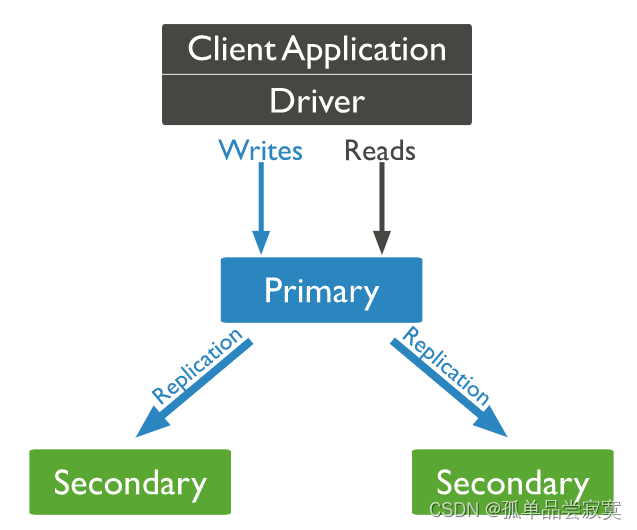
Conjunto de réplicas do MongoDB
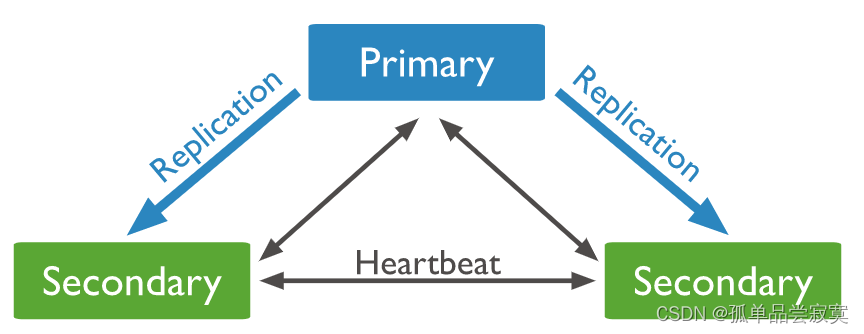
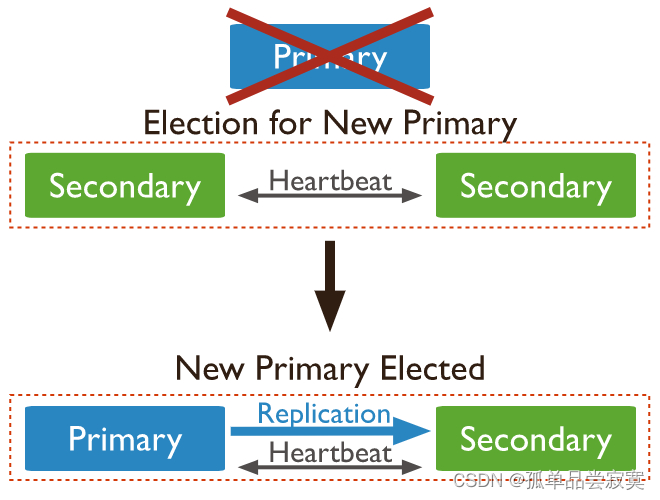
Arquitetura do Conjunto de Réplicas

mkdir ‐p /data/db{1,2,3}systemLog:
destination: file
path: /data/db1/mongod.log # log path
logAppend: true
storage:
dbPath: /data/db1 # data directory
net:
bindIp: 0.0.0.0
port: 28017 # port
replication:
replSetName: rs0
processManagement:
fork: truemongod ‐f /data/db1/mongod.conf
mongod ‐f /data/db2/mongod.conf
mongod ‐f /data/db3/mongod.conf# 永久关闭,将SELINUX=enforcing改为SELINUX=disabled,设置后需要重启才能生效
vim /etc/selinux/config
# 查看SELINUX
/usr/sbin/sestatus ‐v# mongo ‐‐port 28017
# 初始化复制集
> rs.initiate()
# 将其余成员添加到复制集
> rs.add("192.168.65.174:28018")
> rs.add("192.168.65.174:28019")# mongo ‐‐port 28017
# 初始化复制集
> rs.initiate({
_id: "rs0",
members: [{
_id: 0,
host: "192.168.65.174:28017"
},{
_id: 1,
host: "192.168.65.174:28018"
},{
_id: 2,
host: "192.168.65.174:28019"
}]
})# mongo ‐‐port 28017
rs0:PRIMARY> db.user.insert([{name:"fox"},{name:"monkey"}])# mongo ‐‐port 28018
# 指定从节点可读
rs0:SECONDARY> rs.secondaryOk()
rs0:SECONDARY> db.user.find()rs.status()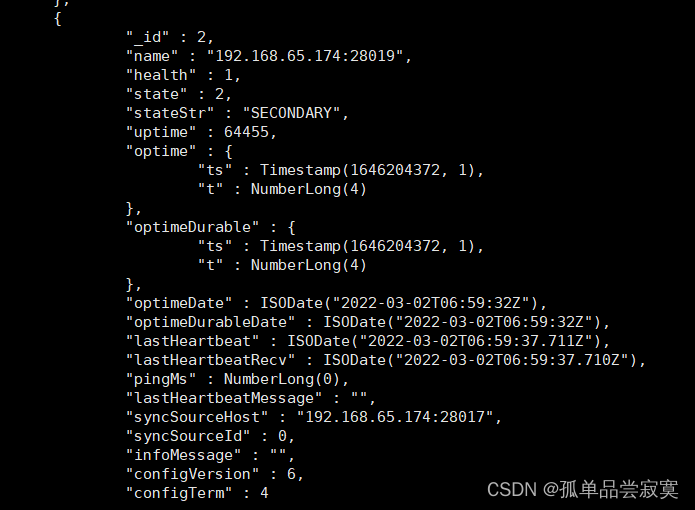
Veja as funções atuais do nó:
db.isMaster()Comandos do Conjunto de Réplicas do Mongo Shell
| comando |
descrever |
| rs . adicionar() |
Adicionar novos nós |
| rs.ad dArb () |
Adicionar um |
| rs.conf() |
Retorne as informações de configuração do conjunto de réplicas |
| rs.fr eeze () |
Impedir que o nó atual seja eleito como o nó mestre por um período de tempo |
| rs.ajuda() |
Ajuda de comando de retorno para conjunto de réplicas |
| rs. iniciar () |
Inicializar um novo conjunto de réplicas |
| rs.printReplicationInfo ( ) |
Retorna um relatório de status da replicação da perspectiva do nó mestre |
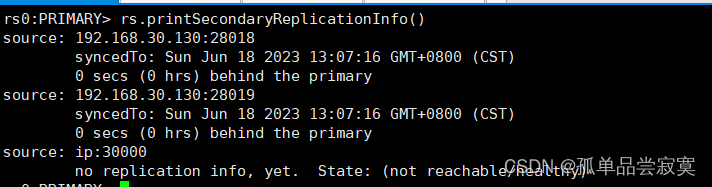
| rs.printSeconda ryReplicationInfo () |
Retorna um relatório de status de replicação da perspectiva do nó escravo |
| rs. reconfigurar () |
Atualize a configuração para o conjunto de réplicas reaplicando |
| rs.re mover () |
Remover um nó de um conjunto de réplicas |
| rs . secundárioOk ( ) |
Define o nó escravo para ser legível para a conexão atual |
| rs.st atus () |
Retorna informações de status do conjunto de réplicas. |
| rs. stepdown () |
Deixe o primário atual se tornar um nó escravo e acionar a eleição |
| rs. sincronizarDe () |
Defina o nó do qual o nó do conjunto de réplicas sincroniza os dados, o que substituirá a lógica de seleção padrão |
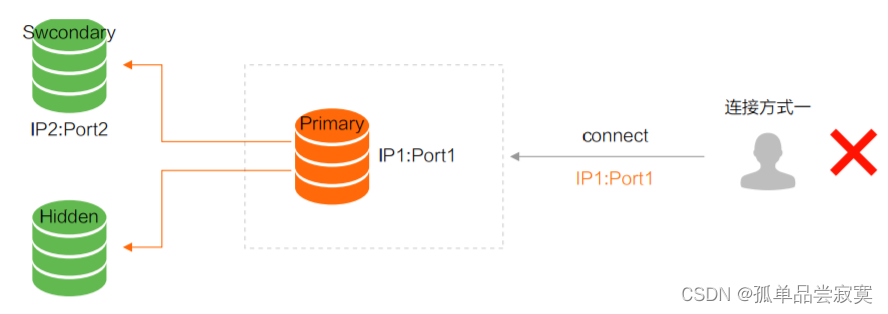
Método de conexão do conjunto de réplicas

configuração do conjunto de réplicas da operação springboot
spring:
data:
mongodb:
uri:
mongodb://yanqiuxiang:[email protected]:192.168.30.130:192.168.30.130:28019/test?authSource=admin&replicaSet=rs0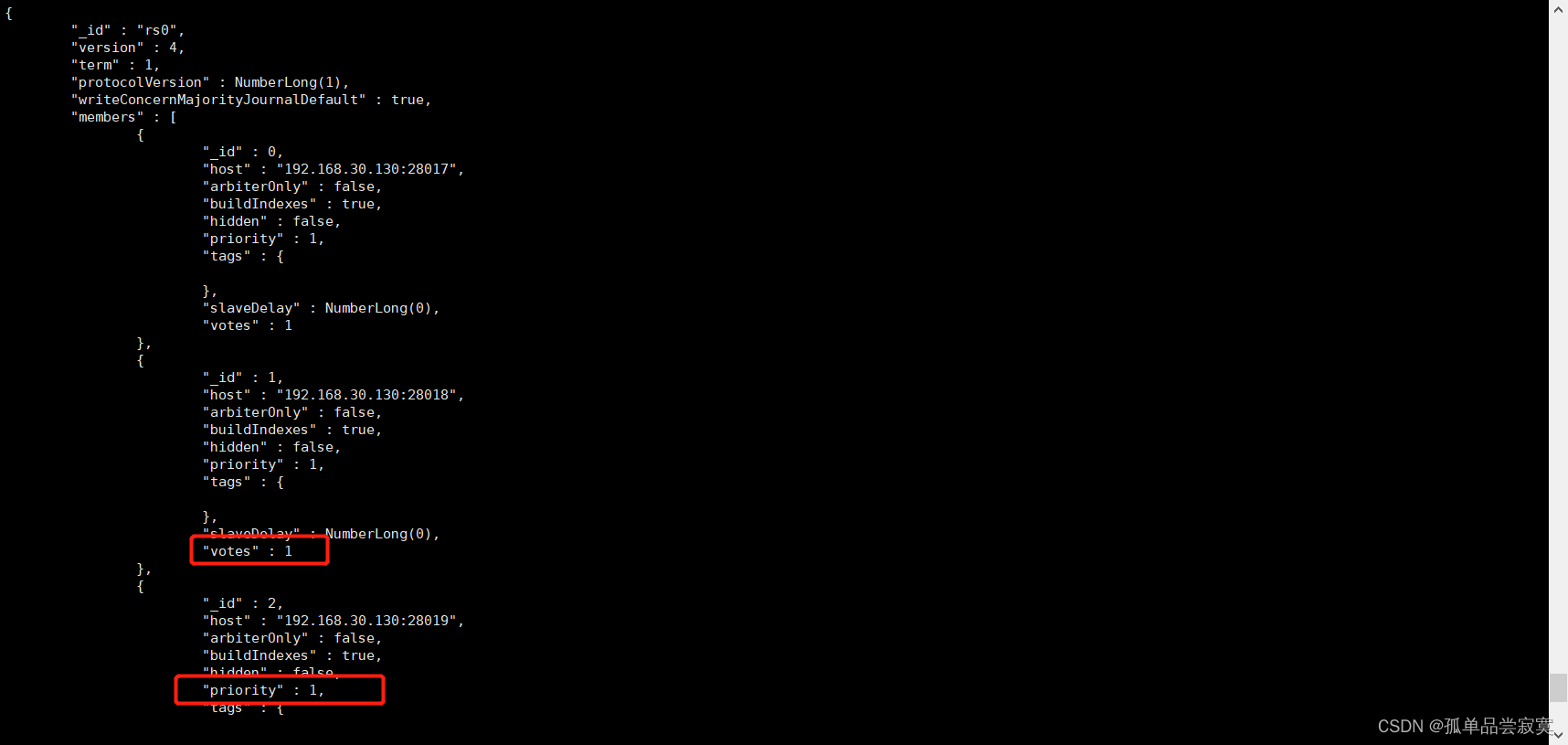
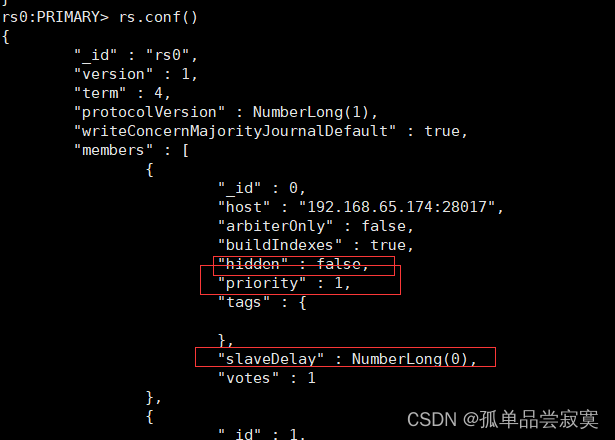
Configurar nós ocultos
cfg = rs.conf()
cfg.members[1].priority = 0
cfg.members[1].hidden = true
rs.reconfig(cfg)cfg = rs.conf()
cfg.members[1].priority = 0
cfg.members[1].hidden = true
#延迟1分钟
cfg.members[1].slaveDelay = 60
rs.reconfig(cfg)
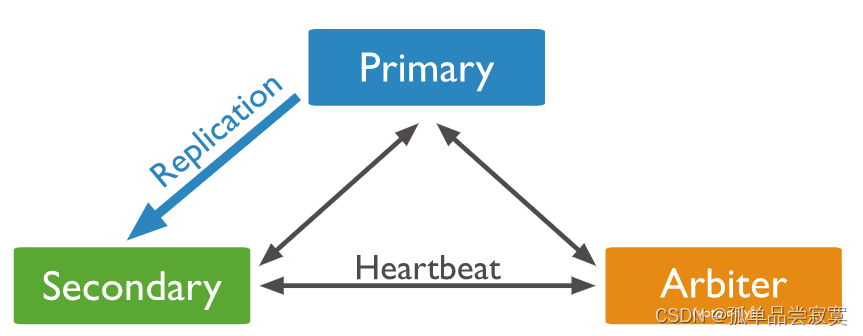
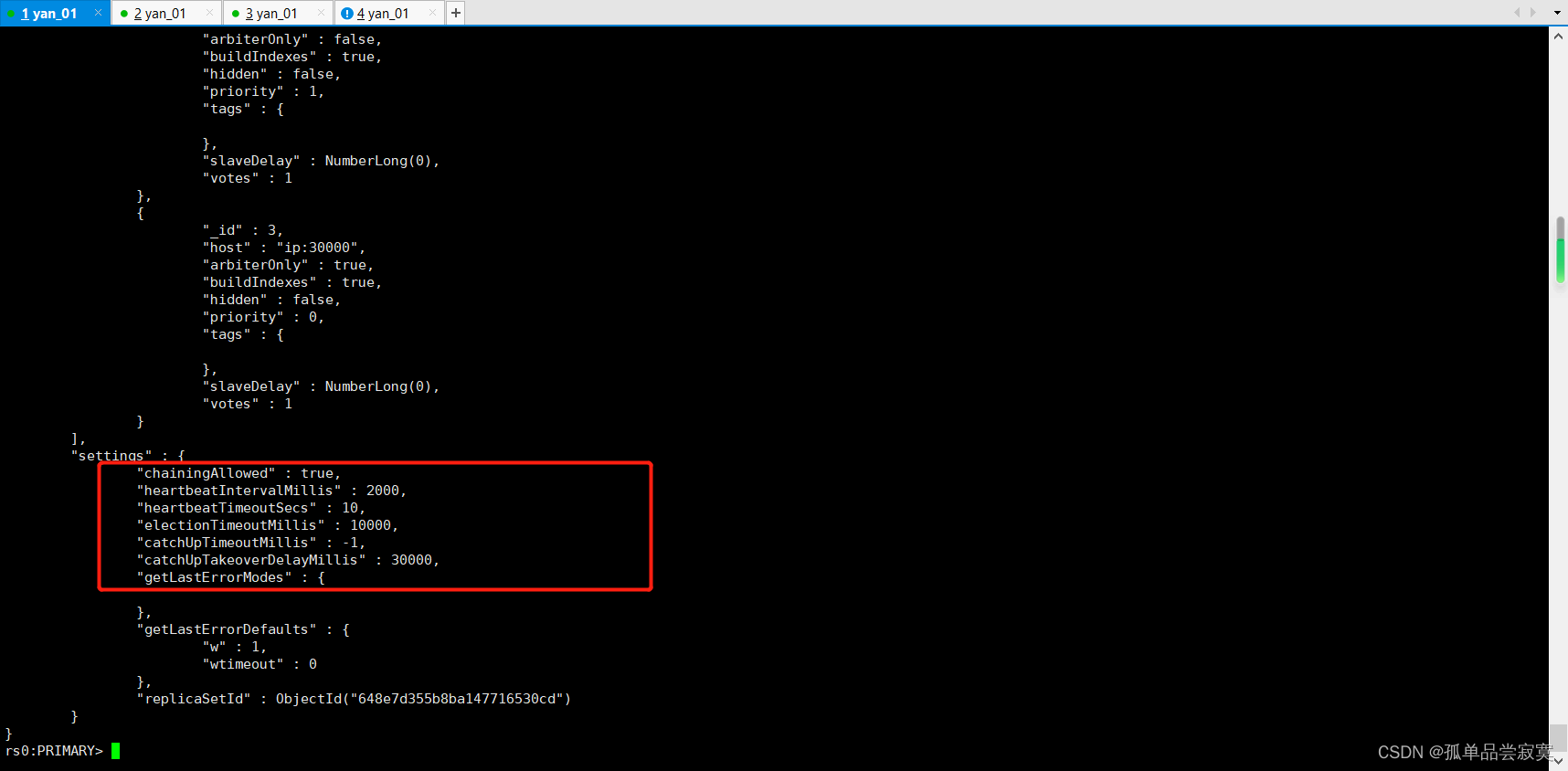
Adicionar nó de votação
# 为仲裁节点创建数据目录,存放配置数据。该目录将不保存数据集
mkdir /data/arb
# 启动仲裁节点,指定数据目录和复制集名称
mongod ‐‐port 30000 ‐‐dbpath /data/arb ‐‐replSet rs0
# 进入mongo shell,添加仲裁节点到复制集
rs.addArb("ip:30000")rs.remove("ip:port")cfg = rs.conf()
cfg.members.splice(2,1) #从2开始移除1个元素
rs.reconfig(cfg)cfg = rs.conf()
cfg.members[0].host = "ip:port"
rs.reconfig(cfg)| Membros votantes |
maioria |
Número de Falhas Toleradas |
| 1 |
1 |
0 |
| 2 |
2 |
0 |
| 3 |
2 |
1 |
| 4 |
3 |
1 |
| 5 |
3 |
2 |
| 6 |
4 |
2 |
| 7 |
4 |
3 |

Avaliação de impacto nos negócios
# MongoDB Drivers 启用可重试写入
mongodb://localhost/?retryWrites=true
# mongo shell
mongo ‐‐retryWrites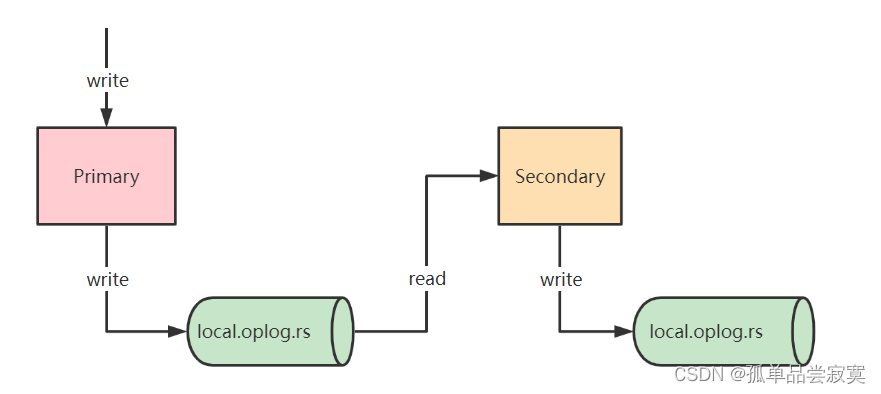
o que é oplog

use local
db.oplog.rs.find().sort({$natural:‐1}).pretty()
oplogSizeMB = min(磁盘可用空间*5%,50GB)# 将复制集成员的oplog大小修改为60g 指定大小必须大于990M
db.adminCommand({replSetResizeOplog: 1, size: 60000})
# 查看oplog大小
use local
db.oplog.rs.stats().maxSizedb.coll.insert({_id:1,x:[1,2,3]})rs0:PRIMARY> db.coll.update({_id: 1}, {$push: {x: { $each: [4, 5] }}})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
rs0:PRIMARY> db.coll.find()
{ "_id" : 1, "x" : [ 1, 2, 3, 4, 5 ] }
rs0:PRIMARY> use local
switched to db local
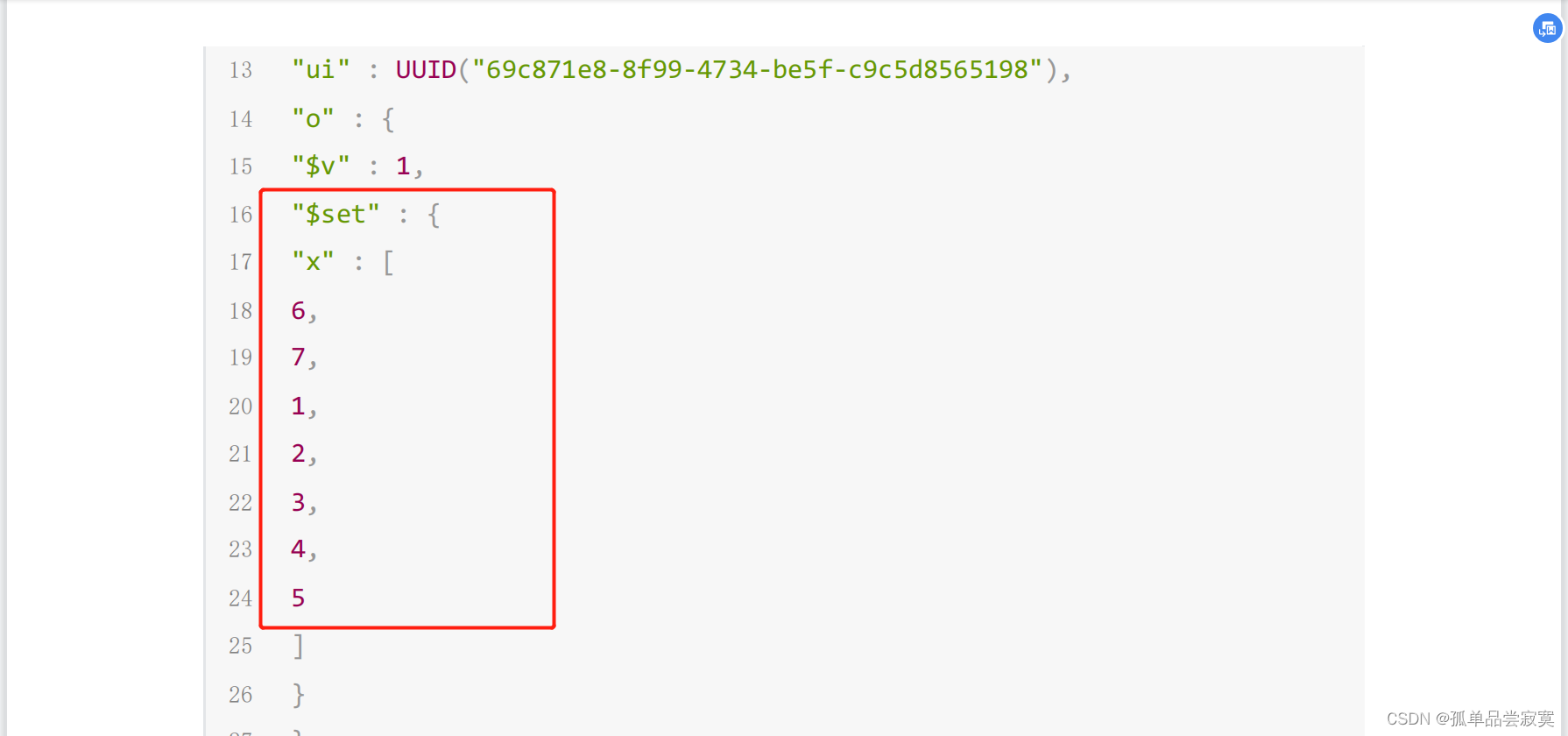
rs0:PRIMARY> db.oplog.rs.find({ns:"test.coll"}).sort({$natural:‐1}).prett
()
{
"op" : "u",
"ns" : "test.coll",
"ui" : UUID("69c871e8‐8f99‐4734‐be5f‐c9c5d8565198"),
"o" : {
"$v" : 1,
"$set" : {
"x.3" : 4,
"x.4" : 5
}
},
"o2" : {
"_id" : 1
},
"ts" : Timestamp(1646223051, 1),
"t" : NumberLong(4),
"v" : NumberLong(2),
"wall" : ISODate("2022‐03‐02T12:10:51.882Z")
}
mongorestore ‐‐host 192.168.30.130:27018 ‐‐db test ‐‐collection emp ‐u yanqiuxiang ‐p
yanqiuxiang
‐‐authenticationDatabase=admin rollback/emp_rollback.bsoncfg = rs.config()
cfg.settings.chainingAllowed = false
rs.reconfig(cfg)db.adminCommand( { replSetSyncFrom: "hostname:port" })