Original: conversa sobre dados de contas públicas
【Atualização】Tutorial básico do Python: Capítulo 6_Contêiner de dados
Por que estudar contêineres de dados
Pense em uma pergunta: Se eu quiser gravar informações de 5 alunos, como nomes, no programa.
A melhor maneira não é simplesmente definir 5 variáveis de string
name1="Wang Lihong"
name2="Zhou Jielun"
name3="Lin Junjie"
name4="Zhang Xueyou"
name5="Liu Dehua"
Embora esse método possa atender às nossas necessidades, é um pouco complicado escrever à mão. Temos apenas informações de 5 alunos, portanto, se for 50 ou 500, realmente precisamos definir 500 variáveis? Isso é definitivamente irreal, portanto, embora nosso O método de escrita pode ser realizado, não é avançado e ineficiente. Para atender a esse requisito, podemos usar o contêiner de dados para realizá-lo.
Isso é feito com uma variável:
lista de nomes = ["Wang Lihong", "Zhou Jielun", "Lin Junjie", "Zhang Xueyou", "Liu Dehua"]
Neste código, uma nova estrutura de dados é definida, que nunca vimos antes, então este é o contêiner de dados.
Como você pode ver, este código registra 5 dados de uma vez e salva os 5 dados em uma variável. Portanto, quando escrevemos código, podemos facilmente usar uma variável para registrar vários dados e pode ser facilmente estendido mesmo se precisarmos registrar mais dados. Este é o valor mais básico de um contêiner de dados, que pode acomodar várias cópias de dados, tornando nosso código mais elegante e eficiente. Portanto, o principal objetivo do aprendizado de contêineres de dados é obter armazenamento em lote e processamento de várias cópias de dados. Este é o maior valor que os contêineres de dados nos trazem.
Os alunos que estão acostumados a assistir a vídeos podem assistir a este tutorial gratuito:
https://www.bilibili.com/video/BV1ZK411Q7uX/?vd_source=704fe2a34559a0ef859c3225a1fb1b42&wxfid=o7omF0RELrnx5_fUSp6D59_9ms3Y
recipiente de dados
Contêineres de dados em Python
Um tipo de dados que pode conter várias partes de dados. Cada parte de dados é chamada de 1 elemento. Cada elemento pode ser qualquer tipo de dados, como strings, números, booleanos etc.
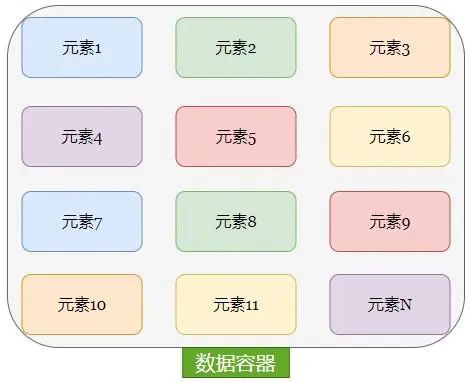
Como mostra a figura acima, podemos ver que existe um container de dados do nosso lado, e dentro do container haverá uma série de elementos como elemento 1, elemento 2, elemento 6, elemento 9 e elemento n.
Então esse número pode ser muito, muito grande. Os contêineres de dados variam de acordo com suas características, como:
-
Se deve suportar elementos repetidos
-
pode ser modificado
-
Está em ordem etc.
Dividido em 5 categorias, a saber:
List (list), tuple (tuple), string (str), coleção (set), dicionário (dict) Vamos aprendê-los um por um.
definição de lista
meta de aprendizado
-
Domine o formato de definição da lista
por que você precisa de uma lista
Pensando: Como o nome de uma pessoa (TOM) é armazenado no programa?
Resposta: variável string
Pensando: se houver 100 alunos em uma classe e o nome de todos precisar ser armazenado, como o programa deve ser escrito? Declarar 100 variáveis?
Resposta: Não, podemos usar a lista, que pode armazenar vários dados por vez
O tipo lista (lista) é um tipo de contêiner de dados, vamos aprendê-lo em detalhes. A sintaxe básica para definir uma lista é:
# Literal
[elemento 1, elemento 2, elemento 3, elemento 4,...]
# define variáveis
nome da variável = [elemento 1, elemento 2, elemento 3, elemento 4,...]
# define
variável de lista vazia nome = [ ]
nome da variável = lista()
Cada dado na lista é chamado de elemento
-
Marcado por []
-
Cada elemento da lista é separado por uma vírgula
como a lista é definida
Agora vamos dar uma breve olhada em sua demonstração de caso. Suponha que queremos armazenar 3 strings de dados e, em seguida, imprimir seu conteúdo por meio da instrução print e verificar seu tipo por meio da instrução type:
name_list = ['itheima','itcast','python']
print(name_list)
print(type(name_list))
A saída é:
['itheima', 'itcast', 'python']
<class 'lista'>
Ao mesmo tempo, você pode ver que o tipo dele é chamado de lista, então é isso que chamamos de lista.
Definimos outra lista abaixo, então você encontrará na lista que os três elementos parecem ser de tipos diferentes
minha_lista = ['itheima',666,True]
print(minha_lista)
print(type(minha_lista))
Em seguida, imprimimos seu conteúdo após a gravação e imprimimos seu tipo ao mesmo tempo, e também descobriremos que ele pode ser gerado normalmente.
['itheima', 666, Verdadeiro]
<class 'lista'>
Isso prova uma coisa, ou seja, os tipos de elementos armazenados em nossa lista podem ser tipos de dados diferentes.
Já que este é o caso, vamos pensar sobre isso, o tipo de elementos que armazenamos é ilimitado, então posso armazenar outra lista nela? É definitivamente possível, portanto, se for armazenado na lista e, em seguida, armazenado na lista. Então, chamamos esse comportamento de aninhamento.
minha_lista = [[1,2,3],[4,5,6]]
print(minha_lista)
print(tipo(minha_lista))
Descobriremos que há dois elementos nele, o primeiro elemento é uma lista e o segundo elemento também é uma lista. Portanto, o código que estamos escrevendo atualmente é para escrever uma lista com dois elementos, e cada elemento é uma lista, então imprimimos o resultado por meio da instrução print e da instrução type:
[[1, 2, 3], [4, 5, 6]]
<class 'lista'>
Também pode ser gerado normalmente e o tipo também é um tipo de lista.
Observação: a lista pode armazenar vários dados por vez e pode ser de diferentes tipos de dados e oferece suporte a aninhamento.
índice subscrito da lista
meta de aprendizado
-
Domine o índice subscrito da lista para retirar elementos da lista
Como obter os dados em uma posição específica da lista? Podemos usar: índice subscrito

Como mostra a figura, cada elemento da lista tem seu índice subscrito de posição, de frente para trás, começando em 0 e aumentando sequencialmente. Basta seguir o índice subscrito para obter o elemento na posição correspondente.
name_list =['Tom','Lily','Rose']
print(name_list[0]) # resultado: Tom
print(name_list[1]) # resultado: Lily
print(name_list[2]) # resultado: Rose
Subscrito de lista (índice) - reverso
Ou, você pode inverter o índice, ou seja, de trás para frente: partindo de -1, diminuindo na ordem (-1, -2, -3...)

Conforme mostrado na figura, de trás para frente, os índices subscritos são: -1, -2, -3, decrescentes em ordem.
name_list =['Tom','Lily','Rose']
print(name_list[-1]) # resultado: Rose
print(name_list[-2]) # result: Lily
print(name_list[-3]) # result: Tom
subscrito (índice) da lista aninhada
Se a lista for uma lista aninhada, índices subscritos também são suportados.Na verdade, precisamos escrever duas camadas de índices subscritos.
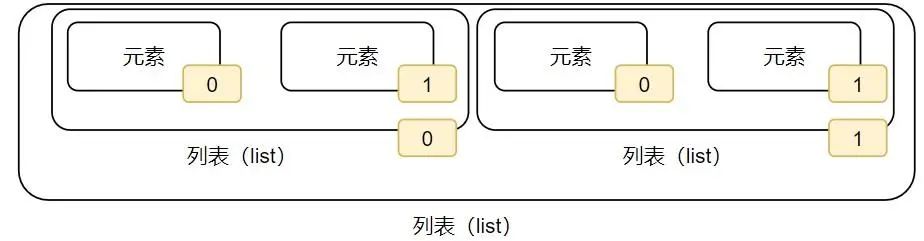
Conforme mostrado na figura, existem 2 níveis de subscritos.
# 1ist aninhada em 2 camadas
my_list=[[1,2,3],[4,5,6]]
# Obtenha a primeira 1ist na camada interna
print(my_list[0]) #Result: [1,2,3 ]
# Obtenha o primeiro elemento da primeira 1ist na camada interna
print(my_list[0][0]) #Result: 1
Operações comuns em listas
meta de aprendizado
-
Domine as operações comuns (métodos) e as características das listas
Aprendemos sobre a definição de listas e o uso de índices subscritos para obter valores de elementos especificados. Além dessas duas operações, nossas listas também fornecem uma série de funções: como inserir elementos, excluir elementos e limpar a lista. , modificando elementos, contando o número de elementos, etc., então essas funções, todos nós chamamos de método chamado lista.
Aqui temos um novo termo chamado método, então o que é método?
Vamos relembrar um conteúdo: já aprendemos sobre funções antes, então sabemos que uma função é uma unidade de código encapsulada que pode fornecer funções específicas. Em Python, se definirmos uma função em uma classe e também um membro da classe, então o nome dessa função não será mais chamada de função, mas será chamada de método.
Pode-se ver que, de fato, funções e métodos são realmente iguais em função, mas são escritos em lugares diferentes.
# function
def add(x, y)
return x + y
# método
class Aluno:
def add(self,x, y):
return x + y
Com relação à definição de classes e métodos, aprendemos no capítulo de orientação a objetos, até agora só sabemos como usar métodos.
Função de consulta de lista (método)
Uma função é uma unidade de código encapsulada que fornece uma funcionalidade específica. Em Python, se uma função for definida como membro de uma classe (classe), então a função será chamada: o método method é o mesmo que a função function, com parâmetros de entrada e um valor de retorno, mas o formato do método é diferente: o uso da função:
num = somar(1,2)
Uso do método:
aluno = Aluno()
num = aluno.add(1,2)
-
Encontrar o subscrito de um elemento
Função: Encontre o subscrito do elemento especificado na lista, se não for encontrado, reporte ValueError
Sintaxe: list.index(element)
index é o método interno (função) do objeto de lista (variável)
my_list = ['itheima','itcast','python']
print(my_list.index('itcast')) # 结果1
função de modificação de lista (método)
-
Modifique o valor do elemento em uma posição específica (índice):
-
Sintaxe: lista[subscrito] = valor
Você pode usar a sintaxe acima para reatribuir (modificar) diretamente o valor do subscrito especificado (os subscritos direto e reverso são aceitáveis)
#Forward subscript
my_list = [1,2,3]
my_list[0] = 5
print(my_list) #Result: [5,2,3]
#Reverse subscript
my_list = [1,2,3]
my_list[ -3] = 5
print(minha_lista) # resultado: [5,2,3]
-
Inserir elemento:
Sintaxe: list.insert(subscript, element), insira o elemento especificado na posição do subscrito especificada
minha_lista = [1,2,3]
minha_lista.insert(1,"itheima")
print(minha_lista) # 结果 [1, 'itheima', 2, 3]
-
Acrescentar elemento:
Sintaxe: list.append(element), anexa o elemento especificado ao final da lista
minha_lista = [1,2,3]
minha_lista.append(4)
print(minha_lista) # 结果 [1, 2, 3, 4]
minha_lista = [1,2,3]
minha_lista.append([4,5,6] )
print(minha_lista) #结果 [1, 2, 3, [4, 5, 6]]
-
Anexar método de elemento 2:
Sintaxe: list.extend(outros contêineres de dados), retira o conteúdo de outros contêineres de dados e os anexa ao final da lista sucessivamente
minha_lista = [1,2,3]
minha_lista.extend([4,5,6])
print(minha_lista) # 结果 [1, 2, 3, 4, 5, 6]
-
Remover elemento:
Sintaxe 1: del list[subscrito]
Sintaxe 2: list.pop(subscript)
minha_lista = [1,2,3]
#método 1
del minha_lista[0]
print(minha_lista) #resultado[2, 3]
#método 2
minha_lista.pop(0)
print(minha_lista) #resultado[2, 3]
-
remove a primeira ocorrência de um elemento na lista
Sintaxe: list.remove(element)
minha_lista = [1,2,3,2,3]
minha_lista.remove(2)
print(minha_lista) # 结果:[1, 3, 2, 3]
-
limpar conteúdo da lista
Sintaxe: lista.clear()
minha_lista = [1,2,3]
minha_lista.clear()
print(minha_lista) # 结果[]
-
Contar o número de elementos em uma lista
Sintaxe: list.count(element)
minha_lista = [1,1,1,2,3]
print(minha_lista.contagem(1)) # resultado: 3
Função de consulta de lista (método)
-
Conte quantos elementos estão na lista Sintaxe: len(lista)
Um número int pode ser obtido, indicando o número de elementos na lista
minha_lista = [1,2,3,4,5]
print(len(minha_lista)) # resultado: 5
Listar Métodos - Visão Geral
| número de série |
Como usar |
efeito |
|---|---|---|
| 1 |
list.append(elemento) |
Anexar um elemento à lista |
| 2 |
list.extend(contêiner) |
Retire o conteúdo do contêiner de dados e anexe-o ao final da lista |
| 3 |
lista.insert(subscrito, elemento) |
Inserir o elemento especificado no subscrito especificado |
| 4 |
del list[subscrito] |
Excluir o elemento subscrito especificado da lista |
| 5 |
lista.pop(subscrito) |
Excluir o elemento subscrito especificado da lista |
| 6 |
lista.remove(elemento) |
Da frente para trás, remova a primeira ocorrência deste elemento |
| 7 |
lista.limpar() |
limpar a lista |
| 8 |
lista.contagem(elementos) |
Conta o número de vezes que este elemento ocorre na lista |
| 9 |
lista.index(elemento) |
Encontre o elemento especificado no subscrito da lista e não pode encontrar um erro ValueError |
| 10 |
len(lista) |
conta quantos elementos estão no container |
Método de Lista - Descrição
Existem tantos métodos funcionais que os alunos não precisam memorizá-los.
Aprender programação não é apenas a própria linguagem Python, mas você aprenderá mais tecnologias de estrutura de acordo com a direção no futuro.
Com exceção dos usados com frequência, a maioria deles não pode ser lembrada.
O que temos a fazer é ter uma vaga impressão e saber que existe tal uso.
Você pode verificar as informações a qualquer momento quando precisar.
Características da lista
Depois de estudar a lista acima, pode-se concluir que a lista possui as seguintes características:
-
Pode conter vários elementos (o limite superior é 2 ** 63-1, 9223372036854775807)
-
Pode acomodar diferentes tipos de elementos (misto)
-
Os dados são armazenados em ordem (com número de série subscrito)
-
Dados duplicados são permitidos
-
Pode ser modificado (adicionar ou remover elementos, etc.)
Caso prático: exercícios de funções comuns
Existe uma lista, o conteúdo é: [21, 25, 21, 23, 22, 20], que registra a idade de um grupo de alunos
Por favor, passe a função (método) da lista, para ela
-
Defina esta lista e receba-a com variável
-
Acrescenta um número 31, ao final da lista
-
Anexar uma nova lista [29, 33, 30] ao final da lista
-
Retire o primeiro elemento (deve ser: 21)
-
Retire o último elemento (deve ser: 30)
-
Encontre o elemento 31, posição do subscrito na lista
Código de referência:
"""
Exercício para demonstrar o funcionamento comum da Lista
"""
# 1. Defina esta lista e use variáveis para recebê-la, o conteúdo é: [21, 25, 21, 23, 22, 20]
minhalista = [21, 25 , 21 , 23, 22, 20]
# 2. Acrescente um número 31 ao final da lista
mylist.append(31)
# 3. Acrescente uma nova lista [29, 33, 30] ao final da lista
mylist. extend([29 , 33, 30])
# 4. Retire o primeiro elemento (deve ser: 21)
num1 = mylist[0]
print(f"Retire o primeiro elemento da lista, deve ser 21, na verdade: {num1 }")
# 5. Retire o último elemento (deve ser: 30)
num2 = minhalista[-1]
print(f"Retire o último elemento da lista, deve ser 30, na verdade: {num2}" )
# 6. Encontre o elemento 31, a posição do subscrito na lista
index = mylist.index(31)
print(f"A posição do subscrito do elemento 31 na lista é: {index}")
print(f"O conteúdo da a lista final é: {minhalista}")
Resultado de saída:
Retire o primeiro elemento da lista, deve ser 21, na verdade é: 21
Retire o último elemento da lista, deve ser 30, na verdade é: 30
A posição subscrita do elemento 31 na lista é: 6
A última lista O conteúdo de é: [21, 25, 21, 23, 22, 20, 31, 29, 33, 30]
Travessia de lista (lista)
meta de aprendizado
-
Domine o uso do loop while para percorrer os elementos da lista
-
Domine o uso do loop for para percorrer os elementos da lista
Passagem de lista - loop while
Uma vez que o contêiner de dados pode armazenar vários elementos, haverá a necessidade de retirar sequencialmente os elementos do contêiner para operação. O comportamento de retirar os elementos do contêiner para processamento por sua vez é chamado de travessia e iteração. Como iterar pelos elementos da lista? Você pode usar o loop while que aprendeu anteriormente
-
Como extrair os elementos da lista no loop?
-
Use a lista [subscrito] para sair
Como as condições do loop são controladas?
-
Defina uma variável para representar o subscrito, começando em 0
-
A condição do loop é o valor subscrito < o número de elementos na lista
index = 0
while index < len(list):
element = list[index]
para processar o elemento
index += 1
Passagem de lista - loop for
Além do loop while, existe outra forma de loop em Python: o loop for.
Comparado com while, o loop for é mais adequado para percorrer contêineres de dados, como listas.
gramática:
# para variável temporária no contêiner de dados:
# processar a variável temporária
Exemplo de demonstração:
minha_lista = [1,2,3,4,5,]
for i in minha_lista:
print(i)
#O resultado é:
1
2
3
4
5
Indica que, do contêiner, os elementos são retirados sequencialmente e atribuídos a variáveis temporárias.
Como resultado, em cada loop, podemos processar variáveis temporárias (elementos).
Cada ciclo retira os elementos da lista e os atribui à variável i para operação
Comparação entre o loop while e o loop for
O loop while e o loop for são instruções de loop, mas os detalhes são diferentes:
-
No controle de loop:
-
O loop while pode personalizar a condição do loop e controlá-lo sozinho
-
O loop for não pode personalizar a condição do loop, ele só pode retirar os dados do contêiner um por um
-
Em loop infinito:
-
O loop while pode ser repetido infinitamente através do controle condicional
-
O loop for é teoricamente impossível, porque a capacidade do contêiner percorrido não é infinita
-
Em cenários de uso:
-
O loop while é adequado para qualquer cenário em que você deseja fazer um loop
-
O loop for é adequado para cenários que atravessam contêineres de dados ou cenários simples de loop de número fixo
o código
minha_lista = [1,2,3,4,5]
for i em minha_lista:
print("Xiaomei, eu gosto de você")
A saída é:
Mei, eu gosto de você
Mei, eu gosto de você
Mei, eu
gosto de você
Mei, eu gosto de você
Caso prático: retire o número par da lista
Defina uma lista, o conteúdo é: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
-
Atravesse a lista, retire os números pares da lista e armazene-os em um novo objeto de lista
-
Use loop while e loop for para operar uma vez
Através do loop while, retire os números pares da lista: [1,2,3,4,5,6,7,8,9,10] para formar uma nova lista: [2,4,6,8,10 ]
percorrer f0 , pegue os números pares da lista: [1,2,3,4,5,6,7,8,9,10] para formar uma nova lista: [2,4,6,8,10]
dica:
-
Confirme o número par por meio do julgamento
-
Adicione elementos através do método append da lista
Código de referência:
# while 方法
old_list = [1,2,3,4,5,6,7,8,9,10]
new_list = []
i = 0
while i < len(old_list):
if old_list[i] % 2 == 0:
new_list.append(old_list[i])
i += 1
print(new_list)
# for 方法
old_list = [1,2,3,4,5,6,7,8,9,10]
new_list = []
for num in old_list:
if num % 2 == 0:
new_list.append(num)
print(new_list)
Definição de tupla
meta de aprendizado
-
Domine o formato de definição de tuplas
Por que você precisa de tuplas
Ok, primeiro vamos pensar em uma pergunta: por que precisamos de tuplas? A lista que aprendemos antes é muito poderosa, pode armazenar vários tipos de elementos e não é limitada, mas vamos pensar nisso: a lista tem uma característica, é modificável. Se as informações que preciso passar não podem ser adulteradas, as listas não são uma boa opção. Portanto, precisamos introduzir outro contêiner de dados - tupla.
As tuplas, assim como as listas, podem armazenar vários elementos de tipos diferentes, mas sua maior diferença é que, uma vez definida uma tupla, ela não pode ser modificada, portanto pode ser considerada uma lista somente leitura. Portanto, se precisarmos encapsular dados no programa, mas não quisermos que os dados encapsulados sejam adulterados, as tuplas são muito adequadas.
A seguir, veremos como definir tuplas.
tupla de definição
Definição de tupla: use parênteses para definir uma tupla e use vírgulas para separar cada dado. Os dados podem ser de diferentes tipos de dados.
# Definir literal de tupla
(elemento, elemento, elemento, ..., elemento,)
# Definir variável de tupla variável
nome = (elemento, elemento, elemento, ..., elemento,)
# Definir
variável de tupla vazia nome = () # Modo 1
nome da variável = tuple() # Modo 2
Precauções:
# Define uma tupla de 3 elementos
t1 = (1,"Hello",True)
# Define uma tupla de 1 elemento
t2 = ("Hello",) #Observe que uma vírgula deve ser incluída, caso contrário não é uma tupla
Nota: A tupla possui apenas um dado, devendo ser adicionada uma vírgula após este dado
Tuplas também suportam aninhamento:
# Definir uma tupla aninhada
t1=((1,2,3),(4,5,6))
print(t1[0][0]) #Result: 1
Operações relacionadas em tuplas:
#Obtenha os dados de acordo com o subscrito (index)
t1=(1,2,'he11o')
print(t1[2]) #Result: 'he11o'
#De acordo com index(), encontre o primeiro item correspondente de um determinado element
t1= (1,2,'hello',3,4,'hello')
print(t1.index('hello')) # Result: 2
# Conta quantas vezes um determinado dado aparece na tupla
t1= (1,2 ,'he11o',3,4,'he11o')
print(t1.count('he1lo')) # Resultado: 2
# Conta o número de elementos na tupla
t1=(1,2,3)
print(len(t1)) # resultado 3
| número de série |
método |
efeito |
|
|---|---|---|---|
| 1 |
índice() |
Encontre um determinado dado, se o dado existir, retorne o subscrito correspondente, caso contrário, reporte um erro |
|
| 2 |
contar() |
Conte o número de vezes que um dado aparece na tupla atual |
|
| 3 |
len(tupla) |
Contar o número de elementos em uma tupla |
|
Devido à natureza não modificável das tuplas, existem muito poucos métodos de operação
Operações relacionadas em tuplas - Notas
-
O conteúdo da tupla não pode ser modificado, caso contrário, um erro será relatado diretamente
# Tente modificar o conteúdo da tupla
t1=(1,2,3)
t1[0]=5
TypeError: objeto 'tuple' não suporta atribuição de item
-
Você pode modificar o conteúdo da lista na tupla (modificar elementos, adicionar, excluir, inverter, etc.)
# Tente modificar o conteúdo da tupla
t1 = (1,2,['itheima','itcast'])
t1[2][1]='best'
print(t1) #Result: (1,2,['itheima ' ,'melhor'])
(1, 2, ['iheima', 'melhor'])
-
Não é possível substituir a lista por outras listas ou outros tipos
# Tente modificar o conteúdo da tupla
t1 = (1,2,['itheima','itcast'])
t1[2]= [1,2,3]
print(t1)
TypeError: 'tuple' object does not support item atribuição
Percurso de tuplas
Assim como as listas, as tuplas também podem ser iteradas.
Ele pode ser percorrido usando loop while e loop for
loop while
my_tuple=(1,2,3,4,5)
index =0
while index < len(my_tuple):
print(my_tuple[index])
index += 1
para loop
my_tuple=(1,2,3,4,5)
for i in my_tuple:
print(i)
resultado da operação
1
2
3
4
5
Características das tuplas
Após o estudo de tuplas acima, pode-se concluir que a lista possui as seguintes características:
-
Pode conter vários dados
-
Pode acomodar diferentes tipos de dados (misto)
-
Os dados são armazenados em ordem (índice subscrito)
-
Dados duplicados são permitidos
-
Não pode ser modificado (adicionar ou excluir elementos, etc.)
-
Suporte para loop
A maioria dos recursos são os mesmos da lista, a diferença está nos recursos não modificáveis.
Caso prático: operações básicas em tuplas
Defina uma tupla, o conteúdo é: ('Jay Chow', 11, ['futebol', 'música']), o registro é uma informação do aluno (nome, idade, hobbies) Por favor, passe a função da tupla (método ) , qual é
-
Consultar a posição do subscrito onde a idade está localizada
-
Pesquise o nome de um aluno
-
Excluir o futebol dos hobbies dos alunos
-
Adicione hobbies: codificação à lista de hobbies
-
Consultar a posição do subscrito de sua idade:
Código de referência
# Consulta a posição do subscrito da idade do
aluno = ('Jielun Zhou', 11, ['futebol', 'música'])
age_index = student.index(11)
print(age_index) # Saída: 1
# Consulta o nome do aluno:
aluno = ('Jay Chou', 11, ['futebol', 'música'])
nome = aluno[0]
print(nome) # saída: Jay Chou
# ou
aluno = ('Jay Chou', 11, ['futebol ', 'music'])
name = student.index('Jay Chou')
print(name) # Saída: 0
# Excluir futebol no hobby do aluno:
student = ('Jay Chou', 11 , ['futebol', ' music'])
student[2].remove('football')
print(student) # Output: ('Jay Chow', 11, ['music'])
# Add hobbies: coding to In the hobby list:
student = ( 'Jay Chou', 11, ['futebol', 'música'])
aluno[2].append('codificação')
print(student) # Saída: ('Jay Chow', 11, ['futebol', 'música', 'codificação'])
corda
meta de aprendizado
-
Domine operações comuns em strings
Reconhecer a string
Nesta seção, vamos aprender sobre um velho amigo - strings. O objetivo de aprendizado desta seção também é muito simples. Precisamos aprender sobre strings da perspectiva dos contêineres de dados e dominar suas operações comuns.
Embora as strings não pareçam armazenar muitos dados tão obviamente quanto as listas ou tuplas, é inegável que as strings também são um tipo de contêiner de dados, que é um contêiner de caracteres. Uma string pode armazenar qualquer número de caracteres.
Por exemplo, a string "iheima", se for considerada como um recipiente de dados, ficará como na figura abaixo, onde cada caractere é um elemento, e cada elemento também possui um índice subscrito.

subscrito (índice) da string
Como outros contêineres, como listas e tuplas, as strings também podem ser acessadas por meio de subscritos
-
Da frente para trás, os subscritos começam em 0
-
De trás para a frente, os subscritos começam em -1
#Obtém caracteres de posição específicos por meio do nome subscrito
="itheima"
print(name[0]) #result i
print(name[-1]) #result a
Assim como as tuplas, as strings são uma só: contêineres de dados não modificáveis. então:
-
Modifique o caractere do subscrito especificado (por exemplo: string[0] = "a")
-
Remova o caractere de um subscrito específico (como: del string[0], string.remove(), string.pop(), etc.)
-
Acrescentar caracteres etc. (por exemplo: String.append())
Nenhum dos dois pôde ser concluído. Se você precisar fazer isso, poderá obter apenas uma nova string e a string antiga não poderá ser modificada.
Operações comuns em strings
-
Encontre o valor do índice subscrito de uma string específica
Sintaxe: string.index(string)
my_str = "itcast and itheima"
print(my_str.index("and")) # 结果7
-
substituição de string
Sintaxe: string.replace(string1, string2)
Função: substitua tudo na string: string 1 pela string 2
Nota: ao invés de modificar a própria string, uma nova string é obtida
name = "itheima itcast"
new_name=name.replace("it","Chuanzhi")
print(new_name) # Resultado: Chuanzhi heima Chuanzhi cast
print(name) # Resultado: itheima itcast
Como você pode ver, o próprio nome da string não muda, mas recebe um novo objeto string
-
divisão de cordas
Sintaxe: string.split(delimiter string)
Função: De acordo com a string delimitadora especificada, divida a string em várias strings e armazene-as no objeto de lista
Observação: a string em si permanece inalterada, mas um objeto de lista é obtido
name="Chuanzhi Podcast Chuanzhi Education Programador Dark Horse Erudite Valley"
name_list = name.split(" ")
print(name_list) # Result: [Chuanzhi Podcast, 'Chuanzhi Education, Dark Horse Programmer, Erudite Valley
print(type (name_list)) # Resultado: <class!1ist'>
Pode-se ver que a string é dividida de acordo com o <espaço> fornecido, transformada em várias substrings e armazenada em um objeto de lista.
-
Operação regular de strings (remover espaços iniciais e finais)
Sintaxe: String.strip()
my_str = "itheima and itcast"
print(my_str.strip()) # 结果:"itheima and itcast"
-
Operação regular de strings (ir e especificar strings antes e depois)
Sintaxe: string.strip(string)
my_str ="12itheima and itcast21"
print(my_str.strip("12")) # 结果:"itheima and itcast"
Observe que o "12" passado é na verdade: "1" e "2" serão removidos de acordo com um único caractere.
-
Contar o número de ocorrências de uma string em uma string
Sintaxe: string.count(string)
my_str = "itheima and itcast"
print(my_str.count ("it")) # 结果:2
-
Conte o comprimento da corda
Sintaxe: len(string)
my_str="1234abcd!@#$Dark Horse Programmer"
print(len(my_str)) #Resultado: 20
Como pode ser visto:
-
números (1, 2, 3...)
-
Letras (abcd, ABCD, etc.)
-
Símbolos (espaço, !, @, #, $, etc.)
-
chinês
Ambos contam como 1 caractere, então o código acima resulta em 20
Resumo das operações de string comuns
| número de série |
operar |
ilustrar |
|---|---|---|
| 1 |
string[subscrito] |
Extraia o caractere em uma posição específica de acordo com o índice subscrito |
| 2 |
string.index(string) |
Encontre o subscrito da primeira ocorrência do caractere fornecido |
| 3 |
string.replace(string1, string2) |
Substituir toda a string 1 na string pela string 2 não modificará a string original, mas obterá uma nova |
| 4 |
string.split(string) |
De acordo com a string fornecida, delimitar a string não modificará a string original, mas obterá uma nova lista |
| 5 |
string.strip() string.strip(string) |
Remova espaços iniciais e finais e novas linhas ou especifique uma string |
| 6 |
string.count(string) |
Contar o número de ocorrências de uma string em uma string |
| 7 |
len(corda) |
Contar o número de caracteres em uma string |
Travessia de String
Como listas e tuplas, strings também suportam loops while e loops for para travessia
loop while
my_str = "Dark Horse Programmer"
index = 0
while index < len(my_str):
print(my_str[index])
index += 1
para loop
my_str = "Dark Horse Programmer"
for i in my_str:
print(i)
Os resultados de saída são:
Programador Dark
Horse _ _
Características das cordas
Como um contêiner de dados, as strings têm as seguintes características:
-
Apenas strings podem ser armazenadas
-
Qualquer comprimento (depende do tamanho da memória)
-
Índice de subscrito de suporte
-
Permitir a existência de strings duplicadas
-
Não pode ser modificado (adicionar ou excluir elementos, etc.)
-
Suporte para loop
Basicamente o mesmo que listas e tuplas
A diferença de listas e tuplas é que o tipo que um contêiner de string pode conter é um tipo único, que só pode ser um tipo de string.
Ao contrário das listas, o mesmo que as tuplas: as strings não podem ser modificadas
Exemplo de exercício: dividir uma string
Dada uma string: "itheima itcast boxuegu"
-
Conte quantos caracteres "it" estão na string
-
Substitua todos os espaços na string por caracteres: "|"
-
E divida a string de acordo com "|" para obter uma lista
dica:
A string itheima itcast boxuegu contém: 2 caracteres it
A string itheima itcast boxuegu, depois de substituída por espaços, o resultado: itheima|itcastboxuegu
A string itheima|itcastlboxuegu, separada por |, obtém: ['itheima','itcast', ' boxuegu']
contar, substituir, dividir
Código de amostra:
"""
Demonstração de exercício de string após classe
"itheima itcast boxuegu"
"""
my_str = "itheima itcast boxuegu"
# Conte quantos caracteres "it" existem na string
num = my_str.count("it")
print(f" Existem {num} caracteres it na string {my_str}")
# Substitua todos os espaços na string por caracteres: "|"
new_my_str = my_str.replace(" ", "|")
print(f"string After {my_str} é substituído por espaços, o resultado é: {new_my_str}")
# e divida a string de acordo com "|" para obter a lista
my_str_list = new_my_str.split("|")
print(f"string {new_my_str} de acordo com | O resultado após a divisão é: {my_str_list}")
Fatiamento de contêineres de dados (sequências)
meta de aprendizado
-
Entenda o que é uma sequência
-
Domine a operação de divisão da sequência
seqüência
Então, o que é uma sequência? A sequência refere-se a um tipo de contêiner de dados cujo conteúdo é contínuo e ordenado e que pode ser indexado por subscritos. As listas, tuplas e strings que aprendemos anteriormente satisfazem todas essas características, de modo que podem ser chamadas de sequências. Conforme mostrado na figura abaixo, todas são sequências típicas: os elementos são organizados um a um, os elementos adjacentes são contínuos e as operações de indexação de subscrito são suportadas.


O conceito de sequência é relativamente simples. Agora vamos ver a operação de sequência. Uma das operações comumente usadas é o fatiamento.
Operações comuns em sequências - corte
As sequências suportam o fatiamento, ou seja: listas, tuplas e strings, todas as quais suportam operações de fatiamento
Corte: pegue uma subsequência de uma sequência
Sintaxe: sequência [start subscript: end subscript: tamanho do passo]
Indica que a partir da sequência, partindo da posição especificada, retirando elementos em sequência e terminando na posição especificada, obtém-se uma nova sequência:
-
O subscrito start indica onde começar, pode ser deixado em branco e será considerado como começando do começo
-
O subscrito final (não incluído) indica onde terminar, pode ser deixado em branco, será considerado como interceptado até o final
-
O tamanho do passo indica que o intervalo de elementos é tomado sucessivamente
-
Tamanho do passo 1 significa, pegue os elementos um por um
-
Um tamanho de passo de 2 significa que um elemento é ignorado a cada vez
-
O tamanho do passo N significa que N-1 elementos são ignorados a cada vez para levar
-
Se o tamanho do passo for um número negativo, ele é invertido (observe que o subscrito inicial e o subscrito final também devem ser marcados ao contrário)
Observe que esta operação não afeta a sequência em si, mas resulta em uma nova sequência (lista, tupla, string)
Fatiando a Demonstração de uma Sequência
my_list = [1, 2, 3, 4, 5]
new_list = my_list[1:4] # Comece com subscrito 1, termine com subscrito 4 (excluindo), passo 1
print(new_list) # Resultado: [2, 3 , 4 ]
my_tuple = (1, 2, 3, 4, 5)
new_tuple = my_tuple[:] # começa do começo, termina no final, tamanho do passo 1
print(new_tuple) # resultado: (1, 2, 3, 4, 5 )
my_list = [1, 2, 3, 4, 5]
new_list = my_list[::2] # começa do começo, termina no final, tamanho do passo 2
print(new_list) # resultado: [1, 3, 5 ]
my_str = " 12345"
new_str = my_str[:4:2] # Comece do início, termine no subscrito 4 (não incluído), tamanho do passo 2
print(new_str) # Resultado: "13"
my_str = "12345"
new_str = my_str[::- 1] # Começar do começo (último), fim ao fim, tamanho do passo -1 (ordem inversa)
print(new_str) # Resultado: "54321"
my_list = [1, 2, 3, 4, 5]
new_list = my_list[3:1 :-1] # Começa no subscrito 3 e termina no subscrito 1 (excluindo), tamanho do passo -1 (ordem inversa)
print(new_list) # Resultado: [4, 3]
my_tuple = (1, 2, 3, 4, 5)
new_tuple = my_tuple[:1:-2]
# Começa do começo (último), termina no subscrito 1 (excluindo), passo -2 (ordem inversa)
print(new_tuple ) # resultado: (5, 3)
Como você pode ver, esta operação é comum para listas, tuplas e strings
Ao mesmo tempo, é muito flexível.De acordo com as necessidades, a posição inicial, a posição final e o tamanho do passo (ordem direta e inversa) podem ser controlados por você.
Caso prático: prática de corte de sequência
Há uma string: "Milhares de meses de salário, os programadores estão aqui, nohtyP aprende"
-
Por favor, use qualquer método que você aprendeu para obter "Dark Horse Programmer"
Métodos disponíveis para referência:
-
Inverta a corda, corte ou corte e, em seguida, inverta
-
split "," replace "to" está vazio, string reversa
"""
Exercício após aula de fatiamento da sequência de demonstração
"Se o mês de salário acabar, o programador aprenderá com nohtyP" ""
"
my_str = "Após o mês de salário, o programador virá de nohtyP"
# Ordem inversa String, slice out
result1 = my_str[::-1][9:14]
print(f"Method 1 result: {result1}")
# fatie, depois inverta a ordem
result2 = my_str[5:10][::- 1]
print(f"Resultado do método 2: {resultado2}")
# divisão separada", "substituir "para" está vazio, string reversa
resultado3 = my_str.split(",")[1].replace("para ", "" )[::-1]
print(f"Resultado do método 3: {resultado3}")
Contêiner de dados: conjunto (coleção)
meta de aprendizado
-
Domine o formato de definição de coleções
-
Domine as características das coleções
-
Domine operações comuns em coleções
Por que usar coleções
Entramos em contato com os três contêineres de dados de listas, tuplas e strings. Basicamente atende a maioria dos cenários de uso.
Por que você precisa aprender um novo tipo de coleção?
Analise por características:
-
As listas são modificáveis, suportam elementos repetidos e são ordenadas
-
Tuplas e strings não são modificáveis, suportam elementos repetidos e estão em ordem Alunos, vocês veem algumas limitações?
A limitação é esta: todos eles suportam elementos repetidos. Se a cena precisar desduplicar o conteúdo, listas, tuplas e strings serão inconvenientes. A principal característica da coleção é que ela não suporta a repetição de elementos (com sua própria função de desduplicação) e o conteúdo está fora de ordem
definição de coleção
Sintaxe básica:
#Define coleção literal
{elemento, elemento,...., elemento}
#Define coleção variável
variável nome={elemento, elemento,...,elemento}
#define coleção vazia
nome variável=set()
Basicamente a mesma definição de listas, tuplas, strings, etc.:
-
Uso da lista: []
-
Uso de tupla: ()
-
Uso da string: ""
-
Uso da coleção: {}
Código de amostra
nomes = {"Dark Horse Programmer","Chuanzhi Podcast","itcast","itheima","Dark Horse Programmer","Chuanzhi Podcast"} print(nomes
)
resultado da operação
{'itcast', 'Chuanzhi Podcast', 'Dark Horse Programmer', 'itheima'}
Pode-se observar nos resultados: desduplicação e desordem porque os elementos precisam ser removidos, portanto não é possível garantir que a ordem seja consistente com o reprocessamento no momento da criação
Operações comuns em coleções - modificar
Em primeiro lugar, porque a coleção não é ordenada, a coleção não suporta acesso ao índice subscrito, mas a coleção, como a lista, permite modificação, então vamos dar uma olhada no método de modificação da coleção.
-
adicionar novo elemento
Sintaxe: coleção.add(elemento).
Função: Adicionar o elemento especificado à coleção
Resultado: a própria coleção é modificada, novos elementos são adicionados
my_set = {"Hello","World"}
my_set.add("itheima")
print(my_set) # 结果 {'Hello','itheima','World']
-
remover elemento
Sintaxe: coleção.remove(elemento)
Função: remove o elemento especificado da coleção
Resultado: a própria coleção é modificada, removendo o elemento
my_set = {"Hello","World","itheima"}
my_set.remove("Hello")
print(my_set) # 结果{'World','itheima'
-
Remover aleatoriamente elementos de uma coleção
Sintaxe: coleção.pop()
Função para pegar aleatoriamente um elemento de uma coleção
Resultado: Será obtido um resultado de um elemento. Ao mesmo tempo, a própria coleção é modificada e os elementos são removidos
my_set = {"Hello","World","itheima"}
element =my_set.pop()
print(my_set) #result {'World','iheima'}
print(element) #result'He11o
-
coleção vazia
Sintaxe: coleção.clear()
função, esvaziando a coleção
Resultado: a própria coleção é esvaziada
my_set = {"Hello","World","itheima"}
my_set.clear()
print(my_set) #Resultado: set() conjunto vazio
-
Pegue a diferença de 2 conjuntos
Sintaxe: set1.difference(set2),
Função: Tirar a diferença entre o conjunto 1 e o conjunto 2 (o conjunto 1 tem, mas o conjunto 2 não)
Resultado: obtenha um novo conjunto, conjunto 1 e conjunto 2 inalterado
set1 = {1,2,3}
set2 = {1,5,6}
set3 = set1.difference(set2)
print(set3) # resultado: {2,3} o novo conjunto
print(set1) # resultado: { 1 ,2,3}
print(set2) inalterado # Resultado: {1,5,6} inalterado
-
Elimine a diferença de 2 conjuntos
Sintaxe: set1.difference_update(set2)
Função: Compare o conjunto 1 e o conjunto 2, exclua os mesmos elementos do conjunto 2 no conjunto 1.
Resultado: o conjunto 1 é modificado, o conjunto 2 permanece inalterado
setl ={1,2,3}
set2={1,5,6}
set1.difference_update(set2)
print(set1) # resultado: {2,3]
print(set2) # resultado: {1,5,6}
-
2 coleções mescladas
Sintaxe: set1.union(set2)
Função: Combine o conjunto 1 e o conjunto 2 em um novo conjunto
Resultado: obtenha um novo conjunto, conjunto 1 e conjunto 2 inalterado
set1 = {1,2,3}
set2 = {1,5,6}
set3 = set1.union(set2)
print(set3) # resultado: {1,2,3,5,6}, novo conjunto
print(set1 ) # Result: {1,2,3}, set1 inalterado
print(set2) # Result: {1,5,6}, set2 inalterado
Operações comuns em coleções - comprimento da coleção
-
Exibir o número de elementos em uma coleção
Sintaxe: len(coleção)
Função: contar quantos elementos há na coleção
Resultado: obtenha um resultado inteiro
set1={1,2,3}
print(len(set1)) # resultado 3
Operações comuns em coleções - para passagem de loop
As coleções também suportam loop traversal
set1={1,2,3}
for i in set1:
print(i)
# 结果
1
2
3
Nota: as coleções não suportam índices subscritos, portanto, o uso de loops while não é suportado.
Coleção de resumo de funções comuns
| número de série |
operar |
ilustrar |
|---|---|---|
| 1 |
coleção.add(elemento) |
adicionar um elemento à coleção |
| 2 |
coleção.remove(elemento) |
remove o elemento especificado da coleção |
| 3 |
coleção.pop() |
Selecione aleatoriamente um elemento de uma coleção |
| 4 |
Set.clear() |
esvaziar a coleção |
| 5 |
conjunto1.diferença(conjunto2) |
Obtenha um novo conjunto, que contém o conjunto de diferença de 2 conjuntos, e o conteúdo dos 2 conjuntos originais permanece inalterado |
| 6 |
set1.difference_update(set2) |
No conjunto 1, exclua os elementos presentes no conjunto 2, o conjunto 1 é modificado, o conjunto 2 permanece inalterado |
| 7 |
Coleção 1.união(coleção 2) |
Obtenha uma nova coleção, contendo todos os elementos das duas coleções, o conteúdo das duas coleções originais permanece inalterado |
| 8 |
len(coleção) |
Obtenha um número inteiro que registra o número de elementos na coleção |
Características da Coleção
Após o estudo das coleções acima, pode-se concluir que as coleções têm as seguintes características:
-
Pode acomodar vários dados • Pode acomodar diferentes tipos de dados (misto)
-
Os dados são armazenados fora de ordem (índices subscritos não são suportados)
-
Dados duplicados não são permitidos
-
Pode ser modificado (adicionar ou remover elementos, etc.)
-
Suporte para loop
Caso prático: desduplicação de informações
Existem os seguintes objetos de lista: my_list = ['Dark Horse Programmer', 'Chuanzhi Podcast', 'Dark Horse Programmer', 'Chuanzhi Podcast', 'itheima', 'itcast', 'itheima', 'itcast', 'best '] por favor:
-
definir uma coleção vazia
-
Iterando a lista com um loop for
-
Adicionando elementos de uma lista a uma coleção em um loop for
-
Finalmente, obtenha o objeto de coleção após a desduplicação dos elementos e imprima

Código de amostra:
"""
演示集合的课后练习题
my_list = ['黑马程序员', '传智播客', '黑马程序员', '传智播客',
'itheima', 'itcast', 'itheima', 'itcast', 'best']
"""
my_list = ['黑马程序员', '传智播客', '黑马程序员', '传智播客',
'itheima', 'itcast', 'itheima', 'itcast', 'best']
# 定义一个空集合
my_set = set()
# 通过for循环遍历列表
for element in my_list:
# 在for循环中将列表的元素添加至集合
my_set.add(element)
# 最终得到元素去重后的集合对象,并打印输出
print(f"列表的内容是:{my_list}")
print(f"通过for循环后,得到的集合对象是:{my_set}")
字典的定义
学习目标
-
掌握字典的定义格式
为什么使用字典
生活中的字

通过【字】就能找到对应的【含义】
所以,我们可以认为,生活中的字典就是记录的一堆:【字】:【含义】 【字】:【含义】 ..
为什么需要字典
Python中字典和生活中字典十分相像:
| 生活中的字典 |
Python中的字典 |
|---|---|
| 【字】:【含义】【字】:【含义】 |
|
| 可以按【字】找出对应的【含义】 |
Key: Value Key: Value |
| 可以按【Key】找出对应的【Value】 |
老师有一份名单,记录了学生的姓名和考试总成绩。
| 姓名 |
成绩 |
|---|---|
| 王力鸿 |
77 |
| 周杰轮 |
88 |
| 林俊节 |
99 |
现在需要将其通过Python录入至程序中,并可以通过学生姓名检索学生的成绩。使用字典最为合适:
{"王力鸿":99,
"周杰轮":88,
"林俊节":77
}
可以通过Key(学生姓名),取到对应的Value(考试成绩)
所以,为什么使用字典?
因为可以使用字典,实现用key取出Value的操作
字典的定义
字典的定义,同样使用{},不过存储的元素是一个个的:键值对,如下语法:
#定义字典字面量
{key:value,key:value,......,key:value}
#定义字典变量
my_dict = {key:value,key:value,......,key:value}
#定义空字典
my_dict ={} # 空字典定义方式1
my_dict= dict{} # 空字典定义方式2
-
使用{}存储原始,每一个元素是一个键值对
-
每一个键值对包含Key和Value(用冒号分隔)
-
键值对之间使用逗号分隔
-
Key和Value可以是任意类型的数据(key不可为字典)
-
Key不可重复,重复会对原有数据覆盖
前文中记录学生成绩的需求,可以如下记录:
stu_score = {"王力鸿":99,"周杰轮":88,"林俊节":77}
字典数据的获取
字典同集合一样,不可以使用下标索引
但是字典可以通过Key值来取得对应的Value
# 语法,字典[Key]可以取到对应的Value
stu_score={"王力鸿":99,"周杰轮":88,"林俊节":77}
print(stu_score["王力鸿"]) # 结果99
print(stu_score["周杰轮"]) # 结果88
print(stu_score["林俊节"]) # 结果77
字典的嵌套
字典的Key和Value可以是任意数据类型(Key不可为字典)那么,就表明,字典是可以嵌套的需求如下:记录学生各科的考试信息
| 姓名 |
语文 |
数学 |
英语 |
|---|---|---|---|
| 王力鸿 |
77 |
66 |
33 |
| 周杰轮 |
88 |
86 |
55 |
| 林俊节 |
99 |
96 |
66 |
代码:
stu_score={"王力鸿":{"语文":77,"数学":66,"英语":33},"周杰轮":{"语文":88,"数学":86,"英语":55},
"林俊节":{"语文":99,"数学":96,"英语":66}}
优化一下可读性,可以写成:
stu_score = {
"王力鸿":{"语文":77,"数学":66,"英语":33},
"周杰轮":{"语文":88,"数学":86,"英语":55},
"林俊节":{"语文":99,"数学":96,"英语":66}
}
嵌套字典的内容获取,如下所示:
stu_score = {
"王力鸿":{"语文":77,"数学":66,"英语":33},
"周杰轮":{"语文":88,"数学":86,"英语":55},
"林俊节":{"语文":99,"数学":96,"英语":66}
}
print(stu_score["王力鸿"]) # 结果:{"语文":77,"数学":66,"英语":33}
print(stu_score["王力鸿"]["语文"]) # 结果:77
print(stu_score["周杰轮"]["数学"]) # 结果:86
字典的常用操作
学习目标
-
掌握字典的常用操作
-
掌握字典的特点
字典的常用操作
-
新增元素
语法:字典[Key] = Value
结果:字典被修改,新增了元素
stu_score ={
"王力鸿":77,
"周杰轮":88,
"林俊节":99
}
# 新增:张学油的考试成绩
stu_score['张学油']=66
print(stu_score) # 结果:{王力鸿:77,'周杰轮:88,林俊节:99,张学油:66}
-
更新元素
语法:字典[Key] = Value
结果:字典被修改,元素被更新
注意:字典Key不可以重复,所以对已存在的Key执行上述操作,就是更新Value值
stu_score ={
"王力鸿":77,
"周杰轮":88,
"林俊节":99
}
# 更新:王力鸿的考试成绩
stu_score['王力鸿']=100
print(stu_score) # 结果:{王力鸿:100,周杰轮:88,林俊节:99}
-
删除元素
语法:字典.pop(Key)
结果:获得指定Key的Value,同时字典被修改,指定Key的数据被删除
stu_score ={
"王力鸿":77,
"周杰轮":88,
"林俊节":99
}
value=stu_score.pop("王力鸿")
print(value) # 结果:77
print(stu_score) # 结果:{"周杰轮":88,"林俊节":99}
-
清空字典
语法:字典.clear()
结果:字典被修改,元素被清空
stu_score ={
"王力鸿":77,
"周杰轮":88,
"林俊节":99
}
stu_score.clear()
print(stu_score) # 结果:{}
-
获取全部的key
语法:字典.keys()
结果:得到字典中的全部Key
stu_score ={
"王力鸿":77,
"周杰轮":88,
"林俊节":99
}
keys = stu_score.keys()
print(keys) # 结果:dict_keys(['王力鸿','周杰轮','林俊节])
-
遍历字典
语法:for key in 字典.keys()
stu_score ={
"王力鸿":77,
"周杰轮":88,
"林俊节":99
}
keys = stu_score.keys()
for key in keys:
print(f"学生:{key},分数:{stu_score[key]}")
学生:王力鸿,分数:77
学生:周杰轮,分数:88
学生:林俊节,分数:99
注意:字典不支持下标索引,所以同样不可以用while循环遍历。
-
计算字典内的全部元素(键值对)数量
语法:len(字典)
结果:得到一个整数,表示字典内元素(键值对)的数量
stu_score ={
"王力鸿":77,
"周杰轮":88,
"林俊节":99
}
print(len(stu_score)) # 结果 3
字典的常用操作总结
| 编号 |
操作 |
说明 |
|---|---|---|
| 1 |
字典[Key] |
获取指定Key对应的Value值 |
| 2 |
字典[Key] = Value |
添加或更新键值对 |
| 3 |
字典.pop(Key) |
取出Key对应的Value并在字典内删除此Key的键值对 |
| 4 |
字典.clear() |
清空字典 |
| 5 |
字典.keys() |
获取字典的全部Key,可用于for循环遍历字典 |
| 6 |
len(字典) |
计算字典内的元素数量 |
字典的特点
经过上述对字典的学习,可以总结出字典有如下特点:
-
可以容纳多个数据 • 可以容纳不同类型的数据
-
每一份数据是KeyValue键值对
-
可以通过Key获取到Value,Key不可重复(重复会覆盖)
-
不支持下标索引
-
可以修改(增加或删除更新元素等)
-
支持for循环,不支持while循环
课后练习:升职加薪
有如下员工信息,请使用字典完成数据的记录。
并通过for循环,对所有级别为1级的员工,级别上升1级,薪水增加1000元
| 姓名 |
部门 |
工资 |
级别 |
|---|---|---|---|
| 王力鸿 |
科技部 |
3000 |
1 |
| 周杰轮 |
市场部 |
5000 |
2 |
| 林俊节 |
市场部 |
7000 |
3 |
| 张学油 |
科技部 |
4000 |
1 |
| 刘德滑 |
市场部 |
6000 |
2 |
运行后,输出如下信息:
全体员工当前信息如下:
{'王力鸿':{'部门':'科技部','工资':3000,'级别':1},'周杰轮':{'部门':'市场部','工资':5000,'级别':2},
'林俊节':{'部门':'市场部','工资':6000,'级别':3},'张学油':{'部门':'科技部','工资':4000,'级别':1},
'刘德滑':{'部门':'市场部','工资':6000,'级别':2}}
全体员工级别为1的员工完成升值加薪操作,操作后:
{'王力鸿':{'部门':'科技部','工资':4000,'级别':2},'周杰轮':{'部门':'市场部','工资':5000,'级别':2},
'林俊节':{'部门':'市场部','工资':6000,'级别':3},'张学油':{'部门':'科技部','工资':5000,'级别':2},
'刘德滑':{'部门':'市场部','工资':6000,'级别':2}}
参考代码:
"""
演示字典的课后练习:升职加薪,对所有级别为1级的员工,级别上升1级,薪水增加1000元
"""
# 组织字典记录数据
info_dict = {
"王力鸿": {
"部门": "科技部",
"工资": 3000,
"级别": 1
},
"周杰轮": {
"部门": "市场部",
"工资": 5000,
"级别": 2
},
"林俊节": {
"部门": "市场部",
"工资": 7000,
"级别": 3
},
"张学油": {
"部门": "科技部",
"工资": 4000,
"级别": 1
},
"刘德滑": {
"部门": "市场部",
"工资": 6000,
"级别": 2
}
}
print(f"员工在升值加薪之前的结果:{info_dict}")
# for循环遍历字典
for name in info_dict:
# if条件判断符合条件员工
if info_dict[name]["级别"] == 1:
# 升职加薪操作
# 获取到员工的信息字典
employee_info_dict = info_dict[name]
# 修改员工的信息
employee_info_dict["级别"] = 2 # 级别+1
employee_info_dict["工资"] += 1000 # 工资+1000
# 将员工的信息更新回info_dict
info_dict[name] = employee_info_dict
# 输出结果
print(f"对员工进行升级加薪后的结果是:{info_dict}")
拓展:数据容器对比总结
数据容器分类
数据容器可以从以下视角进行简单的分类:
-
是否支持下标索引
-
支持:列表、元组、字符串 - 序列类型
-
不支持:集合、字典 - 非序列类型
-
是否支持重复元素:
-
支持:列表、元组、字符串 - 序列类型
-
不支持:集合、字典 - 非序列类型
-
是否可以修改
-
支持:列表、集合、字典
-
不支持:元组、字符串
数据容器特点对比
| 列表 |
元组 |
字符串 |
集合 |
字典 |
|
|---|---|---|---|---|---|
| 元素数量 |
支持多个 |
支持多个 |
支持多个 |
支持多个 |
支持多个 |
| 元素类型 |
任意 |
任意 |
仅字符 |
任意 |
Key:Value Key:除字典外任意类型 Value:任意类型 |
| 下标索引 |
支持 |
支持 |
支持 |
不支持 |
不支持 |
| 重复元素 |
支持 |
支持 |
支持 |
不支持 |
不支持 |
| 可修改性 |
支持 |
不支持 |
不支持 |
支持 |
支持 |
| 数据有序 |
是 |
是 |
是 |
否 |
否 |
| 使用场景 |
可修改、可重复的一批数据记录场景 |
不可修改、可重复的一批数据记录场景 |
一串字符的记录场景 |
不可重复的数据记录场景 |
以Key检索 Value的数据记录场景 |
数据容器的通用操作
到目前为止,我们已经掌握了 5 种数据容器。现在,让我们来学习它们的通用操作。虽然每种容器都有自己独特的特点,但它们也有一些通用的操作。
数据容器的通用操作 - 遍历
数据容器尽管各自有各自的特点,但是它们也有通用的一些操作。首先,在遍历上:
-
5类数据容器都支持for循环遍历
-
列表、元组、字符串支持while循环,集合、字典不支持(无法下标索引)
尽管遍历的形式各有不同,但是,它们都支持遍历操作。
数据容器的通用统计功能
除了遍历这个共性外,数据容器可以通用非常多的功能方法
-
len(容器)
统计容器的元素个数
my_list = [1, 2, 3]
my_tuple = (1, 2, 3, 4, 5)
my_str = "itiheima"
print(len(my_list)) # 结果3
print(len(my_tuple)) # 结果5
print(len(my_str)) # 结果7
-
max(容器)
统计容器的最大元素
my_list = [1, 2, 3]
my_tuple = (1, 2, 3, 4, 5)
my_str = "itiheima"
print(max(my_list)) # 结果3
print(max(my_tuple)) # 结果5
print(max(my_str)) # 结果t
-
min(容器)
统计容器的最小元素
my_list = [1, 2, 3]
my_tuple = (1, 2, 3, 4, 5)
my_str = "itiheima"
print(min(my_list)) # 结果1
print(min(my_tuple)) # 结果1
print(min(my_str)) # 结果a
同学们可能会疑惑,字符串如何确定大小?下一小节讲解。
容器的通用转换功能
除了下标索引这个共性外,还可以通用类型转换
list(容器) 将给定容器转换为列表
tuple(容器) 将给定容器转换为元组
str(容器) 将给定容器转换为字符串
set(容器) 将给定容器转换为集合
容器通用排序功能
通用排序功能 sorted(容器, [reverse=True]) 将给定容器进行排序
注意,排序后都会得到列表(list)对象。
容器通用功能总览
| 功能 |
描述 |
|---|---|
| 通用for循环 |
遍历容器(字典是遍历key) |
| max |
容器内最大元素 |
| min() |
容器内最小元素 |
| len() |
容器元素个数 |
| list() |
转换为列表 |
| tuple() |
转换为元组 |
| str() |
转换为字符串 |
| set() |
转换为集合 |
| sorted(序列, [reverse=True]) |
排序,reverse=True表示降序得到一个排好序的列表 |
字符串大小比较
在上一节课的通用数据容器操作中,我们使用了Min和Max函数,在数据容器中找到最小和最大的元素。在上一节课中,我们有一个问题,那就是字符串如何进行大小比较?在本节课中,我们将讲解这个问题。但在讲解字符串大小比较之前,我们需要先普及一个概念,这就是ASCII码表。在我们的程序中,字符串中使用的字符可以是大写或小写的英文字母、数字以及特殊符号,如感叹号、斜杠、竖杠、“@”符号、井号、空格等。每个字符都有其对应的ASCII码表值,因此字符串的比较基于字符所对应的数字码值的大小来进行。
字符串进行比较就是基于数字的码值大小进行比较的。
下面是一个典型的ASCII码表,其中我们可以找到我们所使用的一系列符号或字符对应的码值。例如,数字0123456789对应的码值从48到57,我们经常使用的大写英文字母从A到Z,对应的码值在65到90之间,小写英文字母从a到z,对应的码值在97到122之间。因此,我们常用字符的码值都可以在表中找到,因此,字符串的大小比较就很容易理解了。
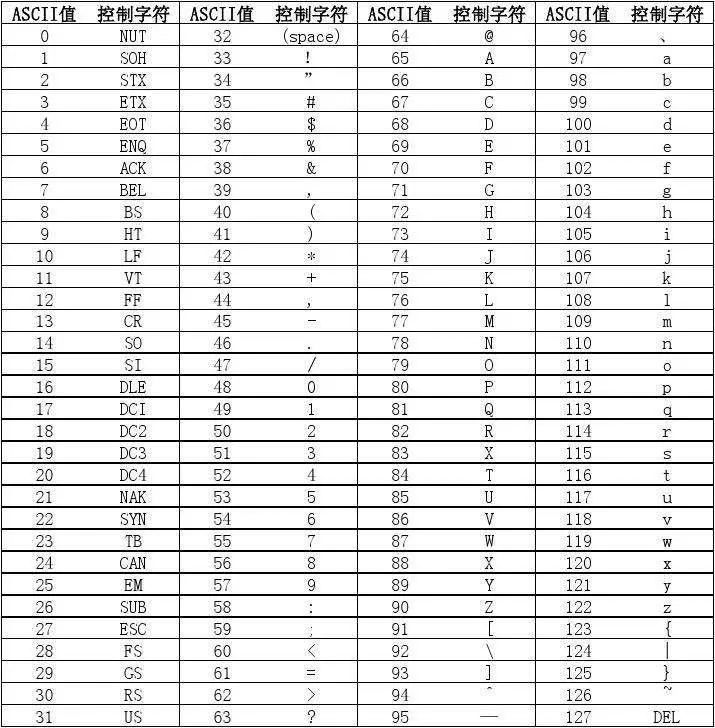
Por exemplo, um a minúsculo e um A maiúsculo, dizemos quem é maior e quem é menor, na verdade, eles são comparados por valor de código. O a minúsculo e o A maiúsculo, o que for maior, também descobrirão que o valor do código do a minúsculo é 97, que é maior que o 65 do A maiúsculo; Tabela de códigos ASCII. Com esse conceito em mente, vamos ver como as strings são comparadas.
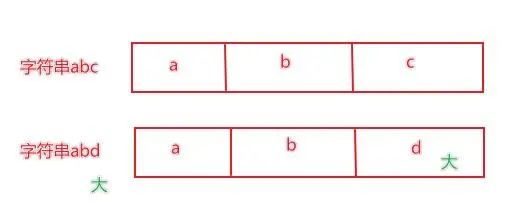
comparação de strings
As strings são comparadas bit a bit, ou seja, bit a bit é comparada, desde que um bit seja maior, o todo é maior.
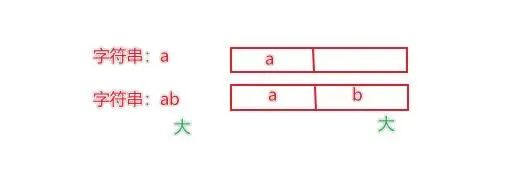
"""
Comparação de tamanho de string de demonstração
"""
# abc compara abd
print(f"abd é maior que abc, resultado: {'abd' > 'abc'}")
#a compara ab
print(f"ab é maior que a , result: {'ab' > 'a'}")
# compare a com A
print(f"a é maior que A, result: {'a' > 'A'}")
# key1 compara key2
print(f" key2 > key1, resultado: {'key2' > 'key1'}")
resultado de saída
abd é maior que abc, resultado: Verdadeiro
ab é maior que a, resultado: Verdadeiro
a é maior que A, resultado: Verdadeiro
key2 > key1, resultado: True