Este artigo enfoca a prática de construção do sistema de recuperação de desastres do banco de dados da Meituan. O conteúdo principal inclui arquitetura de negócios, capacitação da plataforma de recuperação de desastres do banco de dados, construção do sistema de perfuração e algumas conquistas dessas construções. Finalmente, ele compartilhará o pensamento futuro da construção de recuperação de desastres . Espero que possa ser útil ou inspirador para todos.
1 Introdução à recuperação de desastres
2 Arquitetura de recuperação de desastres de negócios
2.1 Evolução da arquitetura de recuperação de desastres
2.2 Arquitetura Meituan de Recuperação de Desastres
3 Construção de recuperação de desastres de banco de dados
3.1 Desafios
3.2 Alta Disponibilidade Básica
3.3 Caminho de construção de recuperação de desastres
3.4 Capacitação da plataforma
3.5 Construção do sistema de perfuração
4 pensamento futuro
4.1 Compensar as deficiências
4.2 Arquitetura iterativa
1 Introdução à recuperação de desastres
Normalmente, dividimos as falhas em três categorias: uma são as falhas do host, a outra são as falhas da sala de computadores e a terceira são as falhas regionais. Cada tipo de falha tem seus próprios fatores de desencadeamento e, do mainframe à sala de computadores e à região, a probabilidade de falha é cada vez menor, mas o impacto da falha é cada vez maior.
O objetivo de construir a capacidade de recuperação de desastres é muito claro, que é ser capaz de enfrentar e lidar com essas falhas de grande escala no nível da sala de informática e no nível regional, de modo a garantir a continuidade dos negócios. Nos últimos anos, houve muitas falhas no nível do data center no setor, que tiveram um impacto negativo muito grande nos negócios e na marca das empresas relacionadas. A atual capacidade de recuperação de desastres tornou-se uma obrigação para muitas empresas de TI construir sistemas de informação.

2 Arquitetura de recuperação de desastres de negócios
2.1 Evolução da Arquitetura de Recuperação de Desastres
A arquitetura de recuperação de desastres evoluiu do primeiro modo ativo único (backup ativo na mesma cidade) para o modo multiativo na mesma cidade e, em seguida, evoluiu para multiativo remoto. De acordo com esse caminho, a recuperação de desastres pode ser dividida em três tipos: recuperação de desastres 1.0, recuperação de desastres 2.0 e recuperação de desastres 3.0.
Recuperação de desastres 1.0 : O sistema de recuperação de desastres gira em torno da construção de dados e é implantado principalmente em modo de espera ativa, mas a sala de computadores de backup não suporta tráfego e é basicamente uma estrutura ativa única.
Recuperação de desastres 2.0 : A perspectiva de recuperação de desastres é transformada de dados para sistema de aplicação. O negócio tem a capacidade de ativo-ativo na mesma cidade ou multi-ativo na mesma cidade. Adota a arquitetura de implantação de ativo-ativo no mesma cidade ou ativo-ativo na mesma cidade mais cold backup remoto (dois locais e três centros) Todas as salas de computadores, exceto as que possuem capacidade de processamento de tráfego.
Disaster Recovery 3.0 : Centrado no negócio, adota principalmente uma arquitetura unitizada. A recuperação de desastres é realizada com base em backup par a par entre as unidades. De acordo com o local de implantação da unidade, pode realizar multiativos na mesma cidade e multiativos em lugares diferentes. Os aplicativos que usam uma arquitetura unificada têm bons recursos de expansão e recuperação de desastres.
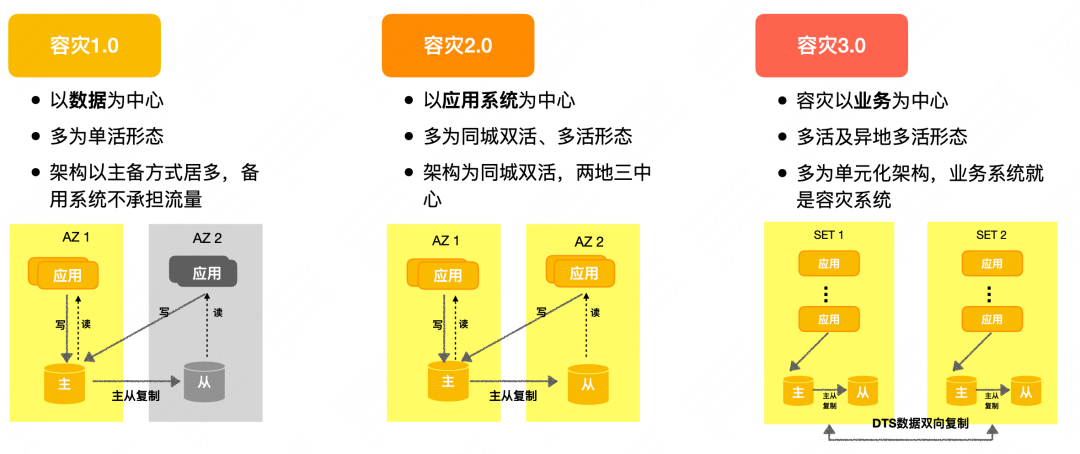
Devido aos diferentes estágios de desenvolvimento de cada empresa, as soluções adotadas também serão diferentes. A maioria dos negócios da Meituan está no estágio 2.0 (ou seja, a mesma cidade com estrutura dual-ativa ou multi-ativa), mas para grandes, recuperação de desastre regional e expansão regional As empresas com altos requisitos de segurança estão no estágio de recuperação de desastre 3.0. A seguir apresentará a arquitetura de recuperação de desastres da Meituan.
2.2 Arquitetura Meituan de Recuperação de Desastres
A arquitetura de recuperação de desastres da Meituan inclui principalmente dois tipos, um é a arquitetura de recuperação de desastres N+1 e o outro é a arquitetura SET.
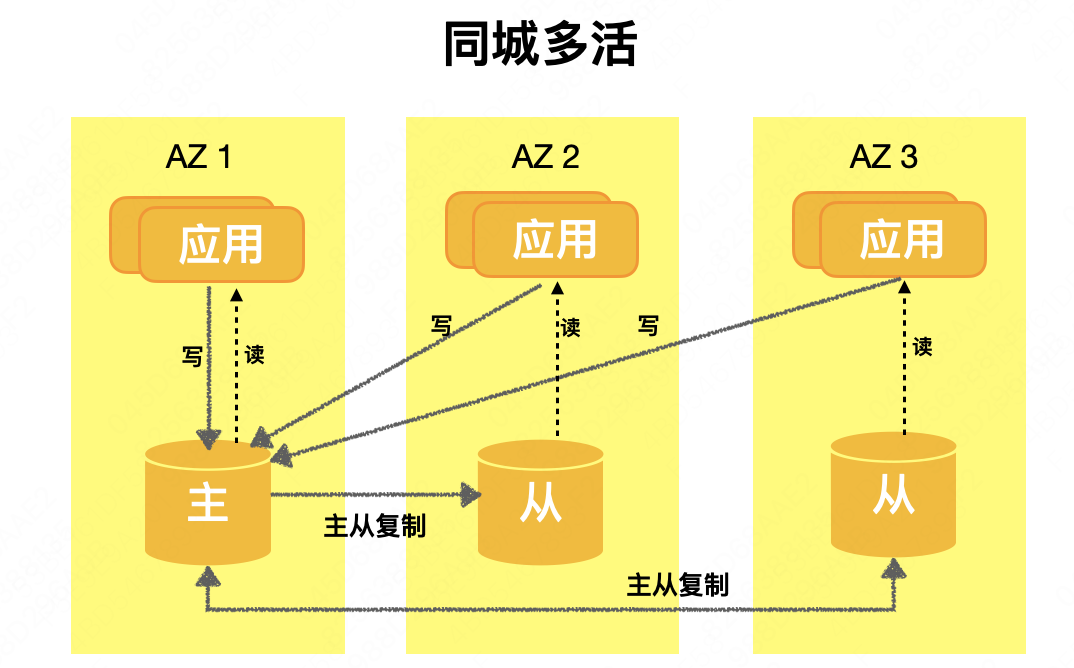
Arquitetura N+1 : no setor, também é chamada de solução de implantação dispersa ou multi-AZ. Um sistema com capacidade C é implantado em salas de computadores N+1. Cada sala de computadores pode fornecer pelo menos capacidade C/N. Quando qualquer sala de informática é suspensa, o sistema restante ainda pode suportar a capacidade de C. O núcleo desta solução é transferir a capacidade de recuperação de desastres para os componentes de PaaS. Quando ocorre uma falha no nível da sala de equipamentos ou no nível regional, cada componente de PaaS conclui independentemente a transição de recuperação de desastres para realizar a recuperação de negócios. A arquitetura geral é mostrada na figura abaixo. O desempenho do negócio é multi-computer rooms e multi-active. O banco de dados adota esta arquitetura mestre-escravo. Uma única sala de computador lida com o tráfego de gravação e o tráfego de leitura com balanceamento de carga das salas com vários computadores . A seguinte "Prática de construção do sistema de recuperação de desastres de banco de dados" é orientada para a arquitetura N+1.
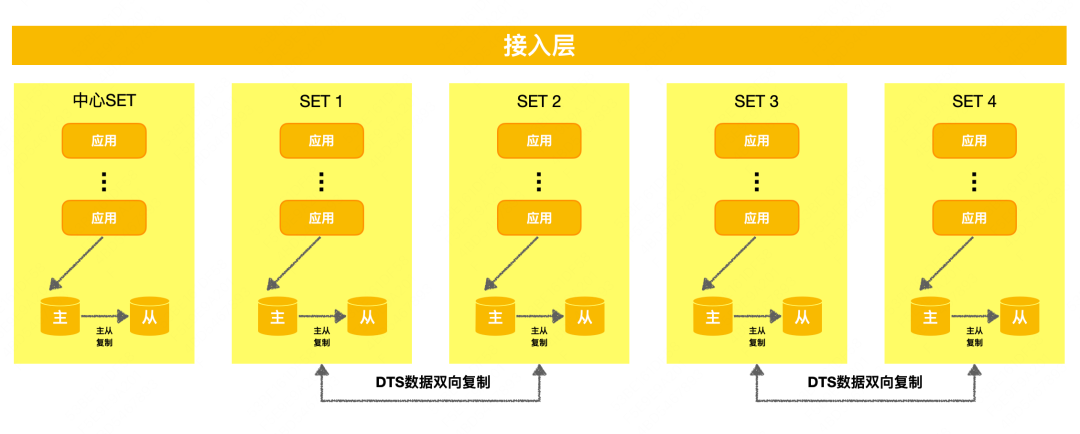
Arquitetura unitizada : também chamada de arquitetura baseada em SET, esta é uma arquitetura de recuperação de desastres que é parcial para a camada de aplicativos. Ela divide aplicativos, dados e componentes básicos em várias unidades de acordo com uma dimensão unificada, e cada unidade lida com uma parte -tráfego de loop. A empresa usa a unidade como unidade de implantação e realiza a recuperação de desastres na mesma cidade ou em um local diferente por meio de backup mútuo das unidades. Negócios financeiros em geral ou negócios de grande escala escolherão esse tipo de arquitetura. Sua vantagem é que o tráfego pode ser de loop fechado e os recursos são isolados, além de ter fortes recursos de recuperação de desastres e expansão entre domínios. No entanto, a implementação de A arquitetura baseada em SET requer muitos sistemas de negócios. Transformação, operação e gerenciamento de manutenção também são mais complicados. O diagrama simplificado é o seguinte:
A maioria dos negócios internos da Meituan tem uma estrutura N+1, e negócios como entrega de alimentos e finanças adotaram uma estrutura unificada. Em geral, Meituan tem multiatividade dentro da cidade e multiatividade remota, e as duas soluções de recuperação de desastres coexistem.
3 Construção de recuperação de desastres de banco de dados
| 3.1 Desafios
Desafios trazidos por clusters de grande escala : os negócios da empresa estão se desenvolvendo rapidamente, a escala de servidores está aumentando exponencialmente e a escala de data centers está ficando cada vez maior. Existem milhares de clusters de banco de dados e dezenas de milhares de instâncias em a grande sala de informática.
Problema de desempenho : há um gargalo óbvio na capacidade de processamento de falha simultânea do sistema de alta disponibilidade.
Risco de falha de recuperação de desastres : O link de gerenciamento e controle torna-se cada vez mais complexo com o aumento do número de clusters, e um problema em um link levará à falha da capacidade geral de recuperação de desastres.
Falhas frequentes : O número e a escala de clusters aumentaram, fazendo com que falhas em grande escala com baixa probabilidade se tornem falhas comuns, e a frequência e a probabilidade de ocorrência estão ficando cada vez maiores.
O custo dos exercícios é alto e a frequência é baixa : a verificação dos recursos principais é insuficiente, a capacidade de responder a falhas em grande escala está em um estado desconhecido e é difícil "manter atualizado" os recursos conhecidos de recuperação de desastres. Tomando as capacidades relevantes para lidar com falhas em larga escala no nível da sala de informática, uma grande parte está em um estado desconhecido ou existe apenas na análise do "papel", e para as capacidades verificadas à medida que a arquitetura evolui e itera, o "frescor" é também muito importante. dificuldade.
Como um dos serviços com estado, o próprio banco de dados é relativamente mais difícil e desafiador para construir a capacidade de lidar com falhas em grande escala.
| 3.2 Alta Disponibilidade Básica
Existem duas arquiteturas de banco de dados principais no Meituan, uma é a arquitetura mestre-escravo e a outra é a arquitetura MGR.
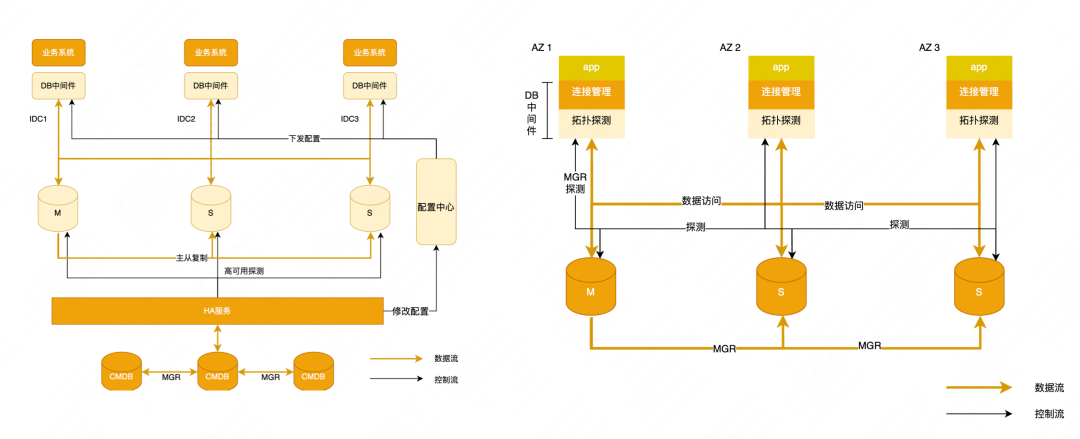
Arquitetura mestre-escravo : os aplicativos acessam o banco de dados por meio de middleware de banco de dados. Quando ocorre uma falha, a alta disponibilidade é usada para detecção de falhas, ajuste de topologia, entrega de configuração e recuperação de aplicativos.
Arquitetura MGR : O aplicativo também acessa o banco de dados através do middleware, mas o middleware é adaptado para MGR. O nome interno é Zebra para MGR. O middleware realiza automaticamente a detecção e percepção da topologia. Uma vez que o MGR é trocado, a nova topologia será detectada e o fonte de dados Ajustes serão feitos e os negócios serão retomados.
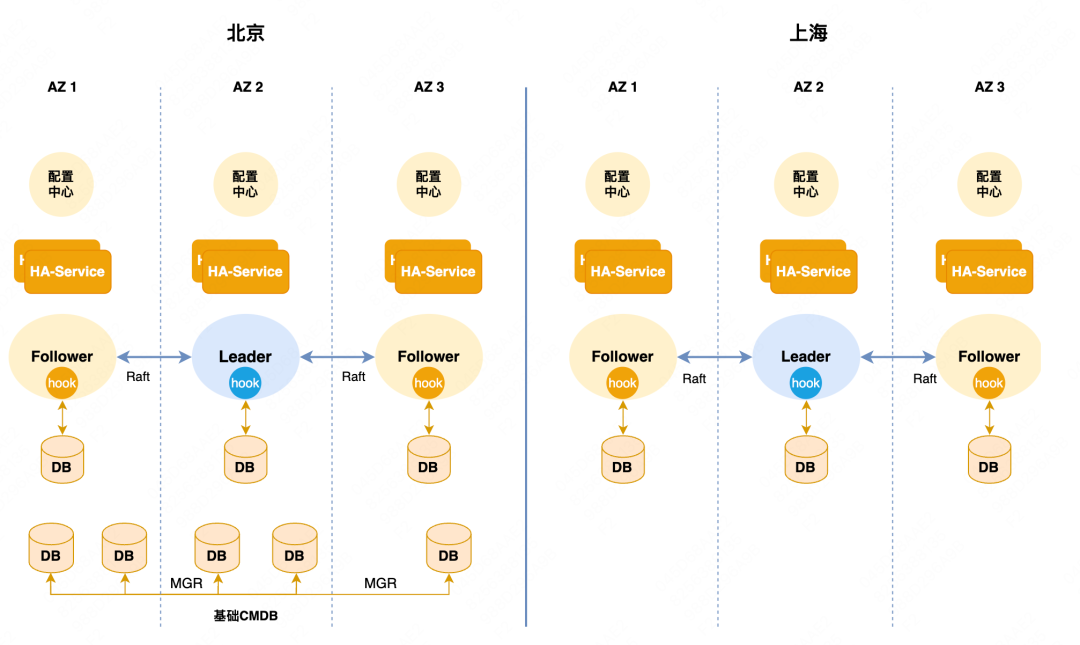
Arquitetura de alta disponibilidade da Meituan : A alta disponibilidade do cluster mestre-escravo da Meituan é baseada no desenvolvimento secundário do Orchestrator. É essencialmente uma arquitetura centralizada de gerenciamento e controle. Conforme mostrado na figura abaixo, existem vários grupos de alta disponibilidade e cada grupo hospeda uma parte Os clusters de banco de dados são implantados em Pequim e Xangai em duas regiões. Os componentes principais subjacentes são implantados apenas em Pequim, como nosso CMBD principal, WorkflowDB etc. a disponibilidade no lado de Xangai falhará e ficará indisponível.
3.3 Caminho de construção de recuperação de desastres
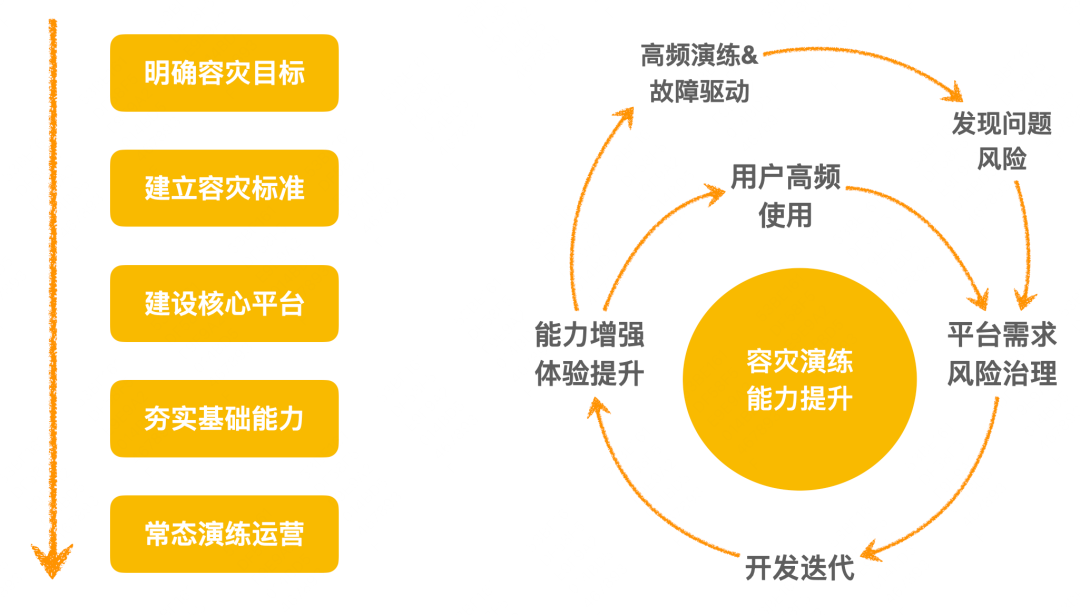
Caminho de construção de recuperação de desastres : determine metas de recuperação de desastres, formule padrões de recuperação de desastres, construa plataformas de recuperação de desastres, consolide recursos básicos, verificação de perfuração e operação de risco.
Flywheel para construção de recuperação de desastres : O anel interno é a capacitação da plataforma, desde a proposta de requisitos de recuperação de desastres até P&D e lançamento, melhoria da experiência, uso do usuário e novos requisitos quando os problemas são descobertos e melhoria iterativa contínua. Outro aspecto é melhorar a construção da plataforma de perfuração, realizar perfurações de alta frequência (ou real-falha), encontrar problemas, propor melhorias e promover a melhoria iterativa contínua das capacidades da plataforma.
3.4 Capacitação da plataforma
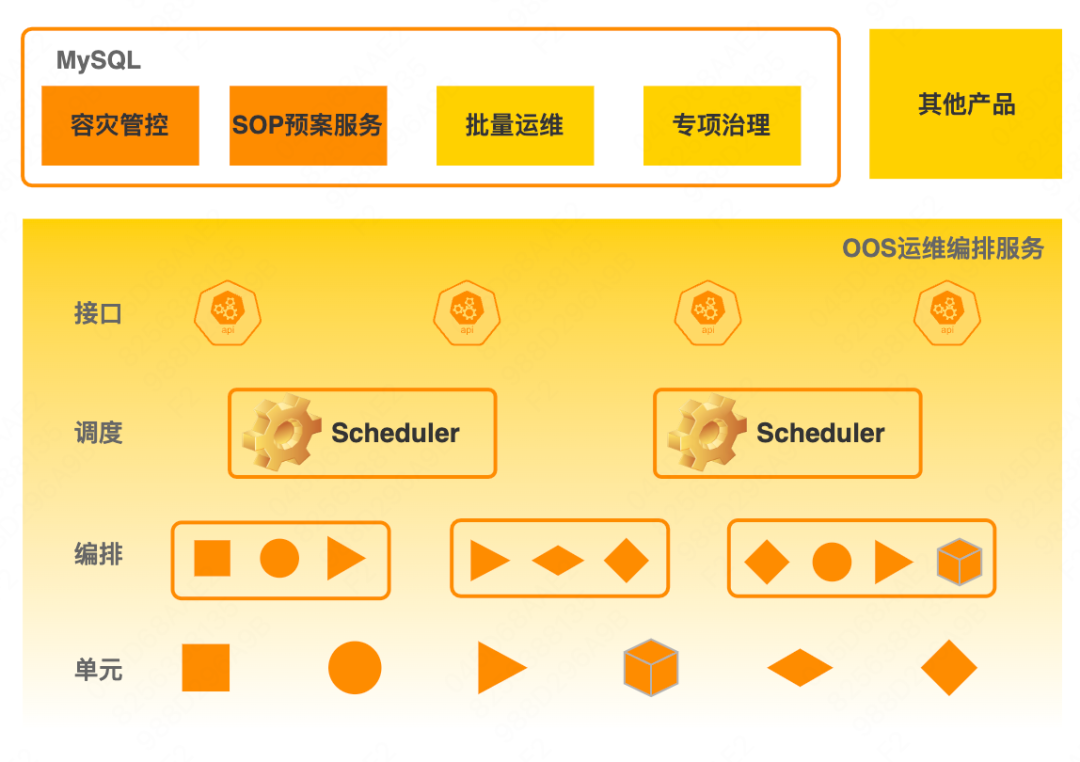
A fim de construir e melhorar a capacidade de recuperação de desastres dos serviços de banco de dados, um projeto de gerenciamento e controle de recuperação de desastres DDTP (Database Disaster Tolerance Platform) foi estabelecido internamente para se concentrar na melhoria da capacidade dos bancos de dados para lidar com falhas de grande escala. : uma é uma plataforma de gerenciamento e controle de recuperação de desastres e a outra é uma plataforma de drill de banco de dados.
A plataforma de gerenciamento e controle de recuperação de desastres concentra-se principalmente na defesa. Suas principais funções incluem principalmente fuga antes do evento, observação durante o evento, stop loss e recuperação após o evento. A plataforma de exercício do banco de dados se concentra no ataque, suporta vários tipos de falha e vários métodos de injeção de falhas e possui recursos essenciais, como orquestração e recuperação de falhas. O segundo artigo desta série, "Database Attack and Defense Drill Construction Practice", é uma introdução detalhada à plataforma de perfuração. A seguir, vamos nos concentrar no conteúdo principal da plataforma de gerenciamento e controle de recuperação de desastres, primeiro observe o panorama:
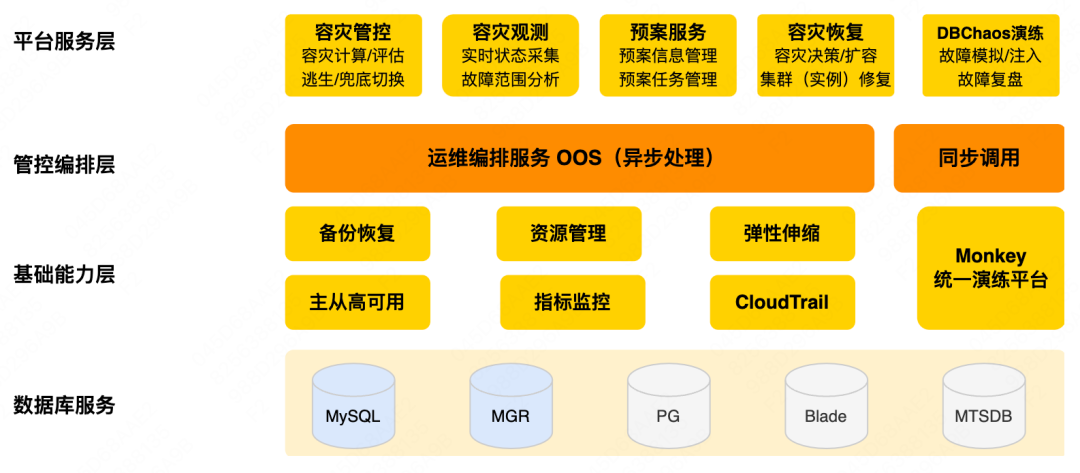
Serviço de banco de dados : incluindo MySQL, Blade, MGR e outros serviços básicos de banco de dados.
Camada de recursos básicos : principalmente backup e recuperação, gerenciamento de recursos, dimensionamento elástico, alta disponibilidade mestre-escravo e recursos de monitoramento de indicadores. Esses recursos são a parte básica da garantia de estabilidade, mas precisam ser fortalecidos ainda mais em cenários de recuperação de desastres para lidar com grandes cenários de falha em escala.
Camada de orquestração de gerenciamento e controle : O núcleo é OOS (Operation Orchestration Service), que orquestrará capacidades básicas sob demanda para gerar procedimentos de processamento correspondentes, também chamados de planos orientados a serviços.Cada plano corresponde a um ou mais cenários específicos de operação e manutenção. Os planos de recuperação de desastres também estão nesta categoria.
Camada de serviço da plataforma : é a camada de capacidade da plataforma de gerenciamento e controle de recuperação de desastres, incluindo: 1) gerenciamento e controle de recuperação de desastres , avaliação de cálculo de recuperação de desastres e gerenciamento de perigos ocultos, bem como recuperação de desastres e fuga antes da falha, de baixo para cima comutação durante falha, extração de falha, etc. 2) Observação de recuperação de desastres , esclarecendo o escopo das falhas e apoiando as decisões de recuperação de desastres durante as falhas. 3) Recuperação de tolerância a desastres , após uma falha, a capacidade de tolerância a desastres do cluster pode ser restaurada rapidamente por meio de funções como reparo de instância e expansão de cluster. 4) Planear serviço , incluindo a gestão e execução de planos de emergência para avarias comuns, etc.
3.4.1 Capacidade até o padrão
O banco de dados estabeleceu um conjunto de padrões de cálculo de recuperação de desastre N+1, que são divididos em 6 níveis. Se o nível de recuperação de desastre do cluster for ≥ 4, o padrão de recuperação de desastre é atendido, caso contrário, o padrão de recuperação de desastre não é atendido.
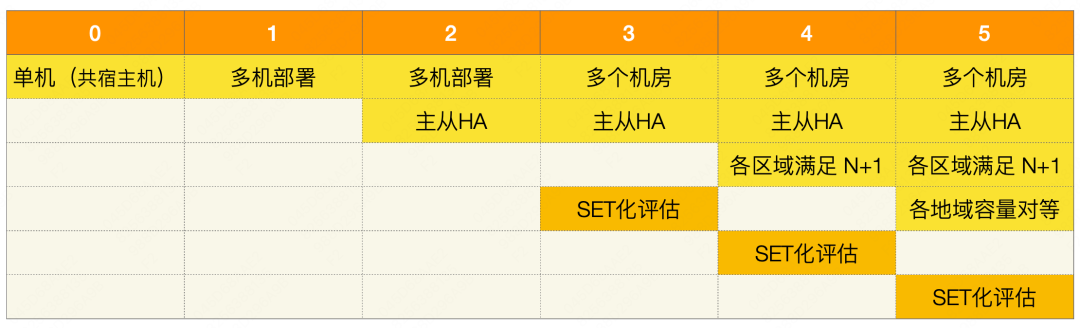
Pode ser visto no padrão que, a partir do nível 3, ele é implantado em várias salas de computadores. A diferença entre o Nível 3 e o Nível 4 e o Nível 5 é que o Nível 3 não atende ao requisito N+1, ou seja, se todos os nós de uma sala de computadores falharem, os nós restantes não poderão suportar o tráfego de pico. Os níveis 4 e 5 atendem ao requisito N+1 e o nível 5 atende à paridade de capacidade entre as regiões. Além dos padrões básicos, os clusters baseados em SET têm regras especiais, como políticas de roteamento de loop fechado, salas de computadores unificadas vinculadas a clusters SET, capacidade SET igual para backup mútuo e modelos unificados dentro do cluster. Essas regras serão incluídas no cálculo de recuperação de desastres para determinar o nível final de recuperação de desastres do cluster.
Na construção de dados básicos de recuperação de desastres, as regras acima serão codificadas e o processo de cálculo será simplificado, e os dados básicos serão mantidos atualizados quase em tempo real. Os dados de recuperação de desastres são os dados básicos usados na plataforma de gerenciamento e controle de recuperação de desastres para comutação de fuga e perdas durante incidentes. Ao mesmo tempo, riscos ocultos (ou seja, perigos ocultos de falha em atender aos padrões de recuperação de desastres) serão construído com base em dados de recuperação de desastres, e esses riscos serão eliminados por meio de certa governança operacional. perigo oculto.
3.4.2 Fuga antes da falha
A capacidade de escapar antes de uma falha é a alternância do banco de dados mestre em lote e a extração do banco de dados escravo. É usado principalmente para receber avisos antecipados antes de falhas, perceber desastres com antecedência e cortar rapidamente todos os serviços de banco de dados em uma sala de computadores ou tráfego de banco de dados escravo off-line para reduzir real O impacto da falha.
Sabemos que, para um cluster com uma arquitetura mestre-escravo, se ocorrer um failover devido a uma queda de energia ou falha de rede, é provável que ocorra perda de dados. Depois que os dados são perdidos, a empresa precisa confirmar e fazer o trabalho posterior, que às vezes é muito complicado. Se você puder escapar com antecedência, evitará esses riscos. Ao mesmo tempo, além do escape do banco de dados mestre, o banco de dados escravo também pode "remover" o tráfego antecipadamente, para que o lado comercial seja "insensível" a falhas.
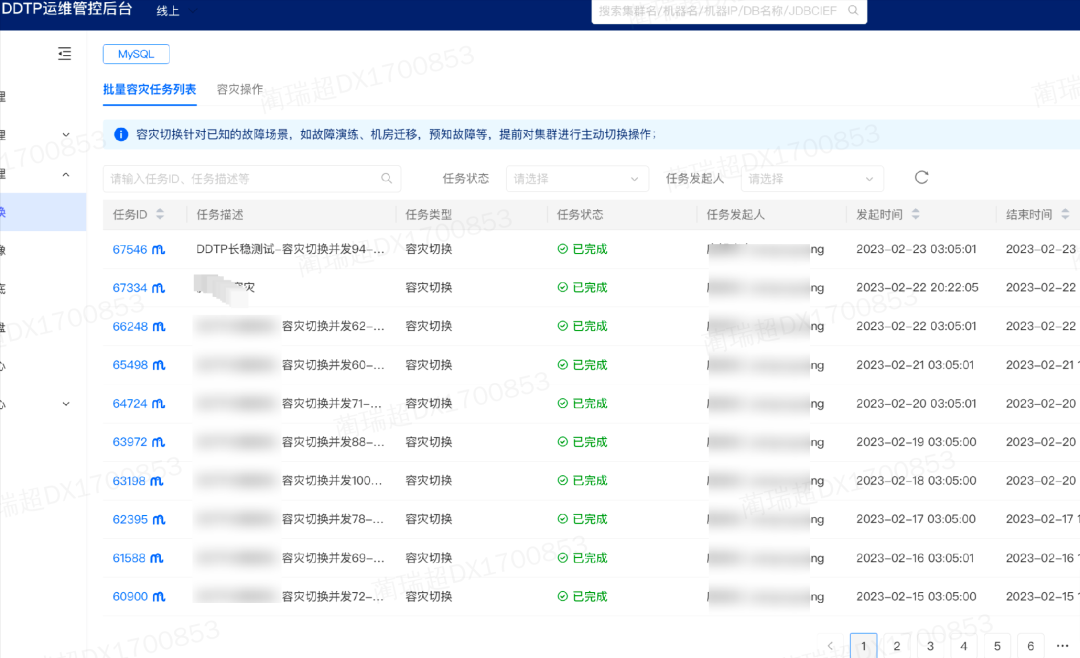
3.4.3 Observação durante faltas
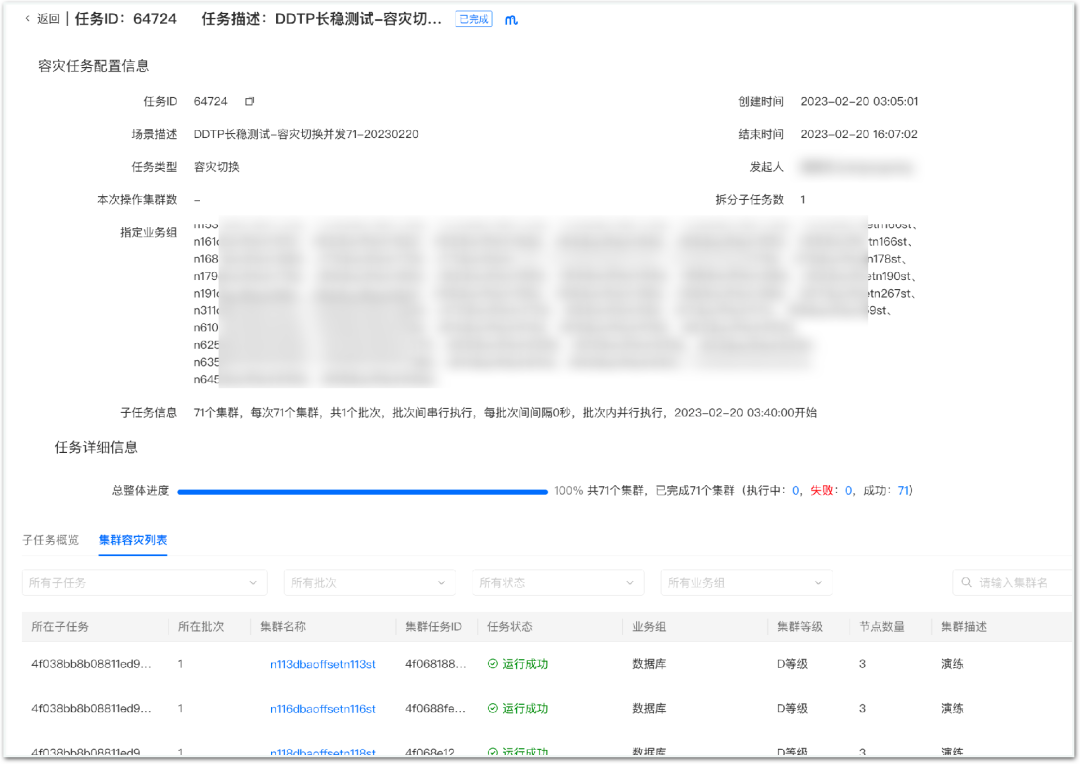
Quando ocorre uma falha em grande escala, geralmente haverá bombardeio de alarme, bombardeio de consulta por telefone, etc. Se não houver capacidade geral de reconhecimento de falhas, o tratamento de falhas será confuso, o tempo de processamento será relativamente longo e o impacto a falha será ampliada. Portanto, construímos o painel de observação de recuperação de desastres, que pode observar falhas em tempo real, com precisão e confiabilidade, para garantir que os alunos de plantão possam entender a situação em tempo real das falhas.
Conforme mostrado na figura abaixo, se ocorrer uma falha, você pode obter rapidamente a lista de clusters ou instâncias com falha e iniciar uma ação de alternância na página correspondente, realizando assim uma perda de parada rápida. O principal requisito para observar o mercado é em tempo real, preciso e confiável. Você pode melhorar sua própria disponibilidade reduzindo as dependências do serviço.
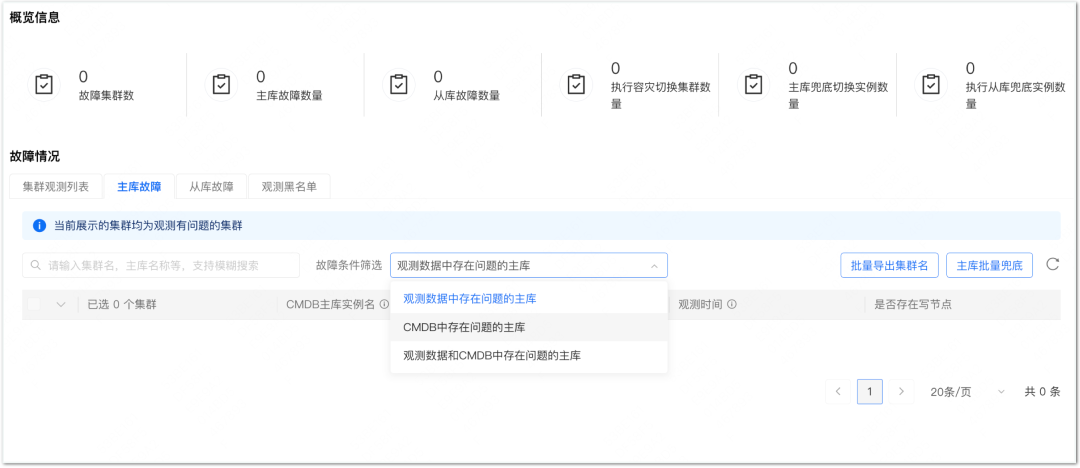
3.4.4 Stop loss durante falha
Antes de introduzir o stop loss na falha, vamos primeiro entender o serviço do plano. A principal função do serviço de plano de contingência é gerenciar falhas comuns e várias contingências de processamento correspondentes e fornecer recursos de controle de execução, para que os planos de contingência possam ser executados de maneira conveniente e controlável.
Stop loss de falha : Depois de ter um plano, podemos realizar um stop loss de baixo para cima. Conforme mostrado na figura abaixo, quando ocorre uma falha em grande escala, o HA tratará automaticamente da falha. Se a comutação do cluster falhar ou for perdida, ela entrará no estágio ascendente. Em primeiro lugar, comece com a plataforma DDTP. Se a plataforma estiver indisponível devido a uma falha, você pode fornecer o resultado final na camada de orquestração de operação e manutenção. Se o serviço de orquestração de operação e manutenção também falhar, você precisará verificar manualmente os detalhes por meio da ferramenta CLI. A CLI é a ferramenta de nível inferior do DBA e ela e a alta disponibilidade são dois links independentes. A CLI executará lógicas como detecção de topologia de cluster, eleição principal, ajuste de topologia, modificação de configuração e distribuição de configuração, que são equivalentes às etapas manuais de comutação de cluster.
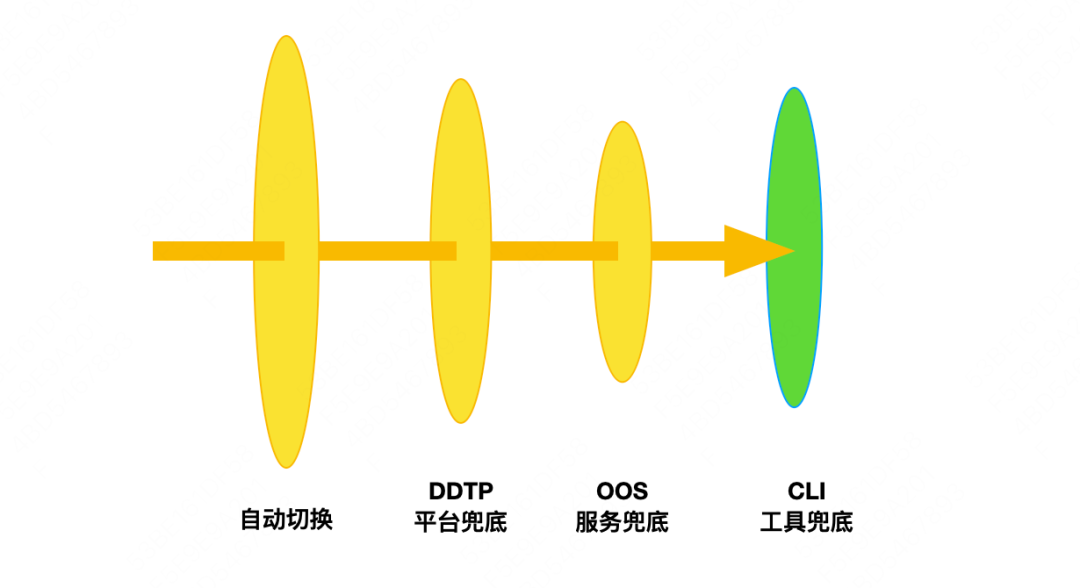
O princípio geral é dar prioridade à melhoria da taxa de sucesso da comutação automática de alta disponibilidade e reduzir o número de clusters na transmissão transparente para o estágio ascendente. Em segundo lugar, melhore a confiabilidade do plano, dê prioridade à tela branca, desça passo a passo, reduza a facilidade de uso e melhore a confiabilidade.
3.4.5 Recuperação após falha
Embora o cluster tenha capacidade N+1, quando uma sala de computadores falha, os nós restantes do cluster podem suportar o tráfego de pico, mas não tem capacidade de recuperação de desastre para outra falha AZ, portanto, após a falha, de acordo com o recurso condições de cada sala de computador, por meio da capacidade O centro de tomada de decisão de desastres expande rapidamente o cluster para complementar a capacidade de recuperação de desastres do cluster principal, tornando-o novamente capaz de recuperação de desastres AZ.
Uma das grandes desvantagens da solução acima é que ela precisa ter recursos suficientes para expandir a capacidade, o que é muito difícil. Atualmente, estamos construindo recursos de recuperação mais rápidos, como reparo no local de instâncias, expansão no local de clusters , etc. Após a recuperação AZ, pode reutilizar rapidamente os recursos da máquina na sala de computadores com falha e realizar a recuperação de desastres e recuperação rápida.
| 3.5 Construção do sistema de perfuração
Vários recursos básicos de recuperação de desastres não podem existir apenas no nível de projeto de arquitetura e avaliação teórica, mas devem ser utilizáveis na prática, o que requer verificação por meio de exercícios. No início do projeto de gerenciamento e controle de recuperação de desastres, uma estratégia baseada em drills foi formulada para verificar e impulsionar a melhoria de várias capacidades básicas. Até agora, um sistema de exercício multi-ambiente, de alta frequência, em larga escala e de longa duração foi estabelecido preliminarmente.

Vários ambientes : construímos uma variedade de ambientes de drill para atender às várias necessidades de drill de recuperação de desastres de cada componente de PaaS. O primeiro é o ambiente estável de longo prazo da plataforma de gerenciamento e controle de recuperação de desastres, o segundo é o ambiente de isolamento off-line dedicado a drills e o terceiro é o ambiente de produção, que possui uma área de drill e um ambiente normal de produção.
Alta frequência : Atualmente, pode atingir níveis diários e semanais. O nível diário é um drill normalizado, que é iniciado automaticamente em um ambiente estável de longo prazo, e a escala do drill é de centenas de clusters; o nível semanal é principalmente para drills reais regulares de rede e falta de energia em ambientes isolados e drill áreas.
Grande escala : é um exercício realizado no ambiente de produção, que é usado para verificar os recursos de processamento em grande escala e alta simultaneidade de alta disponibilidade básica, planos de emergência, planos de fuga, recuperação de desastres e funções de recuperação e determinar o capacidade de atendimento do sistema de gestão e controle.
Link longo : Todo o link de recuperação de desastres envolve muitos componentes, incluindo banco de dados CMDB, banco de dados de processos, componentes de alta disponibilidade, centro de configuração, serviço de plano etc. falhas, descobrir problemas potenciais e verificar o impacto de falhas simultâneas de vários nós de vários serviços na capacidade geral de tratamento de falhas.
3.5.1 Exercício de ambiente de isolamento
Como o nome sugere, o drill ambiente isolado é um ambiente de drill completamente isolado da sala de computadores de produção. Possui seu próprio TOR e gabinetes independentes. Os riscos podem ser completamente isolados e operações independentes de rede ou falha de energia podem ser realizadas. Os componentes de PaaS e os serviços de negócios participantes do drill devem ser implantados de forma independente neste ambiente. No ambiente isolado, além de realizar regularmente vários exercícios de recuperação de desastres para descobrir problemas de recuperação de desastres, também pode verificar os recursos de implantação independentes de cada PaaS, fornecendo uma base para suporte a negócios internacionais.
3.5.2 Simulação do ambiente de produção
Drills de falha normalizados e em grande escala : esse tipo de drill é realizado continuamente diariamente.As falhas são injetadas no cluster de banco de dados por meio da plataforma de drill e a alta disponibilidade é usada para failover. Verifique a capacidade de comutação simultânea de alta disponibilidade por meio de diferentes escalas de perfuração. Além disso, na plataforma de gerenciamento e controle de recuperação de desastres, é possível verificar a capacidade de fuga, o plano de stop loss e a observação de falhas de grande porte. Em suma, ele usa a combinação de "ataque" e "defesa" para realizar a verificação, aceitação e otimização de capacidades.
As principais características desse tipo de drill são: primeiro, os clusters participantes são hospedados pelo grupo de alta disponibilidade do ambiente de produção, o que significa que o drill verifica os recursos de alta disponibilidade do ambiente de produção; segundo, o os clusters que participam do drill são clusters não comerciais. É um cluster recém-criado especialmente usado para drills antes de cada drill. A escala pode ser muito grande. Atualmente, mais de 1.500 clusters podem ser drilled ao mesmo tempo. O terceiro é ter um certo efeito de simulação. A fim de tornar a broca mais realista e avaliar com precisão o RTO e aumentar a capacidade de carga do conjunto de exercícios.
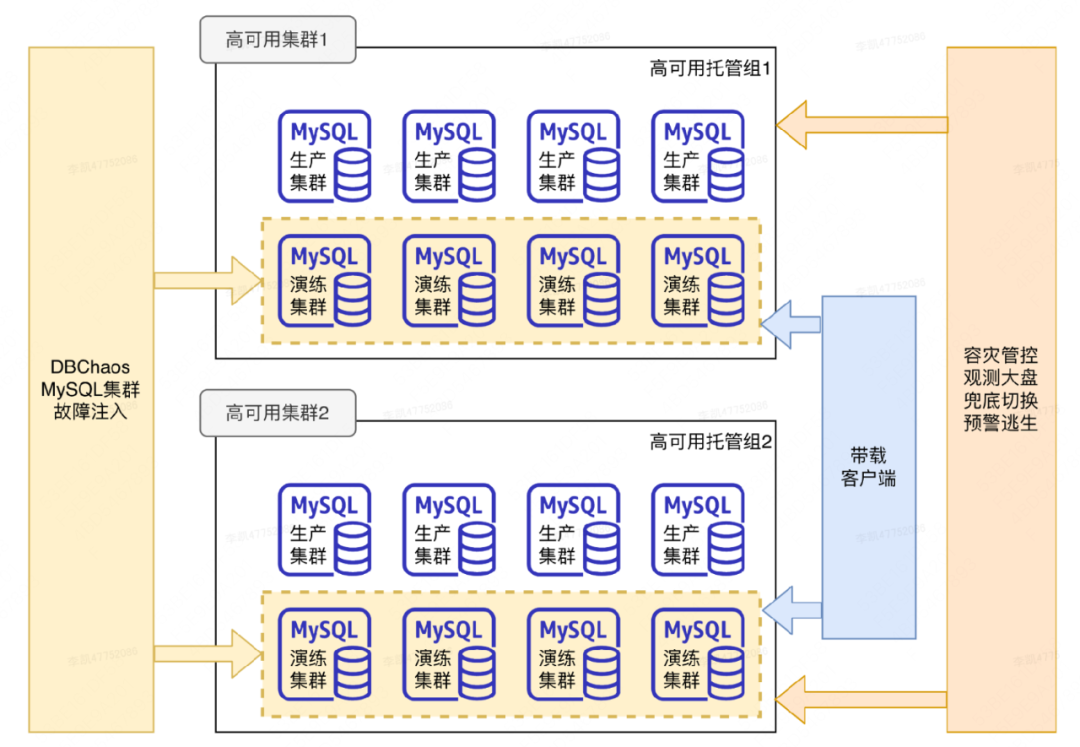
Exercícios de zona real : Os exercícios de ambiente isolado e exercícios em grande escala descritos acima são todos simulados e são bastante diferentes dos cenários de falha reais. Para compensar a lacuna com a chave primária defeituosa real, construímos um drill AZ dedicado baseado na nuvem pública, que pode ser entendido como uma sala de computadores independente. O software PaaS de componentes e negócios participantes implantará alguns nós de serviço que transportam o tráfego de negócios para o drill AZ. Durante o drill real, uma desconexão de rede real será realizada. Os negócios e os componentes podem observar e avaliar seu próprio status de recuperação de desastre quando a rede for desconectada . Será mais realista verificar a recuperação de desastre real de componentes e serviços por meio de salas de computadores reais, clusters de componentes reais e tráfego de negócios real.
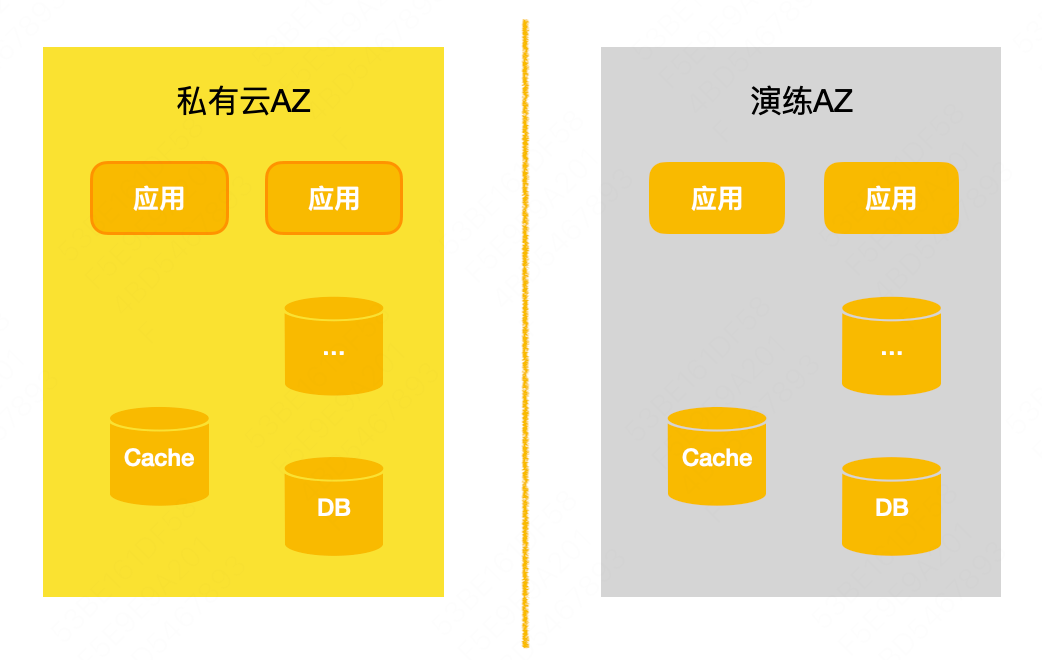
Dia do jogo : Além disso, ainda estamos avaliando e demonstrando a viabilidade de realizar exercícios em salas de computadores reais. Com a normalização de exercícios de ambiente isolado e exercícios de zona, os recursos básicos de recuperação de desastres de cada componente se tornarão cada vez mais fortes e a normalização em salas de computadores reais O objetivo final do exercício na sala de computadores também será alcançado.
4 pensamento futuro
Após mais de dois anos de construção, embora tenha alcançado alguns resultados em comutação automática de alta disponibilidade, gerenciamento de operação de capacidade de recuperação de desastres, observação de falhas em grande escala, plano de perda de parada de falhas, recuperação de desastres e outros aspectos. No entanto, ainda existem muitas deficiências em capacidades que precisam ser preenchidas, e novos desenvolvimentos de negócios também trouxeram novas necessidades e desafios. No futuro, continuaremos a melhorar em duas direções: compensar as deficiências e iterar a arquitetura técnica.
| 4.1 Compensar deficiências
Capacidade insuficiente de escape em larga escala e capacidade de stop loss : Com a implementação de nosso data center autoconstruído, a escala de nosso AZ autoconstruído será maior, o que terá requisitos mais altos para recursos. Vamos melhorar gradualmente os recursos principalmente por meio da plataforma verificação de iteração e drill.
As falhas de linha alugada entre domínios levam à falha da alta disponibilidade no nível da região : Em seguida, exploraremos soluções unificadas ou soluções de implantação independentes para alcançar o gerenciamento de loop fechado no nível da região ou mais granular.
Novos desafios para negócios no exterior : Ir para o exterior trará alguns novos requisitos e desafios para a arquitetura de recuperação de desastres. Seja para adotar "jurisdição de braço longo" ou implantação independente, seja para reutilizar o sistema de tecnologia existente ou criar uma nova arquitetura, essas questões ainda precisa ser melhorada exploração e demonstração.
Eficiência de recuperação de desastres : As funções básicas da plataforma são relativamente completas, mas a tomada de decisões de recuperação de desastres e a coordenação do processamento ainda precisam ser feitas manualmente, e a eficiência é relativamente baixa. No futuro, gerenciamento e controle de recuperação de desastres, perda de parada de emergência e outros recursos serão gradualmente automatizados; drills multiambientes O custo é relativamente alto, e drills automatizados devem ser realizados gradualmente para incorporar gradualmente os principais cenários de drill no ambiente estável de longo prazo e permitir a execução automática de cenários de falha por meio do tempo ou certas estratégias. Precisamos apenas nos concentrar na operação de indicadores centrais.
| 4.2 Arquitetura iterativa
As tecnologias relacionadas a banco de dados estão se desenvolvendo rapidamente. Por exemplo, novas tecnologias como Database Mesh e Serverless serão gradualmente implementadas. Naquela época, middleware, alta disponibilidade e kernel passarão por mudanças relativamente grandes. A introdução de produtos de separação de computação causará relativamente grandes mudanças nos recursos de recuperação de desastres. A construção da capacidade de recuperação de desastres será iterada junto com essas evoluções de produto determinadas.
A construção de recuperação de desastres é uma coisa muito desafiadora e também é algo que todas as empresas devem enfrentar depois que seus negócios crescem. Sejam todos bem-vindos a deixar uma mensagem no final do artigo e se comunicar conosco.
5 Autores
Ruichao, da plataforma básica de pesquisa e desenvolvimento da Meituan - departamento de tecnologia básica.