01 Status atual do data warehouse
O tempo de estabelecimento da pequena empresa A é relativamente curto e acaba de completar seu segundo aniversário; a taxa de crescimento dos negócios é rápida, os dados estão aumentando rapidamente e, ao mesmo tempo, a demanda por acesso a dados está aumentando rapidamente e o cenários de aplicativos de dados têm cada vez mais requisitos para qualidade de dados, velocidade de resposta, pontualidade e estabilidade de dados. Quanto maior, mas os recursos técnicos ficam atrás do crescimento dos negócios, como recursos técnicos de data warehouse em tempo real, alta disponibilidade e recursos de garantia de estabilidade, falta de especificações de processo, etc. Essas capacidades ficam seriamente atrás do desenvolvimento de negócios, e algumas até permanecem no estágio inicial caso a caso da criação da empresa. De acordo com o fluxo de dados no data warehouse (como mostrado na figura abaixo), o pequeno A classifica os problemas na construção do data warehouse desde a medição do sistema de negócios upstream até o data warehouse interno e, finalmente, para o aplicativo de dados downstream .
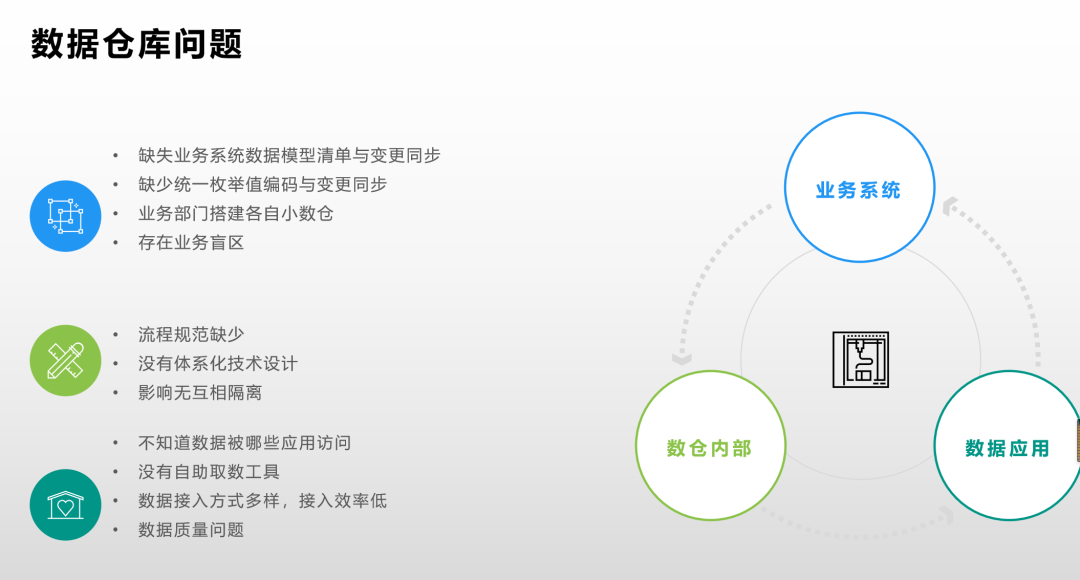
Lado do sistema de negócios [upstream]
O data warehouse primeiro precisa coletar os dados de negócios estruturados, dados de log e dados de pontos incorporados do sistema de negócios; os principais problemas na conexão entre o data warehouse e o sistema de negócios upstream são os seguintes:
-
A lista de modelos de dados do sistema de negócios ausentes é sincronizada com as alterações : não há registro dos modelos de dados que foram coletados no sistema de negócios do data warehouse e não há notificação para o data warehouse quando o modelo de dados do sistema de negócios é A maioria deles ocorre após a ocorrência de problemas ou os usuários de dados informam o warehouse posteriormente.
-
Falta de codificação de valor de enumeração unificada e sincronização de alteração : O sistema de negócios não possui uma codificação de valor de enumeração unificada. Por exemplo, o status do pedido inclui: colocação do pedido, aceitação do pedido e conclusão do pedido. Esses valores de enumeração não são gerenciados uniformemente; se o status do pedido for alterado posteriormente Adicionado um: cancelar o status do pedido, essa alteração não foi notificada ao data warehouse.
-
Os departamentos de negócios constroem seus próprios depósitos decimais : alguns departamentos ignoram os depósitos de dados e acessam diretamente as fontes de dados upstream para construir seus próprios depósitos decimais, resultando em silos de dados, contagem dupla e inconsistências.
-
Existem pontos cegos de negócios : alguns negócios exigem experiência em conhecimento profissional, como: finanças; algumas regras de negócios têm um alto nível de confidencialidade e a lógica de negócios não pode ser divulgada a pessoas não relacionadas aos negócios, como controle de riscos; portanto, é impossível para resolver sistematicamente a relação entre essas entidades de negócios e refinar os indicadores, para compartilhar dados.
Dentro do armazém
Nos primeiros dias da criação da empresa, a quantidade de dados era relativamente pequena, os requisitos de dados não eram muitos e os cenários de aplicação de dados eram relativamente simples. Era mais para satisfazer relatórios simples. Portanto, o armazenamento de dados foi impulsionado principalmente por tomada de pedidos, e a demanda foi feita uma a uma, caso a caso, principalmente para atender rapidamente a demanda. No entanto, com o rápido aumento dos negócios, a quantidade vertiginosa de dados e a diversificação dos cenários de aplicação de dados, os seguintes problemas são gradualmente expostos:
-
Falta de especificação do processo : não há processo e especificação para orientar os desenvolvedores de dados a padronizar a construção de dados de acordo com o processo, resultando em classificação de dados pouco clara e confusão de dados; nomenclatura não padronizada, nomes diferentes com o mesmo nome e nomes diferentes com o mesmo nome mesmo nome; construção repetida de dados, redundância Muitos dados.
-
Nenhum projeto técnico sistemático : seja coleta, processamento e distribuição de dados off-line ou em tempo real, há uma falta de projeto e construção sistemáticos, e mais deve ser reparado caso a caso anterior; por exemplo, a mesma fonte de dados é coletado offline e em tempo real; Não há diferença entre a extração completa de todas as fontes de dados e o cálculo completo da camada DWD para DWS; T+1 e desenvolvimento de chaminé em lote por hora, mesma tabela ampla offline e desenvolvimento de chaminé em tempo real, cálculo repetido e armazenamento, sem diferença para diferentes cenários de aplicação A diferença usa o mesmo armazenamento e cálculo, etc.;
-
Não há isolamento mútuo de impacto : o armazenamento de dados e a computação em armazéns de dados não são isolados do armazenamento e da tecnologia do serviço de aplicativos de dados, e os recursos são separados uns dos outros e os problemas são ampliados; ao mesmo tempo, o design do modelo subjacente dos dados warehouse é difícil de ser compatível com a necessidade de design do modelo de camada de aplicativo de dados
Teste de Aplicação de Dados【Downstream】
Os armazéns de dados precisam fornecer dados para diferentes cenários de aplicativos de dados (controle de vento, C-end, operações de negócios, etc.), e diferentes requisitos de aplicativos de dados são inconsistentes e existem muitas diferenças; ao mesmo tempo, o valor dos dados em diferentes cenários de aplicação também é diferente. Portanto, é necessário entender claramente os cenários de aplicação de dados do downstream e os problemas existentes para melhor atender o lado da aplicação de dados. O downstream apresenta principalmente os seguintes problemas:
-
Nenhuma compreensão dos cenários de aplicação de dados : nenhuma compreensão ou compreensão profunda dos cenários de aplicação de demanda de dados downstream, nenhuma avaliação da seleção de tecnologia para diferentes cenários, uso simples e rude de um truque para conquistar o mundo e um conjunto de computação e armazenamento para diferentes cenários.
-
Não se sabe por quais aplicativos os dados são acessados : não há monitoramento e registro do uso de dados por aplicativos downstream e é impossível quantificar o uso e o valor dos dados
-
Nenhuma prioridade de demanda de dados quantificada : nenhum mecanismo de avaliação de prioridade para demanda de dados downstream, nenhuma prioridade de demanda de dados quantificada
-
Nenhuma ferramenta de acesso de autoatendimento : não há capacidade de acesso downstream, resultando na maior parte do trabalho de acesso que ainda depende do desenvolvimento de dados para ser concluído. A maior parte do tempo de desenvolvimento de dados é ocupada pela demanda de acesso temporário, sendo impossível focar na construção do modelo de data warehouse e na construção dos dados da camada de mercado e, finalmente, forma um círculo vicioso. Por um lado, os dados não são perfeitos, por outro lado, são O desenvolvimento de dados está ocupado com vários requisitos de acesso temporário.
-
Vários métodos de acesso a dados e baixa eficiência de acesso : Cada aplicativo de dados deve desenvolver códigos correspondentes com base em diferentes armazenamentos intermediários. Se vários armazenamentos intermediários estiverem envolvidos, vários conjuntos de códigos precisam ser desenvolvidos e a eficiência de acesso a dados é muito baixa.
-
Problemas de qualidade de dados : os dados geralmente levam a resultados de cálculo incorretos devido ao BUG, que eventualmente leva a decisões de negócios erradas.
02 Como resolver o problema
Lado do sistema de negócios [upstream]
A colaboração com o lado do sistema de negócios requer comunicação e cooperação interdepartamental, portanto, processos e padrões de comunicação são necessários para permitir que ambas as partes se concentrem em objetivos públicos; ao mesmo tempo, a relação de convivência entre você e eu deve ser mantida. Propõe principalmente soluções antes, durante e depois do evento.
-
De antemão : Estabeleça um mecanismo de notificação e um processo colaborativo com o upstream para sincronizar negócios e mudanças de modelo em tempo hábil; assuma a camada ODS e controle a fonte. ODS é a primeira parada para os dados de negócios entrarem no data warehouse e na fonte de todo o processamento de dados. Somente controlando a fonte podemos fundamentalmente prevenir o surgimento de um sistema de dados duplicado.
-
Em andamento : Captura metadados upstream e alterações de valor de dicionário por meios técnicos, de modo a facilitar o rastreamento de problemas futuros e a análise de impacto
-
Após o evento : otimize o processo e a tecnologia iterativa por meio da revisão pós-evento
Dentro do armazém
O data warehouse precisa principalmente resolver esses problemas de várias dimensões, como sistema técnico, especificação de processo e estrutura de dados.
Formular procedimentos e especificações
Processo de desenvolvimento de dados:

Especificação de desenvolvimento de dados:

A especificação do data warehouse inclui principalmente os seguintes conteúdos:
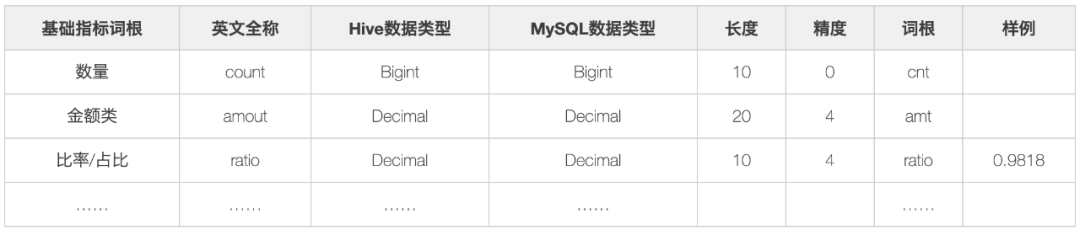
1. Dicionário básico [raiz da palavra]
A palavra raiz é o termo comercial mais refinado da empresa e é a base do gerenciamento de dimensões e índices. A palavra raiz pode ser usada para unificar nomes de tabelas, nomes de campos e nomes de domínios de assuntos; estabelecer e manter uma raiz convergente biblioteca, e podemos usar domínios de negócios e domínios de assunto. A forma de enumerar a raiz é clara e constantemente aprimorada, e a granularidade é a mesma. Os principais são granularidade de tempo, dia, mês, ano, semana etc. , use a raiz para definir a abreviação e os nomes dos campos desenvolvidos pelo data warehouse também podem ser combinados usando a raiz; divisão Para raízes comuns e próprias:
-
Raiz comum: a menor unidade que descreve as coisas, como: transação-comércio.
-
Raiz proprietária: Possui uma descrição convencional ou específica do setor, como: US dollar-USD.
Exemplos de palavras de raiz são os seguintes:
2. Especificações básicas
Domínio de dados: divisão vertical de dados, conforme mostrado na figura abaixo

Nível de dados: camadas horizontais de dados, conforme mostrado na figura abaixo

3. Convenção de nomenclatura
Padronizar a nomenclatura dos modelos e padronizar a nomenclatura de cada camada (ODS, DWD, DWS, DM).Na fase posterior, você pode considerar o uso de ferramentas como as convenções de nomenclatura a seguir para fornecer eficiência e recursos de controle.

4. Avaliação normativa
Meça a padronização dos seguintes ângulos

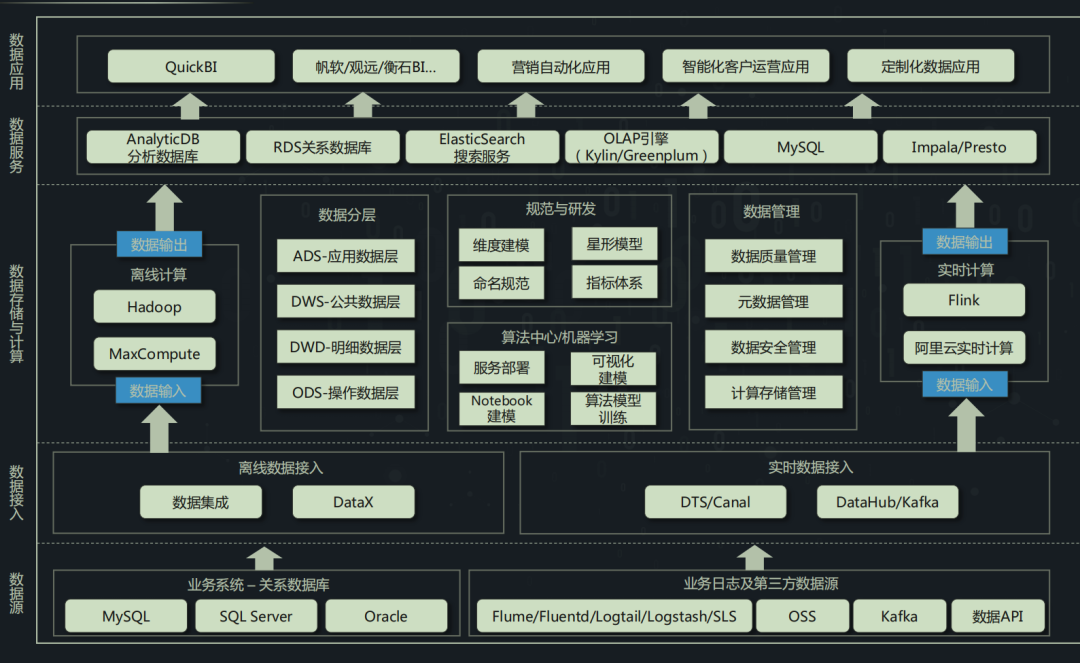
03 Projeto de Arquitetura do Sistema
Projeto de arquitetura técnica desde coleta horizontal, processamento, valor agregado, distribuição e sistematização offline vertical em tempo real.
dimensão consistente
Uma dimensão consistente significa que, se duas dimensões estiverem relacionadas, elas são exatamente iguais ou uma dimensão é um subconjunto da outra em um sentido matemático. Por exemplo, se uma dimensão de mês for criada, as várias descrições da dimensão de mês devem ser totalmente consistentes com as da dimensão de data. A forma mais comum é criar uma exibição na dimensão de data para gerar a dimensão de mês. Dessa forma, a dimensão do mês pode ser um subconjunto da dimensão da data, que pode ser consistente em operações subsequentes, como drill. Se a quantidade de dados na tabela de dimensão for grande, por uma questão de eficiência, uma visualização materializada ou uma tabela física real deve ser estabelecida. Dessa forma, os fatos podem persistir nos data marts assim que as dimensões estiverem alinhadas. Embora sejam fisicamente independentes, logicamente todos os data marts são interligados por dimensões consistentes, e operações como exploração cruzada podem ser executadas a qualquer momento, formando assim um data warehouse.
fatos consistentes
Quando vários data marts são estabelecidos, 80% a 90% da carga de trabalho de consistência foi concluída para concluir a dimensão de consistência. Tudo o que resta é estabelecer fatos consistentes. Fatos consistentes e dimensões consistentes são um pouco diferentes. As dimensões consistentes são mantidas em segundo plano (Back Room) por uma pessoa dedicada e são copiadas de forma síncrona para cada data mart quando são modificadas, enquanto as tabelas de fatos geralmente não são replicadas entre vários data marts. Quando é necessário consultar fatos em vários data marts, isso geralmente é obtido por meio de drill. Para ser capaz de realizar testes cruzados entre vários data marts, os fatos de consistência precisam garantir principalmente dois pontos. A primeira é que os métodos de definição e cálculo dos KPIs devem ser consistentes, e a segunda é que as unidades de fatos devem ser consistentes. Se os requisitos ou fatos de negócios não puderem ser mantidos consistentes, é recomendável que os fatos de diferentes unidades sejam salvos em campos separados. Dessa forma, dimensões consistentes combinam vários data marts e fatos consistentes garantem que os dados factuais entre diferentes data marts possam ser verificados.
Lado do aplicativo de dados [downstream]
A solução para o lado do aplicativo de dados é principalmente melhorar a eficiência da recuperação de dados, reduzir problemas de qualidade de dados e reutilizar dados e interfaces, como segue.
melhorar a qualidade dos dados
Para melhorar a qualidade dos dados, o mais importante é "detecção precoce, recuperação precoce":
-
A detecção precoce é ser capaz de descobrir problemas de dados antes dos usuários de dados e encontrar problemas na origem dos problemas tanto quanto possível, ganhando assim muito tempo para "recuperação antecipada". O método principal é iniciar a tarefa de verificação de auditoria para verificar e calcular os resultados dos dados após a conclusão da tarefa de saída de dados e julgar se ela atende às expectativas das regras (regras de integridade, regras de consistência, regras de precisão).
-
A recuperação antecipada é para encurtar o tempo de recuperação de falhas e reduzir o impacto das falhas na saída de dados. O método principal é estabelecer monitoramento de qualidade de dados de link completo com base na relação de sangue de dados. Depois de adicionar regras de auditoria e verificação a cada tabela no link, quando a saída de dados por qualquer um dos nós for anormal, você poderá localizá-la imediatamente e repará-la imediatamente, de modo a obter detecção e reparo precoces.
Crie uma plataforma de acesso visualizado
Haverá muitos custos de comunicação e colaboração por depender de terceiros para buscar dados. Ao mesmo tempo, devido aos dados incompletos da camada do mercado público, é impossível concluir diretamente a busca de dados com base nos dados existentes e nos novos dados precisa ser desenvolvido e processado, tão demorado e caro É muito longo, geralmente leva uma semana.
O alto custo de acesso a dados suprime a demanda de acesso a dados e também leva a análises exploratórias de dados, impossíveis de serem usadas em larga escala. Através da plataforma de acesso de autoatendimento, a eficiência de acesso é liberada, sendo a maior parte do acesso realizada pelo lado da demanda de pessoal não técnico. Construa uma plataforma de acesso de autoatendimento através dos seguintes pontos:
-
De forma gráfica, ao invés de escrever SQL;
-
Fornece conceitos de processos de negócios, indicadores e dimensões amigáveis ao pessoal de negócios, substituindo tabelas e campos;
-
O calibre de negócios de cada indicador pode ser exibido diretamente;
-
O usuário pode concluir o processo de recuperação de dados selecionando alguns indicadores e dimensões e adicionando alguns valores de filtro;
-
A interface é muito simples e a barreira de uso é muito baixa.