MVSNet (ECCV2018) é um artigo clássico sobre o uso de redes neurais para reconstrução 3D, mas a maioria das explicações são na verdade traduções... Parece que os princípios e funções das etapas mais importantes no treinamento de rede são nebulosos, graças a @百一A postagem do blog usando um livro como metáfora para mapas de recursos me deu uma compreensão geral de todo o processo.
O diagrama abaixo combina meu próprio entendimento para apresentar o processo passo a passo. Pessoalmente, acho que é relativamente fácil de entender. Claro, discussões e trocas são bem-vindas!
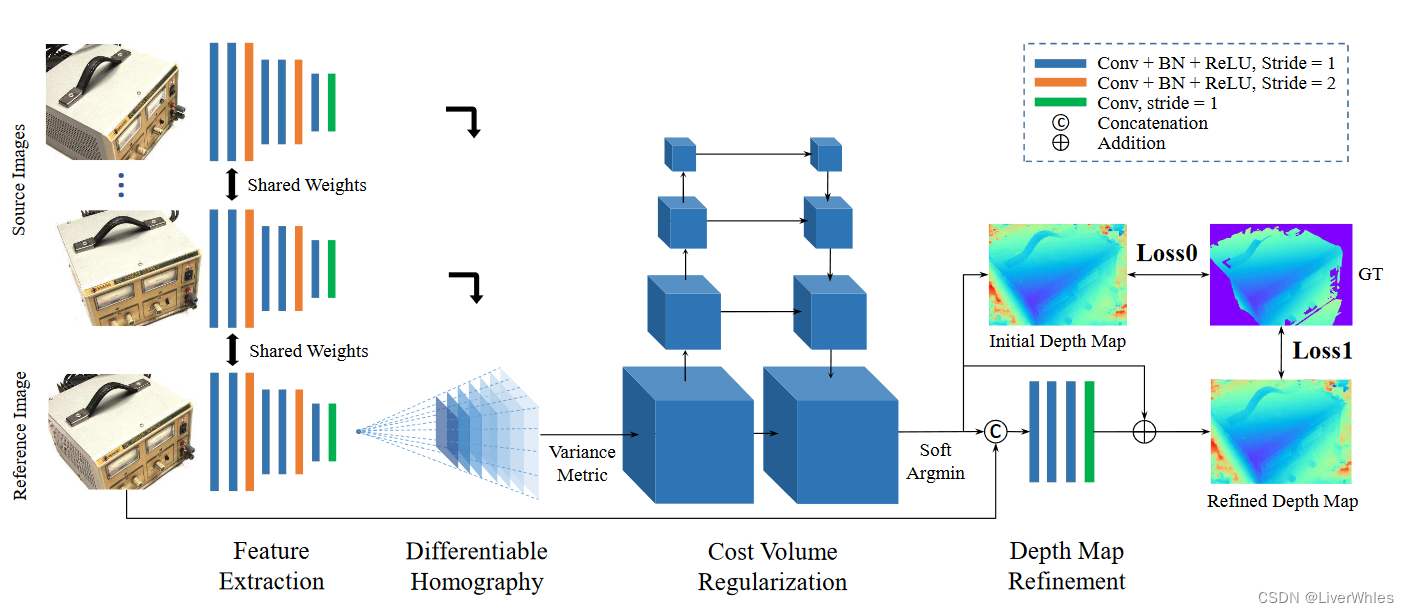
1. Processo de treinamento
1. Extração de características
Semelhante ao método tradicional de reconstrução 3D, a primeira etapa é extrair recursos de imagem (como SIFT). A diferença é que este artigo usa uma rede convolucional de 8 camadas para extrair representações de recursos de imagem mais profundas da imagem. A estrutura da rede é mostrada na figura a seguir:
Entrada: N imagens de 3 canais, largura e altura são W, H
Saída: N grupos de imagens de 32 canais, cada escala de canal é, H/4, W/4

2. Crie um volume de recursos
2.1 Transformação de homografia
Transformação de homografia Simplificando, para um ponto X no espaço 3D, tiramos uma foto com a câmera 1 para obter o ponto de pixel bidimensional P(x,y) correspondente na foto 1; tiramos uma foto com a câmera 2 em outra posição para obter foto 2 O ponto de pixel bidimensional correspondente P'(x', y') em - através de uma matriz de homografia correta H (incluindo os parâmetros de conversão de posição R, T da câmera 1, 2, a distância d da câmera 1 ao ponto X ), pode-se perceber que P' = HP . Ou seja, partindo da premissa de que os parâmetros internos e externos da câmera foram obtidos previamente, apenas uma variável de valor de profundidade é necessária para encontrar a posição do ponto P na imagem de referência correspondente ao ponto P' na imagem de origem.
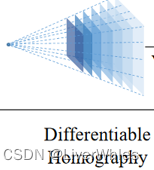
Se conhecemos os parâmetros da câmera de duas poses (os parâmetros de conversão de posição das câmeras 1 e 2), agora defina um intervalo de profundidade [d1, d2] e defina a resolução para Δd, obtendo assim D=(d2-d1) /Δd planos, então cada d corresponde a uma matriz de transformação de homografia h.
Se cada pixel em uma imagem é transformado pela matriz hi correspondente a di, uma imagem transformada pode ser obtida, o que significa que quando a profundidade real de cada pixel é d, cada pixel em outra pose Os autovalores correspondentes de .
E assumimos profundidades D e estamos prestes a obter imagens transformadas D. Cada imagem representa o valor de recurso correspondente da transformação quando a profundidade real do pixel é a profundidade atual, que pode ser entendida como a cor azul de cada camada em a imagem acima. Ilumine a camada.
Por que é um " cone de visão ", porque quando a profundidade real correspondente à matriz de homografia é diferente, pode-se saber pelo princípio do quase grande e do muito pequeno que o número de pontos característicos que podem ser vistos por a câmera na posição atual diminui à medida que a profundidade diminui, então um cone aparece. ( A interpolação bilinear é usada na próxima etapa para construir o corpo do recurso para garantir que os mapas de recursos de todas as profundidades tenham o mesmo tamanho)
2.2 Construção do corpo do recurso
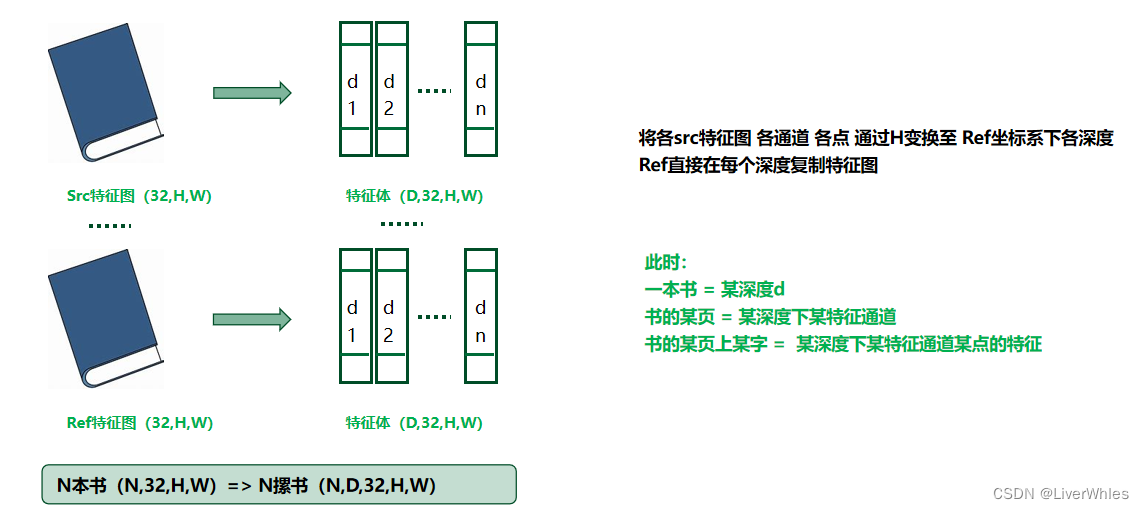
Neste artigo, obtivemos N mapas de recursos (1 imagem de referência, N-1 imagens originais) por meio da extração de recursos, e cada mapa de recursos possui 32 canais.
Cada mapa de recursos pode ser entendido como um livro com 32 páginas, e o tamanho de cada página é AxL.
Então, um livro (um corpo de recursos) torna-se uma pilha de livros por meio da transformação de homografia em 2.1, que equivale a converter o original first A página é transformada na primeira página em n profundidades através da matriz [h1,h2] com profundidade [d1,d2], e a segunda página original se torna a segunda página em n profundidades... Neste momento, um livro
= Uma
certa página de uma certa profundidade d livro = Um certo canal de recursos em uma certa profundidade
Uma certa palavra em uma determinada página do livro = Recursos de um certo ponto em um determinado canal de recursos em uma certa profundidade
Deve-se notar que o mapa de recursos de Ref é copiado diretamente em cada profundidade, porque vários Srcs devem ser transformados neste mapa de referência
3. Gerar Volume de Custo (Volume de Custo)
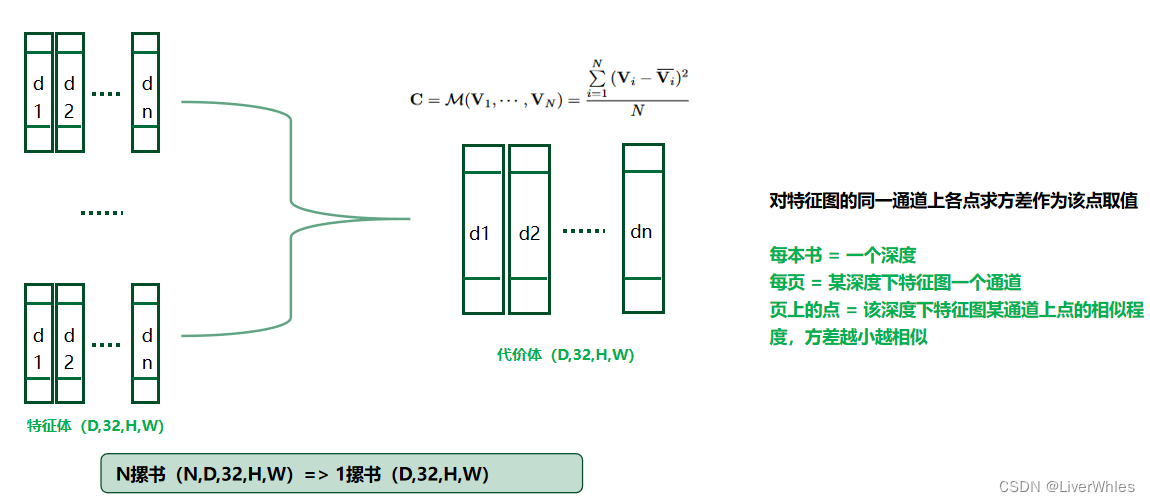
Na segunda etapa, obtivemos N pilhas de livros. Agora observe o primeiro livro de cada pilha de livros verticalmente, que representa o valor de recurso transformado de cada pixel em cada mapa de recursos quando a profundidade assumida é d1 - se um determinado pixel é real Se a profundidade estiver próxima de d1, os autovalores da coluna devem ser aproximados após a transformação .
Com base nessa ideia, a variância é calculada para cada pixel em cada página de cada livro, que representa a diferença entre cada ponto de recurso de cada canal de cada mapa de recursos de imagem quando a profundidade assumida é di. Quanto menor a variância, mais semelhante é. A verdadeira profundidade do ponto de recurso é mais provável de ser di.
Nesta etapa, uma pilha de livros é obtida, cada livro = uma profundidade,
cada página = um canal de um mapa de recursos a uma certa profundidade,
pontos em uma página = similaridade de pontos em um canal de um mapa de recursos a uma certa profundidade , quanto menor a variância, mais semelhante
Esta é a razão pela qual o papel disse que pode aceitar quaisquer entradas N, porque a variância é tomada, então as entradas são todas iguais.
4. Regularização do Volume de Custos
Na terceira etapa, o corpo de custo foi obtido, mas o artigo dizia "O volume de custo bruto calculado a partir de recursos de imagem pode estar contaminado por ruído" , ou seja, o corpo de custo contém ruído devido a superfícies não Lambertianas, oclusão, etc. , e precisa passar pela regularização Para obter um volume de probabilidade P (volume de probabilidade), uma estrutura de rede semelhante à UNet é usada para codificar e decodificar o volume de custo original e, finalmente, comprimir o número de canais para 1, ou seja, transformar uma pilha de livros em um livro livro
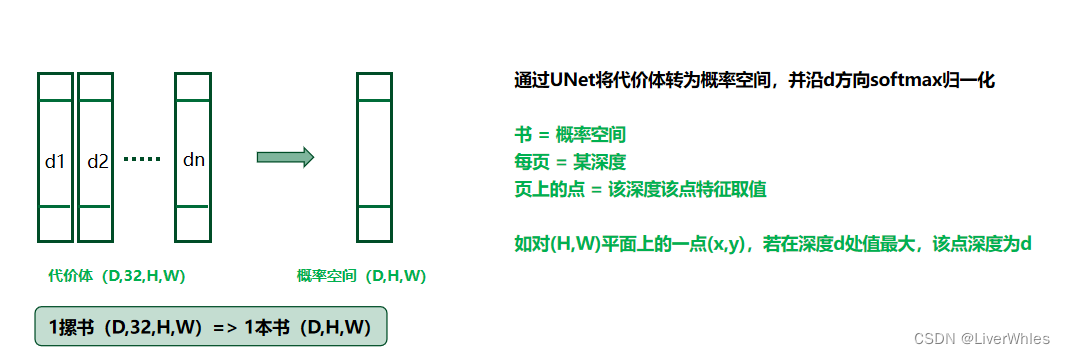
neste momento livro = probabilidade corpo
cada página = um certo
ponto de profundidade na página = a probabilidade do ponto nessa profundidade
Por exemplo, para um ponto (x, y) no plano (H, W), se o valor for o maior na profundidade d, a profundidade do ponto é d
Pessoalmente, sinto que os recursos de vários canais são compactados em um canal. A ideia intuitiva é reter os recursos do canal com a menor variação (mais provável de pertencer à profundidade atual) e, quanto menor a variação, mais provavelmente a profundidade desse pixel é a profundidade da camada atual; mas O artigo diz que é para fins de ruído tentar regularizar a rede para obter o corpo de probabilidade final. Não entendo muito bem por que essa rede UNet é usada.
5. Estimativa inicial do mapa de profundidade

Usando o corpo de probabilidade na etapa 4, calcule a expectativa ao longo da direção da profundidade d e, em seguida, obtenha o valor de profundidade inicial do ponto de pixel correspondente; encontre a
expectativa para cada ponto de pixel, ou seja, transforme o corpo de probabilidade em um mapa de probabilidade .
6. Refinamento do Mapa de Profundidade

7. Cálculo de Perda (Perda)

2. Pós-processamento
O artigo menciona * "Com pós-processamento simples"* no resumo, e o modelo funciona muito bem. Esse pós-processamento inclui principalmente duas partes: filtragem de imagem de profundidade e fusão de imagem de profundidade.
1. Filtro de Mapa de Profundidade
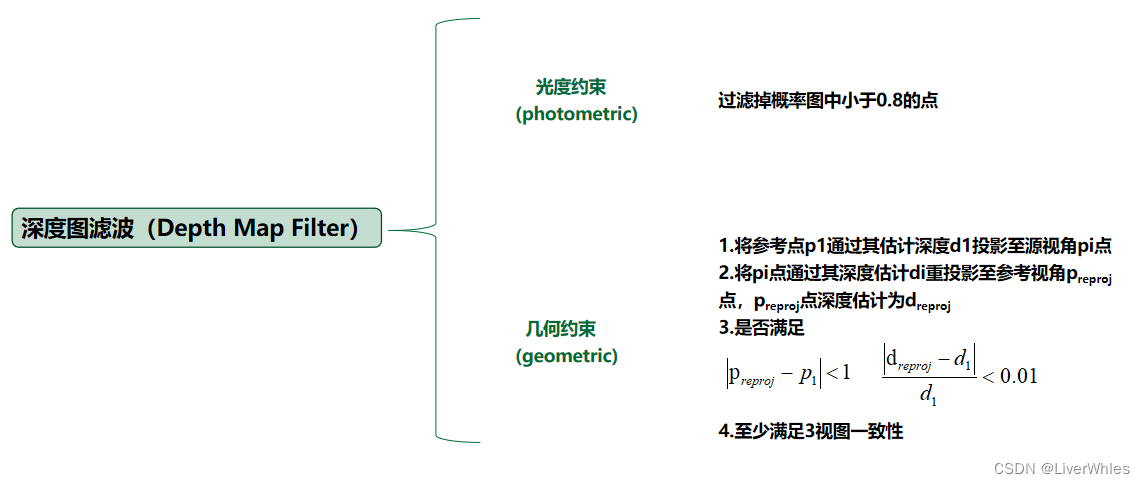
A filtragem de mapa de profundidade propõe principalmente duas restrições, restrições fotométricas e restrições geométricas.
1.1 Restrições geométricas
Em primeiro lugar, as restrições geométricas são relativamente simples, ou seja, o ponto de referência p1 é projetado para o ponto de vista de origem pi através de sua profundidade estimada d1 e, em seguida, o ponto pi é reprojetado para o ponto de vista de referência preproj através de sua profundidade estimativa di. A estimativa de profundidade do ponto pré-projeto após esta reprojeção Para dreproj, se satisfaz ,
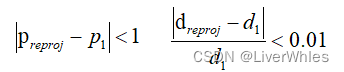
diz-se que satisfaz as restrições geométricas. No artigo, é garantido que as três vistas atendem às restrições geométricas.
1.2 Restrições fotométricas
As restrições de luminosidade, de fato, calculam um mapa de probabilidade enquanto obtêm o mapa de profundidade inicial através do 
ponto de volume de probabilidade.
2. Fusão do Mapa de Profundidade
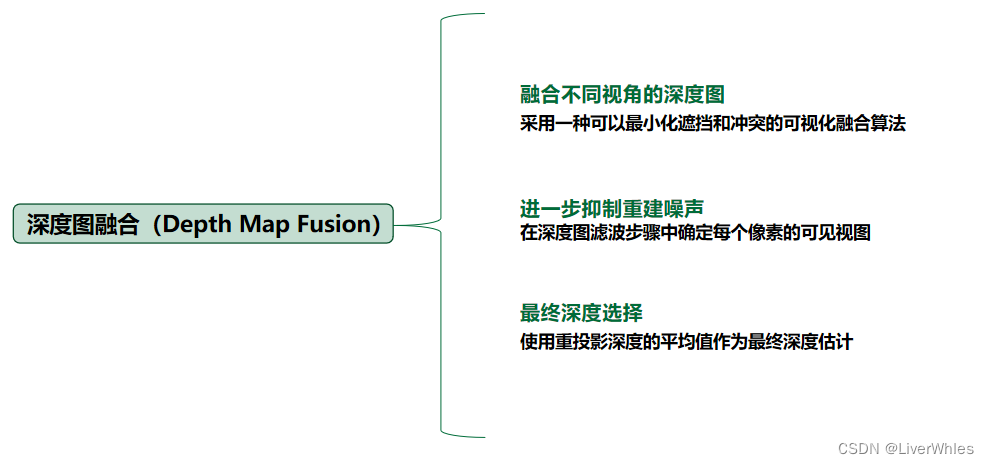
Ou seja, o mapa de profundidade é inferido de vários ângulos de visão e fundido com um algoritmo de fusão específico; a seleção de profundidade de pixel de cada mapa de profundidade deve usar o valor médio da reprojeção calculada quando restrições geométricas são usadas como a estimativa de profundidade final.
3. Resumo
