Índice
1. O que é um cluster de fatia?
2. Como economizar mais dados?
2.1 Expansão horizontal e expansão vertical
2.2 Vantagens e desvantagens da expansão horizontal e expansão vertical
3. O corte de clusters enfrenta dois grandes problemas:
3.1 Expansão horizontal: a relação de distribuição correspondente entre fatias de dados e instâncias
3.2 Como o cliente localiza os dados?
3. Resumo do corte de clusters
Dois: Slicing solução de cluster: Codis \ Redis Cluster
1. A estrutura geral e o processo básico do Codis
1.1 Como o Codis lida com as solicitações
2. Principais princípios técnicos do Codis
2.1 Como os dados são distribuídos no cluster
2.3 A diferença entre a distribuição de dados Codis e Redis Cluster
3. Expansão do cluster e migração de dados
4: Se o cliente pode interagir diretamente com o cluster
5. Como garantir a confiabilidade do cluster?
5.1 Método de confiabilidade da garantia do servidor Codis
5.2 Proxy Codis e confiabilidade do Zookeeper
Painel 5.3 Codis e confiabilidade Codis Fe
6. Sugestões para seleção do esquema de fatiamento de cluster
6.1 Diferença entre Codis e Redis Cluster
6.2 Dois esquemas em aplicação prática
7. Resumo do Cluster Codis e Redis
3. Sobrecarga de comunicação: o principal fator que limita a escala do Redis Cluster
1: Por que o tamanho do cluster deve ser limitado?
2: Método de comunicação da instância e impacto no tamanho do cluster
3.1 Tamanho da mensagem de fofoca
3.2 Frequência de comunicação entre instâncias
4. Como reduzir o overhead de comunicação entre as instâncias?
4.1 Reduzir o tamanho da mensagem transmitida pela instância
4.2 Reduzir a frequência de envio de mensagens entre as instâncias:
5. Resumo da sobrecarga de comunicação:
1. Grupo de fatias
No Redis, os dados aumentaram, devemos adicionar memória ou instâncias?
Usando um host de nuvem para executar uma instância do Redis, como escolher a capacidade de memória do host de nuvem?
Use Redis para salvar 50 milhões de pares chave-valor, cada par chave-valor tem cerca de 512B
Opção 1: host de nuvem com memória grande: escolha um host de nuvem com memória de 32 GB para implantar o Redis. Porque 32 GB de memória podem salvar todos os dados e restam 7 GB para garantir o funcionamento normal do sistema. Ao mesmo tempo, também uso o RDB para persistir os dados para garantir que os dados possam ser recuperados do RDB após a falha da instância do Redis.
Resultado: a resposta do Redis às vezes é muito lenta. Use o comando INFO para visualizar o valor do indicador de current_fork_usec do Redis (indicando o tempo do fork mais recente), e o resultado mostra que o valor do indicador é muito alto, quase ao segundo nível. Isso tem algo a ver com o mecanismo de persistência do Redis. Ao usar o RDB para persistência, o Redis irá bifurcar os subprocessos para concluir. O tempo gasto nas operações de fork está positivamente relacionado à quantidade de dados no Redis, e o fork bloqueará o thread principal durante a execução. Quanto maior a quantidade de dados, mais tempo o thread principal ficará bloqueado pela operação de bifurcação. Portanto, ao usar o RDB para persistir 25 GB de dados, a quantidade de dados é grande e o processo filho executado em segundo plano bloqueia o thread principal quando a bifurcação é criada, o que faz com que a resposta do Redis fique mais lenta.
Solução 2: cluster de fatia do Redis. Embora seja complicado configurar um cluster de fatia, ele pode salvar uma grande quantidade de dados e tem menos impacto no bloqueio do thread principal do Redis.
Se os dados de 25 GB forem divididos em 5 igualmente (é claro, podem ser divididos igualmente) e 5 instâncias forem usadas para salvar, cada instância precisará salvar apenas 5 GB de dados. Como mostrado abaixo:

Então, em um cluster fatiado, quando uma instância gera um RDB para 5GB de dados, a quantidade de dados é bem menor, e o processo fork filho geralmente não bloqueia a thread principal por muito tempo. Depois de usar várias instâncias para salvar fatias de dados, podemos não apenas salvar 25 GB de dados, mas também evitar a desaceleração repentina da resposta causada pelo processo filho fork bloqueando o thread principal.
1. O que é um cluster de fatia?
Slicing cluster, também chamado de sharding cluster, refere-se a iniciar várias instâncias do Redis para formar um cluster e, em seguida, dividir os dados recebidos em vários compartilhamentos de acordo com determinadas regras, cada uma das quais é salva por uma instância.
2. Como economizar mais dados?
2.1 Expansão horizontal e expansão vertical
No caso acima, o método de máquina de chip de nuvem de memória grande e cluster de fatia é usado. Esses dois métodos correspondem a duas soluções para o aumento da quantidade de dados que o Redis pode manipular: expansão vertical (scale up) e expansão horizontal (scale out).
- Expansão vertical : atualize a configuração de recursos de uma única instância do Redis, incluindo aumento da capacidade de memória, aumento da capacidade do disco e uso de CPUs com configuração superior. Conforme mostrado na figura abaixo, a memória da instância original é de 8 GB e o disco rígido é de 50 GB. Após a expansão vertical, a memória é aumentada para 24 GB e o disco é aumentado para 150 GB.
- Expansão horizontal : aumente horizontalmente o número de instâncias atuais do Redis, conforme a figura abaixo, onde é utilizada uma instância com 8GB de memória e 50GB de disco, e agora são utilizadas três instâncias com a mesma configuração.

2.2 Vantagens e desvantagens da expansão horizontal e expansão vertical
2.2.1 Expansão vertical
Prós: Simples e direto de implementar .
problemas potenciais:
O primeiro problema é que, ao usar o RDB para persistir dados, se a quantidade de dados aumentar, a memória necessária também aumentará e o thread principal poderá bloquear ao bifurcar o processo filho (como a situação no exemplo agora) . No entanto, se você não precisar de persistência e salvar dados do Redis, a expansão vertical será uma boa escolha.
O segundo problema: a expansão será limitada pelo hardware e pelo custo . Isso é fácil de entender. Afinal, é fácil expandir a memória de 32 GB para 64 GB. No entanto, se você quiser expandir para 1 TB, terá limitações de capacidade e custo de hardware.
2.2.2 Expansão horizontal
A expansão horizontal é uma solução mais escalável. Se você deseja economizar mais dados, se adotar esta solução, você só precisa aumentar o número de instâncias do Redis e não precisa se preocupar com as limitações de hardware e custo de uma única instância. Ao enfrentar milhões ou dezenas de milhões de usuários, o cluster de fatia Redis de expansão será uma escolha muito boa .
3. O corte de clusters enfrenta dois grandes problemas:
Depois que os dados são fatiados, como eles são distribuídos entre várias instâncias?
Como o cliente determina em qual instância os dados que deseja acessar residem?
3.1 Expansão horizontal: a relação de distribuição correspondente entre fatias de dados e instâncias
Em um cluster fatiado, os dados precisam ser distribuídos em diferentes instâncias. Como os dados devem corresponder às instâncias?
Esquema de Cluster Redis
Antes do Redis 3.0, o oficial não fornecia uma solução específica para clusters fatiados. A partir do 3.0, uma solução oficial chamada Redis Cluster é fornecida para implementar clusters de fatia. As regras correspondentes para dados e instâncias são estipuladas no esquema Redis Cluster.
3.1.1 O que é Redis Cluster?
A solução Redis Cluster usa slots de hash (Hash Slot) para lidar com o relacionamento de mapeamento entre dados e instâncias. No esquema Redis Cluster, um cluster de divisão tem um total de 16384 slots de hash. Esses slots de hash são semelhantes às partições de dados e cada par chave-valor é mapeado para um slot de hash de acordo com sua chave.
O processo de mapeamento específico é dividido em duas etapas: primeiro, de acordo com a chave do par chave-valor, calcule um valor de 16 bits de acordo com o algoritmo CRC16; em seguida, use esse valor de 16 bits para levar o módulo de 16384 para obtenha o módulo na faixa de 0~16383. Cada módulo representa um slot de hash numerado correspondentemente.
3.1.2 Como os slots de hash são mapeados para instâncias específicas do Redis?
Ao implantar a solução Redis Cluster, você pode usar o comando cluster create para criar um cluster. Neste momento, o Redis distribuirá automaticamente esses slots uniformemente nas instâncias do cluster . Por exemplo, se houver N instâncias no cluster, o número de slots em cada instância será 16384/N.
Você também pode usar o comando cluster meet para estabelecer manualmente uma conexão entre as instâncias para formar um cluster e, em seguida, usar o comando cluster addslots para especificar o número de slots de hash em cada instância
Por exemplo, supondo que os tamanhos de memória de diferentes instâncias do Redis no cluster sejam configurados de maneira diferente, se os hash slots forem divididos igualmente entre as instâncias, ao salvar o mesmo número de pares chave-valor, em comparação com instâncias com grande memória, aquelas com memória pequena A instância terá maior pressão de capacidade. Nesse caso, você pode usar o comando cluster addslots para alocar manualmente slots de hash de acordo com a configuração de recursos de diferentes instâncias .

O cluster de fatia no diagrama tem 3 instâncias no total e, assumindo que há 5 slots de hash, podemos primeiro alocar manualmente os slots de hash por meio do seguinte comando: a instância 1 salva os slots de hash 0 e 1 e a instância 2 salva o slot de hash 2 e 3, a instância 3 contém o slot de hash 4.
redis-cli -h 172.16.19.3 –p 6379 cluster addslots 0,1 redis-cli -h 172.16.19.4 –p 6379 cluster addslots 2,3 redis-cli -h 172.16.19.5 –p 6379 cluster addslots 4
Durante a execução do cluster, depois de calcular o valor CRC16 de key1 e key2, pegue o módulo do número total de hash slots 5 e mapeie para a instância 1 e instância 3 correspondentes de acordo com os respectivos resultados do módulo.
Observação: ao atribuir slots de hash manualmente, todos os 16384 slots precisam ser alocados, caso contrário, o cluster Redis não funcionará normalmente .
Os clusters de fatiamento realizam a alocação de dados para slots de hash, slots de hash e instâncias
Mesmo que a instância tenha as informações de mapeamento do hash slot, como o cliente sabe em qual instância os dados a serem acessados estão?
3.2 Como o cliente localiza os dados?
Ao localizar os dados do par chave-valor, os slots de hash em que ele está podem ser obtidos por cálculo, e esse cálculo pode ser executado quando o cliente envia uma solicitação. No entanto, para localizar melhor a instância, também é necessário saber em qual instância o hash slot está distribuído.
De um modo geral, depois que o cliente estabelece uma conexão com a instância do cluster, a instância enviará as informações de alocação do slot de hash ao cliente. No entanto, quando o cluster acaba de ser criado, cada instância sabe apenas a quais slots de hash foi atribuído, mas não conhece as informações de slots de hash pertencentes a outras instâncias.
Por que o cliente pode obter todas as informações do hash slot ao acessar qualquer instância?
A instância do Redis enviará suas próprias informações de slot de hash para outras instâncias conectadas a ela para concluir a difusão das informações de alocação de slot de hash. Quando as instâncias estão conectadas entre si, cada instância tem um relacionamento de mapeamento de todos os slots de hash. Após o cliente receber as informações do slot de hash, ele armazenará as informações do slot de hash localmente. Quando um cliente solicita um par chave-valor, ele primeiro calcula o slot de hash correspondente à chave e, em seguida, envia uma solicitação para a instância correspondente.
Em um cluster, a correspondência entre instâncias e slots de hash não é estática. Existem duas alterações mais comuns:
- No cluster, quando as instâncias são adicionadas ou excluídas, o Redis precisa reatribuir slots de hash;
- Para balanceamento de carga, o Redis precisa redistribuir slots de hash em todas as instâncias.
As instâncias também podem passar mensagens entre si para obter as informações de alocação de slot de hash mais recentes
O cliente não pode perceber ativamente essas mudanças. Isso levará a uma inconsistência entre as informações de alocação que ele armazena em cache e as informações de alocação mais recentes, então o que devo fazer?
O esquema Redis Cluster fornece um mecanismo de redirecionamento, o que significa que quando o cliente envia operações de leitura e gravação de dados para uma instância, não há dados correspondentes na instância e o cliente precisa enviar um comando de operação para uma nova instância.
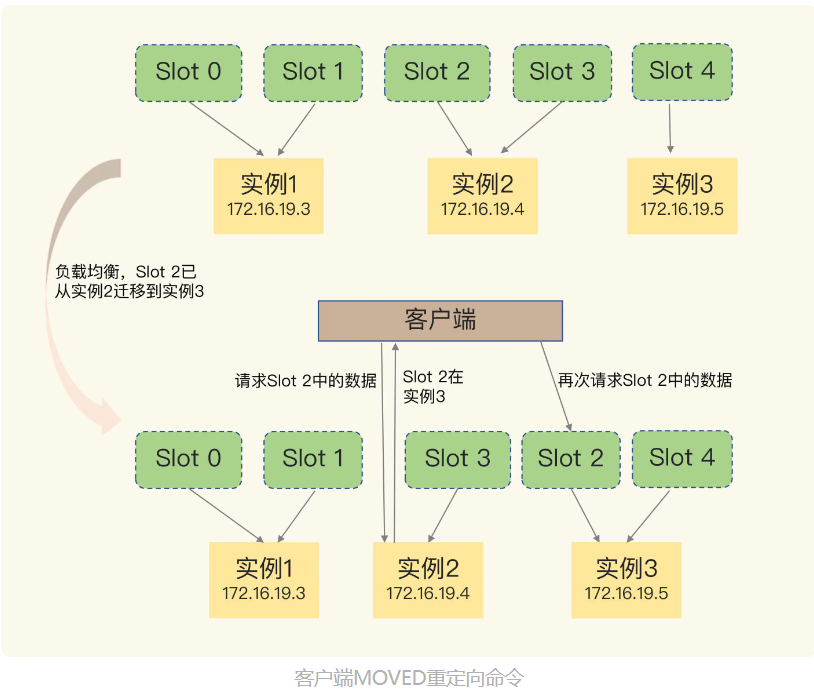
3.2.1 Como usar o comando de redirecionamento MOVED
Como o cliente sabe o endereço de acesso da nova instância durante o redirecionamento? Se o cliente solicitar um slot de hash que não contenha uma chave, como o cluster responderá?
Quando o cliente envia uma solicitação de operação de par chave-valor para uma instância e não há slot de hash de mapeamento de par chave-valor nesta instância, a instância retornará o resultado da resposta do comando MOVED para o cliente e o resultado contém a nova instância endereço.
get hello:key (error)MOVED 13320 172.16.19.5:6379
O comando MOVED indica que o hash slot 13320 onde está localizado o par chave-valor solicitado pelo cliente está na verdade na instância 172.16.19.5. Retornando o comando MOVED, equivale a informar ao cliente as informações da nova instância onde está localizado o hash slot. Desta forma, o cliente pode se conectar diretamente a 172.16.19.5 e enviar solicitações de operação.
Devido ao balanceamento de carga, os dados do Slot 2 foram migrados da instância 2 para a instância 3, mas o cache do cliente ainda registra a informação de que "o Slot 2 está na instância 2", então o comando será enviado para a instância 2. A instância 2 retorna um comando MOVED para o cliente e retorna a localização mais recente do Slot 2 (ou seja, na instância 3) para o cliente, e o cliente enviará uma solicitação para a instância 3 novamente e, ao mesmo tempo, atualizará o local cache para definir o Slot 2 O relacionamento correspondente com a instância é atualizado
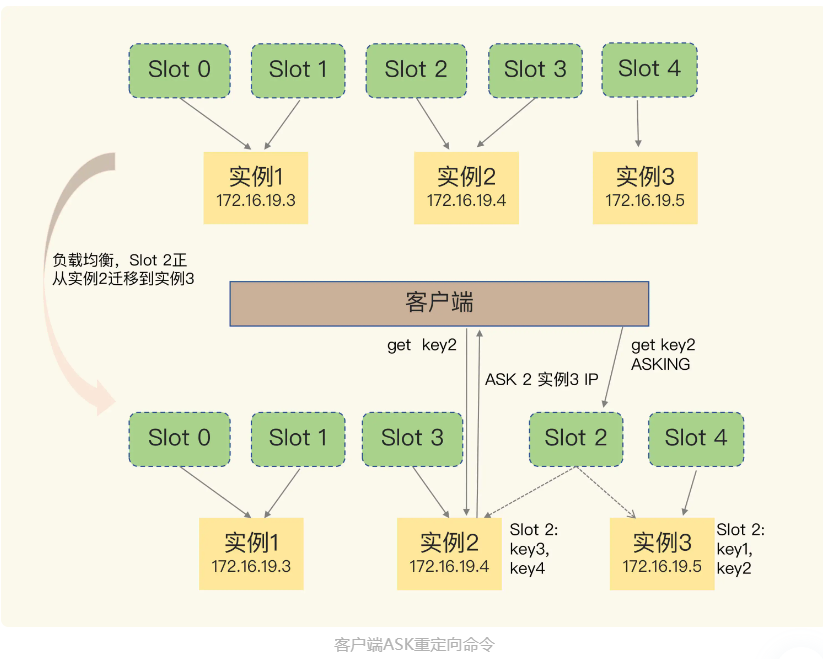
3.2.2 Como usar o comando ASK
Pode haver tal situação: alguns pares chave-valor pertencentes ao slot migrado são armazenados no nó de origem, enquanto outros pares chave-valor são armazenados no nó de destino.
Por exemplo: o cliente envia uma solicitação para a instância 2, mas, neste momento, apenas parte dos dados do Slot 2 foi migrada para a instância 3 e alguns dados não foram migrados. Caso essa migração seja parcialmente concluída, o cliente receberá uma mensagem de erro ASK, conforme abaixo:
Obtenha hello:key (erro) ASK 13320 172.16.19.5:6379
O comando ASK neste resultado indica que o hash slot 13320 onde está localizado o par chave-valor solicitado pelo cliente está na instância 172.16.19.5, mas este hash slot está sendo migrado. Neste ponto, o cliente precisa primeiro enviar um comando ASKING para a instância 172.16.19.5. O significado deste comando é deixar esta instância permitir a execução do comando enviado pelo cliente a seguir. Em seguida, o cliente envia um comando GET para essa instância para ler os dados.
O comando ASK tem dois significados: primeiro, indica que os dados do Slot ainda estão sendo migrados; segundo, o comando ASK retorna ao cliente o último endereço de instância dos dados solicitados pelo cliente. Nesse momento, o cliente precisa enviar o comando PERGUNTAR para a instância 3 e, em seguida, enviar o comando de operação
3.2.3 Diferença entre o comando MOVED e o comando ASK
- O comando MOVED atualizará as informações de alocação do slot de hash do cache do cliente e o ASK não atualizará o cache do cliente. Se o cliente solicitar dados no Slot 2 novamente, ele ainda enviará uma solicitação para a instância 2.
- A função do comando ASK é apenas permitir que o cliente envie uma requisição para a nova instância, enquanto o comando MOVED modifica o cache local para que comandos subseqüentes possam ser enviados para a nova instância.
3. Resumo do corte de clusters
Este artigo descreve principalmente as vantagens dos clusters fatiados no armazenamento de grandes quantidades de dados, bem como o mecanismo de distribuição de dados baseado em hash slot e o método para localizar pares chave-valor do lado do cliente.
- Ao lidar com uma grande quantidade de dados e expansão de dados, embora o método de expansão vertical para aumentar a memória seja simples e direto, ele causará memória excessiva e diminuirá o desempenho. Os colegas também são limitados por hardware e custo.
- O cluster de fatia Redis fornece um modo de expansão horizontal, ou seja, usando várias instâncias e atribuindo um determinado slot de hash a cada instância. Os dados podem ser mapeados para o slot de hash por meio do valor de hash da chave e distribuídos por meio do slot de hash. em uma instância diferente. A escalabilidade é boa e uma grande quantidade de dados pode ser armazenada adicionando instâncias.
- O cluster é o aumento ou diminuição de instâncias e a redistribuição de dados para conseguir o balanceamento de carga, resultando em mudanças no relacionamento de mapeamento entre hash slots e instâncias.Quando um cliente solicitar, receberá uma mensagem de erro para execução do comando. Os comandos MOVED e ASK permitem que o cliente obtenha as informações mais recentes.
- Antes do Redis 3.0, o Redis não fornecia oficialmente uma solução de cluster de fatiamento. No entanto, naquela época, a indústria já tinha algumas soluções de cluster de fatiamento, como ShardedJedis baseado em partição de cliente, Codis e Twemproxy baseados em proxy, etc. A aplicação desses esquemas é anterior ao esquema Redis Cluster
O esquema Redis Cluster atribui pares de chave-valor a diferentes instâncias por meio de slots de hash. Esse processo requer o cálculo de CRC nas chaves dos pares de chave-valor e, em seguida, o mapeamento com slots de hash. Há algum benefício nisso? Se você usar uma tabela para registrar diretamente a correspondência entre o par chave-valor e a instância (por exemplo, o par chave-valor 1 está na instância 2 e o par chave-valor 2 está na instância 1), então não há necessidade para calcular a correspondência entre a chave e o slot de hash, basta procurar na tabela, por que o Redis não faz isso?
1. O número de chaves armazenadas em todo o cluster é imprevisível. Quando o número de chaves for muito grande, registre diretamente o relacionamento de mapeamento de instância correspondente a cada chave. Esta tabela de mapeamento será muito grande. Se esta tabela de mapeamento é armazenada no servidor ou cliente Ambos ocupam muito espaço de memória.
2. Redis Cluster adota um modo descentralizado (sem proxy, o cliente está conectado diretamente ao servidor). O cliente acessa uma chave em um determinado nó. Se a chave não estiver neste nó, este nó precisa corrigir a rota do cliente para A capacidade do nó correto (resposta MOVED), que requer a troca de tabelas de roteamento entre os nós, cada nó tem uma relação de roteamento completa de todo o cluster. Se todo o armazenamento for a correspondência entre chaves e instâncias, as informações trocadas entre os nós ficarão muito grandes, consumindo muitos recursos da rede e, mesmo que a troca seja concluída, cada nó precisa armazenar tabelas de roteamento adicionais de outros nós. uso é muito grande, resultando em desperdício de recursos.
3. Quando o cluster está expandindo, encolhendo e balanceando os dados, ocorrerá a migração de dados entre os nós.Durante a migração, o relacionamento de mapeamento de cada chave precisa ser modificado e o custo de manutenção é alto.
4. Adicionar uma camada de slots de hash no meio pode desacoplar os dados dos nós. A chave é calculada por Hash. Você só precisa se preocupar com qual slot de hash é mapeado e, em seguida, encontrar o nó por meio da tabela de mapeamento do slot de hash e o nó. Por consumir muito poucos recursos da CPU, ele não apenas torna a distribuição de dados mais uniforme, mas também torna a tabela de mapeamento menor, o que é conveniente para o cliente e o servidor economizar e a troca de informações entre os nós fica leve.
5. Quando o cluster está expandindo, encolhendo e balanceando dados, as operações entre os nós, como migração de dados, são todas realizadas com o hash slot como unidade básica, o que simplifica a dificuldade de expansão e redução do nó e facilita a manutenção e gerenciamento do cluster.
Roteamento de solicitação, migração de dados
O Redis usa a solução de cluster para resolver o problema de gargalo de desempenho causado pela grande quantidade de dados e grande volume de gravação de um único nó. Vários nós formam um cluster, o que pode melhorar o desempenho e a confiabilidade do cluster, mas é seguido por problemas de gerenciamento de cluster.Há dois problemas principais: roteamento de solicitação e migração de dados (dimensionamento/diminuição/balanceamento de dados).
1. Roteamento de solicitação: Geralmente, a tabela de mapeamento de slots de hash é usada para encontrar o nó especificado e, em seguida, operar neste nó.
O Redis Cluster registra o relacionamento de mapeamento completo em cada nó (para facilitar a correção da solicitação de roteamento incorreta do cliente) e também o envia ao cliente para permitir que o cliente armazene uma cópia, para que o cliente possa encontrar diretamente o nó especificado e o o cliente e o servidor cooperam para concluir o roteamento de dados, o que exige que, quando a empresa usar o Redis Cluster, ele seja atualizado para a versão do cluster do SDK para oferecer suporte à interação do protocolo entre o cliente e o servidor.
Outras soluções de cluster Redis, como Twemproxy e Codis, são modelos centralizados (adicionando uma camada Proxy). O cliente opera todo o cluster por meio do Proxy. N várias instâncias Redis podem ser vinculadas por trás do Proxy. A camada Proxy mantém a lógica de encaminhamento de roteamento. Operating Proxy é como operar um Redis comum, e o cliente não precisa alterar o SDK, mas o Redis Cluster implementa essas lógicas de roteamento no SDK. Obviamente, adicionar uma camada de Proxy também trará uma certa perda de desempenho.
2. Migração de dados: quando os nós do cluster não são suficientes para atender às necessidades de negócios, os nós precisam ser expandidos. A expansão da capacidade significa que os dados entre os nós precisam ser migrados e se o processo de migração afetará os negócios também é determinar se uma solução de cluster é padrão sofisticado.
Twemproxy não suporta expansão online. Ele apenas resolve o problema de roteamento de solicitação. Ao expandir, ele precisa parar para redistribuição de dados. Tanto o Redis Cluster quanto o Codis alcançaram expansão online (sem afetar o negócio ou ter um impacto muito pequeno nos negócios). O ponto principal é que durante o processo de migração de dados, quando o cliente opera na chave que está sendo migrada, como o cluster lidar com isso? Certifique-se também de que o resultado correto seja respondido?
Ambos Redis Cluster e Codis requerem a cooperação entre o servidor e a camada cliente/Proxy. Durante o processo de migração, o servidor precisa permitir que o cliente ou Proxy acesse (redirecione) o novo nó para a chave que está sendo migrada. Este processo é para garantir que o negócio ainda não seja afetado ao acessar essas chaves, e resultados corretos podem ser obtidos. Devido à existência de redirecionamento, o atraso de acesso neste período será maior. Após a conclusão da migração, cada nó do Redis Cluster atualizará a tabela de mapeamento de rota e, ao mesmo tempo, permitirá que o cliente perceba e atualize o cache do cliente. O Codis atualizará a tabela de roteamento na camada Proxy e o cliente não ficará ciente de todo o processo.
Além de acessar o nó correto, condições anormais (tempo limite de migração, falha de migração) e problemas de desempenho (como tornar a migração de dados mais rápida, como lidar com bigkey) precisam ser resolvidos durante o processo de migração de dados. processo.
A migração de dados do Redis Cluster é síncrona. A migração de uma chave bloqueará o nó de origem e o nó de destino ao mesmo tempo e haverá problemas de desempenho durante o processo de migração. A Codis fornece uma solução para migrar dados de forma assíncrona, com maior velocidade de migração e impacto mínimo no desempenho. Claro, a solução de implementação também é mais complicada.
Dois: Slicing solução de cluster: Codis \ Redis Cluster
Redis Cluster, a solução oficial de cluster de divisão fornecida pela Redis. Mas antes do lançamento oficial da solução Redis Cluster, o Codis, que tem sido amplamente utilizado na indústria, merece atenção.
1. A estrutura geral e o processo básico do Codis
O cluster Codis contém 4 tipos de componentes principais.
- servidor codis: esta é uma instância do Redis que passou por desenvolvimento secundário. Estruturas de dados adicionais são adicionadas para dar suporte às operações de migração de dados. É responsável principalmente pelo processamento de solicitações específicas de leitura e gravação de dados.
- proxy codis: receba solicitações de clientes e encaminhe-as para o servidor codis.
- Cluster do Zookeeper: Salve os metadados do cluster, como informações de localização de dados e informações de proxy codis.
- codis dashboard e codis fe: juntos formam uma ferramenta de gerenciamento de cluster. Entre eles, o painel codis é responsável pelo gerenciamento de cluster, incluindo adicionar e excluir servidor codis, proxy codis e migração de dados. E o codis fe é responsável por fornecer a interface de operação da web do painel, o que é conveniente para nós gerenciarmos o cluster diretamente na interface da web.

1.1 Como o Codis lida com as solicitações
Primeiro de tudo - "Para que o cluster receba e processe solicitações: primeiro use o painel codis para definir os endereços de acesso do servidor codis e do proxy codis. Depois que as configurações forem concluídas, o servidor codis e o proxy codis começarão a receber conexões.
Em segundo lugar - "Quando o cliente deseja ler e gravar dados, o cliente estabelece diretamente uma conexão com o proxy codis. O próprio proxy codis suporta o protocolo de interação RESP do Redis. Quando o cliente acessa o proxy codis, não é diferente de acessando a instância original do Redis. Os clientes originalmente conectados a uma única instância podem facilmente estabelecer uma conexão com o cluster Codis.
Finalmente --"o proxy codis recebe a solicitação, ele consultará o relacionamento de mapeamento entre os dados da solicitação e o servidor codis e encaminhará a solicitação para o servidor codis correspondente para processamento. Quando o servidor codis terminar de processar a requisição, ele retornará o resultado para o proxy codis, e o proxy retornará os dados para o cliente.

2. Principais princípios técnicos do Codis
2.1 Como os dados são distribuídos no cluster
Em um cluster Codis, em qual servidor Codis os dados devem ser salvos é feito através do mapeamento de slot lógico (Slot), especificamente, é dividido em duas etapas.
Na primeira etapa, o cluster Codis possui um total de 1024 Slots, numerados de 0 a 1023. Atribua manualmente esses Slots a servidores codis e cada servidor contém uma parte dos Slots. Você também pode permitir que o painel Codis aloque automaticamente, por exemplo, o painel distribui 1024 slots igualmente entre todos os servidores.
Na segunda etapa, quando o cliente deseja ler e gravar dados, ele usará o algoritmo CRC32 para calcular o valor de hash da chave de dados e obterá o módulo de valor de hash 1024. O valor após a tomada do módulo corresponde ao número do Slot. Neste ponto, de acordo com a relação correspondente entre o Slot e o servidor atribuído na primeira etapa, podemos saber em qual servidor os dados são salvos.
2.2 Exemplos
A figura abaixo mostra a relação de mapeamento e salvamento de dados, slot e servidor codis. Entre eles, os slots 0 e 1 são atribuídos ao server1, o slot 2 é atribuído ao server2, os slots 1022 e 1023 são atribuídos ao server8. Quando o cliente acessa a chave 1 e a chave 2, os valores CRC32 desses dois dados são 1 e 1022 após o módulo 1024. Portanto, eles serão salvos no Slot 1 e Slot 1022, e Slot 1 e Slot 1022 foram alocados para o servidor codis 1 e 8. O local de armazenamento da chave 1 e chave 2 é muito claro.

O relacionamento de mapeamento entre a chave de dados e o Slot é calculado diretamente pelo cliente por meio do CRC32 antes de ler e gravar dados, e o relacionamento de mapeamento entre o Slot e o servidor codis é concluído por meio de alocação, portanto, um sistema de armazenamento precisa ser usado para salvar Caso contrário, se o cluster Se houver uma falha, o relacionamento de mapeamento será perdido.
A relação de mapeamento entre o Slot e o servidor codis é chamada de tabela de roteamento de dados (referida como tabela de roteamento). Depois de alocarmos a tabela de roteamento no painel do codis, o painel enviará a tabela de roteamento para o proxy do codis e, ao mesmo tempo, o painel também salvará a tabela de roteamento no Zookeeper. O codis-proxy armazenará em cache a tabela de roteamento localmente. Ao receber uma solicitação do cliente, ele pode consultar diretamente a tabela de roteamento local para concluir o encaminhamento correto da solicitação.

Em termos de método de implementação de distribuição de dados, Codis e Redis Cluster são muito semelhantes e ambos adotam o mecanismo de mapeamento de chaves para slots e slots para instâncias
2.3 A diferença entre a distribuição de dados Codis e Redis Cluster
- Tabela de roteamento no Codis: alocada e modificada por meio do painel do codis e salva no cluster do Zookeeper. Uma vez que a localização dos dados muda (por exemplo, há um aumento ou diminuição de instâncias), a tabela de roteamento é modificada, o codis dashbaord enviará a tabela de roteamento modificada para o proxy codis e o proxy pode encaminhar a solicitação de acordo com as informações de roteamento mais recentes .
- No Redis Cluster, a tabela de roteamento de dados é passada pela comunicação entre cada instância e, finalmente, uma cópia será salva em cada instância. Quando as informações de roteamento de dados mudam, elas precisam ser transmitidas por meio de mensagens de rede entre todas as instâncias. Portanto, se o número de instâncias for grande, mais recursos de rede do cluster serão consumidos.
3. Expansão do cluster e migração de dados
A expansão do cluster Codis inclui dois aspectos: adicionar servidor codis e adicionar proxy codis.
3.1 Adicionar servidor Codis
Dois passos:
- Inicie um novo servidor codis e adicione-o ao cluster;
- Migre alguns dados para o novo servidor.
3.1.1 Processo básico de migração de dados
O cluster Codis executa a migração de dados de acordo com a granularidade do Slot, e a migração de dados é um mecanismo importante
- No servidor de origem, o Codis seleciona aleatoriamente um dado do Slot a ser migrado e o envia para o servidor de destino.
- Após o servidor de destino confirmar o recebimento dos dados, ele retornará uma mensagem de confirmação ao servidor de origem. Neste momento, o servidor de origem excluirá localmente os dados que acabaram de ser migrados.
- A primeira e a segunda etapas são o processo de migração de um único dado. O Codis continuará repetindo esse processo de migração até que todos os dados do Slot a ser migrado sejam concluídos.

Codis implementa dois modos de migração, ou seja, migração síncrona e migração assíncrona
3.1.2 Migração Síncrona
A migração síncrona significa que, durante o processo de envio de dados do servidor de origem para o servidor de destino, o servidor de origem é bloqueado e não pode lidar com novas operações de solicitação. Este modo é fácil de implementar, mas o processo de migração envolve várias operações (incluindo serialização de dados no servidor de origem, transmissão de rede, desserialização no servidor de destino e exclusão no servidor de origem). servidor ficará bloqueado por um longo tempo e não poderá processar as solicitações do usuário a tempo.
3.1.3 Migração Assíncrona
Para evitar que a migração de dados bloqueie o servidor de origem, o segundo modo de migração implementado pelo Codis é a migração assíncrona
Duas características principais da migração assíncrona
A primeira característica é
Depois que o servidor de origem envia os dados para o servidor de destino, outras operações de solicitação podem ser processadas sem esperar a execução do comando do servidor de destino. Após o servidor de destino receber os dados, desserializá-los e salvá-los localmente, ele envia uma mensagem ACK ao servidor de origem, indicando que a migração foi concluída. Nesse ponto, o servidor de origem exclui localmente os dados que acabaram de ser migrados.
Durante esse processo, os dados migrados serão configurados como somente leitura, portanto os dados do servidor de origem não serão modificados e, naturalmente, não haverá problema de "inconsistência com os dados do servidor de destino"
A segunda característica é
Para bigkey, a migração assíncrona adota o método de divisão de instruções para migração. Especificamente, para cada elemento no bigkey, use uma instrução para migrar, em vez de serializar todo o bigkey e depois transferi-lo como um todo. Essa forma de dividi-lo em partes evita o problema de bloqueio do servidor de origem devido à serialização de uma grande quantidade de dados durante a migração do bigkey.
Quando o bigkey migra parte dos dados, se o Codis falhar, alguns elementos do bigkey estarão no servidor de origem, enquanto a outra parte estará no servidor de destino, o que destrói a atomicidade da migração. Portanto, o Codis definirá um tempo de expiração temporário para o elemento bigkey no servidor de destino . Se ocorrer uma falha durante a migração, a chave no servidor de destino será excluída após a expiração, o que não afetará a atomicidade da migração. Quando a migração for concluída normalmente, o tempo de expiração temporário do elemento bigkey será excluído.
Exemplo de segundo recurso:
Se você deseja migrar um dado do tipo Lista com 10.000 elementos, quando for utilizada a migração assíncrona, o servidor de origem transmitirá 10.000 comandos RPUSH para o servidor de destino, sendo que cada comando corresponde à inserção de um elemento na Lista. No servidor de destino, esses 10.000 comandos são executados sequencialmente para concluir a migração de dados.
Para melhorar a eficiência da migração, o Codis permite que várias chaves sejam migradas ao mesmo tempo ao migrar slots de forma assíncrona. Você pode definir o número de chaves para cada migração através do parâmetro numkeys do comando de migração assíncrona SLOTSMGRTTAGSLOT-ASYNC
3.2 Adicionar proxy codis
No cluster Codis, o cliente está conectado diretamente ao proxy codis, portanto, quando o número de clientes aumenta, um proxy não pode suportar um grande número de operações de solicitação e é necessário adicionar um proxy. É mais fácil adicionar um proxy, iniciar o proxy diretamente e, em seguida, adicionar o proxy ao cluster por meio do painel do codis.
Neste momento, as informações de conexão de acesso do proxy codis serão salvas no Zookeeper. Portanto, quando um proxy é adicionado, haverá a lista de acesso mais recente no Zookeeper, e o cliente pode ler a lista de acesso do proxy do Zookeeper e enviar a solicitação para o proxy recém-adicionado. Desta forma, a pressão de acesso do cliente pode ser compartilhada entre vários proxies, conforme a figura abaixo

4: Se o cliente pode interagir diretamente com o cluster
Ao usar uma instância única do Redis, desde que o cliente cumpra o protocolo RESP, ele pode interagir com a instância e ler e gravar dados. No entanto, ao usar um cluster fatiado, algumas funções são diferentes das de uma única instância. Por exemplo, a operação de migração de dados no cluster não existe em uma única instância e, durante o processo de migração, as solicitações de acesso aos dados podem ser redirecionado (como o comando Redis MOVE no cluster).
O cliente precisa adicionar suporte para operações de comando relacionadas à função de cluster. Se você usou originalmente um cliente de instância única e deseja expandir a capacidade para usar um cluster, precisará usar um novo cliente, que não é particularmente amigável para a compatibilidade de aplicativos de negócios.
O cluster Codis foi projetado com total consideração para compatibilidade com clientes de instância única existentes.
Codis usa o proxy codis para se conectar diretamente aos clientes, e o proxy codis é compatível com clientes de instância única. O trabalho de gerenciamento relacionado ao cluster (como encaminhamento de solicitação, migração de dados etc.) é feito por componentes como proxy codis e painel codis, sem a participação do cliente.
Quando o aplicativo de negócios usa o cluster Codis, não há necessidade de modificar o cliente. O cliente pode ser reutilizado e conectado a uma única instância. Ele pode não apenas usar o cluster para ler e gravar dados de grande capacidade, mas também evitar a modificação o cliente para adicionar lógica de operação complexa, garantindo a estabilidade e compatibilidade do código de negócios.
5. Como garantir a confiabilidade do cluster?
A confiabilidade é um requisito básico para aplicativos de negócios reais. Para um sistema distribuído, sua confiabilidade está relacionada ao número de componentes do sistema: quanto mais componentes, mais pontos de risco potenciais . Ao contrário do Redis Cluster, que contém apenas instâncias do Redis, o Codis Cluster contém 4 tipos de componentes
Métodos de garantia de confiabilidade para diferentes componentes do Codis.
5.1 Método de confiabilidade da garantia do servidor Codis
- O servidor codis é, na verdade, uma instância do Redis, mas foram adicionados comandos relacionados às operações do cluster. O mecanismo de replicação mestre-escravo do Redis e o mecanismo sentinela estão disponíveis no servidor codis, portanto, o Codis usa um cluster mestre-escravo para garantir a confiabilidade do servidor codis. Simplificando, o Codis configura uma biblioteca escrava para cada servidor e usa o mecanismo sentinela para monitoramento.Quando ocorre uma falha, a biblioteca mestre-escravo pode ser trocada para garantir a confiabilidade do servidor.
- Nessa configuração, cada servidor se torna um grupo de servidores e cada grupo é um servidor com um mestre e vários escravos. Os slots utilizados para distribuição de dados também são alocados de acordo com a granularidade do grupo. Ao mesmo tempo, quando o codis proxy encaminha a solicitação, ele também envia a solicitação de gravação para a biblioteca principal do grupo correspondente de acordo com o relacionamento correspondente entre o Slot e o grupo onde os dados estão localizados e envia a solicitação de leitura para o biblioteca principal ou a biblioteca escrava no grupo.
A figura abaixo mostra a arquitetura de cluster do Codis configurada com o grupo de servidores. No cluster Codis, implementamos a opção mestre-escravo do servidor codis implantando o grupo de servidores e o cluster sentinela para melhorar a confiabilidade do cluster.

5.2 Proxy Codis e confiabilidade do Zookeeper
- Ao projetar um cluster Codis, a fonte de informações no proxy vem do Zookeeper (como a tabela de roteamento). O cluster Zookeeper usa várias instâncias para salvar dados. Desde que mais da metade das instâncias Zookeeper funcionem normalmente, o cluster Zookeeper pode fornecer serviços e garantir a confiabilidade desses dados.
- Portanto, o proxy codis usa o cluster Zookeeper para salvar a tabela de roteamento e pode fazer uso total da garantia de alta confiabilidade do Zookeeper para garantir a confiabilidade do proxy codis sem nenhum trabalho adicional. Quando o proxy codis falhar, basta reiniciar o proxy diretamente. O proxy reiniciado pode obter a tabela de roteamento do cluster Zookeeper por meio do painel do codis e, em seguida, pode receber solicitações do cliente e encaminhá-las. Esse design também reduz a complexidade de desenvolvimento do próprio cluster do Codis.
Painel 5.3 Codis e confiabilidade Codis Fe
Eles fornecem principalmente gerenciamento de configuração e operação manual por administradores, e a pressão de carga não é alta, portanto, sua confiabilidade pode ser garantida sem garantias adicionais.
6. Sugestões para seleção do esquema de fatiamento de cluster
6.1 Diferença entre Codis e Redis Cluster

6.2 Dois esquemas em aplicação prática
Do ponto de vista de estabilidade e maturidade, o Codis foi aplicado anteriormente e tem implantação de produção madura na indústria. Embora o Codis introduza o proxy e o Zookeeper, o que aumenta a complexidade do cluster, o design sem estado do proxy e a estabilidade do próprio Zookeeper também fornecem uma garantia para o uso estável do Codis. No entanto, o Redis Cluster foi lançado depois do Codis. Relativamente falando, sua maturidade é mais fraca do que o Codis. Se você quiser escolher uma solução madura e estável, o Codis é mais adequado.
- Do ponto de vista da compatibilidade do cliente de aplicativos de negócios, os clientes que se conectam a uma única instância podem se conectar diretamente ao proxy codis, enquanto os clientes que se conectam originalmente a uma única instância precisam desenvolver novas funções se quiserem se conectar ao Redis Cluster. Portanto, se você usa um grande número de clientes de instância única em seus aplicativos de negócios e agora deseja aplicar clusters de fatia, é recomendável escolher Codis, o que pode evitar a modificação dos clientes em seus aplicativos de negócios.
- Do ponto de vista do uso de novos comandos e recursos do Redis, o servidor Codis é desenvolvido com base no Redis 3.2.8 de código aberto, portanto, o Codis não oferece suporte a novos comandos e tipos de dados em versões subsequentes de código aberto do Redis. Além disso, o Codis não implementa todos os comandos da versão Redis de código aberto, como BITOP, BLPOP, BRPOP e MUTLI, EXEC e outros comandos relacionados a transações. A lista de comandos não suportados está listada no site oficial do Codis, lembre-se de verificar quando for usá-lo. Portanto, se você deseja usar os novos recursos da versão Redis de código aberto, o Redis Cluster é uma escolha adequada.
- Do ponto de vista do desempenho da migração de dados, o Codis pode oferecer suporte à migração assíncrona. A migração assíncrona tem menos impacto no desempenho do cluster que processa solicitações normais do que a migração síncrona. Portanto, se você tiver migração frequente de dados ao aplicar clusters, o Codis é uma escolha mais adequada.
7. Resumo do Cluster Codis e Redis
O cluster Codis inclui quatro componentes principais: servidor codis, proxy codis, Zookeeper, painel codis e codis fe.
- O proxy Codis e o servidor Codis são responsáveis pelo processamento de solicitações de leitura e gravação de dados. Entre eles, o proxy Codis se conecta ao cliente, recebe a solicitação e encaminha a solicitação ao servidor Codis, e o servidor Codis é responsável pelo processamento específico do solicitar.
- O codis dashboard e o codis fe são responsáveis pelo gerenciamento do cluster, onde o codis dashboard realiza operações de gerenciamento e o codis fe fornece uma interface de gerenciamento da web.
- O cluster Zookeeper é responsável por salvar todas as informações de metadados do cluster, incluindo tabela de roteamento, informações de instância de proxy, etc. Aqui, há algo que você precisa prestar atenção: além de usar o Zookeeper, o Codis também pode usar o etcd ou o sistema de arquivos local para salvar informações de metadados.
Sugestões de uso do Codis: Quando você tem várias linhas de negócios para usar o Codis, pode iniciar vários painéis Codis, cada painel gerencia uma parte do servidor Codis e, ao mesmo tempo, usar outro painel para ser responsável pelo gerenciamento do cluster de um linha de negócios, portanto, você pode usar um cluster Codis para realizar o gerenciamento de isolamento de várias linhas de negócios.
Suponha que 80% dos pares chave-valor armazenados no cluster Codis sejam do tipo Hash, o número de elementos em cada coleção Hash seja de 100.000 a 200.000 e o tamanho de cada elemento da coleção seja 2 KB. Você acha que a migração desses dados de coleta de Hash afetará o desempenho do Codis?
Quando o Codis migra dados, o esquema de design pode garantir que o desempenho da migração não seja afetado.
1. Migração assíncrona: O nó de origem envia os dados migrados para o nó de destino e, em seguida, retorna e processa as solicitações do cliente. Este estágio não bloqueará o nó de origem por muito tempo. Após o nó de destino carregar com sucesso os dados migrados, ele envia um comando ACK ao nó de origem para informá-lo de que a migração foi bem-sucedida.
2. O nó de origem libera a chave de forma assíncrona: Após o nó de origem receber o ACK do nó de destino, a operação de deletar a chave na instância de origem e liberar a memória da chave será executada na thread de segundo plano sem bloquear a instância de origem. (Sim, o Codis suportava lazy-free antes do Redis, mas era usado apenas na migração de dados).
3. Transmissão serializada de pequenos objetos: Pequenos objetos ainda são migrados de forma serializada, economizando tráfego de rede.
4. Bigkey migração em lotes: o bigkey é dividido em comandos, empacotado e migrado em lotes (usando as vantagens do Pipeline), e a velocidade de migração é melhorada.
5. Migre várias chaves de uma só vez: envie várias chaves para migração de uma só vez para melhorar a eficiência da migração.
6. Controle do fluxo de migração: O tamanho do buffer será controlado durante a migração para evitar o preenchimento da largura de banda da rede.
7. Garanta a atomicidade da migração bigkey (compatibilidade com falha de migração): envie um comando DEL para o nó de destino antes da migração (a repetição pode garantir idempotência), depois divida bigkey em comandos e defina um tempo de expiração temporário (para evitar falha de migração de deixando dados de lixo no nó de destino), após a migração bem-sucedida, defina o tempo de expiração real no nó de destino. O Codis é melhor que o Redis Cluster na migração de dados, e o Codis também possui uma interface de operação e manutenção muito amigável, que é conveniente para o DBA executar operações como adicionar e excluir nós, comutação mestre-escravo e migração de dados.
3. Sobrecarga de comunicação: o principal fator que limita a escala do Redis Cluster
1: Por que o tamanho do cluster deve ser limitado?
A quantidade de dados que o Redis Cluster pode armazenar e a taxa de transferência suportada estão intimamente relacionadas ao tamanho da instância do cluster. Redis dá oficialmente o limite superior da escala do Redis Cluster, ou seja, um cluster executa 1000 instâncias
Um fator chave aqui é que a sobrecarga de comunicação entre as instâncias aumentará à medida que a escala da instância aumentar. Quando o cluster exceder uma determinada escala (como 800 nós), a taxa de transferência do cluster diminuirá. Portanto, o tamanho real do cluster será limitado .
2: Método de comunicação da instância e impacto no tamanho do cluster
Quando o Cluster Redis estiver em execução, cada instância salvará o relacionamento correspondente entre o Slot e a instância (ou seja, a tabela de mapeamento do Slot), bem como suas próprias informações de status.
Para que cada instância no cluster conheça as informações de estado de todas as outras instâncias, as instâncias se comunicarão de acordo com certas regras. Esta regra é o protocolo Gossip
2.1 Protocolo de fofoca
O princípio de funcionamento do protocolo Gossip pode ser resumido em dois pontos. : Quando a instância for detectada online\retorne uma mensagem PONG para a instância que envia o comando PING
- Primeiro, cada instância selecionará aleatoriamente algumas instâncias do cluster de acordo com uma determinada frequência e enviará mensagens PING para as instâncias selecionadas para detectar se essas instâncias estão online e trocar informações de status entre si. A mensagem PING encapsula as informações de status da própria instância que envia a mensagem, as informações de status de algumas outras instâncias e a tabela de mapeamento de slots.
- Em segundo lugar, após uma instância receber uma mensagem PING, ela enviará uma mensagem PONG para a instância que enviou a mensagem PING. As mensagens PONG contêm o mesmo conteúdo das mensagens PING.

O protocolo Gossip pode garantir que, após um período de tempo, cada instância no cluster possa obter as informações de estado de todas as outras instâncias.
Dessa forma, mesmo que ocorram eventos como entrada de novo nó, falha de nó e mudança de slot, o status do cluster pode ser sincronizado em cada instância por meio da transmissão de mensagens PING e PONG
3. Impacto da comunicação
Ao usar o protocolo Gossip para comunicação entre instâncias, o overhead de comunicação é afetado pelo tamanho da mensagem de comunicação e pela frequência de comunicação. Quanto maiores e mais frequentes forem as mensagens, maior será o overhead de comunicação correspondente. Se você deseja obter uma comunicação eficiente, pode partir desses dois aspectos para sintonizar
3.1 Tamanho da mensagem de fofoca
O corpo da mensagem PING enviada pela instância do Redis é composto pela estrutura clusterMsgDataGossip, que é definida da seguinte forma:
typedef struct {
char nodename[CLUSTER_NAMELEN]; //40 bytes
uint32_t ping_sent; //4 bytes
uint32_t pong_received; //4 bytes
char ip[NET_IP_STR_LEN]; //46 bytes
uint16_t port; //2 bytes
uint16_t cport; //2 bytes
uint16_t sinalizadores; //2 bytes
uint32_t notused1; //4 bytes
} clusterMsgDataGossip;
Entre eles, os valores de CLUSTER_NAMELEN e NET_IP_STR_LEN são 40 e 46 respectivamente, indicando que os comprimentos das matrizes de dois bytes de nodename e ip são 40 bytes e 46 bytes, e somamos o tamanho de outras informações na estrutura para get Você pode obter o tamanho de uma mensagem Gossip, que é de 104 bytes.
Quando cada instância enviar uma mensagem Gossip, além de suas próprias informações de status, ela também transmitirá as informações de status de um décimo das instâncias do cluster por padrão.
exemplo
Portanto, para um cluster contendo 1000 instâncias, quando cada instância enviar uma mensagem PING, ela conterá as informações de status de 100 instâncias, o volume total de dados é de 10400 bytes, mais as informações enviadas pela própria instância, Uma mensagem Gossip tem cerca de 10KB . Para permitir que a tabela de mapeamento de Slots seja propagada entre diferentes instâncias, a mensagem PING também contém um Bitmap com comprimento de 16.384 bits. Cada bit do Bitmap corresponde a um Slot. Se um determinado bit for 1, significa que o O slot pertence à instância atual. Depois que o tamanho do bitmap é convertido em bytes, o tamanho de uma mensagem PING pode ser obtido adicionando as informações de status da instância de 2 KB e as informações de alocação de slot, que são cerca de 12 KB.
A mensagem PONG tem o mesmo conteúdo da mensagem PING e seu tamanho é de cerca de 12KB. Após cada instância enviar uma mensagem PING, ela também receberá uma mensagem PONG retornada e o total das duas mensagens é de 24 KB.
Do ponto de vista do valor absoluto, 24 KB não é muito grande, mas se uma única solicitação normalmente processada por uma instância tiver apenas alguns KB, a mensagem PING/PONG transmitida pela instância para manter um estado de cluster consistente será maior do que uma única solicitação de negócios. Além disso, cada instância envia mensagens PING/PONG para outras instâncias. À medida que o tamanho do cluster aumenta, o número dessas mensagens de pulsação aumentará, o que ocupará uma parte da largura de banda de comunicação de rede do cluster, reduzindo assim o throughput das solicitações normais do cliente do serviço de cluster.
3.2 Frequência de comunicação entre instâncias
Depois que a instância do Redis Cluster é iniciada, por padrão, 5 instâncias serão selecionadas aleatoriamente da lista de instâncias locais a cada segundo e, em seguida, uma instância que não se comunicou por mais tempo será encontrada dessas 5 instâncias e uma mensagem PING será enviado para a instância. Este é o método básico para a instância enviar mensagens PING periodicamente
Há um problema aqui: a instância selecionada pela instância que não se comunica há mais tempo é selecionada a partir de 5 instâncias selecionadas aleatoriamente, o que não garante que essa instância seja a instância que não se comunica há mais tempo em todo o cluster. Pode acontecer que algumas instâncias não tenham recebido mensagens PING, fazendo com que o estado do cluster que elas mantêm expirou.
Para evitar esta situação, a instância Redis Cluster irá varrer a lista de instâncias locais a cada 100 ms. Se for descoberto que a última vez que uma instância recebe uma mensagem PONG é maior que a metade do item de configuração cluster-node- timeout (cluster -node-timeout/2), uma mensagem PING será enviada para a instância imediatamente para atualizar as informações de status do cluster na instância
Quando o tamanho do cluster aumenta, os atrasos de comunicação de rede entre as instâncias aumentam devido ao congestionamento da rede ou à competição de tráfego entre diferentes servidores. Se algumas instâncias não puderem receber mensagens PONG enviadas por outras instâncias, isso fará com que mensagens PING frequentes sejam enviadas entre as instâncias, o que, por sua vez, trará sobrecarga adicional para a comunicação de rede do cluster
Resuma o número de mensagens PING enviadas pela instância do pedido por segundo, da seguinte forma:
Número de mensagens PING enviadas = 1 + 10 * número de instâncias (a última vez que uma mensagem PONG foi recebida excede o cluster-node-timeout/2)
Entre eles, 1 significa que uma única instância normalmente envia uma mensagem PING a cada 1 segundo e 10 significa que a instância fará 10 verificações a cada 1 segundo e, após cada verificação, uma mensagem será enviada para a instância cuja mensagem PONG atinge o tempo limite .
exemplo
Supondo que uma única detecção de instância descubra que 10 instâncias de mensagens PONG recebem tempo limite a cada 100 milissegundos, essa instância enviará 101 mensagens PING por segundo, contabilizando cerca de 1,2 MB/s de largura de banda. Se 30 instâncias no cluster enviarem mensagens nessa frequência, isso consumirá 36 MB/s de largura de banda, o que ocupará a largura de banda no cluster usada para atender às solicitações normais
4. Como reduzir o overhead de comunicação entre as instâncias?
4.1 Reduzir o tamanho da mensagem transmitida pela instância
Para reduzir a sobrecarga de comunicação entre instâncias, em princípio, o tamanho da mensagem transmitida pela instância (mensagem PING/PONG, informações de alocação de slot) pode ser reduzido. No entanto, como as instâncias do cluster dependem de mensagens PING, PONG e slot alocação de informações para manter o cluster A unificação do estado, uma vez que o tamanho da mensagem transmitida é reduzido, levará à redução das informações de comunicação entre as instâncias, o que não favorece a manutenção do cluster. Portanto, esse método não pode ser usado para reduzir o tamanho da mensagem transmitida pela instância.
4.2 Reduzir a frequência de envio de mensagens entre as instâncias:
Existem duas frequências nas quais as mensagens são enviadas entre as instâncias.
- Cada instância envia uma mensagem PING a cada 1 segundo. Essa frequência não é alta. Se a frequência for reduzida ainda mais, o status de cada instância no cluster pode não ser capaz de ser propagado no tempo.
- Cada instância fará uma detecção a cada 100 milissegundos e enviará mensagens PING para nós que recebem mensagens PONG por mais de cluster-node-timeout/2. A frequência com que a instância verifica a cada 100 milissegundos é a frequência unificada da tarefa de inspeção periódica padrão da instância do Redis e geralmente não precisamos modificá-la.
Somente o item de configuração cluster-node-timeout pode ser modificado
O item de configuração cluster-node-timeout define o tempo limite de pulsação para que a instância de cluster seja considerada com falha e o padrão é 15 segundos. Se o valor de tempo limite do nó do cluster for relativamente pequeno, em um cluster de grande escala, o tempo limite de recepção da mensagem PONG ocorrerá com mais frequência, fazendo com que a instância execute "enviar mensagem PING para a instância de tempo limite da mensagem PONG" 10 vezes por segundo "Esta operação
Portanto, para evitar mensagens de pulsação excessivas ocupando a largura de banda do cluster, você pode aumentar o valor de tempo limite do nó do cluster, por exemplo, para 20 segundos ou 25 segundos. Dessa forma, o tempo limite de recebimento de mensagens PONG será reduzido e a única instância não precisará enviar frequentemente pulsações 10 vezes por segundo.
Não ajuste o tempo limite do nó do cluster muito grande, caso contrário, se a instância realmente falhar, ela precisará aguardar o tempo limite do nó do cluster para detectar a falha, o que prolongará o tempo real de recuperação da falha, afetará o normal uso de serviços de cluster
Para verificar se o ajuste do valor de cluster-node-timeout pode reduzir a largura de banda da rede do cluster ocupada por mensagens heartbeat, sugere-se que antes e depois de ajustar o valor de cluster-node-timeout, você pode usar o comando tcpdump para capturar os pacotes de rede de informações de heartbeat enviados pela instância.
Depois de executar o seguinte comando, você pode capturar o pacote de rede heartbeat enviado pela instância na máquina 192.168.10.3 da porta 16379 e salvar o conteúdo do pacote de rede no arquivo r1.cap:
tcpdump host 192.168.10.3 porta 16379 -i nome da placa de rede -w /tmp/r1.cap
Ao analisar o número e o tamanho dos pacotes de rede, você pode julgar a largura de banda ocupada por mensagens de heartbeat antes e depois de ajustar o valor do cluster-node-timeout.
5. Resumo da sobrecarga de comunicação:
Um mecanismo para comunicação entre instâncias do Redis Cluster usando o protocolo Gossip. Quando o Redis Cluster está em execução, cada instância precisa trocar informações por meio de mensagens PING e PONG, que contêm as informações de status da instância atual e de algumas outras instâncias, bem como informações de alocação de slots. Esse mecanismo de comunicação ajuda todas as instâncias no Redis Cluster a terem informações completas sobre o estado do cluster.
No entanto, à medida que o tamanho do cluster aumenta, também aumenta a quantidade de comunicação entre as instâncias. Se você expandir cegamente o Redis Cluster, poderá experimentar um desempenho lento do cluster. Isso ocorre porque as mensagens de pulsação entre instâncias em grande escala no cluster ocuparão a largura de banda do cluster para processar solicitações normais. Além disso, algumas instâncias podem não conseguir receber mensagens PONG a tempo devido ao congestionamento da rede. Cada instância detectará periodicamente (10 vezes por segundo) se isso acontece quando estiver em execução. Assim que ocorrer, enviará essas mensagens PONG imediatamente. As instâncias que expiram enviam mensagens de heartbeat.
Quanto maior o tamanho do cluster, maior a probabilidade de congestionamento da rede.Correspondentemente, maior a probabilidade de tempo limite da mensagem PONG, o que levará a um grande número de mensagens de heartbeat no cluster e afetará as solicitações normais do serviço de cluster. Você pode reduzir a largura de banda ocupada por mensagens de pulsação ajustando o item de configuração cluster-node-timeout. No entanto, em aplicações práticas, se você não precisar particularmente de um cluster de grande capacidade, é recomendável controlar o tamanho do Redis Cluster para 400 ~ 500 instâncias.
Assumindo que uma única instância pode suportar 80.000 operações de solicitação por segundo (80.000 QPS) e cada instância master é configurada com uma instância slave, então 400 ~ 500 instâncias podem suportar 16 milhões a 20 milhões de QPS (200/250 instâncias master* 80.000 QPS =16 milhões/20 milhões de QPS), esse desempenho de taxa de transferência pode atender às necessidades de muitos aplicativos de negócios
Se usarmos um método semelhante ao Codis para salvar as informações de alocação de slots e armazenar as informações de status da instância do cluster e as informações de alocação de slots em um sistema de armazenamento de terceiros (como o Zookeeper), esse método terá algum impacto no tamanho do cluster?
Resposta: Supondo que usamos o Zookeeper como um sistema de armazenamento de terceiros para armazenar informações de status de instância de cluster e informações de alocação de slot, as instâncias precisam apenas se comunicar e trocar informações com o Zookeeper e não há necessidade de enviar um grande número de heartbeat mensagens entre instâncias para sincronizar o status do cluster. Essa prática reduz a quantidade de tráfego de rede usado para pulsação entre as instâncias, o que ajuda a obter clusters de grande escala.
Além disso, a largura de banda da rede pode ser focada em atender às solicitações do cliente. No entanto, neste caso, quando uma instância obtém ou atualiza as informações de status do cluster, ela precisa interagir com o Zookeeper, e os requisitos de largura de banda de comunicação de rede do Zookeeper aumentarão. Portanto, ao utilizar este método, é necessário garantir uma certa largura de banda de rede para o Zookeeper, de modo a evitar que o Zookeeper não consiga se comunicar com as instâncias rapidamente devido a limitações de largura de banda.