1. Análise de algoritmo
Este é o próximo algoritmo de matriz resolvido pelo algoritmo KMP na página 110 da edição de Wangdaoshu Data Structure de 2022. O princípio não é explicado em detalhes no livro, e Xianyu sênior também disse que este é um dos algoritmos mais obscuros do todo o curso, que despertou o pensamento do autor.
void get_next(String T,int next[]){
int i=1, j=0;
next[1]=0;
while(i<T.length){
if(j==0||ch[i]==T.ch[j]){
++i; ++j;
next[i]=j; //若pi=pj,则next[j+1]=next[j]+1
}
else
j=next[j]; //否则令j=next[j],循环继续
}
}
Princípio da solução:
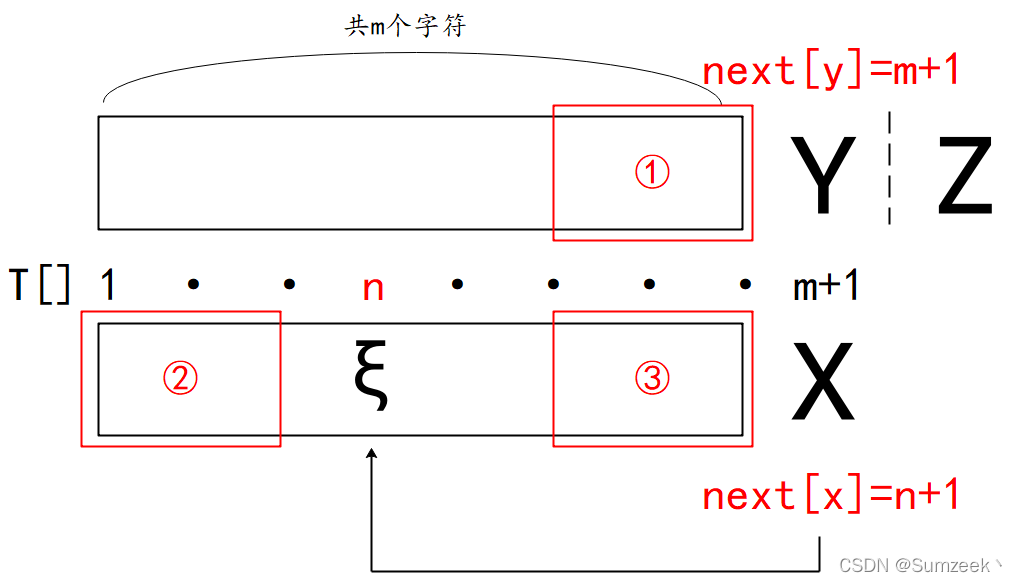
1. Primeiro verifique se o comprimento máximo correspondente do caractere Y antes do caractere Z a ser solicitado é de m caracteres, correspondendo ao inicial T[1]-T[m] , neste momento se X (T[m+1] ) ==Y , então pode-se julgar que o caractere correspondente máximo antes de Z é m+1 , então o próximo é m+2 ;
2. Se X! =Y , você precisa encontrar uma string ① que corresponda à string ② e, como há no máximo n strings correspondentes antes de X, string ②==string ③ e string ①==string ③, encontre uma string que corresponda à string ① ② string , se ξ==Y neste momento , então next[Z]=n+1 de Z ;
Correspondente ao loop while no código acima
while(i<T.length){
if(j==0||ch[i]==T.ch[j]){
++i; ++j;
next[i]=j; //若pi=pj,则next[j+1]=next[j]+1
}
else
j=next[j] //否则令j=next[j],循环继续
}Dois, modelo KMP
O i=0 e j=-1 no modelo são porque a cadeia de caracteres no programa começa do subscrito 0, e Wang Dao explica que o primeiro caractere subscrito é 1 por padrão.
void get_next(string T, int next[]) {
memset(next, 0, sizeof(next)); //多组输入时,每次需要初始化next[]数组
int i = 0, j = -1;
next[0] = -1;
while (i < T.length()){
if (j == -1 || T[i] == T[j]) {
++i; ++j;
next[i] = j; //若pi=pj,则next[j+1]=next[j]+1
}
else
j = next[j]; //否则令j=next[j],循环继续
}
}
int Index_KMP(string S, string T, int next[]) //S是字符串,T是模式串
{
int i = 0, j = 0;
while (i < S.length() && j < T.length()){
if (j == -1 || S[i] == T[j]){
++i; ++j;
}
else
j = next[j];
if (j == T.length()) //匹配成功
return i - T.length();
else //匹配失败
return 0;
}
}Deve-se observar que a função Index_KMP() é uma função para obter o índice correspondente da string padrão. Se o título exigir o número de substrings correspondentes na string, j < T.length() no loop while precisa ser excluído , cujo conteúdo deve ser ajustado de acordo com a situação real.
Além disso, a função get_next() pode ser otimizada na função get_nextval(), que pode acelerar a correspondência de strings. Para obter detalhes do algoritmo, consulte 4.2.3 Otimização adicional do algoritmo KMP na página P111 do Wangdao 2022 livro didático
void get_nextval(string T, int nextval[]) {
memset(next, 0, sizeof(next)); //多组输入时,每次需要初始化next[]数组
int i = 0, j = -1;
nextval[0] = -1;
while (i < T.length()) {
if (j == -1 || T[i] == T[j]) {
++i; ++j;
if (T[i] != T[j]) nextval[i] = j;
else nextval[i] = nextval[j];
}
else
j = nextval[j];
}
}