1: Baixe o código-fonte
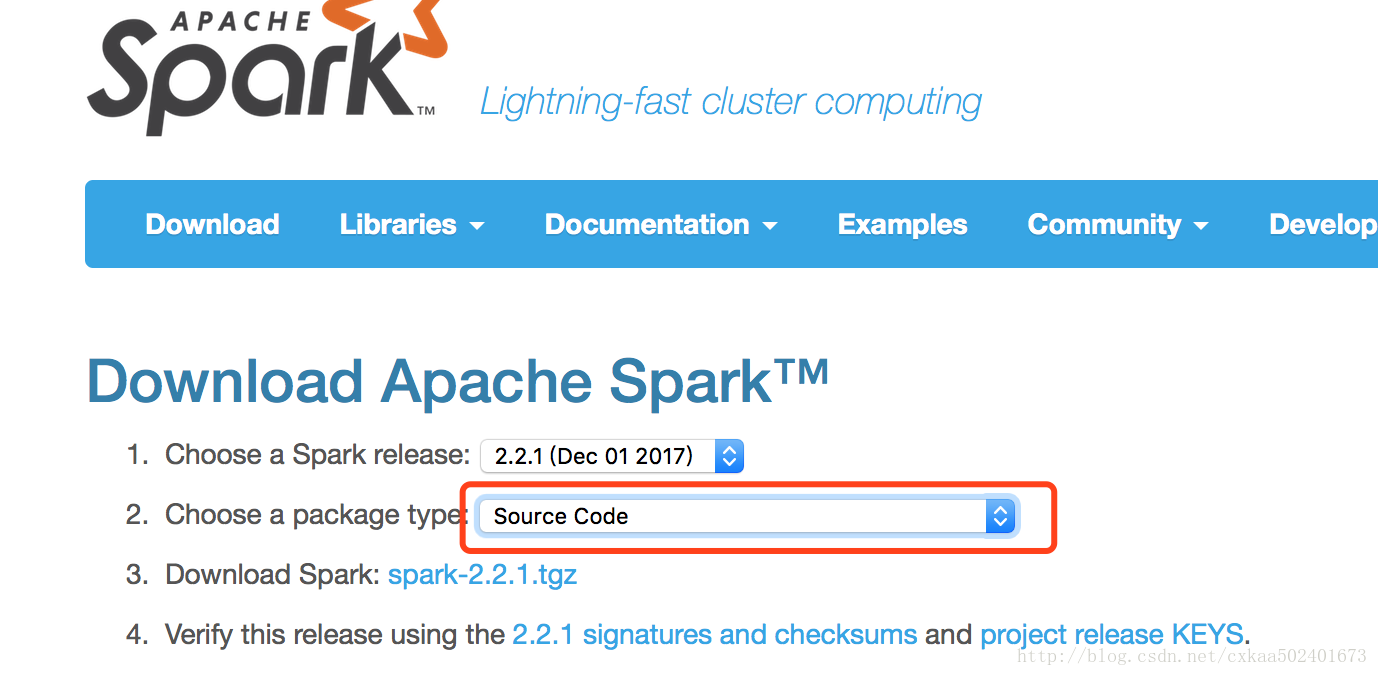
2: Descompacte spark-2.2.1.tgz
3: Configure o ambiente:
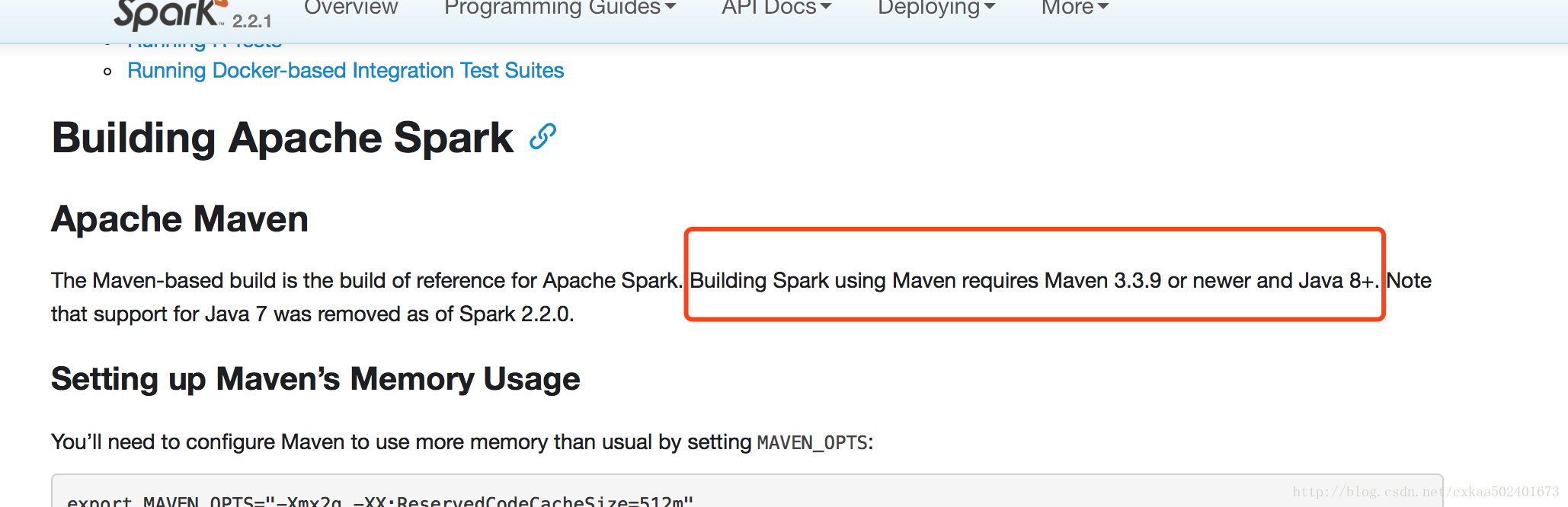
Isso significa que a versão do maven deve ser pelo menos 3.3.9, jdk 1.8 +
Meu ambiente:
jdk1.8.0
mestre 3.3.9
escala 2.11
4: Entre no diretório de origem do Spark e modifique o pom.xml
Adicionar repositório que suporta CDH
<repositório>
<id>cloudera-releases</id>
<name>cdh</name>
<url> https://repository.cloudera.com/artifactory/cloudera-repos/ </url>
</repository>
5: Execute a compilação
mvn -PCDH -Phive -Phive-thriftserver -Pyarn -Phadoop-2.6 -Dhadoop.version=2.6.0-cdh5.7.0 -DskipTests pacote limpo
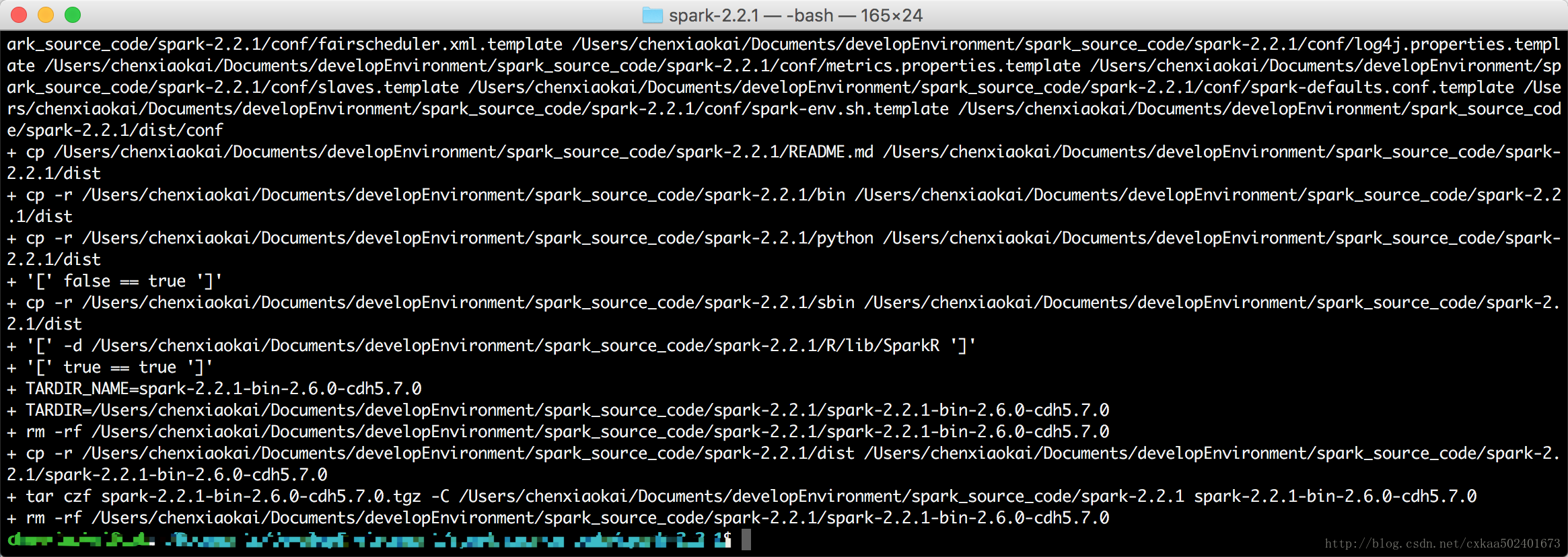
6 Compilar e empacotar:
1: Modifique o número da versão do Spark em dev/make-distribution.sh número da versão scala, número da versão do hadoop, ative o hive
VERSION=2.2.1
SCALA_VERSION=2.11
SPARK_HADOOP_VERSION=2.6.0-cdh5.7.0
SPARK_HIVE=1
(O objetivo de modificar este parâmetro é acelerar o processo de empacotamento)
Entre no diretório spark-2.2.1 e execute
./dev/make-distribution.sh --name 2.6.0-cdh5.7.0 --tgz -Phive - Phive-thriftserver -Pyarn - Phadoop-2.6 -Dhadoop.version=2.6.0-cdh5.7.0
Embalado com sucesso após uma longa espera