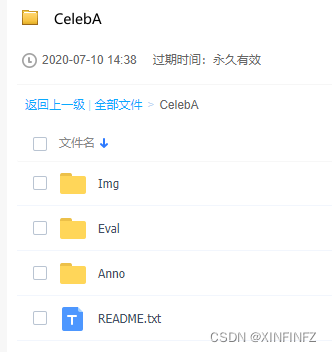
Baixe tudo nas pastas acima e junte-as, por exemplo, depois de baixar aqui, a estrutura é mostrada na figura abaixo, e nenhuma delas pode ser menor ou maior:
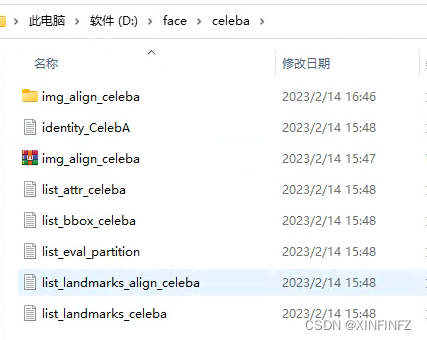
A pasta img_align_celeba fica depois que o pacote compactado é descompactado. A seguir está a foto do rosto diretamente, e não há diretório secundário:
carregar conjunto de dados
Primeiro, use o archvision para carregar diretamente o conjunto de dados, divida o conjunto de treinamento e teste o conjunto. Aqui o download está definido como False para indicar que você baixou manualmente e não precisa baixar automaticamente (a velocidade é muito lenta). Além disso, o caminho raiz é o caminho raiz do conjunto de dados, coloquei tudo aqui em D:/face/celeba, então o caminho raiz é escrever D:/face.
from torchvision import datasets
import torchvision.transforms as transforms
train_dataset = datasets.CelebA(root="D:/face",
split='train',
transform = transforms.Compose([
transforms.CenterCrop(128),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5, 0.5, 0.5],
std=[0.5, 0.5, 0.5])]),
download=False)
test_dataset = datasets.CelebA(root="D:/face",
split='test',
transform = transforms.Compose([
transforms.CenterCrop(128),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5, 0.5, 0.5],
std=[0.5, 0.5, 0.5])]),
download=False)
Aqui, três etapas de pré-processamento são realizadas no conjunto de dados, porque envolve a eliminação da tocha para o mesmo processamento no processo de raciocínio posterior, por isso precisa ser explicado em detalhes:
| frase | significado |
|---|---|
| transforms.CenterCrop(128) | Corte central da imagem 128 x 128 |
| transforma.ToTensor() | Divida o valor do pixel de 0-255 por 255 e converta-o em 0-1 |
| transforma.Normalize(média=[0,5, 0,5, 0,5],std=[0,5, 0,5, 0,5])]) | Subtraia 0,5 da média para três canais e divida por 0,5 desvio padrão |
Em seguida, usamos a classe dataloader da tocha para carregar formalmente o conjunto de dados para leitura:
import torch
train_dataloader = torch.utils.data.DataLoader(dataset=train_dataset, shuffle=True, batch_size=128,num_workers=4)
test_dataloader = torch.utils.data.DataLoader(dataset=test_dataset, shuffle=False, batch_size=128,num_workers=4)
Ajustei batch_size para 128 e num_workers para 4. Esses dois indicadores afetam a velocidade do treinamento. Se a configuração do computador não estiver boa, reduza-a apropriadamente. Se a configuração estiver boa, aumente a velocidade do treinamento. A própria quantidade de dados ainda é muito grande. 2 minutos.
Defina a classe do modelo
O modelo adota a arquitetura slimnet em 2017, que é uma rede muito leve. Se você estiver interessado em slimnet, procure artigos relacionados por conta própria. Aqui está o código diretamente:
import torch
import torch.nn as nn
import torch.nn.functional as F
class ConvBNReLU(nn.Sequential):
def __init__(self, in_planes, out_planes, kernel_size=3, stride=1, groups=1):
padding = (kernel_size - 1) // 2
super(ConvBNReLU, self).__init__(
nn.Conv2d(in_planes, out_planes, kernel_size, stride, padding, groups=groups, bias=False),
nn.BatchNorm2d(out_planes),
nn.ReLU(inplace=True)
)
class DWSeparableConv(nn.Module):
def __init__(self, inp, oup):
super().__init__()
self.dwc = ConvBNReLU(inp, inp, kernel_size=3, groups=inp)
self.pwc = ConvBNReLU(inp, oup, kernel_size=1)
def forward(self, x):
x = self.dwc(x)
x = self.pwc(x)
return x
class SSEBlock(nn.Module):
def __init__(self, inp, oup):
super().__init__()
out_channel = oup * 4
self.pwc1 = ConvBNReLU(inp, oup, kernel_size=1)
self.pwc2 = ConvBNReLU(oup, out_channel, kernel_size=1)
self.dwc = DWSeparableConv(oup, out_channel)
def forward(self, x):
x = self.pwc1(x)
out1 = self.pwc2(x)
out2 = self.dwc(x)
return torch.cat((out1, out2), 1)
class SlimModule(nn.Module):
def __init__(self, inp, oup):
super().__init__()
hidden_dim = oup * 4
out_channel = oup * 3
self.sse1 = SSEBlock(inp, oup)
self.sse2 = SSEBlock(hidden_dim * 2, oup)
self.dwc = DWSeparableConv(hidden_dim * 2, out_channel)
self.conv = ConvBNReLU(inp, hidden_dim * 2, kernel_size=1)
def forward(self, x):
out = self.sse1(x)
out += self.conv(x)
out = self.sse2(out)
out = self.dwc(out)
return out
class SlimNet(nn.Module):
def __init__(self, num_classes):
super().__init__()
self.conv = ConvBNReLU(3, 96, kernel_size=7, stride=2)
self.max_pool0 = nn.MaxPool2d(kernel_size=3, stride=2)
self.module1 = SlimModule(96, 16)
self.module2 = SlimModule(48, 32)
self.module3 = SlimModule(96, 48)
self.module4 = SlimModule(144, 64)
self.max_pool1 = nn.MaxPool2d(kernel_size=3, stride=2)
self.max_pool2 = nn.MaxPool2d(kernel_size=3, stride=2)
self.max_pool3 = nn.MaxPool2d(kernel_size=3, stride=2)
self.max_pool4 = nn.MaxPool2d(kernel_size=3, stride=2)
self.gap = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(192, num_classes)
def forward(self, x):
x = self.max_pool0(self.conv(x))
x = self.max_pool1(self.module1(x))
x = self.max_pool2(self.module2(x))
x = self.max_pool3(self.module3(x))
x = self.max_pool4(self.module4(x))
x = self.gap(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
device = torch.device('cuda')
model = SlimNet(num_classes=40).to(device=device)
Eu usei cuda training para o dispositivo aqui. Se você não tiver uma placa de vídeo Nvidia, escreva cpu. num_classes=40 significa que a saída final tem 40 recursos de atributos faciais. A seguir estão os recursos que traduzi para facilitar o entendimento:

Pode-se ver que finalmente somos uma tarefa de multiclassificação, mas a saída da rede aqui não é a classificação de 0,1, nem o valor de probabilidade de 0-1. É necessário usar a função sigmoide para converter para a possibilidade de 0-1 ao prever e, em seguida, use a classificação de 0,5.
rede de treinamento
Não vou entrar em detalhes sobre o processo de treinamento no meio. Eles são todos estereótipos pytorch. Deve-se notar que ao selecionar uma função de perda, você deve entender seu tipo de dados. Aqui, o destino é um tipo inteiro, que precisa para ser convertido para um tipo duplo para calcular a perda com a pontuação. Neste treinamento, um best_acc é definido manualmente para indicar a melhor precisão. Uma vez que a precisão seja melhor do que ao avaliar o conjunto de teste durante o treinamento, o modelo atual será salvo automaticamente.
loss_criterion = nn.BCEWithLogitsLoss() #定义损失函数
optimizer = torch.optim.Adam(model.parameters(), lr = 0.001) #定义优化器
best_acc = 0.90325 #最好的在测试集上的准确度,可手动修改
seed = 18203861252700 #固定起始种子
for epoch in range(50): #训练五十轮
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True#以上这些都是企图固定种子,但经过测试只能固定起始种子,可删掉
total_train = 0 #总共的训练图片数量,用来计算准确率
correct_train = 0 #模型分类对的训练图片
running_loss = 0 #训练集上的loss
running_test_loss = 0 #测试集上的loss
total_test = 0 #测试的图片总数
correct_test = 0 #分类对的测试图片数
model.train() #训练模式
for data, target in train_dataloader:
data = data.to(device=device)
target = target.type(torch.DoubleTensor).to(device=device)
score = model(data)
loss = loss_criterion(score, target)
running_loss += loss.item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
sigmoid_logits = torch.sigmoid(score)
predictions = sigmoid_logits > 0.5 #使结果变为true,false的数组
total_train += target.size(0) * target.size(1)
correct_train += (target.type(predictions.type()) == predictions).sum().item()
model.eval() #测试模式
with torch.no_grad():
for batch_idx, (images,labels) in enumerate(test_dataloader):
images, labels = images.to(device), labels.type(torch.DoubleTensor).to(device)
logits = model.forward(images)
test_loss = loss_criterion(logits, labels)
running_test_loss += test_loss.item()
sigmoid_logits = torch.sigmoid(logits)
predictions = sigmoid_logits > 0.5
total_test += labels.size(0) * labels.size(1)
correct_test += (labels.int() == predictions.int()).sum().item()
test_acc = correct_test/total_test
if test_acc > best_acc:
best_acc = test_acc
torch.save(model,f"model_{
test_acc*100}.pt")
print(f"For epoch : {
epoch} training loss: {
running_loss/len(train_dataloader)}")
print(f'train accruacy is {
correct_train*100/total_train}%')
print(f"For epoch : {
epoch} test loss: {
running_test_loss/len(test_dataloader)}")
print(f'test accruacy is {
test_acc*100}%')
Após o treinamento, você pode encontrar os seguintes arquivos no diretório, que são os bons modelos que encontramos durante o processo de treinamento, para posterior exportação:

Modelo de exportação onnx
O melhor é anotar no mesmo caderno acima, se salvar separado, precisa copiar e colar a parte que define a rede acima, caso contrário não encontrará a definição da rede.
torch_model = torch.load("model_90.56845506462278.pt", map_location='cpu')
torch_model.eval()
x = torch.randn(1, 3, 128, 128, requires_grad=True) #随机128x128输入
torch_out = torch_model(x)
print(torch_out)
# 导出模型
torch.onnx.export(torch_model, # 需要导出的模型
x, # 模型输入
"cpu.onnx", # 保存模型位置
export_params=True, # 保存训练参数
opset_version=10, # onnx的opset版本
do_constant_folding=True, # 是否进行常量折叠优化,这里开关都一样
input_names = ['input'], # 输入名字
output_names = ['output'], # 输出名字
)
ort_session = onnxruntime.InferenceSession("cpu.onnx",providers=['CPUExecutionProvider'])
#尝试进行推理看是否报错
def to_numpy(tensor):
return tensor.detach().cpu().numpy() if tensor.requires_grad else tensor.cpu().numpy()
ort_inputs = {
ort_session.get_inputs()[0].name: to_numpy(x)}
ort_outs = ort_session.run(None, ort_inputs)
print(ort_outs[0])
# 比较onnx模型推理的结果和torch推理的结果误差是否在可容忍范围内
np.testing.assert_allclose(to_numpy(torch_out), ort_outs[0], rtol=1e-03, atol=1e-05)
print("Exported model has been tested with ONNXRuntime, and the result looks good!")
Se tudo estiver ok, você encontrará o arquivo cpu.onnx no diretório:

Exemplo de inferência mínima de imagem
Copiamos diretamente a primeira imagem no conjunto de dados e a renomeamos como test_face.jpg

para raciocínio:
from PIL import Image
import torchvision.transforms as transforms
import onnxruntime
import torch
import numpy as np
img = Image.open("test_face.jpg")
comp = transforms.Compose([transforms.CenterCrop(128),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),]) #torch的预处理
img = comp(img)
img.unsqueeze_(0)
def to_numpy(tensor):
return tensor.detach().cpu().numpy() if tensor.requires_grad else tensor.cpu().numpy()
x = to_numpy(img)
ort_session = onnxruntime.InferenceSession("cpu.onnx")
ort_inputs = {
ort_session.get_inputs()[0].name: x}
ort_outs = ort_session.run(None, ort_inputs)
def sigmoid_array(x): #使用sigmoid转换概率值
return 1 / (1 + np.exp(-x))
result = sigmoid_array(ort_outs[0]) > 0.5
list_attr_cn = np.array(["早上刚刮下午长出来的一点胡子","拱形眉毛","有吸引力的","眼袋","秃头","刘海","大嘴唇"
,"大鼻子","黑发","金发","模糊的","棕发","浓眉","圆胖","双下巴","眼镜","山羊胡子","灰白发","浓妆","高高的颧骨",
"男性","嘴微微张开","胡子","眯眯眼","没有胡子","鹅蛋脸","苍白皮肤","尖鼻子","后退的发际线","红润脸颊",
"鬓角","微笑","直发","卷发","耳环","帽子","口红","项链","领带","年轻"])
print(list_attr_cn[result[0]])
Aqui estão os resultados:
['sobrancelhas arqueadas' 'atraente' 'cabelo castanho' 'maquiagem pesada' 'maçãs do rosto salientes' 'boca ligeiramente aberta' 'sem barba' 'nariz pontudo' 'sorriso' 'batom' 'jovem']
Com o exemplo do brinquedo, todo o sistema pode ser completado apenas adicionando alguns milhões de detalhes.
Detecção de rosto em vídeo em tempo real
Coloque o código diretamente. Se você quiser explicar muito em detalhes, não é tão conveniente quanto o comentário direto do código. Resumindo, use o opencv para ler o vídeo e desenhar o texto e use o Mediapipe para reconhecimento facial rápido.
import onnxruntime
import time
import numpy as np
import cv2
import mediapipe as mp
mp_face_detection = mp.solutions.face_detection
mp_drawing = mp.solutions.drawing_utils
cap = cv2.VideoCapture("test_face3.mp4") #视频输入,如果需要摄像头,请改成数字0,并修改下面的break为continue
ort_session = onnxruntime.InferenceSession("cpu.onnx")
list_attr_en = np.array(["5_o_Clock_Shadow","Arched_Eyebrows","Attractive","Bags_Under_Eyes","Bald",
"Bangs","Big_Lips","Big_Nose","Black_Hair","Blond_Hair","Blurry","Brown_Hair",
"Bushy_Eyebrows","Chubby","Double_Chin","Eyeglasses","Goatee","Gray_Hair",
"Heavy_Makeup","High_Cheekbones","Male","Mouth_Slightly_Open","Mustache","Narrow_Eyes",
"No_Beard","Oval_Face","Pale_Skin","Pointy_Nose","Receding_Hairline","Rosy_Cheeks",
"Sideburns","Smiling","Straight_Hair","Wavy_Hair","Wearing_Earrings","Wearing_Hat",
"Wearing_Lipstick","Wearing_Necklace","Wearing_Necktie","Young"]) #英文原版属性
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)) #获取视频宽度
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)) #获取视频高度
fps = cap.get(cv2.CAP_PROP_FPS) #获取视频FPS,如果是实时摄像头请手动设定帧数
out = cv2.VideoWriter('output3.avi', cv2.VideoWriter_fourcc(*"MJPG"), fps, (width,height)) #保存视频,没需求可去掉
def cv2_preprocess(img): #numpy预处理和torch处理一样
img = cv2.resize(img, (128, 128), interpolation=cv2.INTER_NEAREST)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
mean = [0.5,0.5,0.5] #一定要是3个通道,不能直接减0.5
std = [0.5,0.5,0.5]
img = ((img / 255.0 - mean) / std)
img = img.transpose((2,0,1)) #hwc变为chw
img = np.expand_dims(img, axis=0) #3维到4维
img = np.ascontiguousarray(img, dtype=np.float32) #转换浮点型
return img
def sigmoid_array(x): #sigmoid函数手动设定
return 1 / (1 + np.exp(-x))
def result_inference(input_array): #推理环节
ort_inputs = {
ort_session.get_inputs()[0].name: input_array}
ort_outs = ort_session.run(None, ort_inputs)
possibility = sigmoid_array(ort_outs[0]) > 0.5
result = list_attr_en[possibility[0]]
return result
with mp_face_detection.FaceDetection(
model_selection=1, min_detection_confidence=0.5) as face_detection:
#人脸识别,1为通用模型,0为近距离模型
while cap.isOpened():
a1 = time.time()
success, image = cap.read()
if not success:
print("Ignoring empty camera frame.")
break
image.flags.writeable = False #据说这样写可以加速人脸识别推理
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
results = face_detection.process(image)
image.flags.writeable = True
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)
image2 = image.copy() #copy复制,因为cv2会直接覆盖原有数组
if results.detections:
for detection in results.detections:
mp_drawing.draw_detection(image, detection)
image_rows, image_cols, _ = image.shape
location = detection.location_data.relative_bounding_box #获取人脸位置
start_point = mp_drawing._normalized_to_pixel_coordinates(location.xmin, location.ymin,image_cols,image_rows) #获取人脸左上角的点
end_point = mp_drawing._normalized_to_pixel_coordinates(location.xmin + location.width, location.ymin + location.height,image_cols,image_rows) #获取右下角的点
x1,y1 = start_point #左上点坐标
x2,y2 = end_point #右下点坐标
img_infer = image2[y1-70:y2,x1-50:x2+50].copy() #为了营造相似环境,把左上角和右上角的点连线囊括的区域扩大提高准确度
img_infer = cv2_preprocess(img_infer)
result = result_inference(img_infer)
# # cv2.imshow('test',img_infer)
# if cv2.waitKey(5) & 0xFF == 27:
# break
for i in range(0,len(result)):
image = cv2.putText(image, result[i],(x1,y1+i*40), cv2.FONT_HERSHEY_SIMPLEX,
1, (255,255,255), 1, cv2.LINE_AA) #画文字,一行一行画,如果想要中文请自行编译安装freetype版opencv,不推荐用别的库包裹转换中文,速度慢
a2 = time.time()
out.write(image)
print(f'one pic time is {
a2 - a1} s')
Além disso, a função fornecida pelo próprio mediapipe é desenhar os pontos-chave do rosto. Se você não quiser os pontos-chave, pode comentar como eu:
resultado final
O tempo de inferência testou vários vídeos. O tempo para um quadro completo desde a leitura até a detecção e desenho é de cerca de 0,01-0,035, que pode atingir 30-100 quadros por segundo.
Como você pode ver na foto abaixo, os atributos identificados são bastante precisos.A foto mostra uma jovem atraente com cabelos castanhos e sem barba. A barra de atributos muda porque as áreas capturadas pelo reconhecimento facial são diferentes e não há algoritmo para rastreamento facial.
