1. Introdução
Apache Hudi é uma nova geração de plataforma de armazenamento de dados baseada em computação de fluxo no campo de big data, também conhecida como Data Lake Platform (Data Lake Platform), que integra as principais funções de bancos de dados tradicionais e data warehouses para fornecer integração de dados diversificada , recursos de plataforma de processamento e armazenamento de dados. As principais funções fornecidas pelo Hudi incluem serviço de gerenciamento de tabela de dados, serviço de gerenciamento de transações, adição eficiente, exclusão, modificação e serviço de operação de consulta, serviço de sistema de índice avançado, serviço de coleta de dados de streaming, cluster de dados e serviço de otimização de compactação, serviço de controle de simultaneidade de alto desempenho , Hudi O formato de armazenamento da organização de dados no data lake é um formato de arquivo de código aberto.
O Apache Hudi pode suportar cargas de trabalho de processamento de fluxo em larga escala e, ao mesmo tempo, também fornece pipelines de dados que podem criar processamento eficiente, incremental e em lote.
O Apache Hudi pode ser facilmente implantado em qualquer plataforma de armazenamento em nuvem e, combinado com os mecanismos de consulta e análise de dados Apache Spark, Flink, Presto, Trino e Hive atualmente populares, pode fornecer recursos de análise de dados com desempenho superior.
2 Descrição da arquitetura
A arquitetura geral do aplicativo da plataforma de data lake Apache Hudi é a seguinte:
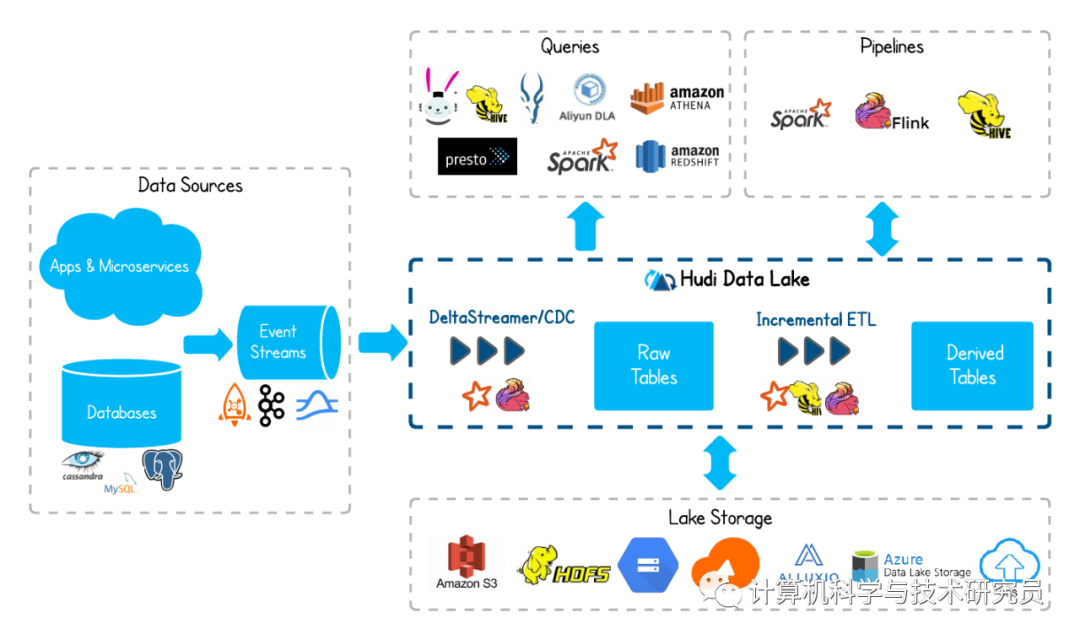
| Fontes de dados Fonte de dados, fornecendo entrada de dados |
| Aplicativos e microsserviços Fontes de dados de tipos de aplicativos e microsserviços, fornecendo entrada para eventos |
| bancos de dados Fonte de dados de banco de dados SQL ou tipo de banco de dados NoSQL, fornecendo entrada de eventos |
| fluxos de eventos Middleware de mensagem ou evento, que aceita a entrada de eventos de outras fontes de dados e os agrega em fluxos de eventos |
| Hudi Data Lake A plataforma de data lake Hudi usa tecnologia de computação de streaming para fornecer serviços de armazenamento e processamento de dados estruturados ou não estruturados em larga escala |
| DeltaStreamer/CDC Processador de eventos de computação em fluxo/alterações de dados de captura, usados para processar fluxos de eventos e processar alterações de eventos |
| Tabelas de linhas Uma tabela de dados para armazenamento de linha, usada para armazenar eventos que foram processados na etapa anterior |
| ETL incremental As etapas de processamento padrão do data warehouse, usando processadores de eventos de computação incremental, streaming e pipeline, convergem para a entrada do próximo fluxo de eventos |
| Tabelas derivadas Armazene o evento de fluxo de entrada da etapa anterior ou os dados finais a serem analisados |
| Armazenamento do lago Armazenamento de organização de dados da tabela de dados Hudi, suporte a HDFS ou armazenamento de objetos em ambiente de nuvem pública |
| Consultas Mecanismo de consulta, fornecendo serviços de consulta e recuperação de data lake Hudi |
| Oleodutos Mecanismo de análise, fornecendo serviços de consulta e análise de data lake Hudi |
(continua)