Este blog primeiro descreve brevemente os fundamentos do áudio e, em seguida, ajuda os leitores a começar com o esp-sr SDK.
1 Conceitos Básicos de Áudio
1.1 A natureza do som
A essência do som é o fenômeno da propagação da onda no meio, e a essência da onda sonora é uma onda, uma quantidade física. Os dois são diferentes: o som é uma abstração, um fenômeno de propagação da onda sonora, e a onda sonora é uma quantidade física.
1.2 Três elementos do som
- Loudness: O tamanho do som (comumente conhecido como volume) que as pessoas percebem subjetivamente, que é determinado pela amplitude e a distância entre a pessoa e a fonte sonora.
- Tom: A diferença de frequência determina o tom do som (agudos, graves). Quanto maior a frequência, mais alto o tom (a unidade de frequência é Hz, Hertz). A faixa de audição humana é de 20 a 20.000 Hz. Abaixo de 20 Hz é chamado de infrassom, acima de 20000 Hz é chamado de ultrassônico).
- Timbre: Devido às características de diferentes objetos e materiais, o som tem características diferentes. O próprio timbre é uma coisa abstrata, mas a forma de onda é essa performance abstrata e intuitiva. As formas de onda variam de afinação para afinação, e diferentes afinações podem ser distinguidas por suas formas de onda.
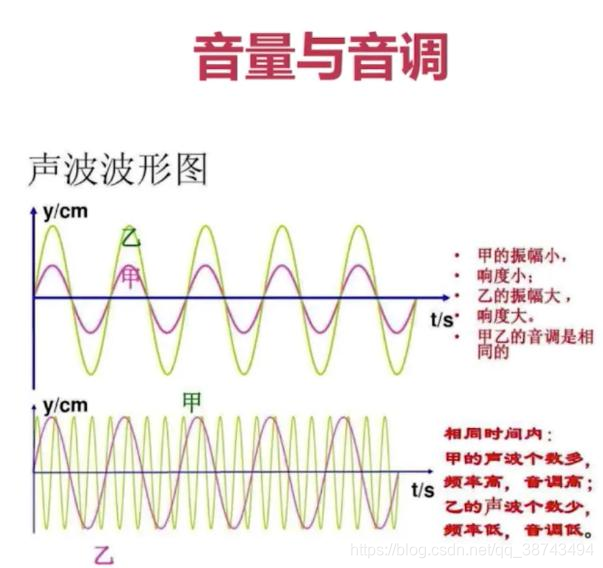
1.3 Vários conceitos básicos de áudio digital
1.3.1 Amostragem
A chamada amostragem é para digitalizar o sinal apenas no eixo do tempo.
- De acordo com a lei de Nyquist (também conhecida como lei de amostragem), a amostragem é realizada com o dobro da frequência mais alta do som. A faixa de frequência (pitch) da audição humana é de 20 Hz a 20 KHz. Portanto, pelo menos maior que 40 kHz. A frequência de amostragem é normalmente de 44,1 kHz, o que garante que sons de até 20 kHz também possam ser digitalizados. 44,1 kHz significa 44100 amostras por segundo.
A voz Espressif AI usa uma taxa de amostragem de 16 kHz. Metade da frequência de amostragem de 16 kHz corresponde ao limite superior da banda de frequência comumente usada da fala humana, que é de cerca de 8 kHz. Além disso, a taxa de amostragem de 44,1 kHz é outra taxa de amostragem comumente usada A taxa de amostragem de 44,1 kHz Porque em um mesmo período de tempo, quanto maior a taxa de amostragem, maior a quantidade de dados, então: Geralmente o áudio das mensagens instantâneas usará uma taxa de amostragem de 16 kHz ou até menor para garantir a pontualidade da transmissão do sinal, mas também afetam a qualidade do áudio Causam certas perdas (como som opaco); durante a gravação de recursos de áudio que se concentram em som de alta qualidade usarão uma taxa de amostragem de 44,1 kHz ou até 48 kHz para garantir alta fidelidade do sinal de reprodução ao custo de mais armazenamento de dados.

Portanto, esta parte inclui principalmente os três parâmetros a seguir:
- Taxa de bits: A taxa de bits é o número de bits transmitidos por segundo. As unidades são bits (bps bits por segundo).
- Amostragem: A amostragem é converter um sinal de tempo contínuo em um sinal digital discreto.
- Taxa de amostragem: A taxa de amostragem é quantas amostras são tomadas por segundo.
1.3.2 Quantização
A quantização refere-se à digitalização de um sinal no eixo de magnitude. Se uma amostra for representada por um sinal binário de 16 bits, o intervalo representado por uma amostra é [-32768, 32767].
A voz Espressif AI usa quantização de 16 bits.
1.3.3 Número de canais
O número de canais é o número de canais de som, e os mais comuns são mono, binaural e estéreo.
-
O som monofônico só pode ser produzido por um alto-falante ou pode ser processado em dois alto-falantes para emitir o som do mesmo canal. Ao reproduzir informações monofônicas por meio de dois alto-falantes, podemos sentir claramente que o som vem de dois alto-falantes. É impossível ouvir determinar a localização específica da fonte de som se ela for transmitida aos nossos ouvidos entre os dois alto-falantes.
-
Binaural significa que existem dois canais de som. O princípio é que quando as pessoas ouvem o som, elas podem julgar a posição específica da fonte de som de acordo com a diferença de fase entre o ouvido esquerdo e o ouvido direito. O som foi dividido em dois canais separados durante a gravação, resultando em ótima localização sonora.
1.3.4 Cálculo do tamanho do áudio
Por exemplo: Para gravar um trecho de áudio com tempo de 1 s, taxa de amostragem de 16000 HZ, tamanho de amostragem de 16 e número de canal de 2, o espaço ocupado é: 16000 * 16 * 2 * 1 s= 500 mil
2 front-end acústico (front-end de áudio, AFE)
Um conjunto de estrutura de algoritmo Espressif AFE pode ser usado para processamento de front-end acústico com base no poderoso ESP32 e ESP32-S3 SoC, permitindo que os usuários obtenham dados de áudio estáveis e de alta qualidade, de modo a criar produtos de voz inteligentes com excelente desempenho e desempenho de alto custo.
2.1 Cancelamento de Eco Acústico (AEC)
O algoritmo de cancelamento de eco acústico usa filtragem adaptável para eliminar ecos quando o áudio é inserido de um microfone. Esse algoritmo é adequado para cenários como dispositivos de voz reproduzindo áudio por meio de alto-falantes.
O algoritmo suporta no máximo processamento de microfone duplo, o que pode efetivamente remover o som de reprodução automática no sinal de entrada do microfone. Dessa forma, aplicativos como reconhecimento de voz podem ser bem executados sob a condição de tocar música por si só.
2.2 Separação Cega de Fontes (BSS)
O algoritmo Blind Source Separation usa vários microfones para detectar a direção do áudio de entrada e enfatiza a entrada de áudio de uma determinada direção. Este algoritmo melhora a qualidade do som da fonte de áudio desejada em ambientes ruidosos.
2.3 Supressão de Ruído (NS)
O algoritmo de supressão de ruído suporta processamento de sinal de áudio de canal único, que pode efetivamente eliminar sons não humanos inúteis (como aspiradores de pó ou condicionadores de ar), melhorando assim o sinal de áudio a ser processado.
3 Cenários suportados pelo Espressif AFE
As funções do Espressif AFE destinam-se a dois cenários diferentes:
-
cena de reconhecimento de voz
-
cena de chamada de voz
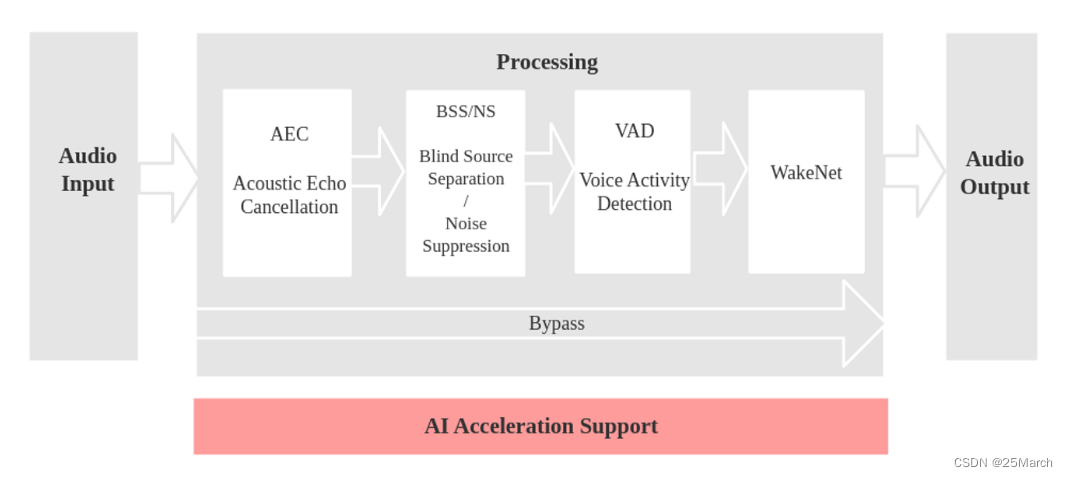
3.1 Cenário de Reconhecimento de Fala
Etapas do modelo:
-
entrada de áudio
-
AEC para cancelamento de eco (remove seu próprio anúncio de áudio, que requer um canal de eco)
- Retorno de chamada rígido: leia diretamente os dados gravados no alto-falante por meio do IIS (pode compartilhar um IIS com o microfone)
- Retorno de chamada suave: dados de cópia de software gravados no alto-falante (ainda não suportado, aguardando desenvolvimento)
-
BSS/NS
- O algoritmo BSS (Blind Source Separation) suporta processamento de canal duplo , que pode separar cegamente a fonte de som alvo de outros sons interferentes, extraindo assim sinais de áudio úteis e garantindo a qualidade da fala subsequente.
- O algoritmo NS (Supressão de Ruído) suporta processamento de canal único , que pode suprimir o ruído de voz não humana em áudio de canal único, especialmente para ruído de estado estacionário, e tem um bom efeito de supressão.
- Qual algoritmo usar depende do número de microfones configurados.
-
O QUE
- O algoritmo VAD (Voice Activity Detection) suporta saída em tempo real do status da atividade de voz do quadro atual
-
WakeNetName
palavra de despertar
O fluxograma correspondente é o seguinte:
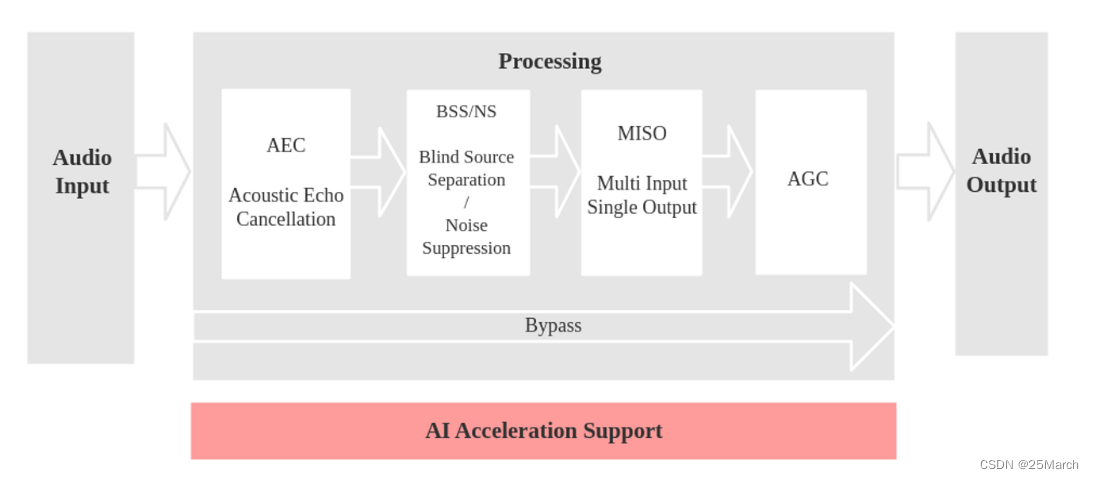
3.2 Cenário de chamada de voz
Etapas do modelo:
- entrada de áudio
- AEC para cancelamento de eco (remove seu próprio anúncio de áudio, que requer um canal de eco)
- Retorno de chamada rígido: leia diretamente os dados gravados no alto-falante por meio do IIS (pode compartilhar um IIS com o microfone)
- Retorno de chamada suave: dados de cópia de software gravados no alto-falante (ainda não suportado, aguardando desenvolvimento)
- BSS/NS
- O algoritmo BSS (Blind Source Separation) suporta processamento de canal duplo , que pode separar cegamente a fonte de som alvo de outros sons interferentes, extraindo assim sinais de áudio úteis e garantindo a qualidade da fala subsequente.
- O algoritmo NS (Supressão de Ruído) suporta processamento de canal único , que pode suprimir o ruído de voz não humana em áudio de canal único, especialmente para ruído de estado estacionário, e tem um bom efeito de supressão.
- Qual algoritmo usar depende do número de microfones configurados.
- MISSÔ
- O algoritmo MISO (Multi Input Single Output) suporta entrada de canal duplo e saída de canal único. Ele é usado para selecionar uma saída de áudio com uma alta relação sinal/ruído em um cenário de microfone duplo sem ativação ativada.
- CAG
- O AGC (Automatic Gain Control) ajusta dinamicamente a amplitude do áudio de saída. Quando um sinal fraco é inserido, a amplitude de saída é amplificada; quando o sinal de entrada atinge uma certa força, a amplitude de saída é comprimida.
O fluxograma correspondente é o seguinte:
3.3 Referência do código de configuração
#define AFE_CONFIG_DEFAULT() {
\
.aec_init = true, \ //AEC 算法是否使能
.se_init = true, \ //BSS/NS 算法是否使能
.vad_init = true, \ //VAD 是否使能 ( 仅可在语音识别场景中使用 )
.wakenet_init = true, \ //唤醒是否使能.
.voice_communication_init = false, \ //语音通话是否使能。与 wakenet_init 不能同时使能.
.voice_communication_agc_init = false, \ //语音通话中AGC是否使能
.voice_communication_agc_gain = 15, \ //AGC的增益值,单位为dB
.vad_mode = VAD_MODE_3, \ //VAD 检测的操作模式,越大越激进
.wakenet_model_name = NULL, \ //选择唤醒词模型
.wakenet_mode = DET_MODE_2CH_90, \ //唤醒的模式。对应为多少通道的唤醒,根据mic通道的数量选择
.afe_mode = SR_MODE_LOW_COST, \ //SR_MODE_LOW_COST: 量化版本,占用资源较少。
//SR_MODE_HIGH_PERF: 非量化版本,占用资源较多。
.afe_perferred_core = 0, \ //AFE 内部 BSS/NS/MISO 算法,运行在哪个 CPU 核
.afe_perferred_priority = 5, \ //AFE 内部 BSS/NS/MISO 算法,运行的task优先级。
.afe_ringbuf_size = 50, \ //内部 ringbuf 大小的配置
.memory_alloc_mode = AFE_MEMORY_ALLOC_MORE_PSRAM, \ //绝大部分从外部psram分配
.agc_mode = AFE_MN_PEAK_AGC_MODE_2, \ //线性放大喂给后续multinet的音频,峰值处为 -4dB。
.pcm_config.total_ch_num = 3, \ //total_ch_num = mic_num + ref_num
.pcm_config.mic_num = 2, \ //音频的麦克风通道数。目前仅支持配置为 1 或 2。
.pcm_config.ref_num = 1, \ //音频的参考回路通道数,目前仅支持配置为 0 或 1。
}
4 modelo de voz AI
4.1 WakeNet
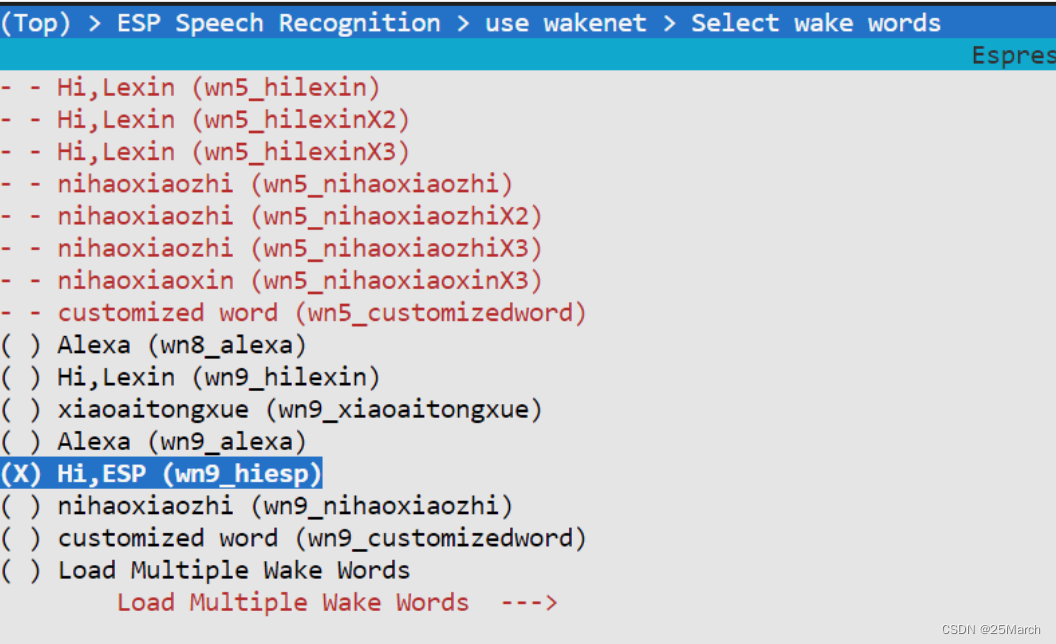
4.1.1 Selecione o modelo através do menuconfig
wn9_hiesp (o último wn9 é a quantização padrão de 8 bits): versão 9, a palavra de ativação é hi, esp
4.2 multi-rede
4.2.1 Selecione o modelo através do menuconfig
mn4q8_cn : Versão 4, quantização de 8 bits, palavras de comando em chinês
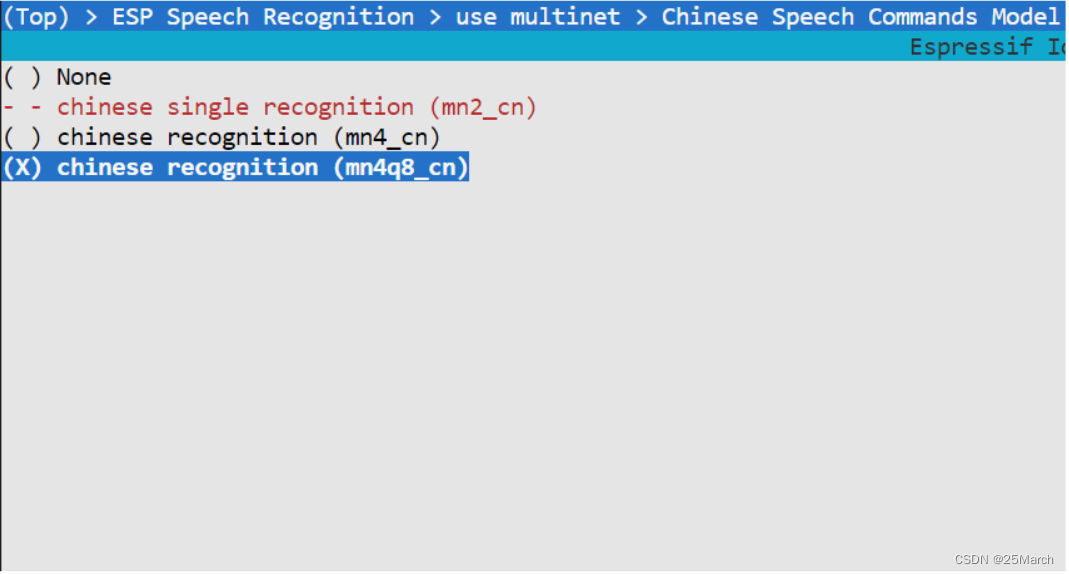
4.3 Adicionar palavras de comando
4.3.1 Adicionar palavras de comando através do menuconfig
-
Adicione pinyin diretamente às palavras de comando em chinês: ligue o ar condicionado (da kai kong tiao) e também suporte várias frases para suportar o mesmo COMMAND ID, velocidade máxima do vento/velocidade máxima do vento
Adicionar palavras de comando do dialeto: adicione a pronúncia correspondente
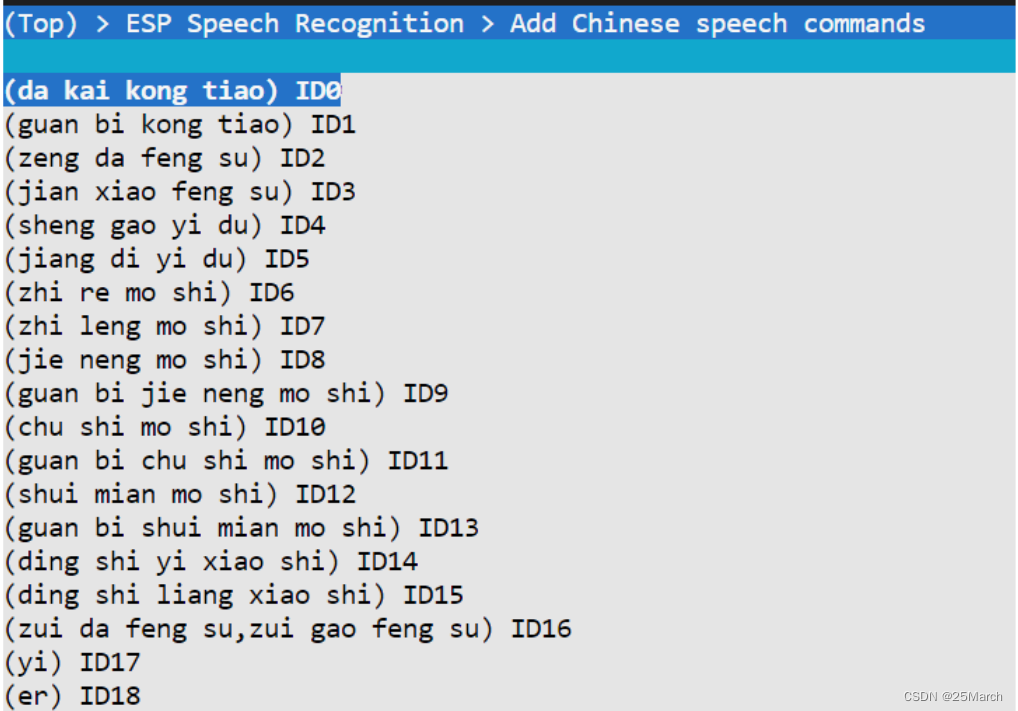
-
Palavras de comando em inglês precisam adicionar fonemas correspondentes, que são gerados por meio de scripts python
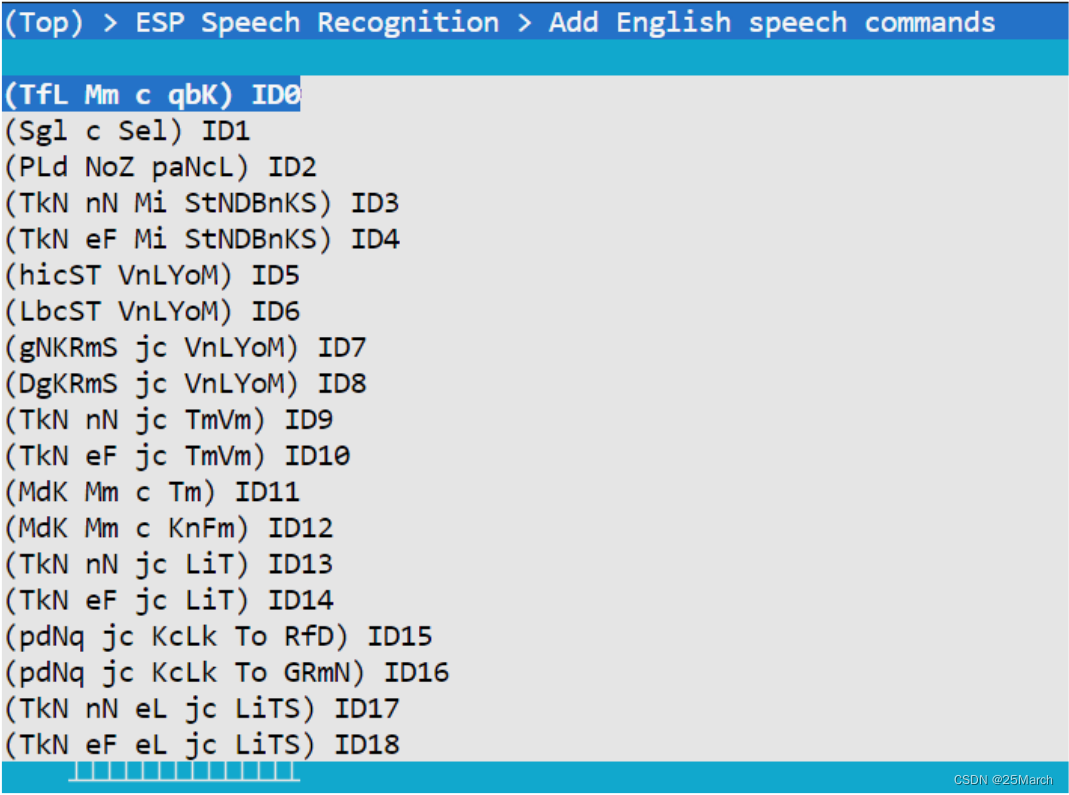
4.3.2 Adicionar dinamicamente palavras de comando no código
esp_mn_commands_add(i, token);
Adicione palavras de comando dinamicamente chamando api.
desempenho do algoritmo
Consome apenas cerca de 20% da CPU, 30 KB SRAM e 500 KB PSRAM
5 Design de Microfone
5.1 Recomendação de desempenho do microfone
-
Tipo de microfone: microfone MEMS omnidirecional.
-
Sensibilidade:
- Sob pressão sonora de 1 Pa, a sensibilidade analógica não deve ser inferior a -38 dBV e a sensibilidade digital não deve ser inferior a -26 dB
- A tolerância é controlada em ±2 dB, ±1 dB é recomendado para matrizes Mike
-
SNR
A relação sinal-ruído não é inferior a 62 dB, e >64 dB é recomendado:
Quanto maior a relação sinal-ruído, mais fidelidade o som
- Resposta de frequência: A flutuação da resposta de frequência na faixa de 50 ~ 16 kHz está dentro de ± 3 dB
- Taxa de rejeição da fonte de alimentação (PSRR): n >55 dB(MEMS MIC)
6 Sugestões de Projeto Estrutural
-
Recomenda-se que o diâmetro ou a largura do orifício do microfone seja superior a 1 mm, o tubo de captação deve ser o mais curto possível e a cavidade deve ser a menor possível para garantir que a frequência de ressonância do microfone e dos componentes estruturais esteja acima 9 KHz.
-
A relação profundidade/diâmetro do orifício coletor é inferior a 2:1, e a espessura do invólucro é recomendada para ser de 1 mm. Se o invólucro for muito grosso, a área do orifício precisa ser aumentada.
-
Os orifícios do rack precisam ser protegidos por redes à prova de poeira.
-
Uma luva de silicone ou espuma deve ser adicionada entre o microfone e o invólucro do dispositivo para vedação e à prova de choque, e um design de ajuste de interferência é necessário para garantir a estanqueidade do microfone.
-
O orifício do microfone não pode ser bloqueado e o orifício inferior do microfone precisa ser levantado na estrutura para evitar que o orifício do microfone seja bloqueado pela mesa.
-
O microfone deve ser colocado longe de alto-falantes e outros objetos que gerem ruído ou vibração e deve ser isolado e protegido da cavidade do alto-falante por almofadas de borracha.
7 explicação do código (CN_SPEECH_COMMANDS_RECOGNITION)
7.1 Arquivos de cabeçalho
#include "esp_wn_iface.h" //唤醒词模型的一系列API
#include "esp_wn_models.h" //根据输入的模型名称得到具体的唤醒词模型
#include "esp_afe_sr_iface.h" //语音识别的音频前端算法的一系列API
#include "esp_afe_sr_models.h" //语音前端模型的声明
#include "esp_mn_iface.h" //命令词模型的一系列API
#include "esp_mn_models.h" //命令词模型的声明
#include "esp_board_init.h" //开发板硬件初始化
#include "driver/i2s.h" //i2s 驱动
#include "speech_commands_action.h" //根据识别到的 command 进行语音播报/闪烁 LED
#include "model_path.h" //从 spiffs 文件管理中返回模型路径等 API
7.2 app_main
void app_main()
{
models = esp_srmodel_init("model"); //spiffs 中的所有可用模型或 model 默认是从`flash`读
ESP_ERROR_CHECK(esp_board_init(AUDIO_HAL_08K_SAMPLES, 1, 16)); //Special config for dev board
// ESP_ERROR_CHECK(esp_sdcard_init("/sdcard", 10)); //初始化 SD card
#if defined CONFIG_ESP32_KORVO_V1_1_BOARD
led_init(); //LED 初始化
#endif
afe_handle = &ESP_AFE_SR_HANDLE;
afe_config_t afe_config = AFE_CONFIG_DEFAULT(); //音频前端的配置项
afe_config.wakenet_model_name = esp_srmodel_filter(models, ESP_WN_PREFIX, NULL);; //从有所可用的模型中找到唤醒词模型的名字
#if defined CONFIG_ESP32_S3_BOX_BOARD || defined CONFIG_ESP32_S3_EYE_BOARD
afe_config.aec_init = false;
#endif
//afe_config.aec_init = false; //关闭 AEC
//afe_config.se_init = false; //关闭 SE
//afe_config.vad_init = false; //关闭VAD
//afe_config.pcm_config.total_ch_num = 2; //设置为单麦单回采
//afe_config.pcm_config.mic_num = 1; //麦克风通道一
esp_afe_sr_data_t *afe_data = afe_handle->create_from_config(&afe_config);
xTaskCreatePinnedToCore(&feed_Task, "feed", 4 * 1024, (void*)afe_data, 5, NULL, 0); //feed 从 i2s 拿到音频数据
xTaskCreatePinnedToCore(&detect_Task, "detect", 8 * 1024, (void*)afe_data, 5, NULL, 1); //将音频数据喂给模型获取检测结果
#if defined CONFIG_ESP32_S3_KORVO_1_V4_0_BOARD || defined CONFIG_ESP32_KORVO_V1_1_BOARD
xTaskCreatePinnedToCore(&led_Task, "led", 2 * 1024, NULL, 5, NULL, 0); //开启LED
#endif
#if defined CONFIG_ESP32_S3_KORVO_1_V4_0_BOARD || CONFIG_ESP32_S3_KORVO_2_V3_0_BOARD || CONFIG_ESP32_KORVO_V1_1_BOARD
xTaskCreatePinnedToCore(&play_music, "play", 2 * 1024, NULL, 5, NULL, 1); //开启语音播报
#endif
}
7.2 Operação de alimentação
void feed_Task(void *arg)
{
esp_afe_sr_data_t *afe_data = arg;
int audio_chunksize = afe_handle->get_feed_chunksize(afe_data);
int nch = afe_handle->get_channel_num(afe_data);
int feed_channel = esp_get_feed_channel(); //3;
int16_t *i2s_buff = malloc(audio_chunksize * sizeof(int16_t) * feed_channel);
assert(i2s_buff);
size_t bytes_read;
while (1) {
//第一种方式
//audio_chunksize:音频时间 512->32ms 256->16ms
//int16_t:16位量化
//feed_channel:两麦克风通道数据一回采通道数据
esp_get_feed_data(i2s_buff, audio_chunksize * sizeof(int16_t) * feed_channel);
//第二种方式
i2s_read(I2S_NUM_1, i2s_buff, audio_chunksize * sizeof(int16_t) * feed_channel, &bytes_read, portMAX_DELAY);
afe_handle->feed(afe_data, i2s_buff);
}
afe_handle->destroy(afe_data);
vTaskDelete(NULL);
}
7.3 operação de detecção
void detect_Task(void *arg)
{
esp_afe_sr_data_t *afe_data = arg;
int afe_chunksize = afe_handle->get_fetch_chunksize(afe_data);
int nch = afe_handle->get_channel_num(afe_data);
char *mn_name = esp_srmodel_filter(models, ESP_MN_PREFIX, ESP_MN_CHINESE); //从模型队列中获取命令词模型名字
printf("multinet:%s\n", mn_name);
esp_mn_iface_t *multinet = esp_mn_handle_from_name(mn_name); //获取命令词模型
model_iface_data_t *model_data = multinet->create(mn_name, 5760); //创建
esp_mn_commands_update_from_sdkconfig(multinet, model_data); // Add speech commands from sdkconfig
int mu_chunksize = multinet->get_samp_chunksize(model_data);
int chunk_num = multinet->get_samp_chunknum(model_data);
assert(mu_chunksize == afe_chunksize);
printf("------------detect start------------\n");
// FILE *fp = fopen("/sdcard/out1", "w");
// if (fp == NULL) printf("can not open file\n");
while (1) {
afe_fetch_result_t* res = afe_handle->fetch(afe_data); //获得AEF的处理结果
if (!res || res->ret_value == ESP_FAIL) {
printf("fetch error!\n");
break;
}
#if CONFIG_IDF_TARGET_ESP32
if (res->wakeup_state == WAKENET_DETECTED) {
printf("wakeword detected\n");
play_voice = -1;
detect_flag = 1;
afe_handle->disable_wakenet(afe_data);
printf("-----------listening-----------\n");
}
#elif CONFIG_IDF_TARGET_ESP32S3
if (res->wakeup_state == WAKENET_DETECTED) {
printf("WAKEWORD DETECTED\n"); //如果被唤醒将唤醒标志置位True
} else if (res->wakeup_state == WAKENET_CHANNEL_VERIFIED) {
play_voice = -1;
detect_flag = 1;
printf("AFE_FETCH_CHANNEL_VERIFIED, channel index: %d\n", res->trigger_channel_id);
}
#endif
if (detect_flag == 1) {
esp_mn_state_t mn_state = multinet->detect(model_data, res->data); //将AFE处理后的音频数据给命令词模型
if (mn_state == ESP_MN_STATE_DETECTING) {
continue;
}
if (mn_state == ESP_MN_STATE_DETECTED) {
esp_mn_results_t *mn_result = multinet->get_results(model_data); //得到结果
for (int i = 0; i < mn_result->num; i++) {
printf("TOP %d, command_id: %d, phrase_id: %d, prob: %f\n",
i+1, mn_result->command_id[i], mn_result->phrase_id[i], mn_result->prob[i]);
}
printf("\n-----------listening-----------\n");
}
if (mn_state == ESP_MN_STATE_TIMEOUT) {
//超时关闭
afe_handle->enable_wakenet(afe_data);
detect_flag = 0;
printf("\n-----------awaits to be waken up-----------\n");
continue;
}
}
}
afe_handle->destroy(afe_data);
vTaskDelete(NULL);
}
8 Referência do Github relacionada ao Espressif AI
- esp-sr : Ao mesmo tempo, você pode consultar a documentação do esp-sr
- esp-skainet