01
Introdução
Desde que o iQIYI lançou seu negócio de big data em 2012, ele construiu uma série de plataformas baseadas em serviços ecológicos de código aberto de big data, cobrindo todo o processo de big data, como coleta de dados, processamento de dados, análise de dados e aplicação de dados, fornecendo suporte para as decisões operacionais da empresa e vários negócios de inteligência de dados fornecem forte suporte. Com o crescimento contínuo da escala de dados e o aumento da complexidade computacional, como minerar rapidamente o valor potencial dos dados trouxe grandes desafios para a plataforma de big data.
Em resposta às necessidades de análise em tempo real de dados massivos, a equipe de big data lançou um projeto de aceleração de big data desde 2020, baseado na tecnologia de big data para acelerar a circulação de dados iQIYI e promover mais tomada de decisões operacionais em tempo real e muito mais distribuição eficiente de informações. Uma delas é promover a troca da análise de dados OLAP da engine Hive para a engine Spark SQL, que tem alcançado benefícios significativos, com aceleração de tarefas em 67% e economia de recursos em 50%, trazendo eficiência e aumento de receita para negócios como como BI, publicidade, associação e crescimento de usuários.
02
fundo
No estágio inicial da construção da plataforma de big data da iQIYI, uma infraestrutura de big data e data warehouse foram construídos com base no ecossistema Hadoop de código aberto, e o Hive foi usado principalmente para processamento e análise de dados. Hive é uma ferramenta de análise off-line baseada em Hadoop, que fornece uma linguagem SQL avançada para analisar dados armazenados no sistema de arquivos distribuído Hadoop: suporta mapeamento de arquivos de dados estruturados em uma tabela de banco de dados e fornece função de consulta SQL completa; suporta conversão de instruções SQL em Tarefas do Hadoop MapReduce para executar e analisar o conteúdo necessário por meio de consulta SQL, para que os usuários que não estão familiarizados com o Hadoop MapReduce possam facilmente usar a linguagem SQL para consultar, resumir e analisar dados. No entanto, a velocidade de processamento do Hive é relativamente lenta, especialmente ao processar consultas complexas com dados de grande escala.
Com o desenvolvimento dos negócios e o aumento do volume de dados, especialmente após o acesso de novos serviços sensíveis ao tempo, como lances inteligentes de publicidade, recomendação de fluxo de informações, operação de associação em tempo real e crescimento de usuários, usar o Hive para análise offline não pode mais atender aos requisitos de negócios para pontualidade de dados. necessidades sexuais. Para esse fim, introduzimos uma série de mecanismos OLAP mais eficientes, como Trino e ClickHouse, mas esses mecanismos são mais focados na análise de dados. base da Hive. superior. Portanto, como melhorar o desempenho do processamento e análise do Hive, de modo a realizar a aceleração geral do link de big data do iQIYI, tornou-se um problema urgente a ser resolvido.
03
Seleção de esquema
Investigamos várias alternativas convencionais, como Hive on Tez, Hive on Spark e Spark SQL, e as analisamos e comparamos sistematicamente em várias dimensões, como compatibilidade funcional, desempenho, estabilidade e custos de transformação e, finalmente, selecionamos o Spark SQL.
Colmeia em Tez
Esta solução usa o Tez como um mecanismo de execução conectável do Hive para substituir o MapReduce para executar tarefas. Tez é a estrutura de computação de código aberto do Apache que oferece suporte a tarefas DAG. Sua ideia principal é dividir ainda mais as duas operações de Map e Reduce para formar uma grande tarefa DAG. Comparado com o MapReduce, o Tez economiza muito armazenamento de dados intermediários desnecessários e processos de leitura e expressa diretamente em um trabalho o que o MapReduce requer a cooperação de vários trabalhos para ser concluído.
Vantagem:
Comutação insensível: a sintaxe do SQL ainda é Hive SQL, e o mecanismo de execução do Hive pode ser substituído pelo Tez do MapReduce por meio da configuração, e o aplicativo da camada superior não precisa ser modificado
Desvantagens:
Baixo desempenho: Este esquema tem baixa capacidade de processamento paralelo para conjuntos de dados em grande escala, e é óbvio quando ocorre distorção de dados
A comunidade não é ativa: o programa é relativamente pouco implementado na indústria e não há muitas trocas e discussões na comunidade
Altos custos de operação e manutenção: Quando o motor Tez funciona de forma anormal, há poucos materiais de referência
Colmeia no Spark
Esta solução usa o Spark como um mecanismo de execução conectável do Hive para substituir o MapReduce para executar tarefas. Spark é um mecanismo de processamento de dados em grande escala baseado em computação de memória. Comparado com MapReduce, Spark tem as características de escalabilidade, uso total de memória e modelos de computação flexíveis. É mais eficiente no processamento de tarefas complexas.
Vantagem:
Comutação insensível: a sintaxe do SQL ainda é Hive SQL, e o mecanismo de execução do Hive pode ser substituído pelo Spark do MapReduce por meio da configuração, e o aplicativo da camada superior não precisa ser modificado
Desvantagens:
Compatibilidade de versão insatisfatória: apenas o Spark 2.3 e inferior são suportados, e os novos recursos do Spark 3.xe superior não podem ser usados, o que não atende aos requisitos de atualização futura
Desempenho insatisfatório: Hive on Spark ainda usa Hive Calcite para analisar SQL em primitivas MapReduce, mas usa o mecanismo Spark em vez do mecanismo MapReduce para executar essas primitivas, e o desempenho não é muito ideal
A comunidade não é ativa: o programa raramente é implementado na indústria e a comunidade não é ativa
Aplicação de recursos inflexíveis: ao enviar tarefas do Spark na solução Hive on Spark, os recursos só podem ser definidos de forma fixa, o que é difícil de aplicar a cenários multilocatários e multifilas
Spark SQL
O Spark SQL é a solução do Spark para dados estruturados. Ele fornece sintaxe SQL compatível com Hive, suporta o uso de metadados Hive Metastore e pode fornecer funções de consulta SQL completas. Portanto, o data warehouse baseado em Hive ainda pode ser usado no cenário do Spark SQL, e a maioria das tarefas existentes do Hive SQL podem ser facilmente alternadas para o Spark SQL.
O Spark SQL converte instruções SQL em tarefas do Spark para executar e usa um modelo baseado em memória para organizar o cálculo e o cache de dados. Em comparação com a solução Hive on MapReduce que coloca dados intermediários no disco, a sobrecarga do Disk IO é menor e a eficiência da execução é maior.
Resumo da seleção
A tabela a seguir mostra a comparação detalhada entre Hive on MapReduce, Hive on Tez, Hive on Spark e Spark SQL. Pode-se ver que o Spark SQL é o mais adequado para o nosso cenário.
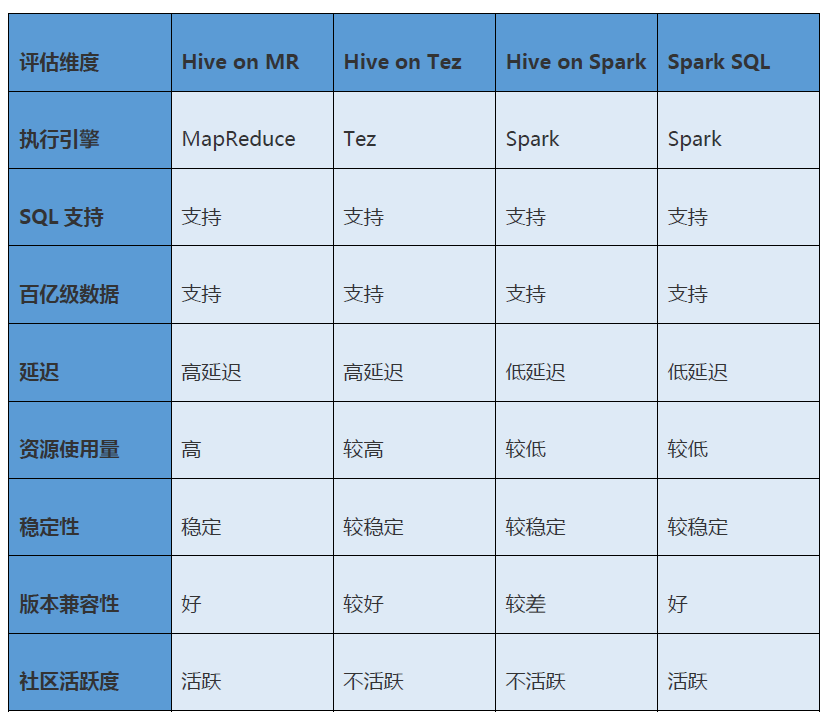
04
transformação técnica
A migração de Hive para Spark SQL enfrenta muitos desafios e trabalhos de transformação, incluindo transformação de compatibilidade Spark e otimização de desempenho, ajuste de sintaxe de tarefa SQL, garantia de consistência de dados, integração de sistema e transformação de dependência, etc.
Transformação de compatibilidade do Spark
Existem certas diferenças gramaticais entre o Spark SQL e o Hive SQL, e muitos problemas de compatibilidade foram encontrados durante o processo de migração. Interceptamos e reescrevemos o plano de execução de cada estágio do SQL por meio do método Spark Extension e percebemos a sintaxe, a lógica de execução e as funções do método , etc. A compatibilidade melhora a taxa de sucesso da migração.
Aqui estão algumas diferenças importantes:
Suporte UDF multi-threading: Anteriormente, UDFs no Hive não lançariam uma exceção ao processar datas do tipo SimpleDateFormat. No entanto, um erro será relatado ao executá-los com o Spark, porque o mecanismo Spark usa um método multi-threaded para executar tais funções. Esse problema pode ser resolvido modificando o código de UDF e definindo SimpleDateFormat como ThreadLocal.
Suporte a ID de agrupamento: Spark não oferece suporte a grouping_id do Hive e usa seu próprio grouping_id(), mas isso causará problemas de compatibilidade. Ao modificar o Spark, percebemos que grouping_id é convertido automaticamente em grouping_id() ao analisar SQL
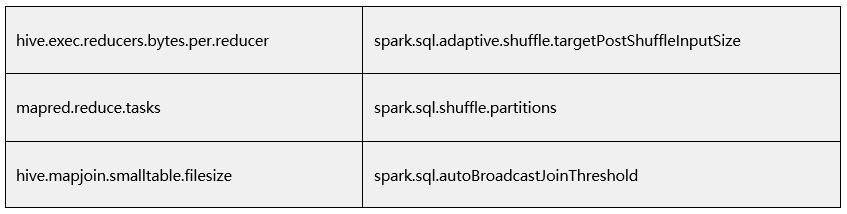
Compatibilidade de parâmetros: os parâmetros específicos do Hive precisam ser mapeados para os parâmetros correspondentes no Spark
Funções complicadas não podem ser alias: No Hive, se você não criar um alias para uma coluna calculada, o Hive fornecerá um nome de coluna começando com _c por padrão, mas o Spark não. Ao chamar algum Quando uma função que retorna uma vírgula (como get_json_object) , ele relatará um problema de que o número de colunas não corresponde. A sugestão alternativa para esta questão é criar um alias para todas as colunas, rejeitando um alias como _c0.
Não oferece suporte a funções permanentes: o motivo pelo qual o Spark não oferece suporte a funções permanentes é que o pacote jar não é baixado do HDFS no código. Além disso, a função temporária não precisa especificar o nome da biblioteca, mas a função permanente é necessária. Para promover a função permanente, uma função especial é adicionada: quando a função correspondente não pode ser encontrada na biblioteca atual, ela será procure a função permanente na biblioteca padrão.
O parâmetro reset não é suportado: há cenários em que o comando reset é usado para tarefas online. Modificamos o Spark para permitir que o Spark SQL suporte o comando reset.
Acenda a ativação de novos recursos e a otimização de configuração
Habilitar Estratégia de Alocação Dinâmica de Recursos (DRA): Tarefas se aplicam ou liberam Executores automaticamente de acordo com as necessidades do programa atual para alcançar o ajuste dinâmico de recursos, o que resolve o problema de alocação irracional de recursos. A recuperação automática de recursos ociosos reduz muito o desperdício de recursos do cluster.Além disso, ao limitar o número máximo de Executores, grandes consultas podem evitar o bloqueio de filas causado pela ocupação excessiva de recursos.
Ativar Adaptive Query Optimization (AQE): Registre indicadores estatísticos relevantes na fase de execução da tarefa e otimize o plano de execução na fase de execução subsequente com base nos indicadores estatísticos, como: mesclar dinamicamente pequenas partições Shuffle, selecionar dinamicamente a estratégia Join apropriada, e otimizar dinamicamente o particionamento distorcido, etc., melhora a eficiência do processamento de dados.
Mescle arquivos pequenos automaticamente: insira o operador Rebalance antes de escrever e combine com a otimização AQE do Spark para mesclar automaticamente pequenas partições e dividir grandes partições, resolvendo assim o problema de um grande número de arquivos pequenos.
Melhorias na Arquitetura do Spark
Em nosso cenário, o aplicativo envia tarefas SQL para Spark ThriftServer por meio de JDBC e, em seguida, acessa o cluster Spark. No entanto, o Spark ThriftServer oferece suporte apenas a um único usuário, o que limita a capacidade de vários locatários acessarem o Spark e apresenta problemas como baixa utilização de recursos e interferência mútua de UDF.
Para superar esses problemas, apresentamos o Apache Kyuubi. Kyuubi é uma solução Spark ThriftServer de código aberto que suporta o uso de uma SparkSession independente para processar solicitações SQL e tem os mesmos recursos do Spark Thrift Server. Comparado com o Spark ThriftServer, o Apache Kyuubi oferece suporte ao isolamento de usuários, filas e recursos e possui recursos baseados em plataformas e orientados a serviços.
Para o Apache Kyuubi, também fizemos algumas alterações personalizadas para atender melhor os cenários de produção:
Configuração baseada em tags: Para diferentes cenários ou plataformas computacionais, alguns tags são predefinidos para vincular algumas configurações específicas. Ao executar a tarefa, você só precisa trazer os tags correspondentes, e a configuração predefinida será complementada automaticamente no centro de configuração. Por exemplo: tarefas de consulta ad hoc, configurações como mecanismos compartilhados e grandes limites de consulta; tarefas ETL, configurações de mecanismos independentes e configurações de mesclagem de arquivos pequenos, etc.
Limite de simultaneidade: em algumas situações anormais, um cliente pode enviar um grande número de solicitações e o thread de trabalho do serviço Kyuubi pode estar totalmente ocupado. Em Kyuubi, implementamos restrições de simultaneidade nos níveis de usuário e IP para evitar que um usuário ou cliente envie um grande número de solicitações e faça com que o serviço fique cheio. Esse recurso também foi contribuído para a comunidade.
Coleta de eventos: Kyuubi expõe vários eventos em cada estágio da execução SQL. Por meio desses eventos, auditoria SQL e análise de exceção podem ser facilmente executadas, fornecendo bom suporte de dados para otimização de arquivos pequenos e otimização SQL.
05
Ferramenta de Migração Automatizada
Ao migrar do Hive para o Spark SQL, além de resolver os problemas de compatibilidade conhecidos acima, alguns problemas desconhecidos também podem ser encontrados. É necessário garantir que o mecanismo possa funcionar com sucesso após a troca, a troca não causará inconsistência de dados , e fornecer a capacidade de fazer downgrade automaticamente para a solução original para evitar afetar os dados online. O método comumente usado é geralmente dois conjuntos de motores executados logaritmicamente por um período de tempo e, em seguida, alternam depois que os resultados logarítmicos são consistentes.
Antes da mudança, mais de 20.000 tarefas do Hive estavam em execução na plataforma de big data e obviamente não era realista mudar para o Spark SQL uma a uma manualmente. Para melhorar a eficiência da migração, projetamos e desenvolvemos um conjunto de ferramentas de migração logarítmica e de mecanismo de comutação automática baseadas no Pilot.
O Pilot é um mecanismo SQL inteligente desenvolvido em conjunto pela equipe de big data da iQIYI e pela equipe de espelho mágico de BI. Ele fornece uma entrada unificada para análise de dados OLAP e integra vários mecanismos de análise OLAP, como Hive, Spark SQL, Impala, Trino, ClickHouse e Kylin. Suporta funções como roteamento automático, downgrade automático, limitação de corrente, interceptação, análise e diagnóstico inteligente e auditoria entre diferentes clusters/diferentes mecanismos. Atualmente, o Pilot está conectado a plataformas de desenvolvimento e análise de dados, como a plataforma de desenvolvimento de dados Babel, mecanismo de fluxo de trabalho de temporização Gear, plataforma de dados de publicidade, sistema de relatórios de portal de BI, espelho mágico, Paodingjian e centro de serviços de log Venus.
Ao alternar automaticamente o mecanismo SQL pelo Pilot, podemos alternar o Hive SQL para o Spark SQL sem a percepção do usuário, garantindo a consistência dos dados e tendo a capacidade de reverter:
Colete informações sobre as tarefas do Hive por meio do Pilot e obtenha informações como instruções SQL, filas e nomes de fluxo de trabalho
Análise SQL: Use SparkParser para analisar a instrução SQL da tarefa Hive, encontre o banco de dados, tabela de dados e outras informações correspondentes à entrada e saída
Crie uma tabela de mapeamento de saída: crie uma tabela de mapeamento para dados de saída para tarefas de execução dupla, diferencie-a da tabela de dados online e evite afetar os dados online
Substituição do mecanismo: substitua o mecanismo de execução da tarefa de execução dupla pelo Spark SQL
Execução de simulação: use os mecanismos Hive e Spark para executar as tarefas SQL correspondentes e envie os resultados da execução da tarefa para a tabela de mapeamento acima para verificação logarítmica
Verificação de consistência: execute a verificação de consistência de dados comparando o número de linhas e o código de redundância cíclica (baseado no algoritmo CRC32) das duas tabelas.
Entre eles, o algoritmo CRC32 é um algoritmo de verificação de dados simples e rápido. O Spark fornece a função integrada CRC32. O valor dessa função é do tipo Long e o valor máximo não excede 10^19. Em nosso cenário de aplicação, primeiro concat_ws os dados da coluna de cada linha da tabela para calcular seu CRC32, e converter o CRC32 para Decimal(19, 0); em seguida, somar os valores CRC32 calculados em cada linha da tabela para obter o valor refletido da soma de verificação CRC32 de todo o conteúdo da tabela é usado para comparação de consistência. A verificação SQL é especificamente:

Alguns campos na tabela de mapeamento são tipos de coleção, como Mapa e Lista, e haverá duas tabelas com os mesmos dados reais. Devido à diferença na classificação interna de dados dos campos do tipo coleção, os resultados estatísticos CRC32 serão compensados e afetam os resultados da verificação de consistência. Em resposta a tais situações, desenvolvemos uma UDF especial para realizar verificações de consistência após a classificação interna da coleção.

Alguns campos da tabela de mapeamento são do tipo ponto flutuante, como Float e Double. No processo de verificação da consistência dos dados, devido ao problema de precisão estatística, pode haver diferenças nos resultados estatísticos CRC32 das duas tabelas, resultando em erros de julgamento no processo de verificação de consistência. Por este motivo, otimizamos o algoritmo de verificação e, ao calcular o valor estatístico CRC32, 4 dígitos após a vírgula são reservados para o campo de ponto flutuante.

Downgrade automático: quando a tarefa do Hive mudar para SparkSQL e não for executada, ela será automaticamente rebaixada para o Hive por meio do Pilot e reenviada para execução, garantindo que a tarefa possa ser executada sem problemas, não importa o que aconteça.
Fornecemos um meio baseado em plataforma para executar o processo acima: os usuários encontram o fluxo de trabalho ao qual pertencem de acordo com o nome do projeto.

Configuração simples do projeto, entrada de parâmetros públicos a serem usados quando a simulação da tarefa for executada.
Durante o estágio de operação de simulação, ele suporta o monitoramento do status da operação

Após a execução da simulação, um conjunto de tarefas com condições de migração pode ser obtido. Com base nisso, a migração com um clique pode ser realizada por meio de operações simples.
06
efeito de transferência
Após um período de trabalho árduo, migramos sem problemas 90% das tarefas do Hive para o Spark SQL e obtivemos benefícios óbvios. O desempenho da tarefa aumentou em 67%, o uso da CPU foi reduzido em 50% e o uso de memória foi reduzido em 44%.
Aqui estão alguns efeitos de negócios:
Publicidade: o desempenho geral das tarefas off-line é aprimorado em cerca de 38%, os recursos de computação são economizados em 30%, a eficiência da computação é aumentada em 20% e a saída de dados de publicidade é acelerada para aumentar a receita
BI: O consumo total de tempo é reduzido em 79%, os recursos são economizados em 43% e a pontualidade de saída das tarefas P0 é garantida.Relatórios principais são produzidos meia hora a uma hora antes.
Crescimento do usuário: a produção de dados é avançada em 2 horas, ajudando os relatórios principais de crescimento do usuário a serem produzidos antes das 10:00, melhorando a eficiência operacional do UG
Membros: a produção de dados do pedido é produzida 8 horas antes e a velocidade da análise de dados é aumentada em mais de 10 vezes, ajudando os membros a melhorar a eficiência da análise operacional
iQiyi: O tempo médio de execução é reduzido em 40% e o tempo de execução diário é reduzido em cerca de 100 horas
07
Plano futuro
Atualizar ferramenta de migração
Para algumas tarefas do Hive que não atendem às condições para uma migração suave, elas precisam ser reescritas em SQL compatível com a sintaxe Spark SQL antes de continuar a migração. Estamos aprimorando a ferramenta de migração para oferecer suporte à extração de informações de erro chave para tarefas com falha e correspondência automática tags de causa raiz de diagnóstico, dando sugestões de otimização e até reescrita automática para ajudar a acelerar a migração.
otimização do motor
No nível do motor Spark, ainda existem alguns problemas que precisam ser acompanhados e otimizados:
Problema de armazenamento maior: Devido à introdução de Repartição na otimização de arquivos pequenos, os dados são fragmentados, resultando em uma redução na taxa de compactação de dados gravados por algumas tarefas. Pesquisas de acompanhamento sobre otimização de ordem Z fornecidas pela comunidade serão otimizar automaticamente a distribuição de dados.
O DPP torna a análise SQL muito lenta: durante a migração, descobriu-se que a otimização DPP pode levar a uma análise SQL muito lenta de algumas junções de várias tabelas. Atualmente, esse problema é evitado limitando o número de junções otimizadas para DPP. Em Spark 3.2 e versões subsequentes, a análise do Spark SQL é acelerada e também existem alguns patches relacionados, que estão planejados para serem analisados e aplicados à versão atual.
Indicadores de missão crítica perfeitos: Coletamos alguns indicadores de execução do Spark SQL no lado da plataforma, como: tamanho do arquivo de entrada e saída e número de arquivos, e o tempo de execução de cada estágio do Spark SQL, etc., para que possamos veja intuitivamente tarefas problemáticas e algumas otimizações Efeito. No futuro, esses indicadores precisam ser aprimorados, como: Shuffle data volume, data skew, data expansion e outros indicadores, e explorar mais métodos de otimização para melhorar a eficiência de cálculo do Spark SQL.
motor de teste de simulação
Em cenários como atualizações de versão de serviço, otimização de parâmetro do mecanismo SQL e migração de cluster, muitas vezes é necessário executar novamente testes em dados de negócios para garantir a precisão e a consistência do processamento de dados. O método tradicional de teste de reexecução depende do pessoal da empresa para projetar e implementar manualmente, o que geralmente é ineficiente.
A ferramenta de simulação de execução dupla do Pilot pode resolver os pontos problemáticos acima. Planejamos fornecer essa ferramenta independentemente como um serviço e transformá-la em um mecanismo de teste de simulação mais geral para ajudar os usuários a criar rapidamente tarefas de execução dupla e executar logaritmos automatizados.